
Sure, you can handle it. But should you?
Let our experts manage the tech maintenance while you focus on your business.
Let our experts manage the tech maintenance while you focus on your business.
Japanese Language Tokenizer
Kuromoji
Introduction
This document deals with the Japanese tokenizer. This allows Mindbreeze InSpire to crawl and understand Japanese content. Essentially, this technology splits sentences into individual interrelated parts (tokens) in order to provide an optimized search experience. The tokenizer is based on the Kuromoji framework.
WARNING: The Japanese (Kuromoji) Tokenizer is deprecated and will be removed in future releases. Please use the CJK Tokenizer instead.
Requirements
Before using the tokenizer, make sure that the Mindbreeze server is installed. To use the plugin, an index with an active crawler that contains the Japanese content must be configured on the Mindbreeze InSpire appliance.
Set-up
To activate the Japanese tokenizer, the following steps must be carried out:
- Installing the plugin
- Setting up the post filter
- Setting up query transformation services
- Reindexing contents that were already indexed before the tokenizer was installed
Installing the plugin
The tokenizer is available as a ZIP file. This file must be installed as follows on the Mindbreeze InSpire Appliance using the Management Center:
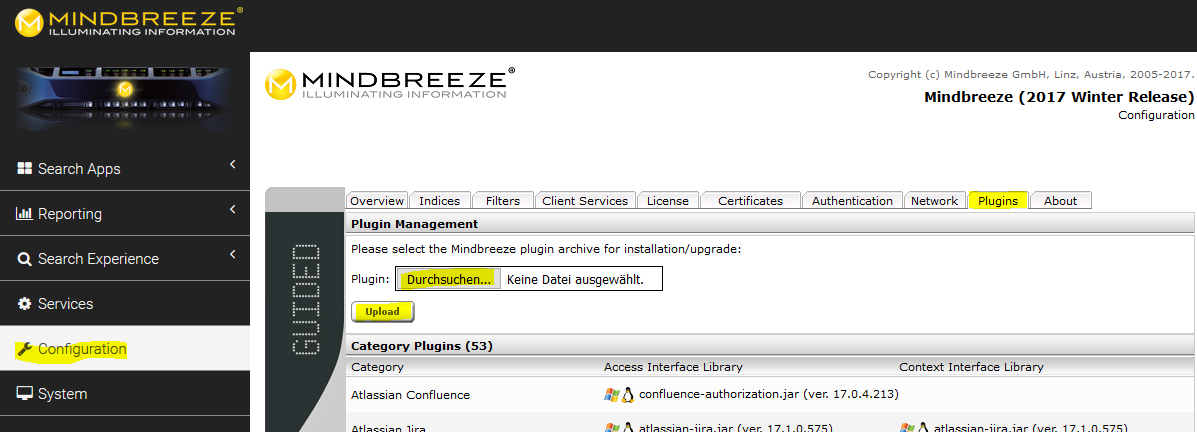
- Navigate to the Management Center
- Then select the Plugins tab and upload the tokenizer plugin.zip.
Uninstalling
To uninstall the tokenizer, you must first delete all uses of the tokenizer in the configuration and then delete the plugin from the Mindbreeze InSpire Appliance as described in the following steps:
- Navigate to the Management Center
- Then select the “Plugins” tab and upload the tokenizer plugin.zip.
- Select the “Plugins” tab and locate the installed tokenizer plugin.

Setting up the post filter
In the tokenizer, the post filter is used to tokenize (split) the contents during crawling and before they are stored in the index.
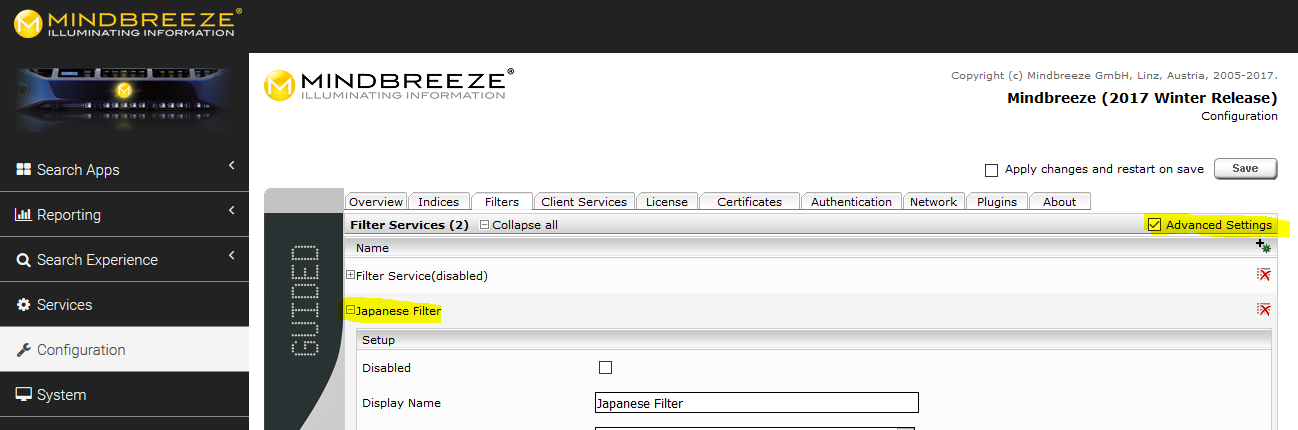
- Navigate to the Management Center
- Select the “Filter” tab, activate “Advanced Settings” and open the filter that you want to use to tokenize Japanese content:
- Then search for the “Post Filter Transformation Services” option and add the tokenizer post filter plugin (TextPlugin.Kuromoji):

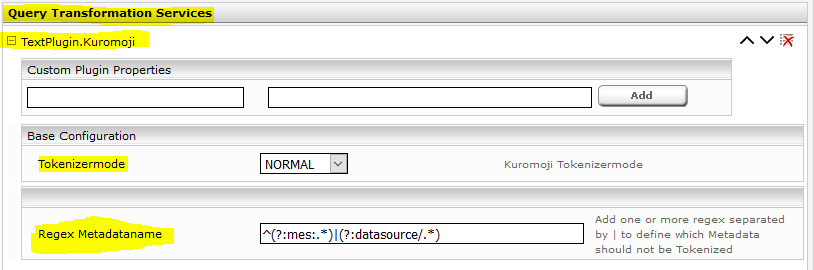
To modify the tokenizer settings, expand them by clicking the “plus sign” icon.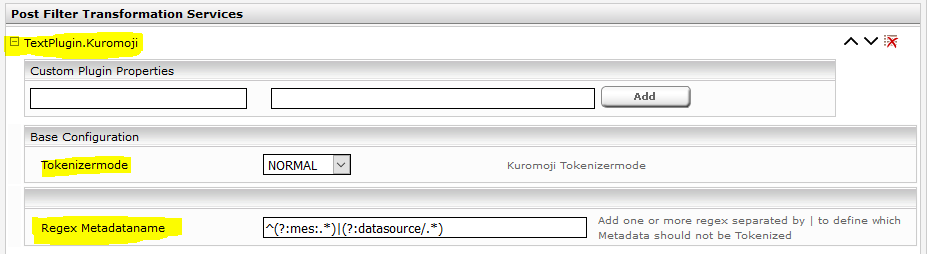
Tokenizer mode: This allows you to switch between the different tokenizer modes of the Kuromoji framework: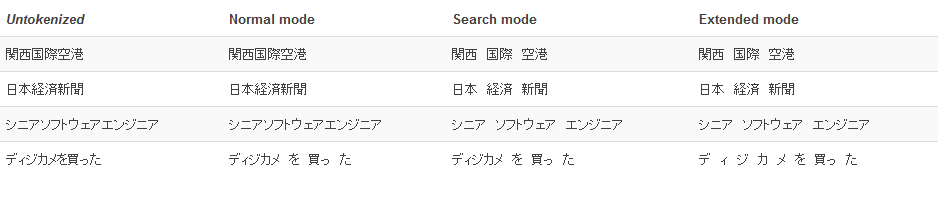
Regex metadata name: In this field, you can use regex to define which metadata names should be excluded from tokenizing. If you formulate several regular expressions, they can be linked using the “|” symbol. In most cases, this can be left empty by default.
Setting up the query transformation service
In the tokenizer, the query transformation service is used to ensure that the text entered by the end user in the search field is also “tokenized” before the query. If this is not the case, the index tokenization doesn’t match that of the search query. This would have the same effect as as if you had not configured a tokenizer.
- Navigate to the Management Center
- Choose the “Indices” tab
- Activate the “Advanced Settings” and open the index containing the Japanese contents. Select the filter on which you have configured the post filter:
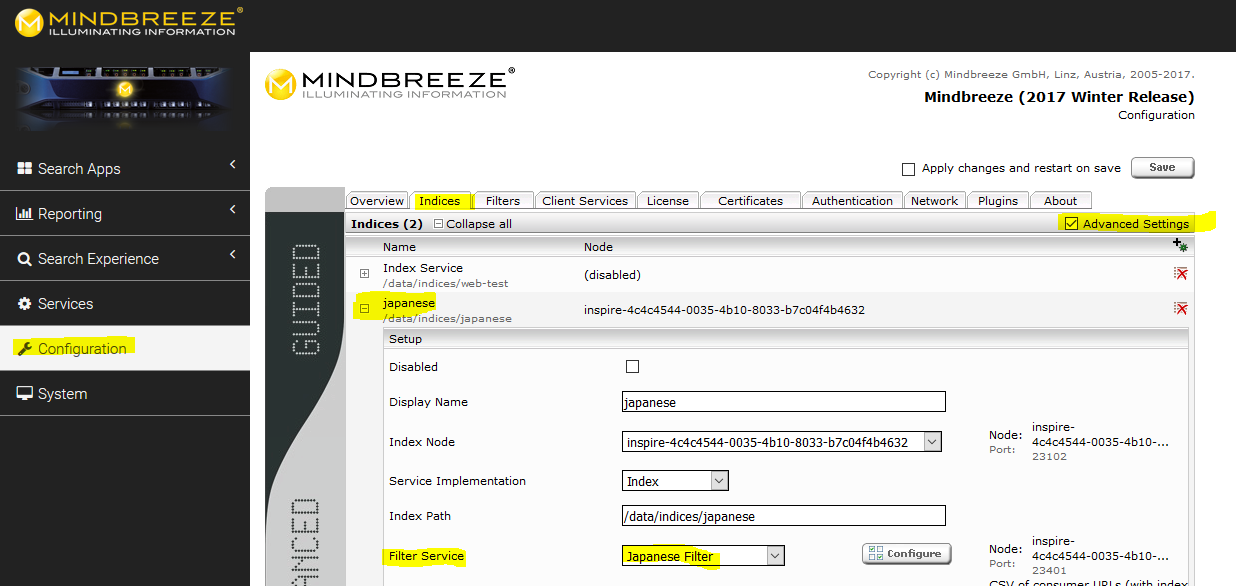
- Look for the setting Query Transformation Services and add the tokenizer service:

- Then open the settings of the Query Transformation Service by clicking the “plus sign” icon, and configure this equivalent to the post filter:
Content re-indexing
If documents already exist in your index, they must be re-indexed because the existing documents have not yet been tokenized.