
Sure, you can handle it. But should you?
Let our experts manage the tech maintenance while you focus on your business.
Let our experts manage the tech maintenance while you focus on your business.
Atlassian Jira Connector
Installation and Configuration
Installation
Before you install the Atlassian Jira connector, you must ensure that the Mindbreeze server is installed and that the Atlassian Jira connector is included in the license. Use the Mindbreeze Management Center to install or update the connector.
Configuring the Index and Crawler
Navigate to the tab "Indices" and click on "+ Add Index" in the upper right corner to create a new index.

Add a new data source by clicking on "Add Data Source" in the upper right corner. Select the category "Atlassian Jira".
Configure the following required settings:
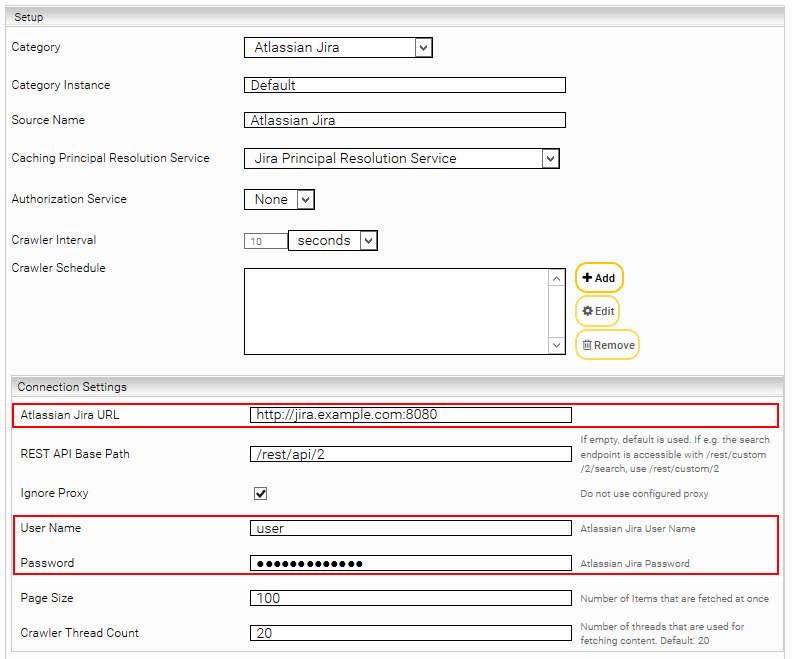
“User Name” | User name of a Jira user who has read access to the REST API. ATTENTION: This user should have the same time zone preference set as the time zone of the Jira server. If "Disable ACLs" is set, the fields "User Name" and "Password" can be left empty. See below for more information on "Disable ACLs". |
“Password” | Password of the user If you want to index a Jira Cloud instance, the API token must be set here instead. You can find out how to create this in the next section. |
“Atlassian Jira URL” | URL of the Jira REST-API |
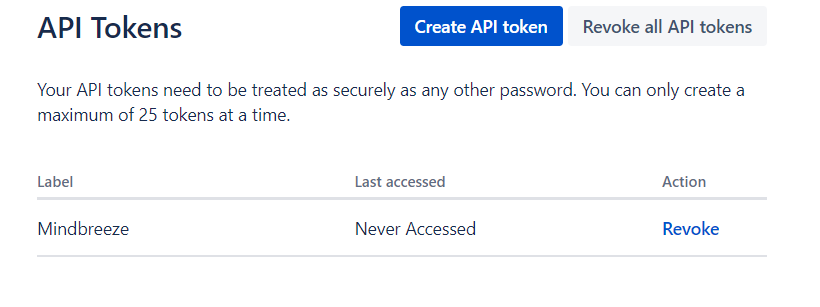
To create an API token, go to https://id.atlassian.com/manage-profile/security/api-tokens and log in with the Jira user that will be used for crawling. Then click on "Create API token" to create, name, and then copy the token.
The following settings are optional:
“REST API Base Path” (Advanced Setting) | Normally, the REST API is located at “<Atlassian Jira URL>/rest/api/2”, but if the path to your API is other than "rest/api/2", you can specify it here |
“Is Cloud” | Enable this setting when indexing a Jira Cloud instance. |
“Ignore Proxy” | Ignores the proxy settings of the „Network“ tab |
“Page Size” (Advanced Setting) | Number of Elements that a requested at the same time. Default value: 100 (Note: higher values can increase throughput, but also increase memory consumption) |
“Crawler Thread Count” (Advanced Setting) | Number of threads used to download content. Default: 20 |
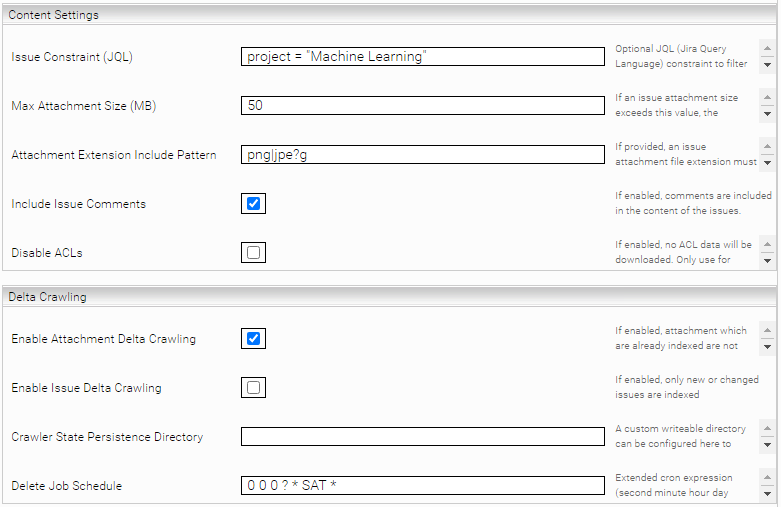
„Issue Constraint (JQL)“ | A JQL (Jira Query Language) Query that restricts the issues to be crawled. E.g.: project = "Machine Learning". You can use the "Advanced Search" in the Jira interface to create a suitable JQL query. You can also find the official Jira documentation on JQL syntax here. Note: the keywords "ORDER BY" must not be used, as this is used by the crawler itself. Changing this option requires a re-index. Default value: not set (All issues will be crawled). |
“Max Attachment Size (MB)” | If set, attachment exceeding this size limit are not indexed. (A setting of 0 disables the indexing of attachments completely) |
“Attachment Extension Include Pattern” | If set, only attachments matching this regular expression are indexed (Java Regex) for example. odt|xls|doc|docx |
“Include Issue Comments” | If active, comments on issues are set as HTML content |
“Disable ACLs“ | If set, no ACL information is indexed. Use only for public servers. Also, in the index configuration (Advanced Settings must be enabled), enable the "Unrestricted Public Access" option and disable the "Enforce ACL Evaluation" option. ATTENTION: All documents on the index are then visible to every user. |
„Ignore Issue Level Security“ | Normally, this option is not enabled and all (Jira-)Issues with "Issue Level Security" set are not accessible to anyone for security reasons If this option is enabled, all issues that have the “Issue Level Security” property will also be crawled and the relevant project permissions will be used. CAUTION: If you enable this option, users may see Issues that they are not supposed to see in Jira. |
„Issue Level Security Override“ | The project roles (one per line) that should have access to all Issues where "Issue Level Security" is set. If this option is empty, all Issues with "Issue Level Security" set are not accessible to anyone for security reasons. CAUTION: If you enable this option, users may see Issues that they are not supposed to see in Jira. |
„Custom Metadata Mapping Path” (Advanced Settings) | The path to a custom metadata mapping file. The custom metadata mapping, if configured, will be combined with the default mapping and steers which metadata will set on the documents. |
If your Jira instance contains a large amount of data, it is recommended to enable delta crawling:
"Enable Attachment Delta Crawling" | If active, only attachments that have not yet been indexed are downloaded |
"Enable Issue Delta Crawling" | If active, only new or changed issues are downloaded. Issues that have been deleted in Jira are not deleted during a delta crawl run. In order to remove deleted issues from the index, you must configure a "Delete Job Schedule" (see description below). |
"Crawler State Persistence Directory" | If "Enable Issue Delta Crawling" is active, a directory is required to store status information about the last delta crawl run (or delete crawl run). If no directory is specified, this status information is stored in "/data/servicedata/<service-id>" by default. |
"Delete Job Schedule" | If "Enable Issue Delta Crawling" is active, it is recommended to specify an extended cron expression here (documentation and examples of cron expressions can be found here). If the cron job is triggered, a delete crawl run will be started immediately after the next delta crawl run to delete issues and attachments that are no longer present in Jira. Please note that a delete crawl run can take a long time when dealing with large amounts of data. |
Then save the configuration and restart.
Configuration of the Principal Resolution Service
In the new or existing service, select the Atlassian Jira Caching Principal Resolution Service option in the Service setting. For more information about additional configuration options and how to create a cache and how to do the basic configuration of a cache for a Principal Resolution Service, see Installation & Configuration - Caching Principal Resolution Service.
Configure the following required settings:
“User Name” | User name of a Jira user who has read access to the REST API. |
“Password” | Password of the user |
“Atlassian Jira URL” | URL of the Jira REST-API |
The following settings are optional:
"REST API Base Path" (Advanced Setting) | Normally, the REST API is located at “<Atlassian Jira URL>/rest/api/2”, but if the path to your API is other than "rest/api/2", you can specify it here | ||||||
“Is Cloud” | Enable this setting when indexing a Jira Cloud instance. | ||||||
“Ignore Proxy” | Ignores the proxy settings of the „Network“ tab | ||||||
“Page Size” (Advanced Setting) | Number of Elements that a requested at the same time. Default value: 100 (Note: higher values can increase throughput, but also increase memory consumption) | ||||||
“Maximum Request Threads” | The maximum number of threads used to make Jira API requests. A higher value can shorten the cache update duration, but results in a higher load on the Jira server. | ||||||
„CSV Access Logging Mode“ | HTTP requests to the Jira API are logged in access-log.csv in the log directory. This option can be used to control how detailed they are logged. The following selections are available:
|

Metadata indexed by default
By default, the following Jira fields are downloaded per issue and converted to metadata:
Jira Field Name | Notes |
Summary | The title (“Summary”) of the Jira Issue. Will be used as the title of the Mindbreeze document. |
Created Updated | The Jira fields “Created” and “Updated”. Will be used as the creation and modification date for the indexed Mindbreeze document. |
Description Comments | These Jira fields are used for the content of the document. The comments will only be indexed, if activated via crawler configuration. |
Type | - |
Priority | - |
Labels | - |
Component(s) | - |
Status | - |
Creator Reporter Assignee | - - - |
Fix Version(s) Affects Version(s) | - |
Project | - |
Attachments | Will be indexed as its own document type. |
If additional Jira fields should be indexed, downloaded or eventually converted to metadata, follow the instructions in Configuration - Jira Connector.
Indexing of custom metadata
Overview
JIRA allows its users to create custom fields, display them in the UI and assign values to these fields, either when creating or editing issues.
In some cases, you may want the values of these fields as metadata on your indexed issues in Mindbreeze InSpire. This is possible via the following steps:
- Find out the unique identifier of the custom fields in JIRA (see the chapter Locating the Field ID of custom JIRA fields).
- Create a YAML file for custom metadata mapping
- In most cases here you only need to specify the unique identifier (Field ID) in the section “indexedFields”. For more information on the format of the metadata mapping and the section “indexedFields”, see the chapter Custom Metadata Mapping.
- The result of this step should be a YAML file like customMetadataMapping.yaml .
- Upload the custom mapping to Mindbreeze InSpire.
- This can be done in the Mindbreeze InSpire Management Center in the menu item "File Manager". For example at /data/resources/mapping (this folder does not exist per default):

- Configure the JIRA Crawler
- Create a JIRA crawler and adapt the configuration to your needs. For more information about the configuration of the index and crawler, see the chapter Configuring the Index and crawler.
- Additionally, in the configuration set the advanced setting "Custom Metadata Mapping Path" to, for example, /data/resources/mapping/customMetadataMapping.yaml.
Attention: Specifying a custom metadata mapping does NOT override the default mapping. Rather, it extends the default mapping.
Locating the Field ID of custom JIRA fields
There are two approaches to locate the Field ID of a custom JIRA field. Either via the JIRA GUI or via the Mindbreeze crawler logs.
JIRA GUI
First, open the Jira administration page and click the menu item “Issues”.
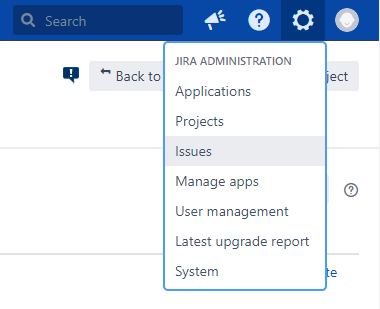
On the left side, click the menu item “Custom Fields”.
Afterwards, go to the desired field and click on "Configure".

You will find the Field ID in the URL of the website.
![]()
The complete Field ID for this field is “customfield_10601“.
Mindbreeze Crawler Logs
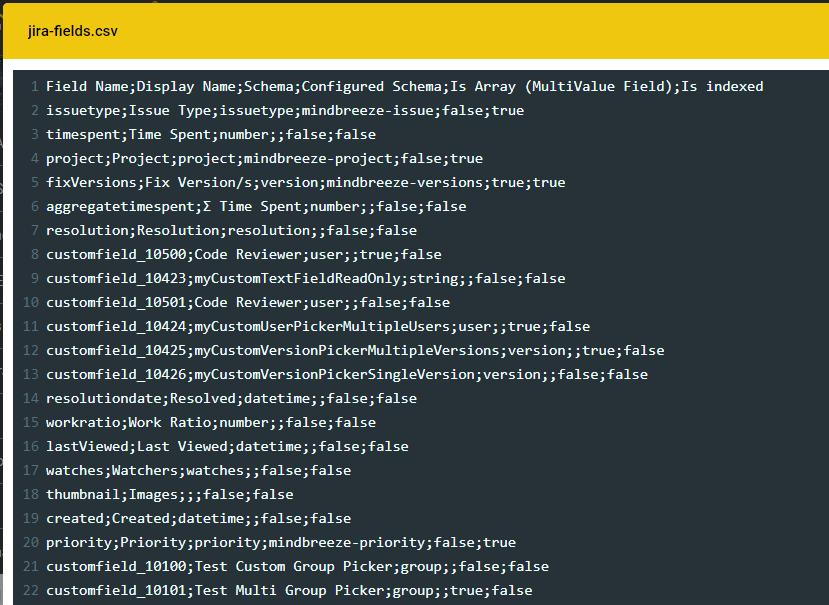
The Field ID can also be located in the Mindbreeze crawler log directory. There the file jira-fields.csv can be found, which gives an overview over all JIRA fields.
The following information can be found there:
- Field ID
- Display name (in JIRA)
- Schema (according to JIRA)
- Configured schema (according to the default and the custom metadata mapping)
- Single-value or multi-value field
- Is the field currently configured to be indexed (metadata is going to be extracted) or not?
Custom Metadata Mapping
Overview
The metadata mapping is defined in the YAML format and consists of 2 main sections – the schemas and the indexedFields.
The metadata mapping describes which fields should be indexed ("indexedFields" section) and how this metadata should be created ("schemas" section).
Since all of the JIRA field types (JIRA schemas) are already predefined in the default metadata mapping and the needed schema for a JIRA field can be automatically detected, in most use cases, it is sufficient to only specify the indexed field, as shown in the chapter Automatic Schema Detection. This has to be done in the indexedFields section. See the chapter Complete Example for a finished mapping.yaml.
IndexedFields
An indexed field specifies a JIRA field from which metadata should be generated and which schema should be used.
An indexed field always consists of the FIeld ID and, optionally, of additional attributes.
Attention: In most cases, the specification of optional attributes is not necessary. The important attributes (schema, metadataBaseName and multiValueField) are automatically retrieved from JIRA.
Optional Attributes
string | Defines the schema to be used for processing the field. | |
metadataBaseName | string | Specifies the base name (base prefix) for the created metadata. If this attribute is set, this name will be used. Otherwise, the JIRA display name of the field will be converted to snake case and used as the base name. If, for some reason, the display name for this field cannot be retrieved and no metadataBaseName is specified, the Field ID will be used as the base name. |
customNameDelimiter | string | Defines the delimiter to use when creating hierarchical (prefixed) metadata names. Default: “_“ . |
multiValueField | boolean | Specifies whether this field is an array. This can be used when a schema that is intended for a single-value field is also used for a multi-value field. Default: False. |
ignoreField | boolean | Specifies whether this field should be ignored. This has the effect that no metadata is extracted for this field. This can be used to skip the creation of metadata for fields that are specified in the default metadata mapping. |
Examples
Automatic Schema Detection
Objective: In your JIRA setup, you have a custom multi-user picker with the Field ID “customfield_10401” and the display name “Involved People”. Metadata should be extracted from this field.
The following field mapping would do the trick:
customfield_10401: {}
With this specification, the crawler would, via the JIRA fields endpoint, automatically find out that the configured field is a multi-value field with the schema "user" and the metadata base name "involved_people". In this case the "user" schema does not have to be specified manually, as almost all of the JIRA default schemas are already defined in the default metadata mapping.
If the metadata base name "involved_people" is not desired, a different name can be specified for it via the following configuration:
customfield_10401:
metadataBaseName: 'my_custom_base_name'
Attention: The schema does not need to be specified.
Multi Value Field
Objective: You want to use a different schema for the “Involved People” field, than the default user schema. To achieve this, the schema must be specified manually. If a schema is specified manually, the attribute 'multiValueField' must be specified manually as well:
schema: 'my-custom-user-schema'
multiValueField: True
Ignore Field
Objective: Mindbreeze specifies the field “reporter” per default as indexed field. You want to avoid this, since this metadata is not needed.
To achieve this, the field must be set to ignored in the custom configuration:
reporter:
ignoreField: True
Schemas
Schemas describe how different JIRA fields (from the API in JSON format) should be handled, what properties (JSON keys) there are, and how to create a metadata from them. A schema consists of a property definition, which can have various attributes. Those attributes are described in the following chapter.
Property Definition
string | Defines a key in a JSON. In the JSON {"demo_key": "demo_value"} the property would be "demo_key". | |
name | string | Specifies the name of the current property. The defined name will be used when creating the metadata name. If no name is specified, the name (=key) of the property (see above) will be used as the name. |
searchable | boolean | Specifies whether a metadata value will be searchable or not. This attribute only takes effect if a property has no nested sub-properties. Otherwise it will be ignored. Default: True. |
multiValue | boolean | Specifies whether the current property is an array. Default: False. |
prefixName | boolean | Specifies whether the name of an extracted metadatum should be hierarchically prefixed or whether the name of the metadatum should just be the property name. Default: True. |
parsingStrategy | enum value | Specifies if and how a property should be parsed. If not specified, the value of the resulting metadata will be of the type string. This attribute only takes effect if a property has no nested sub-properties. Otherwise it will be ignored. Possible values:
|
properties | nested (array) property definitions | When dealing with a JSON object, properties define how the object should be handled and which sub-properties should be extracted. |
Examples
To make the examples easier to understand, let's look at the following custom JIRA field first. Suppose you have created a custom field called “Code Reviewer” that is a “SingleUserPicker”.

When the issue JSON is fetched by Mindbreeze, the field with its value (representing a single user) looks like this. (note that the name of the ID of this custom field is created by JIRA. Iin this example, the ID is "customfield_10413"):
"self": "http://jira.url/rest/api/2/user?username=john.doe",
"name": "john.doe",
"key": "john.doe",
"emailAddress": "john.doe@email.com",
"avatarUrls": {
"48x48": "http://jira.url/secure/useravatar?avatarId=10122",
"24x24": "http://jira.url /secure/useravatar?size=small&avatarId=10122",
"16x16": "http://jira.url/secure/useravatar?size=xsmall&avatarId=10122",
"32x32": "http://jira.url/secure/useravatar?size=medium&avatarId=10122"
},
"displayName": "John Doe",
"active": true,
"timeZone": "Europe/Vienna"
}
Example of a simple User Schema
Objective: Generate metadata for the values “displayName”, “emailAddress” and “key”. Furthermore, the names of the metadata should be slightly altered.
To do this, the schema must look like this (the default schema when a field of the type “user” is encountered):
properties:
- property: 'displayName'
name: 'name'
- property: 'emailAddress'
name: 'email'
- property: 'key'
First the schema name is defined, in this case the name is “my-user-schema“. The value of a schema is already a property definition. So all of the attributes, defined in the table, can be used here.
Since the value of customfield_10413 is on a (JSON) object, the sub-properties of this object need to be defined.
In the example shown, the desired properties are:
displayName (the name is overwritten to name)
emailAddress (the name will be overwritten with email)
key
Since none of these properties have other attributes specified (for example “prefixName“ or „parsingStrategy“) the resulting metadata will look like this:
Value Type | Value | |
code_reviewer_name | string | John Doe |
code_reviewer_email | string | john.doe@email.com |
code_reviewer_key | string | john.doe |
Example of an Extended User Schema
Objective: Generate metadata for the values “displayName”, “emailAddress” and “key”. Furthermore, the names of the metadata should be slightly altered. Additionally, create a metadatum for avatar URL in the size 48 x 48 Pixel and make it non-searchable. So it cannot be found when for example the number “10122” is being searched.
The following schema accomplishes this:
properties:
- property: 'displayName'
name: 'name'
- property: 'emailAddress'
name: 'email'
- property: 'key'
- property: 'avatarUrls'
properties:
- property: '48x48'
searchable: False
Since the avatarUrls in the JSON also has an object as value, the sub-properties of that object need to be defined via the properties attribute.
The resulting metadata will look like this:
Value Type | Value | |
code_reviewer_name | string | John Doe |
code_reviewer_email | string | john.doe@email.com |
code_reviewer_key | string | john.doe |
code_reviewer_avatarUrls_48x48 | string | http://jira.url/secure/useravatar?avatarId=10122 |
If the name should be code_reviewer_avatar_url rather than code_reviewer_avatarUrls_48x48, the property can be specified like this:
name: ''# when creating the hierarchical name, empty names are skipped
properties:
- property: '48x48'
name: 'avatar_url'
searchable: False
Another way to achieve this is to use the following method:
properties:
- property: '48x48'
name: 'code_reviewer_avatar_url'
prefixName: False # defines that this name should not be prefixed
searchable: False
Attention: This method is not recommended, since this schema only makes sense in combination with the code reviewer field and not with for example “SingleUserPickers”. Additionally, it is easier to create name conflicts with this method.
Complete Example
Objectives:
Add avatar URL for all Mindbreeze default indexed user metadata.
Add custom schema which does not convert a date field to a calendar, adds the value as directly as string and use it for a custom date picker.
Add the JIRA affected versions as new metadatum.
Ignore the metadatum (field) “reporter”.
Add avatar URL for users
To accomplish that, the schema “mindbreeze-user” must be overridden. This schema is the default schema for the fields “reporter”, “assignee” and “creator”.
First a copy of the default schema should be created, to not lose any already existing metadata. Then add the property "avatarUrls" with its sub-property "48x48" to the schema to get the URL for the largest avatar URL available. If desired, the names can be adjusted as well.
The schema should look like this:
properties:
- property: 'displayName'
name: 'name'
- property: 'key'
- property: 'emailAddress'
name: 'email'
- property: 'avatarUrls'
name: ''
properties:
- property: '48x48'
name: '_avatar_url'
New schema for human readable date
The default schema for fields with the type "date" looks like this:
parsingStrategy: TO_CALENDAR
The goal here is to avoid the parsing step. This can easily be done by not specifying a parsing strategy. The new schema should look like this:
string_date: {}
The schema can now be used for date fields (e.g., custom date picker fields):
customfield_10401: # example custom date picker field
schema: 'string_date'
Ignore the field "reporter"
Like shown in a previous example, this can be accomplished with a simple field specification:
ignoreField: True
Add field "Affects Version/s”
The Field ID for this field is "versions", since the default schema, defined by JIRA, as well as the display name are sufficient. Just specify the field "versions" in the indexedFields:
Since the JIRA names (display names as shown in the JIRA UI) are converted to snake case when used as metadata names, the final metadata would be prefixed with "affects_versions" (special characters like in this case “/” are removed as well).
Final Mapping
When everything is brought together, the final custom metadata mapping should look like this:
schemas:
string_date: {}
mindbreeze-user:
properties:
- property: 'displayName'
name: 'name'
- property: 'key'
- property: 'emailAddress'
name: 'email'
- property: 'avatarUrls'
name: ''
properties:
- property: '16x16'
name: '_avatar_url'
indexedFields:
versions: {}
customfield_10401:
schema: 'string_date'
reporter:
ignoreField: True
View effects of a custom mapping configuration
The crawler logs show an overview over the effects of the custom mapping configuration at the start:
Found custom metadata mapping at: '/data/resources/mapping/metadataMapping.yaml'. This will have the following effects:
- Schemas:
- Newly added:
- string_date
- Overridden:
- mindbreeze-user
- Indexed Fields:
- Newly added:
- customfield_10401
- versions
- Ignored (removed):
- reporter
Appendix
Restrictions
- Jira permission schemes with "Group custom field value" in the "Browse projects" permission are not supported.
- Jira issue-level security is not supported. Jira issues with security level set cannot be found in the search if ACLs are enabled.
- For the Principal Resolution Service to resolve Project Roles or Groups for a user, the user’s email address needs to be public. You can configure this here. To do this, set the column "Who can see this?" to "Anyone" for the user's email address.
Troubleshooting
“ERROR: CrawlRun was unsuccessful” with URL Path “/search” and “status code 400”
Most likely an "Issue Constraint (JQL)" is configured, which causes the error
- Check the configured "Issue Constraint (JQL)" using the "Advanced Search" function in Jira directly. In any case, the JQL must work within Jira.
- Check that there are no forbidden keywords in the JQL, such as "ORDER BY". Remove these keywords.
- The crawler does not use the entered JQL directly, but transforms it before performing Jira API requests. The entered JQL is enclosed in brackets and further constraints and sorting are performed. The transformed JQL is then passed as a URL parameter in the Jira API requests. The effective URL is then displayed in the error message.
E.g.: https://jira.myorganization.com/ rest/api/2/search?jql=%28proect+%3D+%22Big+Data%22%29+AND+updated+%3E%3D+%272020-06-17+17%3A10%27+ORDER+BY+updated+ASC&startAt=100&maxResults=100&fields=key,updated,description...
This corresponds decoded e.g. to the effective JQL: (proect = \"Big Data\") AND updated >= '2020-06-17 17:10' ORDER BY updated ASC
If you open the effective URL from the error message in a browser, you will get a detailed error message about what exactly went wrong with the effective JQL. E.g.: "Field 'proect' does not exist or you do not have permission to view it."
Crawl run is not completed or certain issues were not indexed
If the time zone preference of the user used for crawling and the Jira server are different, various errors can occur. For example, it is possible that the crawl run is never completed or certain issues are skipped.
The former case can be detected by checking the log of the crawler. If the same URLs are called over and over again, the reason may be the user's time zone.
Therefore, you should always make sure that the user's time zone matches the server's time zone. This can be set in the user's profile.
A User is finding too little documents and calling ‘checkprinicpals’ on the Principal Resolution Service does not return Project Roles or Groups
As described in Section 4.1 Restrictions, the Principal Resolution Service can only resolve the Project Roles and Groups of users, if their Email Address is public. You can configure this here. To do this, set the column "Who can see this?" to "Anyone" for the user's email address.