
Sure, you can handle it. But should you?
Let our experts manage the tech maintenance while you focus on your business.
Let our experts manage the tech maintenance while you focus on your business.
Atlassian Confluence Connector
Installation and Configuration
Installation
Before you install the Atlassian Confluence Connector plugin, you need to ensure that the Mindbreeze server is installed and that this connector is also included in the Mindbreeze license. The Atlassian Confluence Connector is installed by default on the Mindbreeze InSpire server. If you want to install or update the connector manually, use the Mindbreeze Management Center.
Mindbreeze Configuration
Index and Crawler Configuration
When prompted to choose an installation method, select "Advanced".
Click on the "Indices" tab and then on the "Add new index" icon to create a new index.
Enter the index path, e.g. "/data/indices/confluence". If necessary, adjust the Display Name of the Index Service and the associated Filter Service.
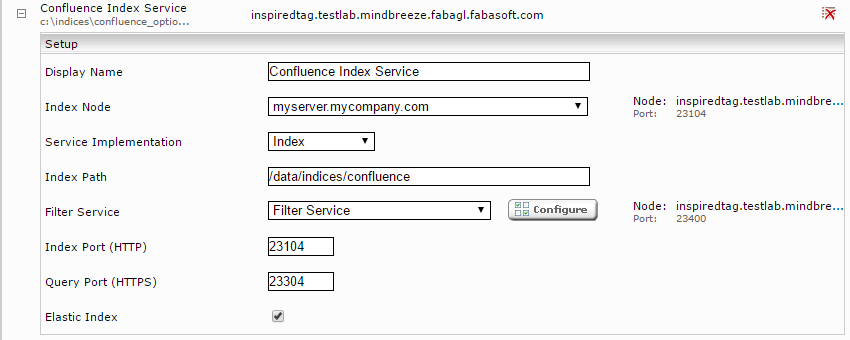
Add a new data source using the symbol "Add new custom source" on the lower right.
If not already selected, select "Atlassian Confluence" using the "Category" button.
With the "Crawler Interval" setting, you configure the amount of time that elapses between two indexing runs.
Web Page
The “Crawling Root” field allows you to specify an URL, via which an Atlassian Confluence sitemap is accessible. If you have the Mindbreeze Sitemap Generator add-on installed on your Atlassian Confluence server and a sitemap is generated, enter the URL <Atlassian Confluence URL>/plugins/servlet/sitemapservlet?jobbased=true.
The field "URL Regex" lets you define a regular expression, which sets a pattern for the links which are to be indexed.
If certain URLs should be excluded from the crawl, they can be configured using a regular expression under "URL Exclude Pattern".
With the option "Include URL By Metadata" or "Exclude URL by Metadata", certain pages can be excluded when crawling with sitemaps based on the metadata in the sitemap. The Metadata Name field specifies the metadata name and the Pattern field specifies the regular expression against which the metadata value is matched.
If "URL Regex", "URL Exclude Pattern" and "Include/Exclude URL by Metadata" are used simultaneously, "URL Regex" is applied first, then the pages are excluded with "URL Exclude Pattern" and finally the remaining pages are filtered with "Include/Exclude URL by Metadata".
With the option „Convert URL-s to lower case“, all located URLs will be converted to lower case.
If the DNS resolution of certain Web servers doesn’t work due to a problem with the network, you can specify the IPs using "Additional Hosts File".
Use the "Accept Headers" setting if you want to add specific HTTP headers (for example, Accept-Language).
If Confluence sitemaps are crawled, you can use the option “Use Rest API for Page Content” to obtain content from pages in a performance-friendly way and without running macros.
You can set the option „Confluence Rest API Base Path“ if the Confluence REST-API is reachable on this path.
The option "Confluence Rest Content Representation" can be used to determine in which format the content of the Confluence pages should be fetched. The default value "Storage" is performance-friendly, since no macros are executed on the Confluence service, but the content may be incomplete or incorrect in certain situations. The "Export View" option executes macros, which can result in improved rendering, but may affect performance. For more information on these options, see https://docs.atlassian.com/atlassian-confluence/6.5.2/com/atlassian/confluence/api/model/content/ContentRepresentation.html.
The "Confluence Rest Content Extension" option can be used to determine the extension of the indexed Mindbreeze documents. This has an influence on the specific filter that is used.
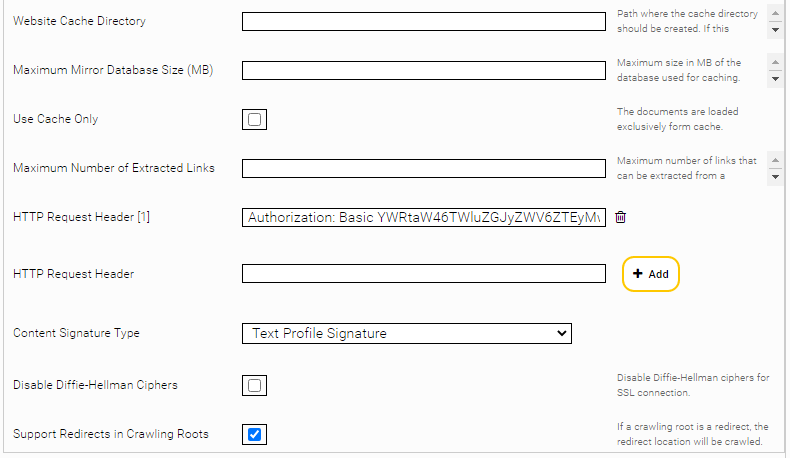
In order to actually prevent the use of macros, HTML thumbnailing should also be disabled. If the option “Disable Web Page Thumbnail Generation” is enabled, the metadata “htmlfilter:skipthumbnailgneneration” is set on all documents. Additional options have to be configured in the filter service (see paragraph after screenshot).
The “Max Retries” option determines how often the connector tries to download a document when temporary errors (e.g. socket timeouts) occur. The default value is 0. (No further download attempts). If you are crawling across an unstable network (that causes timeouts), this value should be increased to 10, for example. If the timeouts are caused by an overloaded data source, the value should be left at 0 so that the data source is not loaded even further.
The “Retry Delay Seconds” option determines the waiting time (in seconds) between download attempts (see "Max Retries"). The default value is 1.

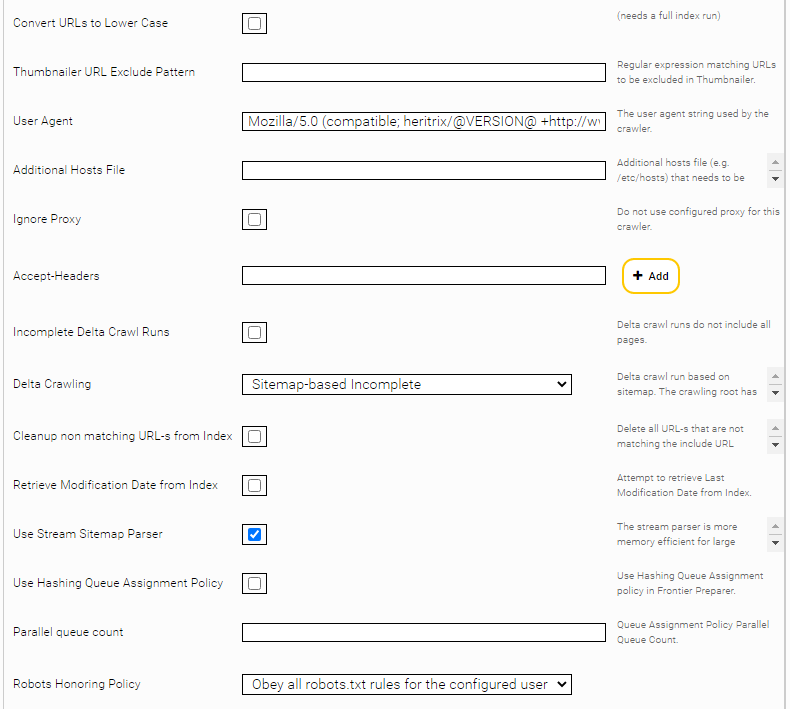
To disable HTML thumbnailing, set the option “Disable Thumbnails Metadata Pattern” to “htmlfilter:skipthumbnailgeneration” in the filter service for the filter plugin “JerichoWithThumbnails.” This will index the HTML documents without thumbnails where the metadata “htmlfilter:skipthumbnailgeneration” is set.
Sitemap-based Crawling
To edit Confluence sitemaps, activate "Delta Crawling" and enter the Confluence sitemap URL as the crawling root.
In this mode, the Connector reads the websites solely from the sitemaps. Here the property lastmod of the pages of the site map is compared with the indexed pages. Very high frequency indexing strategies can be applied using a precise sitemap.
For the "Sitemap-based Delta Crawling" mode, two options are available:
- „Sitemap Based Incomplete“: the URLs of the configured sitemaps are indexed; documents which have already been indexed and are not included in the sitemaps remain in the index.
- „Sitemap Based Complete“: the URLs of the configured sitemaps are indexed; documents which have already been indexed and are not included in the sitemaps will be deleted.
The "Use Stream Parser" option uses a stream parser for processing the sitemap. This option is suitable for sitemaps with a lot of URLs.
Resource Parameters
In this section (available only when "Advanced Settings" is selected), the crawl speed can be adjusted.
Under "Number Of Crawler Threads", you can define how many threads simultaneously pick sites from the web server.
"Request Interval" defines the number of milliseconds the crawler (thread) waits between each single request. However, a "crawl-delay" robot command is always taken into consideration and will override this value.

Proxy
You can enter a proxy server in the "Network" tab if your infrastructure so requires.
Confluence Login
This chapter describes the various authentication methods for the Atlassian Confluence Connector. Therefore, the methods that can be used to index content that is located behind a login are highlighted in this chapter.
Basic Authorization
If the Atlassian Confluence sitemap and documents are accessible by HTTP basic authorization the header can be configured as “HTTP Request Header”.
Form Based Login
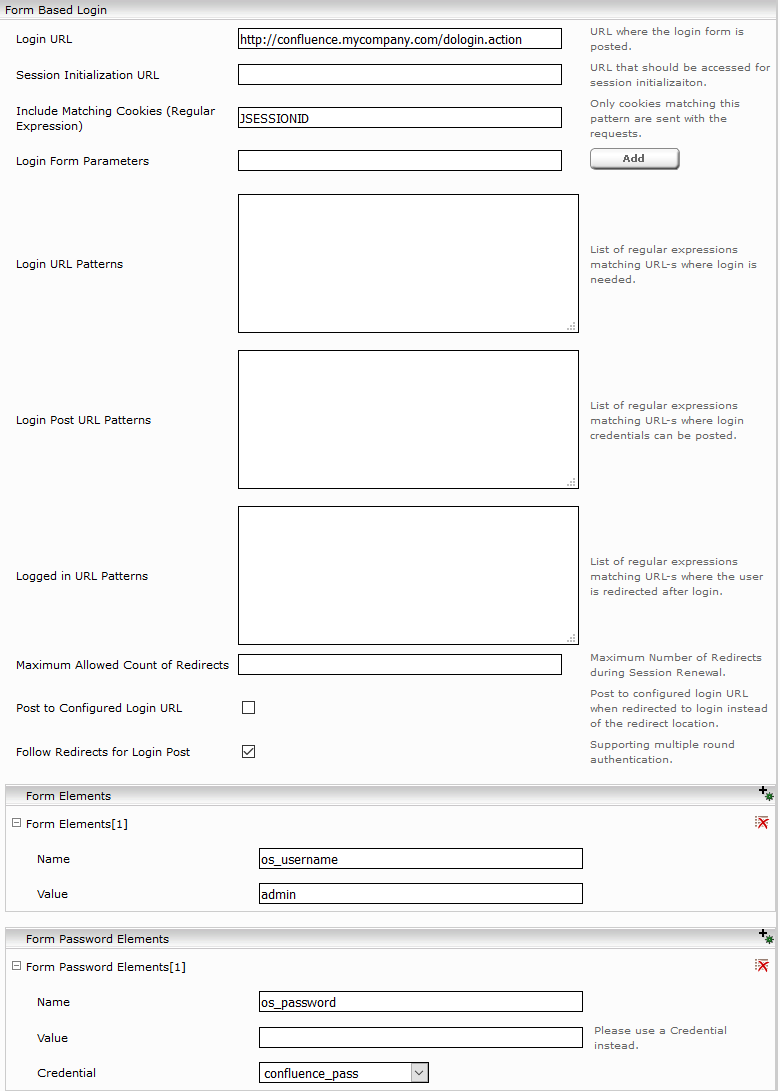
If the Atlassian Confluence sitemap is accessible by http form authentication, the login parameters in the "Form Based Login" section can be configured as follows:
- Login URL: the Atlassian Confluence URL to which the login form is to be sent: e.g. http://<confluence_url>/dologin.action
- Form Elements: an element with the name “os_username“ needs to be added here. The value (“Value”) should be the user name of the user who is authorized to download the sitemap.
- Form Password Elements: an element with the name “os_password“ needs to be added here. The value (“Value”) should be the password of the previously specified user.
- Include Matching Cookies (Regular Expression): If the http-request becomes to large because all cookies are included you choose the required cookies with this option.

The form-based authentication is only supported till Confluence version 8.
Complex form-based authentication
If the previous scenario is not sufficient, the following settings can be used:
- Session initialization URL: This URL is opened at the beginning so that it can then be dynamically redirected. The cookies received in the process are retained for the session.
- Login form parameters: If hidden fields are set in the login form, they can be listed here. They are extracted and sent along with the login request. A typical example of this is the dynamically generated FormID, which is returned as a hidden parameter from the Web server.
- Login form parameters: If hidden fields are set in the login form, they can be listed here. They are extracted and sent along with the login request. A typical example of this is the dynamically generated FormID, which is returned as a hidden parameter from the Web server.
- Login URL patterns: All redirects that correspond to the regular expressions specified here are tracked during the login process.
- Login post URL patterns: When tracking the redirects that correspond to the regular expressions specified here, all collected form parameters are sent using an HTTP POST request.
- Logged in URL patterns: If you are redirected to an URL that matches the regular expressions specified here, the login process was successful.
- Maximum allowed count of redirects: This can be used to set the maximum depth of the tracked redirects.
NTLM
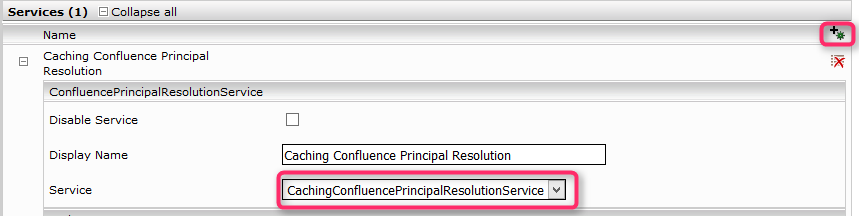
To use NTLM authentication, the user, the password, and the domain need to be configured as credentials in the Network tab first:
After this, this credential has to be selected in the Atlassian Confluence Connector in the "NTLM Credential” setting:
In the field “Mindbreeze InSpire Fully Qualified Domain Name,” the “Fully Qualified Domain Name” of the Mindbreeze InSpire server must be entered.

Note: When NTLM authentication is used, the thumbnails in Mindbreeze InSpire do not work.
NTLM authentication is only supported till Confluence version 8.
Configuring “Access Check Rules”
Access check rules are comprised of:
- “Access Check Principal,” the user names can be in the format “username@domain," “domain\username,” or “distinguished name.” The group names can only be in the distinguished name format. In addition, a reference to a capture group in the selection pattern can be used here.
- “Access Check Action,” grant or deny.
- “Metadata Key for Selection,” a metadata name; can be empty (all documents are selected)
- “Selection Pattern,” a regular expression; can be empty (all documents are selected).
Atlassian Confluence Principal Resolution
In the new or existing service, select the CachingConfluencePrincipalResolutionService option in the Service setting. For more information about additional configuration options and how to create a cache and how to do the basic configuration of a cache for a Principal Resolution Service, see Installation & Configuration - Caching Principal Resolution Service.
If the option is not visible, make sure that ConfluenceAccessx.x.x.zip has been installed in the Plugins tab.

Enter the "Confluence Server URL".
The necessary login information for accessing the "Confluence Server URL" needs to be configured in the "Network" tab and mapped to the "Confluence Server URL" endpoint.

Specify the directory path for the cache in the “Database Directory Path“ field and change the “Cache In Memory Items Size” if necessary, depending on the available memory capacity of the JVM. In the “Cache Update Interval (Minutes)“ field, specify the time (in minutes) that should elapse before the cache is updated. This time interval is ignored the first time the service is started. The next time the service is started, this time will be taken into account. The settings “Health Check Interval“, “Health Check max. Retries On Failure“ and “Heath Check Request Timeout“ allow this service to be restarted if, for instance, there are persistent connection problems.

If users cannot be resolved for a search query, a request will be sent directly to Confluence if the option "Suppress Confluence Service Calls" is not enabled. However, for performance reasons, it is recommended that you enable this option so that no live requests are made to Confluence.
Service Settings

Lowercase Principals | With this option, the principals from the cache are written in lowercase. This should be enabled if the connector returns principals in lower case. Warning: This option is disabled by default. |
Attention: Please do not change the default setting. For more information on the "Lowercase Principles" setting see Installation & Configuration - Caching Principal Resolution Service - Service Settings.
Confluence Settings
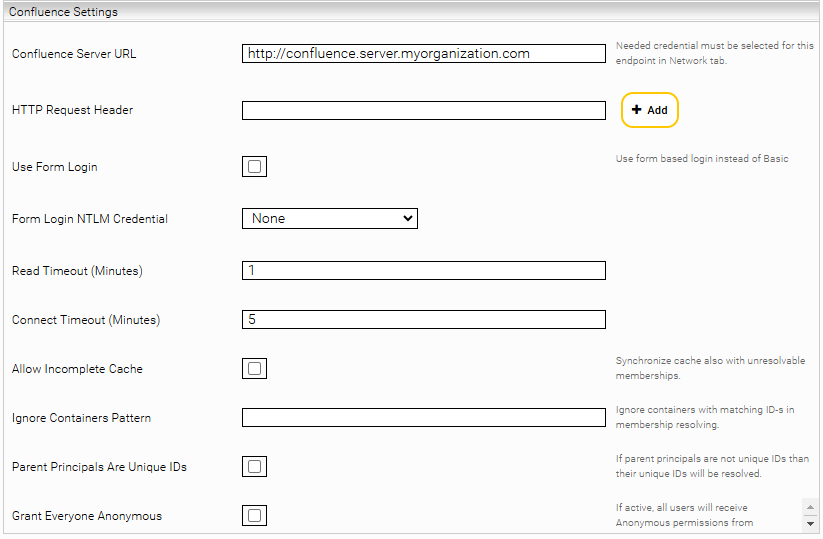
Confluence Server URL | The URL of the Confluence server, e.g. https://confluence.myorganization.com |
HTTP Request Header | Additional HTTP headers to be sent with each request. The format is HeaderName:HeaderValue |
Use Form Login | Is this option enabled, the service sends a login request to the Confluence server. Otherwise, a Basic Authentication header is used. |
Form Login NTLM Credential | The NTLM credential, as described in the section NTLM. |
Read Timeout (Minutes) | Defines the read timeout for outgoing connections. |
Connect Timeout (Minutes) | Defines the connect timeout for outgoing connections. |
Allow Incomplete Cache | If this option is activated, the principal resolution cache is updated even if the resolution of some groups fails. This can lead to inconsistencies between the Mindbreeze search and Confluence. Enable this option only to temporarily work around a persistent error. |
Ignore Containers Pattern | Regex pattern that defines which Confluence containers should not be resolved by the Principal Resolution Service. |
Parent Principals Are Unique IDs | This option must not be selected if the resolved user principals contain aliases. |
Grant Everyone Anonymous | When this option is enabled and access is permitted for anonymous Users under “Global Permissions” in Atlassian Confluence, all logged in users are treated as if they have global Atlassian Confluence usage rights. If this option is disabled, no access will be granted to anonymous users. Note: It is possible to configure Atlassian Confluence in a way, that logged in users do not have access to documents, but anonymous users do. In this case, if this setting is enabled, users might find more documents in Mindbreeze than in Atlassian Confluence. |
For additional information, see Installation & Configuration - Caching Principal Resolution Service.
Confluence Authorization Service
The Confluence Authorization Service sends requests to Confluence for each object during the search in order to find out whether the respective user actually has access to this object. Since this can take a lot of time, the Authorization Service should only be used for testing purposes. Normally, all Authorization Service checks have to be positive anyway. However, it is easy to find out if there are any problems with the permissions of certain objects.
In order for the Authorization Service to be used in the search, Advanced Settings must be activated and in the index the option "Approved Hits Reauthorize" must be set to "External Authorizer". Then, the created Authorization Service must be selected as the "Authorization Service" in the crawler.
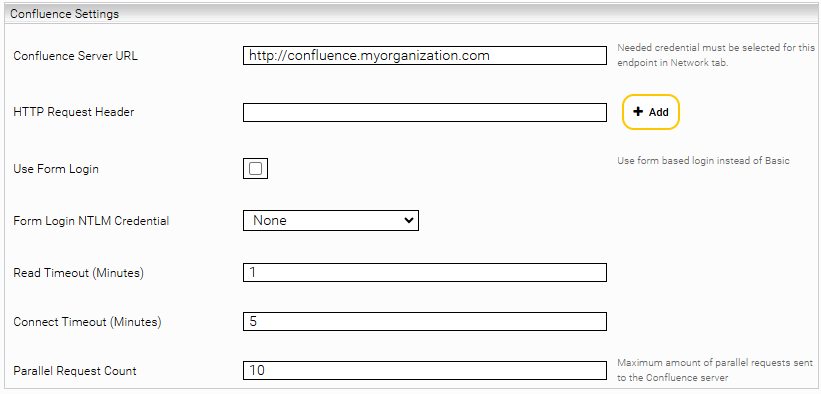
Confluence Settings
Confluence Server URL | The URL of the Confluence server, e.g. https://confluence.myorganization.com |
HTTP Request Header | Additional HTTP headers to be sent with each request. The format is HeaderName:HeaderValue |
Use Form Login | Is this option enabled, the service sends a login request to the Confluence server. Otherwise, a Basic Authentication header is used. |
Form Login NTLM Credential | The NTLM credential, as described in the section NTLM. |
Read Timeout (Minutes) | Defines the read timeout for outgoing connections. |
Connect Timeout (Minutes) | Defines the connect timeout for outgoing connections. |
Parallel Request Count | Defines the maximum number of requests sent to the Confluence server at the same time. |
Troubleshooting
Missing documents in the search due to the version of the Sitemap Generator
If it happens that documents can no longer be found, although they are present in the index, checking the logs of the Principal Resolution Service is recommended as the first step.
There, the following error message could be found in the logs:
"The installed version (x.x.x.x) of the Confluence Sitemap Generator is unsafe. Please upgrade to the newest version of the Sitemap Generator."
Is this the case, an unsafe version of the Sitemap Generator is installed. Therefore the Sitemap Generator must be upgraded to a safe version. Until the upgrade is done, it is likely that the search will no longer work.
Fixing status code 401 after password change
If all requests return status code 401, the crawler or the principal resolution service may have encountered Confluence's captcha security check.
This can happen, for example, if the password was changed and the service was not updated.
With the Captcha security checks the administrator can set a number of login attempts. Is that number exceeded, the user is forced to solve a captcha to log in.
This setting can be found at "<your-confluence-url>/admin/viewsecurityconfig.action".
There it is possible to disable or restrict the setting: "CAPTCHA on login".
To restart the service properly, the wrong password must be changed in the configuration and the captcha must be solved manually on the website.