
Sure, you can handle it. But should you?
Let our experts manage the tech maintenance while you focus on your business.
Let our experts manage the tech maintenance while you focus on your business.
Installation and Configuration
Data Integration Connector
Important Notice
The Talend Open Studio software product was discontinued on January 31, 2024. Therefore, the Data Integration Connector can no longer be further developed in its current form and will only receive maintenance updates.
For alternatives and questions regarding the maintenance of existing solutions, please contact Mindbreeze Support at support@mindbreeze.com.
Creating a “Data Integration Process“
The Data Integration Connector can be used together with Talend Open Studio to connect your own data sources. Talend Open Studio is available for download under https://www.talend.com/products/data-integration/data-integration-open-studio/.
Older versions can be downloaded from https://www.talend.com/products/data-integration-manuals-release-notes/. Please note that you do not use Milestone versions (with M1, M2, etc. at the end of the version number). These are beta versions which are often unstable.
Note: The Mindbreeze Java SDK supports Java version 11. It is possible that Talend Open Studio automatically installs a different Java version on your system, which can then lead to problems with the Mindbreeze Java SDK later on. Make sure that Java version 11 is installed and that the JAVA_HOME environment variable is set to the Java 11 JDK installation directory.
The Data Integration Connector contains components for Talend Open Studio, which will need to be installed separately. Unpack the file components-<<VERSION>>.zip from the Data Integration Connector installation package into any folder (e.g. C:\custom-talend-components-12.03.123\). We recommend to include the version number in the directory name.
Create a new project after installing Talend Open Studio.

Open Window -> Preferences in the Talend Open Studio menu:
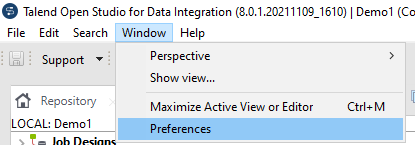
Select Talend -> Components and enter the name of the folder into which you unpacked the components in the field “User component folder”.
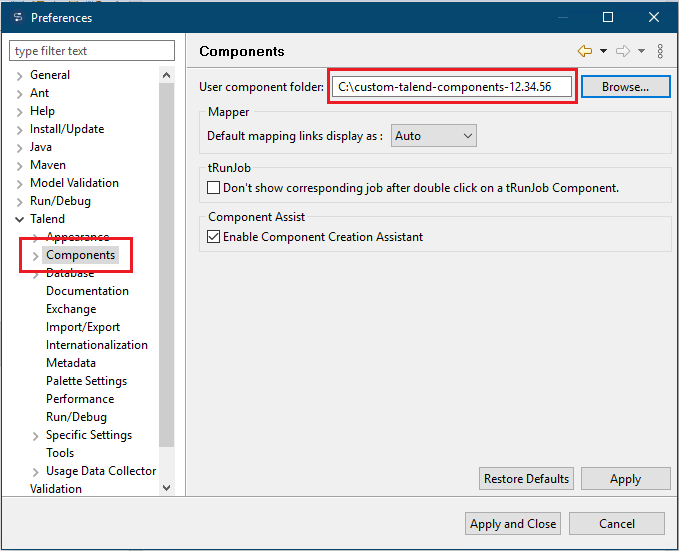
Select Import/Export Settings an activate the Option “Add classpath.jar in exported jobs”:
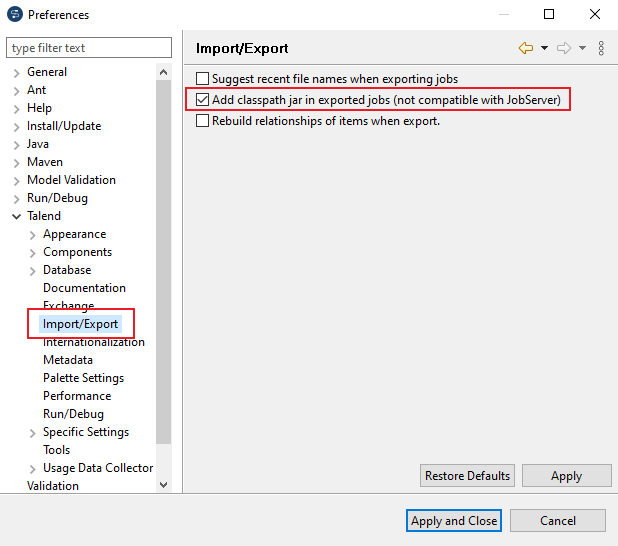
You can now create a new job. Add data sources according to your requirements. More information about working with Talend Open Studio is available in the Talend Open Studio documentation.
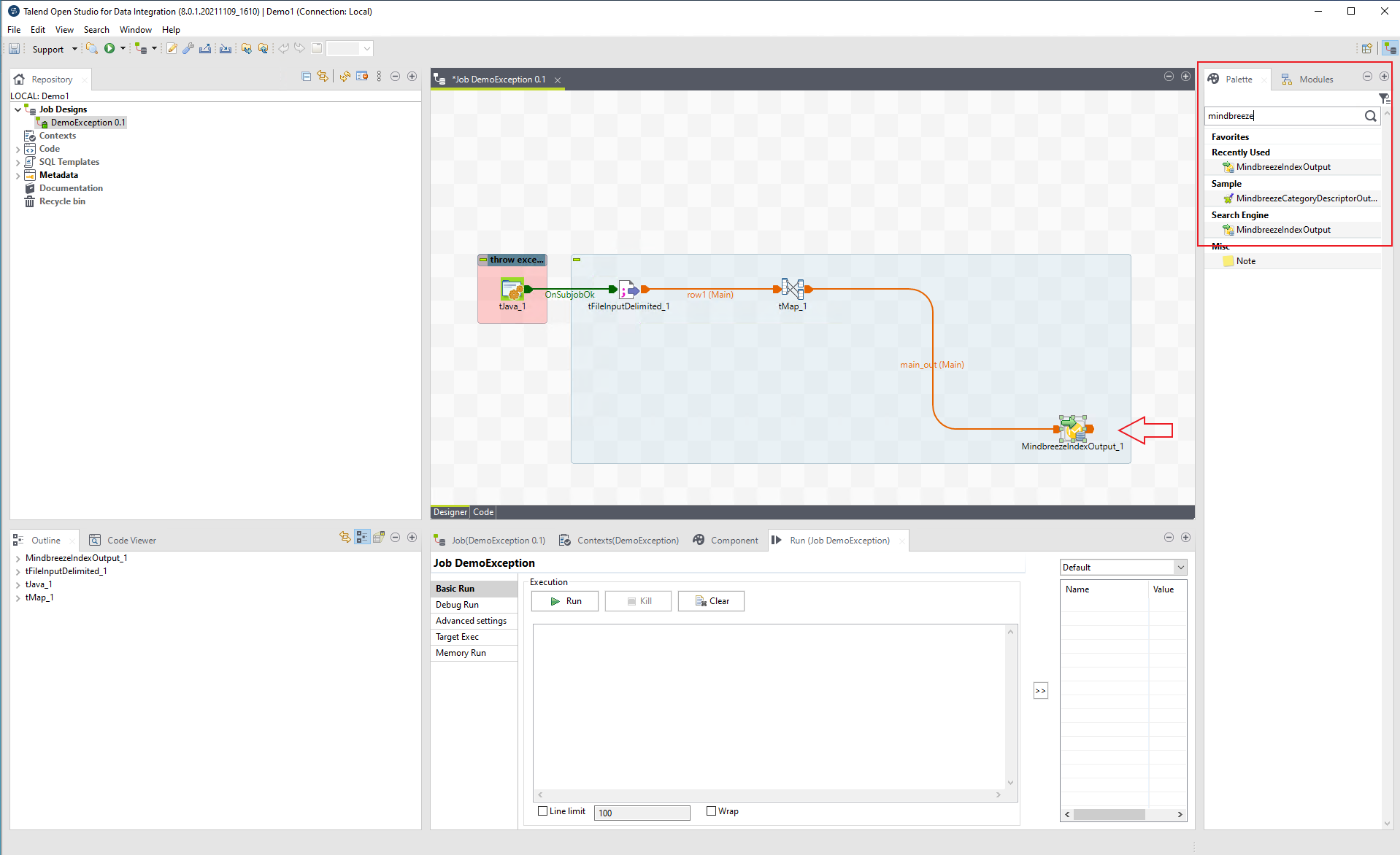
The target of this kind of processing chain must always be the component named "MindbreezeIndexOutput".
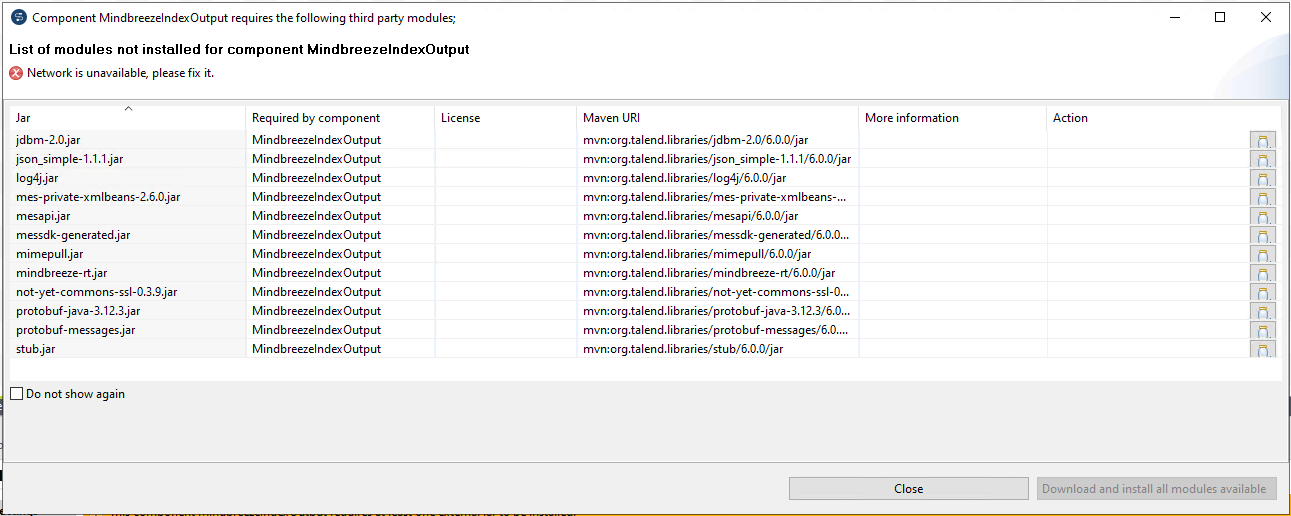
Troubleshooting - Dependencies
In recent versions of Talend Open Studio, dependencies may not be detected automatically:
![]()
In this case the JAR file dependencies have to be resolved manually:
- Click button “Install…”
- Click on each
 -Symbol
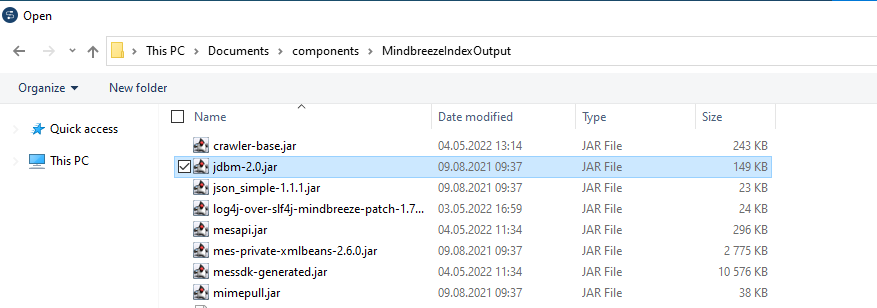
-Symbol - Assign JARs with matching name in the folder MindbreezeIndexOutput
Updating the Mindbreeze Components
To achieve seamless operation, we recommend that you always update the Mindbreeze Components to the same version as the Mindbreeze InSpire version you are using. The update works similar to the initial configuration, but requires additional steps.
- As explained in the section "Configuring Mindbreeze User Components", download the Mindbreeze Components from the Mindbreeze website and unpack the "components-<<VERSION>>.zip" archive. E.g. to the location "C:\custom-talend-components-12.03.123".
It is recommended to change the path of the User Component folder in the Talend Settings after each update or to always use the version number in the path. This is because Talend often does not recognize that the User Components have been updated. In this case, Talend internally continues to use the old cached versions of the components without this being apparent.
- Restart Talend before continuing. Only restarting Talend will ensure that the new version of Mindbreeze Components is completely reloaded. (The automatic update when Talend is open is not sufficient).
Using Mindbreeze Components
Furthermore, please note that for the component to function correctly, the following fields (string type) must be defined in the data set schema:
- key
- title
- extension
- categoryClass
The following fields are optional and can additionally be used for further processing in the Mindbreeze Index:
- acl (list of string values) in the format: "TestUser1||GRANT"
- date (type "Date")
- modificationDate (type "Date")
- content (type "String")
Should further fields be defined in the schema, these are imported as metadata. It is also possible to define annotations in the following format:
val1|||mes:annotated|||categoryclass=cc1|||value=v1
In this example, "val1" becomes an annotation with the categoryClass "cc1" and the value "v1".
All "list" type fields become lists of metadata; all other fields are automatically converted into "string" types.
Testing and exporting the “Data Integration Job”
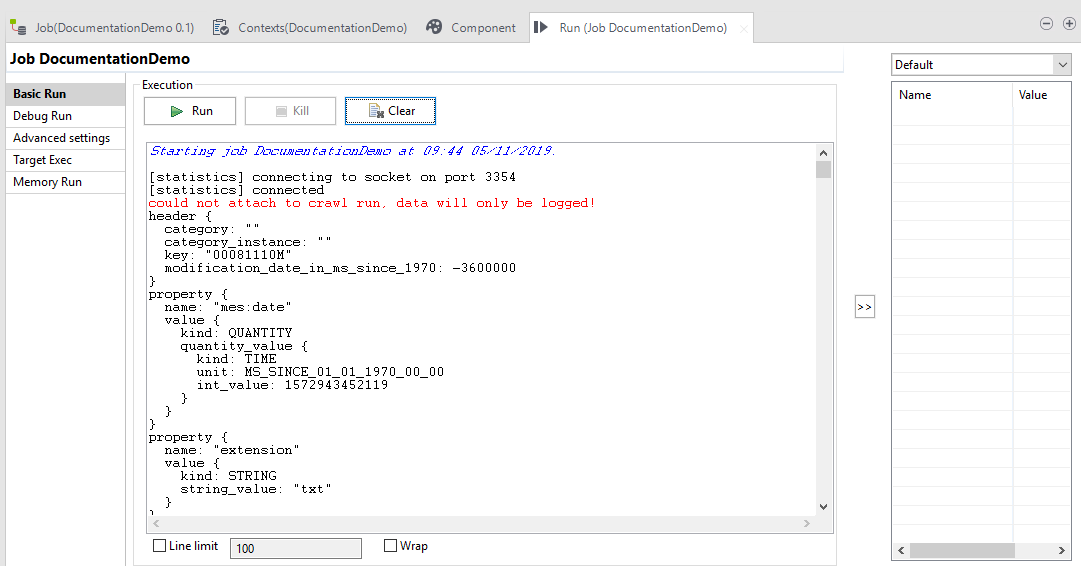
Test with logging
When your job configuration is complete, you can run it to test its functionality. The data are not sent to an index but exported to Talend Open Studio.
Test as pusher
You can test the job by sending data to the Mindbreeze InSpire Appliance without exporting it first. The corresponding Index has to be created first:
Then click on “Save” to save the changes. The following pop-up is displayed by your browser, which you must confirm with ‘OK’:

You must perform the next step in Talend Open Studio again. In the Designer, select the “MindbreezeIndexOutput” component you are using and select “Use as Pusher”.

Configure the following settings:
Setting | Description |
Category | The category. |
Category Instance | The category instance. |
InSpire Base URL | The URL pointing to your Mindbreeze InSpire appliance. |
Filter Pipeline ID | The port of the Filter Service (23400 by default). |
Index ID | The port of the Index Service. |
Node ID | The Node ID of the appliance (can also be found in the previously created index). |
Inspire Generation | The following options are available:
|
Username | The user name that is used for indexing. If your appliance is G6, “inspireapi” must be used. If you have a G7 appliance, you can use any user who has the role “InSpire Index Writer”. Further configuration: https://help.mindbreeze.com/de/index.php?topic=doc/Konfiguration---Backend-Credentials/index.htm. |
Password | The password of the user, WITHOUT quotation marks. Tip: If your password contains characters that must not occur in a Java String literal, they must be escaped: https://docs.oracle.com/javase/tutorial/java/data/characters.html |
Additional Settings for G7:
Setting | Description |
Client ID | The Client ID of the OAuth2 Client in Keycloak (e.g mindbreeze-inspire-public). |
Client Secret | Not necessary for „mindbreeze-inspire-public“. |
Use external Auth URL | Select this option, if you use an external Keycloak installation |
External Auth URL | The URL of the external Keycloak installation from which you can obtain the Bearer token: {base-url}/realms/{realm-name}/protocol/openid-connect/token. |
Export
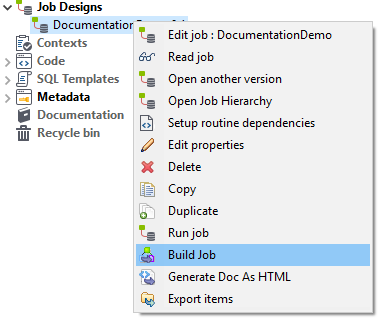
If the functionality test runs smoothly, the job still needs to be exported. That can be done by clicking in the context menu of the job:
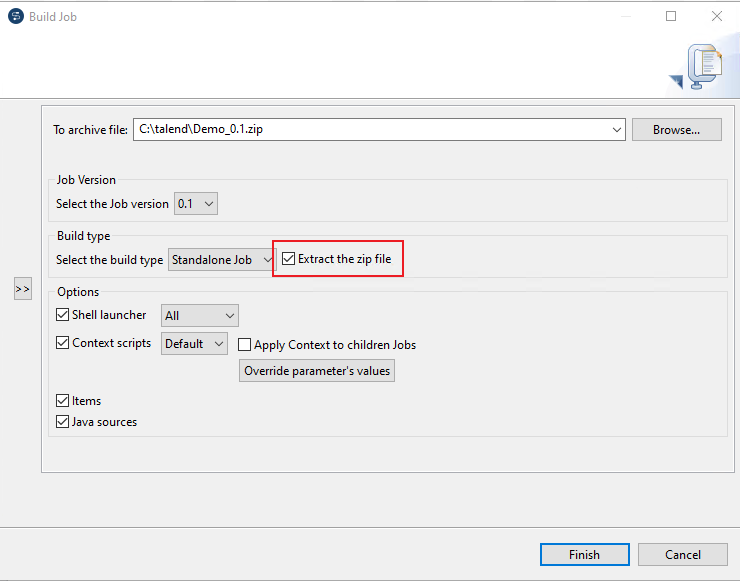
It is important that the generated ZIP-file is also unpacked.

The "Main-Class" required for the configuration of Fabasoft Mindbreeze Enterprise can be found in the generated batch file.
Configuration of Mindbreeze
Select the setting “Advanced Settings”.
Click on the “Indices” tab and then on the “Add new index” symbol to create a new index.
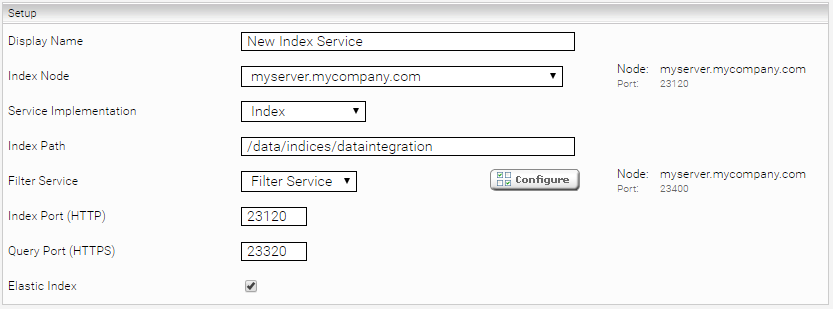
Enter the index path, e.g. “C:\Index”. Adapt the Display Name of the Index Service and the related Filter Service if necessary:
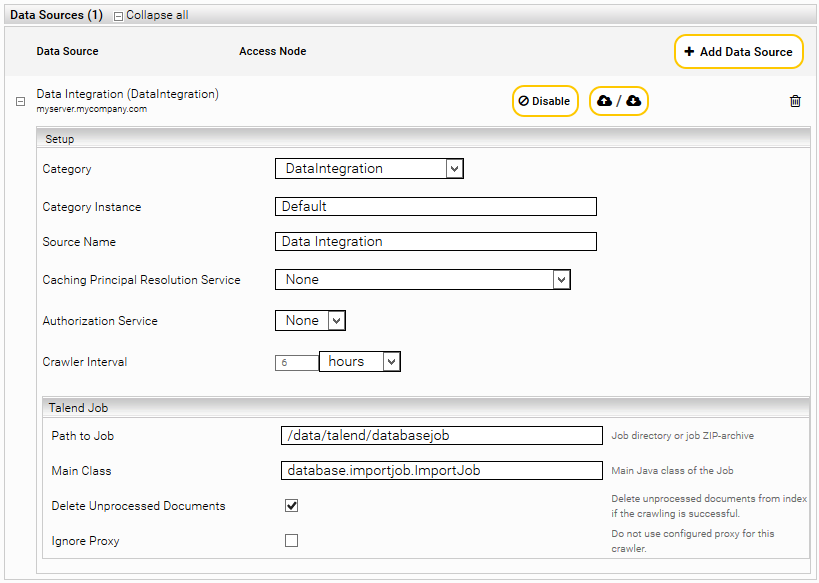
Add a new data source with the symbol “Add new custom source” at the bottom right.
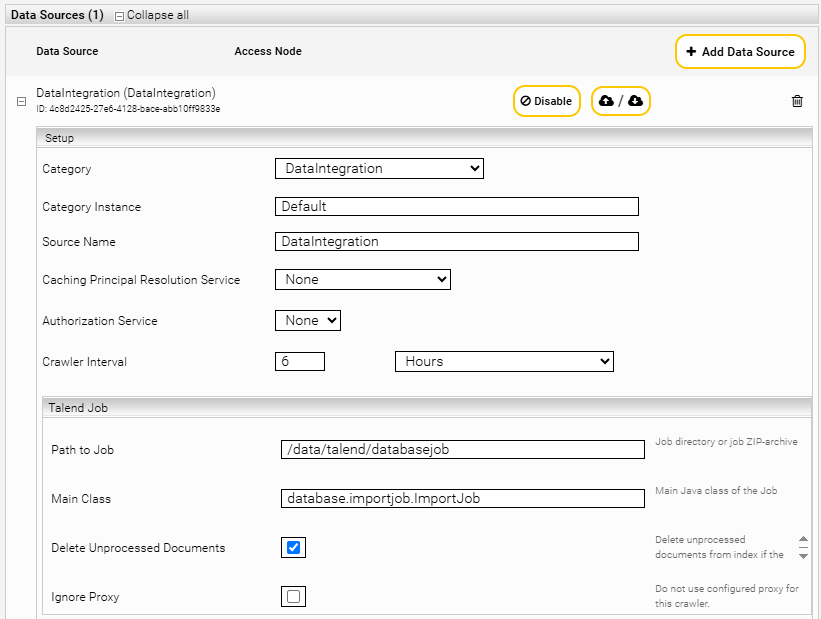
To configure the crawler, you need to enter the Job ZIP archive or the extracted job directory in "Path to Job" and the Java job class in "Main Class". Please note that Talend Job Zip archives are only supported starting with Mindbreeze InSpire G7.
If the option “Delete Unprocessed Documents” is enabled, then all unprocessed documents in the index are delete if the crawlrun was successful (exit code of the Talend-Job is 0).