
Sure, you can handle it. But should you?
Let our experts manage the tech maintenance while you focus on your business.
Let our experts manage the tech maintenance while you focus on your business.
Microsoft File Connector
Installation and Configuration
Video Tutorial „Set up a basic Microsoft File Connector”
This Video describes how to configure the Microsoft File Connector. See what preconditions are necessary and how to configure the index. Also have a look at the Active Directory Based Authentication, as well as LDAP and how to analyze crawled documents and crawl runs in app.telemetry:
https://www.youtube.com/watch?v=S2JCrM98W30
Configuration of Mindbreeze
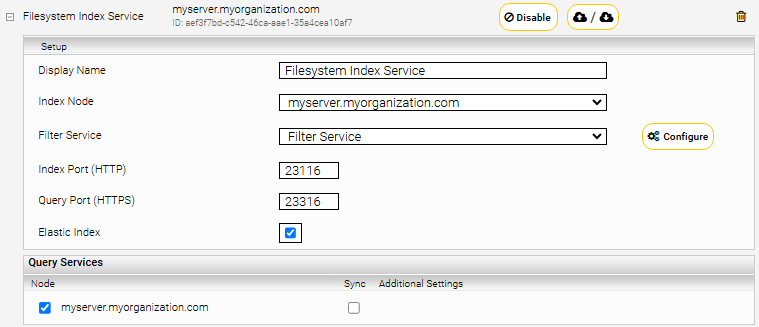
Click on the “Indices” tab and then on the “Add new index” symbol to create a new index.
Enter the index path, e.g. “/data/indices/filesystem”. Change the Display Name of the Index Service and the related Filter Service if necessary.
Add a new data source with the symbol “Add new custom source” at the bottom right.
Setting | Description |
Ignore Category Instance | When multiple file crawlers are configured on an index, the search is not restricted to specific category instances. |
Authorization Service | Currently we provide no Authorization Service for Microsoft File. |
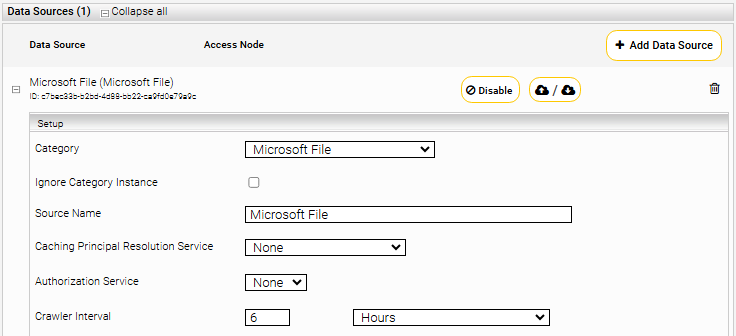
Configuration of Data Source
Caching Principal Resoution Service
To use the Caching Principal Resolution Service you have to select CachingLdapPrincipalResoution. Then it is used to resolve the AD group membership of a user in the search.
For more details click here Caching Principal Resolution Service.
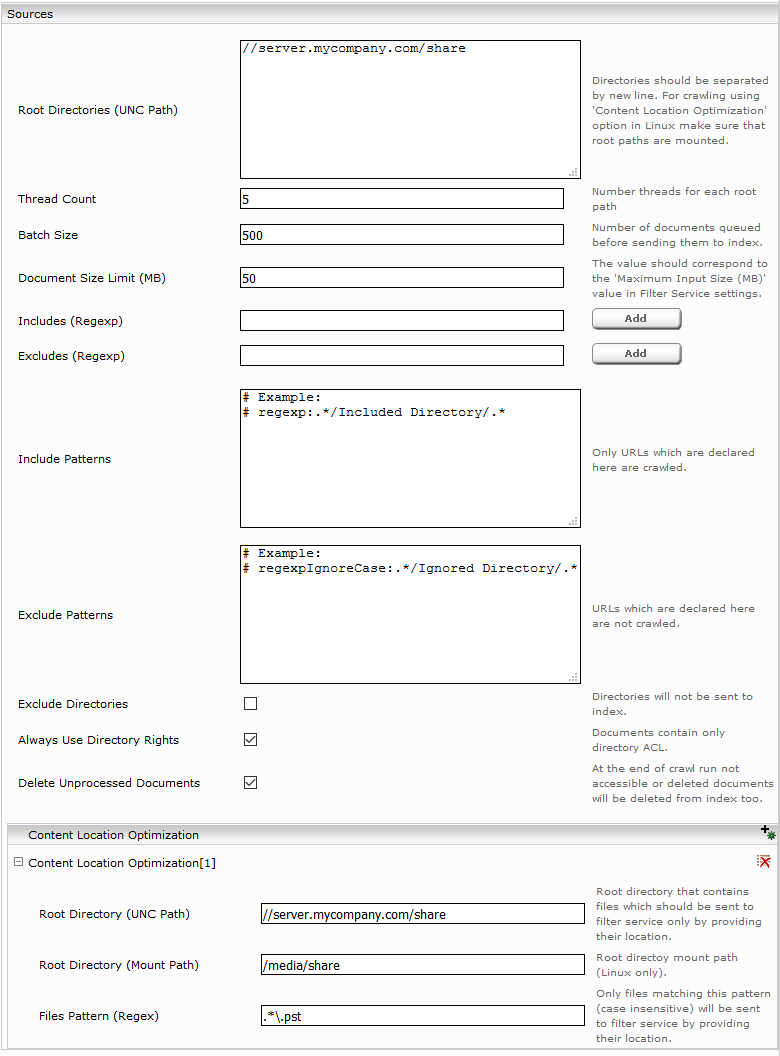
Section “Sources”
Configure the following settings in the section “Sources” in the datasource:


Setting | Description |
Root Directories (UNC Path) | In this option you can specify which directories should be crawled. Notes:
Attention: Make sure that the specified path ends with a backslash. If this is not the case, the specified path will not be recognized. |
Supports SMBv2/v3 | If disabled, only SMBv1 protocol is used. If enabled, SMBv2/v3 protocols are also used. |
Disable SMB Packet Signing | If enabled, no signature is generated for sent SMB packets and the signature is not verified for received packets. |
(Advanced Setting) | Enables data encryption. Ensure that “Maximum SMB2 Dialect” is either Auto or one of the following SMB2 dialects: 3.0.0, 3.0.2, 3.1.1. |
Disable SMB2 Multi-Protocol Negotiate | If enabled, this can result in better error messages if the server only supports SMBv1. |
Minimum SMB2 Dialect (Advanced Setting) | Supported SMB2 dialects are 2.0.2, 2.1.0, 3.0.0, 3.0.2 and 3.1.1. This value should be less than or equal to the “Maximum SMB2 Dialect”. The actual SMB2 dialect used is determined by the result of SMB2 Protocol Negotiation with the file share server. |
Maximum SMB2 Dialect (Advanced Setting) | Supported SMB2 dialects are 2.0.2, 2.1.0, 3.0.0, 3.0.2 and 3.1.1. This value should be greater than or equal to “Minimum SMB2 Dialect”. The default value is Auto. For Azure file shares, the value is set to 3.1.1. For all other file shares, it is set to 3.0.2. The effective SMB2 dialect is determined by the result of the SMB2 Protocol Negotiation with the file share server. |
SMB Client Transaction Timeout | Here you can specify the thread timeout (in seconds) for SMB connections. |
SMB Client Socket Timeout | Here you can specify the socket timeout (in seconds) for SMB connections. |
Crawl Last Modified Directory Files First | If enabled, while traversing a directory, the files and subdirectories are sorted by modification date. This causes the most recently changed files and directories to be crawled first. |
Root Traversal Threads Count | Here you can set the number of threads that traverse the directories from the "Root Directories" field in parallel. |
Documents Dispatcher Threads Count | Here you can define the number of threads that send the directories and their documents that are in the "Documents Dispatcher Queue" to the index in parallel. |
Documents Dispatcher Queue Size | Here you can specify the maximum number of directories and their documents that should be in the queue before they are removed from the queue by "Document Dispatcher Threads" and sent to Index. |
Directory Files Lister Threads Count | Here you can define the number of threads that retrieve the files, subdirectories and the ACLs of a directory from the filesystem share via SMB. The subdirectories are stored in the "Directory Files Lister Queue". The directories and their files are stored in the "Document Dispatcher Queue". |
Directory Files Lister Queue Size | Here you can specify the maximum number of directories for which no files, subdirectories and ACLs have yet been retrieved from the filesystem share to be queued. |
Document Size Limit (MB) | Here you can set the maximum document size. Documents larger than this value will be ignored. Note: If this value is changed, the "Document Size Limit (MB)" and "Filter RPC Timeout (non-streamed)" options in the Filter Service should also be adjusted. |
Maximum Crawled Content Length in MB. | If documents exceed the size (in MB) specified in this option, they will be sent to the filter with empty content. |
Includes (Regexp) | If this option is configured, only those files and directories are indexed which match the specified pattern (regular expression). Excludes have higher priority than includes (i.e. if a document is both included and excluded, it will not be indexed). |
Excludes (Regexp) | If this option is configured, those files and directories that match the specified pattern (regular expression) will be ignored. Excludes have higher priority than includes (i.e. if a document is both included and excluded, it will not be indexed). |
Include Patterns | Only those files and directories are indexed which match the specified pattern (regular expression). In contrast to the "Includes (Regexp)" field, here you have the possibility to define "case-sensitive" patterns (reqular expression) by using "regexpIgnoreCase:", "case-insensitive" and "regexp:" or to comment out the pattern with the "#" character at the beginning of the line. |
Exclude Patterns | Those files and directories are ignored which match the specified pattern (regular expression) In contrast to the "Includes (Regexp)" field, here you have the possibility to define "case-sensitive" patterns (reqular expression) by using "regexpIgnoreCase:", "case-insensitive" and "regexp:" or to comment out the pattern with the "#" character at the beginning of the line |
Exclude Directories | If enabled, directories are not indexed. |
Full Traversal Interval (Hours) | Here you can define the interval (in hours) between two full traversals of all documents in the fileshare. The default setting (-1) is sufficient for most use cases and it is a full traversal of all documents. For very large fileshares it may be useful to perform incremental traversal to speed it up. In this case, documents with filter errors in previous full traversal are ignored. Modified documents are indexed, document ACLs changes are updated and deleted documents are removed from index at the end of incremental traversal which happens at "Crawler Interval" interval until “Full Traversal Inveral (Hours)” is reached. |
Remove Deleted Documents From Index | If enabled, the documents deleted from the fileshare will be deleted from the index at the end of a full traversal. |
Remove Old Documents From Index (Number of Years) | If configured, documents whose modification date is older than a certain date are removed from the index at the end of a traversal. This date is calculated from the start date of the crawler minus the number of years configured in this field. Example: The modification date of a document is 20/09/2020 and the setting “Remove Old Documents From Index (Number Of Years)” is configured with the value “3”. Accordingly, the document is removed from the index on 21/09/2023. |
Content Location Optimization | The description of this option can be found here. |
Section „Access Rights Settings“
Configure the following settings in the section “Access Rights Settings” in the datasource:

Setting | Description |
ACL Security Level | The following options are available:
|
Permission Mapping (Advanced Settings) | The following options are available:
The crawler denies access to the file to users or groups who have “Deny” access type for one of the above-mentioned extended access permissions. The other extended access permissions are ignored by the crawler. |
Permission Mapping Validation (Advanced Settings) | If this option is configured, a log file is created to compare the selected permission mapping with the other one defined by this option.
|
Normalize ACLs (Advanced Settings) | If this checkbox is activated, all ACLs are saved in “Distinguished Name” format. If it is not activated, the ACLs remain in SID format. In this case, it is important to configure objectsid in the “User Alias Name LDAP Attribute” and “Group Alias Name LDAP Attribute” fields in the selected LDAP principal resolution service. |
Resolve Local Group Members (Advanced Settings) | Sometimes there are local groups in ACLs of the documents. In order to resolve the domain users or domain groups inside these local groups there is an access to LSA (Local Security Authority) and SAM (Service Account Manager) using the RPC-SMB protocol needed. However, this is generally not recommended and should only be disabled in exceptional cases |
LSA/SAM Desired Access (Advanced Settings) | The preferred access permission of the crawler service user to LSA and SAM: Maximum allowed, Generic all, Generic execute, Generic Read or Read Control. For crawling NetApp share Read Control may be needed as Desired LSA/SAM Access to be selected. If the access with selected permission was not successful, the other access permissions will be tried |
Resolve All Domains (Advanced Settings) | To correctly assign the file permissions (ACLs) of different domains, select the Resolve All Domains option. For this it is necessary that either the LDAP servers of these domains are configured directly under "LDAP Server" or can be resolved via DNS SRV Records from AD using LDAP. Therefore, the domains should be configured in the Network Tab under LDAP Setting. If "Resolve All Domains" is not selected, only the ACLs from the File Share Server domain will be resolved correctly |
Section „Trustee Information Settings“

Setting | Description |
Trustee Information File Path | Path to the Trustee information file which can reside in a local folder or an UNC-Path. |
Trustee Volume Path | The Volume-Path of the Root folder in the Trustee information file. Can be omitted if the Root folder is equal to the Volume-Path. |
Section „Extensions“ (Index File Lister)
These are plugins that can be provided by Mindbreeze to cover special use cases. The files are not indexed by classical "browsing" through the file trees, but a file or a database or something similar is bound, which contains a list of files to be indexed. So only the URLs files of these lists are indexed instead of "browsing" through all trees. This mechanism is similar to Sitemaps in the Web Connector.
Microsoft File Connector provides the Interface IndexFileListerPlugin (index-filelister-spi.jar) to list documents together with additional properties from an index file for crawling.
public interface IndexFileListerPlugin {
boolean isIndexFile(ReadonlyFile file);
void init(Properties properties);
Collection<Map.Entry<ReadonlyFile, TypesProtos.Item>> listIndexFile(FilesystemContext context, ReadonlyFile indexFile);
}
messdk-generated.jar and protobuf-java-3.0.0.jar from Java service API together with index-filelister-spi.jar are needed to implement the IndexFileListerPlugin. After implementing the plugin, it should be configured as follows. Provide the path of JAR file containing the implementation in the „Index File Lister Plugin“ field. The optional „Index File Lister Plugin Property“ fields define the properties needed by the plugin to be initialized with.
Index Files are queued „Queue Size“ during directory traversal, which are then handled by parallel threads „Thread Count”. The option „Skip unchanged Index File Listing during Incremental Traversal“ should be selected only if the option „Full Traversal Interval” is also configured. By this means index files which are not changed are ignored during incremental traversals “Crawler Interval”.
The Microsoft File Connector contains a preconfigured content mapping file (XML) which provides necessary rules to be applied on documents according to their content type. Sometimes it is necessary to change these rules and save this mapping file in separate location. In order to use this modified mapping file, it is necessary to configure this file’s location in “Content Type Mapping Description File”.
Section “Content Location Optimization”
For crawling large files it is beneficial to use Content Location Optimzation in the section “Sources”. For example, if you want to crawl Outlook PST Files.
Configure the mount point according to the screenshot above. The following configuration Options are needed:

Setting | Description |
Root Directory (UNC Path) | Use the same root path you used in the source config above. |
Root Directory (Mount Path) | The local path to which the UNC Path is mounted. |
Files Pattern (Regex) | A regex pattern matchting those files which should be indexed using Content Location Optimization. |
The Content Location Optimization feature requires that the UNC Path is mounted locally. This can be configured using the System Configuration in the Management Center:
- Create the local folder using Filemin:
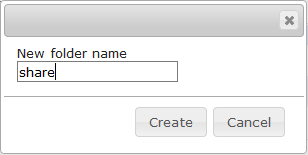
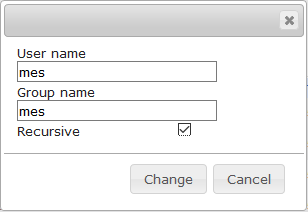
- Grant Permissions to the Mindbreeze user (mes):

- Add a CIFS mount using the “Disk and Network Filesystems” Module:

- Configure the mount:
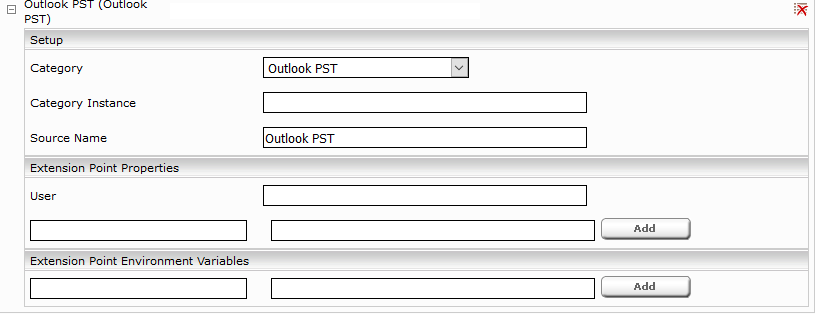
- After you press “Create” the Network filesystem will be mounted and is ready for use.
Crawling Outlook PST Files
In addition to the File Crawler configuration above you also need to add an Outlook PST Datasource to crawl PST Files remove “Default” from Category Instance field.

And finally ensure that a Filter Plugin is enabled for .pst extension.
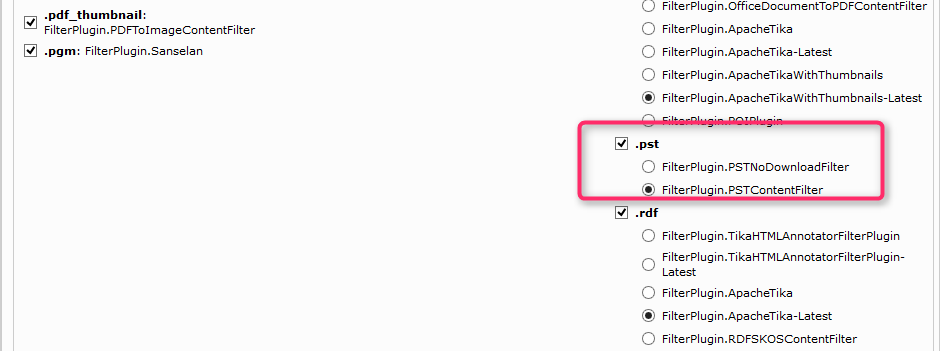

Credentials
The user must have read permissions for the shared directory that is to be crawled. The credentials for this can be configured in the following "Credentials" area.
|
|
|
|
|
|
|
|
|
NTLM authentication is used by default. This requires that "Username", "Domain" and "Password" must be configured. If Kerberos authentication is selected, a Kerberos keytab and Principal must be selected for the crawler in the “Authentication” tab. More information can be found here. Alternatively, "Username", "Domain" and "Password" can also be configured for this, but it is not recommended for this authentication method. |
Additional Settings

Setting | Description |
Dry Run (Advanced Settings) | During a dry run, the indexing status of the documents is not changed. All documents in the configured file share are run through, metadata and ACLs are compared with the index without downloading the content, and the result is logged in the crawler log directory. With a dry run, you can test certain configuration changes, e.g. "ACL Security Level", in advance. |
Content Type Mapping Description File | The path to the file containing customized rules for the mapping of the document metadata.
|
Always Update Files Matching Regex |
|
Ignore Content of Documents without Extension | If this setting is activated, the automatic mimetype detection is deactivated for documents without extension. The contents of these documents are not indexed. |
Disable Default Extension |
If this setting is deactivated, a default extension is used. |
Fetch Preview Content from Datasource | To provide PDF Preview for PDF documents, the binary content of PDF documents is stored in the index. If this setting is activated, the binary content will be fetched directly from the datasource instead. The storing of the PDF content in the index can then be disabled in the filter configuration with which the disk usage of the index will be reduced. |
Enable Heap Dump On OutOfMemory | If the crawler needs more memory than configured in the Plugins.xml <vm_arg> a heap dump is generated in the log directory for further analysis. The amount of memory available to the crawler can be found in the Connector Plugins.xml under <vm_arg>. |
Max. Retry Duration by Filter Connection Problems | The maximum amount of time the crawler is allowed to retry sending a document to the filter service during connection problems. |
Retry Interval during Repository Connection Problems | The amount of time the crawler waits before retrying to connect to the data source during connection problems. |
Max. Retry Duration during Repository Connection Problems | Maximum amount of time the crawler is allowed to retry connecting to the data source during connection problems. |
Disable logging for excluded documents (Advanced Settings) | Is this setting activated, excluded documents are not logged in the crawler logs and in the app.telemetry crawler service log pool. This is only necessary, if there are many documents that are excluded by the setting “Exclude Patterns”. |
Open Search Results
Search results from a Microsoft File datasource (Microsoft Word, Microsoft Excel and Microsoft Powerpoint) are opened on Windows 10 directly in the respective program if the current user is signed in to the respective fileserver and Microsoft Office 2019 is installed.