
Product Information
Mindbreeze InSpire
Copyright ©
Mindbreeze GmbH, A-4020 Linz, 2024.
All rights reserved. All hardware and software names used are registered trade names and/or registered trademarks of the respective manufacturers.
These documents are highly confidential. No rights to our software or our professional services, or results of our professional services, or other protected rights can be based on the handing over and presentation of these documents. Distribution, publication or duplication is not permitted.
.
.
Overview 
This product information (PI) defines the scope of usage and the features of Mindbreeze InSpire services. In addition, it provides an overview of the application interfaces and supported platforms.
Mindbreeze InSpire is a software system enabling the search for information objects in a corporate context ("Enterprise Search Software"). Information objects can be any kind of information contained in structured, partially structured or unstructured storage systems. For most use cases, these information objects will be files in a file system, e-mails in an e-mail inbox system or documents in a document management system or archive (if connected to Mindbreeze InSpire via the Mindbreeze InSpire SDK).
Licensing
The use of the software product underlying the service package is based on a licence model for which
- a. the number of documents indexed with the help of the software product and
- b. the number of calls to the Insight Services of the software product in a period of 12 months (=12 month period) is decisive. The start date for the 12-month period of calls is the start date of the service package. The count is reset once (to '0') at the start of each new 12-month period so that the total number of calls can be used again for the next 12-month period. If the customer switches to a service package with higher performance parameters during a 12-month period, the aliquot fee to be paid for this will be charged for the remaining payment period of the original service package. The customer is entitled to the aliquot number of calls from the higher service package for the remaining term. During the term of the service package, it is not possible to switch to a service package with lower performance parameters.
A document is a file that can be managed or edited by a programme, a compound file and its contained files (a file that contains other data formats, such as a Word document or PDF document) or an electronic document (text, image and/or audio information) that has been created and converted by digitisation into one or more files/documents (in the index).
A call consists of a request from a user or service and a response from the respective Insight Service called. Each request/response is counted as one call. If several Insight Services are involved in a request, these internal calls are also counted as individual calls.
Which calls are counted is explained in detail in this product information.
The software product seamlessly records the number of documents indexed by the customer with the help of the software product as well as the number of Insight Service calls and continuously displays this number in the user interface visible to the customer. This recording technology alone is decisive for determining the number of documents that have been indexed with the help of the software product. Once the maximum number of documents agreed with the customer has been reached, no further documents can or may be indexed using the software product. If the maximum number of calls to Insight Services agreed with the customer has been reached, no further calls can or may be answered using the software product.
The licence material also includes the application documentation. The licence material is protected against duplication. The licence material includes new editions or additions to the licence material that the customer receives from Mindbreeze during the agreed term of the contract. The same applies to corrected versions. The software product is protected by an electronic licence key, which is also part of the licence material.
System Overview
Mindbreeze InSpire comprises a multi-stage service-oriented architecture for indexing and searching document files and e-mails on desktop and server computers in enterprises.
For accessing systems containing contents to be indexed (for search) – i.e. data sources – the following architecture components are utilized: index service, filter service, crawler service, query service and client service. The chart below shows the logical components of this architecture.
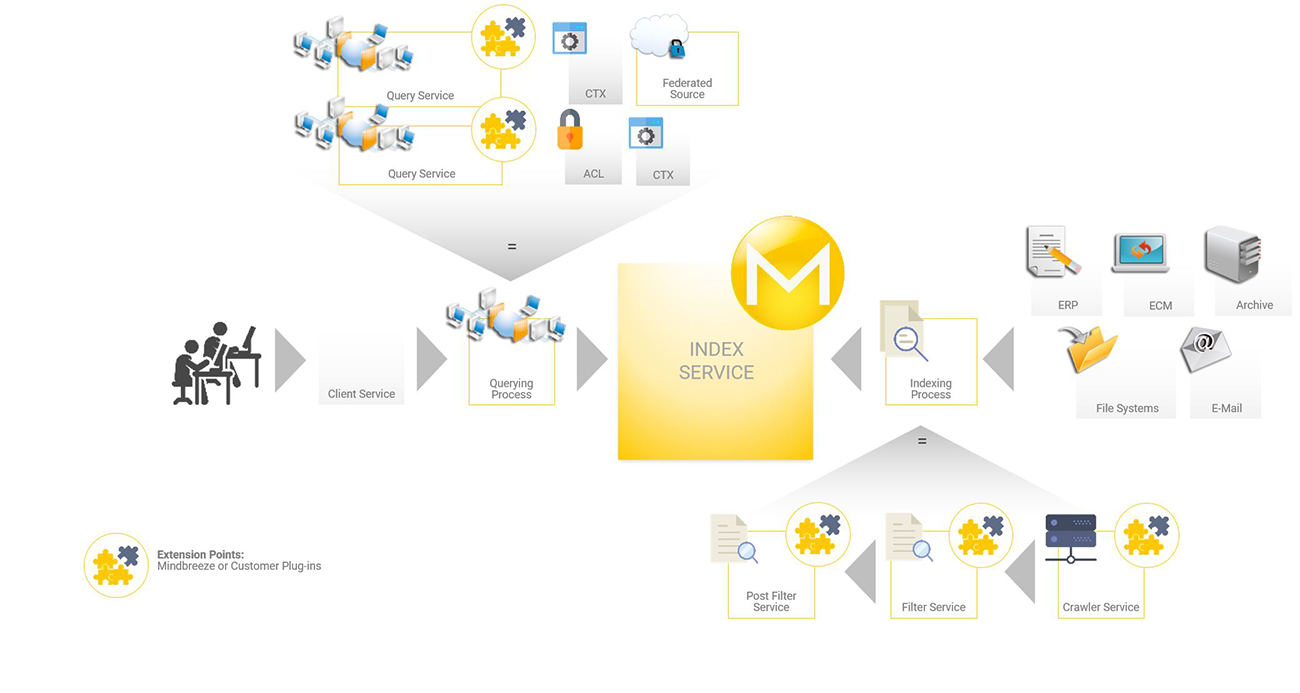
The above chart shows the system for indexing typical schematic data sources. The components correspond to the essential working steps of the indexing process and will be discussed in the following chapters.
All components communicate based on HTTP/S connections.
Mindbreeze InSpire – Crawler Service
The crawler searches the source system exhaustively for new and changed contents that need to be indexed.
This can be achieved in two ways:
- either the crawler searches the source system actively (e.g. file systems) to identify changed data and to forward them to the indexing process or
- the source system (e.g. DMS) is able to identify all changes itself and forwards this information to the crawler.
Mindbreeze InSpire - Filter Service
The Mindbreeze InSpire – Filter Service enables extraction and filtering of the textual information from various file types. For this purpose, document files are forwarded by Mindbreeze InSpire - Crawler Service to Mindbreeze InSpire - Filter Service.
Note: Due to many proprietary formats the filter service cannot guarantee that the text/HTML output is 100% identical to the original file content.
Mindbreeze InSpire - Index Service
In this working step, the actual index for full text search is created or updated if the source system was changed. The index store can be considered as storage with index information which optimized to answer search queries.
Mindbreeze InSpire – Index Services store objects/documents with each up to 200 metadata and a maximum of 10MB per metadata value. Supported maximum is 200 annotations per content. The maximum supported content size is 50MB. The theoretical maximum document size is 1GB including metadata. For each document at most 100000 unique terms are processed. Per index the average consumption (plaintext content, inverted index, term lexicon, ...) of a document of maximum 500KB is supported.
Mindbreeze InSpire - Query Service
The clients connect with Mindbreeze InSpire – Query Service to query the index. Query loads can be distributed by utilizing several Mindbreeze InSpire – Query Service and Client Service services. Several types of clients can be used (e.g. Mindbreeze InApp client, to be integrated into third-party products), which can be realised based on Mindbreeze InSpire SDK.
Mindbreeze InSpire – Client Service
The Mindbreeze InSpire – Web Client connects with the Client Service to send queries to the Query Service.
Mindbreeze InSpire - Insight Services
Insight Services allow insights to be extracted from data and made available via APIs. Insight Services are licensed on a call basis. A call consists of a request and the corresponding response. If sub-calls are made for a call, these are also counted as additional calls.
Insight Services are used in the following use cases, among others:
Fact extraction
Categorisation of images and text
Retrieval Augmented Generation (RAG)
Generated information in the form of insight apps such as 360-degree views
Mindbreeze InSpire - Insight Services for RAG
The Insight Services for RAG form the basis for GenAI use cases based on Mindbreeze InSpire. The Insight Services for RAG use the semantic search of Mindbreeze InSpire on the one hand and a Large Language Model (LLM) on the other. This allows answers to questions to be generated in natural language formulations on the basis of facts extracted from the index.
As can be seen in section 6.7 InSpire AI Chat, various LLMs can be used. If LLMs hosted by Mindbreeze are used, not only the call itself is relevant in this case, but a token limit can also be applied, depending on which LLM is used.
The semantic search is explained in more detail in section 5.5.3 Semantic Sentence Similarity Search.
Mindbreeze InSpire – Management Service
Mindbreeze InSpire – Management Service enables central configuration and deployment of services for Mindbreeze Enterprise Search.
Mindbreeze InSpire – Advanced Configuration
Mindbreeze InSpire – Advanced Configuration helps you to configure a distributed Mindbreeze InSpire infrastructure.
Access Check
An essential component for securing access rights is the so-called access check. The access check ensures that the context of the user logged onto the system is evaluated for any potential search result and applied so that only those search results a user has the appropriate rights for will be displayed. This can be an external authorization of results or the authorization of results against an ACL (access control list) stored in the index. This depends on the data source connected via a specific connector.
Context Interface (CTX)
The context of files and documents that are displayed as search results in a client (within the context of a query) is provided by this component. This enables, for example, the provision of application-specific context menu entries for data and documents in the search result list.
Features
This section shows all features of Mindbreeze InSpire.
Availability and Scalability
- The server-side Mindbreeze InSpire software architecture is based on redundant units. Mixing operating systems in one infrastructure is not supported.
- The scaling via hardware units optimizes response times and makes the system highly available. In addition, a redundant structure of backend systems increases availability and in this way avoids a typical "Single Points of Failure".
- The following redundancy options are possible:
- The Mindbreeze InSpire – Client Service can be operated redundantly with the use of load balancing hardware.
- The Mindbreeze InSpire – Query Service can be operated for each physical index redundantly with the use of load balancing hardware.
Extensibility
Mindbreeze InSpire comprises the following SDK interfaces:
- Extensibility of the system via file filters on Microsoft Windows platforms - via the Mindbreeze InSpire - Filter Interface.
- Connection of additional external data sources via the Mindbreeze InSpire Connector Interface. Mindbreeze provides a Software Development Kit (SDK) for implementation of these interfaces by third-party manufacturers, which is available at http://www.mindbreeze.com/developer.
Mindbreeze InSpire SDK - Support Matrix
The Mindbreeze InSpire SDK was updated. Please make sure you use the updated SDK for future development.
Mindbreeze InSpire 24.4 Version supports all SDK versions since: Mindbreeze InSpire SDK 2013 Summer Release
The Mindbreeze InSpire Java SDK is compatible with Java 8.
Administration
Mindbreeze InSpire provides a central configuration tool for creation, regular maintenance and administration of index catalogues. In addition, this central tool distributes the system components to the servers of the entire system. Central administration comprises all components of Mindbreeze InSpire (Mindbreeze InSpire – Crawler Service, - Filter Service, - Index Service, - Query Service, - Client Service) from a single point.
File Manager
For viewing and editing files on the local appliance a web-based File Manager interface is provided in the Management Service.
Editing and viewing is only supported for text files encoded in UTF-8. Files larger than 10MB can be opened read-only. For details on the supported formats for syntax highlighting please refer to the documentation of the used component CodeMirror version 5.51.0.
Binary files cannot be edited or viewed but downloaded instead.
Indexing
Server-side contents are indexed by Mindbreeze InSpire – Crawler Service component at regular intervals. The intervals can be defined for each data source (in seconds).
Software Update
Re-indexing is in general not necessary for a software update from version 2016 Spring Release to the current Mindbreeze InSpire product version.
Indexes created or changed with a current version cannot be opened by older versions.
Supported Data Sources
Mindbreeze InSpire 24.4 supports the data sources listed below for indexing, navigation and interaction during search. Additional data sources can be integrated via the Mindbreeze InSpire Connector Interface and Mindbreeze InSpire Software Development Kit (SDK) made available.
File Systems:
- Microsoft Windows net shares with user accounts in Microsoft Active Directory are supported. Groups are resolved against Active Directory.
- Linux/Samba shares are supported, but local groups must be resolvable to LDAP groups/users (Microsoft AD, Univention CS, Samba with OpenLDAP).
- To open documents from the search results a supported version of Microsoft Office and a supported Browser need to be installed. These are Microsoft Office 2019 and the Browsers: Microsoft Internet Explorer, Microsoft Edge (from Version 79), Google Chrome, Mozilla Firefox. Only documents that can be opened in Microsoft Office are supported.
Mail Server:
- Microsoft Exchange Server 2013 via the Microsoft Exchange Connector Plugin (prerequisite: Kerberos authentication and integrated login respectively SAML 2.0 infrastructure according to note)
- Microsoft Exchange Server 2016 via the Microsoft Exchange Connector Plugin (prerequisite: Kerberos authentication and integrated login respectively SAML 2.0 infrastructure according to note)
- Microsoft Exchange Server 2019 via the Microsoft Exchange Connector Plugin (prerequisite: Kerberos authentication and integrated login respectively SAML 2.0 infrastructure according to note)
- OpenText Documentum 6.6, 7.3, 16.7
Data Integration
Important note: The Talend Open Studio software product was discontinued on January 31, 2024. Therefore, the Data Integration Connector can no longer be further developed in its current form and will only receive maintenance updates.
For alternatives and questions regarding the maintenance of existing solutions, please contact Mindbreeze Support at support@mindbreeze.com.
- The Data Integration Connector is used to integrate complex ETL-Processes (Extract, Transform and Load) into Mindbreeze InSpire. Such ETL Processes/Jobs can be created using the Talend Open Studio which will also generate the required Java Code for integration into Mindbreeze InSpire.
- Access Plugin: Since the permissions of such ETL Processes/Jobs depend mainly on the used data sources a customized Access plugin is required to fulfill the desired access restrictions of the source application. Such a customized Access plugin can be created using the Mindbreeze SDK.
- Context Plugin: The Context plugin provides for every data object deliverd as search result specific context information (e.g. icon or context-menu with context actions). Such application specific context actions can be developed using the Mindbreeze SDK
LDAP / Microsoft Active Directory
Microsoft SharePoint 2013/2016/2019 and Microsoft SharePoint Online
- Mindbreeze InSpire – Microsoft SharePoint Crawler can be used to crawl „Document Libraries“ of Microsoft SharePoint datasources, these can be indexed.
- The following metadata information gets default extracted:
- listId: ID of a Microsoft SharePoint list
- sharepointURL: URL of a Microsoft SharePoint server
- listName: Name of a Microsoft SharePoint list
- folder: Folder within a document list
- site: Name of a Microsoft SharePoint site
Web
Mindbreeze InSpire – Web Connector allows to crawl intranet and extranet sources by following links extracted from HTML sources. The following policy can be restricted to different levels: all, site only, link-depth, sitemap. Access restrictions for the Web Connector are set to unrestricted public access, meaning, if you need to restrict access to certain web content you need to implement a plugin based on the Mindbreeze InSpire – Connector Framework (SDK) that fits your situation and need.
From version 20.5 (only on Mindbreeze InSpire G7) it is possible to enable the execution of JavaScript code on the web pages during crawling.
Atlassian Jira 8
Atlassian Confluence 7.19 (LTS), 8.5 (LTS), 8.9
HCL Notes/Dominio 8.5 and 9.0
Third party components:
Authentication mechanisms with Mindbreeze InSpire Web Client other than Kerberos (e.g. certificate-based authentication, form-based authentication, basic authentication,...) can be established by providing a SAML 2.0 identity provider infrastructure.
OAuth Version 2.0 authentication using bearer-tokens to the OAuth Server Keycloak in version 14 is supported.
Note: Using Mindbreeze InSpire Client Service together with SAML 2.0 Identity Provider (IdP) was tested exclusively with the SAML 2.0 compliant IDPs: Shibboleth 4.0.1, Microsoft Azure. Other SAML 2.0 IdPs may but are not guaranteed to work out of the box.
IMPORTANT NOTE: 100% complete and correct extraction of all content cannot be guaranteed.
Resolution of Authorization
To authorize search results, the searching user's roles and groups are resolved and matched against the resulting document's access control list
If present, data source-specific roles and groups are resolved by the specified Mindbreeze InSpire connector plugins. In these cases, the supported application versions for role and group resolution are the same as specified in the Supported Data Sources section.
Additionally, Mindbreeze InSpire supports the resolution of groups of the following Directory Servers by default:
- Microsoft Active Directory (Windows Server, version 2012 to 2022)
- Novell eDirectory (Open Enterprise Server, 2018.1)
- Azure Active Directory (via Microsoft Graph)
Supported File Types
Filters delivered by Mindbreeze
Microsoft Office:
- Versions
- Microsoft Word, Microsoft Power Point, Version 2003 to 2019
- Microsoft Office: Microsoft Excel, Version ‘97 to 2019
- Microsoft Outlook 2003 - 2019
- Formats: PST, MSG, DOC, PPT, XLS, DOCX, PPTX, XLSX
Mail: MBOX, EML
Calendar: ICS
Contact: VCF
Open Document Format: ODT, ODS, ODP
Open Office:
- Versions
- OpenOffice.org Version 1.1 to 4.0
- OpenDocument Version 1.0
- Formats: SXC, SXD, SXI, SXW
Text files: TXT
Images: BMP, GIF, JPEG, JPG, PNG, TIF, TIFF, PNM, PGM, PPM, PBM, SVG
Web: HTML: CFM, HTM, HTML / XHTML: XHT, XHTM
Audio: MP3, AU, AIF, WAV, MID
Ebook: EPUB
ASCII- and ANSI-based text files (UTF-8)
Archive files: ZIP, JAR
Additional supported formats: PDF (Adobe PDF Format), RTF, URL, XML, COOML, RDF, FLV (Flash-Video), CLASS (Java Class Files)
The Mindbreeze InSpire - Filter Service supports Abbyy FineReader Engine 12 for OCR processing of contents by means of using appropriate Mindbreeze plugins. The 3rd party components (from vendor Abbyy) have to be licensed separately.
NOTE: Mindbreeze InSpire – Filter Service analyzers and filters files according to their content. A 100% complete and correct filtering of all contents can’t be guaranteed.
Restrictions for using the “Microsoft Outlook PST file” filter:
- During a delta index run, documents are not removed from the index, even if they were deleted from the indexed PST file.
- During a delta index run, documents (PST contents) are not removed from the index, even if the indexed PST file itself was deleted.
It is strongly recommended to create a separate index for Microsoft Outlook PST files.
Languages and Character Codes of the Documents:
Mindbreeze InSpire supports the Unicode standard (UTF-8 and UTF-16) – in this way, all language and character set systems defined by this standard are supported.
Semantic Extraction and Semantic Search
Important: Semantic extraction and semantic search via trained models cannot be guaranteed to be 100% complete and correct. If model customization is required, this is only supported within a dedicated project where appropriately labeled training and test data is made available and provided by the customer.
Compound Splitting
Supported languages:
- German
- English
Restriction:
Compound splitting, if enabled, occurs during indexing. Re-indexing is required for reprocessing. Currently no adaptation of models is supported. For further restrictions please see above.
Extraction of Named Entities from Text
Supported languages:
- German
- English
Supported entities:
- Person
- Organization
- Location
- Misc.
Restriction:
Extraction, if enabled, occurs during indexing. Re-indexing is required for reprocessing. Currently no adaptation of models is supported. For further restrictions please see above.
Semantic Sentence Similarity Search
Important Note: The Semantic Similarity Search requires considerably more computing power for processing the data. To guarantee the full number of documents at optimum speed, an additional Mindbreeze InSpire AI instance or appliance may be necessary depending on the use case and dataset. In this case, please contact our sales team (sales@mindbreeze.com).
In order to enable this functionality, two items can be configured in the Index Service:
- Model for trained weights of sentence similarity
- Tokenizer configuration of the model to transform words into tokens
This functionality decomposes documents into sentences. These sentences are transformed into tokens via the vocabulary and the model returns a vector of weights for a sentence. When searching, the query, similar to sentences, is represented as a vector and similar sentences are computed from it, which are then processed further.
The quality of the similarity thus depends on the weighting of the trained model. The threshold of similarity can be specified in the search. Therefore, it is not part of the guarantee that the similarity search will provide optimal hits.
Supported model format and tokenizer configuration
In principle, models of the Sentence Transformer family can be loaded in ONNX format, if they have the appropriate format (dense tensors, tokens in Int64, output weights in float representation). The tokenizer configuration must be a PreTrainedTokenizer JSON format represented tokenizer in HuggingFace. The tokenizer model types "WordPiece" and "Unigram" have been used for testing.
Delivered model
The delivered model is based on the Sentence Transformer model with the ID "multi-qa-mpnet-base-dot-v1".
Object Recognition in Images
The model is trained based on the ImageNet Large Scale Visual Recognition Challenge (ILSVRC) 2012-2017 image classification dataset. The dataset includes 1000 object classes. The dataset includes more than 1 million training images associated with the classes. The object classes are grouped into 68 categories. The categories are translated so that multilingual searches can be performed.
Translated languages:
- English
- German
- French
Supported image formats:
- BMP
- GIF
- JPG
- PNG
- TIFF
Restriction:
Extraction, if enabled, occurs during indexing. Re-indexing is required for reprocessing. Currently adaptation of models is supported. For further restrictions see above.
Search
This chapter provides a brief overview of query language and handling, as well as the presentation of search results.
Overview
The queries Mindbreeze InSpire Web Client sets off against server-side contents are taken over by Mindbreeze InSpire - Client Service of Mindbreeze InSpire architecture.
Users can search in one or more index catalogues at the same time using Mindbreeze InSpire Web Client. The catalogues can be located on one or more servers. The search results originating from specific indexes can be displayed or hidden as required by the user.
Search Based on Words and on Phrases
Mindbreeze InSpire enables an exact search for words (word based search) and for groups of words (phrase search). Such search will only display those results which contain the entire search term (single word or phrase).
Words longer than the maximum length of 50 characters are not distinguished for the search.
Query Language
Mindbreeze InSpire has an intuitive query language as known from Internet search engines.
By default, all search terms separated by space characters are forwarded to the search engine via a logic AND operator. A search for phrases can be performed by using quotation marks. The results can be limited by specifying the file type (file extension) and by specifying a category (e-mail, file, etc.) (see user manual).
In addition to the automatic AND operation, the Boolean operators "AND" and "OR" and brackets can be used. This enables performing a more detailed search.
Proximity of words can be used by "NEAR" to display preferably those results where both search terms are closer together.
The search also supports wildcards at the ending of words. The search functionality automatically provides a wildcard search in a special situation. During a search in the "title" metadata, wildcards are implicitly supported at the beginning and at the end of the search term; e.g.; a search for "report" will return results for *report* in the "title" metadata.
Partial words are only considered for the search from a length of 3 to a maximum of 50 characters.
Search Results
The search results are displayed in the main window according to categories. Depending on the search result, the following categories may be displayed (if there are results in the respective category):
- Files: The search term(s) is/are contained in the full text of the document or in a selection of the additionally stored metadata.
- E-mails: The search term is contained in the full text or in common boxes (sender, subject, etc.).
- Contacts: The search term was found in the data boxes of a Microsoft Exchange/Outlook contact.
- Calendar: The search term was found in the Microsoft Exchange/Outlook calendar entries.
- Tasks: The search term was found in the Microsoft Exchange/Outlook tasks.
- Notes: The search term was found in the Microsoft Outlook/Exchange notes.
- Application-specific category names defined by integrators: (e.g. Fabasoft Folio): list hits of the respective category with the possibility of assigning subcategories.
- Images including preview: The search term is contained in the file name or in the directory of an image.
The number of hits selected by the user are displayed for each category. Besides the navigation buttons ("Next", "Back") the hits of each category are dynamically classified to find the result faster. The type and manner of classification depends on the sorting of the result. If the result is sorted by date, classification will be done in time segments. Depending on the dimension of time covered by all results, results of this category will be divided into years, quarters and months (so-called "drill down" over time).
Sorting and Grouping of Search Results
This section describes how to preview, highlight search terms and how to range and navigate in search results.
Preview and Highlighting of Search Terms
The main window displays the search results in two levels of detail. The overview only displays essential elements (e.g. name, place or date) to get a relatively quick overview of the results; such display varies according to the metadata which is available for the hits. In the more detailed view, a text preview of the content is provided, trying to display relevant passages of the summary text saved in the index. Each search term is highlighted in a different colour.
Ranking
During the search the results are sorted within a category according to semantic relevance or chronologically, displaying the more important or more recent elements first. In the case of a chronological sorting the date of the last modification is used.
Alternatively, a ranking algorithm may be chosen which considers several criteria, including the number of times a search term is contained in a document and in what position (content-based ranking) for calculating a ranking based on the quality of a search result. When searching several phrases, the proximity of the phrases is considered, like when searching with "NEAR".
Navigation
Mindbreeze InSpire allows for a simple and very quick navigation through the search results by means of the contextual navigation elements. In addition to the buttons for browsing (forward and backward), the divisions calculated online and dynamically are available. This enables a behaviour for fast navigation called "drill-down" in database technology. Even without knowing much about a searched object (few search terms), the result can be found simply and quickly.
Contextual Actions
In addition to opening a result (starting the associated application), Mindbreeze InSpire provides many possibilities for processing the searched object. Depending on the type, the context menu offers options for opening an object with other programs, opening the containing folder, copying the object to the Microsoft Windows clip board or displaying it in the Microsoft Windows Explorer. For each data source (source system) this menu is adapted to the conditions of the data source via the context interface and/or extended.
Search Tabs
Mindbreeze InSpire offers so called „Search Tabs“. “Search Tabs” allow to constraint search requests for certain views. “Search Tabs“ are defined in user profile files and can be
- one setting for all users and/or
- dedicated settings on a per user basis.

Security
Mindbreeze InSpire displays only those search results for which the current user has access rights (at least read-only access)..
For access checking Mindbreeze InSpire supports the following options according to the data source.
- Online access check for the data source is performed via the correlative Mindbreeze InSpire interface. This secures within all systems to factor all changes in access rights and prevent security risks. If the access check fails the actual displayed content (e.g. a document) is removed from the result list and is not displayed.
- Within the indexing process Authorization information (ACLs) can be added to the index. This grants a constant search rate without any external dependency. The user has to account a latency for the authorization information in the index.
InSpire AI Chat
With the Mindbreeze InSpire AI Chat the possibility is offered to access facts according to the access rights in Mindbreeze InSpire based on a Generative AI and carried out via a Large Language Model (LLM) and Retrieval Augmented Generation (RAG). In addition to an index and client service, an Insight Services for RAG can also be set up.
InSpire LLMs
For the generation itself an Large Language Model (LLM) is required. Mindbreeze provides an LLM if required (at the moment the delivered model is based on FastChat-T5 - lmsys/fastchat-t5-3b-v1.0). For On-Premises or the use of a LLM, additional hardware / GPU is required. Please contact Mindbreeze Sales (sales@mindbreeze.com) if you wish to run an LLM. As a minimum requirement for a GPU model, an Nvidia A40 with 48 GB RAM is recommended.
Mindbreeze SaaS customers have the option to use a remote LLM. Please contact Mindbreeze Sales (sales@mindbreeze.com).
Currently, external LLMs can be connected using the Huggingface TGI API via HTTPs. For authentication, OAuth2 tokens are currently supported.
For the usage of Retrieval Augmented Generation (RAG), the current version requires an indice in the Sentence Transformer format.
OpenAI, Microsoft Azure OpenAI and Aleph Alpha LLM API
In order to use LLMs from AI providers such as OpenAI, Microsoft Azure OpenAI and Aleph Alpha as models for pipelines in Insight Services for RAG, it is mandatory to accept the data privacy disclaimer for using these APIs. The disclaimer is presented as a dialog when adding an LLM in the Insight Services for RAG administration. Below you see an example based on OpenAI:
|
|
Initial dialog, without confirmation, creation not allowed. | Only after confirming, creation is possible. |
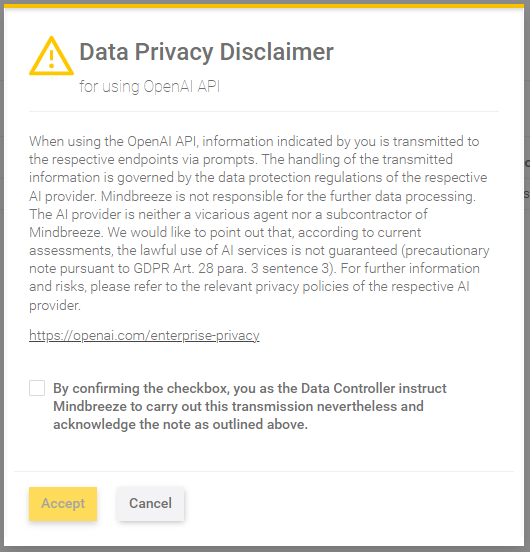
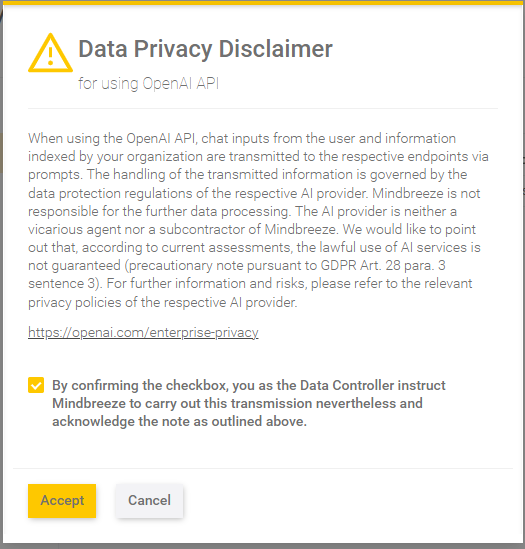
- The text of the data privacy disclaimer is as follows:
- When using the Aleph Alpha, Azure OpenAI, or OpenAI API chat inputs from the user and information indexed by your organization are transmitted to the respective endpoints via prompts. The handling of the transmitted information is governed by the data protection regulations of the respective AI provider. Mindbreeze is not responsible for the further data processing. The AI provider is neither a vicarious agent nor a subcontractor of Mindbreeze. We would like to point out that, according to current assessments, the lawful use of AI services is not guaranteed (precautionary note pursuant to GDPR Art. 28 para. 3 sentence 3). For further information and risks, please refer to the relevant privacy policies of the respective AI provider.
- For more Information visit:
- Aleph Alpha: https://aleph-alpha.com/data-privacy/
- Azure OpenAPI: https://learn.microsoft.com/en-us/legal/cognitive-services/openai/data-privacy
- OpenAPI: https://openai.com/enterprise-privacy
- By confirming the checkbox, you as the Data Controller instruct Mindbreeze to carry out this transmission nevertheless and acknowledge the note as outlined above.
Supported index formats
To use the Retrieval Augmented Generation (RAG), an index in Sentence Transformer format is required in the current version.
Prompt and answer quality
When using generative AI and semantic search via trained models, a 100% complete and correct extraction and search cannot be ensured. The response quality of the InSpire AI Chat depends on many factors, which can also be adjusted in the Insight Services for Retrieval Augmented Generation (RAG). In particular, it is important to define a data set to measure the quality of the responses. Pre-defined prompts are provided, which can also be customised.
Extensions
In addition to browser-based solutions, Mindbreeze offers other options for displaying search results.
Microsoft Outlook Add-In
The Outlook Add-In enables Mindbreeze search results to be displayed in addition to the standard Outlook results.
iOS App
It is possible to display the search results in the familiar design on the smartphone.
In order to use the iOS app for Apple devices, the URL of the desired Mindbreeze InSpire - Web Client needs to be stored.
Browser Extension
The Mindbreeze browser extension for Chrome and Edge offers another option for displaying search results.
Services and Connectors
Services
Mindbreeze InSpire comprises the following services:
- Filter Service
- Index Service
- Query Service
- Client Service
- Crawler Service
- Insight Services for Retrieval Augmented Generation (RAG)
Important Notes for Operation
- During initial or delta indexing, user queries against the Mindbreeze InSpire - Query Service should be avoided if possible.
- Mindbreeze InSpire can process the following maximum number of queries per second, depending on the appliance model:
- For Mindbreeze InSpire 500K and 1M, up to 3 queries per second are supported.
- For Mindbreeze InSpire >=2M, up to 5 queries per second are supported.
Connectors
Mindbreeze InSpire - File System Crawler Service
- Mindbreeze InSpire (Microsoft Windows-based Appliance)
- Microsoft Windows file shares and DFS
- File Systems: FAT32 und NTFS
Mindbreeze InSpire – Microsoft Exchange Crawler Service
- Microsoft Exchange Server 2013 (64-bit x64)
- Microsoft Exchange Server 2016 (64-bit x64)
- Microsoft Exchange Server 2019 (64-bit x64)
Mindbreeze InSpire – Web Connector
Mindbreeze InSpire – Microsoft SharePoint Connector
- Microsoft SharePoint 2013 (64-bit, x64)
- Microsoft SharePoint 2016 (64-bit, x64)
- Microsoft SharePoint 2019 (64-bit, x64)
- Microsoft SharePoint Online
- Mindbreeze InSpire – Data Integration Connector
Mindbreeze InSpire – LDAP/Active Directory Connector
Mindbreeze InSpire – OpenText Documentum Connector
- OpenText Documentum 6.6
- OpenText Documentum 7.3
- OpenText Documentum 16.7
Mindbreeze InSpire - ServiceNow Connector
If 'Extended User Criteria Conditions' or 'Advanced User Criteria Resolution' are used, we do not guarantee that the permissions in Mindbreeze actually match the ServiceNow permissions. In this case on the deployment side appropriate access tests must be performed.
Supported Client Environments
Web Browser Client
Supported Browsers and Operating Systems:
- Edge 126 (Win 10, Win 11)
- Firefox 127 (Win 10, Win 11, Apple macOS 14.5 Sonoma)
- Chrome 126 (Win 10, Win 11, Apple macOS 14.5 Sonoma)
- Safari 17.5 (Apple macOS 14.5 Sonoma)
- iPhone iOS 17.5
- iPad iOS 17.5
More recent browsers than those specified are supported on an ongoing basis after successful testing.
Accessibility
The following components are certified according to the W3C standard WCAG 2.1 - AA Silver:
- Search box
- Tabs
- Results list
- Settings
- Saved searches
- Filters
- Date picker
- Load more results
- Help
Administration – Management Center (MMC)
Supported Browser and Operating Systems:
- Edge 126 (Win 10, Win 11)
- Firefox 127 (Win 10, Win 11, Apple macOS 14.5 Sonoma)
- Chrome 126 (Win 10, Win 11, Apple macOS 14.5 Sonoma)
- Safari 17.5 (Apple macOS 14.5 Sonoma)
Microsoft Outlook Add-In
Supported Microsoft Outlook versions and Operating Systems:
- Microsoft Outlook 2016 (Win 10, Win 11)
- Microsoft Outlook 2019 (Win 10, Win 11)
- Microsoft Outlook 2021 LTSC (Win 10, Win 11)
- Microsoft Outlook 365 Windows App Build 2108 (Win 10, Win 11)
The MSI installer supports both 32bit and 64bit versions of Microsoft Outlook.
The click-once installer supports both 32bit and 64bit versions of Microsoft Outlook.
Browser Extension
Supported Browser and Operating Systems:
- Edge 126 (Win 10, Win 11)
- Chrome 126 (Win 10, Win 11, Apple macOS 14.5 Sonoma)
iOS App
- iPhone iOS 17.5
Supported Languages
User interface of the software product:
- English: Mindbreeze InSpire Server Configuration
- Supported Languages for Mindbreeze InSpire - Web Client User Interface (without help):
- English
- German
- Italian
- French
- Bulgarian
- Croation
- Portuguese
- Romanian
- Serbian
- Slovak
- Slovenian
- Spanish
- Czech
- Hungarian
- Russian
- Dutch
- Turkish
- Norwegian
- Japanese
- Chinese (Traditional)
- Indonesian
Documentation:
- English/German: Installation and Administration Manual
Hardware Product Information
Hardware On-Premise
The specification and equipment of the hardware depends on the Mindbreeze InSpire version. There are hardware configurations for the 500K, 1M, 2M, 5M and 10M variants.
The 2M, 5M and 10M hardware configurations support Self-Encrypting Drives (SED) for encrypting the contents of the hard disk. For 500K and 1M there is no encryption of the data stored on the hard disks.
The hardware is delivered with the following service contract:
- 3 years of support; next working day on-site.
Minimum Hardware Requirements for Virtual Machine Images
Mindbreeze InSpire can also be purchased as an image for virtual machines. This is possible either via Amazon Web Services or via the Microsoft Azure Marketplace. Here you can also choose between the 1M, 2M, 5M and 10M variants. The minimum hardware requirements for each variant are as follows:
Attention: The following specifications are recommendations and do not contain a warranty.
Without GPU | |||||
CPU | 1M | 2M | 5M | 10M | |
Amazon Web Services | Comparable with Intel Xeon Gold x86_64 | 12 Cores (without Hyper Threading) 128 GB RAM 1,7 TB SSD Storage | 24 Cores (without Hyper Threading) 256 GB RAM 4 TB SSD Storage | 24 Cores (without Hyper Threading) 384 GB RAM 8 TB SSD Storage | 32 Cores (without Hyper Threading) 512 GB RAM 16 TB SSD Storage |
Google Cloud | |||||
Microsoft Azure | Comparable with Intel Xeon Gold Generation 2 Virtual Machine x86_64 | ||||
Minimum Hardware Requirements for the Use of GPU Memory
GPU memory is not necessarily required to run a virtual machine image. If large language models are to be used, GPU memory is required. The following minimum hardware requirements apply.
Attention: The following specifications are recommendations and do not contain a warranty.
CPU | GPU Memory | 1M | 2M | 5M | 10M | |
Amazon Web Services | comparable with Intel Xeon Gold x86_64 | Comparable with: NVidia A40 GPU 48 GB of memory with a GPU Memory | 12 Cores (without Hyper Threading) 128 GB RAM 1,7 TB SSD Storage | 24 Cores (without Hyper Threading) 256 GB RAM 4 TB SSD Storage | 24 Cores (without Hyper Threading) 384 GB RAM 8 TB SSD Storage | 32 Cores (without Hyper Threading) 512 GB RAM 16 TB SSD Storage |
Microsoft Azure | comparable with Intel Xeon Gold Generation 2 Virtual Machine x86_64 |
Next Business Day Support
Mindbreeze InSpire includes Next Business Day basic support, which only applies to product problems around functionality described in this product information.
Product issues must be reproducible in an isolated environment.
Therefore a ticket must contain:
- Description of product issue
- Description of infrastructure constraints in which the problem is reproducible
- Significant logs (e.g. app.telemetry information) that describe the product issue and help our support team to understand the cause of the problem.
- Step by step description, how the problem can be reproduced
- If the problem only occurs with concrete files (content-driven), we will need an anonymized set of such files.
- Exact version and build number in use
- Support tickets need to be opened via https://tickets.mindbreeze.com.
- The first response time is next business day after ticket creation (Austrian holidays excluded):
- Monday – Thursday from 8:15am to 5:15pm (CEST)
- Friday from 8:15am to 3:15pm (CEST)
- Time zone: Central European Standard Time
- Important: Technical consulting for project-specific questions or requirements is not included in the basic support and needs to be ordered separately.
Condition of Use
- All statements contained in this software product information concerning designated use and operating conditions of the product exclusively constitute principal information. To ensure and guarantee that the product is used in accordance with the designated use and operating conditions in everyday use, expert training by qualified expert staff is mandatory.
- Third-party software products that are required or supported by Mindbreeze products, proper licensing and installation of the same, necessary tests prior to product release, as well as appropriate manufacturer support are not included in the scope of delivery and services and, therefore, they are not subject to warranty of Mindbreeze regarding functionality, mode of operation or features. Mindbreeze shall not be liable for errors or malfunctions, which are caused by third-party software products and/or software products that are not included in the scope of delivery and services. Thus, Mindbreeze may only be liable - apart from the other requirements - if it is shown that the third-party products work without errors. In connection with the interaction of hardware and software environments reference is made to the information given in the licence agreement.
- Mindbreeze does not make any explicit or implicit statements concerning performance or response times of Mindbreeze software products because performance and response times significantly depend on the infrastructure used. For layout, configuration and sizing of the relevant infrastructure please see the information, recommendations and specifications of the relevant manufacturers.
- In particular no functionalities for backup, restore or disaster recovery are included in the scope of delivery of Mindbreeze products.
- This product is intended for customary commercial use. This does not include usage that demands special security requirements.
- The licensor reserves the right to modify the conditions of designated use and the operating conditions of the program, which means that the product manufacturer exclusively holds title to proprietary rights.
- The customer acknowledges that the customer is exclusively responsible for the protection of its business secrets, trade secrets and professional secrets as well as for safeguarding all protected legal positions and related legal consequences from publication of the customer's work results.
- To ensure the highest possible security when accessing Mindbreeze InSpire, it is the customer's duty to use secure browser versions for accessing the administration interface and search.
- Access information to connected systems must be generated, transmitted and updated by the customer according to his internal company specifications, e.g. password strength and password lifetime.
- The customer is responsible for securing communication between Mindbreeze InSpire and connected systems, e.g. no use of outdated or insecure protocols.