
Sure, you can handle it. But should you?
Let our experts manage the tech maintenance while you focus on your business.
Let our experts manage the tech maintenance while you focus on your business.
Configuration
CJK Text Tokenizer Plugin
Introduction
This document deals with the CJK Tokenizer Plugin. It allows Mindbreeze InSpire to crawl and understand Chinese or Japanese content. For example, sentences can be divided into individual parts (tokens) that belong together in order to provide an optimized search experience. The Tokenizer Plugin supports multiple Tokenizers. An external tokenizer service is also supported (not included).
Prerequisites
If an external Tokenizer service is to be used, this service must already be configured.
Setup
To activate the CJK Tokenizer the following steps have to be performed:
- Setup of the Postfilter
- Setup of the QueryTransformationService
- Reindex the contents that were already indexed before the Tokenizer installation.
Setup of the Launched Service
The CJK Tokenizer plugin is configured as a single Launched Service. This is the only way to achieve high performance. After configuration, this Launched Service is referenced as a Postfilter and QueryTransformationService.
To set up the CJK Tokenizer Plugin Launched Service, switch to the "Index" tab in the configuration and add a new service in the "Services" section.

Base Configuration
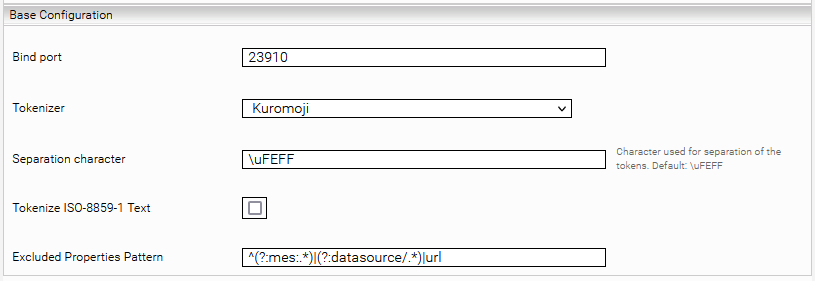
Bind port | A free TCP port on the appliance on which it runs Launched Service. | ||||||
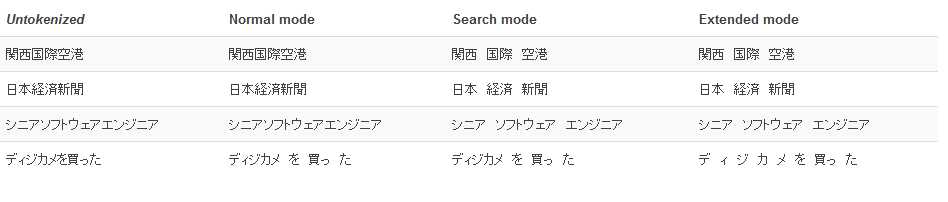
Tokenizer | Selects the Tokenizer mode. The following modes are selectable:
| ||||||
Separation character | Character used to separate the tokens. The default value is \uFEFF . This value can also be changed for testing purposes. For the search to work correctly, however, the default value must be retained. | ||||||
Tokenize ISO-8859-1 Text | If this option is activated, ISO-8859-1 encoded text is also processed by the tokenizer. | ||||||
Enable Text Normalization | Text is normalized so that, for example, documents with full-width characters can be found even though normal western characters were used in the search. The normalization form used is NFKC. | ||||||
Excluded Properties Pattern | The properties configured here using regular expression are not processed by the tokenizer. |
Jieba Configuration
Note: only relevant if the value Jieba is selected at Tokenizer.

Segmentation Dictionary | The dictionary used for tokenizing:
| ||||
Segmentation Mode | Depending on whether the service is used as a QueryExprTransformation service or as a post-filter, different settings can be used. However, the default value "Index" is sufficient for both service types.
|
HANLP Configuration (deprecated)
Note: only relevant if the value HANLP is selected at Tokenizer.

[Deprecated] EndPoint URL | URL of the /parse servlet of the Tokenizer service |
Kuromoji Configuration
Note: only relevant if the value Kuromoji is selected at Tokenizer.

Tokenizermode | Kuromoji Tokenizer Mode, also see Javadoc |
Setup of the Postfilter
The postfilter is used by the tokenizer to tokenize (decompose) the contents at crawling time before they are stored in the index.
- To do this, navigate to the Management Center.
- Select the tab Filter, activate the "Advanced Settings" and open the desired filter, which should tokenize the Chinese content:
- Then search for the Post Filter Transformation Services option and add the reference to the CJK Tokenizer PostFilter Plugin (TextPlugin. CJKTokenizer) (recognizable by the "@" in the name):

Setup of the Query Transformation Service
With the Tokenizer, the Transformation Service query ensures that the text entered by the end user in the search field is tokenized before the query. If this is not the case, the tokenization of the index does not match that of the search query. This would have the same effect as if you had not configured a Tokeinzer.
- To do this, navigate to the Management Center.
- Select the Indices tab
- Activate the "Advanced Settings" and open the index containing the Chinese content. Select the filter on which you have configured the post filter:
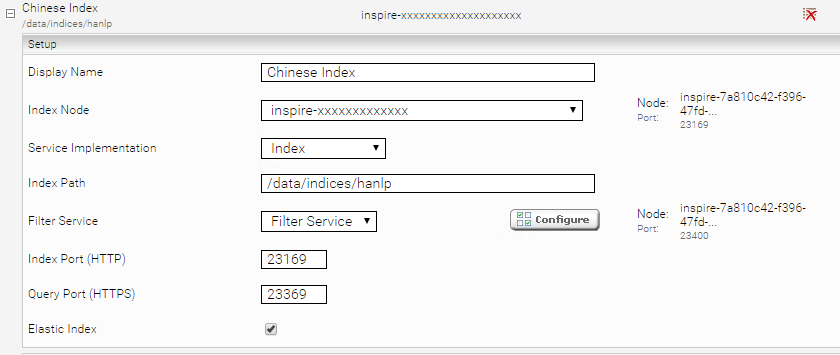
- Search for the setting Query Transformation Services and add the reference to the CJK Tokenizer QueryTransformation Plugin (TextPlugin.CJKTokenizer) (recognizable by the "@" in the name):

Re-indexing of contents
If documents already exist in your index, they must be re-indexed because the existing documents have not yet been tokenized.
Troubleshooting
The CJK Tokenizer Plugins runs a test servlet on the BindPort, which can be used for diagnostic purposes. For example, you can "tokenize" any text fragments in the web browser.
For example, the call results in:
https://myappliance:8443/index/{{BindPort}}/tokenize?text=清洁技术
the result:
<font color="#ffff00">-=清洁=- sync:ßÇÈâÈâ
Note: The default separation character is not visible. To make these separators visible, you can copy the result to an editor.