
Sure, you can handle it. But should you?
Let our experts manage the tech maintenance while you focus on your business.
Let our experts manage the tech maintenance while you focus on your business.
Egnyte Connector
Installation and Configuration
Installation
Before you install the Egnyte connector, you must ensure that the Mindbreeze server is installed and that the Egnyte connector is included in the license. Use the Mindbreeze Management Center to install or update the connector.
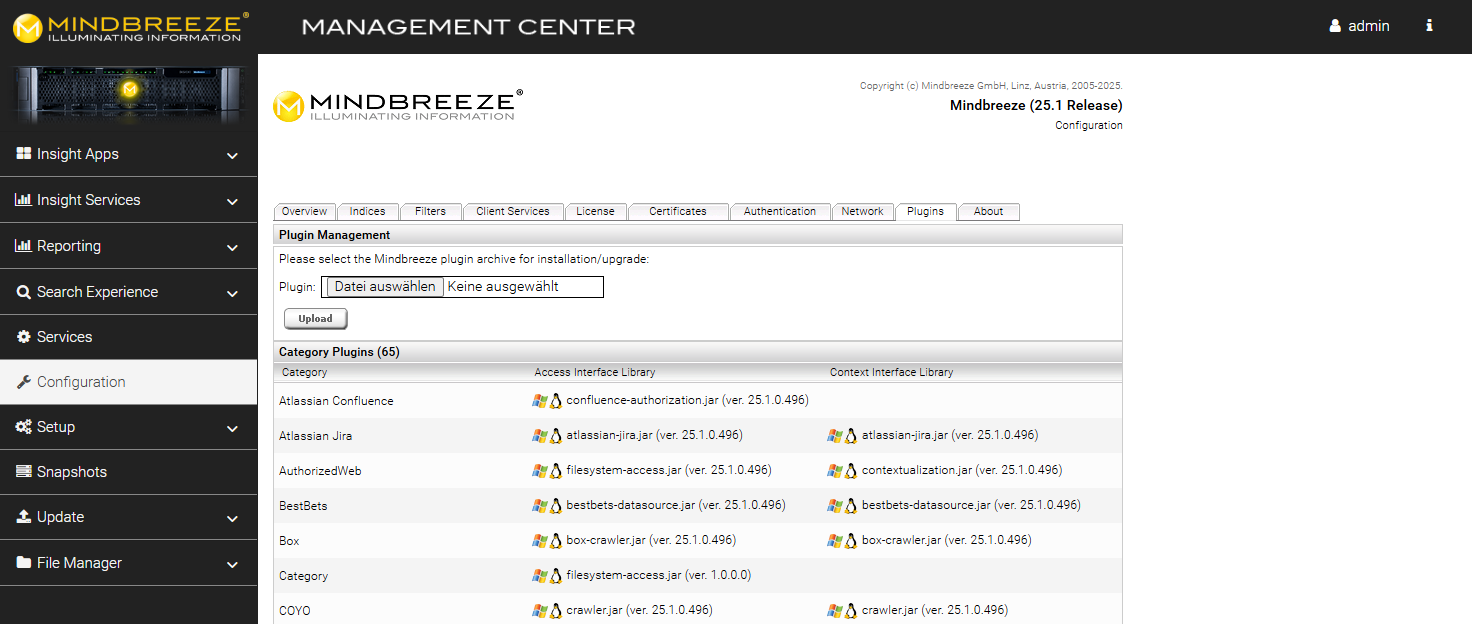
Plugin installation via Mindbreeze Management Center
To install the plug-in, open the Mindbreeze Management Center. Select "Configuration" from the menu pane on the left-hand side. Then navigate to the "Plugins" tab. In the "Plugin Management" section, select the appropriate zip file and upload it by clicking the "Upload" button. (Note: The name of the plugin is "WebRestConnector".) This automatically installs or updates the connector, as the case may be. In this process, the Mindbreeze services are restarted.
Configuring the index and crawler
To create a new index, navigate to the "Indices" tab and click on the "Add new index" icon in the upper right corner.
Enter the path to the index and change the "Display Name" if necessary.
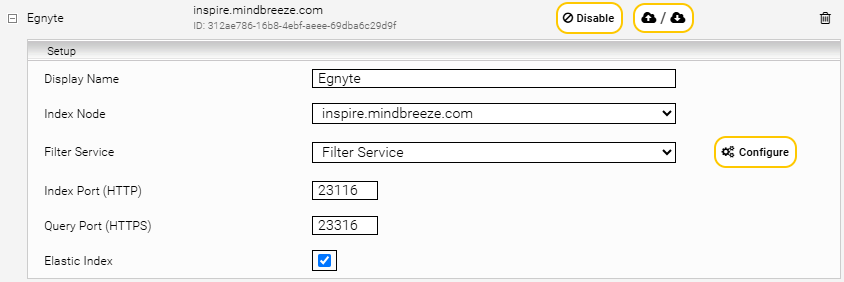
Add a new data source by clicking on the "Add new custom source" icon in the upper right corner. Select the category "Egnyte".
Configure the settings as follows:
Setting | Description |
Egnyte API Token | The API token for the Egnyte web service |
Number of crawler threads | Number of threads that perform HTTP requests in parallel. Default: 2. |
Full Crawl Schedule | Extended cron expression that performs a full crawl on the subsequent crawl run. (Optional) Documentation and examples of the cron expressions can be found here. |
Crawling URL | Path to the directory that should be indexed. You can specify multiple paths using the "Add" button. Note: The path must be URL-encoded, but slashes (/) must not be URL-encoded. |
Page Size | Max. Number of elements that are downloaded during a request. Default 100. |
Max Content Size (MB) | Max. file size that will be sent to the filter. Default: 50 MB. For larger documents, only the metadata is indexed. |
Exclude Path Pattern | Regular expression (Java) that matches to the path of a document. With a match the document is not indexed. E.g. with the expression ^/MyFolder/.*\.zip$ the document with the path /MyFolder/test.zip will not be indexed. (optional) |
Note: The connector stores small amounts of data between crawl runs in the messervicedata directory (/data/messervicedata/<<service-guid>>/), this directory can be changed if needed with the following manual property: egnytepersistencedirectory .

Then save the configuration and restart.
Information about the number of requests to the Egnyte API
This section roughly describes how many HTTP requests the connector sends to the Egnyte API during operation. A distinction is made between metadata requests, which only retrieve compact metadata such as title, author or modification date, and content requests, which retrieve the actual content of the documents, for example JPG or PDF. The number of requests described here is only a rough quantity structure and serves as an orientation. The actual number of requests may differ.
Initial indexing
During initial indexing, a metadata request is performed for each folder and a content request for each file. For larger folders (larger than "Page Size"), another metadata request is performed for each additional page.
Delta indexing
With delta indexing, a metadata request and a content request are performed for each new file added. For each deleted file, only one metadata request is performed. If many files have been added/deleted/changed since the last delta indexing (more than "Page Size"), then another metadata request is performed for each additional page.
Full indexing (according to Full Crawl Schedule)
In case of a full indexing (with already full index), if nothing has changed in the egnyte since the last full indexing, a metadata request is performed for each folder. For larger folders (larger than "Page Size"), another metadata request is performed for each additional page. Content requests are only performed if it is clear from the metadata that the file has changed. Then a content request is performed for each changed file.