Sure, you can handle it. But should you?
Let our experts manage the tech maintenance while you focus on your business.
Let our experts manage the tech maintenance while you focus on your business.
Microsoft File Connector (Legacy)
Installation and Configuration
Installation
Before installing the Microsoft File Connector ensure that the Mindbreeze Server is already installed and this connector is also included in the Mindbreeze license.
Needed Rights for Crawling User
Configuration of Mindbreeze
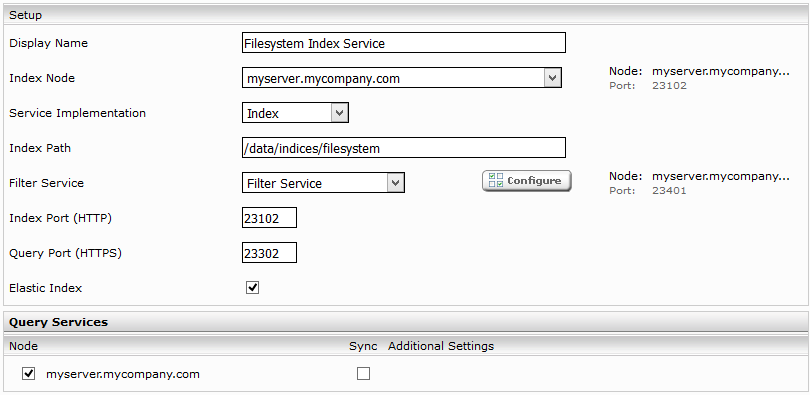
Click on the “Indices” tab and then on the “Add new index” symbol to create a new index.
Enter the index path, e.g. “/data/indices/filesystem”. Change the Display Name of the Index Service and the related Filter Service if necessary.
Add a new data source with the symbol “Add new custom source” at the bottom right.

Configuration of Data Source
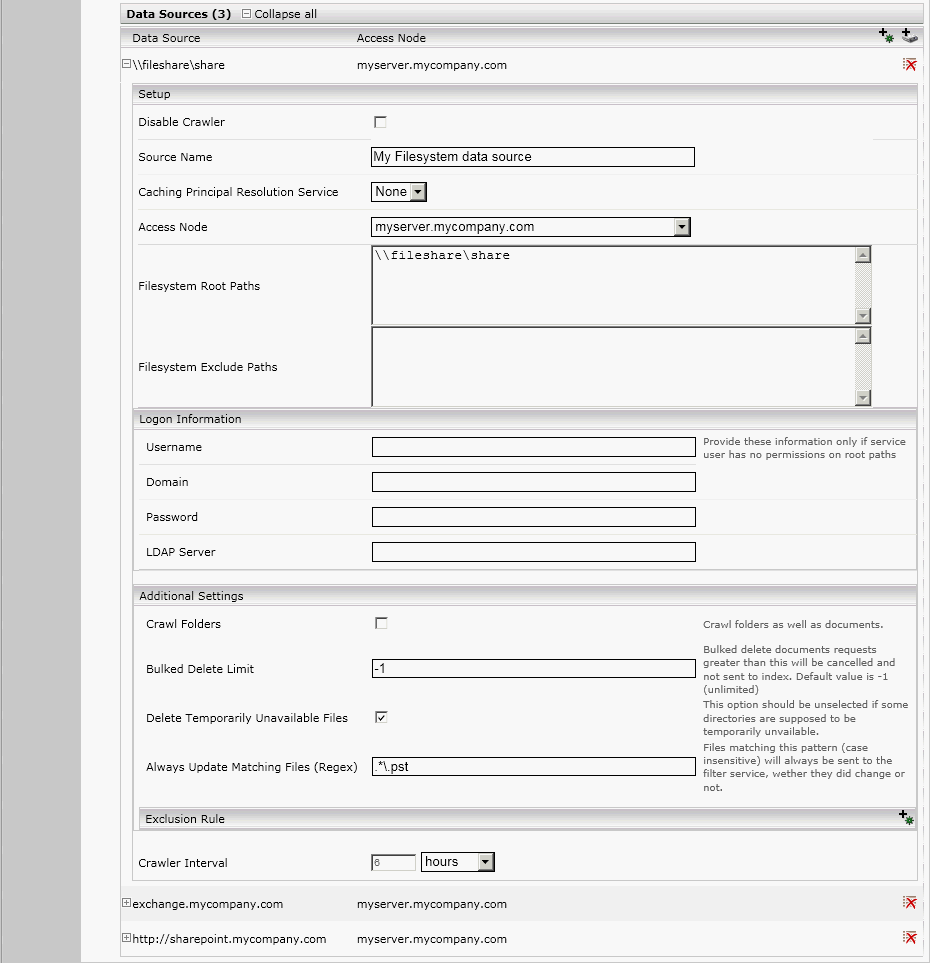
The file system data source allows you to make a folder and its subfolders searchable.
In order to create a file system data source, proceed as follows:
- Click the symbol
 to open the configuration form for file system data sources.
to open the configuration form for file system data sources. - In the field “Source name” enter an appropriate name for this data source.
- In the field “Access Node” you can choose the node which will access the files for this data source.
- The field “Filesystem Root Path” specifies a fileshare as a starting point searching for files to index. The contents of this folder and all its subfolders will be indexed. The specified fileshare must be accessible by all computers enabled to search in this index, otherwise they will be unable to open files system search hits.
- In the subsection „Path Exclusion Rules“, you can configure paths to be excluded from indexing, by adding an „Exclusion Rule“ using the plus symbol.
There are three modes of exclusion:- Setting „Format“ to „Absolute Path“, the field „Excluded Value“ can be used to specify an absolute path to be excluded from indexing.
- Setting „Format“ to „Path Component“, the field „Excluded Value“ can be used to specify a path component (name of a subdirectory or file), to be excluded from indexing.
- Setting „Format“ to „Regular Expression“, the field „Excluded Value“ can be used to specify a regular expression, which will be applied to the full path.
- In the field “Crawler Interval”, a time interval is specified within which the index updates its information about the content of this folder and its subfolders after a completed crawl.

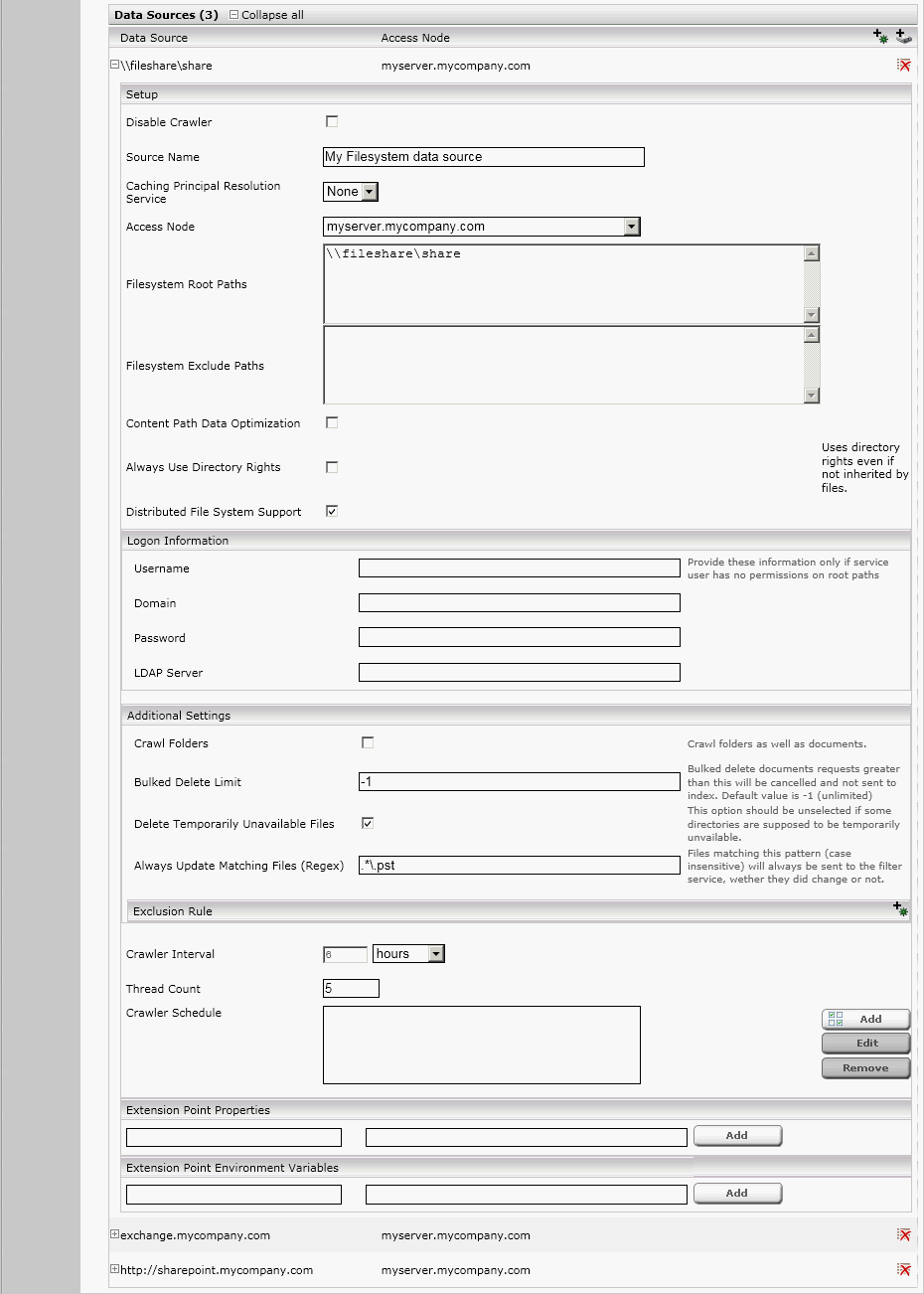
In order to perform additional fine-tuning of the data source settings, click the “Advanced settings” check box at the top.
The following configuration screen will be displayed, where you can specify additional settings:

- The field “Content Path Data Optimization” selects whether the file system crawler sends file content as references (i.e. UNC path) to the files or the actual file data to the filter. On enabled checkbox references are sent. This may increase crawler and filter performance, but the filter service the file system crawler uses must have access to all file references the crawler sends.
- In the field “Thread Count” you can set how many threads will be used for indexing the folder defined above. The thread count directly impacts folder and subfolder processing performance. However, a higher thread count also contributes to higher load on the hard disks.
- The “Crawler Schedule” section enables you to specify crawler operation time intervals. Please refer to the appropriate chapter of this manual for detailed information.
- The “Logon Information” is necessary to configure if the service user has no read permissions on file shares. Provide “LDAP Server” only if you want to override LDAP setting configured under “Network Setting” tab.
In order to store the settings defined, click the ”Save“ button in the top-right corner.
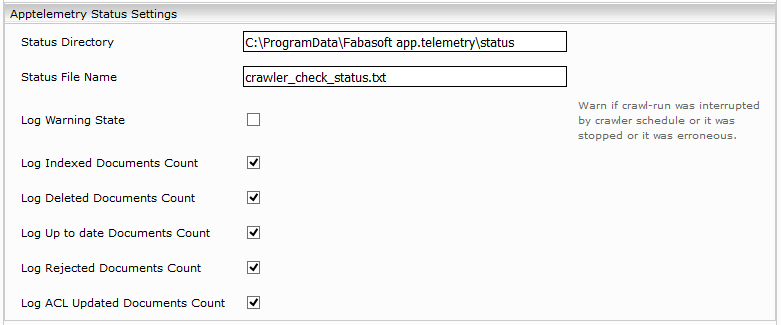
app.telemetry Status Settings
Configure the path to file where the information about finished crawler runs are to be written. This file will be periodically checked by app.telemetry. See (Service Check Configuration).
Service Check Configuration (app.telemetry)
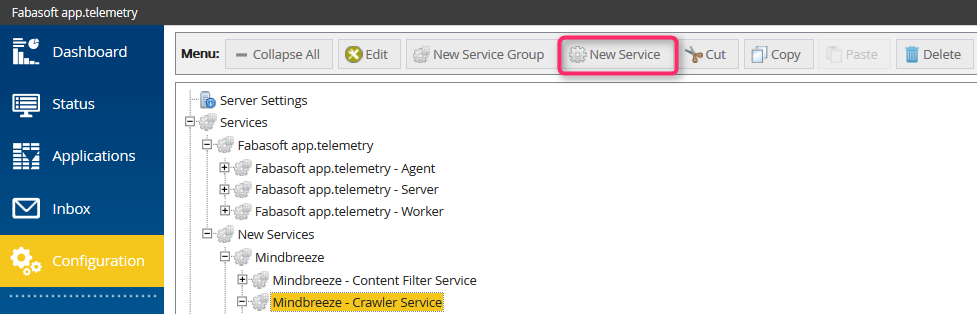
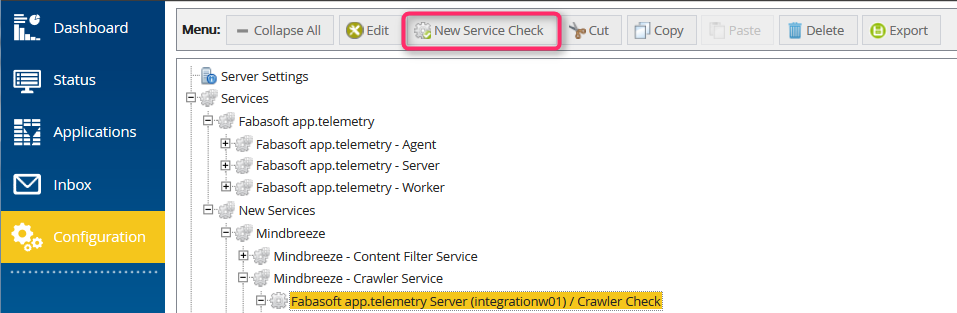
Through the following steps, a Service Check is added to the Mindbreeze Crawler Service but it can be a new or any other service as well.
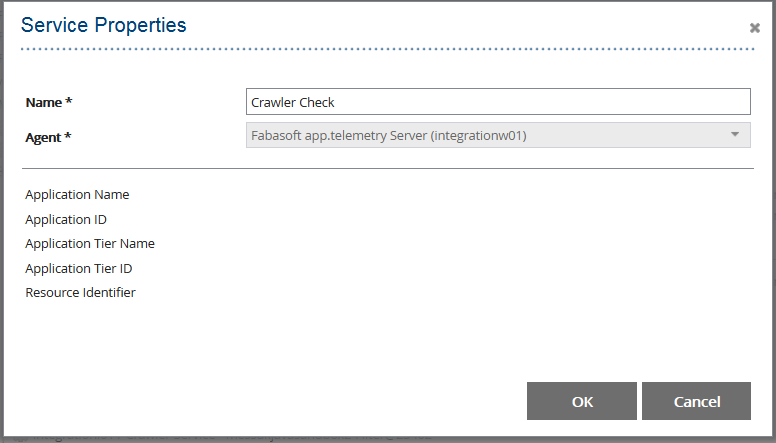
- Add new Service for Mindbreeze – Crawler Service
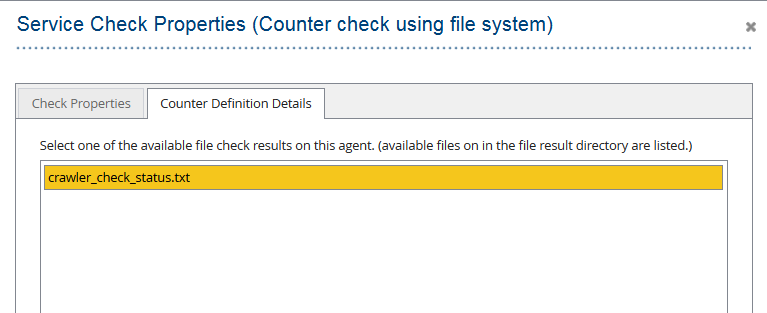
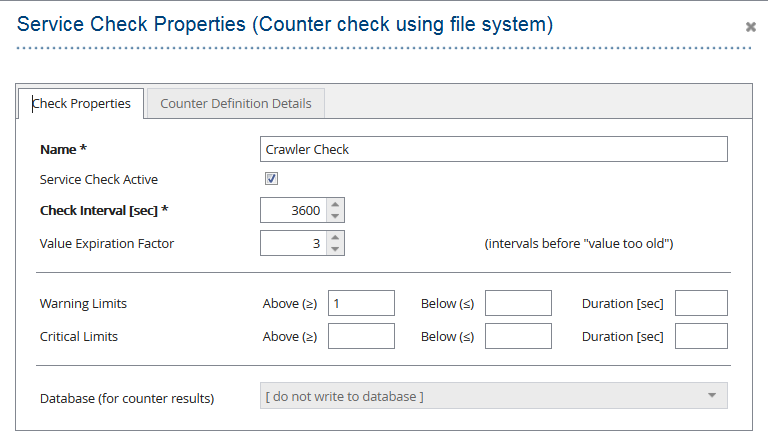
- Add new Service Check (Counter check using file system)
- Define Check Interval (for example 1 hour) and Warning Limit. A value greater than 0 in Warning Limit field indicates the number of crawlers failed to complete a crawl run. It is important that the check file is periodically updated within the check intervals in order to have a correct status.
- Provide the path to file configured in “Apptelemetry Status Settings” (for example each hour). See (Apptelemetry Status Settings):

Service Check Status
The “Value” column indicates the number crawlers that did not succeed to perform a complete crawl run.
The “Message” column contains the IDs of crawlers, which are monitored.
Successful crawler runs status example:
Unsuccessful crawler runs status example: