
Sure, you can handle it. But should you?
Let our experts manage the tech maintenance while you focus on your business.
Let our experts manage the tech maintenance while you focus on your business.
Language Detection
LanguageDetector Plug-In
Introduction
Mindbreeze provides languge dectection for documents using the LangugageDector ItemTransformer plugin.
LanguageDetector Plug-In
To use the language detection the LanguageDetector has to be added to you Mindbreeze installation by loading the corresponding plugin (the Item Transformation Services are included in the package “ Mindbreeze Item Transformation Plugins”). Install the plugin use the manager UI.
The plugin also has to be included in your Mindbreeze license.
Configuration
- Activate the plugin for each needed index using the manager UI:
- Select the tab „Indices“ and activate „Advanced Settings“
- Scroll to the „Item Transformation Services” section
- Select the “TextPlugin.LanguageDetector” plugin and click add.
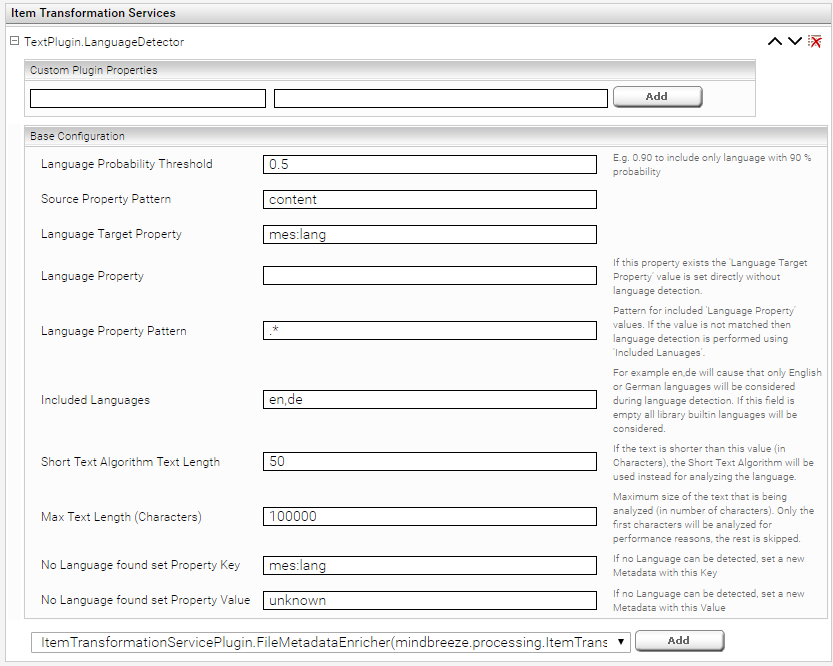
- Language Probability Threshold: Specifies the probability threshold which has to be reached for a language to be included.
- Source Property Pattern: Specifies the property used for language detection.
- Language Target Property: Specifies the new property for the detected languages. To be able to filter by this metadata, it must be aggregatable. To do this, activate the Advanced Settings and add the metadata in the Aggregated Metadata Keys option in the index configuration.
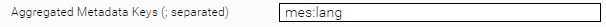
- Language Property: defines the property which already includes the language. This skips the language detection and sets target property.
- Language Property Pattern: Defines languages that should be considered from the “Language Property”
- Included Languages: Defines the languages for language detection (use the language abbreviations, see table in the appendix section, separated by commas, e.g. en,de). If no languages are specified, the plugin tries to detect all supported languages. It is recommended to specify the required languages, as this will improve the quality of the language detection significantly.
- Force Included Languages: If enabled, the probabilities are only calculated on the basis of the “Included Languages" (and not on the basis of all supported languages). If only a few languages are configured in "Included Languages", it is advisable to disable this option.
- Short Text Algorithm Text Length: For short texts, the quality of speech recognition can be improved by using the "Short Text Algorithm". This setting determines the maximum length of the text (in characters) for which the "Short Text Algorithm" is used. Longer texts are analyzed with the “normal” algorithm.
- Max Text Length (characters): Determines the maximum length of the text (in number of characters) to be used for the analysis. For performance reasons, only the first characters of longer texts are used for analysis, the rest is skipped. The length of the text includes the sum of the contents of all metadata found with the Source Property Pattern. Default value: 100000
- No Language found set property key and No Language found property value: If speech recognition could not determine a language, a metadata can be set with a name (key) and a value (value). This can be useful to explicitly mark documents with no recognized language.
Run the LanguageDetector as separate Service
The LanguageDetector plugin can be used not only as an item transformation service, but also as a separate service. This can provide performance advantages for large installations with multiple indices, since only one single LanguageDetector service is operated for all indices and not one instance per index.
To run the LanguageDetector plugin as a standalone service, install the MetadataTransformationService-<version>.zip plugin. Add a new service in the "Indices" tab in the "Services" section and select "ItemTransformationServicePlugin.LanguageDetector". In the settings of the new service set a "Display Name" and the "Bind port" to a free TCP port. The remaining settings are to be set according to the section "Configuration". Finally, switch to the "Indices" section in the "Indices" tab and add an Item Transformation Service to the respective index and reference the created service.
Appendix
Language profiles
Here you can find a list of language profiles supported by the LanguageDetector. The listed languages can be used in the configuration of the LanguageDetector ("Included Languages" option). The option "Short Text Algorithm Text Length" defines for which text lengths the long or short text profile of the respective languages is selected. For more information on configuration, see below.
Abbreviation | Language | Long text | Short text profile available |
af | Afrikaans | X | |
an | Aragonese | X | |
ar | Arabic | X | |
ast | Asturian | X | |
be | Belarusian | X | |
br | Breton | X | |
ca | Catalan | X | |
bg | Bulgarian | X | |
bn | Bengali | X | |
cs | Czech | X | X |
cy | Welsh | X | |
da | Danish | X | X |
de | German | X | X |
el | Greek | X | |
en | English | X | X |
es | Spanish | X | X |
et | Estonian | X | |
eu | Basque | X | |
fa | Persian | X | |
fi | Finnish | X | X |
fr | French | X | X |
ga | Irish | X | |
gl | Galician | X | |
gu | Gujarati | X | |
he | Hebrew | X | |
hi | Hindi | X | |
hr | Croatian | X | |
ht | Haitian | X | |
hu | Hungarian | X | |
id | Indonesian | X | X |
is | Icelandic | X | |
it | Italian | X | X |
ja | Japanese | X | |
km | Khmer | X | |
kn | Kannada | X | |
ko | Korean | X | |
lt | Lithuanian | X | |
lv | Latvian | X | |
mk | Macedonian | X | |
ml | Malayalam | X | |
mr | Marathi | X | |
ms | Malay | X | |
mt | Maltese | X | |
ne | Nepali | X | |
nl | Dutch | X | X |
no | Norwegian | X | X |
oc | Occitan | X | |
pa | Punjabi | X | |
pl | Polish | X | X |
pt | Portuguese | X | X |
ro | Romanian | X | X |
ru | Russian | X | |
sk | Slovak | X | |
sl | Slovene | X | |
so | Somali | X | |
sq | Albanian | X | |
sr | Serbian | X | |
sv | Swedish | X | X |
sw | Swahili | X | |
ta | Tamil | X | |
te | Telugu | X | |
th | Thai | X | |
tl | Tagalog | X | |
tr | Turkish | X | X |
uk | Ukrainian | X | |
ur | Urdu | X | |
vi | Vietnamese | X | X |
yi | Yiddish | X | |
zh-cn | Simplified Chinese | X | |
zh-tw | Traditional Chinese | X |