
Sure, you can handle it. But should you?
Let our experts manage the tech maintenance while you focus on your business.
Let our experts manage the tech maintenance while you focus on your business.
Installation and Configuration
Microsoft SharePoint Online Connector
Installation
Before installing the SharePoint Online connector, make sure that the Mindbreeze server is installed and the SharePoint Online connector is included in the license. Use the Mindbreeze Management Center to install or update the connector.
Hint: Microsoft Entra ID (ME-ID) is the new name for Microsoft Azure Active Directory (Azure AD). For more information about what Microsoft Entra ID is and what changes to note with the name change, see What is Microsoft Entra ID? - Microsoft Entra | Microsoft Learn and New name for Azure Active Directory - Microsoft Entra | Microsoft Learn
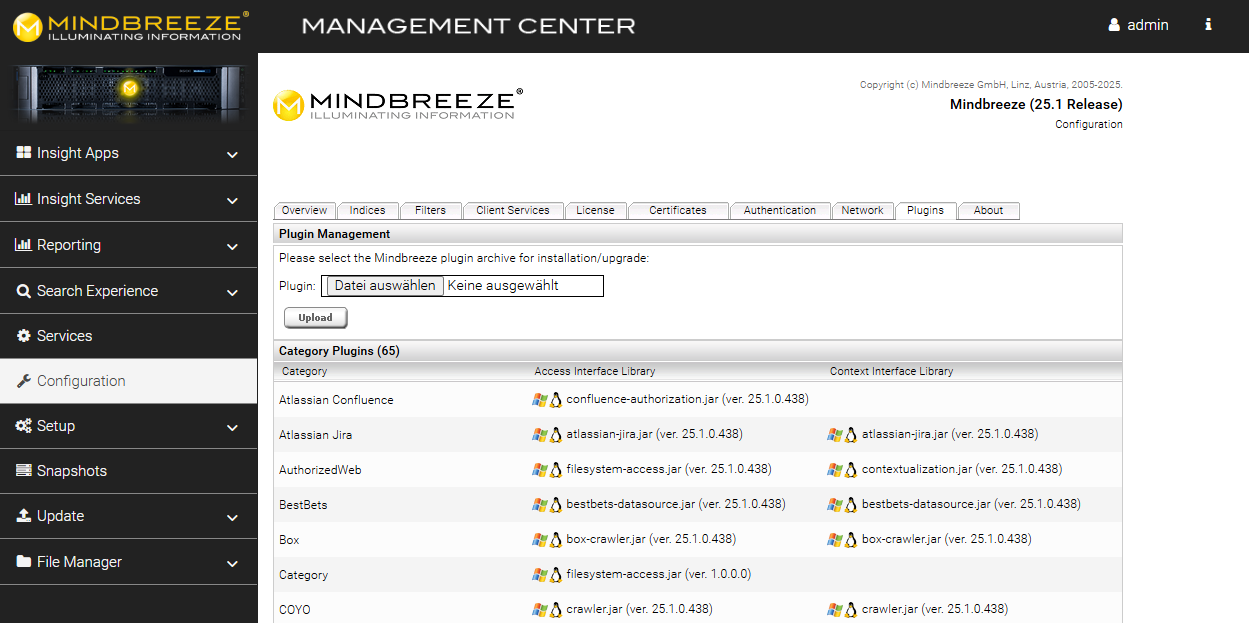
Plugin installation via Mindbreeze Management Center
To install the plug-in, open the Mindbreeze Management Center. Select “Configuration” from the menu pane on the left-hand side. Then navigate to the “Plugins” tab. Under “Plugin Management,” select the appropriate zip file and upload it by clicking “Upload.” This automatically installs or updates the connector, as the case may be. In the process, the Mindbreeze services are restarted.
Overview
To configure the SharePoint Online Connector by default, the following plugins must be configured:
- SharePoint Online Crawler (Chapter: Configuring the data source)
- SharePoint Online Principal Cache Service (Chapter: Configuring the principal resolution service)
- Microsoft AAD Graph Principal Resolution Service (Chapter: Configuration of the Microsoft AAD Graph Principal Resolution Service)
- Optional if LDAP available: Configuration - LDAP Connector
Configuring Mindbreeze
Select the “Advanced” installation method for configuration.
Configuring the index
To create a new index, navigate to the “Indices” tab and click the “Add Index” icon in the upper right corner.
Enter the path to the index and change the display name as necessary.

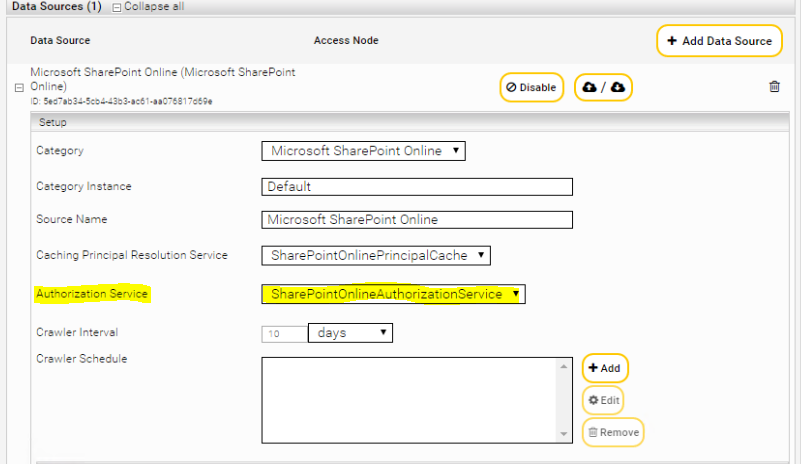
Configuring the data source
Add a new data source by clicking the “Add new custom source” icon at the top right. Select the category “Microsoft SharePoint Online” and configure the data source according to your needs.
Section “Sharepoint Online”
In the "Sharepoint Online" area you can define your Microsoft SharePoint Online installation that is to be indexed. The following options are available:
Setting | Description |
Server URL | The URL of the Sharepoint Online instance, e.g.: https://myorganization.sharepoint.com |
Admin Server URL | The admin URL of the SharePoint Online instance. Often this is just the server URL with the suffix -admin. e.g: https://myorganization-admin.sharepoint.com |
Site Relative URL | The relative paths to the sites to be crawled, starting with a slash, e.g.: /sites/mysite. Each line can contain a path. If this field is left empty, all detected sites are crawled. When sites are specified in this field, only specified sites and their subsites are crawled. |
Detect Yammer Attachment Sites | When this setting is enabled, additionally to your currently configured Site Discovery Settings, the Crawler tries to find every SharePoint Site which was automatically created by Yammer to store attachments. When this setting is enabled and no Site Relative URLs are defined, only Yammer Attachment Sites will be crawled. |
Site Discovery Schedule | An extended cron expression that specifies when to run site discovery. The results are then used in the next crawl runs. This means that the potentially time-consuming site discovery does not have to be repeated with each crawl run. Documentation and examples of cron expressions can be found here. |
Background Site Discovery Parallel Request Count | Limits the number of parallel HTTP requests sent by the Site Discovery. |
Site Discovery Strategy | The strategy by which the site discovery is to be performed.
|
Ignore Site Discovery Errors | If this option is enabled, all site discovery errors will only be logged and otherwise ignored. You can use this option if you have a large and constantly changing number of sites and unexpected errors occur. |
Do Not Crawl Root Site | If this option is activated, the root page of the Sharepoint Online instance (e.g. myorganization.sharepoint.com) and its subpages will not be crawled. |
Included Sites URL (regex) | Regular expression that can be used to specify which subsites are to be crawled. If this option is left empty, all subsites will be crawled. The regex matches relative URLs. e.g /sites/mysite |
Excluded Sites URL (regex) | Regular expression that can be used to specify which subsites are to be excluded. The regex matches relative URLs. e.g /sites/mysite |
Included Lists/Files/Folders URL (regex) | Regular Expression, which can be used to specify which lists, files and folders should be included. The metadata "url" (absolute url) is compared. If this option is left empty, everything is included. Note: If you want to include/exclude complete subsites, please use the option "Included Sites URL (regex)" or "Excluded Sites URL (regex)" |
Excluded Lists/Files/Folders URL (regex) | Regular Expression, which can be used to specify which lists, files and folders should be excluded. The metadata "url" (absolute url) is compared. For example, if you find a document in the Mindbreeze search that you want to exclude, you can copy the URL from the "Open" action and use it in the "Excluded Lists/Files/Folders URL (regex)" option |
Included Metadata Names (regex) | Regular expression used to include generic metadata with the name of the metadata. If nothing is specified, all metadata is included. The regex is applied to the name of the metadata (without the sp_ prefix). |
Excluded Metadata Names (regex) | Regular expression that excludes generic metadata with the name of the metadata. If nothing is specified, all metadata is included. The regex is applied to the name of the metadata (without the sp_ prefix). |
Index Complex Metadata Types (regex) | Regular expression that can be used to include complex metadata for indexing. By default, complex metadata (e.g. metadata entries that themselves have multiple metadata) are not indexed. This pattern refers to the "type" of the metadata, for example SP.FieldUrlValue for Link Fields or SP.Taxonomy.TaxonomyFieldValue for Managed Metadata. |
Included Content Types (regex) | Regular expression that includes content types (e.g. file, folder) via the name of the content type. If nothing is specified, all content types are included. The content type of objects can be found in the contenttype metadata. |
Excluded Content Types (regex) | Regular expression that excludes content types (e.g. file, folder) via the name of the content type. If nothing is specified, all content types are included. The content type of objects can be found in the contenttype metadata. |
[Deprecated] Use delta key format | This option is deprecated and should always be left enabled so that the full functionality of the crawler can be used. If set, a different format is used for the keys. Certain functions of the delta crawl (e.g. renaming lists, deleting attachment files) do not work without this option. If this option is changed, the index should be cleaned and re-indexed. |
Enable Delta Crawl | If set, the Sharepoint Online API will only fetch changes to files instead of crawling over the whole Sharepoint Online instance. For full functionality "Use delta key format" should be set. |
Skip Delta Errors | If set, errors are skipped during the delta crawl. Otherwise, the document where the error occurred will be indexed again during the next crawl run. Warning: If this option is enabled, there may be differences between the Mindbreeze index and SharePoint Online. Enable this option only temporarily if persistent errors occur during delta crawling that do not resolve after several crawl runs. |
Index Sites As Document | If set, all SharePoint Online sites are also indexed as Mindbreeze documents. The content of these documents is the Welcome Page of the site. When you deactivate this setting, a complete re-index is required. |
Crawl hidden lists | If set, lists that are defined as hidden are also indexed |
Crawl lists with property 'NoCrawl’ | If this option is set, those lists are also indexed that have the "NoCrawl" property in Microsoft SharePoint Online |
Max Change Count Per Site | Number of changes that are processed in the delta crawl per page before the next page is processed. The remaining changes are processed at the next crawl run. |
Trust all SSL Certificates | Allows the use of unsecured connections, for example for test systems. Must not be activated in production systems. |
Parallel Request Count | Limits the number of parallel HTTP requests sent by the crawler. |
Page Size | Maximum number of objects received per request to the API. A high value results in higher speed but higher memory consumption during the crawl run, a small value results in less memory consumption but reduces the speed. If the value is set to 0, no paging is used, meaning that the crawler attempts to fetch all objects at once with the request. |
Max Content Length (MB) | Limits the maximum document size. If a document is larger than this limit, the content of the document is not downloaded (the metadata is retained). The default value is 50 megabytes |
[Deprecated] Send User Agent | This option is deprecated and should always remain enabled. The User Agent header should always be sent with the request. Adjust the "User Agent" option instead. If set, the header configured with the "User Agent" option is sent with every HTTP request. |
User Agent | The specified value is sent with the HTTP request in the User-Agent header, it the option “Send User Agent” is set. |
Thumbnail Generation for Web Content (Advanced Setting) | If set, thumbnails are generated for web documents. It is not recommended to enable this feature as it only works for public pages with anonymous access which have already been discontinued. |
Dump Change Responses | If set, the Sharepoint API responses are written to a log file during delta crawling. |
Log All HTTP Requests | If set, all HTTP requests sent by the crawler during the crawl run are written to a .csv file (sp-request-log.csv). |
Update Crawler State During Crawlrun | If set, the crawler state is continuously updated during the crawl run (instead of only at the beginning of the crawl run), which can prevent multiple downloads of the same file in certain situations. This option is only active for Delta Crawlruns. |
Recrawl CSV File Path | If set, the specified file will be monitored and in case of changes during the crawl, a re-indexing of certain pages, lists or items/files can be triggered. The CSV file must have the following header: Each line can have the following values:
Only the Site Relative URL is required, the rest of the values are optional. Example lines: /sites/Marketing;Documents;Schedule.docx;true: The file “Schedule.docx” in the list “Documents” in the site “/sites/Marketing” will be re-indexed. /sites/Marketing;SalesData;;: The list "SalesData" in the site "/sites/Marketing" and all its items will be re-indexed if they have not been indexed yet or if their modification date or permission information is different from the currently indexed version. After the CSV file is processed, it is renamed to <filename>.old. Then a new file can be created with new objects to be indexed. For performance reasons, it is recommended to put the CSV file in its own folder, without other files that are often edited. For this the mes user needs at least Read, Write and Execute permissions on the folder and Read and Write permissions on the file. |
Custom Delta CSV Path | With this option a path to a .csv file can be specified, with which own delta points can be set. Each line must contain two entries separated by semicolons: First the Site Relative URL and then a time in the format yyyy-MM-ddTHH:mm:ssZ. Example: /sites/MySite; 2019-10-02T10:00:00Z This state is not adopted if a state already exists. If the old state is to be overwritten, it must be deleted from the DeltaState file. |
Deleted Items Cleanup Strategy (Advanced Setting) | Determines how documents are deleted within document libraries. The following options are available:
Default setting: Delete Event Only |
Deleted Items Cleanup Schedule (Advanced Setting) | Specifies with an extended cron expression when documents in document libraries should be deleted. The deletion will take place during the next crawl run. You can find documentation and examples of cron expressions here. |
Update ACLs and URLs Strategy | Defines how the updating of ACLs (and URL metadata) should be performed. The following options are available:
Default setting: Change Event Only |
ACLs and URLs Update Schedule (Advanced Setting) | Specifies with an extended cron expression when ACLs (and URL metadata) should be updated. The updates will be applied during the next crawl run. You can find documentation and examples of cron expressions here. |
Check for Role Update within past Days | With this setting, the crawler will check for Role Updates of all sites within the past days as configured. Due to limitations of the SharePoint Online getChanges API, the maximum value is 59 days. |
Dry Run Role Update Check | If set, the check for Role Updates since the date configured above is only logged into a role-update.csv file instead of being fully processed. |
Ignore Sharepoint ACLs (Advanced Setting) | If set, no access permissions to lists or documents are fetched from Sharepoint. This option can only be set if at least one Site ACL is configured. |
Use ACL References (Advanced Settings) | If this setting is enabled, crawling is performed more efficiently by avoiding access permission resolution for documents and items that inherit permissions. This setting requires the setting “Use ACL Reference” to also be enabled in the index configuration. Changing this setting requires a full reindexing of all documents. |
Site ACL | With this option you can set your own ACLs. The Site URL Pattern is a regular expression for which pages this principal should be configured, Access Check Action can be used to select whether it is a grant or deny, and Principal is used to specify the group/user to which the principal should apply (e.g. everyone or max.mustermann@myorganization.onmicrosoft.com). |
Remove Old Documents From Index (Number Of Years) | If configured, documents whose modification date is older than the specified number of years are removed from the index at the end of a traversal. This date is calculated from the start date of the crawler minus the number of years configured in this field. Example: The modification date of a document is 20.09.2020 and the setting “Remove Old Documents From Index (Number Of Years)” is configured with the value “3”. Accordingly, the document is removed from the index on the 21.09.2023. Hint: Reducing the number of years is possible without reindexing but increasing or removing the setting is only possible with a reindex to fetch all data again. |



Section “Azure Endpoints”
Only enter the URL for the Azure AD endpoint in the “Azure AD endpoint” field if you use a SharePoint National Cloud.
The following environments require special URLs:
Environment | URL |
China | |
US Government |
A complete list for Azure endpoints can also be found at:
Section “Application Authentication”
Configure the settings as follows:
Setting | Description |
Use Application Authentication | When this setting is selected, application authentication is used instead of user-based authentication. If this setting is selected, “Client ID” and “App Certificate” also need to be configured. In addition, you need to perform all the “App Registration” steps below. |
Client ID | The client ID that is generated as described below. |
App Certificate | The Certificate Credential as described below. |
[Deprecated] App-Only Credential (Advanced Settings) | Attention: This setting is deprecated and should no longer be used. Use the setting “App Certificate” instead. The credential that was created in the Network tab and contains the Client ID and the Secret generated, as described below. |
[Deprecated] Client secret (Advanced Settings) | Achtung: This setting is deprecated and should no longer be used. Use the setting “App Certificate” instead. The client secret that is generated as described below. |
See the chapter Certificate-based Application Authentication for more details.
The creation of a new application is carried out in Microsoft Entra - Microsoft Entra admin center. For more information, see the following links:
- Registration of a new application: How to register an app in Microsoft Entra ID - Microsoft identity platform | Microsoft Learn
- Creation of a Client Secret: Add and manage app credentials in Microsoft Entra ID - Microsoft identity platform | Microsoft Learn
- Granting of access rights: Web API app registration and API permissions - Microsoft identity platform | Microsoft Learn
Section “Performance Settings” (Advanced Settings)
Setting | Description |
Concurrent Filter and Index Dispatch Threads | Defines the number of threads that send data to the Filter Service and the Index Service. If the number is less than or equal to zero, data is transmitted serially. |
Document Library Root Folder | Defines a list of folders in document libraries that are to be explicitly targeted for indexing. The folders are specified as folder paths (one path per line). The following structure must be followed: /sites/<Site Name>/<List Name>/<Folder Name>/<Subfolder Name> Examples: /sites/mysite/Shared Documents/dir1 /sites/mysite/My Documents/dir2/subdir Hint: This is not a regular expression. Placeholders are not supported. Do not use URL encoding, use the original values instead. Avoid duplicates or paths that are already included in other paths. This setting is a performance optimization and should only be used in specific situations where only individual folders within a document library are to be indexed, rather than the entire document library. |
Section “Content Settings“ (Advanced Settings)
Setting | Description |
Do Not Request File Author Metadata | If active no information regarding authors is requests for Lists, Items or Files. This may help resolve the following Error: „HTTP 500: User cannot be found". |
Get Author From File Properties | If active, the author metadata is retrieved from the File/Properties object instead of the File/Author object. This prevents errors during crawl runs, for example, if the user has since been deleted. A complete re-index is required so that this option can be used correctly. |
List All Content Types | If active, an all-content-types.csv file is created in the log directory at the beginning of a crawl run, which contains all content types of all lists of all configured pages. |
Analyse Completeness | When enabled, a list-based completeness analysis of the index is performed during the crawl, which is written to a CompletenessAnalysis.csv file in the log directory. Note: The Completeness Analysis does not check all sites in SharePoint Online, but only those that are configured for indexing. |
Include Unpublished Documents | If active, all documents/items are always indexed in their most recent version, regardless of whether they have already been published. If this option is disabled, only published sites and only major versions (1.0, 2.0 etc., usually created with each publish) will be indexed. |
ASPX Content Metadata | With this option you can set your own metadata as content for .aspx files. By default, "WikiField" and "CanvasContent1" are used. If metadata is set with this option, it will be used instead, if available. For this option to be applied correctly, a full re-index is required. |
Download OneNote Files as HTML via Graph API | If enabled, all OneNote documents (.one files) are downloaded as HTML documents via the Microsoft Graph API. This allows for a more accurate interpretation of the document contents. The documents will still be displayed as .one files. Note: To use this function, the following points must be taken into account:
|
Section “Graph API” (Advanced Settings)
Setting | Description |
Graph Service Root | The endpoint/URL of the Microsoft Graph API. By default, "https://graph.microsoft.com". Change this setting only if you are using a national (non-international) Microsoft Cloud. A list of all available national cloud endpoints can be found further below. |
Graph Tenant ID | The Tenant ID of your Microsoft 365 instance. You can find this on the Overview page of the app you created in Azure. |
Graph App ID | The Application (Client) ID of the app created in Azure. |
Graph Client Secret | The Credential created in the Network tab, which contains the created Client Secret. |
Available national Microsoft Cloud endpoints
Endpoint | URL |
Globaler Service | https://graph.microsoft.com |
China | https://microsoftgraph.chinacloudapi.cn |
US Government L4 | https://graph.microsoft.us |
US Government L5 (DOD) | https://dod-graph.microsoft.us |
You can find a complete list of national Cloud Endpoints here:
https://learn.microsoft.com/en-us/graph/deployments#microsoft-graph-and-graph-explorer-service-root-endpoints
Creating the Application in Microsoft Entra ID
In order for Microsoft Graph to be retrieved from the SharePoint Online Connector, a new app must first be created that has the permissions for Microsoft Graph.
The creation of a new application is carried out in Microsoft Entra - Microsoft Entra admin center. For more information, see the following links:
- Registration of a new application: How to register an app in Microsoft Entra ID - Microsoft identity platform | Microsoft Learn
- Creation of a Client Secret: Add and manage app credentials in Microsoft Entra ID - Microsoft identity platform | Microsoft Learn
- Granting of access rights: Web API app registration and API permissions - Microsoft identity platform | Microsoft Learn
The application must have the following access rights:
- Notes.Read.All
- Sites.Read.All
Attention: Make a note of the client secret immediately after it has been created, as it can no longer be viewed once you have left the page. You must copy the value in the column “Value” of the created secret so that you can enter it directly into the Mindbreeze configuration. You can add the secret in the “Network” tab under the section “Credentials” by clicking on “Add Credential.”
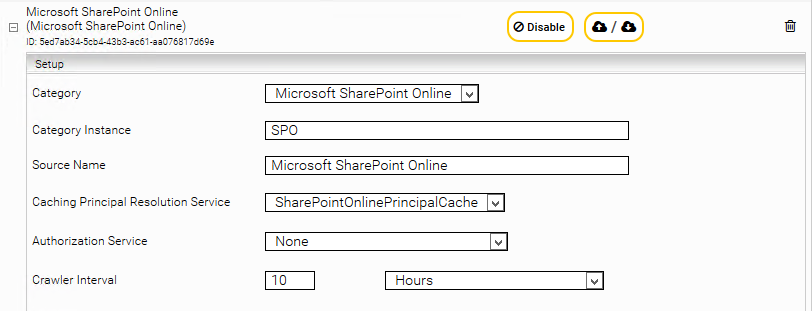
Configuration of the principal resolution service
In the new or existing service, select in the Service setting the option SharepointOnlinePrincipalCache. For more information about additional configuration options and how to create a cache and how to do the basic configuration of a cache for a Principal Resolution Service, see Installation & Configuration - Caching Principal Resolution Service.

Section “Sharepoint Online”
Setting | Description |
Server URL | The URL of the Sharepoint Online instance, e.g.: https://myorganization.sharepoint.com Should be configured the same way as in the crawler. |
Admin Server URL | The admin URL of the SharePoint Online instance. Often this is just the server URL with the suffix -admin. e.g: https://myorganization-admin.sharepoint.com Should be configured the same way as in the crawler. |
Regex for your organization | Regular expression that defines whether a user belongs to the organization or not. This is used to resolve the principal “everyone_except_external”. Caution: This is a security relevant setting! The regular expression can refer to the e-mail address, the ObjectSID or the ObjectGUID from LDAP. The default value contains no users. |
Site Relative URL | The relative paths to the sites to be crawled, starting with a slash, e.g.: /sites/mysite. Each line can contain a path. If this is left empty all detected sites are crawled. If Sites are specified here only this sites and their subsites are crawled Should be configured the same way as in the crawler. |
Site Discovery Schedule | An extended cron expression that specifies when to run site discovery. The results are then used in the next crawl runs. This means that the potentially time-consuming site discovery does not have to be repeated with each crawl run. Documentation and examples of cron expressions can be found here. |
Background Site Discovery Parallel Request Count | Limits the number of parallel HTTP requests sent by the Site Discovery. |
Site Discovery Strategy | The strategy by which the site discovery is to be performed.
|
Ignore Site Discovery Errors | If this option is enabled, all site discovery errors will only be logged and otherwise ignored. You can use this option if you have a large and constantly changing number of sites and unexpected errors occur. |
Do Not Crawl Root Site | If this option is activated, the root page of the Sharepoint Online instance (e.g. myorganization.sharepoint.com) and its subpages will not be crawled. Should be configured the same way as in the crawler. |
Included Sites URL (regex) | Regular expression that can be used to specify which subsites are to be crawled. If this option is left empty, all subsites will be crawled. The regex matches relative URLs. e.g /sites/mysite Should be configured the same way as in the crawler. |
Excluded Sites URL (regex) | Regular expression that can be used to specify which subsites are to be excluded. The regex matches relative URLs. e.g /sites/mysite Should be configured the same way as in the crawler. |
Enable Delta Update | If enabled, only the changes to the groups will be fetched from Sharepoint Online after the first cache creation, instead of fetching all groups each time. This is especially recommended for very large Sharepoint instances, as a regular cache update can otherwise take a long time. Delta Updating with User Based Authentication is not supported - if Delta Updating is required, App Only authentication must be used |
Skip Cache Empty Check | If enabled, the check whether the cache is empty in order to make a full update in this case is skipped. Attention: This option may only be activated if the cache has already been completely and successfully built once. Do not delete the cache directory manually if this option is enabled! The cache will not be completely rebuilt in this case! This option should only be enabled if there are performance problems with very large caches. |
[Deprecated] Send User Agent | This option is deprecated and should always remain enabled. The User Agent header should always be sent with the request. Adjust the "User Agent" option instead. If set, the header configured with the "User Agent" option is sent with every HTTP request. |
User Agent | The specified value is sent with the HTTP request in the User-Agent header. |
Dump Change Responses | If activated, the changes we receive from Sharepoint Online during the Delta Update are dumped into a file. This is very helpful for troubleshooting. |
Log All HTTP Requests | If set, all HTTP requests sent by the Principal Resolution Service during the cache update are written to a .csv file (sp-request-log.csv). |
Parallel Request Count | You can use this option to define how many HTTP requests are sent simultaneously by the crawler. The higher the value, the faster the crawl run should be, but too high a value can also lead to many "Too Many Requests" errors on the part of Sharepoint. A value above 30 is not recommended. |
Page Size | Maximum number of objects received per request to the API. A high value results in higher speed but higher memory consumption during the cache update, a small value results in less memory consumption but reduces the speed. If the value is set to 0, no paging is used, meaning that the crawler attempts to fetch all objects at once with the request. |
Trust all SSL Certificates | Allows the use of unsecured connections, for example for test systems. Must not be activated in production systems. |
Heap Dump On Out Of Memory | When activated, the Principal Service will do a Heap Dump if it runs Out Of Memory |

Section “Application Authentication”
Configuration should be done similar to the Application Authentication in the data source.

Parent Cache Settings
If an LDAP cache is to be used as a parent cache, the following values should be entered in the LDAP cache under “User Alias Name LDAP Attributes” or “Group Alias Name LDAP Attributes”:
cn
objectGUID
objectSID
For more information about Parent Cache Settings, see Installation & Configuration - Caching Principal Resolution Service - Parent Cache Settings.
For more Information about the LDAP cache and the LDAP connector, see Configuration - LDAP Connector.
Section “Azure Endpoints”
Only enter the URLs for Azure AD Endpoint Endpoint in the “SharePoint Azure AD Endpoint” field if you use a SharePoint National Cloud.
The following environments require special URLs:
Environment | URL |
China | |
US Government |
A complete list for Azure AD endpoints can also be found at https://learn.microsoft.com/en-us/azure/active-directory/develop/authentication-national-cloud#azure-ad-authentication-endpoints.

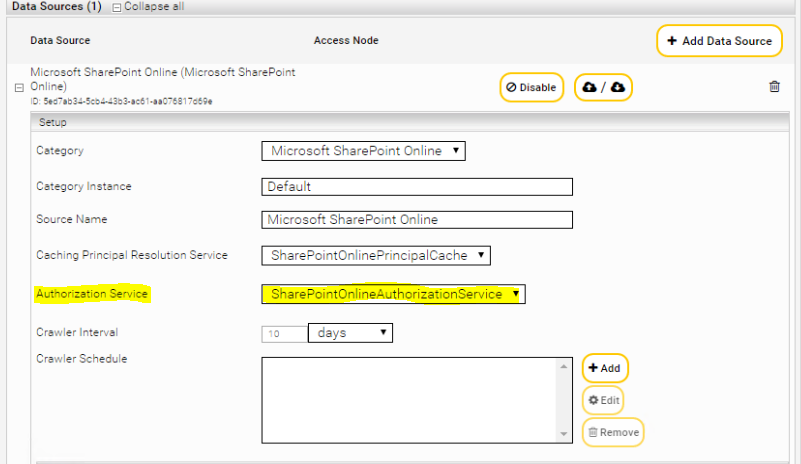
Using the SharePoint Online Authorization Service
The SharePoint Online Authorization Service makes requests to SharePoint Online for each object to find out whether the respective user actually has access to this object. Since this can take a lot of time, the Authorization Service should only be used for testing purposes - normally, all checks of the Authorization Service should be positive anyway. But this makes it easy to find out if there are any problems with the permissions of certain objects.
In order to use the Authorization Service in the search, you have to set the option "Approved Hits Reauthorize" in the index Advanced Settings to "External Authorizer" and in the crawler the Authorization Service created has to be selected as "Authorization Service".

Section „SharePoint Online“
Setting | Description |
Server URL | The URL of the Sharepoint Online instance, e.g.: https://myorganization.sharepoint.com Should be configured the same way as in the crawler. |
SharePoint Online Email Regex | Regex pattern for email addresses used in SharePoint Online. This pattern is used to decide which principal is used to check the permissions in SharePoint Online. |
Parallel Request Count | You can use this option to define how many HTTP requests are sent simultaneously by the authorization service. The higher the value, the faster it should be, but too high a value can also lead to many "Too Many Requests" errors on the part of Sharepoint. A value above 30 is not recommended. |
[Deprecated] Send User Agent | This option is deprecated and should always remain enabled. The User Agent header should always be sent with the request. Adjust the "User Agent" option instead. If set, the header configured with the "User Agent" option is sent with every HTTP request. |
User Agent | The specified value is sent with the HTTP request in the User-Agent header, it the option “Send User Agent” is set. |
Section “Azure Endpoints”
Only enter the URL for the Azure AD endpoint in the “Azure AD endpoint” field if you use a SharePoint National Cloud.
The following environments require special URLs:
Environment | URL |
China | |
US Government |
A complete list for Azure ACS endpoints can also be found at https://learn.microsoft.com/en-us/azure/active-directory/develop/authentication-national-cloud#azure-ad-authentication-endpoints.
Section „Application Authentication“
Configuration should be done similar to the Application Authentication in data source.
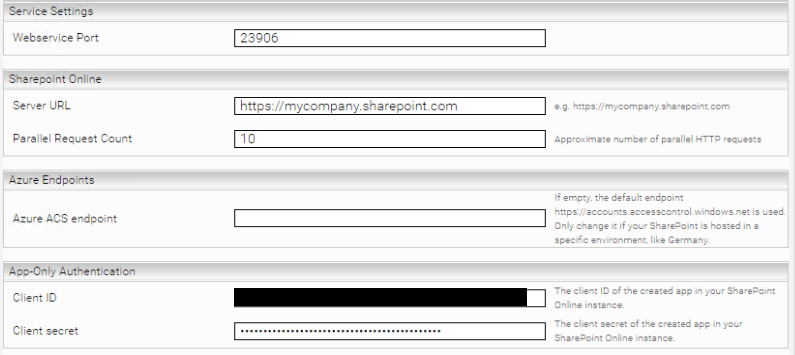
Configuring credentials and endpoints
If you are using application authentication, this section is NOT applicable to you. Otherwise, proceed as follows:
Navigate to the “Network” tab and add a new credential for Microsoft SharePoint Online under “Credentials” by clicking “Add Credential.”
Enter the credentials for the user you want to use for indexing and assign a name for the credential. Select a user with adequate permissions to read all relevant pages and permissions.

Then add a new endpoint for the credential you just created by clicking on “Add Endpoint” under “Endpoints.” Enter the server URL of your Microsoft SharePoint Online installation as the location and select the credential you just created.

Hints for crawling OneDrive
Configuration
With the help of the Sharepoint Online Connector, OneDrive pages can also be crawled.
For this you have to consider some points for the configuration:
- In the Server URL -my has to be appended to the tenant name, e.g. https://myorganization-my.sharepoint.com
- Site Discovery for OneDrive is supported, but requires AppOnly authentication
- The option "Grant Site Owner" in the Advanced Settings should be activated, otherwise there may be inconsistencies with the permissions.
Certificate-based Application Authentication
App Registration
The creation of a new application is carried out in Microsoft Entra - Microsoft Entra admin center. For more information, see the following link:
- Registration of a new application: How to register an app in Microsoft Entra ID - Microsoft identity platform | Microsoft Learn
Configuration steps in Azure Portal/Microsoft Entra ID
Creation of an Azure application with Tenant-Wide API Permissions
If an Azure application with Tenant-Wide API Permissions is needed, see the described configuration steps in Whitepaper - Migration of Tenant-Wide Permissions for the MS SharePoint Online Connector.
Creation of an Azure application with Sites Selected API Permissions
If an Azure application with Sites Selected API Permissions is needed, see the described configuration steps in Whitepaper - Migration of Sites Selected Permissions for the MS SharePoint Online Connector.
Configuration steps in Mindbreeze InSpire
Once an Azure application has been created with either Tenant-Wide or Sites Selected API permissions, the following configuration steps must be performed in Mindbreeze InSpire.
Requirements
- Mindbreeze InSpire has been updated to the Mindbreeze InSpire 26.1 Release or newer.
- Hint: If an older release is being used, the certificate-based authentication will not be available.
- A self-signed or CA-signed certificate (.cer, crt or .pem) is available and is already uploaded to the Azure application.
- Hint: If the .p12 certificate has multiple key pairs, only the first key pair in the certificate file is to be used for Mindbreeze InSpire.
Step 1: Upload of the certificate in Mindbreeze InSpire
To upload the created certificate in Mindbreeze InSpire, go to the Management Center and click on “Configuration” in the side navigation. Then continue to the “Certificates” tab, make sure that the certificate option “SSL” is selected and select the certificate in the format “.p12”. Enter the password, if the certificate is password protected or leave the field empty when the certificate is not password protected. Finally, “Upload” the certificate.

Hint: If the field “Password” is not visible, make sure that Mindbreeze InSpire is updated to the Mindbreeze InSpire 26.1 Release. For more information, see the chapter “Requirements”.
After the successful upload, the certificate will be listed in the section “Available SSL Certificates”.
The certificate is now ready to be assigned to services.
Step 2: Creation of the certificate credential
After the successful upload of the certificate in Mindbreeze InSpire, a credential must be created that uses the certificate for authentication.
Go to the “Network” tab and create a new credential with the following settings:
Entry | |
Name | Example: SPO Certificate Credential |
Type | Client Certificate |
Certificate | Choose the previously created certificate via dropdown menu. |
Save the credential to finish this step. Now, the certificate credential can be used by the SharePoint Online crawler, Principal Resolution Service and Authorization Service.
Step 3: Assigning the certificate credential
In this last step, the certificate credential must be assigned to the SharePoint Online crawler, Principal Resolution Cache and Authorization Service.
To assign the certificate credential, go to the section “Data Sources” in the connector or service and continue to the section “Application Authentication”. Set the following settings:
Entry | |
Use Application Authentication | Activated |
Client ID | The Application (Client) ID of your Microsoft Entra ID application. Example: 12a34bc5-67ef-89gh-10ij-klmn11121opq |
App Certificate | Choose the previously created certificate credential via dropdown menu. |
Finally, save the configuration to apply the changes and to finish the configuration of certificate-based authentication.
Hint: If an App-Only Client Secret or an App-Only Credential was configured previously, do the following:
- Select the option “None” in the advanced setting “[Deprecated] App-Only Credential”.
- Delete the entered value in the advanced setting “[Deprecated] App-Only Client Secret”.
Attention: If an “Azure ACS Endpoint” has been configured previously that is not the default endpoint, make sure to migrate the endpoint to the new advanced setting “Azure Active Directory Endpoint”.

Attention: In the case of indexing documents from Sites.Selected Azure applications, make sure that the crawler and cache setting “Do Not Crawl Root Site” in the section “Sharepoint Online” is activated. If this setting is deactivated, the crawler and cache will unsuccessfully try to crawl the root page of the SharePoint Online instance and its subpages while not having the according access rights due to the API permission “Sites.Selected”.
Appendix
Used SharePoint Online API Endpoints
The following SharePoint Online API endpoints are used by the SharePoint Online Crawler and the SharePoint Online Principal Resolution Service.
HTTP-Method | Description | |
<Azure Endpoint>/GetUserRealm.srf | POST | If the user is an ADFS user, the authentication server is fetched with this endpoint. |
<ADFS Authenticationserver> | POST | A login request is made against the server that was fetched with the GetUserRealm call. |
<Azure Endpoint>/rst2.srf | POST | A login token with the entered username/password credentials is retrieved. |
<ServerURL>/_vti_bin/idcrl.svc/ <AdminServerURL>/_vti_bin/idcrl.svc/ | GET | Login cookies are retrieved with the previously retrieved token. The cookies of the admin URL are required for SiteDiscovery. |
<AdminServerURL>/_vti_bin/sites.asmx | POST | With the previously retrieved cookies, a digest hash is retrieved, which is required for SiteDiscovery. |
<ServerURL>/_vti_bin/client.svc <AdminServerURL>/_vti_bin/client.svc | GET | This endpoint is used to get information about the tenant, e.g. the TenantId. |
<Azure Endpoint>/<Tenant Id>/tokens/OAuth/2 | POST | This endpoint is used to generate an Access Token for AppOnly Authorization. |
<AdminServerURL>/_api/ProcessQuery | POST | This endpoint finds all sites on the Sharepoint Online instance when AppOnly authentication is used and the Site Discovery Strategy is set to Auto or when the Site Discovery Strategy is set to Admin API. |
<ServerURL>/_api/search/query | GET | This endpoint finds all sites on the Sharepoint Online instance to which the user has access if User Based Authentication is used and the Site Discovery Strategy is set to Auto or if the Site Discovery Strategy is set to Search. |
<ServerURL><SiteRelativeUrl>/_api/web/siteusers | GET | With this endpoint, all users are fetched to find out which are Site Collection Administrators. |
<ServerURL><SiteRelativeUrl>/_api/Web/getChanges | POST | With this endpoint all changes of a Site are fetched during the delta crawl. |
<ServerURL><SiteRelativeUrl>/_api/Site/getChanges | POST | With this endpoint all Group Membership changes of a Site are fetched during the Delta Update. |
<ServerURL><SiteRelativeUrl>/_api/Web/webs | GET | This endpoint is used to fetch the direct Subsites of Sites. |
<ServerURL><SiteRelativeUrl>/_api/Web/RegionalSettings/TimeZone | GET | This endpoint is used to fetch the set time zone of the Site. |
<ServerURL><SiteRelativeUrl>/_api/Web | GET | This endpoint is used to fetch the metadata of a Site. |
<ServerURL><SiteRelativeUrl>/_api/web/lists | GET | With this endpoint all lists of a Site and some additional metadata are fetched, among others also the "RoleAssignments" field, for which "Enumerate Permissions" permissions are needed. |
<ServerURL><SiteRelativeUrl>/_api/web/lists(guid’<ListId>’) | GET | This endpoint is used to fetch a single list. |
<ServerURL><SiteRelativeUrl>/_api/web/lists(guid’<ListId>’)/Items | GET | With this endpoint all items of a list and some additional metadata are fetched, among others also the "RoleAssignments" field, for which "Enumerate Permissions" permissions rights. |
<ServerURL><SiteRelativeUrl>/_api/web/lists(guid’<ListId>’)/Items(<ItemId>) | GET | This endpoint is used to fetch a single item. |
<ServerURL><SiteRelativeUrl>/_api/web/GetFileByServerRelativeUrl(‘<FileRelativeUrl’) <ServerURL><SiteRelativeUrl>/_api/web/GetFileById (‘<FileId>’) <ServerURL><SiteRelativeUrl>/_api/web/GetFileById (‘<FileId>’)/ListItemAllFields <ServerURL><SiteRelativeUrl>/_api/web/GetFileById (‘<FileId>’)/ListItemAllFields/Versions(<VersionId>) | GET | These endpoints are used to fetch the metadata of a file. |
<Direct link to a file>/$value | GET | This endpoint is used to download the contents of a file. |
<ServerURL><SiteRelativeUrl>/_api/Site | GET | This endpoint is used to fetch the Site Collection metadata. |
<ServerURL><SiteRelativeUrl>/_api/Web/GetUserById(<Id>) | GET | This endpoint is used to fetch a user's metadata. |
<ServerURL><SiteRelativeUrl>/_api/web/sitegroups <ServerURL><SiteRelativeUrl>/_api/web/sitegroups(<GroupId>)/users | GET | With this endpoint all groups of a site and all users in these groups are fetched. Enumerate Permissions" permissions are required for this endpoint. |
Authentication Variants
There are two categories of possible authentication methods for the SharePoint Online Crawler to authenticate and crawl a SharePoint Online instance:
- “User Based”: This logs the crawler into the SharePoint Online Server as a user, and relies on that users’ permissions to crawl each site and file.
- “Application Authentication”: This uses the granted app permissions from a generated SharePoint App. The app client ID and certificate are used to grant the crawler access to the SharePoint server. This approach is more universal and requires less fine tuning.
Application Authentication
Application Authentication is the recommended approach for SharePoint Online authentication, as it is quick to set up, requires no fine tuning with permissions or settings, and supports Delta Crawling/Update.
If full functionality of the crawler is required, i.e.:
- Indexing files and lists
- Getting ACL information about these items
- Building the cache
the crawler needs to be given Full Control permissions. The full control permissions need to be granted on both the site collection level and the tenant level.
If ACLs are not required (for example, only crawling public sites), it would be possible to perform crawling with write permissions (if site discovery is required) or read permissions (if site discovery is not required).
User Based Authentication
There are currently two available user-based authentication methods available, NTLM and ADFS. There is effectively no difference in configuration and permission settings between these two methods.
The SharePoint Online Crawler will automatically determine whether the configured crawling user is from an ADFS system or if it is an NTLM User. The Crawler will then automatically login either via ADFS or directly on SharePoint Online (if NTLM)
For both of these authentication methods, credentials need to be added to the Network tab, with an endpoint pointing towards the SharePoint Online instance.
If full functionality of the crawler is required, i.e.:
- Indexing files and lists
- Getting ACL information about these items
- Building the cache
the user needs to have at least the “Enumerate Permissions” and “Use Remote Interfaces” permissions on every site, list, and item which should be crawled. Unless inheritance is broken somewhere within the SharePoint hierarchy, simply assigning the user those permissions on every site should be sufficient. If inheritance is broken somewhere within the file/folder/sub-site hierarchy of the SharePoint online server, then special care needs to be taken when indexing these specific areas. The user needs to be given specific permissions for each of these inheritance exceptions. If this is not done correctly, some items might not be indexed or the crawl could abort.
Delta Update (Cache) is not supported with user-based authentication.
User Based Authentication Trouble Shooting Guide
Since User Based Authentication uses the permissions of the user, authorization problems can occur at some points during crawling if the user does not have the necessary permissions. This section should help you to find and fix possible causes for problems (e.g. 403 Forbidden Responses during crawling) that may occur although the user has already been given permissions to all pages to be crawled.
The user has insufficient permissions
At least "Enumerate Permissions" permissions are required for the calls used in the crawler and principal cache. Unfortunately, these are not specified in any default Permission Level (Read, Write, Manage, Full Control are the Default Levels - Enumerate Permissions is only included in Full Control), so it would be best to specify a separate Permission Level and give it to the user on each page to be crawled.
This can be done by clicking on "Permission Levels" on the Permissions page of the site () and then creating a new Permission Level with "Enumerate Permissions" and "Use Remote Interfaces" (if Enumerate Permissions is selected, all inherent permissions will be selected):


Lists/items on the page break the inheritance
By default, all objects in SharePoint Online (i.e. all pages, lists, items, files etc.) inherit the permission settings of their parent. However, this inheritance can be broken, so that permission changes of the parent do not affect the child object. In this case, the user must be given separate permissions for these objects.
If there are objects that break the inheritance, you will get a warning on the Permission Settings page ():

A Hidden List Breaks the Inheritance
Hidden Lists are usually lists that are not used by users, but by SharePoint Online itself for various things. These lists usually do not need to be indexed, because they do not contain any data that is interesting for users. The crawling of these lists can be activated and deactivated with the option "Crawl Hidden Lists".
However, if you want to crawl these lists, you have to make sure that none of these lists break the inheritance, or if they do, you have to give the user permission to crawl these lists. Since these lists are not displayed in the GUI, SharePoint Online will not warn you if the inheritance is broken. In this case, the SharePoint API must be used to check whether these lists break the inheritance.
Additional log files
ListItemCount.csv
In the ListItemCount.csv logfile, the number of items in all lists of the indexed sites are listed during a full crawl run.
- The file contains only lists of sites that are indexed.
- The file contains all lists of indexed sites, regardless of configured include/exclude patterns.
- The item count is taken directly from the SharePoint Online API and is not dependent on configured include/exclude patterns.
The file contains the Site Relative URL, List Id, List Name, List URL and number of items in the list.
documents-excluded.csv
In the documents-excluded.csv log file, all documents that were excluded by the configuration settings are listed.
Each entry in the file contains:
- The site
- The ListId
- If relevant, the ItemId and AttachmentId
- If available, the name of the document
- The reason why the item was excluded
Invalid Document Remover JMX Bean
If you suspect that documents that have already been deleted in SharePoint Online are still in the Mindbreeze index, you can use the Invalid Document Remover JMX Bean. With this you can check all SharePoint Online documents in the index and delete them if necessary.
JMX Terminal tool
The "JMX Terminal" tool allows you to query and execute JMX beans. The tool can be found under /opt/mindbreeze/tools/jmxterm-uber.jar or under C:\Program Files\Mindbreeze\Enterprise Search\Server\Tools\jmxterm-uber.jar. The tool contains an interactive shell with integrated help.
To start the tool, the following must be executed:
cd /opt/mindbreeze/tools/
java -jar jmxterm-uber.jar
The interactive shell then starts.
Note: under Windows, it must be ensured that the Java JDK is used.
Using the Invalid Document Remover
To start the Invalid Document Remover, you first need the process ID of the Microsoft SharePoint Online Crawler. This can be found in the current log directory of the crawler as a .pid file.
You can connect to the bean using the following commands:
# starting the tool
cd /opt/mindbreeze/tools/
java -jar jmxterm-uber.jar
#Welcome to JMX terminal. Type "help" for available commands.
$>open <PID>
#Connection to <PID> is opened
$>bean com.mindbreeze.enterprisesearch.connectors.sharepointonline.beans:type=InvalidDocumentRemoverMBean
#bean is set to com.mindbreeze.enterprisesearch.connectors.sharepointonline.beans:type=InvalidDocumentRemoverMBean
Now you can execute the following commands using the run command:
- start: Starts the Invalid Document Remover process.
- cancel: Stops the current Invalid Document Remover process.
- status: Provides status information about the Invalid Document Remover.
If you execute run start, the Invalid Document Remover is started. This checks all SharePoint Online documents in the index in the background and removes documents that no longer exist in SharePoint Online. The process runs until all documents have been processed or it has been stopped with cancel. When the crawler is restarted, the Invalid Document Remover continues where it left off.
You can use the status command to track the progress and find out whether the process was successful or failed.
The result of the process can be found in the log directory of the crawler in the invalid-document-remover.csv file.
Deprecated configurations
Application Registration and Granting Permissions in SharePoint Online
In SharePoint Online:
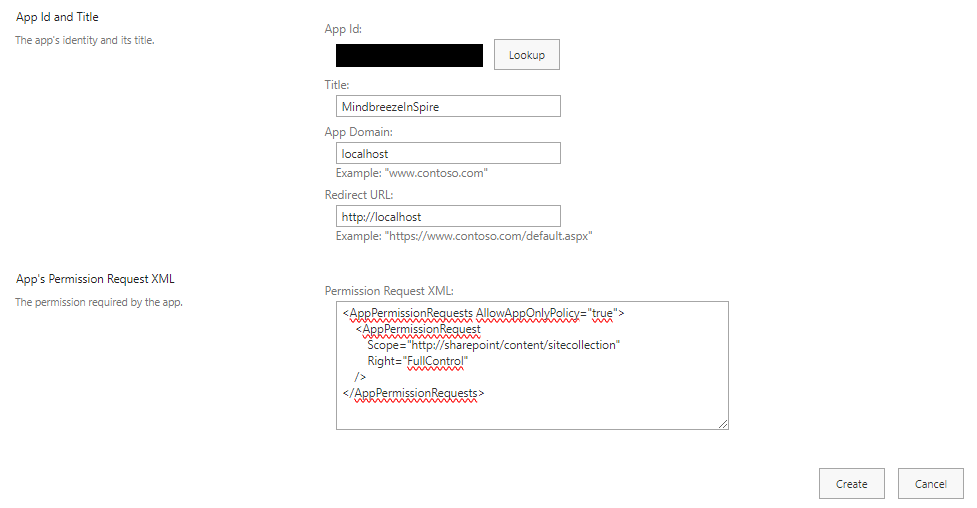
To generate a client ID and a client secret, enter the following URL in the browser:
<Server URL>/_layouts/15/appregnew.aspx
(e.g. https://myorganization.sharepoint.com/_layouts/15/appregnew.aspx)
Click the two buttons "Generate" (for "client Id" and for "client secret") and enter the other information as follows:
- "Title": user-definable
- "App Domain": "localhost"
- “Redirect URI”: https://localhost/
Then click “Create."

Then enter the Client ID and the Client Secret into the Mindbreeze InSpire configuration. Otherwise you will not be able to access the client secret later.
To do this, create a new credential of the type “OAuth 2” in the “Network” tab. You only need to enter the Client ID and Client Secret in this credential.
Then enter the Client ID and the Client Secret into the Mindbreeze InSpire configuration.
Attention: Make a note of the client secret immediately after it has been created, as it can no longer be viewed once you have left the page. You must copy the value in the column “Value” of the created secret so that you can enter it directly into the Mindbreeze configuration. You can add the secret in the “Network” tab under the section “Credentials” by clicking on “Add Credential.”
To do this, create a new credential of the type “OAuth 2” in the “Network” tab. You only need to enter the Client ID and Client Secret in this credential.
You can use this App ID and Secret in step 2 to authorize the app for SharePoint Online.
Granting permissions in SharePoint Online:
There are two ways to assign permissions for the app in SharePoint Online. It is recommended to assign tenant permissions for the app, because this way the app simply gets the permissions for all necessary content and can find and index it without any problems.
Alternatively, you can assign permissions for each page to be indexed individually. This way you can limit the permissions for the app to the minimum, but if you wanted to index a lot or dynamic content, this variant might need a lot of maintenance work.
Preparation: Enabling Custom App Authentication for New Instances
If you have a relatively new SharePoint Online instance (as of around January 2022), it could be that Custom App Authentication is disabled by default. In this case, you will need to run the following commands in your Powershell as described in this Microsoft forum:
Install-Module -Name Microsoft.Online.SharePoint.PowerShell
$adminUPN="<the full email address of a SharePoint administrator account, example: jdoe@contosotoycompany.onmicrosoft.com>"
$orgName="<name of your Office 365 organization, example: contosotoycompany>"
$userCredential = Get-Credential -UserName $adminUPN -Message "Type the password."
Connect-SPOService -Url https://$orgName-admin.sharepoint.com -Credential $userCredential
set-spotenant -DisableCustomAppAuthentication $false
Granting Tenant Permissions in SharePoint Online
Enter the following URL in the browser:
<Admin Site URL>/_layouts/15/appinv.aspx
(e.g. https://myorganization-admin.sharepoint.com/_layouts/15/appinv.aspx)
ATTENTION: Make sure that you are on the admin page. For example, if the URL is https://myorganization.sharepoint.com, then the admin page is usually https://myorganization-admin.sharepoint.com.

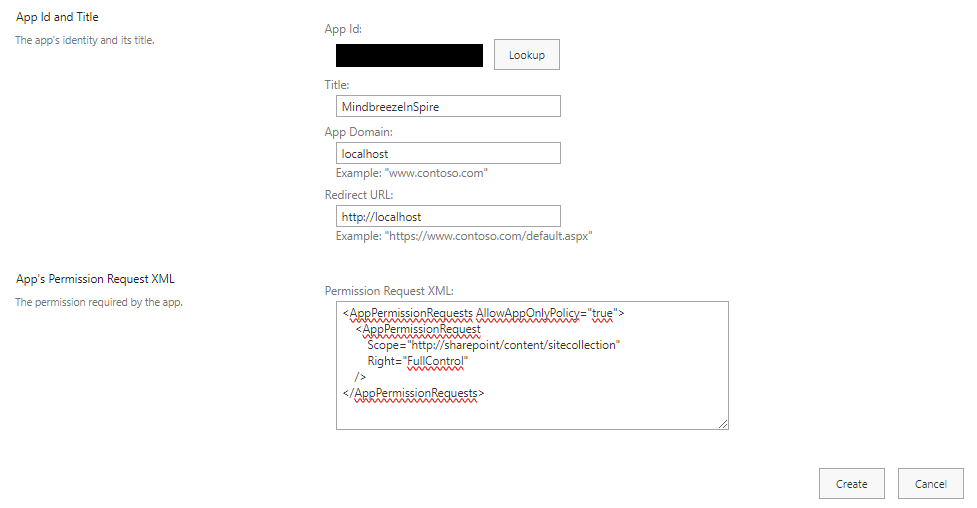
Enter the Client Id in the "App Id" field and activate the "Lookup" button. "Title", "App Domain" and "Redirect URL" will be filled in automatically. Then enter the following in the "Permission Request XML" field:
<AppPermissionRequests AllowAppOnlyPolicy="true">
<AppPermissionRequest
Scope="http://sharepoint/content/tenant"
Right="FullControl" />
</AppPermissionRequests>
Note: "FullControl" is required so that Mindbreeze InSpire has access to the access rights of the SharePoint documents to be indexed in order to map the authorizations in Mindbreeze InSpire.
Then click "Create".
Alternative: Assigning permissions per Site
You have to repeat the following steps for each Site to be indexed.
In the browser, enter the URL:
<Server URL>/<Site Relative URL>/_layouts/15/appinv.aspx
(e.g. https://myorganization.sharepoint.com/_layouts/15/appinv.aspx)

Enter the client id in the “App Id” field and click “Lookup.” “Title,” “App Domain,” and “Redirect URL” will be filled in automatically. Then enter the following in the “Permission Request XML” field:
<AppPermissionRequests AllowAppOnlyPolicy="true">
<AppPermissionRequest
Scope="http://sharepoint/content/sitecollection"
Right="FullControl"
/>
</AppPermissionRequests>
Note: "FullControl" is required so that Mindbreeze InSpire has access to the access rights of the SharePoint documents to be indexed in order to map the authorizations in Mindbreeze InSpire.
Then click “Create."
Configuration of the principal resolution service - Section “Graph API”
The following configuration options are deprecated. Please use the Microsoft Azure Principal Resolution Service instead. This makes cache updates faster and the cache is smaller.
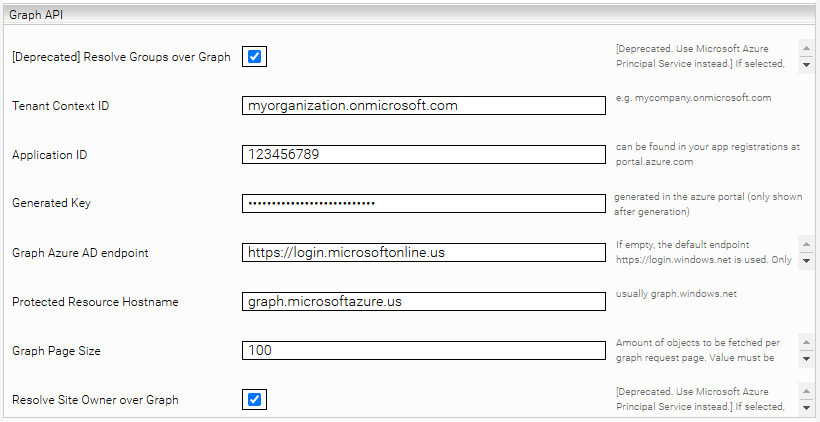
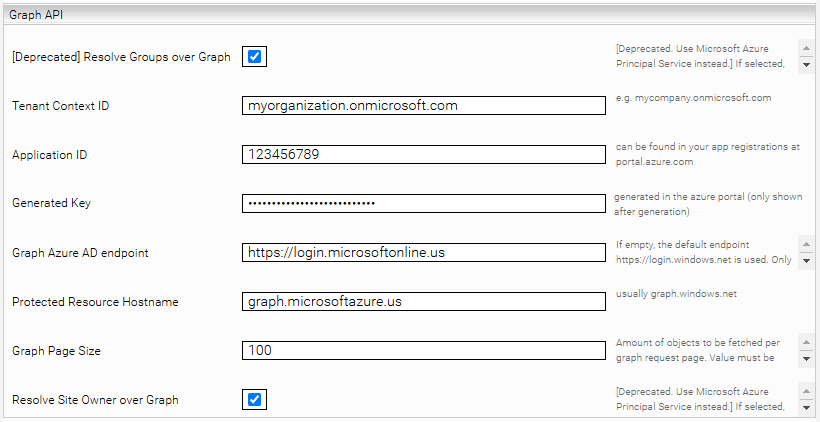
If you have not set up the "AD Connect" function in Azure Active Directory, or crawl SharePoint sites created via Microsoft Teams, select " Resolve Groups over Graph" and fill in the fields "Tenant Context ID", "Application ID", "Generated Key" and "Protected Resource Hostname". The corresponding values can be found in the Azure Portal.
The Graph Page Size defines the maximum number of objects received per request to the Graph API. Unlike SharePoint Online, paging in Graph cannot be disabled, so this value must always be set between 1 and 999.
The option "Resolve Site Owner over Graph" is necessary if "Grant Site Owner" is enabled in the crawler and the Site Owners are Graph groups (as is usually the case in SharePoint Online). Then this group is resolved for all pages.
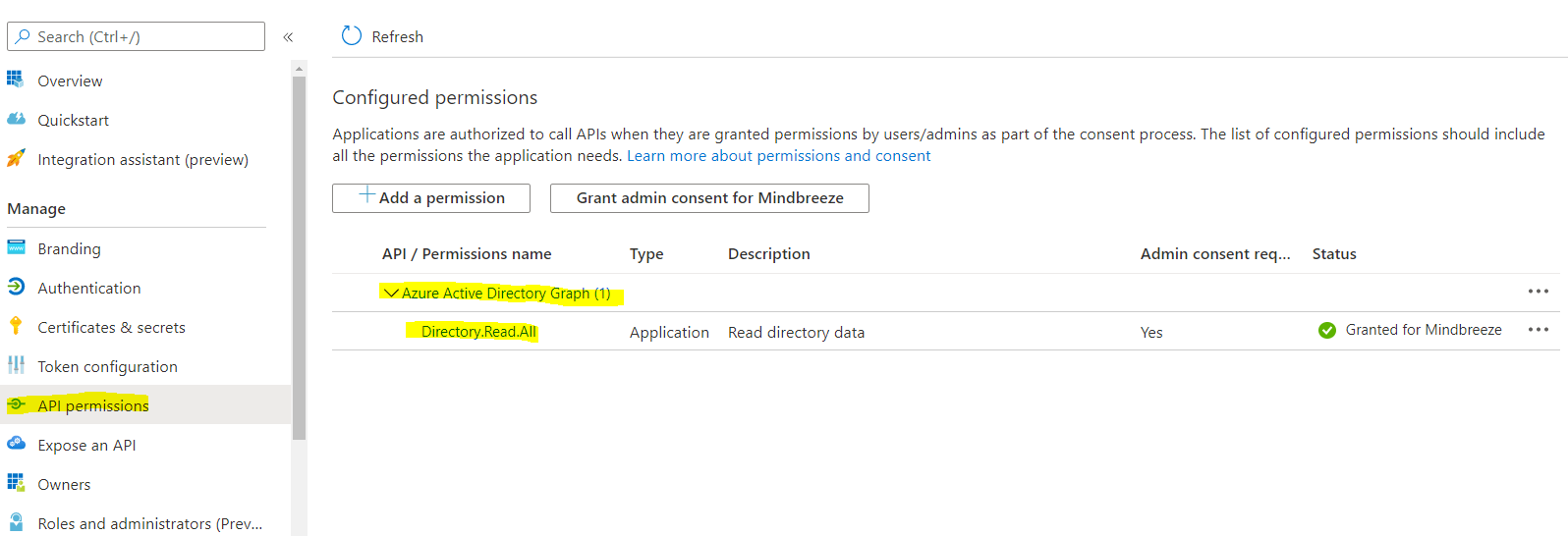
The creation of a new app was already shown in step 1 of the chapter "App-Only Authentication". Just repeat this step (steps 2 and 3 are not necessary).
In the section "API permissions" you must then give the application the necessary permissions. Required here are "Directory.Read.All" permissions for "Azure Active Directory Graph":

If AD Connect is set up in your Azure Active Directory, do not enable the “AD Connect is NOT configured” option.
If you are using a National Cloud, you must also fill in "Graph Azure AD endpoint" and "Protected Resource Hostname".
In the following table you can find the "Graph Azure AD endpoints".
Endpoint | URL |
China | |
US Government |
You can find a complete list of Azure AD endpoints here:
https://learn.microsoft.com/en-us/azure/active-directory/develop/authentication-national-cloud#azure-ad-authentication-endpoints.
The following table lists the „Protected Resource Hostnames“ for different cloud environments:
Cloud Environment | Hostname |
Globaler Service | graph.microsoft.com |
China | graph.chinacloudapi.cn |
US Government L4 | graph.microsoftazure.us |
US Government L5 (DOD) | graph.microsoftazure.us |
Deutschland | graph.cloudapi.de |
You can find a complete list of „Protected Resource Hostnames“ here:
https://learn.microsoft.com/de-de/graph/migrate-azure-ad-graph-request-differences#basic-requests (Column „Azure AD Graph“)
Configuration of the Microsoft AAD Graph Principal Resolution Service
The Microsoft AAD Graph Principal Resolution Service has been deprecated. The API used for this service will soon be discontinued by Microsoft (see here). Use the Microsoft Azure Principal Resolution Service instead. (For completeness, the following sections describe the configuration of the deprecated Microsoft AAD Graph Principal Resolution Service).
When the SharePoint Online groups are resolved in the SharePoint Online Principal Resolution Cache, it can happen that these groups contain Office 365 groups. In this case these groups must be resolved via the Graph API and the Microsoft AAD Graph Principal Resolution Service is required. If you are not sure whether your SharePoint Online groups contain Office 365 groups, because this is often not easily visible through the SharePoint Online UI, you should set up the Microsoft AAD Graph Principal Resolution Service for safety reasons and configure it as a Parent Service for the SharePoint Online Principal Resolution Service.
Setting up the App for Azure AD
The creation of a new app was already shown in step 1 of the chapter "App-Only Authentication". Just repeat this step (steps 2 and 3 are not necessary).
In the area "API permissions" you have to give the application the necessary permissions. Required here are "Directory.Read.All" permissions for "Azure Active Directory Graph":
Setting up the service
Add a new service in the "Services" section by clicking on "Add Service". Select "MicrosoftGraphPrincipalCache" and assign a display name.

Section „Graph Settings“
Setting | Description |
Tenant Context ID | The tenant name of the Microsoft instance, e.g. myorganization.onmicrosoft.com |
Application ID | The application ID of the app created in the Azure Portal |
Generated Key | The secret of the app created in the Azure Portal |
Protected Resource Hostname | If you are not using a specific national cloud deployment, the Protected Resource Hostname is graph.windows.net If you are using a national cloud deployment, please refer to the table below for the resource host name. |
Graph Page Size | The number of graph groups fetched per request to the Graph API |
Log All HTTP Requests | If set, all HTTP requests sent from the cache during the update are written to a .csv file (sp-request log.csv). |
User Agent | The specified value is sent in the User-Agent header with the HTTP request |
Heap Dump On Out Of Memory | If this option is activated, the Principal Service will make a heap dump if it runs Out Of Memory |
The following table shows the "Protected Resource Hostnames" for different cloud environments:
Cloud Environment | Hostname |
Globaler Service | graph.microsoft.com |
Germany | graph.microsoft.de |
China | microsoftgraph.chinacloudapi.cn |
US Government | graph.azure.us |
A complete list of "Protected Resource Hostnames" can also be found at: https://developer.microsoft.com/en-us/graph/docs/concepts/deployments
The LDAP, Cache, Health Check, Service and Consumer Services Settings are equivalent to the SharePoint Online Principal Resolution Service.