Sure, you can handle it. But should you?
Let our experts manage the tech maintenance while you focus on your business.
Let our experts manage the tech maintenance while you focus on your business.
ServiceNow Connector
Installation and Configuration
Introduction
Using the ServiceNow connector, you can connect your ServiceNow instance to Mindbreeze InSpire.
Please be aware that certain types of ServiceNow authorizations are not displayed in the connector, which may prevent the documents concerned from being found by the Mindbreeze InSpire search. The following authorization types are not supported:
- “User Criteria”
- if “Advanced” is set (“Script”, except if the User Criteria was generated by an "HR Criteria”)
- “Access Control Lists” (ACLs)
- ACLs that are defined at the column level (e.g. [incident].[active]); however, table-level ACLs are supported (e.g. [incident].[-- None --])
- ACLs with “Condition” or “Script” (however, “Requires role” is supported)
Installation
Before installing the ServiceNow connector, make sure that the Mindbreeze server is installed and the ServiceNow connector is included in the license.
Configuring ServiceNow
To enable Mindbreeze InSpire to connect to your ServiceNow instance, you first need to configure your ServiceNow instance.
Creating a crawler user
Create a new user in ServiceNow that can be used in the Mindbreeze ServiceNow connector to crawl ServiceNow (see ServiceNow document: Create a user). For this, the user must have the following roles:
- rest_api_explorer
- web_service_admin
The user must also have read access to the necessary tables. This can be achieved in two different ways:
- Either the crawler user is assigned the role of “admin” and also the role “snc_read_only,” so that only read-only access is granted for all the tables that are already authorized (recommended option)
- Permissions are set for tables at a granular level (see appendix: Granular crawler permissions)
Creating an OAuth2 client
Enable OAuth2 in your ServiceNow instance and create a new OAuth2 application. See the ServiceNow documentation: Enable OAuth with inbound REST
Configuring Mindbreeze
To begin configuration, open the Mindbreeze Management Center in your browser.
Configuring the index
Add a new index in the Indices tab with the +Add Index button. Select the desired Index Node and Client Service and enter the data source ServiceNow in the Data Source field. Afterwards, confirm your entries by clicking the Apply button.
Configuring the datasource
Now you can configure the data source.
Legend:
- Properties marked with an *: required fields – these must be explicitly configured
- Properties not specifically marked: optional fields
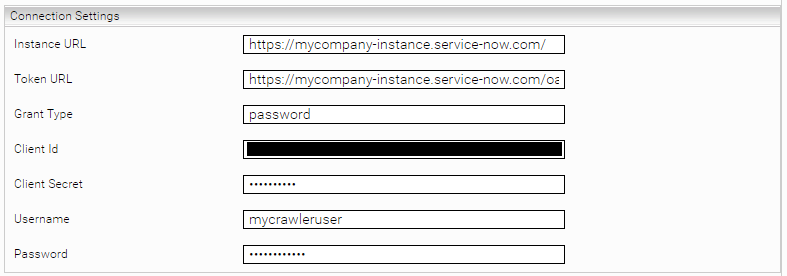
Connection settings

Setting | Description |
Instance URL* | The URL of the ServiceNow instance; for example, https://myorganization.service-now.com/. |
Token URL* | The token endpoint URL; for example, https://myorganization.service-now.com/oauth_token.do. |
Grant Type* | The grant type for retrieving the OAuth2 token (usually “password”). |
Client ID* | The client ID of the OAuth2 application that is configured in ServiceNow. |
Client Secret* | The client secret of the OAuth2 application that is configured in ServiceNow. |
Username* | The crawler user’s username. |
Password* | The crawler user’s password. |
Download settings
Setting | Description |
Page Size | The page size of the REST API bulk requests (default 1000) |
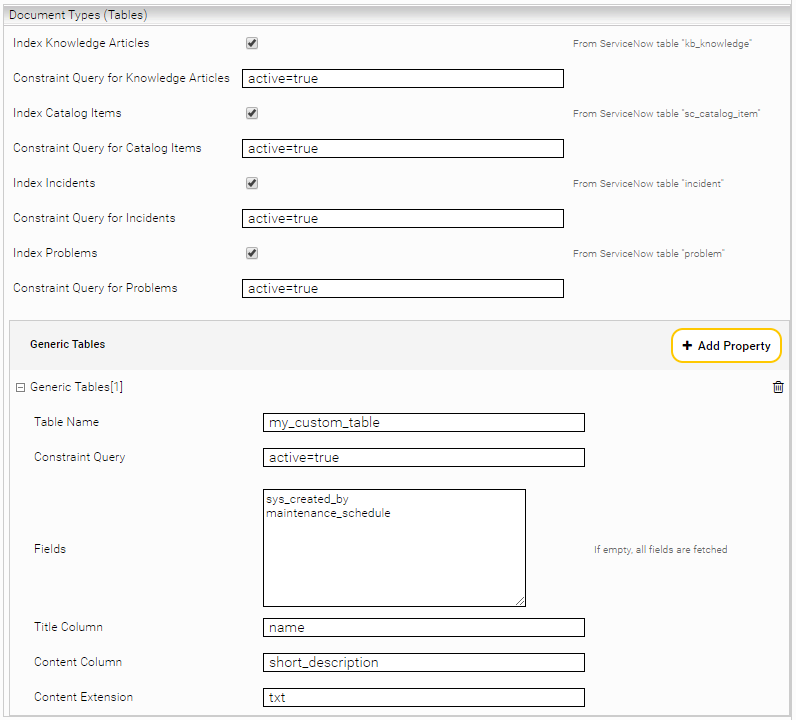
Document types (tables)
Setting | Description | ||||||||||||||
Index <<TABLE_NAME>> | When enabled, the table is indexed (for example, if “Index Knowledge Articles” is enabled, knowledge articles are crawled) | ||||||||||||||
Constraint Query for <<TABLE_NAME>> | A constraint query to restrict which records in a table are indexed (using the ServiceNow filter; see appendix: Constraint queries) | ||||||||||||||
Generic Tables | If you want to index tables other than knowledge articles, catalog items, incidents, or problems, you can configure that here:
|
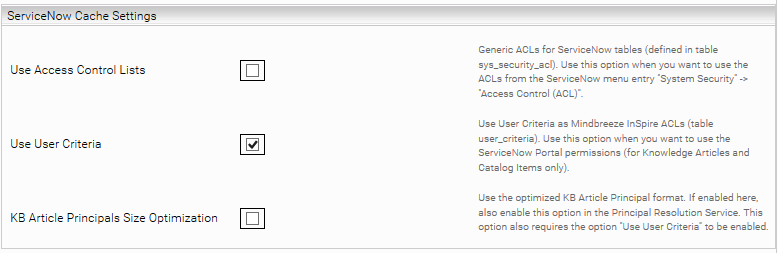
ServiceNow Cache Settings

Setting | Description |
Use Access Control Lists | Roles of ServiceNow ACLs are set to Mindbreeze documents. Only ACLs at the table level (no support at the column level) are included. In addition, the “Condition” and “Script” fields are not supported. Use this option if you are using “Resolve ACLs” in the principal resolution service. |
Use User Criteria | ServiceNow user criteria are set as Mindbreeze ACLs on knowledge articles and catalog items. The “Script” field is not supported. Use this option if you use the option “Resolve User Criteria” in the principal resolution service. |
Extended User Criteria Conditions | Extended User Criteria Conditions that are resolved in the ServiceNow Caching Principal Resolution Service. If there are Extended User Criteria Conditions in ServiceNow that are not specified here, documents that use these conditions cannot be found. Since in this case more requests have to be made against the ServiceNow API, this can also have a negative impact on the crawling speed. Important: Configure this option identically to the option in the ServiceNow Caching Principal Resolution Service. Otherwise, the permission structure cannot be mapped correctly. |
KB Article Principals Size Optimization | Reduces the number of principal containers when user criteria are used. This option is active by default and should not normally be disabled. However, if it is to be disabled anyway, then it must also be disabled in CachingServiceNowPrincipalResolutionService for the permissions to work correctly. |
If you use the “Use Access Control Lists” option, ACL references must be configured in the index. To do this, enable the “Use ACL References” option in the advanced settings of the index configuration.

In addition, we recommend that you configure the following options to hide documents in the search that are only used as ACL references:

Setting | Entry |
Dynamic Constraint Source Expr | category:Undefined |
Dynamic Constraint Pattern | NOT aclReference:true |
Dynamic Constraint Static Fraction | NOT aclReference:true |
A general documentation about these "Dynamic Constraints" settings can be found here.
CSV Logging
ServiceNow user criteria that are not supported by this plugin are logged in “objects-log.csv” in the current log directory:
Caching principal resolution service: user criteria that cannot be resolved (“Advanced”: “true”)
The following settings can be configured both in the crawler settings and in the caching principal resolution service settings:

Setting | Description |
Log Objects to CSV (Advanced Setting) | If enabled, processed objects are also logged |
Log Level (Advanced Setting) | Three levels:
This setting is only effective when "Log Objects to CSV" is enabled. |
Dump User Criteria to CSV | If enabled, CSV dump files are stored in the current log directory:
|
Crawler settings

Setting | Description |
Open URL Template* | A template for the URL that is used to open a search result. The placeholders {{instnace_url}}, {{table}} and {{{sys_id}} can be used; for example: |
Configuring the Caching Principal Resolution Service
In the new or existing service, select the CachingServiceNowPrincipalResolutionService option in the Service setting. For more information about additional configuration options and how to create a cache and how to do the basic configuration of a cache for a Principal Resolution Service, see Installation & Configuration - Caching Principal Resolution Service.
The following tables explain the settings that you can configure for the caching principal resolution service.
Legend:
- Properties marked with an *: required fields – these must be explicitly configured
- Properties not specifically marked: optional fields
Connection Settings
Setting | Description |
Instance URL* | The URL for the ServiceNow instance; for example https://myorganization.service-now.com/ |
Token URL* | The token endpoint URL; for example, https://myorganization.service-now.com/oauth_token.do |
Grant Type* | The grant type for retrieving the OAuth2 token (usually “password”) |
Client ID* | The client ID of the OAuth2 application that is configured in ServiceNow |
Client Secret* | The client secret of the OAuth2 application that is configured in ServiceNow |
Username* | The crawler user’s username |
Password* | The crawler user’s password |
Download Settings
Setting | Description |
The page size of the REST API bulk requests (default 1000) |
ServiceNow Cache Settings

Setting | Description |
Constraint Query for Users | A constraint query to restrict which users are fetched by ServiceNow when updating the cache. (using ServiceNow filter, see Appendix: Constraint Queries). This option can be used to restrict the cache to relevant users. |
Resolve ACLs | Roles of the ServiceNow ACLs are resolved. Only ACLs at the table level (no support at the column level) are included. In addition, the “Condition” and “Script” fields are not supported. Use this option if you use the “Use Access Control Lists” option in the crawler. |
Resolve User Criteria | User criteria users, groups, roles, companies, locations, and departments are resolved. The “Script” field is not supported. Use this option if you use the “Use User Criteria” option in the crawler. |
Extended User Criteria Conditions | Extended User Criteria Conditions which should be resolved. The conditions can be specified either with the internal column name (e.g. "u_my_condition") or with the display name (e.g. "My Condition"). Important: Configure this option identically to the option in ServiceNow Crawler. Otherwise, the permission structure cannot be mapped correctly. |
Resolve Knowledge Article User Criteria | If this option is enabled, the User Criteria for Knowledge Articles are resolved. For better performance or permission control, you can disable this option if you are not indexing Knowledge Articles. |
Constraint Query for Knowledge Articles | A constraint query to restrict which Knowledge Article User Criteria are resolved (using ServiceNow filters, see Appendix: Constraint Queries). This option should be configured identically to the crawler. |
Resolve Catalog Item User Criteria | If this option is enabled, the User Criteria for Catalog Items are resolved. For better performance or permission control, you can disable this option if you are not indexing Catalog Items. |
A constraint query to restrict which category item user criteria are resolved (using ServiceNow filters, see Appendix: Constraint Queries). This option should be configured identically to the crawler. | |
Resolve HR Criteria | Enable this option if you are using HR Criteria in addition to User Criteria. This option has no effect if Resolve User Criteria is disabled. |
KB Article Principals Size Optimization | Reduces the number of principal containers when user criteria are used. This option is active by default and should not normally be disabled. However, if it is to be disabled anyway, it must also be disabled in the ServiceNow crawler for the permissions to work correctly. |
Resolve Empty User Criteria to All Users | If this option is enabled, all empty User Criteria (User Criteria with no criteria set) are resolved to all ServiceNow users. This reflects the behavior in ServiceNow. You can disable this option if you do not use empty User Criterias. |
Advanced User Criteria Resolution | See next section. |
Advanced User Criteria Resolution (Advanced Settings)
Here you can configure rules on how which user criteria are resolved in order to map special permissions in Mindbreeze InSpire. This is particularly useful if you use user criteria that are not supported by Mindbreeze InSpire by default.
This concerns user criteria for which “Advanced” is set (“Script”, except if the user criteria record was generated by an "HR Criteria”)
Setting | Description | ||||||||||
The User Criteria column/field in ServiceNow to which the "UC Selection: Column Pattern" is applied.
| |||||||||||
UC Selection: Column Pattern | The pattern that is applied to the User Criteria column/field ("UC Selection: Column Name"). The pattern is a Java regex where "." (dot) also matches on \n\r (e.g. relevant for field script). Note that a full match must be made on the field so that the "Result Action" is performed for a matching User Criteria. E.g. on the field value "My User Criteria" - "My User" would not match, but - "My User.*" would indeed match | ||||||||||
Resolution Action | Here you can define how to resolve the User Criteria for which "UC Selection: Column Name / Patter" match.
|
CSV Logging (Advanced Settings)
Setting | Descripton |
Log Objects to CSV | If enabled, statistics are logged to the file “objects-log.csv” in the current log directory. |
Log All Objects | If enabled, also successfully processed objects are logged to the CSV. Only has effect if Log Objects to CSV is active. |
Dump User Criteria to CSV | If enabled, all user criteria are written to the CSV file “user-criteria-dump.csv” in the current log directory. |
Dump HR Criteria to CSV | If enabled, all HR criteria are written to the CSV file “hr-criteria-dump.csv” in the current log directory. |
Appendix
Granular crawler permissions (optional)
If you would like to have more control over the permissions of the crawler user, you can define separate roles so that the crawler user has read access to the appropriate tables through the REST API. Create your own ACL rules for all these tables, because some tables have default ACL rules that only allow access to certain entries, which can lead to unexpected behavior.
The crawler user must have read access to the following tables:
- Data tables (depending on which tables you want to index)
- sys_attachment (All Fields)
- kb_knowledge (All Fields)
- sc_cat_item (All Fields)
- incident (All Fields)
- problem (All Fields)
- ... (additional tables you want to crawl) (sys_id, sys_updated_on, all configured fields to index)
- Metadata for tables (Type information relevant for indexing)
- sys_dictionary (All Fields)
- sys_db_object (All Fields)
- sc_req_item (stage, cat_item)
- General authorizations
- sys_user (sys_id, email, active, company, location, department)
- sys_user_group (sys_id, parent)
- sys_user_grmember (user, group)
- sys_user_has_role (user, role)
- Authorizations using ACLs (only necessary if you use ACLs)
- Authorizations based on user criteria (only necessary if you use user criteria)
- For Category Items (only necessary if you index and resolve category items)
- sc_category_user_criteria_mtom (All Fields)
- sc_category_user_criteria_no_mtom (All Fields)
- sc_cat_item_user_criteria_mtom (All Fields)
- sc_cat_item_user_criteria_no_mtom (All Fields)
- For Knowledge Articles (only necessary if you index and resolve knowledge articles)
- sys_properties (sys_name, value)
- kb_uc_can_contribute_mtom (All Fields)
- kb_uc_cannot_contribute_mtom (All Fields)
- kb_uc_can_read_mtom (All Fields)
- kb_uc_cannot_read_mtom (All Fields)
- user_criteria (All Fields)
- sc_category (All Fields)
- For Category Items (only necessary if you index and resolve category items)
- Authorizations based on HR Criteria (only necessary if you use HR criteria)
- sn_hr_core_criteria (All Fields)
- sn_hr_core_m2m_condition_criteria (All Fields)
- sn_hr_core_condition (All Fields)
- All tables referenced in your HR Conditions (the columns referenced in the HR conditions)
- Related Tables (tables not accessed directly, but that have relationships to other tables that are fetched for indexing)
- sc_cat_item_delivery_plan (Table Access, needed for sc_cat_item)
- sys_scope (Table Access, needed for all tables)
- topic (Table Access, needed for sc_cat_item)
- core_company (Table Access, needed for incident, sys_user)
- cmdb_ci (Table Access, needed for incident, problem)
- cmdb_ci_service (Table Access, needed for incident)
- sys_glide_object (Table Access, needed for sys_dictionary)
- cmn_location (Table Access, needed for sys_user)
- cmn_department (Table Access, needed for sys_user)
- sys_security_type (Table Access, needed for sys_security_acl)
- sys_security_operation (Table Access, needed for sys_security_acl)
- sc_homepage_renderer (Table Access, needed for sc_category)
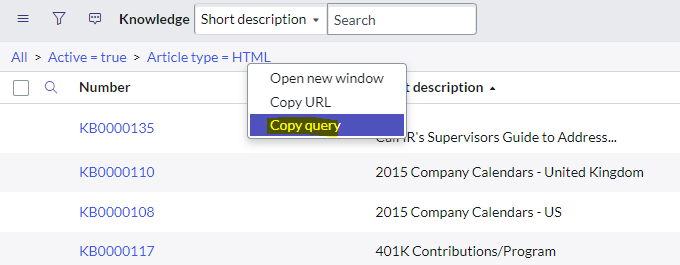
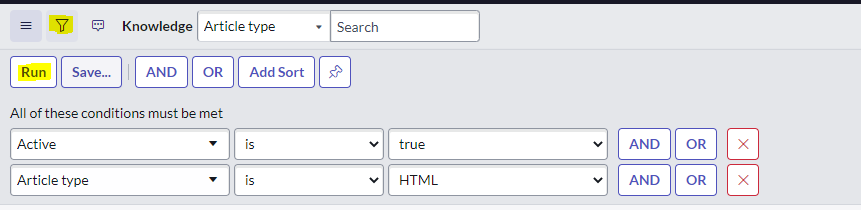
Constraint queries
You can use filters to ensure that the crawler only indexes specific records. To do this, open any table in ServiceNow that you want to filter and apply the filter. Right-click on the filter expression and then click on the “Copy query” entry in the context menu. The filter expression copied from the screenshot below will look like this: active=true^article_type=text. You can define this expression in the configuration of the data source in the Mindbreeze Management Center; for example, under “Constraint Query for Knowledge Articles” or “Generic Tables.” Insert “Constraint Query.”