
Sure, you can handle it. But should you?
Let our experts manage the tech maintenance while you focus on your business.
Let our experts manage the tech maintenance while you focus on your business.
Google Search Appliance Feed Indexing with Mindbreeze InSpire
Configuration and Indexing
Google search appliance feeds
The Mindbreeze InSpire GSA feed adapter makes it possible to index Google Search Appliance feeds with Mindbreeze InSpire.
The feed is an XML file that contains URLs. A feed can also include the contents of the documents, metadata and additional information such as the date of last modification. The XML file must correspond to the pattern defined by gsafeed.dtd. This file is located on the Google Search Appliance at http://< APPLIANCE - Host-Name>:7800/gsafeed.dtd.
The GSA feed XML documents should be sent by an HTTP post request to the GSA feed adapter service port. If the feed has been received and processed successfully, the service sends the text "Success" with the Status 200.
An example of a POST request with curl:
curl -X POST -F "data=@<feed_xml_path>" http://<mindbreeze_inspire_server>:19900/xmlfeed
Storing feeds
The GSA feeds received can be stored for a configured time interval. To do this, enable the “Enable Feed Storage” option in the “Feed Storage Settings” section. This option should be enabled by default.
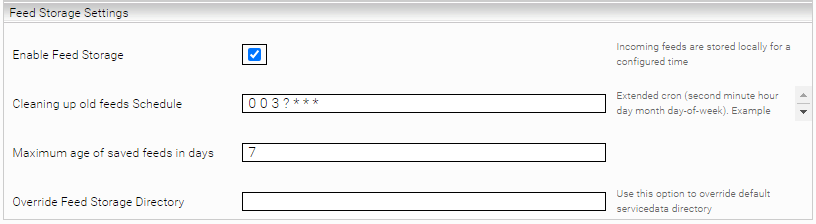
If no directory is configured for feed storage using “Override Feed Storage Directory”, the feeds will be stored in /data/messervicedata/<serviceuid>/
You can use “Cleaning up old feeds Schedule” using an extended cron expression to determine when or in which interval the outdated feeds should be deleted. Documentation and examples of cron expressions can be found here.
Basic configuration of the GSA Feed Adapter Service
Open the “Indices” tab in the Mindbreeze configuration and add a new service with the “Add new Service” icon.
![]()
Set the “Display Name” and select the service type “GSAFeedAdapter”.
Service Settings:
- GSA Feed Adapter Service Port: The HTTP port to which the feed documents can be sent
- “Accept Trusted Requests Only”: If enabled, feeds will only be accepted from IP addresses that are configured in “Trusted Addresses”.
- “Trusted Addresses”: Contains a list of trusted IP addresses. Wildcards are also supported, for example: 192.168.116.*
- “Use Secure Connection”: If enabled, HTTPS is used for the feed services. To enable HTTPS, a credential with SSL certificate must be available.

- “Server Certificate Credential”: The server certificate Credential for HTTPS should be selected here.
- “Use Client Certificate Authentication”: If enabled, feeds are only accepted with client certificate authentication. The client certificates are validated with the installed CA certificates.
- “Trusted CA Certificate Subject Pattern”: Regular expression that can be used to further restrict the trusted CA certificates. Only installed CA certificates with an appropriate Subject Distinguished Name property are used.
- “Following Patterns”: Link patterns that are to be followed
- “Do Not Follow Patterns”: Link patterns that should not be followed
- Document Dispatcher Thread Count: Number of threads that edit the downloaded documents and forward them to the Mindbreeze indices.
- Web Crawler Thread Count: Number of threads that visit URLs and for downloading documents.
- Web Crawler Queue Size: Size of the web crawler document queue
- Enable FeedState CSV logging: If enabled, the feed status is also logged as CSV files in the current service log directory. The following CSV files are created:
- received-feeds.csv: Received feeds with Feed File path
- processed-feeds.csv: Processed feeds with status
- processed-outlinks.csv: Processed URL records with the number of links found
- Full Feed Filter and Indexing Client Shutdown Timeout Seconds: Maximum wait time for Full Feed Filter and Index Client Stop.
- Connection Timeout Seconds: Maximum wait time for responses to HTTP requests.
- Time until revisit Seconds: Time until URLs that have already been visited are crawled again. This option should not be set too low to prevent loops.
- User Agent: A user agent can be configured here. The configured user agent is used for all http requests.
- Ignore robots.txt Rules for Matching URLs: You can use a regular expression here to determine which URLs the robots.txt rules are not used for.
- Exclude Mime Types: Can contain a list of mime types that should not be indexed. The list can also contain Regexp patterns. When documents are found in metadata and URL feeds with these mime types, they are not sent to the index.
- Minimum Delay in Milliseconds Between Consecutive HTTP Requests: Minimum number of milliseconds between consecutive http requests.
- Maximum Delay in Milliseconds Between Consecutive HTTP Requests: Maximum number of milliseconds between consecutive http requests.
- Try to Parse Record Metadata as Date Values: If enabled, it attempts to extract a date value from the feed metadata using Java Date Format configured in Parsable Date Formats (Ordered). The region for the extraction can be set in “Locale String for Date Parsing” with an IETF BCP 47 locale.
- Do not replace crawler metadata with HTML meta tags: If enabled, the metadata set by the GSA feed adapter service is not overwritten by the HTML filter with automatically extracted metadata (HTML meta tags).
- Remove inaccessible URLs from Index: If active, all pages that cannot be reached are removed from the index when the GSA Feed Adapter is started. This option is equivalent to a single execution of the Invalid Documents Deletion Schedule.
- Invalid Documents Deletion Schedule: Specifies when or in which interval the index should be checked for and cleaned from pages that are no longer accessible. For the configuration an extended cron expression must be used. Documentation and examples of cron expressions can be found here.
The “Following” and “Do Not Follow” patterns can be defined with the syntax of Google URL patterns:
https://www.google.com/support/enterprise/static/gsa/docs/admin/72/gsa_doc_set/admin_crawl/url_patterns.html
Collections and destination mappings
Collections
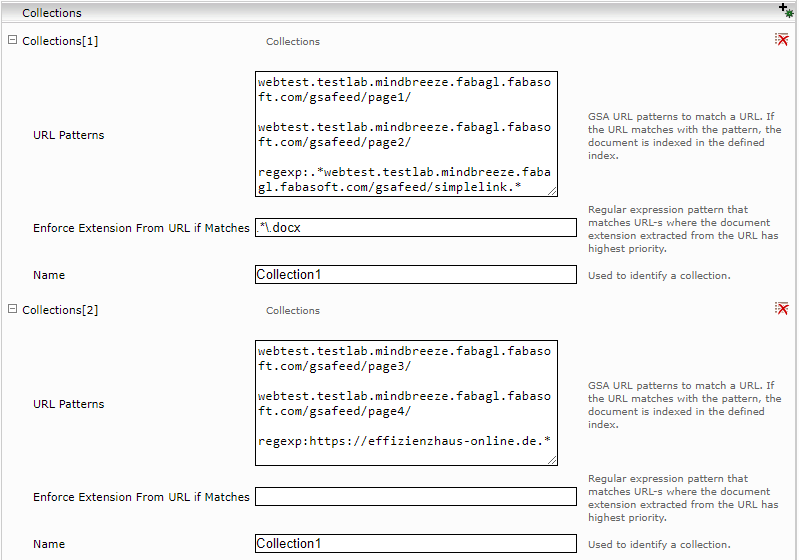
You can define URL groups using URL patterns in the “Collections” section of the GSA feed adapter service configuration. A document can belong to several collections, but is indexed only once per category and category instance.
The names of all collections containing a document are stored in the “collections” metadata.
If a regular expression is set as an “Enforce Extension from URL if Matches” parameter, the extension for documents with matching URLs is derived from the URL instead of from the “Content-Type” http header.
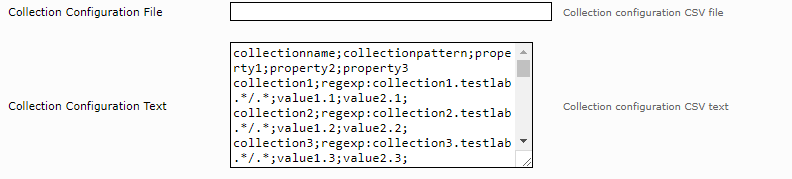
If a large number of collections or additional collection properties are required, the collections can also be defined with a CSV-formatted configuration. Collection configuration can be input from a file or configured directly as text.

The collection configuration must contain a CSV header with the properties “collectionname” and “collectionpattern”. Further properties can also be defined, like in our example: “property1,” “property2” and “property3.”
The CSV lines are grouped by “collectionname.” If you want to define a collection with several URL patterns, you can use the following syntax:
collectionname;collectionpattern;property1;property2;property3
collection1;regexp:server1.testlab.*/.*;value1.1;value2.1;value3.1
collection1;regexp:server1.mindbreeze.*/.*
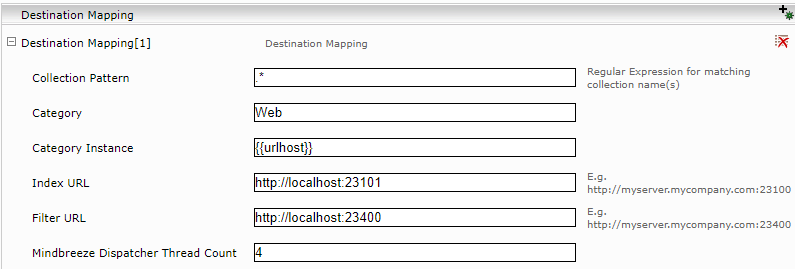
Destination Mappings
To be able to index URLs in the collections, at least one destination mapping must be defined. To do this, click the “Add Composite Property” icon in the “Destination Mapping” section.

Reference one or more collections in the newly added destination mapping (“Collection Pattern”). You can specify a regular expression that matches the desired collection name.
In addition, the category used for indexing and the category instance properties have to be defined here. For example, for web content, the category is “Web”. The “Category Instance” can be freely chosen. The category instance can contain references to defined collection properties, parts of the URL and feed parameters.
Lastly, there is an index URL and a filter URL to which the data should be sent.
With “Mindbreeze Dispatcher Thread Count” you can determine the number of threads that send documents to the configured index and filter services.
Full Feed Destination Mappings
Full feed destination mappings are similar to collection-based destination mappings. If full content feeds should be indexed, the feed data source must be defined as a category instance in a Mindbreeze index.
The GSA full content feeds contain all documents from a data source, defined with the feed “data source” property. All documents that are not in the feed and were previously indexed in this data source are deleted.
A full feed destination mapping has the following attributes:
- Datasource: The feed data source to be sent to the index configured here. The documents are indexed with this category instance.
- Category: The category to be used for indexing.
- Index URL: Mindbreeze index service internal URL (http://localhost:<index_port>)
- Filter URL: Mindbreeze filter service internal URL (http://localhost:<filter_port>)
- Mindbreeze Dispatcher Thread Count: The number of threads that send documents to the configured index and filter services.

If no full feed destination mappings are defined, all feeds are treated as incremental.
Metadata extraction
If documents are indexed with the GSA facade service, it is possible to define user-customized metadata for documents in several ways:
metadata defined in the feed,
metadata added by the HTTP header,
in the case of HTML documents, user-customized metadata from the content,
robots meta tags.
Metadata and URL feeds
The metadata defined in the URL records is automatically extracted and indexed. In this example, the metadata "meta-keywords“, “targetgroup“ and “group“ are indexed.
<record url="http://website.myorganization.com/newsletter" action="add" mimetype="text/html" lock="true" crawl-immediately="true">
<metadata>
<meta name="meta-keywords" content="Newsletter, My Organization"/>
<meta name="targetgroup" content="fachkunde"/>
<meta name="group" content="public"/>
</metadata>
</record>
The metadata of the records is only indexed for the record URLs and not for the subpages.
HTTP headers
In addition to metadata from the http records, the metadata is extracted from the X-gsa-external-metadata http header for all URLs. The header contains a comma-separated list of values. All values have the form meta-name=meta-value. The "meta-name" and "meta-value" elements are URL encoded (http://www.ietf.org/rfc/rfc3986.txt, Section 2).
ACL
The Mindbreeze InSpire GSA feed adapter supports ACLs from feeds with the following constraints:
- ACLs must be set per record
- Inherited ACLs are not supported.
- ACLs from X-google-acl headers are currently not being used.
ACLs from X-Gsa Doc controls http headers are extracted. Only ACLs set by URL are supported here.
Please note: Documents that have inherited ACLs in X-Gsa Doc controls are, by default, not indexed. If these documents should also be indexed, the configuration option "Index Documents with Partial Header ACL" must be enabled.
Metadata extraction from the content
It is also possible to extract user-customized metadata from the content for HTML documents, similar to the Mindbreeze Web Connector.
As with metadata mapping, it is also possible to define "content extractors" and "metadata extractors" for URL collections.
A content extractor has one collection pattern where a regular expression can be configured. On all URLs from all matching collections, the rules for content and title extraction are applied.
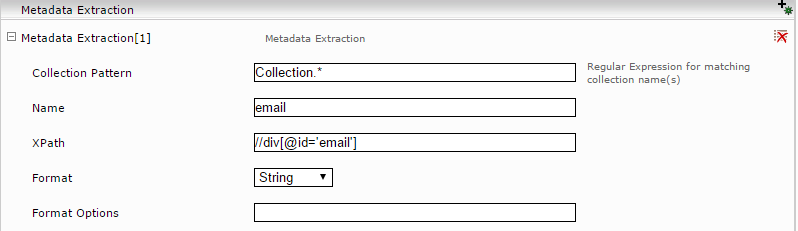
Metadata extractors can also be defined for the collections. Here it is possible to extract user-customized metadata with different formats and formatting options.
The metadata extractors use XPath expressions for extracting textual content. These can then be format-specifically edited, and interpreted, for example, as a date.
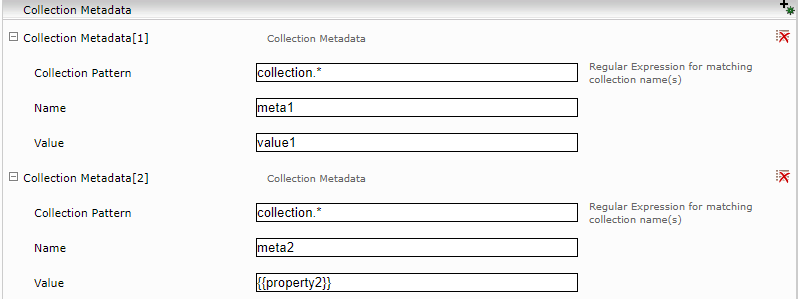
Collection metadata
For each collection, you can define metadata that are set for all associated documents. The metadata values can contain references to defined collection properties. In the following example, the value for “meta2” is set to the value of the property “property2” of the collection. A collection metadata also has a collection pattern where a regular expression can be configured. Metadata is set on all documents of all matching collections.
The metadata can also contain references to the following URL component and feed parameter:
- Hostname: {{urlhost}}
- Port: {{urlport}}
- Pfad: {{urlpath}}
- Feed Datasource: {{datasource}}
- Feed Type: {{feedtype}}
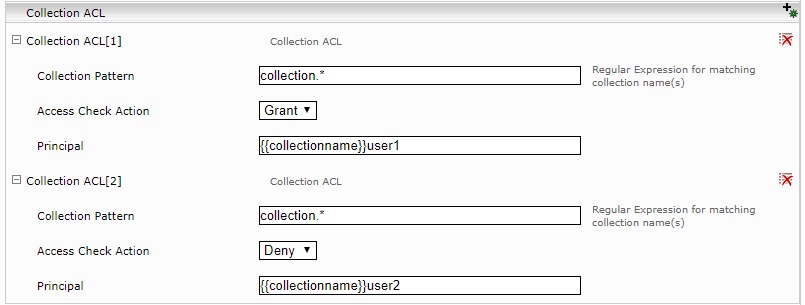
Collection ACL
Like collection metadata, it is possible to define ACL entries on the basis of a collection. The ACL principals can also contain references to collection properties. The ACL entries also have a “Collection Pattern” property which allows you to define the collections for which the ACL entries should be defined. Collection ACLs are only used if no feed ACL has been defined for the documents.
The ACL entries can contain references to the following URL component and feed parameter:
- Hostname: {{urlhost}}
- Port: {{urlport}}
- Path: {{urlpath}}
- Feed Datasource: {{datasource}}
- Feed Type: {{feedtype}}
URLs with multiple collections
If a document belongs to several collections using Collection Configuration, the collection metadata and collection ACL elements of the matching collections are merged.
It is also possible to define the “Category Instance” of the document according to the collection assignment or URL. For the Category Instance property in the Destination Mapping configuration, it is also possible to use the references to the collection properties and URL components, as shown in this example:

Updating metadata
The GSA Feed Adapter can trigger a metadata update for a feed record if the record is added with the action attribute set to “update”
<record url="http://website.myorganization.com/newsletter" action="update" mimetype="text/html" lock="true" crawl-immediately="true">
<metadata>
<meta name="meta-keywords" content="Newsletter, My Organization"/>
</metadata>
</record>
In this case the document with the key set in the URL attribute will be updated with the feed record metadata specified.
Login settings
Form login and session administration with cookies can be defined for given URL patterns using a configuration in CSV format. The login configuration can be input from a file or configured directly as text.
The login configuration must begin with the following header:
urlpattern;actiontype;actionurl;logindata;followredirects;sessionlifetime;parameters
The login configuration lines contain login action definitions grouped with the “urlpattern” property.
As defined in the header, a login action has the following properties:
- urlpattern: A Google URL pattern specifies which URLs the action should be applied to.
- actiontype: The login action type. Supported values are: GET, POST, AWS_SIGN, OAUTH.
- logindata: Additional login data (form content for POST or application credentials for AWS_SIGN).
- followredirects: “true” or “false.” Determines whether the additional http redirections should be tracked automatically.
- sessionlifetime: The session lifetime in seconds (the first value per “urlpattern” applies).
- parameters: additional/optional parameters, used for the Login (currently only “scope” for OAUTH is supported).
The supported login action types are:
- POST: http POST request to a URL with a defined form content. The text must be URL-form coded.
Example:
regexp:confluence.myorganization.com;POST;http://confluence.myorganization.com /dologin.action;os_username=user&os_password=mypassword&login=Anmelden&os_destination=%2Findex.action;false;60
- GET: http GET request to a URL.
- Example:
- regexp:myserver.myorganization.com;GET;http://myserver.myorganization.com /sessionvalidator;;false;60
- AWS_SIGN: Amazon Web Services Signature Version 4 for Amazon REST URLs.
- Example:
- regexp:s3.eu-central-1.amazonaws.com;SIGN_AWS;;eu-central-1:<Access Key ID>:<Secret Key>;false;0
- OAUTH: OAuth Authentication via Access Tokens and Client Credentials (client-id and client-secret)
Example:
regexp:myserver.myorganization.com/protected;OAUTH;https://auth.myserver.myorganization.com/auth/realms/master/protocol/openid-connect/token;cloaktest:acf868e4-4272-42e7-aa2d-b7c63d2ec769;false;60;
Note: The column “parameter” currently only supports the parameter “scope” for generating a bearer token via OAUTH. The value is URL-encoded.
regexp:myserver.myorganization.com/protected;OAUTH;https://auth.myserver.myorganization.com/auth/realms/master/protocol/openid-connect/token;cloaktest:acf868e4-4272-42e7-aa2d-b7c63d2ec769;false;60;scope=openid%20email
If you want to define multiple login actions for one URL pattern, you have to set the same “loginpattern” for the login actions.
Example:
urlpattern;actiontype;actionurl;logindata;followredirects;sessionlifetime
regexp:myserver.myorganization.com;POST;http://myserver.myorganization.com /dologin.action;username=user&password=mypassword;false;60
- regexp:myserver.myorganization.com;GET;http://myserver.myorganization.com /sessionvalidator;;false;60
Limitations
When using the SIGN_AWS login action and your filenames contain a plus sign (+), comma (,) or procent symbol (%), these must be encoded in the XML file of the GSA feed. Otherwise, the AWS_SIGN will return a 403 HTTP status code (= Access Forbidden) as a result and these documents will not be indexed.
Robots meta tag
The robots meta tag allows a detailed, site-specific approach to determine how a particular page should be indexed and displayed for the users in the search results. (https://developers.google.com/webmasters/control-crawl-index/docs/robots_meta_tag?hl=de).
The robots meta tag is placed in the <head> section of the corresponding page:
<!DOCTYPE html>
<html>
<head>
<meta name="robots" content="noindex" />
(…)
</head>
<body>(…)</body>
</html>
The Mindbreeze InSpire GSA feed adapter service considers the following robots meta tag values:
noindex: This site is not indexed.
nofollow: The links on this page are not followed.
none: Equivalent to noindex, nofollow.
Collection statistics servlet
At https://<host>:8443/cache/<port>/collections, you can retrieve statistics for the collections. “Host” stands for the hostname of the Mindbreeze InSpire server, “port” stands for a free port that is automatically selected for the collection statistics servlet. You can find this in the logs and also in the log directory at statistics_servlet_port_<port>.
“Create Statistics” button
User interface
If you call up the URL listed above in the browser, you will receive the following user interface in the browser.

To prompt a calculation of the statistics, you need to click the “Create Statistics” button.
You can also enter additional category instances in the “Category Instances” field (separated by a line break). The purpose of this field is that destination mappings that use placeholders for the category instance (for example, {{urlhost}}) cannot be processed by the collection statistic servlet. To be able to create statistics for the affected destination mappings or collections anyway, you can use the field “Category Instances” in the collection statistic servlet to include all documents with the specified category instances from all destination mappings for the calculation of the statistics. Then click the “Create Statistics” button to trigger the calculation of the statistics.
URL parameters
The following URL query parameters can be set under /collections to create statistics without a user interface:
action=create | Creating the statistics |
categoryInstance | Parameters can be defined more than once so that category instances can be specified as parameter values that are used instead of the destination mappings mentioned above, such as /collections?action=create&categoryInstance=mindbreeze.com&categoryInstance=fabasoft.com |
“Refresh Status” button
User interface
The “Refresh Status” button can be used to retrieve the current status from the statistics creation process.

During the calculation of the statistics, the so-called crawler status is retrieved for all documents – depending on the number of documents in the index, this can take several minutes or even hours. The statistics are then compiled, but the total number of documents to be processed (in this case 4484) is only an estimate.

URL parameter
The following URL query parameter can be set under /collections to query the current status of the statistics without a user interface:
action=refresh | Retrieving the status of the calculation of the current statistics |
“Download Statistics” button
User interface
When the calculation is complete, the “Download Statistics” button will be displayed. By clicking this “Download Statistics” button, the CSV statistics will be downloaded. The CSV file can then be downloaded as often as you want. The CSV file contains one line for each collection. The downloaded file contains the following columns:
CollectionName | Name of the collection |
Category | Category (configured in the corresponding destination mapping) |
CategoryInstance | Category instance (configured in the corresponding destination mapping) |
IndexURL | Index URL (configured in the corresponding destination mapping) |
FilterURL | Filter URL (configured in the corresponding destination mapping) |
DocumentCount | Number of documents in the collection |
Timestamp | Timestamp (format in ISO 8601) of the time/date from which the data originated |
URL parameter
The following URL query parameter can be set under /collections to download the CSV collection statistics:
action=download | Downloading the CSV collection statistics |
Configuration of the index services
Click on the "Indices" tab and then click on the "Add new service" symbol to create an index (optional).

Enter the index path (in "Index Path"). If necessary, adjust the display name (in "Display Name") of the index service, the index parameters, and the associated filter service.
To create data sources for an index, under the section "Data Sources", click on "Add new custom source".
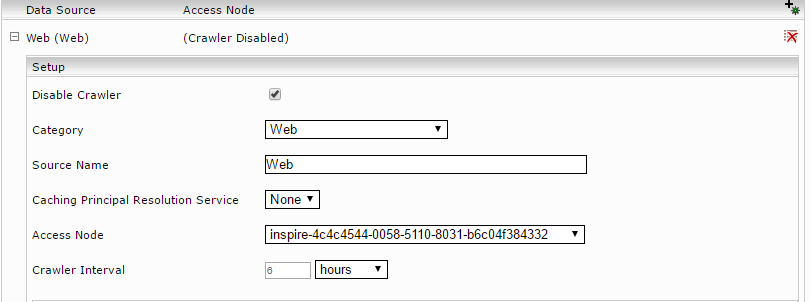
A data source should be configured here for all categories that are assigned to this index in the GSA feed adapter service (see chapter “Basic configuration of the GSA Feed Adapter Service”). Since the data sources are only used for the search, the crawler should be disabled. To do this, activate the "Advanced Settings" mode and select the option "Disable Crawler" for the configured data sources:

GSA transformer
The GSA transformer enables the client service to understand Google Search Appliance XML queries and provide XML responses that are compatible with Google Search Appliance.
You can find more details under Google Search Appliance: Search protocol reference.
Request can be sent to: http://appliance/plugin/GSA/search?q=<query>
Configuring the GSA transformer
The GSA transformer is configured in the client service. Here you can define the metadata that should always be delivered.
The plugin is first added under “API V2 Search Request Response Transformer” in the client service tab.
Configuration options
Setting name | Description |
“Restrict Results” | Search results can be restricted using the Mindbreeze Query Language (e.g. extension:pdf) |
“Metadata used for Open” | |
“Enable Title” | If this option is enabled, the title of the documents is displayed in the search result. |
“Enable Content” | If this option is enabled, the sample text of the documents is displayed in the search result. |
“Content Sample Length” | The maximum length of the sample text. Only effective if “Enable Content” is enabled. |
“Metadata Sample Length” | The maximum length of the metadata in the search result. |
“Enable Paging” | If enabled, the response will provide information for scrolling in the search results. |
“Metadata List Separator“ | Character or character string that is used as a separator symbol to concatenate list metadata in the response to a character string. |
“Parse Query Term Separator Special Character“ | The query can contain special characters that separate the terms from each other and have a logical meaning. If this option is enabled, these characters are parsed and the query is transformed into Mindbreeze-compatible logical expressions. You can find additional information about this below. |
Configuring query constraints
Regular expressions (regex) can be applied to the query string to set query constraints. The query constraints are regular expressions and back references are supported.
An example of a possible use case is, for instance, the search for documents with author numbers that have different syntax, which you want to restrict even more using constraints.
The following documents exist:
Document 1: author:abc_12,def_45 authorid:abc_12
Document 2: author:abc_12,def_45 authorid:abc/12
Document 3: author:abc_12,def_45 authorid:def_45
The following queries are sent:
Query 1: author:abc_12
Query 2: author:abc/12
Despite the differing syntax, both queries should only contain the following two documents:
Document 1: author:abc_12,def_45 authorid:abc_12
Document 2: author:abc_12,def_45 authorid:abc/12
The idea is to work with regex that use underscores or slashes as separators.
This requires you to configure three settings:
Set “Query Contraints Label“ to authorid. Note: The metadata must be “regex matchable.”
Set “Query Pattern” to author:(\S+)[_/](\S+)
Set “Regex Constraint” to \^\\Q$1\\E[_/]\\Q$2\\E\$
You can also search for non-existent metadata, e.g.
Query 1: writer:abc_1
Normally, this query does not return any results, since there is no document with the metadata writer. The plugin can also be configured to manipulate the query itself. To do this, the “Replace Matching Parts from Query Value“ setting needs to be enabled. And the setting “Replace Matching Parts from Query Value“ must be set to ALL. This transforms the query as follows:
Query 1‘: ALL
Since the constraints are set as they were before, the correct documents are now delivered.
Setting name | Description |
“Query Contraints Label” | Name for the query expression label (name of the metadata to be filtered). Note: The metadata must be “regex matchable.” The property must be defined in the category descriptor or in the aggregated metadata keys, otherwise the constraint will not work. |
“Replace Matching Parts from Query” | If active, parts of the query that match will be replaced by a string. Default: inactive |
“Replace Matching Parts from Query Value“ | The value that replaces the matching parts. Default: empty. E.g. ALL |
“Query Pattern” | Regular expression (Java) with which the query is matched. Groups may also be used. For instance: myLabel:(\S+)[_/](\S+) |
“Regex Constraint” | Regular expression (Mindbreeze) for the query constraint regex. References to matched groups are possible with $1, $2... The stand-alone special character $ must be escaped using \. For example: \^\\Q$1\\E[_/]\\Q$2\\E\$ |
Configuring standard metadata and metadata formats
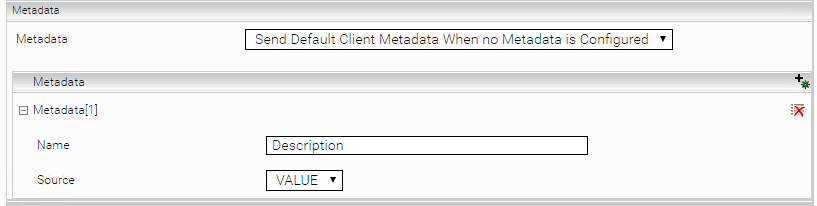
In the “Metadata” section you can configure the metadata to be requested by default.
Setting name | Description |
“Metadata” | Defines the metadata mode. “Disable” requests no metadata by default. “Send Only Configured Metadata” requests the configured metadata. “Send Default Client Metadata When no Metadata is Configured“ requests the default metadata of the data source if no metadata has been configured, otherwise it requests the configured metadata. |
Metadata “Name“ | The name of the metadata. |
Metadata “Source“ | The format of the metadata. “VALUE“ or“HTML“. “HTML“ is the recommended setting for Insight Apps, since this format can be displayed well. “VALUE“ returns the raw value of the metadata. |
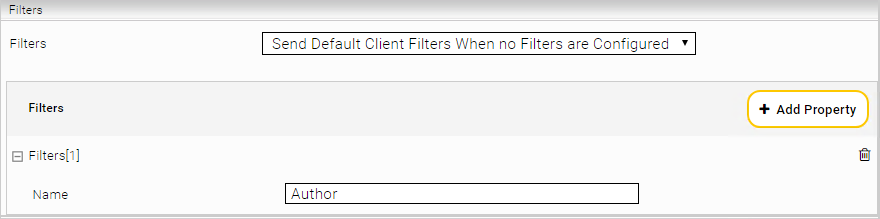
Configuring the standard filter
The filters requested by default can be configured in the “Filters” section.

Setting name | Description |
“Filters“ | Defines the filter mode. By default, “Disable” requests no filters. “Send Only Configured Filters” requests the configured filters. “Send Default Client Filters When No Filters Are Configured“ requests the default filters of the data source if no filters have been configured, otherwise it requests the configured filters. |
Filters “Name“ | Name of the filter to be requested. |
Boosting configuration
In the “Boostings” section, you can define the relevance of documents (order of search results).
Setting name | Description |
“Query Label” | Name of the metadata that is to be compared with the "Query Regex” |
“Query Regex“ | The regex that is to be compared with the metadata with the name from "Query Label". |
“Factor“ | Boosting factor that is applied to the relevance of all the documents found if the regex matches the said metadata value.
|
Boosting – Best Bets application
Without boosting, documents in the “BestBets” category would not always appear first in the search result. However, if you want to have documents from the “BestBets” category at the top of the search results, you can configure the boosting for this. The following screenshot and table describe how to configure these values.

Setting name | Value | Note |
“Query Label” | datasource/category | |
“Query Regex“ | ^BestBets$ | |
“Factor“ | 10 | The optimal value depends on the specific application (search and indexed documents) the value "10" is just an example. |
Features of the GSA XML search query
In addition, the GSA transformer supports the following new features of the GSA XML search queries:
- Request fields
- start
- num
- getfields
- requiredfields
- query operators
- filter
- paging
- Query Term Separator Special Characters
Information about getfields
The getfields parameter determines which metadata is requested. If the getfields parameter is not used or if the getfields value is "*", then the configuration of the metadata (see the above section) determines which metadata is requested.
If metadata is explicitly requested with the getfields parameter, for example with getfields=Author.Description.Revision, then only this metadata is requested, regardless of the configured metadata. This metadata is requested by default in "HTML" format.
However, the format of the requested metadata can be changed with the configured metadata. For instance, if the metadata Description is configured with the format "VALUE", then getfields=Author.Description.Revision requests metadata in the following formats: Author in HTML, Description in VALUE, Revision in HTML.
Notes for Query Term Separator Special Characters
The query can contain special characters to separate the terms and have logic meaning. This characters can be parsed and be used to transform the query into Mindbreeze-compatible logical expressions. Examples for possible transformations are:
Query | Result |
tree|house | tree OR house |
tree -garden | tree NOT garden |
tree.garden | tree AND garden |
inmeta:tree | tree |
description~tree | description:tree |
This behavior can be disabled by deactivating the configuration option „Parse Query Term Separator Special Characters“. Then, the original query will be used for the Search.
Notes on sorting
Google Search Appliance: Search Protocol Reference – Request Format – Sorting describes which query parameters can be sent with a search in order to influence the sorting of the search results. However, Mindbreeze InSpire only supports a subset of the features described on the above page. The following subsections describe which sorting modes are supported by Mindbreeze.
Sorting by date
Parameter: sort=date:<direction>:<mode>:<format>
<direction> value | Supported? | Fallback |
A | Yes | |
D | Yes |
<mode> value | Supported? | Fallback |
S | No | R |
R | Yes | |
L | Yes |
<format> value | Supported? | Fallback |
d1 | Yes |
Sorting by metadatum
Parameter: sort=meta:<name>:<direction>:<mode>:<language>:<case>:<numeric>
All values after <name> are optional and can thus be left empty. For example, if you only want to specify the name and mode, you can use the following format:
meta:<name>::<mode>::: or
meta:<name>::<mode>
<name> value | Supported? | Fallback |
any string | Yes |
<direction> value | Supported? | Fallback |
A | Yes | |
D | Yes |
<mode> value | Supported? | Fallback |
E | Yes | |
ED | No | E |
S | No | E |
SD | No | E |
<language> value | Supported? | Fallback |
any ISO 639-1 code | No |
<case> value | Supported? | Fallback |
D | Yes | |
U | No | D |
L | No | D |
<numeric> value | Supported? | Fallback |
D | No | Y |
Y | Yes | |
F | No | Y |
N | No | Y |