
Sure, you can handle it. But should you?
Let our experts manage the tech maintenance while you focus on your business.
Let our experts manage the tech maintenance while you focus on your business.
Interface Description
Java API
Supported Java Versions
The Mindbreeze Java SDK supports Java JDK version 8 and 11 (Plugins are built in Java 8 compatibility mode).
Indexing
This section deals with sending objects to Mindbreeze. You'll become acquainted with the components of a crawler and learn what data needs to be known for each object sent.
Sending objects to Mindbreeze
To be able to search for an object, it must first be included in the index. This chapter explains how to send objects from your data source to Mindbreeze. It is very easy to make an object searchable; the following lines are sufficient to store an object with the title "title" and the key "1" in the index:
Indexable indexable = new Indexable();
indexable.setKey("1");
indexable.setTitle("title");
client.filterAndIndex(indexable);
When looking at these lines, there are still a few things to consider. First of all, you need to think about which documents from your data source are relevant for the search.
Which objects are present in my data source?
If you want to add a new data source to the search, you should always consider what content will be of interest to the users. This example uses some CMIS services as the data source. CMIS offers four different object types: Folders, documents, relationships, and policies. In the example shown, only documents are sent.
How are objects sent? Which process is in charge of sending?
Mindbreeze uses crawlers to send objects to the index. A crawler knows the data source and sends the objects it contains to be indexed. There is a crawler for each data source type. Mindbreeze InSpire has a Microsoft Exchange crawler and a Microsoft SharePoint crawler, to name two. In our SDK, we offer the same plugin interface that we use for our crawlers.
As a first step, you should package the example crawler as a plugin and import it into your appliance. Right-click on the build.xml file and select Run As > Ant Build..

This creates the plugin archive cmis-datasource.zip in the build directory.
Now the plugin has to be added to the appliance. Open the configuration interface of Mindbreeze and switch to the tab “Plugins”. Select the zip file and confirm with “Upload”.

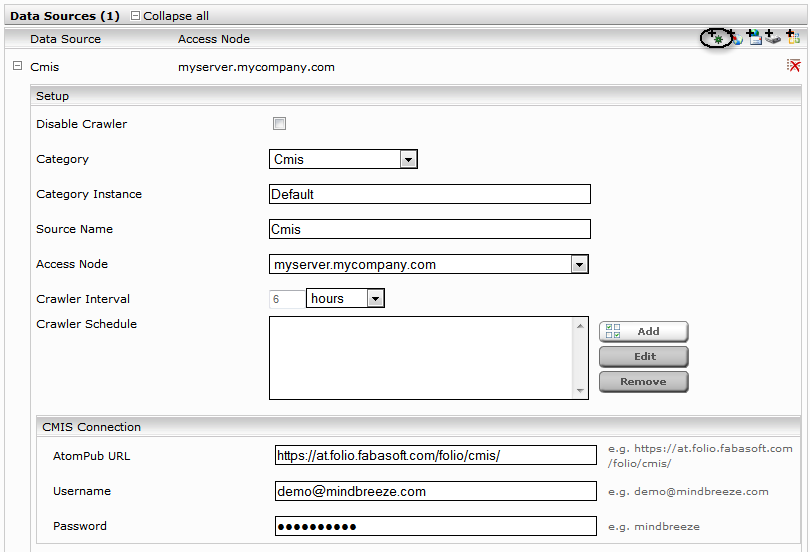
Now the plugin is installed and you can create an index and add a new data source.
Further information
For more information, see https://www.mindbreeze.com/developer/basic-indexing.
Tips for Producer-Consumer scenarios
When a Producer-Consumer setup is used, the indexes synchronize at regular intervals. The synchronization ("SyncDelta") takes anywhere from a few seconds to a few minutes depending on the amount of data. For technical reasons, the index can only be used read-only during this short period of time (the same effect is achieved by manually setting the index to read-only).
If a FilterAndIndexClient is used in this time period, e. g. client.filterAndIndex (indexable), the indexable is not indexed. Due to asynchronous processing, no exception is thrown during this process.
For this reason, we recommend the following error handling strategies.
Automatic repeat
Here, if the index is currently performing a SyncDelta or is read-only, the indexable is automatically repeated until it is successfully indexed.
This has to be activated in the configuration with the property repeat_on_503. The property must be set to true.
In a crawler, the property must be set as an option in plugins.xml.
In a stand-alone pusher, the property must be set in the configuration object when calling the factory method of FilterAndIndexClientFactory.
Manual repeat
In order to find out if the use of FilterAndIndexClient was successful, a ProcessIndexableListener can be registered:
client.addProcessIndexableListener(new ProcessIndexableListener() {
@Override
public void processed(ProcessIndexableEvent event) {
Indexable indexable = event.getSource();
boolean wasSuccessful = event.wasSuccessful();
Operation operation = event.getOperation(); // e.g. FILTER_AND_INDEX or DELETE
Throwable cause = event.getCause(); // if not successful, this is the exception
if (!wasSuccessful){
// Do error handling here
}
}
});
This ProcessIndexableListener is called asynchronously after using the FilterAndIndexClient.
Complex metadata
This section describes the process of indexing simple metadata such as string and date:
https://www.mindbreeze.com/developer/basic-indexing#data-types
However, as this section shows, more complex data structures can also be indexed.
HTML fragments
HTML fragments can be indexed as metadata.
The following example demonstrates the use of ValueParser, which can be used to save an HTML link as metadata:
...
import com.mindbreeze.enterprisesearch.mesapi.filter.ValueParserFactory;
...
ValueParserFactory valueParser = ValueParserFactory.newInstance().newValueParser(null);
...
String htmlString = "<a href=\"http://example.com\">Click me</a>";
Item.Builder value = valueParser.parse(Format.HTML, null, htmlString);
indexable.putProperty(NamedValue.newBuilder().setName("my_html_meta").addValue(value));
Notes: The HTML is fully stored (in transformed form as XHTML) in the index. However, when the search result is displayed as a metadata item, a lot of HTML elements and attributes are removed to protect the layout from unwanted changes. The following HTML elements are displayed in the search result: [a, span]. The following HTML attributes are displayed: all except for [id, class, JavaScript-functions].
If metadata is already in XHTML format, you can specify the format XHTML:
Item.Builder value = valueParser.parse(Format.XHTML, null, xHtmlString);
Note: The parse() method may throw an exception if the passed string does not contain correct XHTML.
These metadata are then displayed as HTML in the search results.
Dynamic aggregatable metadata
For a metadata to be filterable, it must be "aggregatable". Static aggregatable metadata can be defined in categoryDescriptor.xml.
However, in order to be able to decide at runtime which metadata should be filterable, there is dynamic aggregatable metadata. In contrast to static aggregatable metadata, the aggregatability can be determined at runtime and per document.
The following example illustrates how to add a dynamic aggregatable metadata to a Mindbreeze InSpire document:
Indexable indexable = new Indexable();
indexable.putProperty(TypesProtos.NamedValue.newBuilder()
.setName("sample_meta")
.addValue(TypesProtos.Value.newBuilder()
.setStringValue("sample_value")
.setKind(TypesProtos.Value.Kind.STRING).build())
.setFlags(TypesProtos.NamedValue.Flags.INVERTED_VALUE |
TypesProtos.NamedValue.Flags.STORED_VALUE |
TypesProtos.NamedValue.Flags.AGGREGATED_VALUE)
);
Notes for query expression transformation service plugins
Default Order
Since several Query Expression Transformation Service Plugins can be configured, the order in which these plugins successively transform the query expression is important. The default order can be defined by a "priority" in plugins.xml. This priority is a numeric value and must be less than 100.000. The plugins are executed in descending order (high priority first).
The default "priority" can be set per plugin in plugins.xml as follows:
<!-- within the plugins.Plugin.code.Code section -->
<properties>
<KeyValuePair>
<key>priority</key>
<value>10000</value>
</KeyValuePair>
</properties>
If the default order does not show the desired effect, the order of the plugin can be changed with the arrow buttons in the Management Center.
Required plugins
If an error occurs in a query expression transformation service plugin (exception or timeout), the transformation is skipped and the unchanged query expression is used instead.
However, some plugins perform sensitive tasks, such as displaying and hiding security-relevant metadata or resolving DSL keywords. If these sensitive plugins are faulty and errors occur, skipping them would be disastrous, because security-relevant data may be displayed that would not otherwise be displayed if the plugin were working correctly.
For this reason, query expression transformation service plugins can be marked with a “required” flag. Plugins flagged in this way are not skipped in the event of an error, but instead stop the entire pipeline and no results are displayed during the search (“fail-fast” principle).
The “required” flag can be set for each plugin in plugins.xml as follows:
<!-- within the plugins.Plugin.code.Code section -->
<properties>
<KeyValuePair>
<key>required</key>
<value>true</value>
</KeyValuePair>
</properties>
Transform Non-Expandable Query Expressions
Query Expression Transformation Services do not transform the entire search request, but the query expressions contained in the search request. Normally, not all query expressions can be transformed, but only expandable query expressions. In certain situations, this might lead to not available data in the Transformation Service.
To work around this, Query Expression Transformation Services can be marked with a "transform_nonexpandable" flag. Marked Query Expression Transformation Services are also using non-expandable query expressions for transformations.
The "transform_nonexpandable" flag can be set per plugin in plugins.xml as follows:
<!-- within the plugins.Plugin.code.Code section -->
<properties>
<KeyValuePair>
<key>transform_nonexpandable</key>
<value>true</value>
</KeyValuePair>
</properties>
Content Fetch Interface
Using the ContentFetch interface, content can be obtained for various document types:
public interface ContentFetch extends Closeable
The following methods must be implemented:
public String getCategory();
The function getCategory() specifies the category of the data source, such as "Microsoft File", for which the content fetch can be used:
public ContentData fetch(String category, String categoryInstance, String key,
String categoryClass, Principal identity,
Map<String, String> params);
The method fetch() returns the data object of the search result described by the parameters:
Description | |
category | The category of the search result. |
categoryInstance | The category instance of the search result. |
key | The key of the document in the search result. |
categoryClass | The category class of the search result. |
identity | The identity of the search user. |
params | Additional parameters from the context provider. The user can specify the mime type of the document, such as "mimetype" : "application/pdf" in the params of fetch() for faster processing. If the mime type is not specified, it must be determined from the document in the implementation of the fetch() method, which requires additional runtime. public void close(); The method close() cleans up the content fetch object. |