
Sure, you can handle it. But should you?
Let our experts manage the tech maintenance while you focus on your business.
Let our experts manage the tech maintenance while you focus on your business.
SemanticWeb Connector
Installation and Configuration
Installation
Before installing the SemanticWeb Connector, it must be ensured that the Mindbreeze Server is already installed and that this connector is also included in the Mindbreeze licence.
Configuring Mindbreeze
Click the “Indices” tab and then click the “Add new index” icon to create a new index (optional).
Enter the index path. If necessary, adjust the display name of the index service and the associated filter service.

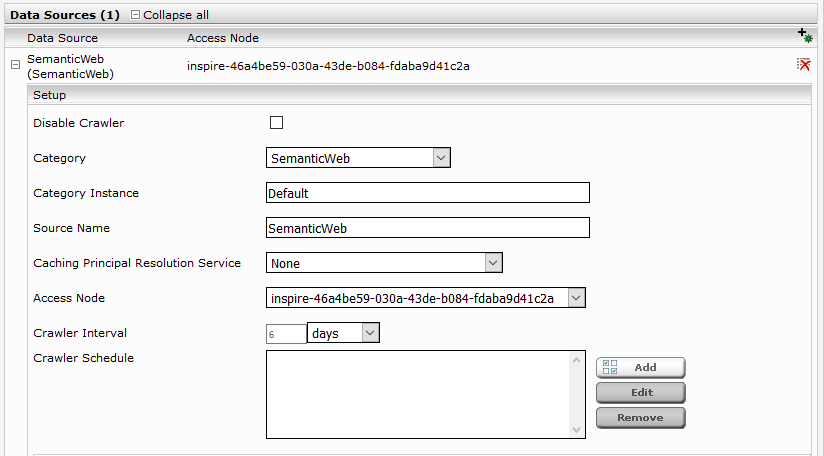
Add a new data source with the “Add new custom source” icon (located at the bottom right).

Section „Sources“
Ressource Settings
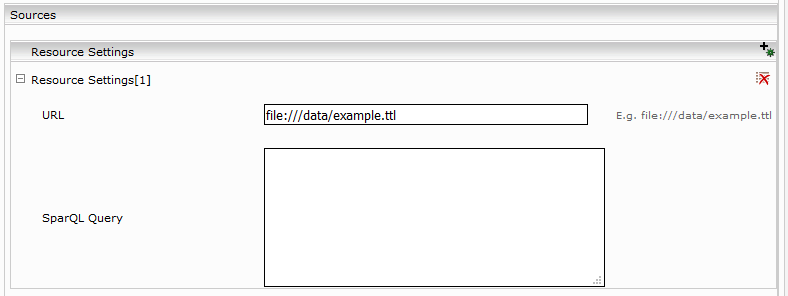
Setting | Description |
URL | defines the location of the data source (Turtle file) to be indexed, for example, file:///d:/data/example.ttl with Windows or file:///data/example.ttl with Linux. If the data source is on a Windows Share, then it should be mounted locally. |
SparQL Query | For example: PREFIX skos: <http://www.w3.org/2004/02/skos/core#> PREFIX umls: <http://bioportal.bioontology.org/ontologies/umls/> PREFIX rdfs: <http://www.w3.org/2000/01/rdf-schema#> PREFIX xsd: <http://www.w3.org/2001/XMLSchema#> SELECT ?key ?title ?code ?cui ?tui ?sty { ?key skos:prefLabel ?title . ?key skos:notation ?code . OPTIONAL {?key umls:cui ?cui } OPTIONAL {?key umls:tui ?tui } OPTIONAL {?key umls:hasSTY ?sty } } The results of the SparQL query (solutions) are indexed as single documents with metadata. It is important that the query has a variable named "key" which is then used as the document key; other variables are indexed as metadata. |
Metadata Mapping
Setting | Description |
Source Name | Is the variable name in the SparQL. |
Mapped Name | Is the metadata name in the index. “mes:key “, "modificationdate” and " title” can also be used as the mapped name, which are not indexed as metadata but as document key, change date, or title of the indexed document. |
Format | The following options are available:
|
Semantic Web ItemTransformation Service
This service allows you to resolve the class hierarchy of metadata in the form of URLs (resources described in the specified RDF data source) during indexing.
Configuration
After installing the plugin (SemanticWebItemTransformationService-<version>.zip) the service "ItemTransformationServicePlugin.SemanticWeb" service is available under "Services" and is configured there as follows:

Setting | Description |
Base Configuration | |
Bind port | Requests from the index are sent to this port. |
Model File (URL) | E.g. file:///data/example.ttl |
Class Hierarchy Resolution | |
Source Property Name | The name of the metadata that contains the resource URLs. |
Target Property Name | The name of the metadata that contains the class hierarchy. |
Class Title | The attributes of the class (in the RDF data source) used as the title (for example skos:prefLabel). |
Class Title Prefix Declaration | SparQL prefix declaration of the class attributes (e.g. the prefix declaration of skos). |
In addition, „Semantic Web Item Transformation Service@ItemTransformationServicePlugin.SemanticWeb“ must be added to the index in the section "Item Transformation Services".