
White Paper
Installation and Configuration of Mindbreeze InSpire
Copyright ©
Mindbreeze GmbH, A-4020 Linz, 2024.
All rights reserved. All hardware and software names used are brand names and/or trademarks of their respective manufacturers.
These documents are strictly confidential. The submission and presentation of these documents does not confer any rights to our software, our services and service outcomes, or any other protected rights. The dissemination, publication, or reproduction hereof is prohibited.
For ease of readability, gender differentiation has been waived. Corresponding terms and definitions apply within the meaning and intent of the equal treatment principle for both sexes.
Introduction
This document describes the installation and configuration of Mindbreeze InSpire in a Microsoft Windows environment.
Mindbreeze InSpire consists of:
- The Mindbreeze InSpire Node, which is used to create indexes which can be queried by the users.
- The Mindbreeze InSpire Management Node, which is used to configure and administer the Mindbreeze InSpire Nodes which are distributed over the network via a graphical user interface.
These components can be installed as required.
Chapter 9 describes the Mindbreeze InSpire query language.
Software Requirements
All information contained in this document implicitly assumes a Mindbreeze InSpire environment and Mindbreeze InSpire 2016 Spring Release.
Requirements:
- All information about our current software requirements you can find in our Software Product Information
The required setup packages are provided on the Mindbreeze InSpire ZIP/ ISO File in the prerequisites directory.
Advanced Configuration of Mindbreeze InSpire
After installing Mindbreeze InSpire, the user interface for configuring Mindbreeze InSpire will be displayed in a web browser.
It is recommended to select „Apply changes and restart on save“ option before saving any changes in the configuration. The services will restart after saving configuration changes. Therefore, it is recommended that these changes should be performed only during maintenance times.

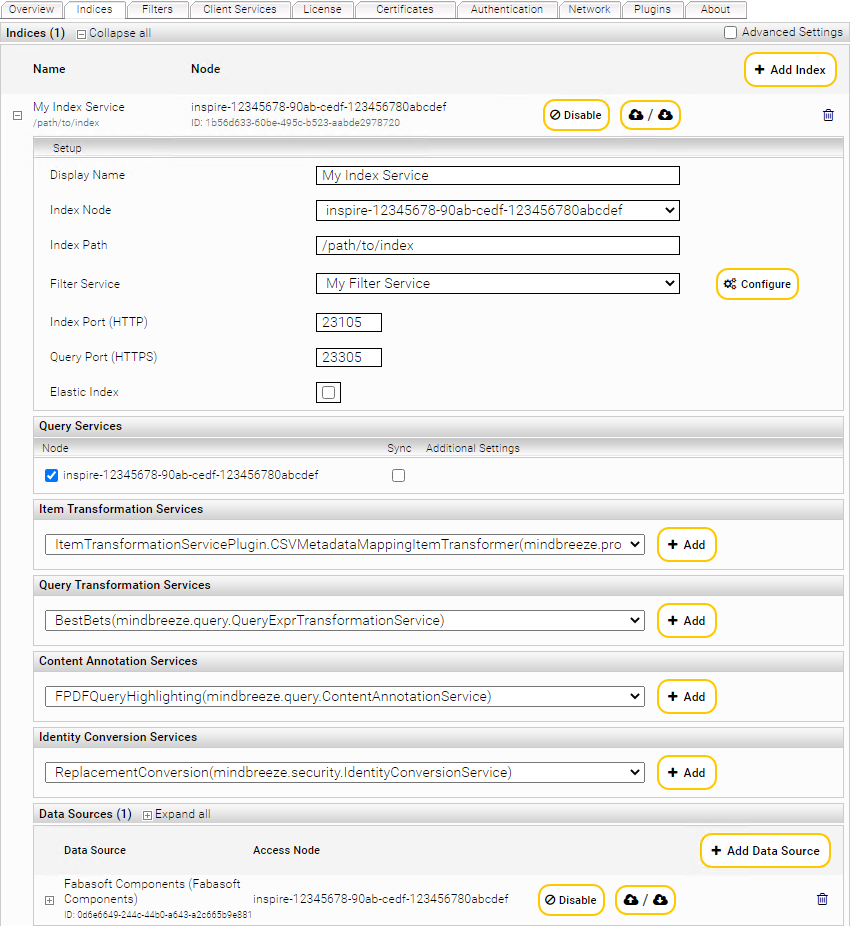
The “Overview“ tab
This screen gives an overview of all Services, Nodes, and Category Plugins configured on the server.

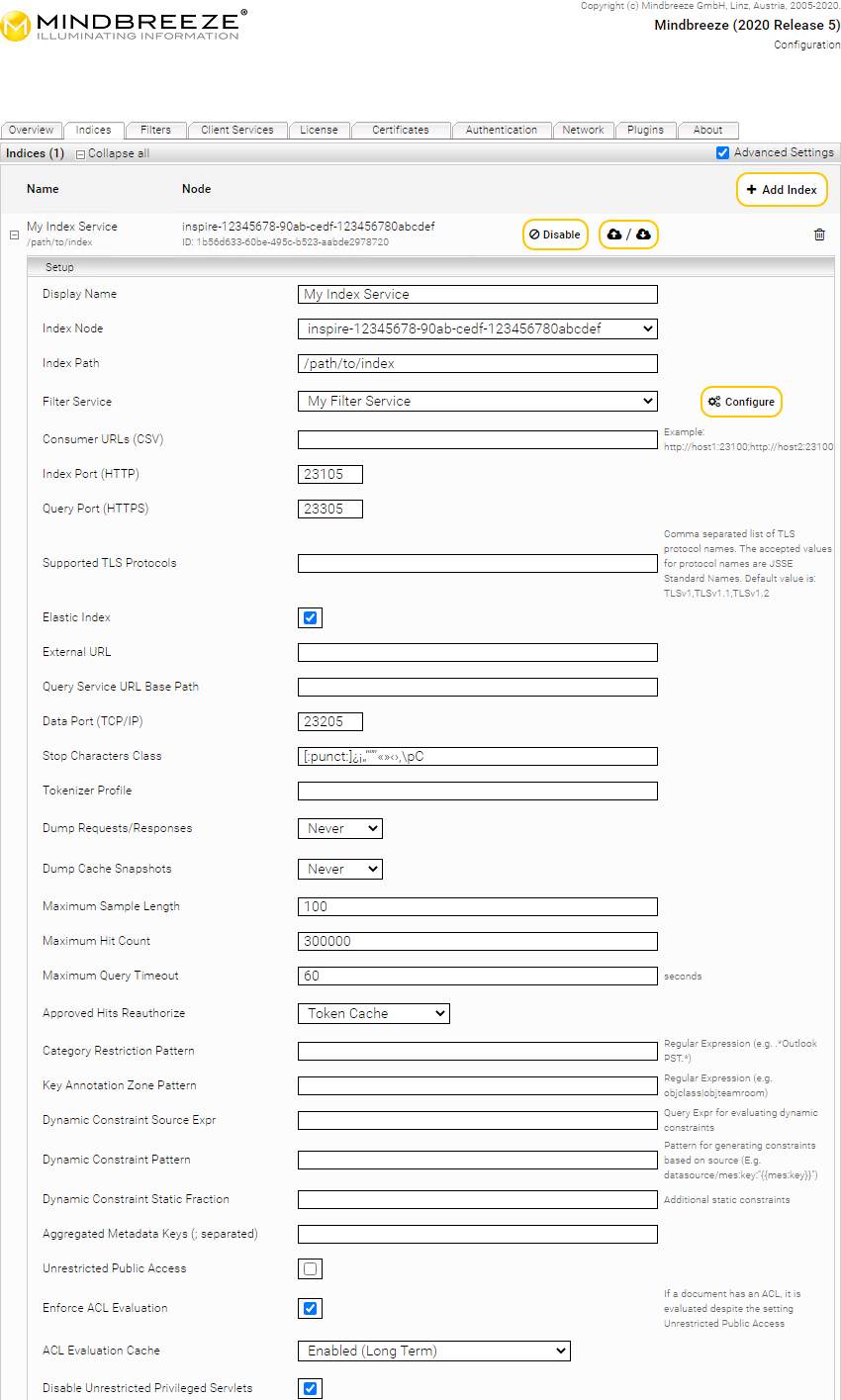
“Indices“ Tab
Index Services can be managed using the “Indices“ tab. All configured index services are listed here. They can be edited and deleted from here. Additionally, new index services can be created.
Index service settings can be imported directly from or to an existing index.
![]()
For detailed instructions visit chapter “Import/Export of Settings”

To create an Index Service on the “Indexes” tab, perform the following steps:
Click the “+ Add Index” button located on the top right-hand side.
By clicking on the "Enable" or "Disable" button, you can temporarily switch an already created index on or off.

Edit the properties of the Index Service:
In the “Setup” box, the fields “Display Name”, “Index Node”, “Index Path” and “Filter Service” are available by default. The following values can be specified in those fields:
Display Name | In this field, a name for the Index Service can be specified. |
Index Node | In this field, the server the Index Service is running on is defined. |
Index Path | In this field, the path to the index directory can be specified. All index files will be stored in this directory. This path is located on the computer defined with "Index Node". |
- “Filter Service”: In this dropdown list, a Filter Service specifying the files which are to be indexed can be selected.
- Note: The Advanced settings checkbox showing additional options can be enabled if required.
- In the “Query Services” field, the Query Services making the Index Service available can be selected.
- In the “Data Sources” field, a data source to be indexed can be defined. Optionally, third-party products can be selected to pass data to the Index Service here.
- Click “Configure“ to get redirected to the configuration interface of the Filter Service in use.
-
- The configuration interface will automatically switch to the “Filters“ tab and the filter service to be configured will be opened in edit mode.
Note: Editing Filter Services can also be done directly via the ”Filters“ tab.
Checking the “Advanced Settings” checkbox located at the top right of this page will allow you to configure more index-related options.
These additional options are:
Section: Setup | |||||||||
Supported TLS Protocols | Allows customizing the set of TLS Protocols that are supported by the Query Service. The value of this field must be a comma separated list of JSSE Protocol names. | ||||||||
External URL | If the Query Service is located behind a load balancer that is accessible with a different host name, it is necessary to enter the external URL to the load balancer including the base path (see Query Service URL Base Path for details). | ||||||||
Query Service URL Base Path | Allows the query service target URL to use a different URL than the default root (“/”) base path. This is needed when using a query service behind a central non rewriting reverse proxy. | ||||||||
Data Port (TCP/IP) | Specifies the TCP with which subsystems will communicate. | ||||||||
Stop Character Class | This option allows custom definition of word separators for this index. By default, an index uses the separator characters as defined by the Unicode standard. If you leave this field empty, the following characters will be used as separator characters: | ||||||||
Tokenizer Profile | Allows custom definition of the tokenizer using a profile name. Currently, two profiles are available:
| ||||||||
Dump Requests /Responses | This option enables enhanced troubleshooting and logs requests and responses to the index path under the “mesindex-debug-dumps” directory. The setting "On Error" logs every time a request produces an error. If the default setting "Never" is chosen, no logging occurs, "Always" logs each request. | ||||||||
Maximum Sample Length | Defines the maximum number of characters that will be sample texted for metadata and contents. | ||||||||
Maximum Hit Count | Specifies the maximum number of hits which will be processed for a single query. | ||||||||
Approved Hits Reauthorize | Defines whether reauthorization of effective results should be performed by an external Data Source or by the internal Token Cache:
| ||||||||
Aggregated Metadata Keys | This option configures the metadata that the user needs for aggregation. | ||||||||
Unrestricted Public Access | When activated, queries to this index will not be access checked. | ||||||||
ACL Evaluation Cache | This option can be used to configure the ACL Evaluation Cache:
| ||||||||
Suppress Identity Conversion | When enabled: directs the Query Service not to use any Identity Conversion Service including internal identity conversion. | ||||||||
Suppress Internal Identity Conversion | Enabling this option directs the Query Service not to normalize the username according to platform standards. This option is useful if the normalization is not required. This use is specific to the Connector and Platform used. | ||||||||
Use Authentication Cache | Is deactivated by default and enables the caching of external authorization results between the “Authentication Cache Flushing Interval”. | ||||||||
Enable Security Token Authentication Cache (Deprecated) | enables the caching of security tokens. This Option ist deprecated and disabled by default. | ||||||||
Authentication Cache Flushing Interval | The time that can be set here, sets the maximum lifetime of a cached access check result. | ||||||||
SyncDelta Wait For Index Production Finished Attempts | can be used to configure the maximum amount of attempts (in 5 second intervals) to check whether the index has finished inversion, before the index synchronization is executed. If the amount is exceeded, the SyncDelta operation is aborted. | ||||||||
Term Boost Factor | Here, the relevance evaluation of terms can be controlled. | ||||||||
NGram Boost Factor | Here, the relevance evaluation of NGrams can be controlled. | ||||||||
Use Term Lexicon | Is activated by default and enables the term lexicon feature. If turned off, the term lexicon will be ignored during index creation and search. | ||||||||
Embedded Java VM Args (-Xms..) | This option enables to pass Java specific arguments such as garbage collection control information to the embedded JVM. | ||||||||
RPC Request Timeout | The time that can be set here, sets the maximum duration of an internal RPC request. | ||||||||
Section: Document Insertion | |
Include Modification Date in Document Replacement | Documents are replaced in case of a different modification date. |
Include Metadata CRC64 in Document Replacement | Documents are replaced in case of a different metadata checksum. |
Include Content CRC64 in Document Replacement | Documents are replaced in case of a different content checksum. |
Update Documents In-place | If the document is changed, an attempt is made to replace the document in the place of the old document, provided the changes are security-relevant or do not affect the inverted index. |
Disable Inversion of Replaced Documents | If this option is enabled, updated documents are not removed from the index unless the new version can be found. If more than "Maximum Number of Tracked Replaced DocIDs" are reached and the new version is not yet searchable, then the document is deleted until the new version is findable. With this option enabled, it is possible to sync while a document is continuously receiving updates and without having to activate the "Wait for Inversion Completed before Synchronization" option. See also Distributed Operation (G7) - Index Synchronization Settings. |
Maximum Number of Tracked Replaced DocIDs | Specifies the maximum number of versions of a document as long as a document is soft deleted, i.e. it is not inverted as deleted. Only effective if "Disable Inversion of Replaced Documents" is enabled. |
Maximum Number of Consecutive Replacements | If a document is replaced frequently within the time configured in Invert Replaced Document Max Age Seconds, it will still be inverted as a non-deleted document. How often it has to be replaced within this time, can be configured with Maximum Number of Consecutive Replacements. Only effective if "Disable Inversion of Replaced Documents" is activated. |
Invert Replaced Document Max Age Seconds | See Maximum Number of Consecutive Replacements |
Section: Indexed Objects Settings | |||||||
Indexed Objects Status Includes | Hier kann man festlegen, welche Objekte der Index dem Crawler als Gesamtmenge der indizierten Dokumente mitteilt:
| ||||||
Section: Inverter Settings | |
Reinversion Startup Delay Seconds | Delays the inversion so that all services, e.g. Item Transformation Service, have time to register at the index. |
Wait for Inversion Completed (Final Buckets) before Switching to Readonly | If this setting is enabled, the index will not be set to read-only until all buckets that are in the finalizing state (i.e., finalized buckets with only the inverter running), are completely finalized. |
Wait for Merging Complete On Set Bucket Readonly Timeout (Seconds) | If the option Wait for Inversion Completed before Synchronization is disabled, non-final buckets are set read-only during synchronization to ensure that they are in a stable state. After stopping the inverter, there is an additional wait until the merging of already inverted documents has been completed. By default, 20 minutes (1200 seconds) is waited for the merging to complete. If the timeout elapses, a warning is logged and the bucket is still set read-only. |
Detect and Ignore Non-Text if Content Size is Greater Than or Equal | Enable Non-Text Content detection for content size greater than the value. 0 will disable this feature. |
Detect and Ignore Non-Text Content Size Unit | Unit Type for „Detect and Ignore Non-Text if Content Size is Greater Than or Equal” Megabytes or Kilobytes. |
Detect and Ignore Non-Text Content Buffer Size | Buffer Size for the Non-Text Content detection. 0 will disable this feature. |
Detect and Ignore Non-Text Content Buffer Unit | Unit Type for „Detect and Ignore Non-Text Content Buffer Size” Megabytes or Kilobytes. |
Verify Document Info Merge Result before Use | If enabled, it will check if the merging of the document info has been done correctly. |
Wait for Event Servlet Update Status Inverval (Seconds) | Defines the maximum amount of time after which an update is sent on the Wait servlet. This can be overridden by the servlet using the parameter update_interval. See Configuration - Index Servlets - Wait. |
Section: Alternatives Query Spelling Settings | |
Alternatives Query Spelling Max Estimated Count | If there are fewer hits than entered in this option, alternative search terms are suggested. |
Force Alternatives Query Spelling Max Estimated Count | If this option is selected than „Alternative Query Spelling Max Estimated Count“-option cannot be overwritten by options in search request sent by client service. |
Section: Query Expansion Settings | |
Disable Query Expansion for Diacritic Term Variants | With this option, the extension of the search to diacritical variants of the search word for the query service can be prevented. |
Section: NonInverted Metadata Settings | |||||||
Strategy for NonInverted Metadata | Here you can define which strategy should be used for the NonInverted metadata.
| ||||||
NonInverted Metadata Keys for Search (newline separated) | Here you can enter the metadata (one metadata per line) to be excluded from the search. | ||||||
Section: Reference Settings | |
Inverted Reference Metadata Keys | Can be configured to resolve inverse references using the Mindbreeze Property Expression Language. If multiple metadata keys are to be configured, they must be separated by semicolons. |
Hash Reference Target Metadata Keys | Can be configured to resolve inverse references using the Mindbreeze Property Expression Language. The Metadata keys (separated by semicolons) to be referenced, are entered here. The metadata keys specified here must be aggregatable (e.g. via Aggregated Metadata Keys). Also configure the Inverted Hash Reference Metadata Keys. |
Inverted Hash Reference Metadata Keys | Can be configured to resolve inverse references using the Mindbreeze Property Expression Language. The Metadata keys (separated by semicolons) to be referenced, are entered here. E.g.: "Document 1" references the person "Max Mustermann" with metadata author_email: max.mustermann@example.com. Person "Max Mustermann" has metadata email: max.mustermann@example.com. For (inverted) string references to work, configure the following options: - Inverted Hash Reference Metadata Keys: author_email - Hash Reference Target Metadata Keys: email Please note that the metadata keys specified here must be aggregatable (e.g. via Aggregated Metadata Keys). |
Enable Find All References For Source | Optimization for string references. Only effective if Inverted Hash Reference Metadata Keys is configured. |
Forced Reference Target Properties | Forward references (not string references) are resolved via metadata key mes:key by default. With this option, it is possible to overwrite the metadata key used to resolve the references, for each FQCategory. E.G.: Forced Reference Target Properties: Web:mindbreeze:page_id, then all references for documents with FQCategory: Web:mindbreeze will be resolved with the metadata page_id instead of mes:key. |
References Repair Bulk Update Size | The number of updates that will be performed within a transaction when repairreferences is called (default 100). See also Repair Refernces. |
Section: Query Transformation Service Settings | |
Query Transformation Service Plugin Processing Timeout (ms) | This option can be used to set a time limit for transformations for query transformation services. By default, the limit is set to 200ms, which means that each transformation is waited for a maximum of this time during a search. If a transformation takes longer than the timeout, this transformation is skipped. The timeout applies to all query transformation plug-ins for each transformation. A value less than or equal to 0ms means that no limit is configured |
Section: Query Settings | |
Use Additive Doc Boosting | Defines the boosting strategy for multiple boostings of one document. By default, “Additive Doc Boosting” is enabled, which considers all boostings on a document for calculating relevance. If the setting is disabled, only the highest boosting is used to calculate relevance. |
Default Restricted Categories for Did You Mean | "Did You Mean" suggestions are calculated only from the categories specified here. If empty, all documents from all categories are included. Separate the categories with line breaks or semicolons. E.g.: Web;Microsoft File |
Query Timeout Percentage for Did You Mean | Here you can set the "Did You Mean" timeout after which this should be aborted. The value is a percentage of the "Query Timeout" option in the client service. Example: Valid values: ]0.0,1.0] |
Max Query Timeout ms for Did You Mean | Upper limit for the effective timeout for Did You Mean in milliseconds. Default value = 500 (0 = unlimited, only "Query Timeout Percentage for Did You Mean" is used). Example: Query Timeout in Client Services: 10 (in seconds). |
Disable Did You Mean Term Count Threshold | Did You Mean is only performed if the number of terms in the query (minus stop words, if configured) does not exceed the configured value. The following values have a special meaning
|
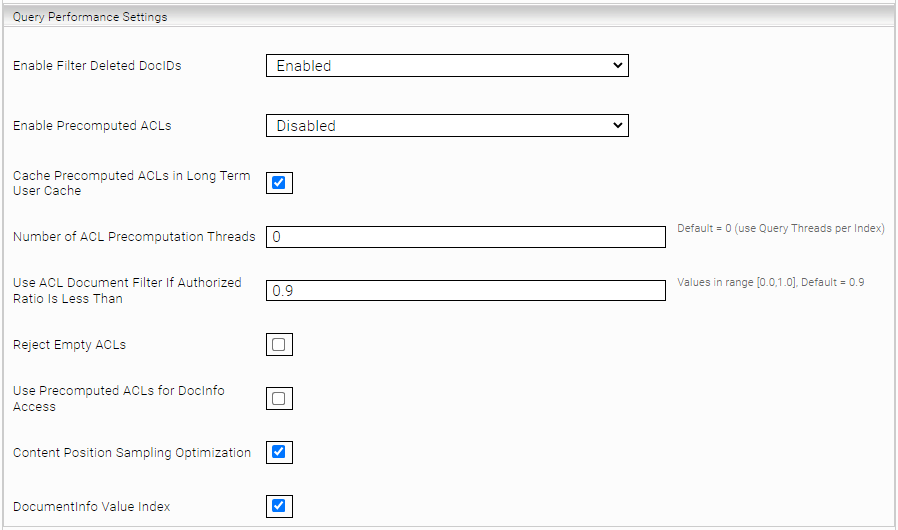
Query performance settings.
The settings in this section are used to improve query performance:

Enable Filter Deleted DocIDs | If this option is enabled, deleted documents are excluded earlier. | ||||||
Enable Precomputed ACLs | Documents for which the querying user has no authorizations are excluded earlier with this option. This option cannot be used if ACL references are also used. Possible values:
| ||||||
Number of ACL Precomputation Threads | This setting determines how many threads are used for this optimization. If the field is empty, the value of the “Query Threads per Index” setting is used. | ||||||
Use ACL Document Filter if Authorized Ratio is Less Than | Precompute ACL optimization is only applied if less than this percentage (0.0–1.0) is authorized for the querying user via ACL in an index. | ||||||
Reject Empty ACLs | Documents with empty ACLs are considered rejected during ACL precalculation. | ||||||
Use Precomputed ACLs for DocInfo Access | When documents reference other documents, the metadata of the referenced documents can be accessed. By default, the ACLs of the referenced documents are not checked. However, if the option "Use precalculated ACLs for DocInfo access" is enabled, the ACLs of the referenced documents are checked in addition to the normal ACL checking. Please note that this option can only be enabled if "Enable Precomputed ACLs" is active | ||||||
Content Position Sampling Optimization | This option enables an optimizes sample texting algorithm. |
Aggregation settings
Aggregated Metadata Keys Without Timeout (; separated) | Aggregation is not aborted for these metadata keys. |
Collected Aggregation Results Limit | The aggregation is not aborted after reaching the number configured here, but only that many results are returned. |
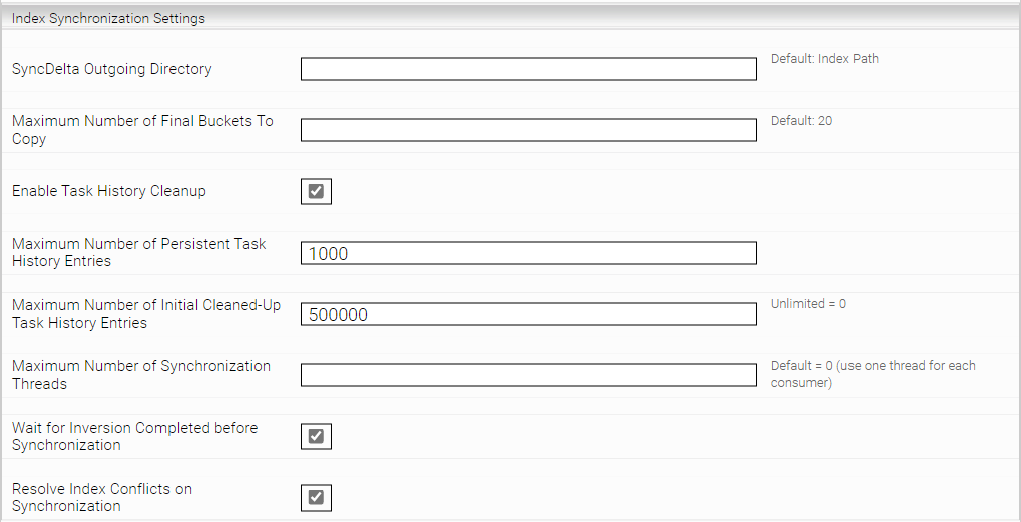
Index Synchronization
These settings are relevant if you use Mindbreeze InSpire in Distributed Operation (G7) mode.
SyncDelta Outgoing Directory | Allows setting a custom temporary directory used for outgoing synchronization operations. |
Maximum Number of Final Buckets To Copy | Allows overriding the default number of buckets copied within one synchronization operation. |
Enable Task History Cleanup | If active, the last task status files are deleted when the index is started. The maximum number of deleted files can be changed with the "Maximum Number of Initial Cleaned-Up Task History Entries" option and is set to 500 000 by default. |
Maximum Number of Persistent Task History Entries | Allows you to specify the maximum number of persistent task history files that are stored locally. These files will not be deleted by the Task History Cleanup. Default value: 10 000. |
Maximum Number of Initial Cleaned-Up Task History Entries | Allows you to configure the maximum number of Task Status files that can be deleted during the Task History Cleanup. Default value: 500 000. |
Maximum Number of Synchronization Threads | Allows limiting the number of threads used for a synchronization operation. |
Wait for Inversion Completed before Synchronization | If active, the index waits for the current inversion tasks before the synchronization process, so that the synchronized data is complete. (Default value: active). |
Resolve Index Conflicts on Synchronization | If turned on, try to resolve index synchronization conflicts implicitly. (Default value: active). |

Index Compactification
Index-performance may degrade over time if many documents are added and deleted. The compactification feature removes buckets that contain deleted documents from the index.
Remaining documents are moved to a new bucket.
Automatic Compactification
Permanent Delete Buckets | If the setting is disabled, buckets are moved to a backup folder instead of deleting. |
Enable Periodic Delete Buckets | Activates automatic compactification. |
Periodic Delete Buckets Schedule | This option defines the automatic compactification schedule using an extended cron expression. |
Periodic Delete Buckets Max Duration | The compactification task is aborted after the specified number of minutes. The next run continues at this point. |
Periodic Delete Bucket if Deleted % | The automatic compactification task considers only those buckets for deletion, which reach the defined deleted document percentage. Only values greater than or equal to 60% are allowed. |
Periodic Clean Documents in Updates Bucket Service | If this setting is set to Deleted, previously deleted buckets will also be deleted from the doc info. This saves unnecessary resources and can improve the synchronisation time between Producer and Consumer. If this setting is set to Deleted and Obsolete Revisions, old revisions of documents saved by updates and changes to the document will also be deleted. |
Periodic Clean Documents in Updates Bucket Service Cron Expr | Sets the schedule (as an extended cron expression) for the automatic compacting of doc-info. For example, the value "0 0 2 * * *" means a run every day at 2:00 (documentation and examples of Cron expressions can be found here). The time refers to the local time. |
Periodic Clean Documents in Updates Bucket Service Max Start Window | Defines the time window (in minutes) in which the doc-info compacting run is triggered. The window starts from the time of the "Periodic Clean Updates Bucket Service Cron Expr". |
Periodic Clean Documents in Updates Bucket Service Max Duration | Defines the timeout of the task. After the timeout has expired, the task is cancelled. |
Manual Compactification
Additionally, a command line interface using the “mescontrol”-tool is available.
- „bucketsinfo”: Prints the current state of the buckets including the deleted documents percentage.
- „listtasks“: Lists all running tasks.
- „taskcancel <taskid>“: Cancels the specified task
- „taskwait <taskid>“: Waits until the specified task is finished
- „taskstatus <taskid>“: Prints the status of the specified task
- „deletebuckets [--sync] [--min-percent-deleted-docs=<0..1>] [<bucketid_1>… <bucketed_n>] [--log-unreferenced-unfiltered-documents] [--cleanup-unreferenced-unfiltered-documents]: Deletes the specified buckets.
- „--sync”: the command returns after the task has finished
- „—min-percent-deleted-docs“: deletes buckets only if the percentage of deleted document exceeds this value
- „bucketid.“: the IDs of the buckets to be deleted
- „--log-unreferenced-unfiltered-documents“: If there are generated metafiles for documents e.g. Thumbnails for PDFs, but the original files were deleted without the metafiles, then logs will be written.
- „--cleanup-unreferenced-unfiltered-documents“: If there are generated metafiles for documents e.g. Thumbnails for PDFs, but the original files were deleted without the metafiles, then these files will be deleted. If „--log-unreferenced-unfiltered-documents“ is also set, logs will be written and the files will be deleted.
Network Settings
You can choose under Network Properties if you want to use the HTTP keep-alive for item transformations. This will reduce the number of open connections to static resources or reuse the connections. This feature is disabled by default.
Item Transformation Service Plugin Timeout: Item transformation requests are aborted after this timeout and the document is inverted without this transformation.

Entity Recognition Parameter
These settings enable the index service to extract metadata from document contents. For more information, see Configuration - Entity Recognition - Entity Recognition Parameter.
If Query Transformation plugins are installed the following section is added to the Index Service configuration panel in “Advanced Settings” mode.
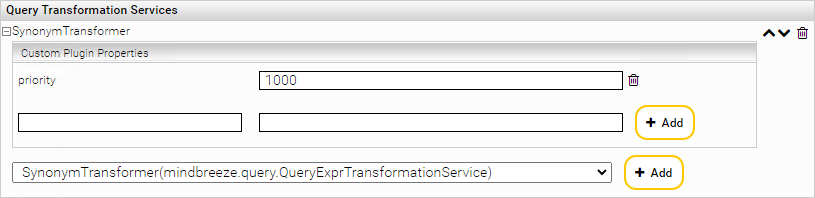
In the drop-down list the available Query Transformation plugins can be selected. The selected plugins can be activated for the current Filter Service using the “Add” button besides.
The activated plugins are listed above. By clicking on the “expand” button (![]() ) of an active plugin, a “Plugin Properties” section will be visible. Here you can define properties for the current plugin instance in form of key-value pairs. With the corresponding “delete” button you can remove (
) of an active plugin, a “Plugin Properties” section will be visible. Here you can define properties for the current plugin instance in form of key-value pairs. With the corresponding “delete” button you can remove (![]() ) these custom properties.
) these custom properties.
By clicking on the delete button besides the active plugin name, the plugin will be removed from the list with all defined instance properties and will not be active for the current Index service.
Global configuration of query and item transformation plugins
Under "Global Index Settings", you can configure the preinstalled query and item transformation plugins globally for all indices. These plugins are also automatically applied to any newly added index. The global configuration is only applied to indices for which no plugins are directly configured or default plugins removed.

Repair References
Using "repairreferences" it is possible to correct references that refer to incorrect uniformitemids. If corrections are made, the DocumentInfo is automatically re-inverted..
The repair is performed using the following steps:
- Scan all documents in the index to ensure that DocIDs are unique
- Repair of document entries in the reference index
- Repair of references in all documents
Usage:
The repair is started with the mescontrol command line tool "repairreferences". It is necessary that the option "Disable Unrestricted Privileged Servlets" is deactivated.
mescontrol http://<INDEXHOST>:<INDEXPORT> repairreferences [--bulk-update-size=0] [--skip-uniformitemid-check] [--dry-run] [<docid> ... <docid>]
Optional parameters:
- --bulk-update-size: The number of updates performed within a transaction. Overrides the References Repair Bulk Update Size index option. Default value: 100
- --skip-uniformitemid-check: Step 1 is skipped
- --dry-run: At the end of step 3 documents are not updated
- docid ... docid: List of documents to be repaired
Enabling Index Backups
Index Backups can be enabled in the “Global Index Settings” section beneath the service configuration sections on the „Indices“ tab.
In the field „Allowed Backup Path Pattern (Regex)“ a regular expression is used to restrict the pattern of allowed backup directory paths.
Note: When separating paths, backslashes must be escaped: \\
To start a backup, the command line tool mescontrol can be used:
mescontrol http://<INDEXHOST>:<INDEXPORT> backup <BACKUPZIELPFAD>
To stop a currently running backup, the following command line can be used:
mescontrol http://<INDEXHOST>:<INDEXPORT> stopbackup
Enabling Support Mode
Activating “Advanced Settings” checkbox also shows the “Support Mode” section beneath the service configuration sections on the “Indices”, “Filter”, as well as “Client Services” tabs. Support mode traces detail information about the individual services into log files defaulting to the Mindbreeze service user’s TEMP directory on Windows and to /var/opt/mindbreeze/log directory on Linux platforms. Custom log directories can be configured in the “Log Location” section below.
Note: Do not keep support mode activated in “normal” operation to avoid decreasing the performance when not needed anymore. If in doubt, keep it disabled.
To persist changes click on the “Save” button on the top right corner.
Sub Query Expression
Sub Query Expression enables reference evaluation inside of metadata. This allows, for example, searching all the files inside a folder, or vice versa, the folder in which a file is located. This can be applied for all Metadata Keys, which point to another document. The reverse direction can also be enabled by adding the metadata keys to the field Inverted Reference Metadata Keys. In addition to forward and reverse references, string and reverse string references (via property expression lookup and rev_lookup) can be used.
Tokenizer Configuration
The options in „Tokenizer Configuration“are used to change the behavior of substring matches for search results

NGrams for Non-Whitespace Separated Tokens Zone Pattern | This option is used to define a Regular Expression (RegEx) for all the Metadata Names for which non-whitespace separated NGRams are to be created. An empty field will disable the feature. Example: (search term list is incomplete) |
When enabled, search queries with separators and special characters provide more precise search results. This makes it easier to find documents with e.g. file numbers, invoice numbers or business references. Documents containing the search term - but without the separators and special characters - will then no longer be displayed. Example: Search for ISBN 978-0201100884 If Match non Whitespace Suffix Stop Characters: - Enabled: Finds only documents that contain ISBN and 978-0201100884. - Disabled: Also finds documents that contain ISBN, 978, and 0201100884. Note: For this setting to take effect, the setting Non Whitespace Stop Characters inverted must also be enabled. Please note that already existing indices must be re-inverted if you enable Non Whitespace Stop Characters inverted; see below for details. | |
Non Whitespace Stop Characters inverted | Must be enabled if Match non Whitespace Suffix Stop Characters is enabled. If Match non Whitespace Suffix Stop Characters is not enabled, then this setting has no effect on the search. Note: Please note that a re-inversion is required for changes to this setting to take effect. If you have an existing index with Mindbreeze InSpire version 22.3 or older and choose to update to version >= 23.1, this index must also be re-inverted for the feature to take effect. |
Minimum Length of Prefix NGram | Sets the minimum length of prefix NGrams (or infix NGrams in the title) that are used for the search. |
Maximum Length of Prefix NGram | Sets the maximum length of prefix NGrams (or infix NGrams in the title) that are used for the search. |
Minimum Characters in a Word | Sets the minimum length of words. Longer words are not distinguished by the search. |
Maximum Characters in a Word | Sets the maximum length of words. Longer words are not distinguished by the search. |
Maximum Count of Non-Whitespace Tokens | This option is used to limit a number of non-whitespace separated tokens. |
Memory Analysis Settings
Memory Test Allocation size in Bytes | This option can be used to test how long an allocation of a certain memory size takes on your JVM. The result is located in the log directory of the index within the log file memory-usage.csv. |
Statistcs Calculation Frequency | Here you can specify the time interval at which the results of the "Memory Test Allocation size in Bytes" and "Enable JVM Statistics" options are to be calculated. (in seconds) |
Enable JVM Statistics | If this option is enabled, the JVM statistics are written to the log file memory-usage.csv in the log directory of the index. |
Enable Core Dumps | If this option is enabled, core dumps are written to a file in case the index crashes. The file is located in the log directory of the index. |
Transaction System Settings
The options in this group can be used for index transactions subsystem fine-tuning.
Disable OOM-Killer On Checkpoint | This option option allows to temporarily disable built-in Linux OOM-Killer functionality at transaction checkpoint steps to avoid the index process being killed in case of out of memory conditions. |
Maximum Cache Size in MB | This option is used to change the cache size default value. |
Maximum Number of Groupcommit Participants | can be used to limit the number of group commit participants, that is number of cores / 4 by default. The option has effect only when “Enable Core Based Groupcommit Strategy” option is enabled. |
Optional Terms
Using the “Optional Terms”, finding documents can be simplified by providing results in which not all search terms necessarily have to occur. To make this transparent for the user, a note is displayed with the search result. This feature is active by default, but can be parameterised or completely deactivated.
It is important to note here that some options in the Global Index, Local Index and Client Service/UI of the Relevance section in the MMC configuration areas have the same name or functionality, but some options override/dominate the others.
In principle, the following mightiness applies (first is least dominant, last is most dominant):
Global Index < Local Index < Client Service/UI of the Relevance section in the MMC
Example:
Global Index: Optional Terms = activated
Local Index: Optional Terms = activated
MMC: Optional Terms = deactivated
In total: Optional Terms = deactivated
Further Example:
Global Index: Optional Terms = deactivated
Local Index: Optional Terms = deactivated
Client Service: Optional Terms = activated
In total: Optional Terms = activated
Area: Global Query Settings | |
Optional Terms Ratio | If this option is activated, the ratio of the terms can also be specified or how many terms can be omitted. Example: |
Term Boost Position Reduction Max | Maximum value by which the boosting of a term can be reduced. Example: |
Term Boost Position Reduction Step | Step size by which each following value is reduced. Example with 0.1 and "Term Boost Position Reduction Max"=0.2 and search input of "My name is John" results in the following term boosting: |
Disable Term Boost Position Reduction | If this option is checked, “Term Boost Position Reduction Max” and “Term Boost Position Reduction Step” are deactivated. |
Default Restricted Categories for Did You Mean | "Did You Mean" suggestions are calculated only from the categories specified here. If empty, all documents from all categories are included. Separate the categories with line breaks or semicolons. E.g.: Web;Microsoft File |
Area: Term Boost Relative to Position in Query | |
Enable Unparsed Term Series to Terms Transformer | If activated, this option enables legacy terms to be transformed into terms. This allows you to enter only a series of terms in the search line as before and the search still uses the Optional Terms. This is a requirement for the "Optional Terms" feature and is enabled by default. If you have older query transformation plugins installed and experience problems with the search, we recommend updating the plugins. If this is not possible, you can disable this setting. This should make older query transformation plugins work again. |
Optional Terms Ratio | See “Optional Terms Ratio” in Global Query Settings. |
Term Boost Position Reduction Max | See “Term Boost Position Reduction Max” in Global Query Settings. |
Term Boost Position Reduction Step | See “Term Boost Position Reduction Step” in Global Query Settings. |
Disable Term Boost Position Reduction | See “Disable Term Boost Position Reduction” in Global Query Settings. |
Area: Query Settings | |
Show Missing Terms in Results | If this option is activated, the missing terms or the terms to be added are also displayed in the search result by means of a note. |
Optional Terms Ratio | See “Optional Terms Ratio” in Term Boost Relative to Position in Query. Note: If this option is deactivated (set to 0), the options "Terms Position Boost Maximum Reduction" and "Terms Position Boost Step Size Reduction" in MMC Relevance (here) are also deactivated. |
Compound Splitting
With the help of compound splitting, individual words composed of several words can be recognized and separated accordingly, so that partial words are also sufficient for the search query to find more complex words.
Example: In order to also find documents that e.g. also contain "recognition", "forbestechcouncil" etc. in the results, the following can be entered in the search input:
AI cognition techcouncil
Notes:
- The prerequisite for the compound splitting is the activation of the "Enable Language Detection" option, which activates the automatic language detection of the documents. Currently, the languages DE and EN are supported for the Compound Splitting functionality. More supportable languages will follow soon.
- The Compound Splitting functionality applies only to newly added documents. To apply the functionality to already existing documents, a full re-inversion of the index is necessary. A description of how to do this can be found here.
- The Compound Splitting function is enabled by default and the following options are available for the respective local indices as well as Global. For a more detailed description, please refer to the "Compound Splitting Strategy" option below.
Area: Compound Splitting | |||||||||||||
Compound Splitting Strategy | With this option you can switch off the compound splitting function or determine a strategy. You can choose between 6 options:
| ||||||||||||
Path to Custom Compound Splitting Models Directory | Here you can specify the directory path (within your local machine) of custom models. Naming convention should be followed, see Appendix G for details. | ||||||||||||
Disable Compound Splitting for Languages matching | Here you can specify which languages should not be considered for Compound Splitting. | ||||||||||||
Enable Compound Splitting for Languages matching | Here you can specify which languages should be considered for Compound Splitting. | ||||||||||||
[Deprecated] Compound Splitting Vocabulary Path | Deprecated –> Should not be used anymore. Here a .csv file (within your local machine) of custom models can be determined. | ||||||||||||
Area: Query Settings | |
Disable Subword Highlighting | If active, the highlighting (in the sample text / preview) of terms that were found via compound splitting is deactivated. Activating this setting can help to improve search performance. |
Note: For Windows users, you need to install additionally: MESExtensionsSetup.exe
Named Entity Recognition (NER)
Named Entity Recognition can be used to identify and classify named entities in both the content and metadata of a document based on AI-based language detection and subsequent sentence segmentation.
Currently, the following named entities are supported, which are already pre-trained and can be adapted and extended in the further course (e.g. by tools).
- Persons (entity:person)
- Locations (entity:location)
- Organizations (entity:organization)
- Numeric values (entity:number)
Example: To find all documents by people that occur near the words "head", "academy" and "mindbreeze", the following can be entered in the search input.
entity:person:ALL NEAR head NEAR academy NEAR mindbreeze
Notes:
- The prerequisite for NER is the activation of the "Enable Language Detection" option, which activates the automatic language detection of the documents. Currently, the languages DE and EN are supported for the NER functionality. In the future, more languages will be supported.
- The composite decomposition functionality applies only to newly added documents. To apply the functionality to already existing documents, a full re-inversion of the index is necessary. A description of how to do this can be found here.
- The NER functionality is disabled by default and the following options are available for the respective local indices as well as Global. For a more detailed description, please refer to the "Compound Splitting Strategy" option below.
A description of how to customize Insight Apps (e.g. for different entity colours) ca be found here and here.
Enable Language Detection | Here you can determine whether the automatic language detection should be activated or not. (Enabled by default) Note: This option is required for the Compound Splitting and NER features. If no language is detected for a document, those two features cannot be applied to that document. The automatic language detection is built into the index, in contrast to the LanguageDetector ItemTransformer plugin, so that the plugin is not needed anymore. | ||||||||||||
Language Detection Min Text Bytes | This option allows you to specify the minimum amount of text in a document above which automatic language detection should be performed. If the specified amount of text (in bytes) is less than the amount of text in the document (in bytes), the automatic language detection will not be performed for that document. | ||||||||||||
Language Detection Max Text Bytes | The specified amount of text (in bytes) corresponds to the maximum amount of text that is considered for automatic language detection, starting from the beginning of the document. The amount of text in the document that exceeds these limits is not relevant for language recognition. | ||||||||||||
Model based NER Extraction | With this option you can switch off the NER function or determine a strategy. You can choose between 6 options:
| ||||||||||||
Path to Custom NER Resources Directory | Here you can specify the directory path (within your local machine) of custom models and catalogs. It is necessary to follow the directory structure and naming convention detailed in Appendix G. | ||||||||||||
Min Words Per Sentence | Specifies the minimum number of words per sentence required for NER evaluation. If a sentence consists of fewer words than specified in this option, then the entire sentence discarded from NER processing. Default value is 5. | ||||||||||||
Max Words Per Sentence | Defines the maximum number of words per sentence for which NER evaluation is performed. If a sentence consists of more words than specified for this option, then the entire sentence Is discarded from NER processing. Default value is 30. | ||||||||||||
Minimum Probability For NER Tags | This parameter influences the number of false positives and tweaks the NER results overall. An individual probability value (floating point number between 0 and 1) is calculated for each calculated tag. If the probability for the calculated tag is smaller than the value specified in this parameter, the tag is discarded and not processed. Therefore, small probability values will display more tags and large probability values will display fewer tags. Default value is 0.5. | ||||||||||||
Restricted Zones Pattern | A regex pattern for document zones to be processed for NER. For example, if this pattern is set to “title|content”, only text in the zones “content” and “title” will be processed for NER. Text in other zones will be ignored. When left empty, all ER zones will be processed for NER. Note: This option can also be used to restrict the processing of metadata by the Sentence Transformer. You can find more information about this in Whitepaper – Natural Language Question Answering (NLQA) – Configuration: Sentence Transformation. | ||||||||||||
Enable NER Highlighting | When enabled, NER-tagged words are highlighted in the search. The Highlighting is only visible if the Client Service parameters “Mark All Entity Types”, or “Mark Entity Types” are configured. See . | ||||||||||||
NER Entity Catalog Filters Strategy | If this setting is enabled, an additional catalog-based filtering is added to the semantic pipeline to help remove false positives. This setting causes words with NER Tags to be removed, unless these words exist in the respective entity catalog. For example, if the word “ABCD” is marked as an NER Tag of type ‘Person’, but no entry “ABCD” is present in the Person-catalogs, then the entity tag will be removed from this word.
| ||||||||||||
When this setting is enabled, additional catalog-based filtering is added to the semantic pipeline to remove false positives, similar to the NER Enitity Catalog Filters Strategy option. This setting causes words with NER tags to be removed if those words are present in the corresponding stop word catalog. Another difference from the NER Enitity Catalog Filters Strategy option is that the stop word catalogs are not entity-dependent, but instead depend on the language of the document. | |||||||||||||
NER Entity Catalog Filter Minimum Matched Words Ratio | This parameter influences the effect of the catalog filters, especially for multi-word entities. This parameter specifies the minimum required ratio (between 0 and 1) of characters that need to match with existing words in the Catalog Filter and total recognized words so that an entity is not discarded. This is particularly relevant for multi-word entities. For example, a string like “Dr. Albert Einstein” could be detected as a multi-word entity. The word “Dr.” does not exist as a person name in the predefined Mindbreeze Catalog, so the resulting ratio of matching words is less than 1. If this setting is set to 1, then the string “Dr. Albert Einstein” will not be tagged as a person entity. Lowering the value of this parameter makes the filter more tolerant, but carries the risk of producing more false positives. | ||||||||||||
NER Stop Word Catalog Filter Maximum Matched Words Ratio | Similar to the “NER Entity Catalog Filter Minimum Matched Words Ratio” option, this parameter influences the effect of catalog filters on multiword entities. If the ratio of the number of characters of the recognized stop words of a multiword entity is greater than the value defined here, the entity marker is removed. | ||||||||||||
Enable Inversion of Text Region Entity Annotations | If this box is checked, custom entity annotations added by the end user can also be reinverted and searched. The custom entity annotations can be highlighted in the same way as the extracted entities using NER (see “Enable NER Highlighting”).They can also be searched like other NER tags, for example using a search-query like: Note: See Hierarchical CSV Enricher for how to add custom entity annotations. | ||||||||||||
Included Text Region Entity Annotation Label Patterns for Inversion | Regex pattern of user-defined entity annotation names to be considered during reinversion, separated by a new line. Leave this setting empty to include all custom entity annotations. | ||||||||||||
Note: For Windows users, you need to additionally install: MESExtensionsSetup.exe .
Named Entity Recognition (Client Service)
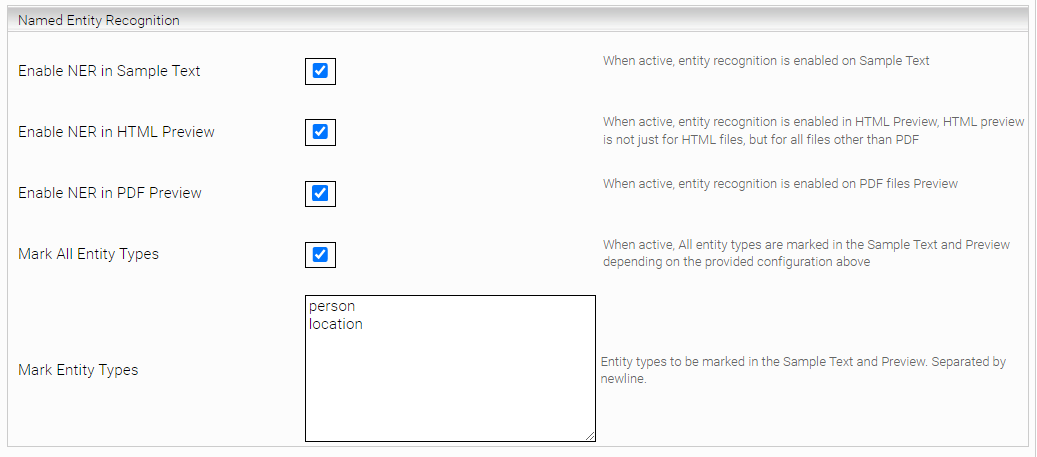
Area: Named entity recognition | |
Enable NER in Sample Text | When active, entity recognition highlighting is enabled for the Sample Text |
Enable NER in HTML Preview | When active, entity recognition highlighting is enabled for the HTML Preview, this affects all document types other than PDF |
Enable NER in PDF Preview | When active, entity recognition highlighting is enabled for the PDF Preview |
Mark All Entity Types | When enabled, all words that have a tagged entity will be highlighted, regardless of their entity type. When disabled, only entity names specified in Mark Entity Types will be marked. |
Mark Entity Types | In this setting, you can specify which Entity types are to be highlighted in the sample text and preview. (newline separated). The prebuilt NER model currently supports the following entities: “person”, ”location” and “organization”. If Mark All Entity types is not checked, only entity types in this text field will be highlighted. If Mark All Entity Types is not checked and Mark Entity Types is left empty, then no highlighting is performed. |
Sentence Transformation
This section describes all the Sentence Transformation configuration options. These settings relate to „Natural Language Question Answering“ (in short: NLQA). Please read the Whitepaper – Natural Language Question Answering (NLQA) first.
Area: Semantic Text Extraction | ||||||||||||||||
Maximum Transformed JSON Rules Cache | Maximum of Transformed JSON Rules saved in Cache, Default is 20. Transformed JSON Rules, send on Document Insertion on metadatum "mes:itemtransformationrulesjson". | |||||||||||||||
Enable this option to enable sentence transformation (is required to enable NLQA). To fully enable NLQA, additional settings must be made, see Whitepaper – Natural Language Question Answering (NLQA) - Configuration | ||||||||||||||||
Sentence Transformers Model ID Setting | Sentence transformer model used for NLQA.
| |||||||||||||||
Path to Custom Sentence Transformers Model | Defines the path to a custom Sentence Transformer model. Is only effective if either "Custom" or "Default" is selected in "Sentence Transformers Model ID Setting". If you would like to use a custom model for your data science project, please contact support@mindbreeze.com. | |||||||||||||||
Path to Custom Sentence Transformers Pooling Model | By default, a Sentence Transformers Pooling model is not used. If you would like to use this for your data science project, please contact support@mindbreeze.com. | |||||||||||||||
Sentence Transformer Max Batches | Can be configured to reduce the indexing time for documents processed by the Sentence Transformer. Blank: No restriction on the number of sentences to be processed. | |||||||||||||||
Sentence Transformer Restrict to Language Pattern | Regex Pattern to restrict documents based on the recognized document language for processing by the Sentence Transformer. If this option is left empty, all documents will be processed regardless of the recognized document language. Default value: empty Attention: The restriction of the Sentence Transformer is only possible with language codes in accordance with ISO 639-1. | |||||||||||||||
Vector Index Merge Service Maximum Runs | Can be configured to limit the number of vector index files. Note: Changes to this setting may affect performance | |||||||||||||||

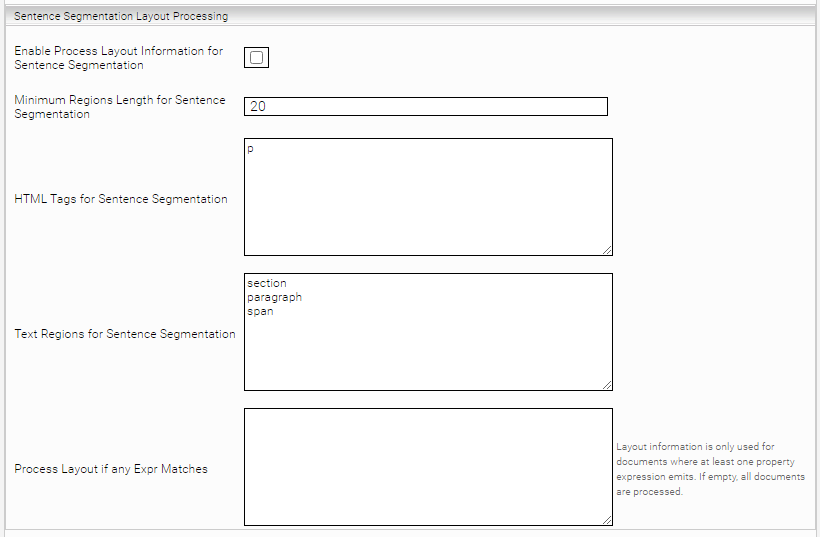
Area: Sentence Segmentation Layout Processing | |
Enable Process Layout Information for Sentence Segmentation | If enabled, layout information (annotations) of the document is considered during sentence segmentation. The segmented sentences form the basis for calculating the vectors of the Sentence Transformer, which enables "Natural Language Question Answering" (NLQA). Default setting: Disabled. |
Minimum Regions Length for Sentence Segmentation | The minimum length for a region to be considered during sentence segmentation. This helps to highlight relevant information in a better way. Default value: 20. |
HTML Tags for Sentence Segmentation | HTML annotations (= HTML Tags) that are considered during sentence segmentation. Default value: |
Text Regions for Sentence Segmentation | Regions annotations that are considered during sentence segmentation. Default value: |
Process Layout if any Expr Matches | Multiple Mindbreeze Property Expressions can be configured here, separated by newline. Attention: Only property expressions that are available at the time of inversion can be used. Layout information is only considered for documents where at least one property expression emits something. For other documents, sentence segmentation is done without considering any layout information. If empty, layout information is considered for all documents. Default value: empty. |
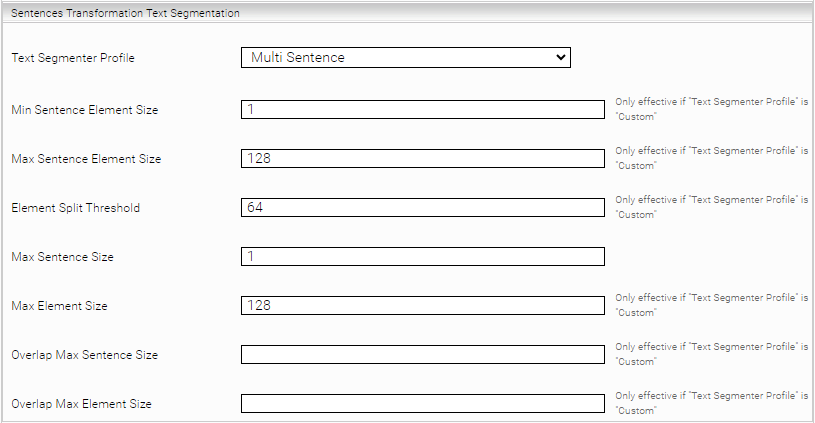
Section: Sentences Transformation Text Segmentation | |||||||||
Text Segmenter Profile | The text segmentation can be controlled via profiles. The segmented text sections form the basis for calculating the vectors of the Sentence Transformer, which enables "Natural Language Question Answering" (NLQA).
| ||||||||
Min Sentence Element Size | Minimum number of elements for a text segment to be counted as a sentence. Note: an "element" is usually a word | ||||||||
Max Sentence Element Size | Maximum number of elements before a text segment is counted as more than one sentence. | ||||||||
Element Split Threshold | If the current text segment including the current sentence is longer than Max Element Size, this option is used to configure at which point the current sentence is split and it is also ensured that the second part of the sentence is not too small. In the latter case, the entire sentence is still included to ensure that the context is preserved. | ||||||||
Max Sentence Size | Maximum number of sentences that a text segment may contain. | ||||||||
Max Element Size | Maximum number of elements that a text segment may contain. | ||||||||
Overlap Max Sentence Size | Maximum number of sentences that are overlapped when calculating the text segments | ||||||||
Overlap Max Element Size | Maximum number of elements that are overlapped when calculating the text segments | ||||||||
Large Text Segment Max Size | Maximum number of segments to be used for large text segments. | ||||||||
Large Text Segment Overlap Size | Number of overlap segments to be used for large segments. | ||||||||
Large Text Segment Min Size | Minimum number of segments to be used for large segments. | ||||||||
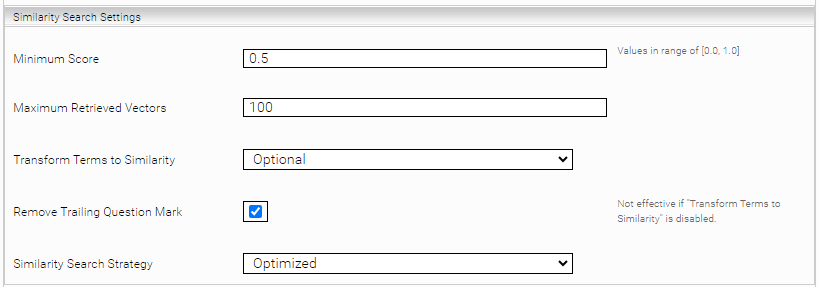
Area: Similarity Search Settings | |||||||||
Minimum Score | Only answers with at least the score configured here will be delivered during the search. Valid values for this option: 0.0 to 1.0 Default value: 0.5 | ||||||||
Maximum Retrieved Vectors | The maximum number of best vectors that are queried first in a Similarity Search before being processed further. Default value: empty (uses the value from the global settings) Note: This setting overrides the global configuration value. | ||||||||
Transform Terms to Similarity | If active, terms_expr are automatically converted to similarity_expr. Thus, a normal unparsed_expr search (e.g. a search with the standard Insight App) will automatically perform a similarity search. Please note that "Enable Unparsed Term Series to Terms Transformer" must also be enabled (default: enabled). Default setting: Optional.
| ||||||||
Remove Trailing Question Mark | If active, the question mark at the end of the query is removed, if present. Only effective if Transform Terms to Similarity is activated (Enabled or Option). Note: With the standard Sentence Transformer model, this option (if active) leads to better results on average. Default value: Enabled | ||||||||
Similarity Search Strategy | The search strategy for the Similarity Search. Changing the default setting can lead to performance degradation and should not be changed under normal circumstances.
| ||||||||
Maximum Retrieved Vectors | The maximum number of best vectors that are queried first in a Similarity Search before being processed further. Default value: 100 |

Area: Similarity Search Settings | |
Answer Count | The maximum number of responses that can be returned with a single request. |
Minimum Score | Only answers with at least the score configured here will be delivered during the search. Valid values for this option: 0.0 to 1.0 Note: This option overrides the Minimum Score index option. If Minimum Score is not configured in the Client Services options, Minimum Score from the Indices options is used. |

Storage Settings
Section: Storage Settings | |
Block Storage Requests on Sync | There is a short time window (during sync) in which no filter/index requests can be processed. The requests are then answered with http status code 503. If this option is enabled, these requests are blocked until they can be processed. |

Stop Word Catalogs Settings
Stop word catalogs can be used to skip stop words in some usecases, such as highlighting.
Section: Stop Word Catalogs Settings | |||||||||||||
Stop Word Catalogs Strategy | With this option you can determine the Stop Word Catalogs to be loaded or disable stop words entirely. You can choose between the following options:
| ||||||||||||
Path to Custom Stop Words Catalogs Directory | Here you can specify the directory path (within your local machine) of custom models and catalogs. It is necessary to follow the directory structure and naming convention detailed in Appendix G . | ||||||||||||
Exclude Stop Words from Highlighting | When this option is enabled, Stop Words are excluded from Highlighting. | ||||||||||||
Exclude Stop Words from Term Lexicons | If this option is enabled, stop words will not be included in the term lexica. Please note that a full re-inversion is required after changing this option. If this option is enabled and the underlying stop word catalogue is changed, a full re-inversion is also required. | ||||||||||||
Text Cleaning
The “Text Cleaning” Feature enables the removal characters belonging to special Unicode categories from the Sample Text and HTML preview. This option is disabled by default.

Data Sources
To create data sources for a particular index, click one of the icons at the top right of the “Data Sources” section. These icons represent the different data sources integrated into the Mindbreeze InSpire software.

Custom data source
A custom data source makes it possible to use the Mindbreeze InSpire Client to search data sources integrated by a third party.
These connectors can be installed from the Mindbreeze Management Center (also see Configuration – Plugin Installation).
Look for detailed installation instructions in the documentation provided with the data source.
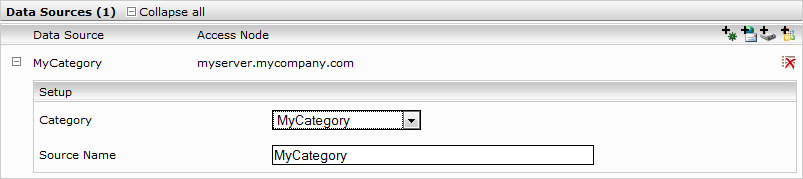
To create a custom data source proceed as follows:
- Click the
 symbol. A configuration form for custom data sources will be displayed.
symbol. A configuration form for custom data sources will be displayed. - In the “Source name” field, assign an appropriate name for this data source.
- In the “Category” field, choose the registered data category corresponding to the data source being set up.

Click the ”Save“ button in the top-right corner to save your settings.
You will find further information on how to register a new custom data source with Mindbreeze InSpire and how to configure its indexing in the documentation of the Mindbreeze connector delivered by the third party.
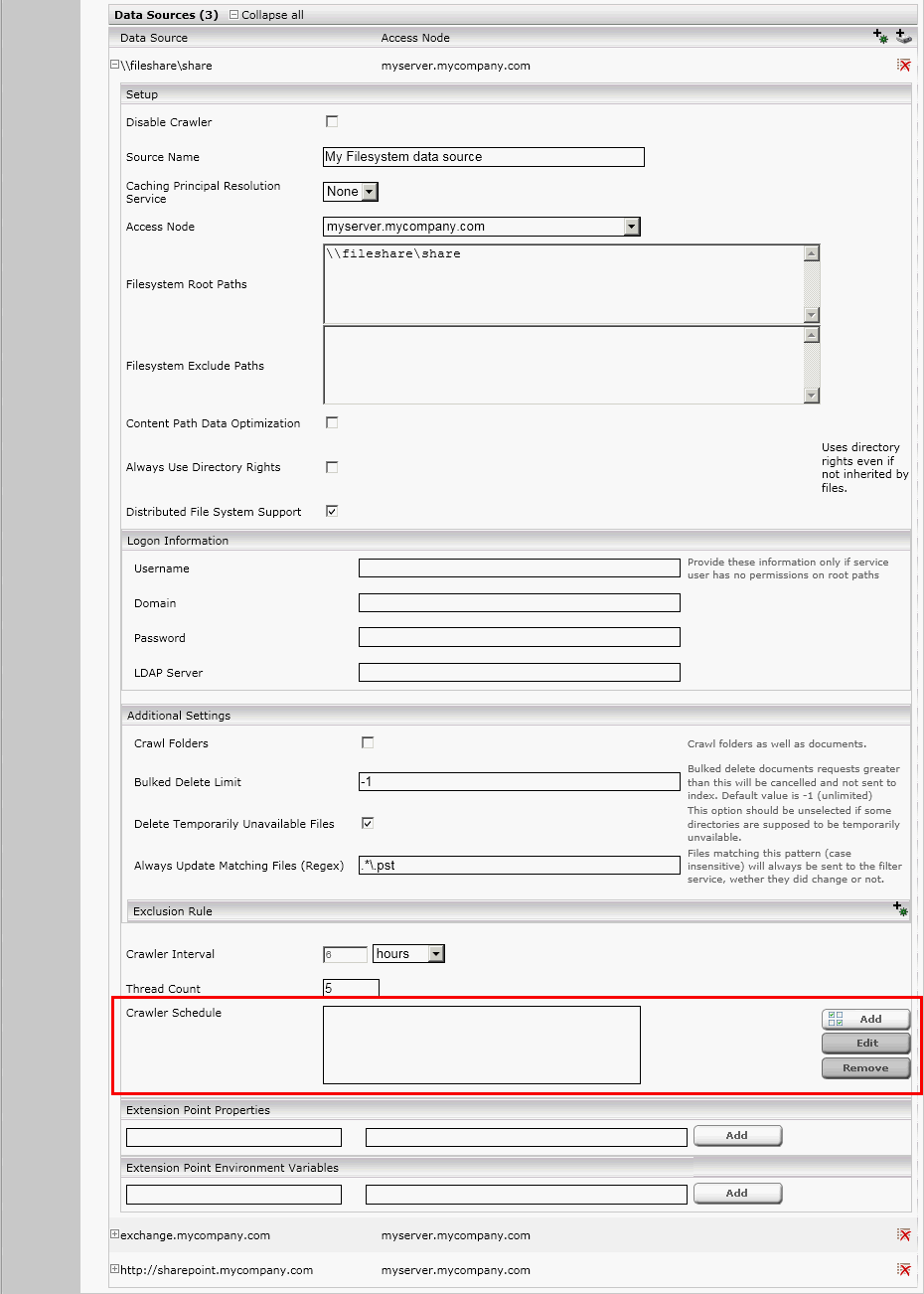
Crawler Scheduling
It is possible to apply one or more user defined time spans for the crawlers to run at. To set up this feature, go to the “Index” tab of your Mindbreeze InSpire Management Web Interface and enable the advanced mode by clicking on the check box at the top right corner of the page. After clicking on this check box some more user controls should appear on the screen, including one called “Crawler Schedule”. This section provides an overview over the already configured time spans that define when the current crawler should run. To add a new entry, simply click the “Add” button and enter the desired time span. To change an already existing time span, select it in the list and then click the “Edit” button. To remove one of the entries, simply select it in the list and then click the “Remove” button.
After clicking the “Add” button, the following screen will appear:

Here you can enter the time interval when the crawler should run. Please use a 24 h time format for your input. After entering your time span you can either click “Apply” to save your changes or “Cancel” to discard them.
Click the “Save” button at the top right of the screen to save your changes and make them take effect.

Filter- and Index performance optimization
Under "Advanced Settings" in the "Performance Settings" section, the option "Concurrent Filter and Index Dispatch Threads" allows you to define the number of threads that download documents in parallel and send them to the filter and index service. With a higher value (e.g. 20) you can optimize the performance, but this also increases the load on the filter and index service.
Default value: 10.

Extension Point Properties and Environment Variables
For every data source, "Extension Point Properties" and "Extension Point Environment Variables" can be defined. These settings are not relevant for you and are for internal use only.
Customizing the category descriptor
The category descriptor specifies the display options and the filter information of a data source and is an XML document stored in the plugin (typically categoryDescriptor.xml; the name is referenced via plugins.xml). The root element is the “category” element.
<?xml version="1.0" encoding="UTF-8"?>
<category id="Category" supportsPublic="false" keep-docinfo-metadata="false">
<name>Category</name>
</category>
Attributes in the “category” element are:
- supportsPublic: specifies whether the data source may be configured in a public index. The default value is false.
- keep-docinfo-metadata: defines whether metadata with aggregatable or regexmatchable attributes will be retained or overwritten by an updated descriptor. The default value is false.
Adding custom metadata columns
A metadata definition could look like this:
<metadata>
<metadatum aggregatable="true" id="current_state" visible="true">
<name xml:lang="en">Ticket State</name>
<name xml:lang="de">Ticket Status</name>
</metadatum>
</metadata>
The following attributes can be defined in the metadatum element and are used to control the metadata in the index:
- aggregatable: If this option is set to true, the column will be available as a filter (should only be defined for properties for which the values allow a grouping of the results – the aggregatable option doesn’t make sense for unique values, which can only occur once in the search result.
- regexmatchable: specifies whether the search for these metadata can be performed with a regular expression.
- visible: specifies whether the column is displayed in the default result presentation.
Replacing the hit icons
The small icon in the data source list of the search client is defined in the file “categoryIcon.png” in the ZIP archive of the data source plugin. You can replace the icon with a 16x16 icon of your choice.
You can also define an icon with the icon tag directly in categoryDescriptor.xml. This requires a unique ID, size attributes (height and width) and the picture itself (value), encoded as Base64 value.
<context>
<Icon alt="Ticket" height="16" width="16"
id="tag:mindbreeze.com,2007/contextitems/contexticon;ticket"
mimetype="image/png"
type="tag:mindbreeze.com,2007/contextitems/contexticon"
value="
iVBORw0KGgoAAAANSUhEUgAAABAAAAAQCAYAAAAf8/9hAAAABmJLR0QA/wD/AP+gvaeTAAAACXBIWXMAAAsTA AALEwEAmpwYAAAAB3RJTUUH3wIXECgw/xAFagAAAS1JREFUOMvFkz1uwkAUhL/nNV4Zesw9wgUILYq4gymCgCiRIG3gCkAOEnMFTgMNFT8W65cCpOAIAqmY8knzaTQ7C/eWvA8Gpd1uN3HOPQFyo0+NMYm1tkcrjmuzJNH/apYk2orjmu+c88tRxHq91tVqJSJ/hBBhu9kQRZGWo0icc74PoFmGqspkPMZae9G/3W55brdJ01Q0ywA4AIAgCPgYDi+agyAAYL/fIyLo8e4fKlEKhQKf0+nZBM45ur1eDoTqCeCo17e36/WrctpTDtDtdAjD8KzROUej0eCxXs/dc4DhaJSjh2FIsVi8nkA8D0Dn87kU/B9mpVLhoVr99ZICoOJ5AuAbY/bLxQJAms3mzQteLhYYY5wM+v1SmqbT45S5ecqe9xVY+3L3z8g3o1Sele9r3SQAAAAASUVORK5CYII= " />
</context>
Adding user-defined hit actions
You can add user-defined actions based on specific metadata, for instance, in order to open a ticket search result in a custom ticket web application.
<context>
<Menu>
<Action name="Open" pattern="http://intranet.mycompany.com/ticketing/show.html?ticketid={{mes:key}}">
<name xml:lang="en">Open Ticket</name>
<name xml:lang="de">Ticket Öffnen</name>
</Action>
</Menu>
</context>
For the changes to take effect, you can upload the ZIP archive plugin with the modified categoryDescriptor.xml via the Mindbreeze configuration interface.
Note: We recommend renaming modified plugins with a separate name to better detect changes in product updates.
Limitations
The usage of the same category descriptor in two custom plugins simultaneously is not supported. In that case the deployment order during a snapshot is not defined.
app.telmetry configuration for Crawl Runs
The crawl run information can be stored in a separate LogPool.
To do this, the Fabasoft app.telemetry log definitions for Mindbreeze Services must be downloaded from the Mindbreeze configuration interface. Select the "Overview" tab and click on the link "Fabasoft app.telemetry log definitions and Dashboards".

Then create a new log pool with the following settings:
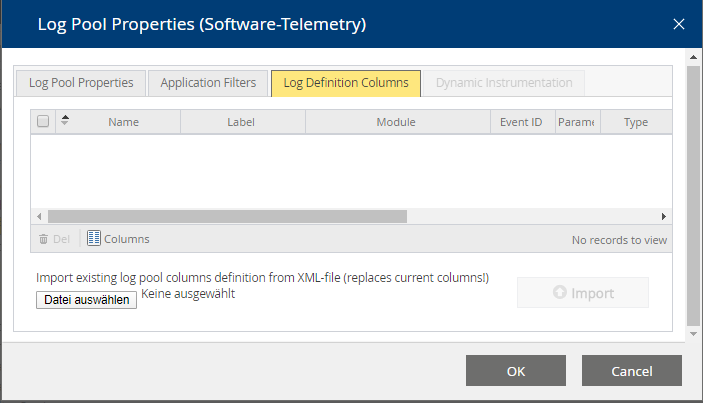

Application: Mindbreeze
Application ID: *
Application Tier: Crawler Service Run
Tier ID: *
In the tab "Log Definition Columns" the xml file: apptelemetrylogdefinitions_crawlerservicerun.xml must be uploaded from the log definition archive.

“Filters“ tab
On the “Filters“ tab, all Filter Services can be managed. In the “Filter Services” box, the available Filter Services are shown. Using the “Add new filter“ button (the plus icon, located toward the top right-hand side) additional Filter Services can be defined.
To create a new Filter Service, perform the following steps:
- Click the plus icon () located at the top right-hand side.
- Edit the properties of the Filter Service.
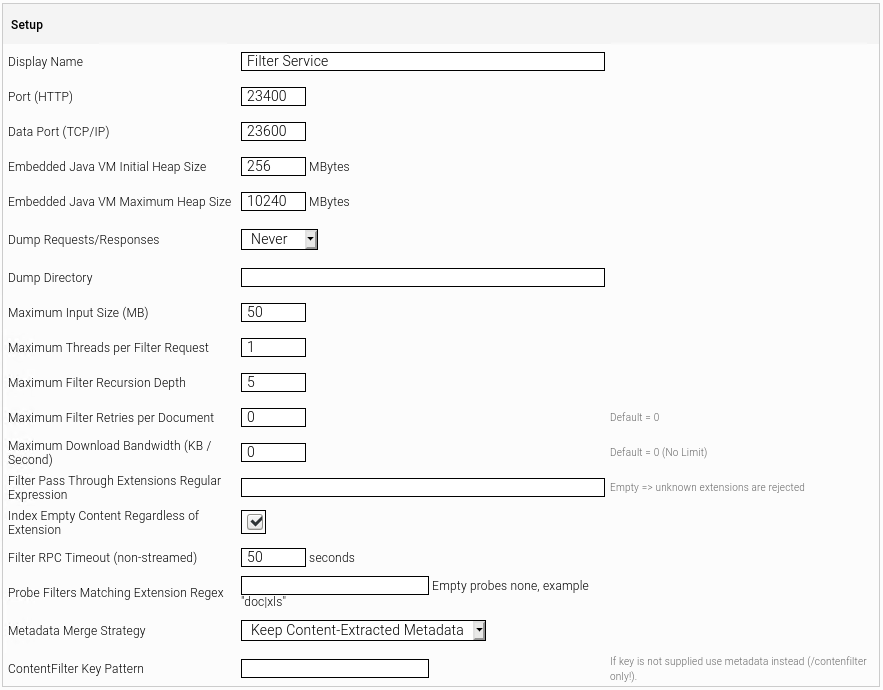
- In the “Setup” box, the “Display Name” field is available by default. A name for the Filter Service can be specified in this field.
- In the “Node” field, the servers on which the Filter Service will be run can be selected.
To configure a Filter Service in more detail, perform the following steps:
- Select “Advanced settings” to display the file extensions that the Filter Service will filter. Available Filters are displayed as well as the filters provided by Mindbreeze InSpire
- If Java filters need more memory increase “Embedded Java VM Maximum Heap Size”.
- To analyze problems with Filters activate “Dump Requests/Responses” and select a directory to store the dumps with the option “Dump Directory”.
- If you want to filter Documents that are bigger than 50 MB increase „Maximal Input Size (MB)”.
- To accelerate filtering of ZIPs and PST-Files increase “Maximum Threads per Filter Request”.
- Configure a custom ”Filter Recursion Depth” to control the number of extracted objects from nested containers like ZIPs .
- Specify a Regular Expression for “Filter Pass Through Extensions Regular Expression” to specify extensions which are sent directly to the Index instead of filtering without contents.
If “Index Empty Content Regardless of Extension” is enabled, documents with empty content are always indexed regardless of extension and availability of matching Content Filter.
- To try all matching Plugins in case of errors in their relative order for a set of extensions, specify the extension as regular expression in the “Probe Filters Matching Extension Regex” field.
- In order to avoid overwriting data source metadata during content filtering select “Keep Datasource Metadata” form “Metadata Merge Strategy” dropdown box.
- Edit the “Filter Plugins” as required: files and documents will be filtered differently depending on their extension, you can adjust which extensions should be treated by which filter plugin from the filter service.
- Select “Ignore Heartbeat Error” to prevent Filter Service restart if it fails to send hearbeat to Node. This may happen in occasions when the system is very busy.
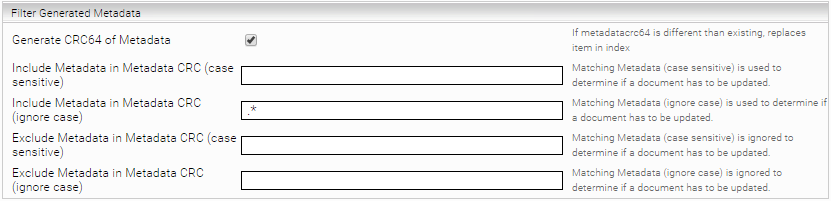
- Select “Generate CRC64 of Metadata“ to generate a CRC64 of the filtered metadata. If the CRC differs, the document will be replaced in the index if needed. Additional Regular Expression rules can be defined to include or exclude Metadata fields sent by the crawler.
- If the option „Generate CRC64 of Metadata“ is activated, the metadatacrc is additionally used to check whether an item should be replaced in the index.
- In the further options a "Regular Expression" can be specified to include or exclude metadata in the CRC.
Extracting additional PDF Meta Keys
The PDF-Filter extracts the following Meta Keys from PDF documents if they are available:
- document:title
- document:Author
- document:Subject
- document:Keywords
- document:Creator
- document:Producer
- document:CreationDate
- document:LastModified
- document:Trapped
- document:PageCount
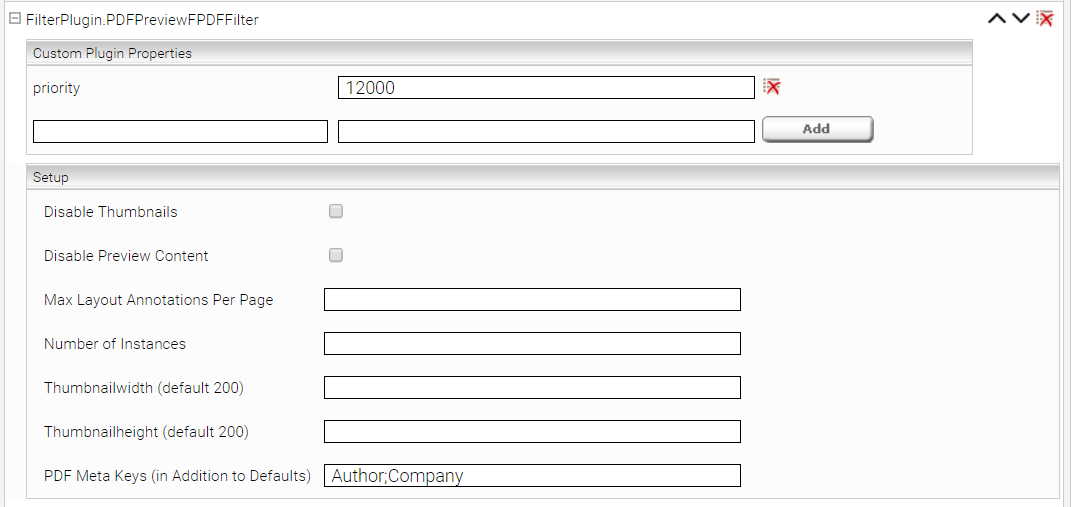
To extract additional Meta Keys add the plugin „FilterPlugin.PDFPreviewFPDFFilter“ to the „Global Filter Plugin Properties“ and configure the property „PDF Meta Keys“. Multiple values are separated via semicolon („;“):

Saving HTML meta tags as metadata
The HTML filter plugins Jericho and JerichoWithThumbnails extract the HTML meta tags as metadata values. If these HTML meta tags occur multiple times (with the same name and value), it is possible to save them only once as a metadata value.
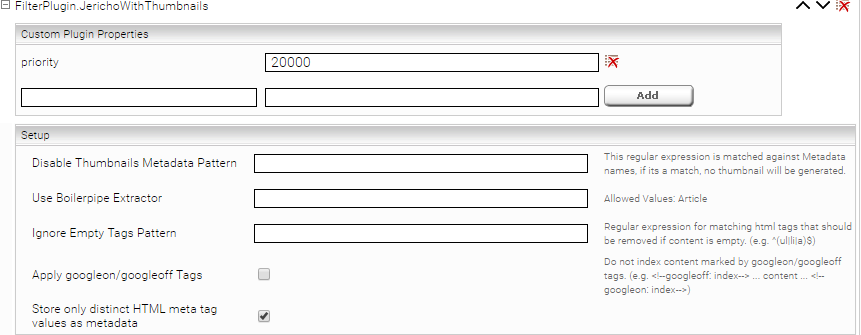
Add the plugin “FilterPlugin.JerichoWithThumbnails” or “FilterPlugin.Jericho” (if no HTML thumbnail generation is used) to the filter under “Global Filter Plugin Properties” and enable the property “Store only distinct HTML meta tag values as metadata”.
If a regular expression is defined here as "Parsable HTML meta tag pattern," only meta tags with matching "name" or "http-equiv" attributes are stored as metadata.
If Post Filter Transformation plugins are installed (f. ex. SignatureToKeyRewriter), the following section is additionally shown in the Filter Service configuration:

In the drop-down list the available Post Filter Transformation plugins can be selected. The selected plugins can be activated for the current Filter Service using the “Add” button besides.
The activated plugins are listed above. By clicking on the “expand” button (![]() ) of an active plugin, a “Plugin Properties” section will be visible. Here you can define properties for the current plugin instance in form of key-value pairs. With the corresponding “delete” button you can remove (
) of an active plugin, a “Plugin Properties” section will be visible. Here you can define properties for the current plugin instance in form of key-value pairs. With the corresponding “delete” button you can remove (![]() ) these custom properties.
) these custom properties.
By clicking on the delete button besides the active plugin name, the plugin will be removed from the list with all defined instance properties and will not be active for the current Filter service.
- To save the modifications, click “Save“. Modifications in the configuration are propagated to the appropriate server nodes.
- Switch to the “Overview“ tab-to get an overview of the mapping of services and server nodes.
Similar to the ”Indexes“ tab, the ”Filters“ tab offers the ability to enable the support mode.

Destination Pattern | This option defines a regular expression that applied to destinations in an Index Request header, e.g. |
Destination Replacement | This option is a replacement text with optional back references for the groups captured with the destination pattern, e.g. |
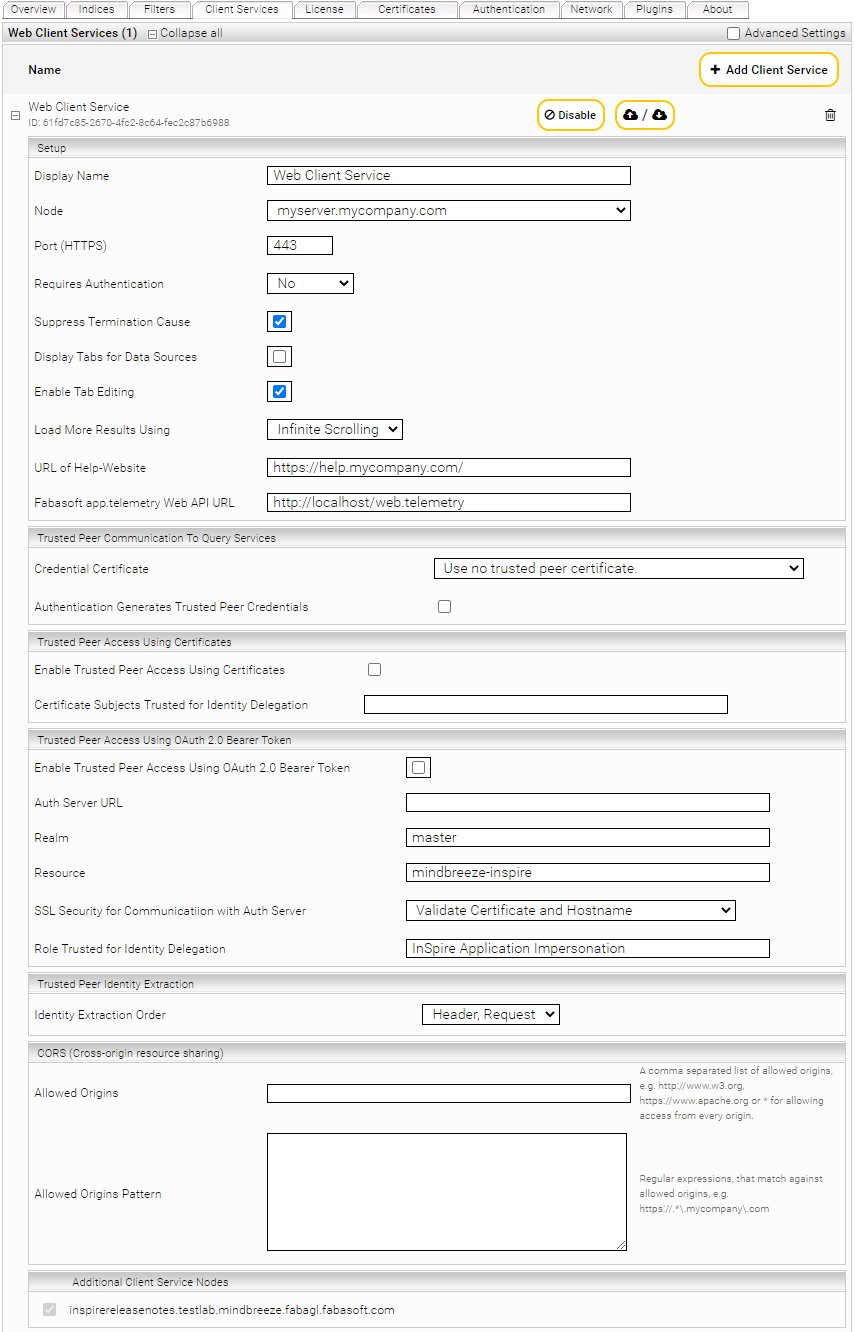
"Client Services" Tab
The ”Client Services“ tab is used to manage all client services. A client service provides the server-side support for the Mindbreeze InSpire Web Client. The field “Web Client Services” shows all existing web client services.

In order to create a new web client service, proceed as follows:
Click the plus symbol (![]() ) located at the top right-hand side.
) located at the top right-hand side.
Modify the settings of the new client service.
In the “Setup” field you can manage the settings “Display Name”, “Node”, “Port (HTTPS)”, “Requires Authentication” and URL of Help-Website. The following values can be defined using those fields:
Section: Setup | |
Display Name | This field can be used to assign an appropriate name to the client service. |
Node | This field defines the node on which the client service will run. |
Port (HTTPS) | This field determines under which TCP port the service will be made accessible. This port is used in the address of the Web Client e.g. “https://myserver.mycompany.com:23350/“. |
Bind Address (HTTPS) | Here you configure on which IP address the service is accessible. By default (value not set) the IP address 0.0.0.0 (all IP addresses) is used. If, for example, the service should only be accessible on localhost, the "Bind Address (HTTPS)" option must be set to the value 127.0.0.1. |
Data Port (TCP/IP) | Determines a TCP port for communication with subservices. |
Query Metrics Port(TCP/IP) | If a port is specified for Query Metrics, recording of Query statistics is enabled. The Port is used to control the Query Metrics recording. |
Requires Authentication | This field defines if the client service offers its resources to the public or only to local users. Should the data be made publicly available, the corresponding data sources must also be configured appropriately (“Advanced Settings”, “Unrestricted Public Access”). |
Suppress Termination Cause | If active not information is displayed on search timeouts. |
Display Tabs for Data Sources | If this option is enabled, the Web Client will show tabs for each activated data source. |
Enable Tab Editing | Tabs can be edited if this setting is enabled. |
Load More Results Using | With Infinite Scrolling more results are loaded automatically when scrolling. Pages activates the paging feature. The number of visible pages is configured with: Maximum Number of Displayed Pages. |
| Pages
|


URL of Help-Website | Here the URL of a Help Website can be entered. This site is then available as link in the Client Service. |
Fabasoft app.telemetry Web API URL | Here the URL of an app.telemetry Web API can be entered, to enable end-to-end software telemetry. |
Dump Requests | To analyse errors and problems, activate this option. |
Dump Directory | Is the directory for storing the "dumps". |
One Phase Search and Enrich | If this option is activated, the search and contextualisation of the results are performed in one query instead of the usual two. Activate this option if only a few query engines are used by the client service. |
Disable External Contextualization | If this option is activated, no external contextualization is performed during the search. This option can be overridden by the search request. Default setting: deactivated. |
Logout Redirect URL | Is the URL where the client gets redirected to after logging out |
User ID is E-Mail Address | If the displayed user name is a valid e-mail address, this can be used to specify that the e-mail address is automatically filled in the feedback dialogue. |
Disable Autocompletion of Query | Deactivates the auto-completion of the search term |
Mandatory Data Source Search In Constraints Resolution | Causes the “Search In Constraints” to be calculated for all data sources. Can be set in the category descriptor for each data source. |
Query Expansion for Diacritic Term Variants | Ist diese Option aktiviert, wird die Suche auf diakritischen Varianten des Suchwortes ausgeweitet. |
Use SSL (HTTPS) | If this option is enabled, the Client Service can be reached via https:// in the browser, while deselecting the option allows connecting using http://. The port setting of the Client Service is respected nonetheless. |
Supported TLS Protocols | This option allows you to configure the TLS protocols supported by the client service. Here you can specify a comma-separated list of JSSE protocol names. |
SSL Certificate | This field allows to select the SSL-Certificate that is used by the Client Service. By default the certificate that is contained in the license (“Use SSL-Certificate supplied with your license”) If SSL-Certificates were installed in the “Certificates” Tab, these certificates can be selected. Only available if "Use SSL (HTTPS)" is enabled. |
Use SAML Authentication | Defines SAML for authentication for the Client Service. |
External URL | If the client service is used behind a proxy, the URL to reach the client service is entered here. |
URL Base Path | Here a different URL base path instead of the default root (“/”) can be entered. This is useful if the client service is running behind a reverse proxy, which can’t rewrite URL paths. |
Override Browser Language | If “Use Browser Language” is selected, the browser language setting of a user is used for the localization of the Client Service. Otherwise, the language selected in this field will take priority over the browser language. |
Enable Explicit Time Zone | By default, the browser's time zone is used for date values in search results. If you want to use a different time zone instead, activate this option and set the desired time zone in the "Explicit Time Zone" option. |
Fallback to English for Languages without Built-In Translations | When enabled, languages that do not have built-in translations are parsed as en-US instead. When disabled, all languages in the ISO 639 standard are accepted and passed to the client service. Hint: This setting is only relevant if you use custom i18n translations for this client service. You can find a list of languages with built-in translations in Mindbreeze Inspire Product Information. |
Explicit Time Zone | Time zone in which the date values are displayed in search results. The supported time zones are listed here. |
Servlet Affinity | This option is only needed if the Client Service works behind a load balancer and SAML authentication is used. The specified value is then set as an "AFFINITY" cookie for each request. |
Maximum Number of User Query Terms | Limits the number of words the user can use in the query. |
Maximum Custom Metadata Count | If the data source supports grouped metadata, this value is used to set the maximum count of grouped metadata displayed in detail view. Additionally, this value limits the displayed length of list-metadata. |
Content Fetch Timeout | Downloads are aborted after this time span is elapsed. |
Query Timeout | Queries are aborted after this time span is elapsed. The searches against individual indexes are executed in parallel. If an index does not return any results within the timeout, then only the results of the other indexes are displayed. Within this timeout, all necessary processes are performed, such as query transformation, search in the index, authorization of hits, etc… |
Refinement Resolution Timeout | Refinement resolution is aborted after this time span is elapsed. |
Search In Resolution Timeout | Specifies the time after which the loading from the "Sources" list is aborted. |
HTTP Connect Timeout | This field defines the maximum wait time when opening a http connection. |
AJAX Request Timeout | AJAX requests are aborted after this time span is elapsed. |
Preview Length | This field defines the length of the preview. |
Maximum Request Size | Maximum request size in kB. |
Maximum Search Request Size | Maximum query size for search queries in kB. |
User Profile Storage Path | This field defines a directory where user profiles are stored. User profiles are saved automatically while the user interacts with the Client. Each Client Service saves its own set of user profiles if no path is configured. If you want multiple Client Services to use the same user profiles, enter the same path for all Client Services. |
Embedded Java VM Args (-Xmx..) | This field defines the options that are assigned to the Client Service on startup. Please use this option only after consulting the Mindbreeze Support. |
Flush in Memory Metrics after (queries) | Query statistics are written to disk after the given number of queries. |
Flush in Memory Metrics after (seconds) | Flush the Query statistics to disk after the given seconds. |
Maximum Metrics Filesize | Query statistic files are limited to the given size. |
Metrics Base Directory | Base Directory to store the Query statistics. |
[Deprecated] Enable Healthcheck | This option is deprecated and should no longer be used. Please use the following Healthcheck Settings option instead. Activates the Healthcheck service, which can be used to test the functionality of the client service. |

Section: Filter Settings | |
Maximum Number of Displayed Values | The maximum count of displayed values can be entered here. |
Always Request All Aggregation Values | (For diagnostic purposes only) If this option is selected, all values are requested from the index instead of just the "Maximum Number of Displayed Values". This can reduce the performance of the search. This has no effect on the number of filter values displayed in the client. (Default value: not active) |
Number of Displayed Values | The number of displayed values can be entered here. |
Collapsible | Filter values are collapsible if selected. |
Open by Default | Filter values are open by default. |
Flat Date Filter Values (Month Year) | If this option is selected, for date values the filter values are displayed as a flat list (instead of hierarchically grouped by year) (default: not active). |
Request facets as properties | If this option is enabled, all filterable properties are also queried for each document. This can be used to correct the number of documents in the filters if multiple indexes contain duplicates. This option can drastically reduce the search performance. |

Chat Service | The insight service, which will be used for generating answers (for the AI Chat) can be selected here. |
Enable Feedback Button | If this option is enabled, a Feedback button is displayed, when you hover of a message in the AI Chat. The feedback will be sent to the app.telemetry Form Log Pool. |
app.telemetry Form ID | The ID of the app.telemetry Form Log Pool for feedback messages. By default, the form log pool "ChatUI" with the form ID "ChatUIForm" is available for this purpose. Additional log pools can be created in the app.telemetry configuration. This setting is only relevant if "Enable Feedback Button" is enabled. |
- „Additional Client Service Nodes“: Mindbreeze nodes on which the Client Service is also started.
- In the section "Data Sources" the sorting of the data sources is defined. “Group by Category" groups the data sources by data source type (category) and then sorts them alphabetically. If you want to change the order of the data source types, enter the desired order, separated by a comma, in the field "Order of Categories". To make a customised sort by data source name, use the "Manual Order of Data Sources" field. If "Group by Category" is activated, the data sources are sorted to the front in the group. If you do not specify all data source types or names used, the remaining data sources will be displayed according to the default sorting. If a value contains a comma, you can use a JSON array instead of the comma-separated list.
- In the part “Filters” filters that are displayed in the Client Service can be chosen. Filters that can be selected depend on the selected Query Services and the defined “Aggregation Metadata Keys”.
- In the “Query Engines” field you can choose the data sources which will be made available over the client service.
- „Federated Query Engines“: Enter URLs of query services that are not managed by this Manager Node here. For authentication a special multi master configuration is necessary, see the whitepaper "SAML-based Authentication (eng)" for details.
- „Federated Client Services“: URLs of Client Services which should be included for all users.
- „Display federated results immediately, ignoring global relevancy ranking “: if activated all requested results from a source are displayed. This may include less relevant results on the first page.
- "Federated Client Services Use Legacy Messageframe Channel": If this option is activated, the communication to the federated Client Services runs via the deprecated Messageframe Channel. This option can be used if you want to include Client Services that run on an InSpire appliance version 20.2 or older.
- „Use Legacy Messageframe Channel“: To also use the Legacy Messageframe Channel for Client Services that were federated directly at the Search Client via the settings, set the option "Use Legacy Messageframe Channel" to “Enable”. The following values can be selected:
- "Auto": Mindbreeze InSpire decides itself whether to use the Legacy Messageframe Channel (recommended)
- "Enable": explicitly enables the Legacy Messageframe Channel
- "Disable": explicitly disables the Legacy Messageframe Channel
- „Metrics Query Engines“: If user requests are to be used for auto-completion, the URLs of query engines with recorded metrics must be entered here.
- „Federated Sources“: Activate “Enable Fabasoft Mindbreeze Cloud Sources” to federate several Fabasoft Mindbreeze Cloud services. To add own services, reference additional service lists.
- „API V2 Concurrent Request Limits”: Set the maximum number of concurrent requests for each API service. If the limit is reached, the API calls return the status message „Maximum number of concurrent requests exceeded, please try again later!“ until the number of concurrent requests is below the limit. 0 means no limit. Default: 0
- „API V2 Named Concurrent Request Limits“: Here you can configure the maximum number of simultaneously processed requests per request name. The request name can be set with the request header “x-mes-api-request-name.” If the “Request Name Pattern” regex matches the request name, the number of requests processed simultaneously will be set to the value in the “Maximum Concurrent Request Count” field. 0 also means no limit here.
- In the section "Query Persistence Settings" you can enable searches to be saved for the user. Activate the functionality with "Enable" and configure a database connection to save the searches using the fields "JDBC URL", "User", "Password" and "Database Table Prefix". The "Database Table Prefix" can be used to store different client services in the same database. The "User" and "Password" parameters can also be configured as username/password credential. To do this, you have to create an endpoint entry for the JDBC URL.
- If the option “Count Filtered Values” in section “Query Settings” is enabled filter counts are also displayed for not selected values.
- If the option “Enable Character NGRAMs” in section “Query Settings” is enabled, Character NGRAMs can be activated or deactivated. Default: true.
- If the option „Ignore Global Uniform Properties“ is enabled, metadata defined in the Uniform Property Descriptor can be overwritten by the Category Descriptor.
Memory Analysis Settings (Advanced Settings)
Area: Memory Analysis Settings | |
Memory Test Allocation size in Bytes | This option can be used to test how long an allocation of a certain memory size takes on your JVM. The result is located in the log directory of the client service within the log file memory-usage.csv. |
Statistcs Calculation Frequency | Here you can specify the time interval at which the results of the "Memory Test Allocation size in Bytes" and "Enable JVM Statistics" options are to be calculated. (in seconds) |
Enable JVM Statistics | If this option is enabled, the JVM statistics are written to the log file memory-usage.csv in the log directory of the client service. |
Configuring permitted forwarding URL for user login

If a user logs in to the client service or if the Insight App Editor is used, HTTP forwarding is performed by the browser (via the address /mashup-login) depending on the configured login type. For security reasons, no forwarding to arbitrary URLs is allowed. These settings can be used to configure which URLs are permitted.
By default, "Allow login redirect URLs to" is set to "Client Service External URL." This means that only URLs that correspond to the "External URL" of the client services are allowed. For example, if the client service external URL is https://search.mycompany.com, then the URL https://search.mycompany.com/login is permitted, but the URL https://crm.mycompany.com/login is not.
Note: If the external URL is not set in the client service, then only the URL model is checked, either HTTP or HTTPS, depending on the "Use SSL" setting in the client service.
Relative URLs are always permitted. If the URL is not permitted, the browser gets an "HTTP 403 Forbidden" error message.
The default settings are usually sufficient for simple applications. In special cases, such as load balancers with differing client service "External URLs" or reverse proxies that terminate SSL, the default settings are not suitable and cause HTTP 403 errors. For these special applications, the setting "Allow login redirect URLs to" must be set to "Custom Pattern", and a regular expression (Java) must be specified for "Custom Pattern". The regular expression is matched directly against the forwarding URL. If there is a match, the URL is permitted, otherwise an HTTP 403 error is output. An example of a regular expression would be https://search.mycompany.com.* which allows the URL https://search.mycompany.com/login, but not https://crm.mycompany.com/login.
Note: If the regular expression is missing or incorrect, then no forwarding URL is permitted.
Settings for impersonating search queries
The impersonation of search queries is used, for example, in the "InSpire AI Chat and Insight Services for Retrieval Augmented Generation" in the "Retrieval" step.

Setting | Description |
Token Lifetime (seconds) | Duration (in seconds) for which the impersonation token is valid (Default: 60 seconds). |
Zone ID | User-defined ID that defines the client services that issue and accept impersonation tokens for each other. Default value: not set. |
Impersonation Zone ID
For security reasons, an impersonation token issued by a client service is by default only accepted by the same client service or by synchronized client services (multi-node scenario). A possible use case is, for example, an InSpire AI Chat that is operated behind a load balancer and performs a failover to another client service.
If required, this behavior can be influenced in the section "Impersonation Settings" with the setting "Zone ID". The Zone ID can be configured to an arbitrary value, which is then used to validate the impersonation token. A possible use case is, for example, to configure the same Zone ID on another client service (on the same or on another node) so that the "InSpire AI Chat" retrieval search process is possible on a different client service than the one that is used by the user to access the service.
Security Notes:
Ensure that all Client Services where you set a Zone ID have a correctly configured authentication. A valid impersonation token enables a search query to be sent without further end user authentication. The overall system is only as secure as the least secure client service of the client services involved.
Settings for non-interactive Impersonation

Setting | Description |
Enable Non-Interactive Impersonation | Is this option activated, non-interactive impersonation is possible. |
Token Lifetime (hours) | The duration (in hours) for which the non-interactive impersonation token is valid. Default setting: 24 hours |
Max Challenge Timestamp Age (seconds) | The maximum age (in seconds) of challenge timestamps. Default setting: 60 seconds |
Allow remote requests | Is this option activated, non-interactive impersonation tokens can also be used outside of the same node. |
Configuring settings for validating requests
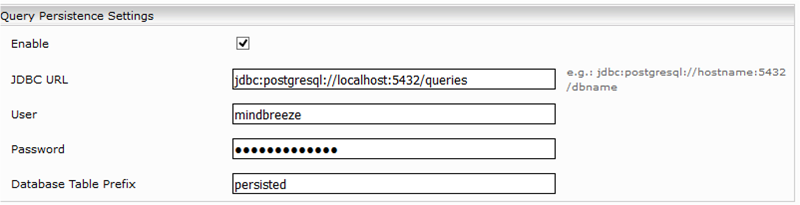
The client service supports the validation of the HTTP host header of requests. This can improve security. The setting "Validate HTTP Request Host Header Pattern" can be used to specify a regular expression that matches the host. The request is only processed if there is a match. Otherwise, an error is noted in the log and the request is rejected with the status HTTP 403.
Configuring settings for the delivery of images
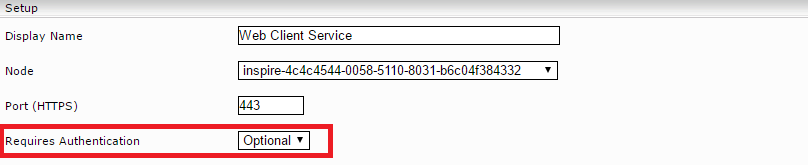
By default, non-static images, such as thumbnails or icons, are delivered as data URLs. If, for instance, a custom client causes problems with data URLs, the setting “Enable Get Image Resources In Separate Requests” can be used to switch the delivery to HTTP(S) URLs. This setting may be removed in the next version of Mindbreeze. Therefore, the custom client must be adapted and data URLs have to be used in order to work even after the next update. Security notice: If this setting is active, the host name in the URL will not be validated.
Configuring settings for Query Service
In a producer-consumer scenario, search queries on the consumer node are directed to the index in the consumer node by default. If, for example, the consumer index cannot be reached due to maintenance, the consumer cannot be used for a search. The Client Service setting "Enable Fallback to Query Services on other Nodes" can be activated to send the search query directly to the Producer Index in such situations. This improves the availability of the search in producer-consumer scenarios.

The setting "Use Credentials from Endpoint Mapping Fallback" is intended for internal use and does not need to be changed.
Enable Saved Searches

- In the Section “Query Persistence Settings” you can set up server-side searches. If enabled is checked, the user can store queries in a database and access them via the Client-Service. Enable this functionality by checking „Enable” and setting up your database connection. The „Database Table Prefix” can be used to use different Client-Services in the same database.
Settings:
- Enable: To save the searches on the server enable this checkbox
- JDBC URL: URL to database
- Max Number Of Database Connections: Maximum number of database connections. Default value: 10, minimum value: 2.
- User: Username of the database
- Password: Password for the user of the database
- Database Table Prefix: Set a table prefix if is needed
Optional Authentication
With the “optional authentication” setting the Mindbreeze InSpire Client Service allows anonymous search in the documents that have no access restrictions. The user can log in for accessing the contents that are restricted and can optionally return to anonymous search by logging off.
For configuring optional authentication, on the Mindbreeze InSpire configuration interface navigate to the “Client Services” tab and set the “Requires Authentication” option to “Optional”.

The optional authentication setting requires that the Client Service has the “Authentication Generates Trusted Peer Credentials” is checked and a “Trusted Peer Credential Certificate” is selected for the Client Service.

If the trusted peer certificate is not available the client service does not allow anonymous access and login is mandatory.
If optional authentication is successfully set the user can switch between authenticated and anonymous modes by clicking on the “Login” respective “Logout” links on the Client Service user interface:


Show/hide user name
If a user is logged in and a user name is available, it can be shown or hidden using the “Display Username” setting.
When this setting is enabled, the full user name is output. If the setting is not enabled, "Login" or "Logout" appears, depending on the login status.

CORS header
If you use federated search, or use a Insight App running on a different server, these settings may be relevant to you. In such scenarios, Web browsers usually prohibit communication with other servers, except for non-authenticated public servers, since no critical data is transferred there.
The option "Allowed Origins" controls which "Origins" are allowed. Origins are absolute URLs from which requests are allowed.
If you want to use a client service with authentication from other origins with different private domains, you must explicitly list the URLs of these origins in the “Allowed Origins” option. For example, http://search.mycompany.com,https://search.mycorporation.com
Alternatively, you can use the “Allowed Origins Pattern” option to control which origins are allowed using regular expressions. You can specify multiple lines here. For example, the value
https://.*\.mycompany\.com
https://.*\.mycorporation\.com
allows access from, for example
https://search.mycompany.com
https://myapp.mycompany.com
https://find.mycorporation.com
but not from
https://search.example.com
Note: as soon as you use the “Allowed Origins Pattern” option, the “Allowed Origins” option has no effect.

Default values
For non-authenticated ClientServices ("Requires Authentication": "No"), the value ".*" is assumed for "Allowed Origins Pattern" by default if "Allowed Origins (Pattern)" is not explicitly configured.
For (optional) authenticated ClientServices ("Requires Authentication": "Optional" or "Yes"), all hosts with any port that are within your top private domain are allowed by default if "Allowed Origins (Pattern)" is not explicitly configured. The "top private domain" is the domain that is one level below the public suffix (as defined in the Mozilla Foundation's Public Suffix List (PSL)). For example, such a domain would be "mindbreeze.com", from which the pattern "(.*\.)?\Qmindbreeze.com\E(:[0-9]+)? " is generated. The domain name is extracted from the "External URL". If this is not configured, it is extracted from the configured "Hostname" from the nodes configuration. If this is also not possible, the domain name is extracted from the system FQDN.
CORS with SAML
If your SAML IDP is not within the domain of your Mindbreeze InSpire appliance, configurations must be made under certain conditions. Mostly, this is of interest for SAML IDPs in the cloud. Please ensure that Mindbreeze InSpire trusts your IDP. To do this, first activate the Advanced Settings.

Trusted Cloud SAML Login Domains | By default, Azure Active Directory and Okta are trusted. If you are using a different SAML IDP, please contact us. We are very interested in what IDPs our customers are using to improve support for those IDPs. |
Trust SAML Hostnames from Authenticators | By default, the IDPs from the "Available SAML Authenticators" settings from the "Authentication" tab are trusted. However, this is not always sufficient as the login URL may be different (e.g. due to redirects). If this is the case, the domain of the login URL can be entered manually in "Trusted Cloud SAML Login Domains". |
Attention: When redirecting through the SAML IDP back to the log-in screen in the client service, a 403 error may appear. The reason for this is that the "Origin” HTTP header has the value "null". To prevent this, set in the setting "Allowed Origins Pattern" the value "null".
Preview Settings
Whether to automatically scroll to the most relevant match result when previewing PDF files. Default: false.
Healthcheck
The health check of the Client Service is configured in the “Healthcheck Settings“ section.
The address <Adresse des Client Services>/ping indicates whether the client service is operational. This allows the service to be monitored in order to inform the operation or to enable/disable it on a load balancer, for example.
By default, the "Workload Check" checks the load of the Web server and the number of parallel requests (see also API V2 Concurrent Request Limits). The "Disabled" setting disables this check.
In addition, you can add your own checks in "JSON Healthcheck Files Directory". This allows search queries to be executed and their results can be checked and processed with Javascript.
Responses
Workload Check | JSON Healthcheck Files Directory | HTTP Status Code | HTTP Body |
OK | Not configured | 200 | OK |
OK | Configured | Acc. to configuration | Acc. to configuration |
NOK | - | 500 | NOK |
Voting
In order to offer the possibility to give feedback on a result (positive or negative feedback), the option "Enable Voting" can be set in the client service.

If this option is active, all results in the client are equipped two additional buttons.
![]()
You can analyse the feedback in app.telemetry (Application -> Query Service Query Log -> View Telemetry Data).
Cookie Settings
The Client Service automatically sets a session cookie (JSESSIONID) by default. If desired, this can be prevented by activating the setting "Disable Session Cookie" (If, for example, the Client Service is operated publicly and cookies are not permitted for legal reasons). Hints: This setting can impair performance. This setting must not be used in conjunction with the authorization form SAML.
The "Same Site Cookie Behavior" setting determines whether cookies are used across domains. If you use the federated search and the servers are on different domains (e.g. search.mycompany.de federated to search.mycorporation.com) and you use cookies to log in to the browser (for example, with the authorization form SAML), then "Same Site Cookie Behavior" must be set to the value "Auto" (default value). This ensures that the cookies required for authorization can be transferred. Note: the "Auto" value determines that when "Use SSL" is active, effectively cookies with Same Site Cookie Behavior "None" are set. If "Use SSL" is not active (e.g. when using a load balancer), no Same Site Cookie Behavior is set.
If you are not using federated search with cookie-based authorization, you can set the “Same Site Cookie Behavior” setting to "Strict" for increased security. This will prevent cookies from being passed on. The other possible values of this setting are for internal use and should not be used.
Operating custom Insight Apps using the Client Service
To operate your own Insight Apps using the Client Service please use the section “Web Application Contexts Settings” as described in the document “Development of Insight Apps”
Using port 80 as the client service port on G7 appliances
To run a client service on port 80, the following steps are required on G7 appliances:
Disable the option: “Use SSL (HTTPS)” and set the “Port (HTTP)” to 23350. Port 80 is automatically forwarded to this port.
![]()
![]()
For security reasons, access to port 80 is restricted. To allow access for specific IP addresses or subnets, edit the file: “/var/data/iptables.sh”.
In the line “iptables -t nat -A PREROUTING -m addrtype --dst-type LOCAL -s 127.0.0.1 -p tcp -m tcp --dport 80 -j DOCKER,” enter the allowed addresses instead of 127.0.0.1 or remove “-s 127.0.0.1” to enable access from anywhere. Then restart the appliance to apply the firewall rules.
During an update, the file “/var/data/iptables.sh” is overwritten and a backup in the format "/var/data/iptables.sh.bak.YYYYY-MM-DD" is automatically created. If necessary, restore your customized rules after the update.
“Administrators“ Tab
The ”Administrators“ tab provides the interface to configure authentication and authorization for accessing the Mindbreeze InSpire configuration.
The box “Authorized Users” shows all users which currently have access to the configuration user interface.
Note: If there is no user in this list, no authentication and hence no access control is performed.
To add a new user, perform the following steps:
Click the plus icon (![]() ) located at the top right-hand side.
) located at the top right-hand side.
Enter the name of the new user who should get access to the configuration user interface in the “Username” field. The name must include the machine or domain name, i.e. MACHINE\username or DOMAIN\username.
Click the “Save” button located at the top right-hand side
As soon as you have entered one or more administrators and clicked save, only the specified users may change the configuration using the web-based user interface. Therefore, ensure that you have added your own user name before closing the user interface.
You may later revoke a user’s rights to manage the configuration by unchecking the “Authorized” checkbox, or remove the user from the list by clicking on the icon at the right window border (![]() ).
).
Authentication is based on Kerberos and NTLM. For Kerberos to work as expected, the Kerberos infrastructure must be configured by adding a so-called Service Principal Name (SPN) for the Mindbreeze InSpire Management Node service user.
“License” tab
The “License“ tab is used to manage the Mindbreeze InSpire license.

To reinstall or upgrade a license, perform the following steps:
- In the field next to "License": select your desired license file. You can use the "Choose File" button for this purpose.
- Then click on "Upload" and save by clicking on "Save".
After saving the license file, the name of the company licensed for the current installation of Mindbreeze InSpire and the license expiration date is displayed in the “Current License Information” box.
The “Licensed Products” section displays your licensed products and their restrictions.
The restrictions include:
- Maximum User Count: Displays the maximum number of users for which the current license is issued.
- Maximum Document Count: Displays the maximum number of indexable documents for which the current license is issued.
“Certificates“ tab
Mindbreeze InSpire offers the possibility for third-party applications to issue queries to the Query Service without providing complete user credentials. Such applications are called ”trusted peers“ and must authenticate themselves using a SSL certificate. In order to ensure the confidentiality of the data stored in the index, it is required that such certificates are signed by a Certificate Authority (CA) which has been registered within Mindbreeze InSpire.

In order to define the trusted CA, use the ”Certificates“ tab to upload the “.CER” file containing the certificate of the CA in PEM format. If you don’t upload any CA certificate, the functionality of trusted peers will not be available. The option “Trusted Peer” enables if an available certificate is used for this purpose. The box “Current Trusted CA Information” shows the currently registered certificates.
All CA-certificates („Available CAs“) can also be used for authentication via client-certificates. This type of authentication can be used from the Windows Client. Every user has to present a certificate signed by a specified CA. The CA has to be defined in the index settings by selecting a certificate for the preference “Authentication Certificate” in “Advanced Settings”.
![]()
In order to operate the Web Client Service with a different SSL-certificate than the supplied one, for example to use load-balancing, upload certificates in pkcs12 format. These certificates show up below “Available SSL Certificates” and can be chosen for each Web Client Service from the “SSL Certificate” option in “Advanced Settings”. The default setting “Use SSL Certificate supplied with your license” uses the certificate supplied with your license.
![]()
Tutorial Video „Install SSL certificate“
This video demonstrates how to install the SSL certificates for both the Web Client and for the Management Center: https://www.youtube.com/watch?v=oThC_VNcc5s
“Network“ Tab
The “Network“ tab enables common network configurations for all services.

Proxy Settings
These proxy settings are used by all Mindbreeze Enterprise Search services in order to access web resources through a proxy server. Host address and port of proxy server and a valid username and password is to be provided if necessary.
LDAP Settings
This information is important for the connection with the LDAP servers necessary for authorisations:
Domain Name | Fully qualified domain name. |
LDAP Server | These LDAP Servers will be preferred for LDAP queries. Additionally the LDAP servers in DNS Server Records (_ldap._tcp.gc._msdcs and _ldap._tcp) of Active Directory will be used if the configured LDAP Server is not reachable or delivers no results. |
Disable LDAP Server Discovery | Only configured LDAP Servers will be used for queries. No LDAP server discovery will be performed. |
Excluded Domain | Domains to be excluded from LDAP queries. |
Connection Encryption | For the connection to the LDAP server, the SSL protocol (LDAPS) on port 636 or the TLS protocol (StartTLS) on port 389 can be selected. If Unencrypted is selected, no encryption is performed. |
Enable Connection Pool Manager | Connections to LDAP server are reused to improve performance. |
Maximum Connections | Maximum number of connections to LDAP server which are established at service startup. These connections can be used in parallel. A LDAP query will be block only if all these connections are in use. |
Maximum Shared Connections | Maximum number of threads that can share the same underlaying physical connection. |
The LDAP queries are logged in the "Network Requests" log pool of AppTelemetry. Scheme "ldap" and port "389" can be used as filters. All queries that are present in the cache have the status "Persisted Cache".
“About“ Tab
The “About“ tab shows common information about the current installation of Mindbreeze InSpire, such as the version number and the copyright.
Recovering Mindbreze Configuration from a backup
When a configuration change is saved, backups of the Mindbreeze configuration files (mesconfig.xml and pluginsite.xml) are automatically created. The backup files can be found in the same folder as the original configuration files:
%userprofile%\AppData\Roaming\Mindbreeze\Enterprise Search\Server\,
The %userprofile% folder is the profile folder of the Mindbreeze Manager Service user. If the service is started with the system user, the configuration files are located in
C:\Windows\System32\config\systemprofile\ AppData\Roaming\Mindbreeze\Enterprise Search\Server\
The backups have the following naming schema: mesconfig.xml.backup_<timestamp> und pluginsite.xml.backup_<timestamp>.
For recovering the last state of the Mindbreeze configuration the following steps are necessary:
- Stop the Mindbreeze Manager and Node services
- Replace the files mesconfig.xml and pluginsite.xml with the corresponding backups: mesconfig.xml.backup_<timestamp>
- Start the Mindbreeze Manager and Node services.
Import/Export of Settings
Settings of various services can be imported and exported using this component:

Format
The following format is used for the import and export of settings:
<settings>
<attributes>
<attribute name="name" value="value"></attribute>
</attributes>
<properties>
<property name="name" value="value"></property>
</properties>
</settings>
Export
The export window (on the left) reads all available options from the service. These options can then be uses for importing into another service.
Import
The import window (in the middle) displays the updated configuration. Notice: The services have to be of the same type for this to work.
Changes
The changes window (on the right) displays a visual diff of the changes.
Remove exisiting settings
If this option is active the configuration of the target service is overwritten.
The following options are never overwritten:
- Service Name
- Index Path
- Index Port (HTTP)
- Data Port (TCP/IP)
- Query Port (HTTPS)
- Filter Service
- Caching Principal Resolution Service
- Authorization Service
If you only wanyt to extend or update the configuration you can disable this option.
Parameterization
Introduction
Through configuration parameters and so-called “Development Snapshots”, changes to
- the Mindbreeze Service configuration (add/remove and customize connectors, indices, filters, client services, ...)
- the semantics pipeline
- the Query Transformation Pipeline
- InSpire Insight Apps
- Any resource files like boosts, relevance parameters
can be exported as a development snapshot and then automatically transferred to production. Any settings (e.g. the data source URL to be indexed) can be overwritten locally as parameters on the respective environment. This ensures that the production data sources are indexed productively and the developer data sources in the development system. Credentials, certificates are not stored and are preserved.
Enable/Disable Parameterization
This feature is available only for G7 appliances.
From the ‘Indices’ tab, check the advanced settings, you can enable or disable the parameterization feature from the following table.
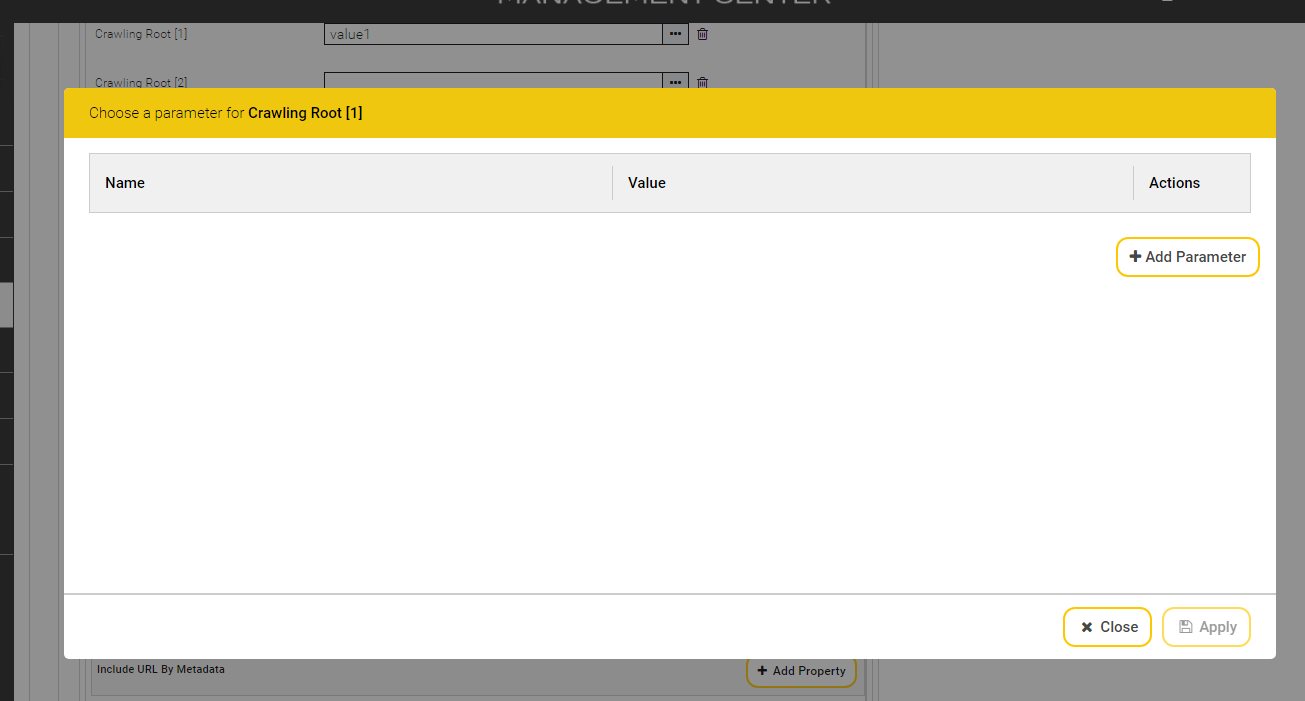
Note: To disable parametrization, click on the ‘Disable Parameterized Configuration’ button. If there are any active parameterized configuration options, the button is disabled. To disable parameterization in that case, you have to remove all parameters first.
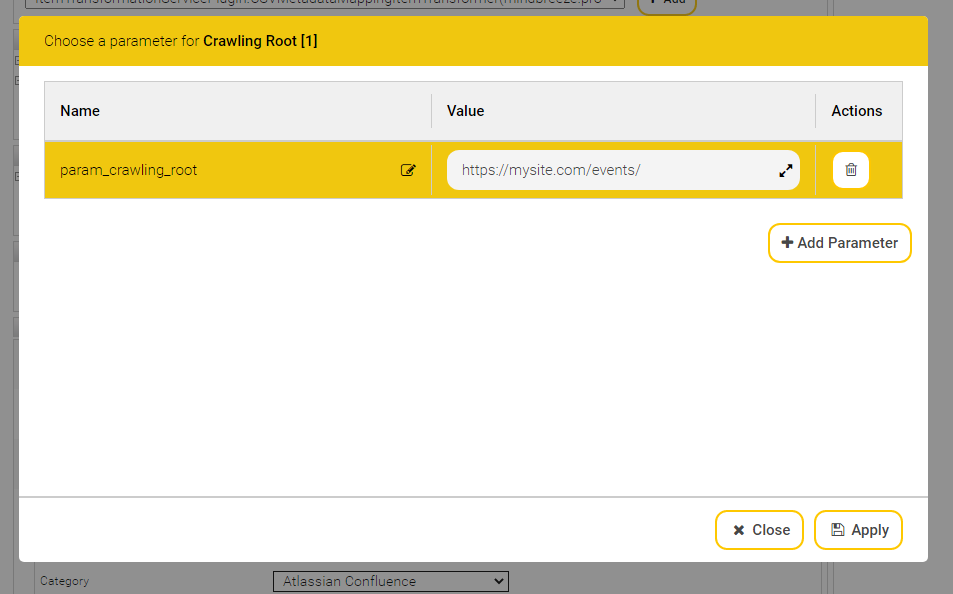
Add a Parameter
Once parametrization is enabled, you can parameterize a configuration option from the following ‘Add/Update Parameter’ (…) button.

You can select one of the existing parameters in your node environment or add a new parameter from the following table.

Note: The parameter’s name must not include any white spaces or special characters.
To apply changes, you have to choose a parameter from the table list.
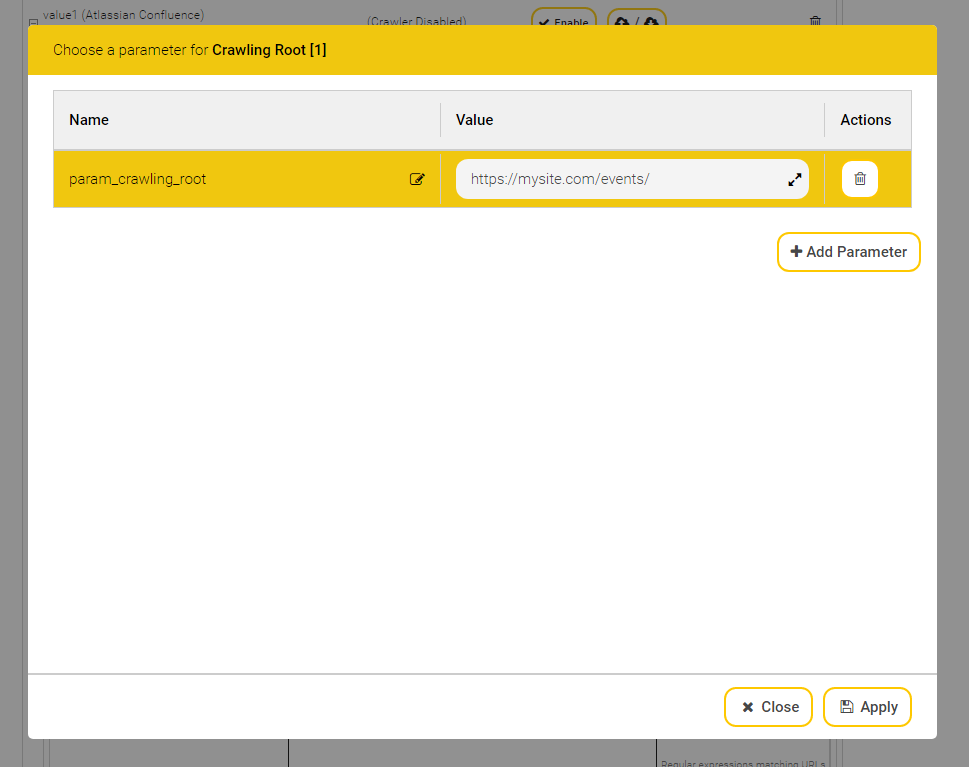
Note: Choosing or selecting a parameter is done by clicking on the table row. If selected, it is yellow highlighted.
After clicking apply, the value of the configuration option ‘Crawling Root [1]’ will be the value of the parameter chosen from the previous table. In addition, the configuration option’s value is now read-only.

Update a Parameter
To edit the parameterized configuration option (e.g. change the parameter value or choose another parameter), click on the following ‘Add/Update parameter’ button.
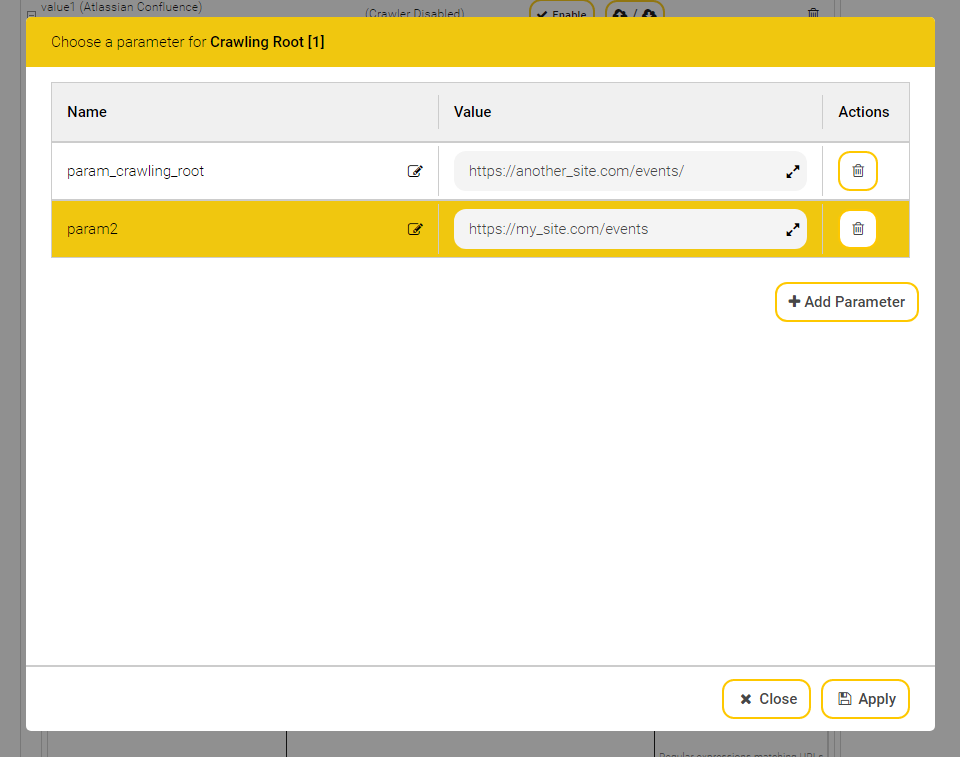
The dialog is opened, where the referenced parameter for this configuration option is automatically chosen (highlighted) from the available list.

Change the value of the parameter (e.g. ‘https://another_site.com/events’) and click apply:
The configuration option’s value will also change accordingly.

Note: Another possible change is to select another parameter (e.g. ‘param2’). In this case, the configuration ‘Crawling Root [1]’ will now refer to the newly chosen parameter.

And the value of ‘Crawling Root [1]’ will accordingly refer to the value of ‘param2’.

Remove a Parameter
To remove a parameter from the configuration option ‘Crawling Root [1]’, you can click on the following ‘Remove parameter’ (x) button.

Note: The value of the configuration option ‘Crawling Root [1]’ is now read/write and it takes the value of the last referenced parameter.

Now clicking on the above ‘Add/Update Parameter’ button will re-open the dialog to parameterize this configuration option from the beginning.
Mindbreeze InSpire Query language
The Mindbreeze InSpire Query language is used to specify queries.
4.1 Querying single terms
To search for a word or the first letters of a word no wildcard characters (%, *, etc...) are required.
Example: | act |
Entering “act” initiates a search for objects that start with the term “act” or contain the word “act”. During a search capitalization is ignored, i.e. a search for the term “act” returns the same results as a search for “Act” or “ACT”, since the query language does not distinguish between upper and lower case letters.
Search for multiple terms in one document
In addition to querying single terms, you can query for multiple terms within one document. A search for multiple terms covers documents containing the terms themselves as well as documents containing words starting with these terms. To be part of the search result, all terms entered have to be contained in a document.
Alternative 1 | Car test |
Alternative 2 | Car Test |
Alternative 3 | CAR TEST |
These three alternatives return the same search result: documents containing words beginning with ”car“ and “test” or containing “car” and “test” as independent terms. The query language does not distinguish between upper and lower case letters.
Search for phrases/definite search
A search for phrases searches for definite words or phrases. This kind of search is initiated via quotation marks (“) at the beginning and at the end of a phrase.
Example: | "Knowledge is a matter of seconds" |
The exact phrase is searched for. Searching for phrases does not make sense if the exact spelling of the words or the phrase is unknown.
Restriction to file extensions
Mindbreeze InSpire is able to restrict the search to files with particular file extensions.
Example: | mind (extension:doc OR extension:xls OR extension:msg) |
This query searches all files with the file extensions “.doc” (Microsoft Word), ”.xls” (Microsoft Excel) and ”.msg” (Microsoft Outlook) for the word “mind” or words starting with "mind" in upper case or lower case letters.
Logic operations
AND
Phrases, words and word beginnings in a search query are implicitly combined with the logical operator AND. The search delivers documents containing all phrases, words and word beginnings listed in the search query. The keyword AND can also be included explicitly in a (for example nested) search query.
Example: | "Mindbreeze" AND "Search" |
OR
The logical operator OR delivers all documents containing at least one of the search criteria: at least one of the phrases, words or word beginnings entered. The search result also contains documents, containing only one entered term or one word beginning with an entered term or containing one of the entered phrases. The key word OR has to be explicitly defined within a search query and can also be used in a nested query.
Example: | |
Alternative 1 | ("Mindbreeze" OR "Search") AND "Software" |
Alternative 2 | ("Mindbreeze" OR "Search") "Software" |
These two queries deliver all documents containing the word “Mindbreeze” and/or the word ”Search” together with the word “Software“. They deliver documents containing the combinations ”Mindbreeze” and ”Software“, “Search” and ”Software” or ”Mindbreeze”, ”Search” and ”Software”.
Key words
NEAR
A search with the NEAR operator delivers documents, in which one word is found near another word.
Mindbreeze NEAR Search |
NOT
A search with the NOT operator returns results within a source set where the word does not occur. NOT cannot be specified without any other word that yields results.
Example: | Mindbreeze NOT slow |
Metadata search
A metadata search is primarily used to refine a search result via additional restrictions. Mindbreeze InSpire provides some default metadata. In addition, manufacturer dependent metadata (defined by Mindbreeze partners) can be used.
Syntax of a metadata search: <metadatum>:<value>
Example: | title:Integration |
A search for a file extension can be defined via the metadatum ”extension”.
Example: | extension:doc mind |
In this example both alternatives produce the same search result: Microsoft Word files containing the word “mind” or words starting with “mind”.
The following table shows the metadata available for the data sources provided by Mindbreeze InSpire by default:
Short name | Metadatum | Description | Available for |
Name | title | Search within name | Any |
Extension | extension | Search within extension | Any |
Directory | directory | Search within folder name | File system, Outlook, Exchange |
Subject | subject | Search within subject | Outlook, Exchange |
From | from | Search within sender | Outlook, Exchange |
To | to | Search within receiver | Outlook, Exchange |
(not displayed) | content | Search within document content | Any |
The Microsoft Exchange Connector defines the metadata terms from and to.
Example: | from:bauernf |
This search query delivers all objects sent by an address with the term ”bauernf”.
Interval Search
A Query containing the „TO“ operator returns search terms between the left and the rigth side of the operator. This is particularly useful when combined with numerical strings. Mindbreeze recognizes numerical values in various formats, for example:
text | canonical representation |
100 | 100,00 |
100.0 | 100,00 |
100,0 | 100,00 |
1.000,00 | 1000,00 |
1.000 | 1,00 |
1,000.00 | 1000,00 |
-100 | -100,00 |
Interval Search Syntax: <from> TO <to>
Example: | 105 TO 110 |
Extended Metadata Interval Search
Extended metadata interval search syntax:
label:[from> TO <to>]
label:[<from>]
label:[TO <to>]
Example: | size:[1MB TO 1,4MB] mes:date:[2012-03-20 TO 2012-03-25] |
Combination of language elements
It is possible to combine the described language elements of the Mindbreeze InSpire query language.
Example: | title:Integration from:bauernf extension:doc |
This example delivers Microsoft Word documents sent by an address with the term ”bauernf“ in it and with a title containing the word “Integration" or a word beginning with ”Integration”.
Useful search results even if not all search terms match
Using the Optional Terms, finding documents can be simplified by providing results in which not all search terms necessarily have to occur. To make this transparent for the user, a note is displayed with the search result. This feature is active by default, but can be parameterised or completely deactivated (see section Optional Terms).
Example Query: | Artificial Intelligence Human Interaction Article |
By default, documents are found in which at least two thirds (67%) of the search terms occur. Since the search query in this example contains 5 search terms, one term can be missing in the result. The screenshot below shows an example where a document is found for this search query that does not contain the term "Article".

Operation and Maintenance
Changing the Index Service-Mode
A Mindbreeze InSpire Index Service supports the following modes:
- Mode: running (
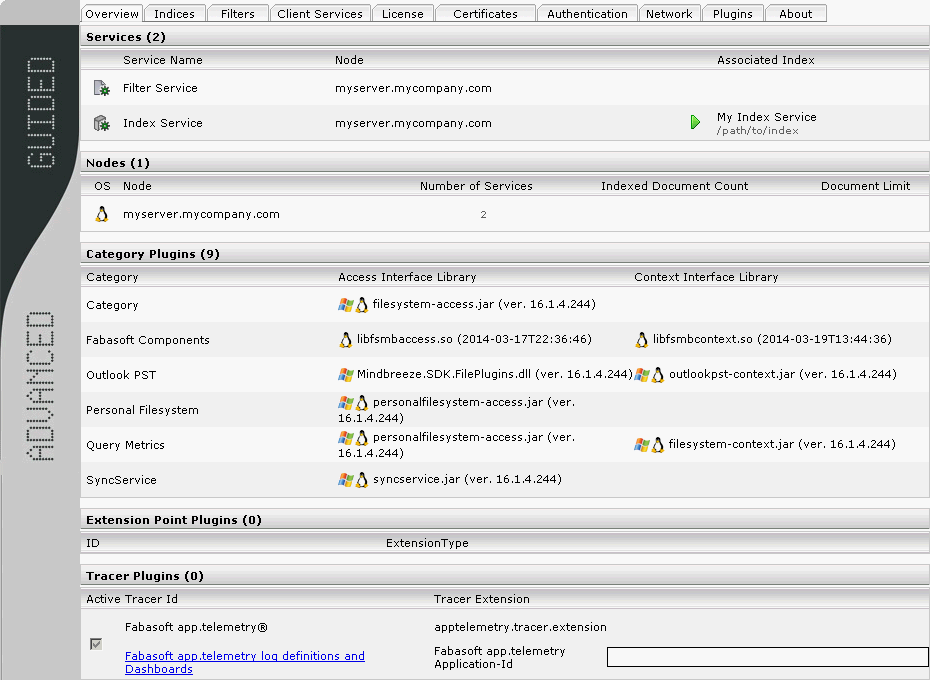 )
)
This is the default mode of a Mindbreeze InSpire Index Service. This mode represents normal operation - Mode: readonly (
 )
)
This mode is used to provide index consistency during backup of the index files for Mindbreeze InSpire
Hint: To allow resumption of the indexing process or start indexing of new documents (delta-indexing), the state must be changed back to “Mode: running”. - Mode: offline (
 )
)
This mode cannot be set explicitly by the user. An Index Service is in this mode when it has been stopped completely
Manually changing the Index Service-Mode
In addition to automatic state changes, the mode can also be changed via the Mindbreeze InSpire configuration user interface. In the “Services” field click the icon in the “Associated Index” column to change the mode. Clicking it again changes the mode back to the original state.

Hint: If the Index Service is not running, there will also be an indication why. The mode of the index service cannot be changed when in this state via the user interface, you must start the Index Service manually.
Changing the Index Service-Mode using a Script
- To change the index service mode to “readonly”, please run the following from the Command Prompt:
mescontrol http://indexserver.yourcompany.com:23100 readonly
- To change the index service mode to “running”, please run the following from the Command Prompt:
mescontrol http://indexserver.yourcompany.com:23100 readwrite
Backing up the index data
Mindbreeze InSpire uses a file-based index. These index files can be backed up completely in a consistent state.
To save index data, perform the following steps:
- Change the mode of the index service to “Mode: readonly “().
- Check the consistency of the index with:
mescontrol http://index.yourcompany.com:23100 checkconsistency - Verify the exit code (ERRORLEVEL) of mescontrol
- Navigate to the directory where the index is stored, and backup the files within this directory, only when no errors occurred up to now
- Change the mode of the index service to “Mode: running” ()
Restoring index data
To restore a previously saved index, perform the following steps:
- Stop the Index Service.
- Delete any existing files in the index directory (if not required any more) or change the path to the index files of the Index Service in the configuration to a new.
Hint: If you define another directory, make sure that the service user has write access to the defined path. - Copy the restored index files into the directory.
- Restart the Index Service.
Index Status Information
Index Statistics
Every Index service provides detailed status information about status of the indexing process and the number of documents indexed by using the “/statistics” URL path:
An example endpoint of an index service on host “indexserver.mycompany.com” listening on 23100 would result in the following URL: http://indexserver.mycompany.com:23100/statistics
Indexed Documents
In addition to getting statistics on the indexing status one can use the “/documents” URL Path to browse indexed documents either by document key (depending on the connector in use) or by document id (docid). Please note that the docid is an internal sequence number and varies between indexing runs.
An example endpoint of an index service on host “indexserver.mycompany.com” listening on 23100 would result in the following URL: http://indexserver.mycompany.com:23100/documents
Retrieving Index Status Information
For health checking purposes one can use the raw index status handler available via /index_mode on the index service’s bind port. For instance on an Index Service running on indexserver.mycompany.com that is listening on port 23100 it would be: http://indexserver.mycompany.com:23100/index_mode
If the Index Service receives a request on this end point, the index responds with status information in form of an XML document that has the following schema:
<status mode=”<status-information>” />
<status-information> indicates the mode of the index which can be:
- normal (read write)
- readonly
- offline (closed)
Receiving an HTTP status code other than 200 also indicates that the index is not fully operational.
Backup of log files
The log files are archived regularly. This is done using a cron job, which is run every Sunday at 2:30 by default.
All log files from the paths /data/logs and /var/opt/mindbreeze/log are archived and stored in /data/backups/log-backups.
Binary files are not backed up but removed during backup.
Only the first 50GB of files larger than that are backed up.
Query Service Reconfiguration
The following query service options can temporarily be changed without index restart, and these changes will not persistent in the index configuration:
- “Query Threads per Index”
- “Number of ACL Precomputation Threads“
This reconfiguration is possible only with disabled “Disable Unrestricted Privileged Servlets” option.
To change the number of query threads, please run the following from the Command Prompt:
mescontrol http://localhost:23100 reconfigure --query-threads=<n>
To change the number of ACL precomputation threads, please run the following from the Command Prompt:
mescontrol http://localhost:23100 reconfigure --precompute-acl-threads=<n>
Appendix A
Service Restart Behavior after Configuration Changes
Change | Index/ | Index/ | Connector | Filter | Filter Plugins | Caching Principal Resolution Service | Client Service | Client Service |
Connector | ||||||||
Adding a new index and a connector | R | R | ||||||
Adding a connector to an existing index | R | R | R | R | ||||
Changing a connector's configuration | R | |||||||
Index/Query | ||||||||
Changing index path | ||||||||
Changing an index's configuration | R | R | ||||||
Adding a query plugins to an existing index | R | R | ||||||
Changing a query plugin's configuration | R | |||||||
Filter | ||||||||
Adding a filter plugin to an existing filter | R | R | ||||||
Changing a filter's configuration | R | R | ||||||
Changing a filter plugin's configuration | R | |||||||
Client Service | ||||||||
Changing a client service's configuration | R | R | ||||||
Adding a client service plugin | R | R | ||||||
Changing a client service's plugin | R | |||||||
Generic | ||||||||
Changing the log level | ||||||||
Changing the log directory | R | R | R | R | R | R | R | R |
Changing the proxy settings | R | R | R | R | R | R | R | R |
Changing the LDAP settings | R | R | R | R | R | R | R | R |
Changing the credentials and endpoints | R | R | R | R | R | |||
Changing the authentication settings ** | R | R | R | R | R | R | ||
Changing the certificates ** | R | R | R | R | R | R | ||
** Only services which are affected directly by the change. For example changing the kerberos keytab will cause restart of the service which uses this keytab. | ||||||||
Appendix B
Manual Configuration of Kerberos-based Authentication
The following steps are needed for manual configuration:
- Set the HTTP/<host_fqdn> service principal name for the service user, using the setspn tool or add manually using adsiedit.msc. Here the <host_fqdn> is the fully qualified domain name of the Mindbreeze InSpire Node:
e.g setspn –a HTTP/myserver.mydomain.com DOMAIN\serviceuser.
Make sure that the SPN is not already set for a different user or host object from the current Windows Active Directory, e.g. using setspn -x (available on Windows Server 2008 servers) or try third party tools like dumpspn. - Set the trusted for delegation flag for the service user in the "Users and Computers" management console plugin (dsa.msc).
Appendix C
This appendix lists useful administration details for Mindbreeze InSpire components.
Web browser configuration
The security restrictions of web-browsers limit the use of file resources (e.g. file://myserver.mycompany.com/share/letter.doc) and they are not accessible in most browsers without modification of security settings. Kerberos support for authentication is also not configured by default but Mindbreeze InSpire uses Kerberos Single Sign On for secure network wide search. This section shows how to manually configure the required browser settings based on Mozilla Firefox and Microsoft Internet Explorer.
Mozilla Firefox – Manually setting the settings
To manually configure Mozilla Firefox, type about:config in the address bar. This will show a list of configuration options.
The following configuration entries have to be set.
Config Value | Description | Example values |
network.negotiate-auth.delegation-uris | This value should contain two entries of the fully qualified hostname of the Mindbreeze Web Client Service. One for the http protocol, the other for https Note: Multiple entries can be specified using a comma (,) as a seperator. | … http://myserver.mycompany.com, https://myserver.mycomapny.com |
network.negotiate-auth.trusted-uris | This value should contain the same entries as the network.negotiate-auth.delegation-uris value Note: Multiple entries can be specified using a comma (,) as a seperator. | http://myserver.mycompany.com, https://myserver.mycomapny.com |
After restarting the Firefox browser, the changes should have been applied. Authentication with the Mindbreeze InSpire Web Client Service should now work as expected.

In addition to Kerberos authentication, another important configuration option is to be able to open file URLs. Mozilla Firefox up to version 1.4, and Mozilla Suite up to version 1.7.x provide only one global value to configure the settings of file URLs. This configuration is called ”security.checkloaduri“ and should be set to ”false“.
Warning: Globally setting this value might open a security risk when visiting malicious internet sites.
Newer versions of Mozilla Firefox (starting with version 1.5) and the Mozilla SeaMonkey Suite starting with version 1.0 are able to set the security settings for a set of web sites which are described by a policy.
To create a policy you have to manually edit the user.js configuration file that resides in your local Mozilla proflie folder. (e.g.: C:\Docments and Settings\User\Application Data\Mozilla\Firefox\Profiles\xxxxx.xxx\user.js).
Note: Please refer to the %USERPROFILE%\Application_Data\Mozilla\Firefox\profiles.ini configuration file, to find your active Firefox profile directory.
The following snippet shows the configuration of a new policy called “messecurity settings” for the Mindbreeze InSpire Web Client Service Node running on myserver.mycompany.com, on port 23350
user_pref("capability.policy.policynames", "messecuritysettings");
user_pref("capability.policy.messecuritysettings.sites", "https://myserver.mycompany.com:23350");
user_pref("capability.policy. messecuritysettings.checkloaduri.enabled", "allAccess");
Note: Several Web Client Services can be added to the policy by separating them with spaces.
Microsoft Internet Explorer
Setting the configuration manually
Microsoft Internet Explorer uses security zones to implement its security model. By default, a web site is located in the “Internet” zone. To grant the necessary rights to the Mindbreeze InSpire Web Client, add the URL of the Mindbreeze InSpire Web Client Services to the “Local intranet” zone.
Double-click the globe symbol toward the right of the status bar. Then in the “Internet Security” tab which is displayed, select “Local Intranet” and “Sites”. Add the Mindbreeze InSpire Client Service URL to the local intranet sites using the following the dialogs.
Add both the http as well as the https URL of the Mindbreeze Enterprise Search Web Client Services to the list of local intranet sites.
Example: Your Mindbreeze InSpire Web Client Service is available from myserver.mycompany.com add the following two entries to the list:
https://myserver.mycompany.com
Also make sure that the option "Display Mixed Content" is enabled for your local intranet. You can check this setting with "Custom level".
Additionally, you should disable the “Do not save encrypted pages” option in the “Advanced” Tab.
To apply the changes, reload the Web Client page after the Web Client address has been added to the Intranet Zone.
Configuration of Microsoft Internet Explorer via Group Policies
Follow the steps below to automatically set the configuration described above for a specific organizational unit in your Active Directory domain. The following section guides you through the steps needed to create a group policy which adds the Mindbreeze InSpire Web Client Service to the Trusted Sites and the Mindbreeze certificate to the Root Certificate Authorities.
First, log on as a member of the “Domain Admins” group. Then open the “Active Directory Users and Computers Management” console. Right-click the domain or Organizational Unit where you want your Internet Explorer to be configured and click “Properties”.
Then select the Group Policy Tab and click the “New” button. Type a name for the new Group Policy Object. (e.g. MES IE Config). Then click the “Edit” button.
In the following section an administrative template which will configure the Internet Explorer settings mentioned above will be added.
After opening the Group Policy Object Editor, right-click “Administrative Templates” and select “Filtering…”.
In the following dialog uncheck “Only show policy settings that can be fully managed”.
Import the administrative template
First right-click “Administrative Templates” and select “Add/Remove Templates…”.
In the following dialog add the file called “MindbreezeEnterpriseSearchWebclient.adm” located on the Mindbreeze InSpire installation ZIP / ISO.
After adding the administrative template, please enable all settings.
To add the Mindbreeze Webclient to the “Trusted Sites” navigate through User Configuration>> Windows Settings >> Internet Explorer Maintenance >> Security. Next, right-click Security Zones and Content Ratings in the right window pane and click Properties.
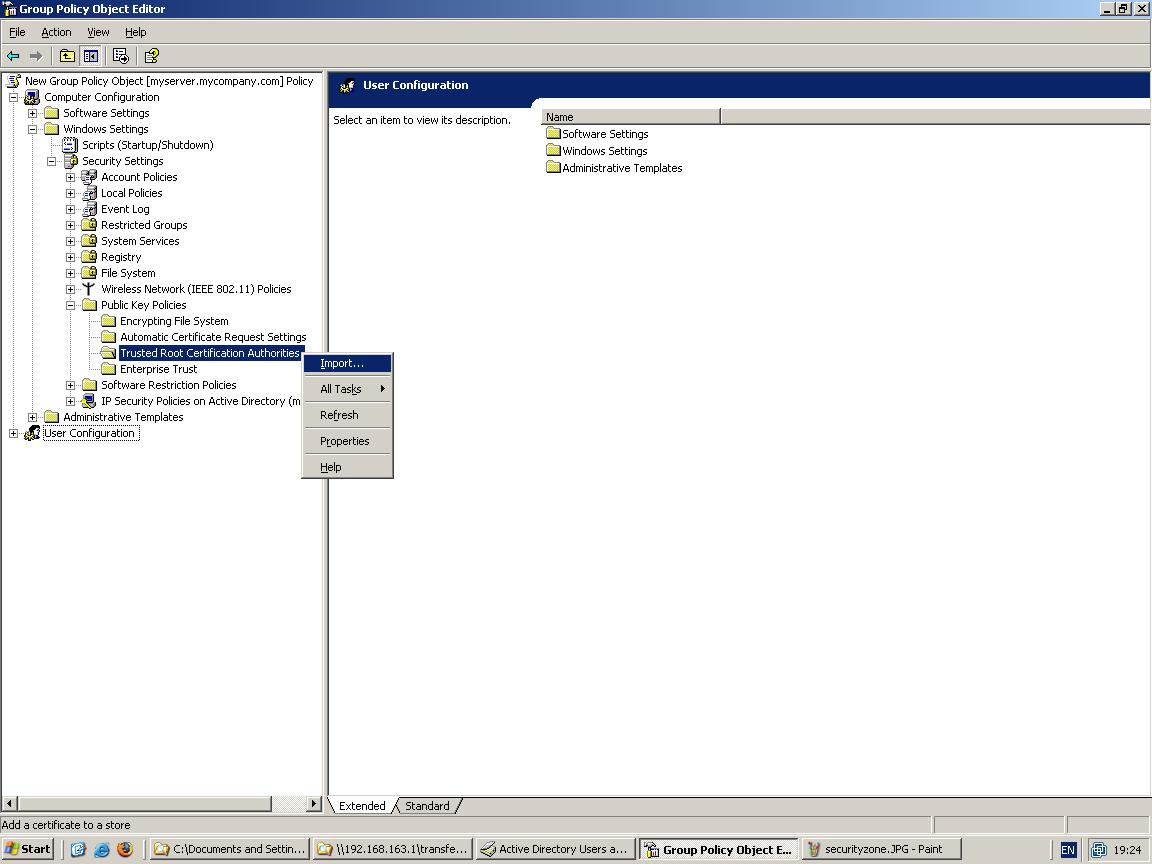
Select “Import the current security zones and privacy settings”. If prompted, click “Continue”. Then click “Modify Settings”.
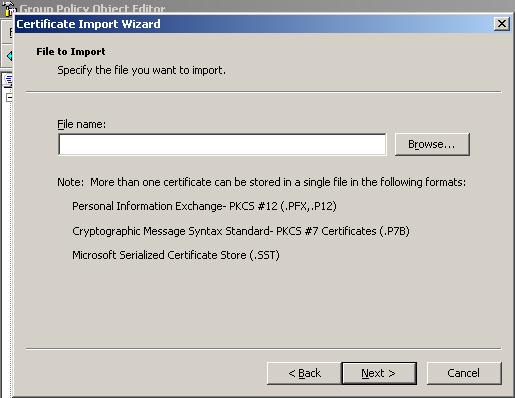
The zone “Internet” is selected by default. Switch to the zone “Local Intranet”. Then click on “Sites”. In some cases, a dialogue will open where you can define which sites belong to the Local Intranet zone. Click on “Advanced”. You can now add the Web Client address. Enter one address for the HTTP protocol and one for the HTTPS protocol (e.g. http://myserver.mycompany.com and https://myserver.mycompany.com).
To add the certificate for Mindbreeze InSpire into the list of the Trusted Root Certification Authorities, navigate down to Computer Configuration > Windows Settings > Security Settings > Public Key Policies > Trusted Root Certification Authorities. Right-click on this option and select “Import”.

In the “Certificate Import Wizard”, browse to the location of the Mindbreeze Certificate called camindbreeze.pem that is located in the installation directory of the Mindbreeze InSpire Node (e.g. /var/opt/lindbreeze/lib/store.). Confirm all open dialogs and wizards.

Now Mindbreeze MES Server Authority should be shown in the list of Trusted Root Certification Authorities. Close all open dialogs and windows of the snap-in.
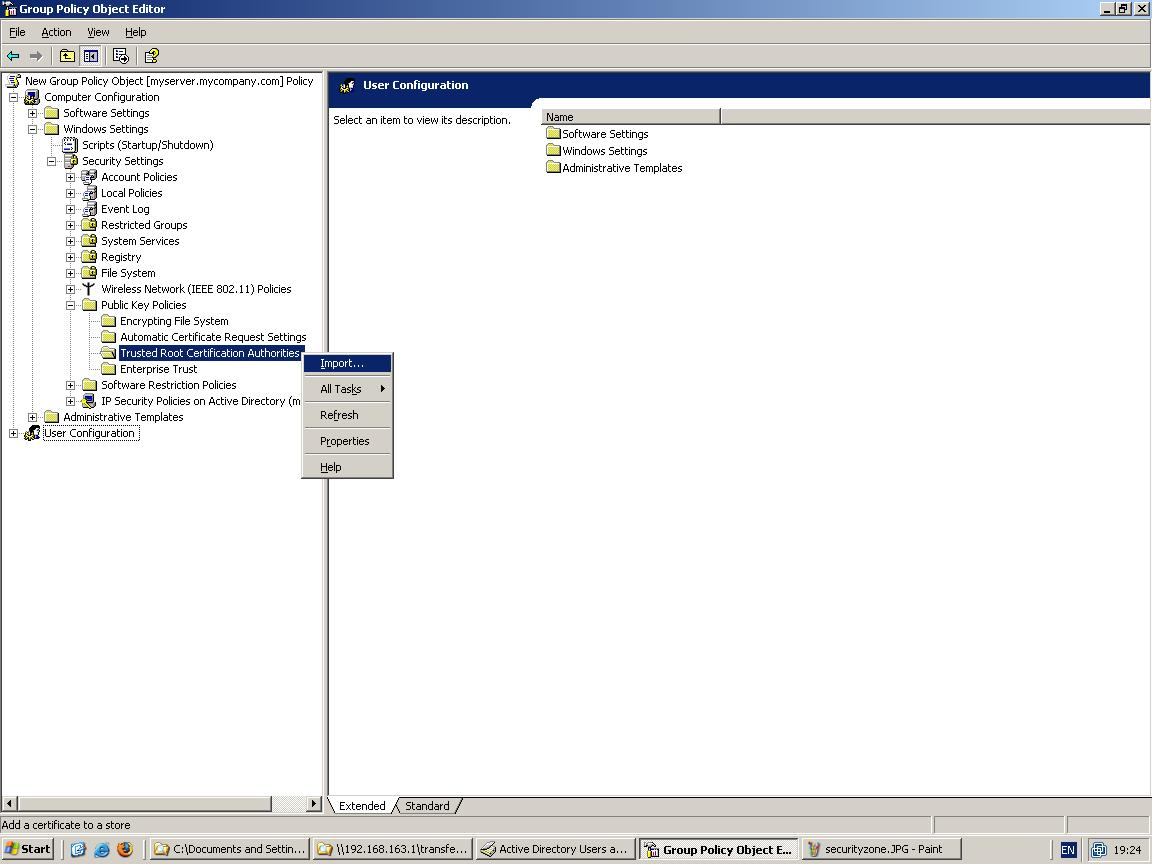
Restart the client computers for changes to take effect. After that the Mindbreeze InSpire Web Client should work without restrictions.
Appendix D
Installation of Fabasoft app.telemetry Log Pools for Mindbreeze
Downloading the Log Definitions
The Fabasoft app.telemetry log definitions for the Mindbreeze services can be downloaded from the Mindbreeze configuration console by clicking on the Link “Fabasoft app.telemetry log definitions and Dashboards” on the “Overview” tab of the Configuration UI.
After downloading and extracting the archive apptelemetryconfig.zip, the Fabasoft app.telemetry log definitions are located in a folder named “Logdefinitions”. Here you can find the following files:
- apptelemetrylogdefinitions_clientservice.xml: log definition file for Mindbreeze Client Services;
- apptelemetrylogdefinitions_client.xml: log definition file for the Mindbreeze JavaScript Clients;
- apptelemetrylogdefinitions_contentfilterservice.xml: log definition file for Mindbreeze Content Filter Services;
- apptelemetrylogdefinitions_crawlerservice.xml: log definition file for the Mindbreeze Crawler Services;
- apptelemetrylogdefinitions_filterservice.xml: log definition file for Mindbreeze Filter Services;
- apptelemetrylogdefinitions_indexservice.xml: log definition file for Mindbreeze Index Services;
- apptelemetrylogdefinitions_jobsyncservice.xml: log definition file for the Mindbreeze JobSync Services (used for Mindbreeze InSite installations);
- apptelemetrylogdefinitions_networkrequests.xml: log definition file for a network requests log pool for Mindbreeze Web Crawlers;
- apptelemetrylogdefinitions_queryservice.xml: log definition file for Mindbreeze Query Services;
- apptelemetrylogdefinitions_sdkcsandbox.xml: log definition file for the Mindbreeze SDKCsandbox services;
- apptelemetrylogdefinitions_tenantqueryservice.xml: additional log definition for multitenant Query services.
Creating Log Pools for the Mindbreeze Services in Fabasoft app.telemetry
Defining Log Pools for the Mindbreeze services can be accomplished following the steps described here:
In the “Log Pool Properties” tab of the log pool configurations the following “Application Filter” parameters should be set correctly for the Mindbreeze log pools:
- Application: Mindbreeze
- Application Tier:
- “Client” for Mindbreze Client log pool
- “Client Service” for Mindbreeze Client Service Log pools
- “Client Service Query Log” for Mindbreeze Client Service Query Log - Log pools
- “Content Filter Service” for Content Fitler Service log pools
- “Index Service” for Index Service log pools
- “Query Service” for Query Service log pools
- “Sandbox” for SDKCsandbox Service log pools.
Appendix E
Extended cron expressions
With an extended cron expression you can define when or in which intervals a task should be executed. This has the advantage that the task is executed automatically instead of having to execute it manually each time.
Format and syntax
Basically, an extended cron expression consists of 6 fields:
1. field | 2. field | 3. field | 4. field | 5. field | 6. field | |
Field name | Seconds | Minutes | Hours | Day of month | Month | Day of week |
Valid values | 0-59 | 0-59 | 0-23 | 1-31 | 1-12 oder | 0-6 oder |
The fields are each separated by a space and look like this (X is a placeholder for a field):
X X X X X X
Examples
0 0 12 * * * | Daily at 12:00 am |
0 15 10 * * * | Daily at 10:15 am |
20 15 10 * * * | Daily at 10:15:20 am |
0 15 10 * * 0 | Every Sunday at 10:15 am |
0 15 10 * * SUN | Every Sunday at 10:15 am |
0 15 10 2 4 * | Every 2nd April at 10:15 am |
0 15 10 * 4 * | Every day in April at 10:15 am |
0 15 10 7 * * | On every 7th day of the month at 10:15 am |
Appendix F
List of supported time zones
Africa/Abidjan, Africa/Accra, Africa/Addis_Ababa, Africa/Algiers, Africa/Asmara, Africa/Asmera, Africa/Bamako, Africa/Bangui, Africa/Banjul, Africa/Bissau, Africa/Blantyre, Africa/Brazzaville, Africa/Bujumbura, Africa/Cairo, Africa/Casablanca, Africa/Ceuta, Africa/Conakry, Africa/Dakar, Africa/Dar_es_Salaam, Africa/Djibouti, Africa/Douala, Africa/El_Aaiun, Africa/Freetown, Africa/Gaborone, Africa/Harare, Africa/Johannesburg, Africa/Juba, Africa/Kampala, Africa/Khartoum, Africa/Kigali, Africa/Kinshasa, Africa/Lagos, Africa/Libreville, Africa/Lome, Africa/Luanda, Africa/Lubumbashi, Africa/Lusaka, Africa/Malabo, Africa/Maputo, Africa/Maseru, Africa/Mbabane, Africa/Mogadishu, Africa/Monrovia, Africa/Nairobi, Africa/Ndjamena, Africa/Niamey, Africa/Nouakchott, Africa/Ouagadougou, Africa/Porto-Novo, Africa/Sao_Tome, Africa/Timbuktu, Africa/Tripoli, Africa/Tunis, Africa/Windhoek, America/Adak, America/Anchorage, America/Anguilla, America/Antigua, America/Araguaina, America/Argentina/Buenos_Aires, America/Argentina/Catamarca, America/Argentina/ComodRivadavia, America/Argentina/Cordoba, America/Argentina/Jujuy, America/Argentina/La_Rioja, America/Argentina/Mendoza, America/Argentina/Rio_Gallegos, America/Argentina/Salta, America/Argentina/San_Juan, America/Argentina/San_Luis, America/Argentina/Tucuman, America/Argentina/Ushuaia, America/Aruba, America/Asuncion, America/Atikokan, America/Atka, America/Bahia, America/Bahia_Banderas, America/Barbados, America/Belem, America/Belize, America/Blanc-Sablon, America/Boa_Vista, America/Bogota, America/Boise, America/Buenos_Aires, America/Cambridge_Bay, America/Campo_Grande, America/Cancun, America/Caracas, America/Catamarca, America/Cayenne, America/Cayman, America/Chicago, America/Chihuahua, America/Coral_Harbour, America/Cordoba, America/Costa_Rica, America/Creston, America/Cuiaba, America/Curacao, America/Danmarkshavn, America/Dawson, America/Dawson_Creek, America/Denver, America/Detroit, America/Dominica, America/Edmonton, America/Eirunepe, America/El_Salvador, America/Ensenada, America/Fort_Nelson, America/Fort_Wayne, America/Fortaleza, America/Glace_Bay, America/Godthab, America/Goose_Bay, America/Grand_Turk, America/Grenada, America/Guadeloupe, America/Guatemala, America/Guayaquil, America/Guyana, America/Halifax, America/Havana, America/Hermosillo, America/Indiana/Indianapolis, America/Indiana/Knox, America/Indiana/Marengo, America/Indiana/Petersburg, America/Indiana/Tell_City, America/Indiana/Vevay, America/Indiana/Vincennes, America/Indiana/Winamac, America/Indianapolis, America/Inuvik, America/Iqaluit, America/Jamaica, America/Jujuy, America/Juneau, America/Kentucky/Louisville, America/Kentucky/Monticello, America/Knox_IN, America/Kralendijk, America/La_Paz, America/Lima, America/Los_Angeles, America/Louisville, America/Lower_Princes, America/Maceio, America/Managua, America/Manaus, America/Marigot, America/Martinique, America/Matamoros, America/Mazatlan, America/Mendoza, America/Menominee, America/Merida, America/Metlakatla, America/Mexico_City, America/Miquelon, America/Moncton, America/Monterrey, America/Montevideo, America/Montreal, America/Montserrat, America/Nassau, America/New_York, America/Nipigon, America/Nome, America/Noronha, America/North_Dakota/Beulah, America/North_Dakota/Center, America/North_Dakota/New_Salem, America/Ojinaga, America/Panama, America/Pangnirtung, America/Paramaribo, America/Phoenix, America/Port-au-Prince, America/Port_of_Spain, America/Porto_Acre, America/Porto_Velho, America/Puerto_Rico, America/Rainy_River, America/Rankin_Inlet, America/Recife, America/Regina, America/Resolute, America/Rio_Branco, America/Rosario, America/Santa_Isabel, America/Santarem, America/Santiago, America/Santo_Domingo, America/Sao_Paulo, America/Scoresbysund, America/Shiprock, America/Sitka, America/St_Barthelemy, America/St_Johns, America/St_Kitts, America/St_Lucia, America/St_Thomas, America/St_Vincent, America/Swift_Current, America/Tegucigalpa, America/Thule, America/Thunder_Bay, America/Tijuana, America/Toronto, America/Tortola, America/Vancouver, America/Virgin, America/Whitehorse, America/Winnipeg, America/Yakutat, America/Yellowknife, Antarctica/Casey, Antarctica/Davis, Antarctica/DumontDUrville, Antarctica/Macquarie, Antarctica/Mawson, Antarctica/McMurdo, Antarctica/Palmer, Antarctica/Rothera, Antarctica/South_Pole, Antarctica/Syowa, Antarctica/Troll, Antarctica/Vostok, Arctic/Longyearbyen, Asia/Aden, Asia/Almaty, Asia/Amman, Asia/Anadyr, Asia/Aqtau, Asia/Aqtobe, Asia/Ashgabat, Asia/Ashkhabad, Asia/Baghdad, Asia/Bahrain, Asia/Baku, Asia/Bangkok, Asia/Barnaul, Asia/Beirut, Asia/Bishkek, Asia/Brunei, Asia/Calcutta, Asia/Chita, Asia/Choibalsan, Asia/Chongqing, Asia/Chungking, Asia/Colombo, Asia/Dacca, Asia/Damascus, Asia/Dhaka, Asia/Dili, Asia/Dubai, Asia/Dushanbe, Asia/Gaza, Asia/Harbin, Asia/Hebron, Asia/Ho_Chi_Minh, Asia/Hong_Kong, Asia/Hovd, Asia/Irkutsk, Asia/Istanbul, Asia/Jakarta, Asia/Jayapura, Asia/Jerusalem, Asia/Kabul, Asia/Kamchatka, Asia/Karachi, Asia/Kashgar, Asia/Kathmandu, Asia/Katmandu, Asia/Khandyga, Asia/Kolkata, Asia/Krasnoyarsk, Asia/Kuala_Lumpur, Asia/Kuching, Asia/Kuwait, Asia/Macao, Asia/Macau, Asia/Magadan, Asia/Makassar, Asia/Manila, Asia/Muscat, Asia/Nicosia, Asia/Novokuznetsk, Asia/Novosibirsk, Asia/Omsk, Asia/Oral, Asia/Phnom_Penh, Asia/Pontianak, Asia/Pyongyang, Asia/Qatar, Asia/Qyzylorda, Asia/Rangoon, Asia/Riyadh, Asia/Saigon, Asia/Sakhalin, Asia/Samarkand, Asia/Seoul, Asia/Shanghai, Asia/Singapore, Asia/Srednekolymsk, Asia/Taipei, Asia/Tashkent, Asia/Tbilisi, Asia/Tehran, Asia/Tel_Aviv, Asia/Thimbu, Asia/Thimphu, Asia/Tokyo, Asia/Tomsk, Asia/Ujung_Pandang, Asia/Ulaanbaatar, Asia/Ulan_Bator, Asia/Urumqi, Asia/Ust-Nera, Asia/Vientiane, Asia/Vladivostok, Asia/Yakutsk, Asia/Yekaterinburg, Asia/Yerevan, Atlantic/Azores, Atlantic/Bermuda, Atlantic/Canary, Atlantic/Cape_Verde, Atlantic/Faeroe, Atlantic/Faroe, Atlantic/Jan_Mayen, Atlantic/Madeira, Atlantic/Reykjavik, Atlantic/South_Georgia, Atlantic/St_Helena, Atlantic/Stanley, Australia/ACT, Australia/Adelaide, Australia/Brisbane, Australia/Broken_Hill, Australia/Canberra, Australia/Currie, Australia/Darwin, Australia/Eucla, Australia/Hobart, Australia/LHI, Australia/Lindeman, Australia/Lord_Howe, Australia/Melbourne, Australia/NSW, Australia/North, Australia/Perth, Australia/Queensland, Australia/South, Australia/Sydney, Australia/Tasmania, Australia/Victoria, Australia/West, Australia/Yancowinna, Brazil/Acre, Brazil/DeNoronha, Brazil/East, Brazil/West, CET, CST6CDT, Canada/Atlantic, Canada/Central, Canada/East-Saskatchewan, Canada/Eastern, Canada/Mountain, Canada/Newfoundland, Canada/Pacific, Canada/Saskatchewan, Canada/Yukon, Chile/Continental, Chile/EasterIsland, Cuba, EET, EST5EDT, Egypt, Eire, Etc/GMT, Etc/GMT+0, Etc/GMT+1, Etc/GMT+10, Etc/GMT+11, Etc/GMT+12, Etc/GMT+2, Etc/GMT+3, Etc/GMT+4, Etc/GMT+5, Etc/GMT+6, Etc/GMT+7, Etc/GMT+8, Etc/GMT+9, Etc/GMT-0, Etc/GMT-1, Etc/GMT-10, Etc/GMT-11, Etc/GMT-12, Etc/GMT-13, Etc/GMT-14, Etc/GMT-2, Etc/GMT-3, Etc/GMT-4, Etc/GMT-5, Etc/GMT-6, Etc/GMT-7, Etc/GMT-8, Etc/GMT-9, Etc/GMT0, Etc/Greenwich, Etc/UCT, Etc/UTC, Etc/Universal, Etc/Zulu, Europe/Amsterdam, Europe/Andorra, Europe/Astrakhan, Europe/Athens, Europe/Belfast, Europe/Belgrade, Europe/Berlin, Europe/Bratislava, Europe/Brussels, Europe/Bucharest, Europe/Budapest, Europe/Busingen, Europe/Chisinau, Europe/Copenhagen, Europe/Dublin, Europe/Gibraltar, Europe/Guernsey, Europe/Helsinki, Europe/Isle_of_Man, Europe/Istanbul, Europe/Jersey, Europe/Kaliningrad, Europe/Kiev, Europe/Kirov, Europe/Lisbon, Europe/Ljubljana, Europe/London, Europe/Luxembourg, Europe/Madrid, Europe/Malta, Europe/Mariehamn, Europe/Minsk, Europe/Monaco, Europe/Moscow, Europe/Nicosia, Europe/Oslo, Europe/Paris, Europe/Podgorica, Europe/Prague, Europe/Riga, Europe/Rome, Europe/Samara, Europe/San_Marino, Europe/Sarajevo, Europe/Simferopol, Europe/Skopje, Europe/Sofia, Europe/Stockholm, Europe/Tallinn, Europe/Tirane, Europe/Tiraspol, Europe/Ulyanovsk, Europe/Uzhgorod, Europe/Vaduz, Europe/Vatican, Europe/Vienna, Europe/Vilnius, Europe/Volgograd, Europe/Warsaw, Europe/Zagreb, Europe/Zaporozhye, Europe/Zurich, GB, GB-Eire, GMT, GMT0, Greenwich, Hongkong, Iceland, Indian/Antananarivo, Indian/Chagos, Indian/Christmas, Indian/Cocos, Indian/Comoro, Indian/Kerguelen, Indian/Mahe, Indian/Maldives, Indian/Mauritius, Indian/Mayotte, Indian/Reunion, Iran, Israel, Jamaica, Japan, Kwajalein, Libya, MET, MST7MDT, Mexico/BajaNorte, Mexico/BajaSur, Mexico/General, NZ, NZ-CHAT, Navajo, PRC, PST8PDT, Pacific/Apia, Pacific/Auckland, Pacific/Bougainville, Pacific/Chatham, Pacific/Chuuk, Pacific/Easter, Pacific/Efate, Pacific/Enderbury, Pacific/Fakaofo, Pacific/Fiji, Pacific/Funafuti, Pacific/Galapagos, Pacific/Gambier, Pacific/Guadalcanal, Pacific/Guam, Pacific/Honolulu, Pacific/Johnston, Pacific/Kiritimati, Pacific/Kosrae, Pacific/Kwajalein, Pacific/Majuro, Pacific/Marquesas, Pacific/Midway, Pacific/Nauru, Pacific/Niue, Pacific/Norfolk, Pacific/Noumea, Pacific/Pago_Pago, Pacific/Palau, Pacific/Pitcairn, Pacific/Pohnpei, Pacific/Ponape, Pacific/Port_Moresby, Pacific/Rarotonga, Pacific/Saipan, Pacific/Samoa, Pacific/Tahiti, Pacific/Tarawa, Pacific/Tongatapu, Pacific/Truk, Pacific/Wake, Pacific/Wallis, Pacific/Yap, Poland, Portugal, ROK, Singapore, SystemV/AST4, SystemV/AST4ADT, SystemV/CST6, SystemV/CST6CDT, SystemV/EST5, SystemV/EST5EDT, SystemV/HST10, SystemV/MST7, SystemV/MST7MDT, SystemV/PST8, SystemV/PST8PDT, SystemV/YST9, SystemV/YST9YDT, Turkey, UCT, US/Alaska, US/Aleutian, US/Arizona, US/Central, US/East-Indiana, US/Eastern, US/Hawaii, US/Indiana-Starke, US/Michigan, US/Mountain, US/Pacific, US/Pacific-New, US/Samoa, UTC, Universal, W-SU, WET, Zulu, EST, HST, MST, ACT, AET, AGT, ART, AST, BET, BST, CAT, CNT, CST, CTT, EAT, ECT, IET, IST, JST, MIT, NET, NST, PLT, PNT, PRT, PST, SST, VST
Appendix G
Mindbreeze provides the possibility to use custom trained models, and custom catalogs for stop words and entity recognition for example.
To use Custom resources, a particular naming convention and folder structure must be used:
|-----parent_folder [Folder]
|------------model_names [Folder]
|------------current_version.json [File]
|------------current_version [Folder]
|-------------------model [File]
Naming conventions for Custom Models and Catalogs
parent_folder [Folder]:
Can be any name allowed by the OS, can contain any number of supported models. This is the folder path that needs to be provided for the index configuration.
model_names [Folder]:
This is a folder that is named after the containing models .
Model names must follow the following naming convention:
Resource type | Naming guideline | Description |
Compound Splitting Models | mindbreeze.models.nlp.char_ngram_hash_profile.wikipedia.<language> | language is the language code for the model (e.g. “en” or “de”). These models are used for compound splitting. Model files of this type must have a proto.bin extension. |
NER Entity Catalogs | mindbreeze.catalogues.nlp.lowercased_word_type.entity.<entityType> | entityType is one of the recognized entity types: location, organization, person, misc. Only words contained in this catalog will be recognized as entities. This can be used as a measure to reduce false positives. This is relevant for NER highlighting and Aggregation. Resource files of this type must have a .csv extension |
NER Stop Words Catalogs | mindbreeze.catalogs.nlp.stop_words.<langage> | language is the language code for the catalog (e.g. “en” or “de”). The words in these catalogs are ignored when doing NER processing. This is used to reduce false positives. Resource files of this type must have a .txt extension |
Stop Words Catalogs | mindbreeze.catalogs.nlp.lowercased_stop_words.<language> | language is the language of the catalog. Words in these catalogs are ignored by normal highlighting and "Did you mean". Resource files of this type must have a .txt extension |
current_version.json [File]:
as there could be many versions of models, this json file indicates which model version to load. This file must exist in the folder structure.
This file should contain the current version of the model to load, as follows:
{
"current_version": "<version>"
}
version can be 1.0.0 for example.
version_folder [Folder]:
This folder is named after the version of the model in question, 1.0.0 for example.
model_file [File]:
This is the model file to load. The file name and extension needs to follow the naming convention described above.