Sure, you can handle it. But should you?
Let our experts manage the tech maintenance while you focus on your business.
Let our experts manage the tech maintenance while you focus on your business.
IBM Connections Connector
Installation and Configuration
Installation
Before you install the IBM Connections Connector plug-in, you must ensure that the Mindbreeze server is installed and this connector is also included in the Mindbreeze license. If you are installing or upgrading the connector, use the Mindbreeze Management Center.
Configuring Mindbreeze
Basic settings
Click on the “Indices“ tab and then on the “Add new index“ icon to create a new index.
Enter the index path, e.g. /data/indices/ibm-connections. If necessary, change the display name of the index service and the associated filter.
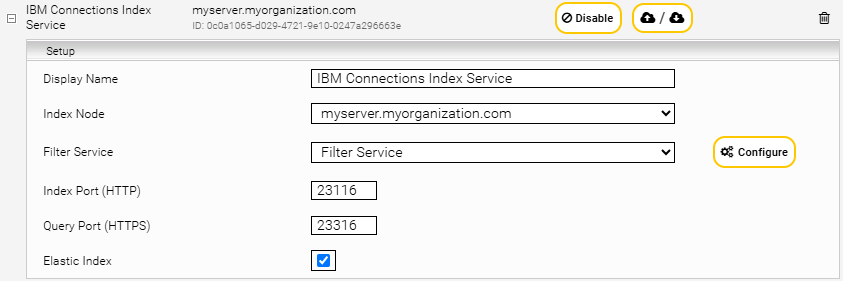
Add a new data source with the icon “Add new custom source” on the lower right-hand side.
If not already selected, select “IBM Connections” by the “Category” button.
Using the “Crawler Interval“ setting, configure the time interval between two indexing runs.
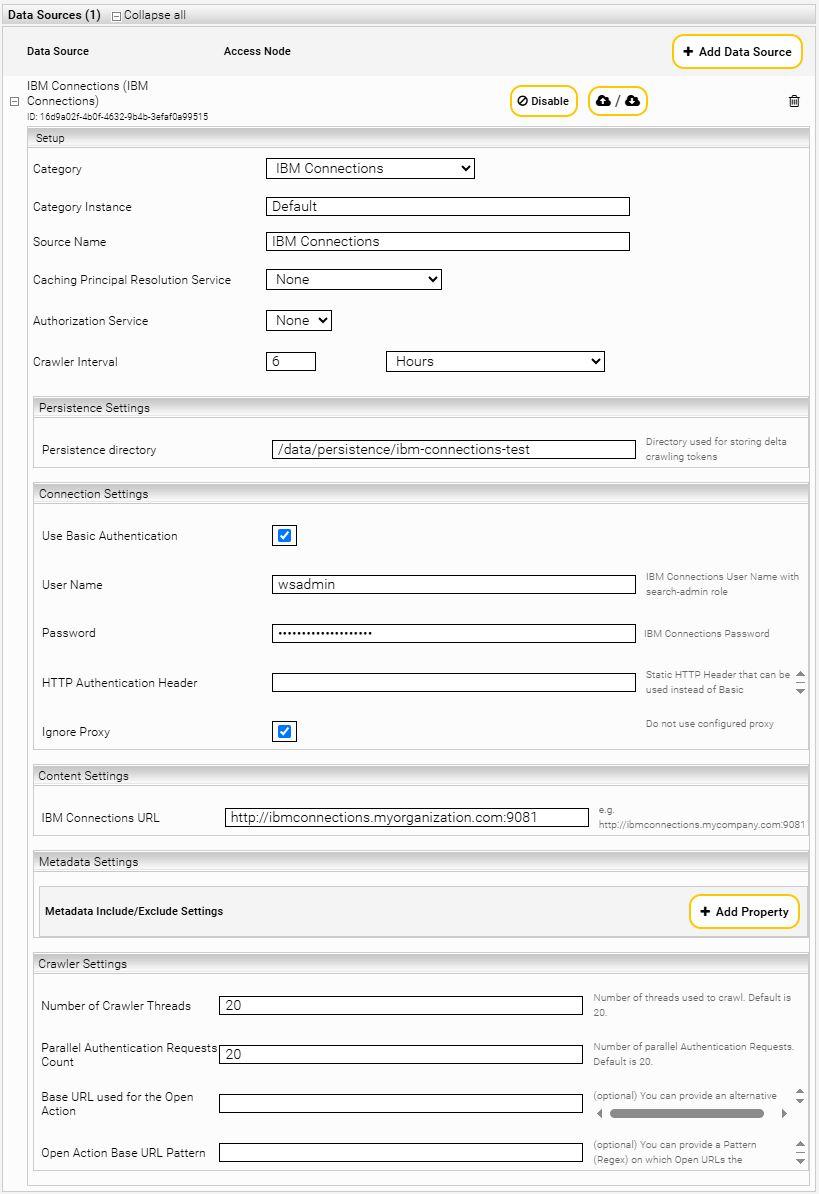
Set the "Persistence directory" field to a valid folder path.
Set the IBM Connections URL field to the appropriate IBM Connections host and port.
You can use two variants for the authentication to IBM Connections:
- HTTP Basic Authentication
- HTTP Authentication Header
However, no matter which one you use, make sure that there is a user with the “search-admin” role in IBM Connections, and that you use this user for the connector.
For the "HTTP Basic Authentication" variant, make sure to tick the box "Use Basic Authentication" in the "Connection Settings" section. Set the "User Name" and "Password" fields accordingly.
For the "HTTP Authentication Header" variant, remove the checkmark from the "Use Basic Authentication" checkbox and insert the appropriate header (with a colon) under "HTTP Authentication Header".
To reduce the load on the datasource when crawlin, reduce the “Number of Crawler Threads”.
To reduce the load on the datasource when searching, reduce the “Parallel Authentication Request Count”.
If the IBM Connections URL differs from from the URL which is accessed by the users it is possible to override the Open URL with “Base URL used for the Open Action”
If this override should only be applied for certain URLs, it is possible to configure a Regex pattern in “Open Action Base URL Pattern”.
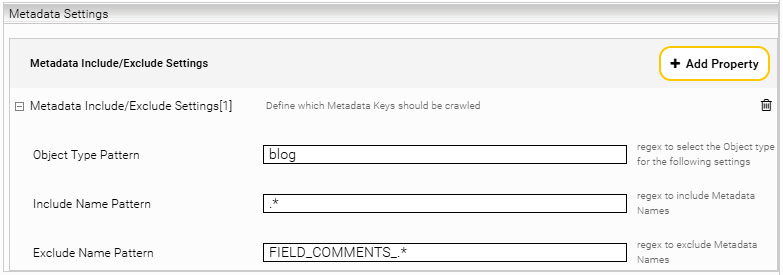
Include or exclude metadata from indexing
IBM Connections has a set of metadata that you can configure in IBM Connections. In Inspire, you can configure which of these metadata should be processed in general.
For example, comments are saved as metadata in the "blog" document type. If you do not want to index these comments, you can configure the "Metadata Include/Exclude" settings in the "Metadata Settings" section.
The following screenshot shows a rule that handles all metadata for the "blog" document type except for comments.