
Sure, you can handle it. But should you?
Let our experts manage the tech maintenance while you focus on your business.
Let our experts manage the tech maintenance while you focus on your business.
Configuration
Filter Plugins
Introduction
In the section „Filter Plugins“of the filter service configuration there are all filter plugins that can be selected for a file extension. The extensions are matched case-insensitive.
If these filter plugins need some customized configuration this should be done in „Global Filter Plugin Properties“ section of filter service configuration. In order to do this the filter plugin should be selected from the dropdown list and added to the filter service configuration and configured as needed.
Common plugin settings
The following field can be configured for several plugins.
Number of instances | Sets how many instances of the plugin should run in parallel. Default value: let the system decide. |
General information about standard e-mail filters (FilterPlugin.POIMsg and FilterPlugin.EML)
E-mails (documents with extension .msg or .eml) usually contain several contents. Examples of such contents are email attachments. The standard e-mail filter plug-ins (FilterPlugin.POIMsg and FilterPlugin.EML) extract e-mail attachments from e-mail documents. Depending on the extension, the attachments are then forwarded to other filters (e.g. PDF, DOCX...), which further extract the content.
The content of an e-mail can also exist in different formats (sometimes even side by side). Examples are plain text (TXT), HTML or rich text (RTF) and HTML formatted emails. If available, HTML is preferred and forwarded to the filter configured for HTML. Otherwise, RTF or TXT will be used as content.
The different parts of an e-mail (attachments, content) are also known as MIME parts. These MIME parts can have different character encodings within the same email, depending on the email application, operating system and location settings. The default e-mail filters (FilterPlugin.POIMsg and FilterPlugin.EML) normalise these character encodings to UTF-8. This behaviour can also be adjusted, if required.
FilterPlugin.POIMsg
The following fields can be configured for POIMsg Filter Plugin:
Field name | Descripton |
Keep Datasource Category Class | All msg files filtered by this plugin get the category class „mail“ per default even if the datasource defines another category class. To keep the category class of the datasource, select this check box. |
Prefer HTML Meta Tag Character Encoding | If enabled, the HTML content of emails will be parsed using the character encoding specified in the HTML meta tag. This means that the character encoding specified in the MIME part is not applied. Default setting: Disabled. |
FilterPlugin.InternalZip
The following fields can be configured for the InternalZip filter plugin:
Field name | Description | ||||||
Datasource Metadata Selection Strategy | The following options are available:
|
FilterPlugin.EML
The following fields can be configured for the EML filter plugin:
Field name | Description |
Prefer HTML Meta Tag Character Encoding | If enabled, the HTML content of emails will be parsed using the character encoding specified in the HTML meta tag. This means that the character encoding specified in the MIME part is not applied. Default setting: Disabled. |
Keep MIME Part Character Encoding | If enabled, text and HTML content will not be normalised to UTF-8, but will remain in the original format. Default setting: Disabled. |
FilterPlugin.MetadataOnly
The FilterPlugin.MetadataOnly serves as a fallback filter if no other filter could filter the document and "Probing" is enabled. With this filter it is possible to index documents that cannot be indexed with other filters.
The FilterPlugin.MetadataOnly only passes documents to the index without filtering the content itself. This means that no content metadata or preview is created for the document. Metadata such as filename, date, author etc. is still passed to the index.
This filter can be used, for example, to index encrypted PDF files. Without this plugin (and without probing activated), encrypted PDF files will be discarded by the filter and not forwarded to the index, because the filter does not have access to the contents of the PDF. If this filter and “Probing” is enabled for the desired extension, the selected PDF filter will continue to filter unencrypted PDF files as usual. Encrypted PDF files are processed by the MetadataOnly-Filter instead and can be found in the search, but without content.
Per default this filter is enabled for all extensions which are per default enabled (e.g.: HTML, txt, pdf etc.) but will only process items if also probing is activated for the desired extensions. For all non-default-enabled extensions, the filter has to be enabled manually by selecting it.
The following fields can be configured for the MetadataOnly filter plugin:
Field name | Description |
Is enabled | Can be used to deactivate the Filter completely. Default setting: Enabled. |
FilterPlugin.PDFPreviewFPDFFilter
The FilterPlugin.PDFPreviewFPDFFilter is used to extract metadata and contents from pdf documents.
The following fields can be configured for the PDFPreviewFPDFFilter plugin:
Field name | Description |
If checked, disables the creation of a thumbnail for the document. Default setting: False (thumbnails are created). | |
Disable Preview Content | If checked, disables the generation of a full preview the PDF document from the search results. In this case, the preview only shows a summary of the contents. Default setting: False (full previews are available). |
Extract Links | If checked, the filter will extract the target of external links in PDF documents. If HTML entity recognition is active for HTML links (see <>), entities will also be extracted. Default setting: Disabled |
Max Layout Annotations Per Page | Maximum number of text boxes to extract as annotations, per page. Default value: 0 |
Thumbnail Width | Maximum width of the thumbnail (in points) Note: The aspect ratio of the page is preserved. Do not specify both a maximum height and a maximum width. Default value: 200pt |
Thumbnail Height | Maximum height of the thumbnail (in points) Note: The aspect ratio of the page is preserved. Do not specify both a maximum height and a maximum width. Default value: 200pt |
PDF Meta Keys (in Addition to Defaults) | Additional PDF metadata to extract, separated by semicolons. Standard metadata (title, author, subject, keywords, creator, producer, creation date, modification date) are extracted by default, it is not necessary to add them. Default value: None |
Sizes are specified in points (1 point = 1/72 inch = approximately 0.3528mm).
FilterPlugin.OfficeDocumentToPDFContentFilter
The filter plugin “OfficeDocumentToPDFContentFilter” is used to prepare Microsoft Office documents for the PDF preview.
This filter plugin is deactivated by default or must be explicitly activated.
The filter plugin can be applied to the following file extensions:
Application | File extension |
Microsoft Word, LibreOffice Writer or Google Text and Tables | odt |
LibreOffice Writer | sxw |
LibreOffice-Suite |
|
ArcScene | sxd |
Microsoft Windows Wordpad, Mac Textedit | rtf |
Microsoft Word |
|
Microsoft PowerPoint |
|
Microsoft Excel |
|
Microsoft Visio |
|
Steinberg Cubase, Imageline FL Studio and Audacity | vst |
The following settings are available:
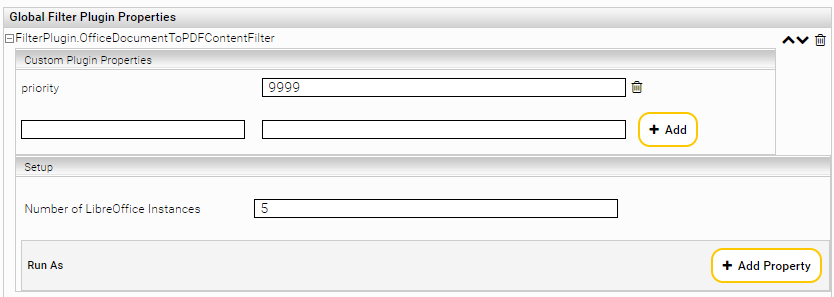
Setting | Description | Example |
Custom Plugin Properties | ||
priority | Specifies the order in which the plugins are executed. The higher the specified number, the higher the priority and the earlier the plugin is executed. The use of this setting is recommended for use cases where the application of different plugins to different file formats is to be controlled in detail. | 1947 |
Setup | ||
Number of LibreOffice Instances | Defines the number of instances that are to be started. If not set, a default value is assumed, which is generally sufficient. | 3 |
Run as | ||
User name | This setting is no longer used. | - |
Password | This setting is no longer used. | - |
Activate the PDF preview for all available file types
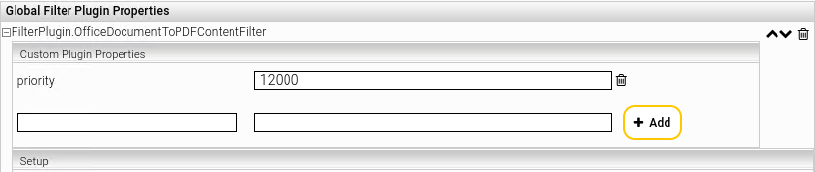
By default, the filter plugin “FilterPlugin.ApacheTikaWithThumbnails-Latest” is used for Microsoft Office documents. In order to pre-queue the filter plugin “FilterPlugin.OfficeDocumentToPDFContentFilter” and thereby generate a PDF preview, the priority of the FilterPlugin.OfficeDocumentToPDFContentFilter must be set to a value greater than 11100. This can be configured in the setting “priority”:
Activating PDF preview for one or more file types
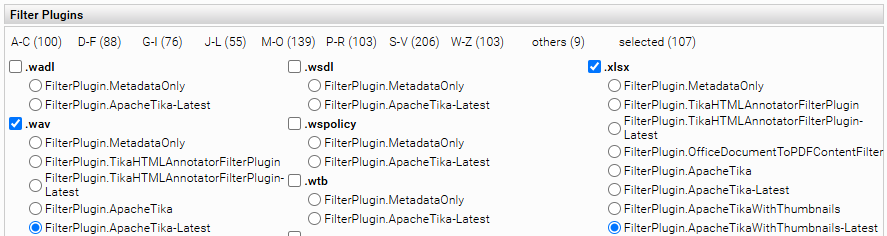
To activate the PDF preview for one or more specific file types, you can activate the filter plugin “FilterPlugin.OfficeDocumentToPDFContentFilter” for a specific file type in the filter settings (see file extension xlsx in the screenshot):
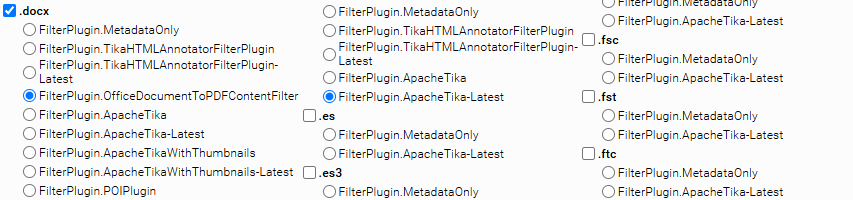
For example, you can select the filter plugin “FilterPlugin.OfficeDocumentToPDFContentFilter” for the .docx file extension with a single click:
FilterPlugin.Pandoc
The filter plugin “FilterPlugin.Pandoc” is used to extract content from Microsoft Office documents.
This filter plugin is deactivated by default or must be explicitly activated.
The filter plugin can be applied to the following file extensions:
Application | File extension |
Microsoft Word, LibreOffice Writer or Google text and tables | odt |
Microsoft Windows Wordpad, Mac Textedit | rtf |
Microsoft Word | docx |
Microsoft PowerPoint | pptx |
Microsoft Excel | xlsx |