
Metadata Enrichment
Configuration
Copyright ©
Mindbreeze GmbH, A-4020 Linz, 2024.
All rights reserved. All hardware and software names are brand names and/or trademarks of their respective manufacturers.
These documents are strictly confidential. The submission and presentation of these documents does not confer any rights to our software, our services and service outcomes or other protected rights. The dissemination, publication or reproduction hereof is prohibited.
For ease of readability, gender differentiation has been waived. Corresponding terms and definitions apply within the meaning and intent of the equal treatment principle for both sexes.
General Information
In order for the enrichment processes to be applied, the new metadata must first be added to the aggregated metadata keys in the index settings. For example:
Entity Recognition
Introduction
This chapter deals with the concept, setup, and troubleshooting methods for configuring entity recognition.
Entity recognition configuration
In this chapter, the concept of entity recognition is explained using a simple example.
To set up entity recognition, follow these steps:
- Connect to the Management Center.
- Navigate to the Configuration menu and then to the Index tab.
- Activate the Advanced Settings and open the index settings of the index you want to configure with Entity Recognition.
- Search for the setting “Entity recognition parameters“ in the Management Center
- Define your Entity Recognition rules in the “Pattern Rules” field to match your metadata.
- The following rule formats are supported: https://github.com/google/re2/wiki/Syntax
In our concrete example:
rule=/\// digits /\//.
digits=/\d+/.
Explanation:
The first rule defines that all numbers between two slashes should match (regex):
Example: test/1234test1234/test/543/test (543 is extracted)
Now add a new “Metadata Definition“ to apply the rules for metadata.
Example:
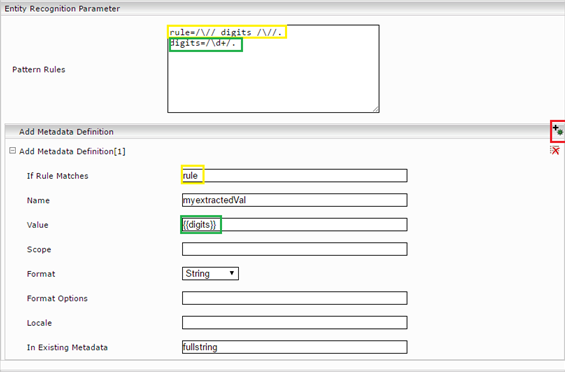
In this example, Mindbreeze searches for numbers between two slashes in the string of the existing metadata with the name “fullstring”. If there are numbers between two slashes, Mindbreeze takes the part of the matches configured in the sub-rule “digits” and writes it as a string in the new metadata “myextractedVal”.
Example:
fullstring: xyz/1234/herbert543/345test
Match of the rule “rule”: /1234/
Value of the rule “digits”: 1234
Value of the metadata myextractedVal==1234
Notes on configuration in the Management Center
When configuring as a metadata in Mindbreeze InSpire, the following fields must be filled in:
- "If Rule Matches": Name of the rule.
- “Name": Name of the metadata
- "Value": Value of the rule. Example: "{{month}}" - can also be normal text or composite. Ex: "Date {{day}}.{{month}}.{{year}}".
- "Format": format of the rule. "string", "date", "number".
- "Format Options": formatting options - especially for date as for simpledateformat
- "In Existing Metadata": scope where the rule will be applied e.g.: content, title, datasource/mes:key, <own metadata>, ...)
- Scope: With the Scope setting it is possible to select an area or several areas with one entity recognition rule, in which the rules for extraction are to be applied. For this purpose, the name of the rule for selecting the area(s) is entered in the scope field. In contrast to value extraction, you have to enter the name without {{}}.
Entity recognition (example: file system)
This chapter uses a simple example to explain entity recognition and its setup with Mindbreeze.
Configuration of entity recognition for a file system:
Pattern Rules:
host=/[^\\]+/.
share=/[^\\]+/.
directory=/[^\\]+/.
UNCPath="\\\\" host "\\" share "\\" directory "\\".
Metadata-Definition 1:
If Rule Matches: UNCPath
Name: FileShare
Value: {{share}}
In Existing Metadata: datasource/mes:key
Metadata-Definition 2:
If Rule Matches: UNCPath
Name: ProjectPath
Value: {{directory}}
In Existing Metadata: datasource/mes:key
Aggregated Metadata Keys (; separated): FileShare; ProjectPath
Date formats for entity recognition are based on the ICU patterns (e.g. locale … de_AT)
Configuration for entity recognition for file system paths (variant 2) – with exceptions:
If the rules are ambiguous, alternative rules, ordering by naming and correct ordering of the metadata extraction definitions can be used to enable more complex usecases. The path as metadata is lower-case and thus better for CSV mapping.
Even a complex use case, in which the rules are ambiguous can be achieved using alternative rules and sequencing by name, as well as the correct sequencing of the multiple metadata extraction. The path, a metadata, is lower-case and thus better for CSV mapping.
Note: An OR (|) operator of sub-rules does not work!
Simple solution without exception:
Pattern rules:
LWPath=/\\\\[^\\]+\\[^\\]+\\[^\\]+\\[^\\]+/.
FilePath=/[^\\]+/.
FullPath=LWPath "\\" FilePath.
Solution with an exception (data\it):
Pattern rules:
ASpecialPath="data\\it".
OtherPath=/[^\\]+/.
BaseShare=/\\\\[^\\]+\\[^\\]+\\[^\\]+/.
LWPathA= BaseShare "\\" ASpecialPath.
LWPathOther= BaseShare "\\" OtherPath.
FilePathA=/[^\\].*/.
FilePathOther=/[^\\].*/.
FullPathA=LWPathA "\\" FilePathA.
FullPathOther=LWPathOther "\\" FilePathOther.
The following screenshot demonstrates the configuration of the rules.


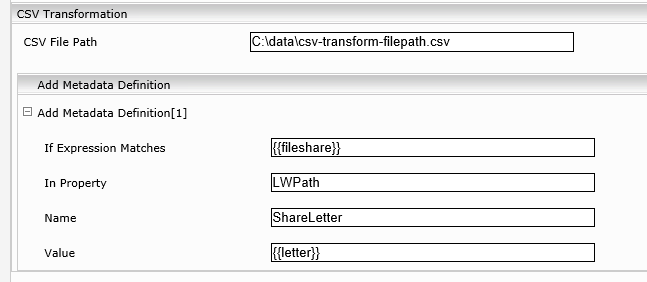
CSV-transform: the extracted value (file share) is case sensitive, so the cases must match. That way the path can be used as source metadata.
fileshare;letter
\\fileserver.mycompany.com\qa\fstest\projekte;U:
\\fileserver.mycompany.com\qa\fstest\vorlagen;T:
\\fileserver.mycompany.com\qa\fstest\allgemein;G:
\\fileserver.mycompany.com\qa\fstest\spezial;M:
\\fileserver.mycompany.com\qa\fstest\data\it;H:
\\fileserver.mycompany.com\qa\fstest\data;H:
\\fileserver.mycompany.com\qa\fstest\data-services;H:
\\fileserver.mycompany.com\qa\fstest\allgemein-retail;G:
Note: A match with mes:key only works in CSV transformation (as well as in ER rules) using: In Property = datasource/mes:key.
Attention: /documents-Servlet does not provide values that are created via index re-invert!
Troubleshooting entity recognition
This chapter deals with troubleshooting the entity recognition rules.
Important information
- In Mindbreeze InSpire, regular expressions are surrounded by a “/”.
- Each rule entry must be separated by a period.
- Rule names may not contain “_”
- Rules are “greedy”, meaning they match as much as possible be careful with “.*” or “.+” configurations).
- Rules are processed alphabetically (case-sensitive!). First in line are uppercase letters from A to Z, then lowercase letters from a to z.
- If a rule matches an entity, no second rule can match. Assumption: If the words “managing board” are used both for the committee and in the keyword, only the metadata with the rule "committee" will include the words “managing board”.
- Entity recognition rules can only be created per index, that is, across all data sources within the index.
Index
Check the index status at http://localhost:8443/index/<Indexport>/statistics
Privileged servlets:
- Connect to the Management Center
- Navigate to the Configuration menu, then go to the index tab
- Activate the advanced settings and open the index setting of the index, which you want to use for testing Entity Recognition
- Deactivate the “Disable Unrestricted Privileged Servlets” checkbox
- Then save the settings and restart the services
- After the services are restarted:
- Open https://yourappliance:8443/index/Indexport (in our example: 23101/processitems) https://yourappliance:8443/index/23101/processitems
- On this page, you can test the rules (pattern rules) with a specific query (e.g. ALL)
- After entering the patterns, click on process. If the syntax of the rules is valid, you’ll have more options to test after pressing the button.
- Select the rule that you want to match and configure the values of the rule(s).
- Then click on process to start testing the rule(s):

Deactivating the greedy strategy of the entity recognition rules
Entity Recognition rules are usually greedy. In the following example, the selected rows are matched:
Rule
R1=/ (?s)(test)(?P<line>.+)\s+(.*Page) /.
Match:

If greedy is deactivated, not everything is matched. Instead, only those blocks that start with test and end with Page are matched:
Rule:
(?U)(?s)(test)(?P<line>.+)\s+(.*Page)(?U)
Match:

Common error sources
An error with the following error message occurred while parsing the ER rules:
“MesQuery::Text::RE2Tokenizer ERROR: Matched empty (epsilon) token, pattern is”
… for instance, a „\“ at the end of a regex is not supported (LWPath=/\\\\[^\\]+\\/. … and an error occurs. Better: LWPath=/\\\\[^\\]+/ “\\“.).
There can also be possible problems with “.*“ in rules.
Entity recognition rules are analyzed in alphabetical order and the first complete match wins.
Regex rules for German words do not match all characters (umlauts, etc.) with \w. Instead, you can use \pL to match all unicode characters.
Typical use cases
Personal information
Social security number
\d{4}(\s|\.|\-)\d{6}
Example
1237 010180
1237.010180
1237-010180
Telephone number
(\+)([\s.\(\)]*\d{1}){8,13}(-)?(\d{1,5})
Example
+43 732 606162-0
+43 732 606162-609
+49(732)606162-609
Number (with delimiters)
RegEx
z1=/\d/.z2=/\d/. (…)Dlmtr=/[\s\-_.:]?/.
z1 Dlmtr z2 Dlmtr z3 Dlmtr z4 Dlmtr z5 Dlmtr z6.
Example
12-34567
12 34 56-7
1-2 3456.7
Amount
((\d{1,3}(\.(\d){3})*)|\d*)(,\d{1,2})
Example
0.84
100,000.49
100,000.00
1,000,000,000,000.00
Date
Handbook for date formats: http://userguide.icu-project.org/formatparse/datetime
- dd(.|-|/)MM(.|-|/)yyyy
- RegEx
((0[1-9])|[1-9]|([1-3][0-9]))(\.|\/|-)((0[1-9])|[1-9]|10|11|12)(\.|\/|-)((19|20)\d{2}) - Example
11.03.2014
11.3.2014
3.3.2014
03.2.2010
11/03/2014
11/3/2014
3/3/2014
03/2/2010
11-03-2014
11-3-2014
3-3-2014
03-2-2010
- RegEx
- dd. MMM yyyy
- RegEx
((0[1-9])|[1-9]|([1-3][0-9]))\..(|January|February|March|April|May|June|July|August|September|October|November|December).((19|20)\d{2}) - Example
3 January 2014
4 February 2012
30 November 2013
- RegEx
- MMM yyyy
- RegEx
(January|February|March|April|May|June|July|August|September|October|November|December).((19|20)\d{2}) - Example
February 2014
September 2014
- RegEx
- MM(.|-|/)yyyy
- RegEx
(January|February|March|April|May|June|July|August|September|October|November|December).((19|20)\d{2})|((0[1-9])|[1-9]|10|11|12)(\.|\/|-)((19|20)\d{2}) - Example
03-2014
03.2014
03/2014
- RegEx
- yyyy(.|-|/)mm(.|-|/)dd
- RegEx
((19|20)\d{2})(\.|\/|-)((0[1-9])|[1-9]|10|11|12)(\.|\/|-)((([1-3][0-9]|0[1-9])|[1-9])) - Example
2014-03-21
- RegEx
- Date-Regex total
((0[1-9])|[1-9]|([1-3][0-9]))(\.|\/|-)((0[1-9])|[1-9]|10|11|12)(\.|\/|-)((19|20)\d{2})|((0[1-9])|[1-9]|([1-3][0-9]))\..(January|February|March|April|May|June|July|August|September|October|November|December).((19|20)\d{2})|(January|February|March|April|May|June|July|August|September|October|November|December).((19|20)\d{2})|((0[1-9])|[1-9]|10|11|12)(\.|\/|-)((19|20)\d{2})|((19|20)\d{2})(\.|\/|-)((0[1-9])|[1-9]|10|11|12)(\.|\/|-)((([1-3][0-9]|0[1-9])|[1-9])) - Date-Regex total II
((((0?[1-9]|[12]\d|3[01])[\.\-\/](0?[13578]|1[02])[\.\-\/]((1[6-9]|[2-9]\d)?\d{2}))|((0?[1-9]|[12]\d|30)[\.\-\/](0?[13456789]|1[012])[\.\-\/]((1[6-9]|[2-9]\d)?\d{2}))|((0?[1-9]|1\d|2[0-8])[\.\-\/]0?2[\.\-\/]((1[6-9]|[2-9]\d)?\d{2}))|(29[\.\-\/]0?2[\.\-\/]((1[6-9]|[2-9]\d)?(0[48]|[2468][048]|[13579][26])|((16|[2468][048]|[3579][26])00)|00)))|(((0[1-9]|[12]\d|3[01])(0[13578]|1[02])((1[6-9]|[2-9]\d)?\d{2}))|((0[1-9]|[12]\d|30)(0[13456789]|1[012])((1[6-9]|[2-9]\d)?\d{2}))|((0[1-9]|1\d|2[0-8])02((1[6-9]|[2-9]\d)?\d{2}))|(2902((1[6-9]|[2-9]\d)?(0[48]|[2468][048]|[13579][26])|((16|[2468][048]|[3579][26])00)|00)))) - Example
31.12.2005
12.12.12
1.2.2003
1.3.98
04-05-2004
Time
(([0-1]?[0-9])|([2][0-3])):([0-5]?[0-9])(:([0-5]?[0-9]))?
Example
11:00:23
12:30
E-mail
([a-zA-Z0-9_\-\.]+)@([a-zA-Z0-9_\-\.]+)\.([a-zA-Z]{2,5})
Example
david.porter@inspire.mindbreeze.com
egov@mindbreeze.com
IBAN
AT\d{18}
Example
AT002105017000123456
Split List by “,” or other symbols
In this example a list of entries separated by semicolon will be interpreted as well as List in Mindbreeze InSpire.
Input: List of word, word,…
value=/[^\s,][^,]*[^,\s]?/.
rule= /\s*/ value /\s*(,\s*|$)/.
Catalog enrichment
New metadata is added to a document. The new metadata is created using a “catalog” (e.g. CSV file).
The following options are outlined here:
- Index CSV transformation (functionality already available in the index)
- HierarchicalCSVEnricher (separate ItemTransformation plugin)
- FileMetadataEnricher (separate ItemTransformation plugin)
CSV Transformation
This section focuses on metadata enrichment using a CSV file. In doing this, it is possible to compare the value of a metadata with the value of a particular column in the CSV. If the value from the metadata matches the value from the column, you can write the value of another column from the same row to a new metadata and attach it to the result.
Setting up the CSV transformation
This chapter uses a concrete example to illustrate setting up CSV transformation. The following steps must be performed for the configuration:
Connect to the management center (default: https://IhreAppliance:8443).
Navigate to the Indices tab, enable the Advanced Settings, and then expand your Index.
Search for the “CSV Transformation” settings and set the function as shown in the example below.
Example: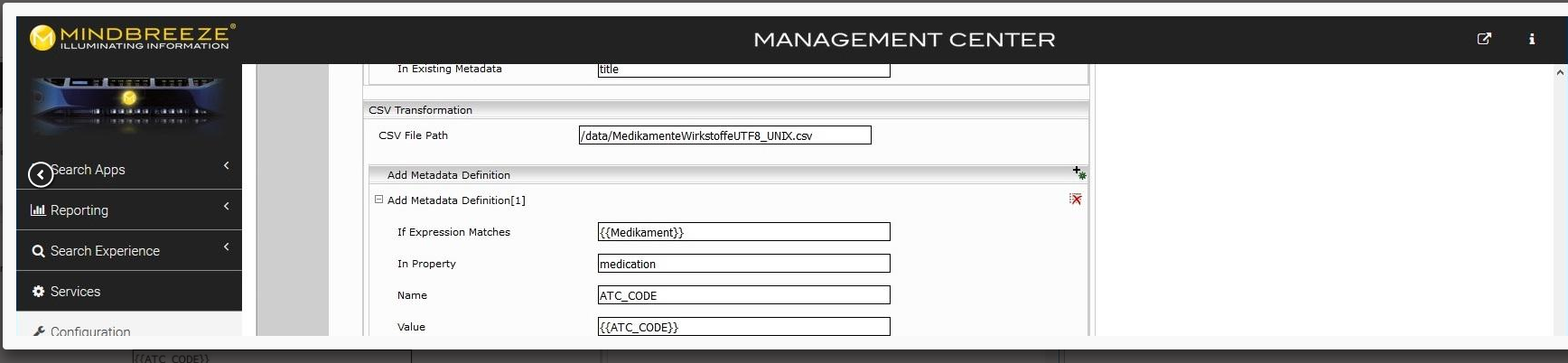
CSV File Path: Path on the server of the CSV file copied by you
If Expression Matches: The name of the column in the CSV, which must match the value of a metadata for the transformation to be performed
In Property: The existing metadata which should be compared with the value from the column in the CSV
Name: The name of the metadata which should contain the new enriched value
Value: The name of the column, the value of which is to be written to the new metadata "Name" in order to enrich the result
Copy any CSV file to the /data/ directory on your Mindbreeze InSpire.
How does it work?
The value of the existing metadata (“medication”) is compared with the value from the column “Medikament”. If a row was found in which these two values were equivalent, the value is extracted from the ATC_CODE column and attached to the metadata ATC_CODE.
Changes in the CSV file using a spreadsheet program
If you edit the CSV using a spreadsheet program such as Excel, you must ensure that the CSV is still in UTF8 format rather than UTF8-BOM format after processing.
You can check this with any text editor such as Notepad++ and, if necessary, convert it back to the UTF8 format.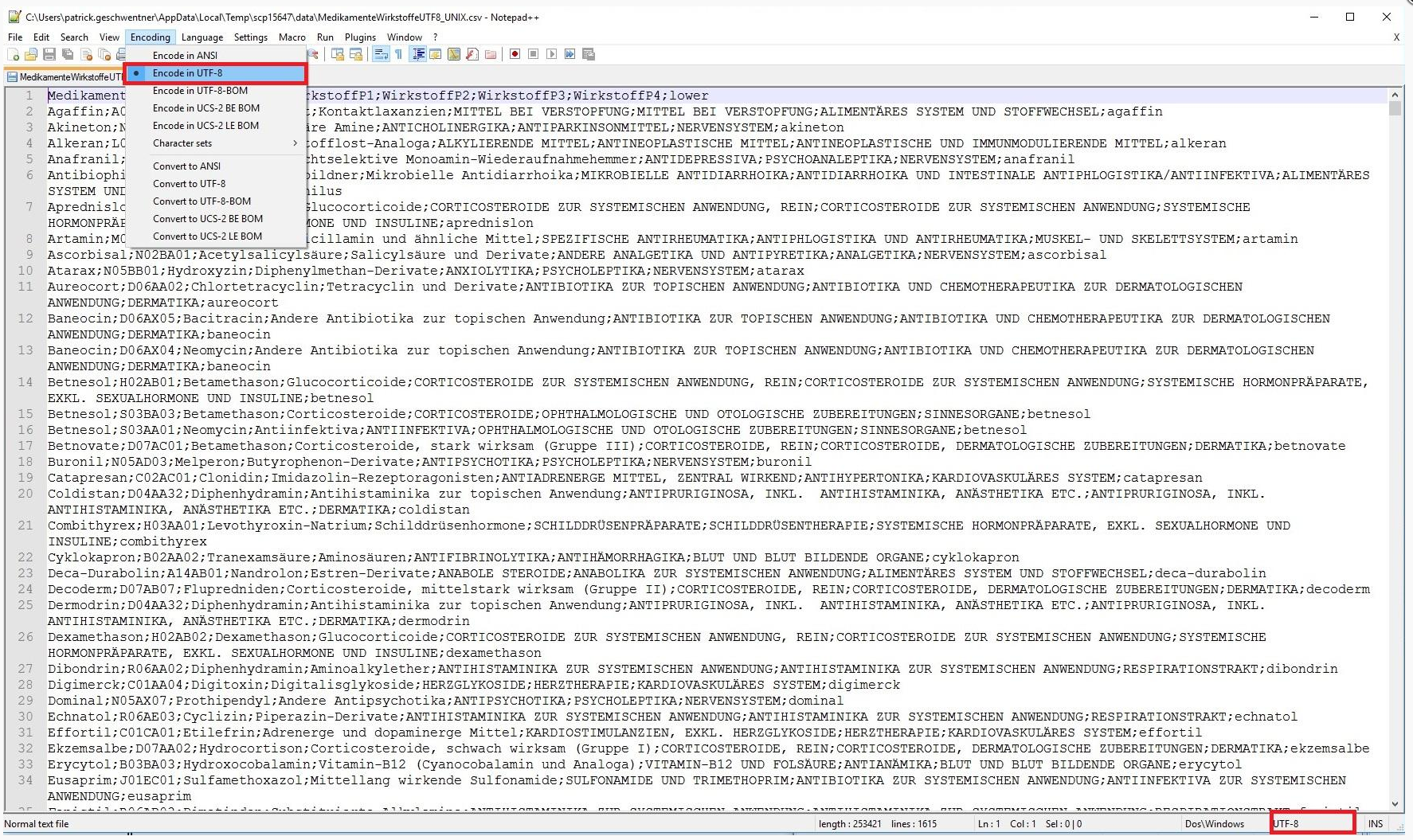
Synthesized Metadata
Using Synthesized Metadata Definitions, rules can be created to enrich documents with metadata. These rules are dynamically evaluated at the time of the search.
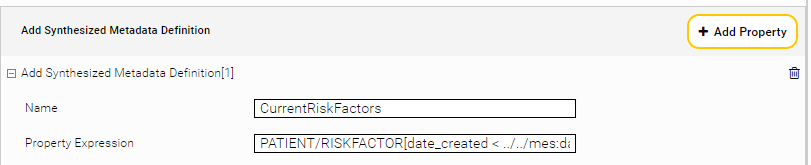
Name | Name of the synthesized metadata |
Property Expression | Expression in Mindbreeze Property Expression Language used to synthesize the metadata value. |
Precomputed Synthesized Metadata
Using Precomputed Synthesized Metadata Definitions, rules can be created to enrich documents with metadata. These rules are evaluated during index inversion to synthesize metadata.
Please note that only a subset of Mindbreeze Property Expression Language is supported for Precomputed Synthesized Metadata Definitions. All expressions in Mindbreeze Property Expression Language - Search specific language elements are not supported, which also affects expressions that contain references, such as paths or inverse references. If you want to use expressions with references, you can create Synthesized Metadata Definitions instead.
Please note that predefined Metadata, like mes:key, Category, CategoryInstance and FQCategory are not available for Precomputed Synthesized Metadata Definitions. Instead, Synthesized Metadata can be used.
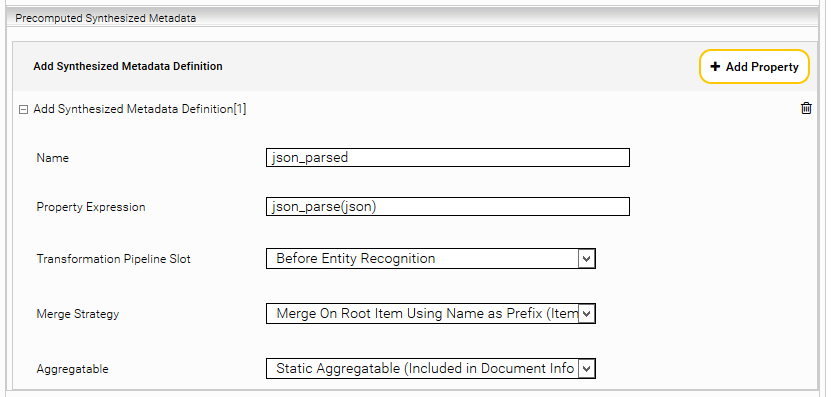
The following options are available:
Name | Name of the synthesized metadata |
Property Expression | Expression in Mindbreeze Property Expression Language used to synthesize the metadata value |
Transformation Pipeline Slot | Defines where the metadata should be synthesized in the semantic pipeline. The following options are available:
|
Merge Strategy | The following options are available:
|
Aggregatable | Defines whether the synthesized metadata should be aggregatable. The following options are available:
|
Hierarchical CSV Enricher (ItemTransformer.HierarchicalCsvEnricher)
Introduction
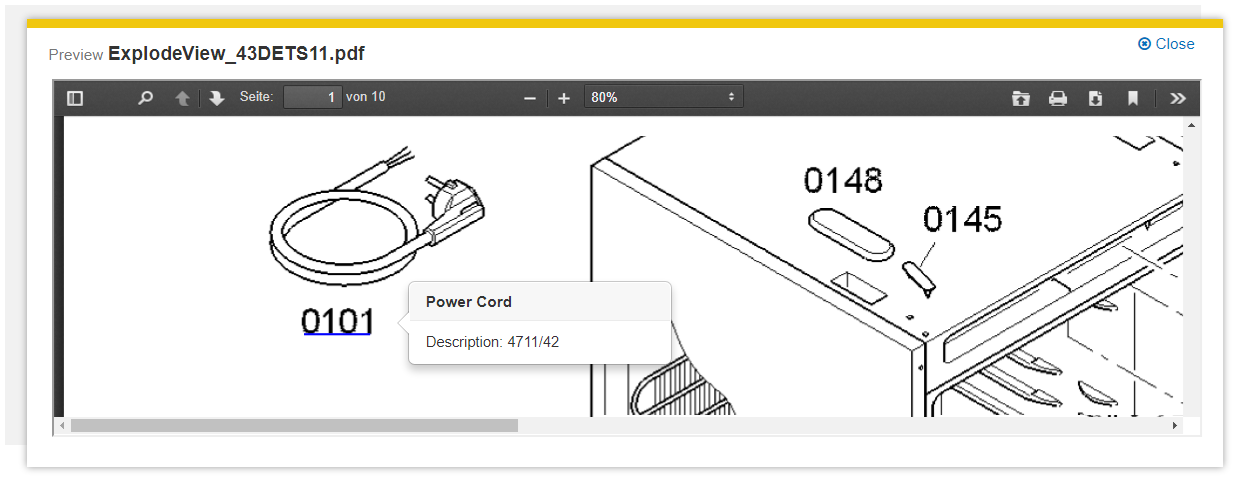
This plugin annotates special words in PDF documents, which are specified in a CSV file. These annotated words (matches) are displayed in the PDF preview as clickable hyperlinks. Custom actions can be linked to these hyperlinks in a custom client. For example, a mouse-over on a particular word can display an explanation in the form of a tool tip. Additionally, the plugin can generate metadata for matches and annotate entities.
Installation
To use the plugin, the MetadataTransformationService plugin must be added to your Mindbreeze installation by loading the appropriate plugin.
Configuration
The plugin is generally started as an independent service (much like caching principal resolution services). References to the service are configured in the indices. The plugin itself is configured in the section “Services”:
- Enable the plugin for each desired index using the Management UI:
- Go to the “Indices” tab and enable “Advanced Settings”
- Scroll down to “Services“
- Select the “ItemTransformationServicePlugin.HierarchicalCsvEnricher” plugin and click “Add”.
Basic settings
“Display Name“ | For simple assignment to the index, select a name that is as descriptive as possible. |
“Nodes“ | Select the node on which you want the service to run. Only indices on the same node can use the service. |
“Bind port” | A free TCP port that is not used by any other service. |
“Max Threads“ | The maximum number of threads the service is allowed to use when processing requests. |
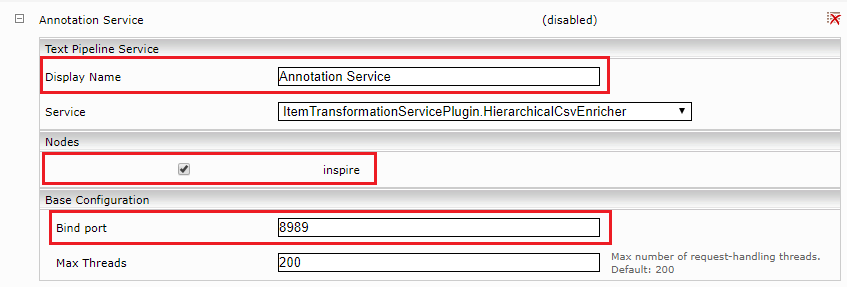
Configuring CSV transformation
Transformation Timeout (ms) (Advanced Setting) | Defines the timeout (in ms) after which the transformation is aborted. The metadata transformed up to this moment is saved. Default value: 250000 ms. |
Document Exclusion Rules | Rules that skip the transformation of documents with certain metadata. See the section below. |
CSV File Path | Paths to the CSV files. Column labels are expected in the first line of the CSV file. You can add several CSV files by clicking the “Add” button. The CSV files are automatically re-imported after a change. |
CSV Delimiter Character | The CSV delimiter. A character. (usually a semicolon) |
Term Column Name | Name of the CSV column used for matching in the documents. |
Entity Column Name | Name of the CSV column used for annotating entities in the documents. (Not compatible with "Entity Value") |
Entity Value | Static value which will be added as entity annotation for all matches. (Not compatible with "Entity Column Name") |
Source Metadata Name | Specifies the metadata from which the text will be taken in order to perform the matching. If this setting is empty, the text of the document is used for matching (default). |
Enable Build Hierarchy | The plugin can be switched to a hierarchy mode with this option. For this, the CSV must have a parent-child relationship between the entries, which is mapped via another column pointing to the parent entry. The hierarchy itself is then used as the metadata value. |
Parent Column Name | Name of the CSV column pointing to the parent entry (the Term-Column in the CSV). This option only has an effect when Enable Build Hierarchy is enabled. |
Skip Root Element | If this option is enabled, the root of the hierarchy is not added to the metadata value. |
Target Metadata Name | Name of the metadata which will be generated. |
Target Metadata Name Pattern | Template pattern from which the metadata name is generated. In placeholders, the CSV column names can be used in double curly brackets, for example: {{Meta Name}}. |
Target Metadata Value Pattern | Template pattern from which the metadata value is generated. In placeholders, the CSV column names can be used in double curly brackets, for example: {{Term Name}} (non-hierarchy mode). |
Merge Strategy | The solution strategy can be defined here if there is already a metadata with the same name. Either “Keep Existing“ or “Overwrite Existing“ |
Overlapping Match Strategy | If multiple overlapping matches are found in one place in the document, this option determines which matches will ultimately be used. Two strategies are available: "Longest" uses only the longest match (number of letters). Note: if "All" is used, overlapping annotations may occur in combination with the "Link HREF Pattern" option. |
Target Metadata Property Constraints | Here you can specify conditions under which a metadata value is to be added. The conditions correspond to the item properties and are configured as a comma-separated list of key value pairs, with the key value pairs separated by an equal sign, for example: name=bob,person=true. This function is usually used to prevent metadata values that are already included in the attribute metadata anyway from being added to the ("normal") metadata. The default value is empty. (all values are added) |
Target Metadata Item Name | Name of the “item” metadata. The plugin can also create a complex metadata containing the corresponding CSV entries for all matches. In addition, a list of events with properties is kept for each CSV entry. |
Target Metadata Item Default Properties | The default values of the properties in the event for the metadata item can be defined here. The properties are configured as a comma-separated list of key value pairs, where the key value pairs are separated by an equal sign. E.g. name=bob,person=true. |
Link HREF Pattern | Template pattern from which the URL is generated with which the PDF document is annotated. The CSV column names in double brackets can be used in placeholders, for example: http://www.example.com/{{Term Name}}. Note: The URL must be valid. The value of the placeholder is URL-encoded. In order for the URL to also be displayed in the PDF preview, in the settings “Aggregated Metadata Keys” of the relevant index the value “@content” must be set. |
Add Additional HREF Link HTML Annotation | If this option is enabled, additional HTML tags are created for HREF links. This makes the links also work in document previews other than PDF, such as HTML or docx. All annotations will be aggregated as well. If this option is to be enabled, a Precomputed Synthesized metadata must also be set over the content in the respective index:
"Transformation Pipeline Slot" and "Aggregatable" can be left at the default value. |
Enable Stemmer | Enables the stemmer. This increases the number of matches, as the modified forms of words also generate matches. |
Stemmer Language | The language of the stemmer. E.g. german, english, russian |
Stemmer Skip Short Roots Length | When using the stemmer, false-positive matches can occur if words in their root form become too short. This setting specifies that the stemmer will not be used for very short stem forms. Defines the minimum length of the stem form as of which the stem is no longer used. |
Stopword Vocabulary Path | Path to a text file with stop words. Stop words are ignored and skipped. One word per line applies in the text file. Case sensitive. |
Replacement Patterns | Replacement rules to replace any character string with another character rule. One rule per line. A rule consists of two parts that are separated by the character string “|>”. The left side is a regular expression (Java regular expression), the right side is any character string. Note: These replacement rules do not change the actual document content, but only affect the generation of new metadata, for example: “(?i:ö)|>oe” replaces the character “ö” with the character string “oe”. |
Attributes | Rules for adding properties to the metadata under certain conditions. See the next section. |
Filter Patterns | Rules from regular expressions (Java) to remove matches. Used to remove false positives. One rule per line. A rule consists of up to three parts. The parts are separated with <| and |>. The three parts correspond to a “prefix", “infix" and “postfix" expression of regular expressions used around a match. If all specified expressions apply, the rule is active and the match is removed. E.g. The rule John\s$<|^Joe$|>^\sDoe removes the match „Joe“, if, for instance, it occurs in connection with: “His name is John Joe Doe, she said.” To simplify, parts of the rule can also be omitted. For example, the following rules are also allowed: ^Joe$|>^\sDoe or John\s$<| The rules are case sensitive. |
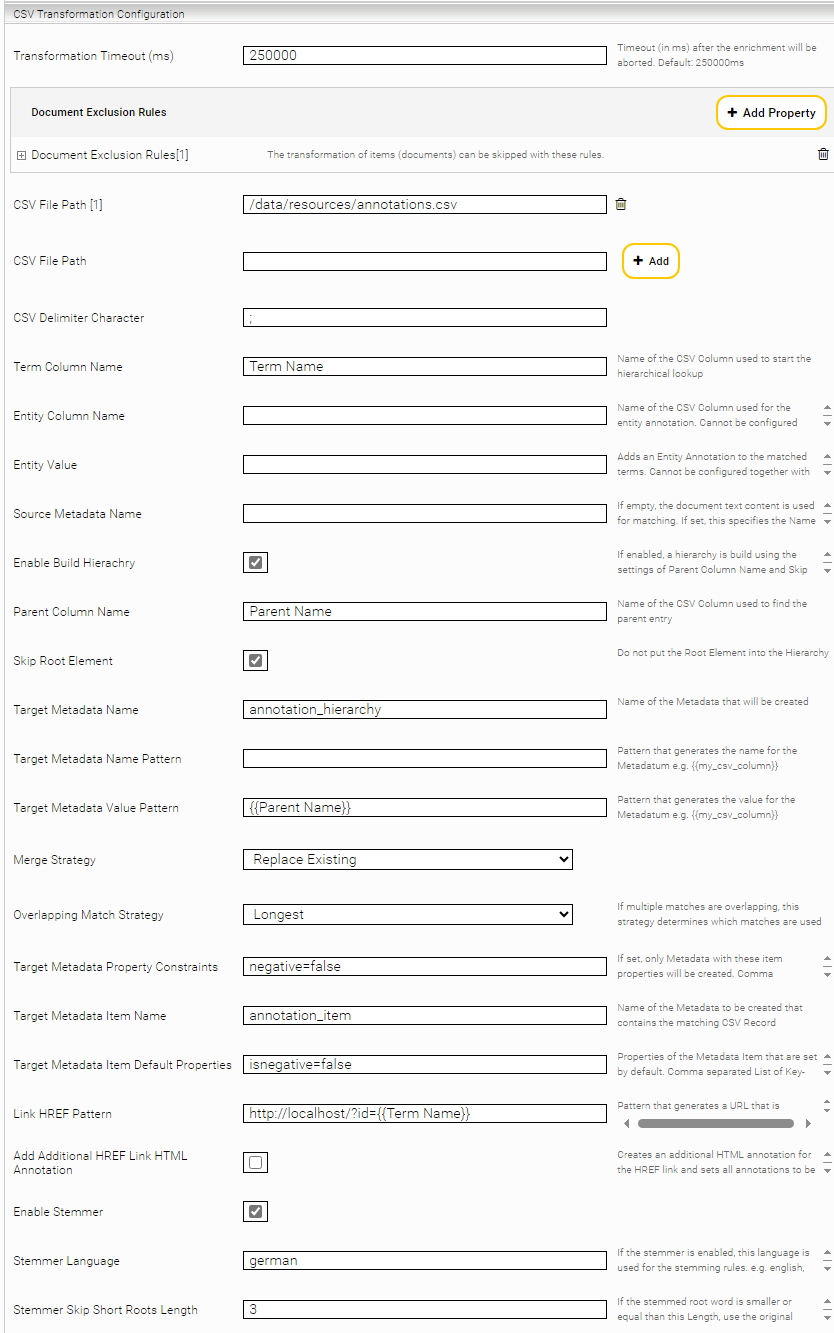
Document exclusion rules
Usually, every document in the index that has configured the transformation service is transformed. With this rule, however, certain documents can be omitted on the basis of metadata and will remain unchanged.
“Metadata Name“ | Name of the metadata to which the rule refers. |
“Exclusion Pattern“ | Regular expression (Java) that is matched to the value of the metadata. If there is a match, the document is not transformed. |

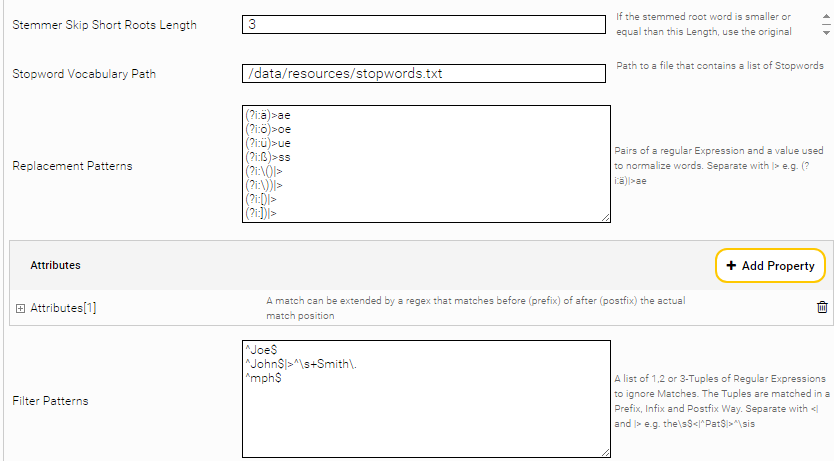
Attributes
Metadata can be modified for matches based on rules from regular expressions. Add attributes with the plus icon.
“PatternPosition“ | The rule applies immediately before the actual match ("prefix") or immediately after the actual match ("postfix"). |
“Patterns“ | List of regular expressions (Java). One expression per line. The regular expressions are applied directly before ("prefix") or after ("postfix") the actual match. If an expression matches, the rule is active. The rules are case insensitive. For example, the rule “no\s+$” becomes active in the match "animal" when it occurs in the following context: "no animal was hurt." |
“Add Metadata Name“ | If the rule is active, a metadata item with this name is created. The value of the metadata is the same as in "Target Metadata." |
“Append HREF Value“ | If the rule is active, this string is added to the "Link HREF Pattern." Note: The URL must remain valid. No automatic URL escaping is carried out. |
“Target Metadata Item Properties“ | If the rule is active, these properties are added or overwritten to the metadata item in the event. The properties are configured as a comma-separated list of key value pairs, where the key value pairs are separated by an equal sign. E.g. name=printer,person=false |
Configuring the index
In order for the index to use the configured service, the service must be referenced in the index settings under "Item Transformation Services." To do this, click "Add" and select the service you have specified.
A property "launchedserviceid" is automatically created; there is no need to change it.

Use as a ContentFilter service
With the installation of the MetadataTransformationService plugin, a filter plugin "FilterPlugin.HierarchicalCsvEnricher" is also registered, which can be enabled for the extension “textcatalogenricher." Navigate to the "Filter" tab in the settings. The configuration is similar to the "ItemTransformer.HierarchicalCsvEnricher" plugin. The following metadata must be set in the filter request:
“extension“ | Must be set to "textcatalogenricher" |
“contentextension“ | Determines the extension that the plugin sets after processing. E.g. “txt“ |

Enable the "Advanced Settings" and add settings for the “FilterPlugin.HierarchicalCsvEnricher – Plugin" under "Global Filter Plugin Properties."
File Metadata Enricher
This chapter deals with the use of the File Metadata Enricher. This plugin allows you to enrich indexed documents (e.g. PDF files) with external sources such as an XML file or a CSV file. This chapter differentiates between XML file metadata enrichment and catalog settings.
Activation
The file metadata enricher is available as an ItemTransformationService plugin and as a PostFilter plugin.
You can configure as the item transformation service for an index service:

The file metadata enricher for a filter can be configured as a post filter plugin. The transformation then happens after filtering.

XML file metadata enrichment
This mechanism is very similar to the mechanism of CSV transformation. In essence, this is about the possibility of comparing the value of a metadata with the value in an XML file. If, for example, there is a file with content (e.g. mindbreeze.pdf) in a data source and another file that contains the metadata separately (e.g. mindbreeze.xml), they can be merged into one result to link the content to the metadata. This mechanism is explained in more detail in the following example:
Configuration example
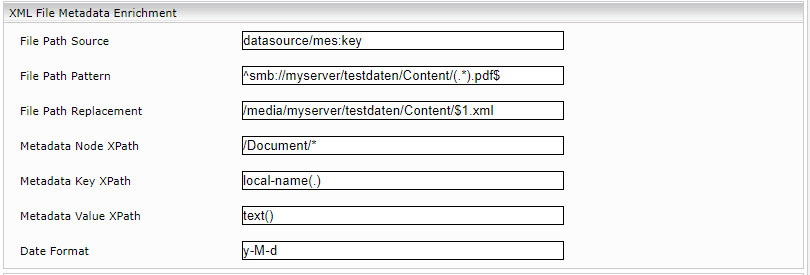
Explanation
File Path Source: Name of a metadata used as a source for the enrichment. For example, a metadata containing the path of the current result can be used. For instance, in the Microsoft File Connector, datasource/mes:key contains smb://myserver/testdaten/Content/.
File Path Pattern: Limits the enricher’s scope of application. All results where the mes:key values do not match the regex regex from File Path Pattern are ignored (The enricher is not applied).
File Path Replacement: The path that contains the metadata of a file is specified here. The files must be located locally on the appliance or at least mounted on it. It is possible to reference a matching value of the regex specified in File Path Pattern as a variable here. The matching groups (REGEX) can be referenced in ascending order with $1 (e.g. $1, $2, $3, ...). The group (.*) can therefore be referenced with $1. In our case, the name of the file is extracted from the string that matches the File Path Pattern.
Metadata Node XPath: Each XML node that is made by this XPATH is interpreted by the enricher as an object with metadata.
Metadata Key XPath: The string that is matched by this XPATH expression is used by the enricher as the name of the new metadata.
Metadata Value XPath: The string that is matched by this XPATH expression is used by the enricher as the value of the new metadata.
Date Format: If a format is specified in Java Simple Date Format, the enricher will try to interpret each string that is matched by Metadata Value XPath as a date in the specified format to provide the entire functionality of the Mindbreeze date format. If the string is not in the specified format, the enricher performs a fallback and interprets the matching string as a string.
Example
This chapter uses a concrete example of the enricher for illustration.
Configuration
XML file (1.xml)
<?xml version="1.0" encoding="utf-8"?>
<Document>
<UserID>4711_12</UserID>
<DocID>PDF_4711_12_CV_001.pdf</DocID>
<DocType>CV</DocType>
</Document>
Explanation
If it matches the regex from the file path pattern, the metadata datasource/mes:key is compared with all local or mounted file names from the file path replacement path for each result that was configured for the index on which the metadata enricher is configured. In so doing, the file name that was defined as a regex group in the file path pattern is used in the File Path Replacement at the reference point.
Example:
Source file: …/1.pdf File Path Replacement: …/1.xml
If the paths match, the XML node /<Document>/* is searched for in the .xml and all child nodes of the node are interpreted as relevant information. The name of the node is interpreted as the metadata name of the new metadata to be created. If the current child node contains a text(), this is set as the value for the newly created metadata, and the metadata is attached to the current result in the index.
Example:
In our case, the following indexed metadata would be attached to the already indexed file 1.pdf:
UserID: 4711_12
DocID: PDF_4711_12_CV_001.pdf
DocType: CV
Catalog Settings
This mechanism uses a CSV file for enrichment. As with CSV transformation, information from Mindbreeze is compared with the value of a column in the CSV. Unlike CSV transformation, the metadata cannot be selected for comparison because the plugin is actively searching for matches in the content of the file. Another important function of the plugin is the recognition of negations. If, for example, there is a match for renal failure, but renal failure is not mentioned in the text, renal failure is attached to the result as a negation in a separate metadata. Additionally, this feature allows automatic links to be attached behind the hits and visualized in the PDF preview. The detailed operation of this function is explained in the following section.
Configuration example
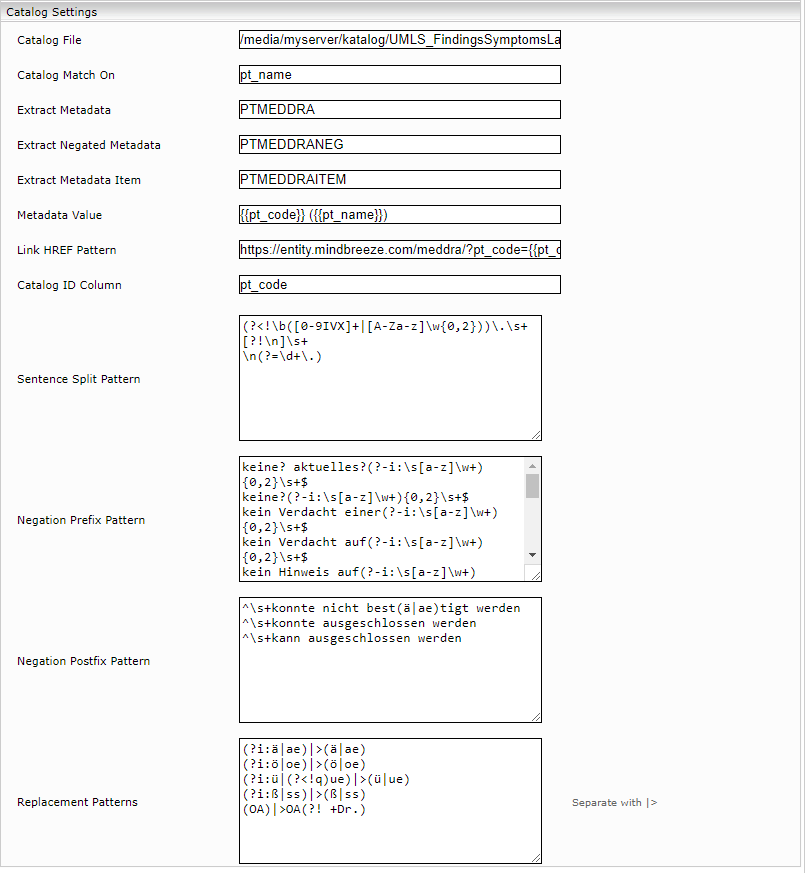
Explanation
Catalog File: This setting includes the path of the CSV file to be used for enrichment. The file must be located locally on the Mindbreeze InSpire Appliance or mounted on it.
Catalog Match On: This setting specifies which column of the CSV file is compared with the information from the content of the results in order to recognize a match.
Extract Metadata: In this field, the name of the metadata is specified in which the text of the Metadata Value column is inserted if there is a match. The metadata is attached to the result.
Extract Negated Metadata: With this setting, you specify the name of the metadata that contains the text of the Metadata Value column if it is matched in the case of a negation. This metadata is attached to the result. The match must be recognized as follows:
Negation Prefix Pattern + Catalog Match On (string for matching) + Negation Postfix Pattern
Extract Metadata Item: This metadata contains a structured form of the entire applied CSV. This metadata is not intended to be a filter and is only intended to support the development of Insight Apps.
Metadata Value: This field must contain the column name of the CSV defined in the Catalog File setting. If the value of the Catalog Match On column matches the string currently compared from the content of the result, the value of the column specified in the Metadata Value field is attached as a string to the metadata Extract Metadata.
Link HREF Pattern: In this setting, a link can be assembled using the extracted metadata. This link is then available in the PDF preview of the client. This link can be interpreted by the developer of the Insight App. The format of the link can be specified as follows:
https://entity.mindbreeze.com/meddra/?code={{pt_code}}
Instead of the placeholder {{pt_code}}, the value that was actually extracted is inserted in the column pt_code from the CSV at time of inversion.
Catalog ID Column: This setting determines which column of the CSV file is unique. This is used internally by Mindbreeze.
Sentence Split Pattern: This setting serves to divide the content of a sentence into sentence parts. The enricher is applied only in those parts of sentences that correspond to the regular expression given here.
Negation Prefix Pattern: This pattern specifies the prefix (usually text) to be used to recognize a negation. Here again, syntax means the syntax of the regular expressions.
Negation Postfix Pattern: This pattern specifies the Postfix (usually text) to be used to recognize a negation. Here again, the syntax means the syntax of the regular expressions.
Replacement Patterns: This field allows certain occurrences of words, sentences, or letters to be synonymous for the enricher. For example, this means it would be possible for ä to be ae and also for ae to be ä. The syntax for this is shown in the following example:
(?i:ä|ae)|>(ä|ae)
(?i:ae|ä)|>(ae|ä)
The symbol, |>, is used as separator. Each rule must be entered as a separate line in the configuration field.
Using the new metadata
The document Development of Insight Apps illustrates how the metadata can be used in a PDF preview when developing Insight Apps.