Query Expression Transformation
Mindbreeze Query Transformer Plugins
Copyright ©
Mindbreeze GmbH, A-4020 Linz, .
All rights reserved. All hardware and software names used are registered trade names and/or registered trademarks of the respective manufacturers.
These documents are highly confidential. No rights to our software or our professional services, or results of our professional services, or other protected rights can be based on the handing over and presentation of these documents.
Distribution, publication or duplication is not permitted.
The term ‘user‘ is used in a gender-neutral sense throughout the document.
Mindbreeze Query Transformation
Mindbreeze provides a list of query transformation services for automatic modification of search queries for better search results.
On the one hand there are the plugin-based extension points that can be loaded on demand into a Mindbreeze installation:
- Synonym Transformer
- Replacement Transformer
- On the other hand there are integrated product features for easier finding the desired results (e.g. by enrichment of indexed documents with additional metadata):
- “Did you mean?”
- Entity Recognition
- CSV Transformation
Query Transformation Plugins
In order to use any of the query transformation services each of them has to be installed into your Mindbreeze installation by means of loading the corresponding plugin (they are delivered within the “Mindbreeze Query Transformation Plugins.zip” package).
The plugin also needs to be included in your Mindbreeze license.
Synonym Transformer Plugin
The SynonymTransformer-Plugin allows you to find search results by looking for different synonyms of a word. Therefore, the query is transformed to search for every term listed in the synonyms list.
Usage: The synonyms can be defined in the Mindbreeze Management Center under "Search Experience" > "Synonyms". Behind this is a CSV file in which a set of synonyms are written in one line, separated by a semicolon (;).
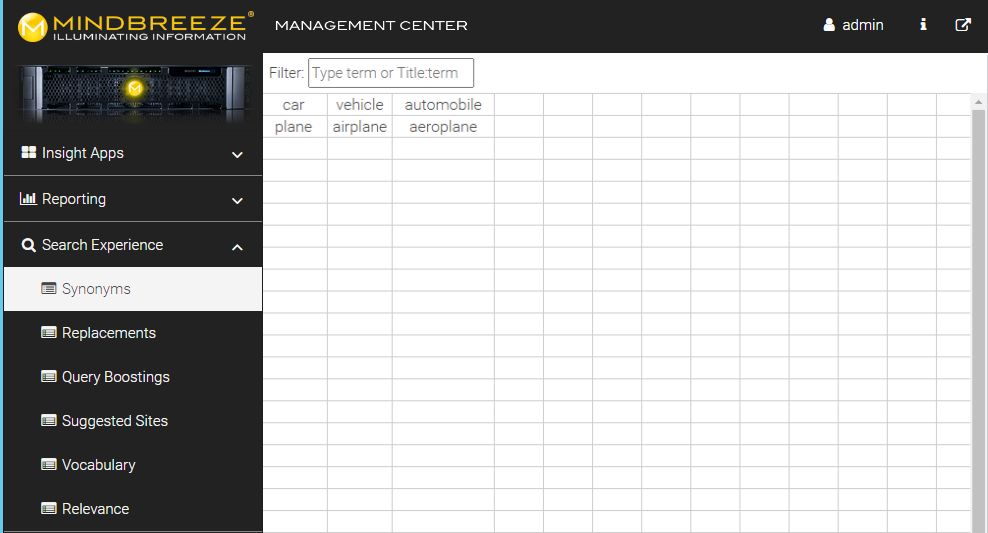
Example of a small synonym.csv file:
car;vehicle;automobile
plane;airplane;aeroplane
Example 1: a search for car sends the transformed query: car OR vehicle OR automobile
Example 2: a search for plane sends the transformed query: plane OR airplane OR aeroplane
Note: The term in first column is used to match on your query. Only single words without spaces are supported in the first column to be matched on.
Installation
- Install the plugin with the Manager UI
- Activate the plugin for every Index you want (with the Manager UI)
- Switch to “Indices”-tab, activate “Advanced Settings”
- Scroll down to the section “Query Transformation Services”
- Select the “SynonymTransformer”-plugin and click “Add”
- Add the path to the CSV-file containing the synonym definitions as “Custom Plugin Properties”
- Add a new property with the name “SYNONYM_CSV_FILE_PATH”
- And assign a value with the path to the CSV-file (either as local file system path or as network path appropriate for the used operating system)
Example 1: SYNONYM_CSV_FILE_PATH C:\data\synonyms.csv
Example 2: SYNONYM_CSV_FILE_PATH \\fileserver.mydomain.com\mes-config\synonyms.csv
Finally save the configuration changes and restart the Mindbreeze Node to propagate all changes.
Note: Any change to the synonym CSV file is applied immediately and will be regarded on the next search.
Replacement Transformer Plugin
The ReplacementTransformer-Plugin is often used to replace unreasonable search terms with better ones or even to disallow search terms.
The main difference to the Synonym transformer plugin is that the original query is really replaced with a new one and will not be shown in the reporting of search terms. The Replacement transformer can therefore be used to hide search results found by users and replace them by something else (e.g. to hide a legacy page and show the new version).
Usage: The terms to be replaced can be defined in the Mindbreeze Management Center under "Search Experience" > "Replacements". Behind this is a CSV file, where the first column defines the term to be replaced. The following columns are taken as disjunctive (OR-combined) replacement value (if empty the term will not be searched for).
Every new search term that should be replaced has to be written on a new line and the columns have to be separated with a semi-colon (;).
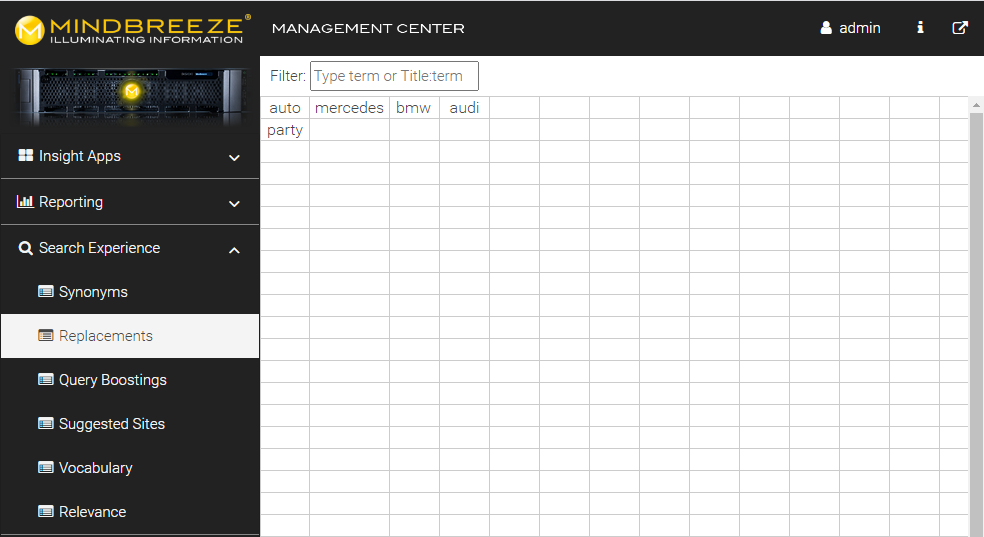
Example of a small replacement.csv file:
car;mercedes;bmw;audi
party
Example 1: a search for car sends the transformed query: mercedes OR bmw OR audi
Example 2: a search for party will not find any results as it is replaced by an “empty” search
Installation
- Install the plugin with the Manager UI
- Activate the plugin for every Index you want (with the Manager UI)
- Switch to “Indices”-tab, activate “Advanced Settings”
- Scroll down to the section “Query Transformation Services”
- Select the “ReplacementTransformer”-plugin and click “Add”
- Add the path to the CSV-file containing the replacement definitions as “Custom Plugin Properties”
- Add a new property with the name “REPLACEMENT_CSV_FILE_PATH”
- And assign a value with the path to the CSV-file (either as local file system path or as network path appropriate for the used operating system)
Example 1: REPLACEMENT_CSV_FILE_PATH C:\data\replacements.csv
Example 2: REPLACEMENT_CSV_FILE_PATH \\fileserver.x.y\config\replacements.csv
Finally save the configuration changes and restart the Mindbreeze Node to propagate all changes.
Note: Any change to the replacement CSV file is applied immediately and will be regarded on the next search.
General Notes on Transformer Plugins (Replacement/Synonym)
Note: If you are using both plugins (Synonym-Transformer and Replacement-Transformer) the Replacement-Transformer is applied first!
The following screenshot displays the configuration of both plugins within the Mindbreeze Manager Interface.
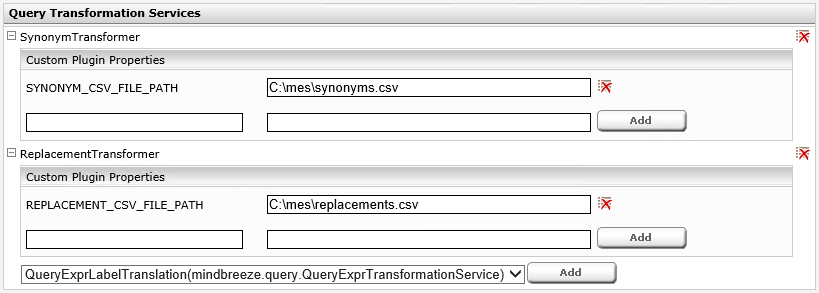
Note: Any change to the synonym CSV file is applied immediately and will be regarded on the next search.
Stemmer transformer plugin
The stemmer transformer plugin allows you to find search results by searching for different stems of a word based on linguistic characteristics of the defined language.
Use: The basic algorithm to find suitable word stems is implemented in the supplied plugin. An additional dictionary with vocabularies of a specific language is available for the most common languages and is used to improve the search results.
In addition, so-called transliterations can also be carried out with the help of the stemmer transformer. In the process, characters are rewritten using rules. Both the original term and the rewritten term are then taken into account in the search.
Example:
A search for leaf will find matches like leaf and leaves.
Installation/configuration
- Install the plugin (if not already installed)
- Enable the plugin for each desired index using the Manager UI:
- Go to the “Indices” tab and enable “Advanced Settings”
- Scroll down to the section “Query Transformation Services“
- Select the “ StemmerTransformer” plugin and click “Add”
![]()
- Configuring properties (depending on use)
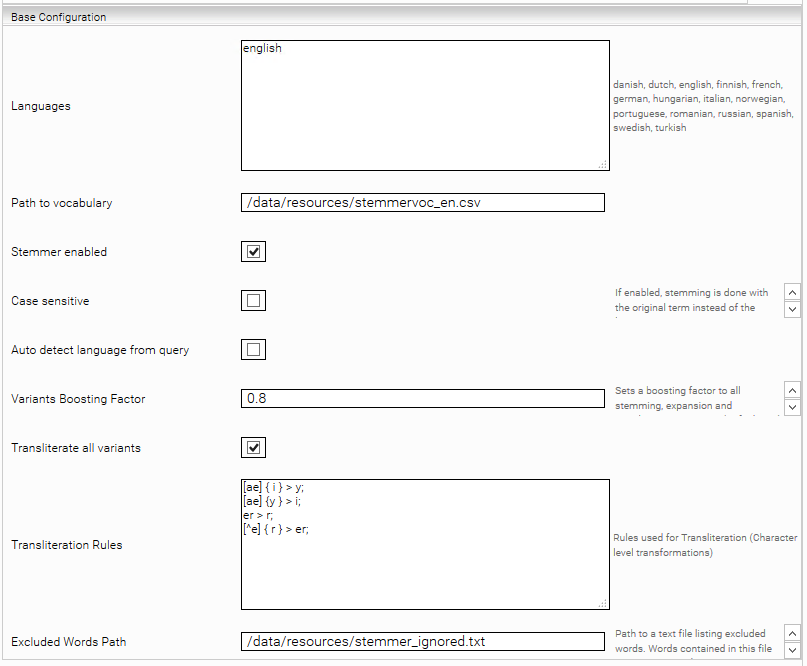
Languages: The languages of the stemmer. One or more languages are permitted. The languages must be separated by commas or line breaks.
Path to vocabulary: A local path on the appliance that contains a vocabulary, so that the extension can be executed without just the reduction to stems (e.g. search for “tree” should also find “trees”).
Stemmer enabled: If checked, the stemmer is used.
Case sensitive: If this option is checked, the reduction of the stems is carried out taking upper and lower case into account (case-sensitive). This can produce more precise – but also fewer – stems. Note: The stem extension vocabulary is always used with no regard to upper and lower case (case-insensitive).
Auto detect language from query: The stemmer tries to derive the language from the search query.
Variants Boosting Factor: Defines the boosting factor for variations. Variantions are the terms that the stemmer generates. This includes root forms, expansions and transliterations. With this factor, for example, the priority of the variations can be reduced so that the meaning of the original value is retained.
Transliterate all variants: This option allows the stemmer to expand the query to include all matching transliterations.
TransliterationRule: Rules for rewriting strings in terms. The following rules can be used: http://icu-project.org/apiref/icu4j/com/ibm/icu/text/RuleBasedTransliterator.html
Excluded Words Path: This option allows you to exclude certain words from stemming. To do so, create a text file with words you want to exclude (1 word per line) and configure the path of the text file in the option.
Add Single Term Alternatives as Alias: With this option active, in case of query expressions of type “terms”, Synonyms for a single term are added as “alias” instead of “alternative” entries in the transformed query.
Then save the changes and restart the Mindbreeze node so that the changes take effect.
Use case: multilingual stemming.
If Mindbreeze is used with multiple languages, it makes sense to configure the stemmer transformer plugin for multiple languages to deliver matching search results for all languages used.
The configuration option "Languages" can be used to configure several languages. The stemmer will then attempt to find stem forms in a search query for each configured language. All stem forms found for all configured languages are then used for the transformation.
If different stem forms of different languages are used together, the search may become too fuzzy and deliver irrelevant search results. To counteract this behavior, you can use the configuration option "Auto detect language from query". If this option is active, a heuristic will be used to determine the language of the search query. Note: The heuristic only determines languages that are configured via the configuration option "Languages". The languages determined are then used for stemming. This means that only the specific language of a search query is used for stemming.
The stemmer vocabulary must be adapted so that expanding the stem forms also works correctly with multiple languages. The stemmer vocabulary ("Path to Vocabulary") is an unsorted text file containing words and has one word in each line. The stemmer plugin reads this text file and creates stem forms for every single word and links the information about which words have the same stem form. This information is used in a search to expand the search term. For example, a search for “tree” should also find “trees.” The language used by the stemmer to find the stem forms in the vocabulary follows the same rules as those used to find the stem forms for a search term. All configured languages are used, or, if the configuration option "Auto detect language from query" is enabled, a heuristic is used to determine the language of a word in the vocabulary. We recommend expanding the vocabulary text file for each configured language. This can be done by simple concatenation – the words do not have to be sorted.
Limitations of the stemmer transformer plugin
Stem forms vs. synonyms
The stemmer uses a primitive algorithm to find stem forms of a word and expands the search query additionally with a vocabulary. However, this only covers minor variations of a word (a few changed letters). This functionality is very useful for the majority of search queries, but may not be sufficient in special cases.
If the expansion of a word (tree trees) is not working correctly, you can take the following measures:
- If no vocabulary is being used, a vocabulary should be configured.
- If an extensive vocabulary is already in use, we recommend including the corresponding word with synonyms in a synonym transformer. If the vocabulary were to be expanded, there would be no guarantee of success, since the existing vocabulary is usually very extensive and the stemmer uses a naive algorithm. If, however, you add a new synonym, you will definitely be able achieve the desired effect.
Known words that are difficult to stem
There are some words for which the stemmer transformer cannot correctly determine the respective stem forms. Known words in the language german are: “Autos,” “Nudeln,” and “Kiwis.” If these words affect the search quality, it is advisable to use a synonym transformer.
Term2DocumentBoost transformer plugin
The Term2DocumentBoost plugin enables relevance tuning for search queries. You can perform the following use cases:
- Increase the relevance of particular documents for certain search queries. For example, a search for “help” can be tailored so that documents with the keyword “documentation,” for instance, are assigned a higher relevance in this search.
- Generally increase the relevance of certain documents. For instance, all documents with the keyword “Mindbreeze” can be assigned a higher relevance.
- Increase the relevance for matching metadata. For example, if you search for any person (search term: “John Smith”), documents by this person (metadata: “Author”) can receive a higher relevance.
- Generally influence the entire relevance model. For instance, change the relevance factor “Term Frequency” to change the priority of the frequency of search hits in the document.
Installation
- Install the plugin using the Manager UI
- Enable the plugin for each desired index using the Manager UI:
- Go to the “Indices” tab and enable “Advanced Settings”
- Scroll down to the section “Query Transformation Services“
- Select the “ Term2DocumentBoost” plugin and click “Add”
- The plugin is configured via 2 files. The
- "Term to Document Boost CSV File" is required for use cases 1, 2, and 3.
- "Default Relevance Options JSON File" is required for use case 4.
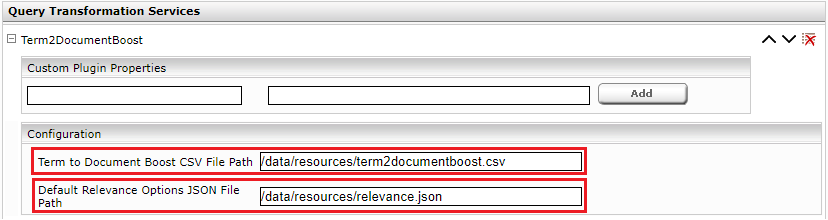
- Configure the settings
|
|
|
|
Then save the changes and restart the Mindbreeze node so that the changes take effect.
- Optional Settings:
„Use Normalization” | It is recommended to enable this setting. When enabled, the capitalization of search terms and relevant document strings is normalized and whitespace characters are combined into a single space character when matching the boosting rules. |
„Boost Quoted Terms” | It is recommended to enable this setting. When enabled, search terms that are set under quotation marks (for an exact search) are also boosted. Otherwise, these search terms are ignored and excluded from boosting. |
Configuration
General description of the Term to Document Boost CSV file format
The CSV file contains one row for each boosting, which in turn contains the following columns:
- Term: the search term
- Metadata key: the name of the metadata property to which the boosting is to be applied
- Pattern: a pattern that determines the value to be boosted
- Boost: the boost factor
- Query: Optional. Expanded configuration. See the Configuration via Query section
Only DocumentInfo metadata (i.e. data that is either aggregatable or regexmatchable) can be used as property here. A list of these properties is available in the designer under "Filter".
If several rules match at the same time, the rule with the largest boost factor is used. However, this behavior could change in future versions.
Note: Any change in the CSV file is applied immediately and will be reflected in the next search.
Calculation of the final value
The final value with which the boost is performed is obtained by multiplying the configured boost factors. The different boost factors are defined with a numeric value, where some boost factors only have a numeric value and some have a numeric value and an exponent. While the base value of each boost factor is set by the application, the exponent can be set by the user. The value of the exponent can be set in the following settings:
- Zone Boost Exponent
- Term Boost Exponent
- Doc Boost Exponent
- Answer Doc Boost Exponent
- Term Match Exponent
- Term Boost IDF Exponent
- Term Boost Zone Coverage Exponent
For the exponent, a value between 0 and 1 can be set. A value of 0 disables the boost factor, as this will result in a total value of 1. Here are two examples for a better understanding.
Example 1:
Based on the Boosting setting, the base has the value of 4. Now the Term Boost Exponent is set to 0,5. This results in the following calculation and the final value for the boost factor:
40,5 = 2.
This results in a final boost factor of 2.
Example 2:
Based on the Boosting setting, the base has the value of 10. Since the settings for the exponent (e.g. Zone Boost Exponent) have not been further configured, the exponent has a value of 0. This results in the following calculation:
100 = 1.
With this, the final boost factor has the value of 1, which disables the boost factor.
Recommended boost factors
The recommended range for the boost factors is between 1 and 10. If a higher factor is used, other fine adjustments can be unintentionally influenced. The use of a boost factor between 1 and 10 can be used in the following functions:
- Zone Boosting
- Document Boosting
- Term Boosting
For more information, see Mindbreeze Query Expression Transformation - Zone boosting (metadata boosting), Mindbreeze Query Expression Transformation - Document boosting (alternative to Term to Document Boost CSV) and Mindbreeze Query Expression Transformation - Term boosting (term and Ngram boosts).
Quick start guide for configuration
This chapter provides a general overview of the steps required to configure boosting. It is important to note that extensive testing is required to verify and adjust the configured boost factors. The following steps must be performed:
- Configuration of Relevance Factors (if default values are not sufficient)
- Optional configuration of Document Boosting
- Optional configuration of Zone Boosting
- Optional configuration of Term Boosting
- Optional configuration of Additive Document Boosting
The Relevance Factors represent the basic boosting configuration and are therefore essential for all use cases. Since the Relevance Factors are global settings, they affect other settings. For the most use cases, the default values are sufficient. If a change of the default values is necessary, the new values must be thoroughly tested. As Relevance Factors are global settings, changes to the values can affect already configured boosts. For more information on Relevance Factors, see Mindbreeze Query Expression Transformation - Relevance factors (term frequency, document frequency).
After the Relevance Factors, boosting can be fine-tuned by configuring Document Boosting, Zone Boosting and Term Boosting. Document Boosting is recommended as the first additional configuration as it is the easiest to perform. It is important to test the settings thoroughly to check the position of the document in the search results. In addition, irrelevant searches should also be performed to check the position of the document in such cases. Depending on the results, the values set in Document Boosting must be readjusted.
If there are metadata where the match should be weighted more heavily, Zone Boosting is recommended. If more complex configurations are required, Term Boosting should be used. Once all the required configurations have been carried out, the Personalised Relevancy Transformer can be used for additional fine tuning. The configuration of Additive Document Boosting is recommended according to the use case.
Use case: increase the relevance of particular documents for certain search queries
Example for a CSV file:
Term;Metadata Key;Pattern;Boost
help;title;portal help|intranet help;5
When a user performs a search for help, documents containing the terms portal help or intranet help in the title will be boosted by a factor of 5.
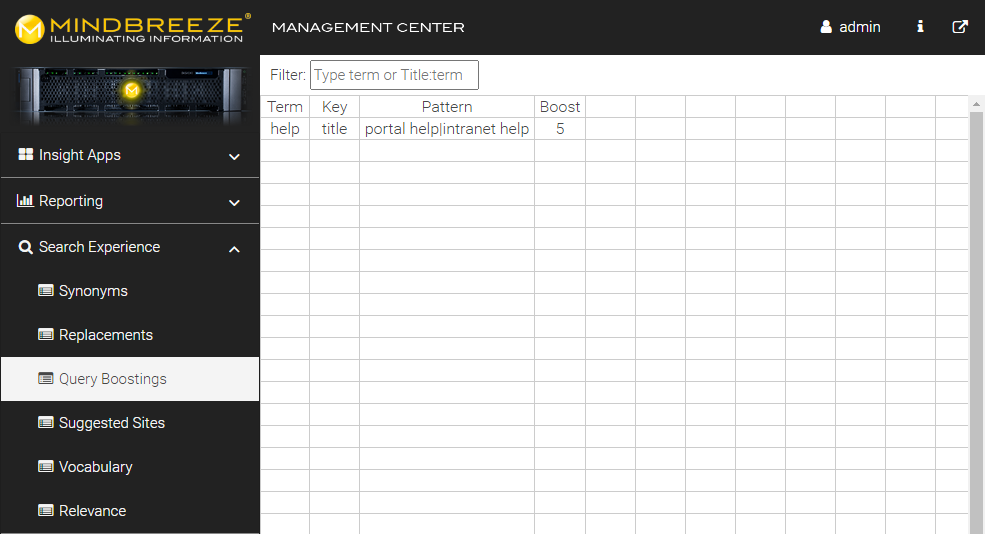
Use case: increase the relevance of particular documents
Term;Metadata Key;Pattern;Boost
;extension;.*pdf;10
Leave the "Term" column empty. The document is boosted regardless of the user’s search query. For example, any document with the extension “pdf” can be boosted up or down.
Introduction to the Mindbreeze relevance model
The Mindbreeze relevance model calculates a relevance count or rank for each result. This is also visible as metadata in Mindbreeze Export:
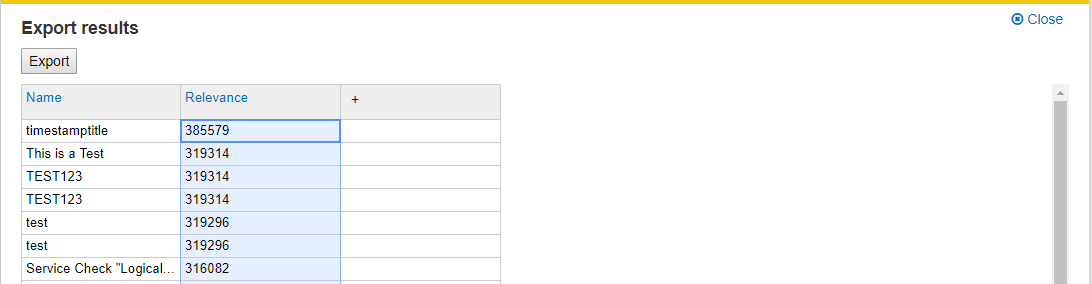
This rank or relevance count is calculated using the following parameters. The higher the count, the more important the result.
Recency
The more recent a result is, the higher the relevance count will be.
Term frequency
The more often the searched term is matched in the current hit, the higher the relevance ranking will be.
Term proximity
If the distance between the matches in the current result is smaller than in another match, then it is more important.
Term inverse zone frequency
If two documents have the same number of matches but one document contains a lot more different terms than the other. The document with the smaller number of other terms then gets a higher rank.
Common misunderstandings and misinterpretations
It is important to note that boosting did not replace the relevance count, instead, it only increased it multiplicatively. If the relevance count of a document is 20 and it is boosted by a factor of 2, the relevance is then 40. This can result in the following phenomenon. You want Result 2 to be in position 1:
Result 1: Rank = 2000
Result 2: Rank = 20
If you boost Result 2 by 10, it will still be in position 2 just like before boosting:
Result 1: Rank = 2000
Result 2: Rank = 200
You therefore need to boost Result 2 by a factor of 101, for example, in order to put it in the first position.
Result 2: Rank = 20020
Result 1: Rank = 2000
Use case: increasing relevance for matching metadata/advanced configuration with query
To achieve more flexibility with boosting, you can also add an additional "Query" column. Here you can specify a query directly with the Mindbreeze InSpire Query Language, which determines the documents to be boosted.
Note: If you use the "Query" column, the "Metadata Key" and "Pattern" columns will be ignored.
Example of query boosting within the MMC table editor:
Term | Metadata Key | Pattern | Boost | Query |
help | 3 | "datasource/mes:key":"http://myweb.com/help-index.html" |
When a user searches for help, documents found with the query "datasource/mes:key": "http://myweb.com/help-index.html" are boosted by a factor of 3.
Another possible use of query boosting is, for example, when searching for people's names, to boost those documents that were written by the person you are searching for.
For this purpose, the metadatum of the document "Author" is used. In the boosting rules, we have the variable {{query}} at our disposal, which in this case corresponds to the value of the person we are searching for.
Thus, we can define a query for this case that finds documents with the author of the search term and boosts them.
The variable {{query}} is used in the query column and is dynamically replaced by the search query during a search.
Note: if you use the Query column, the Term column is also ignored.
If the user searches for the term John Doe, all documents with the author metadata: John Doe are boosted by 7 based on the boosting below.
Term | Metadata Key | Pattern | Boost | Query |
7 | Author:"{{query}}" |
Another useful variable that can be used is the {{lang}} variable. When the user starts a search, those documents should be boosted which correspond to the user`s web browser language.
For this, a document metadatum is needed in which the language of the document is stored.
To do this, the LanguageDetector plugin needs to be configured. The LanguageDetector can then recognise in which language a document is written and sets the corresponding language metadatum (Example: en or de).
The variable {{lang}} contains the language, which is sent in they query by the web browser.
Note: Here the Term column is ignored as well if the Query column is used.
For example, if the user now configures a LanguageDetector plugin that creates a metadata called detectedLanguage, the boosting below it will boost all documents that match the web browser's language by 7.
Term | Metadata Key | Pattern | Boost | Query |
detectedLanguage | {{lang}} | 7 |
The following variables are supported:
Name | Description |
{{query}} | The current search query |
{{lang}} | The language in the User-Context (e.g. en) (if available) |
{{country}} | The country in the User-Context (e.g. US) (if available) |
{{usercontext_language}} | The language code User-Context (e.g. en-US) (if available). |
{{session_<<key>>}} | Any value from the Session of the User-Context. e.g. {{session_mycustomkey}} results in mycustomvalue (if present in the Session properties). |
{{identity_name}} | Name of the user in the User-Context. (e.g. john.doe) (if available) |
{{identity_<<key>>}} | Any values from the user's Identity. e.g. {{identity_mail}} results in john.doe@example.com (if present in the Identity properties). |
{{usercontext_<<key>>}} | Any value from the User-Context. e.g. {{usercontext_mycustomkey}} results in mycustomvalue (if available in the User-Context properties). |
If there is no value for a variable, the associated boosting will not be applied.
Use case: general influence of the relevance model
You can generally adjust all parameters of the relevance model. This is done via the Default Relevance Options JSON file.
It is not advisable to edit this JSON file manually. Instead, you will find the item "Relevance" under the menu item "Search Experience" in the Management Center.
Note: These parameters are a fundamental part of the relevance model; small changes can have a major impact on the order of the search results. It is possible that the boosting factors in the CSV will have to be adjusted at a later time.
The following sections describe which parameters can be adjusted.
For more information, see:
- Mindbreeze InSpire Configuration Manual, Indices tab
- Manual api.v2.search Interface Description
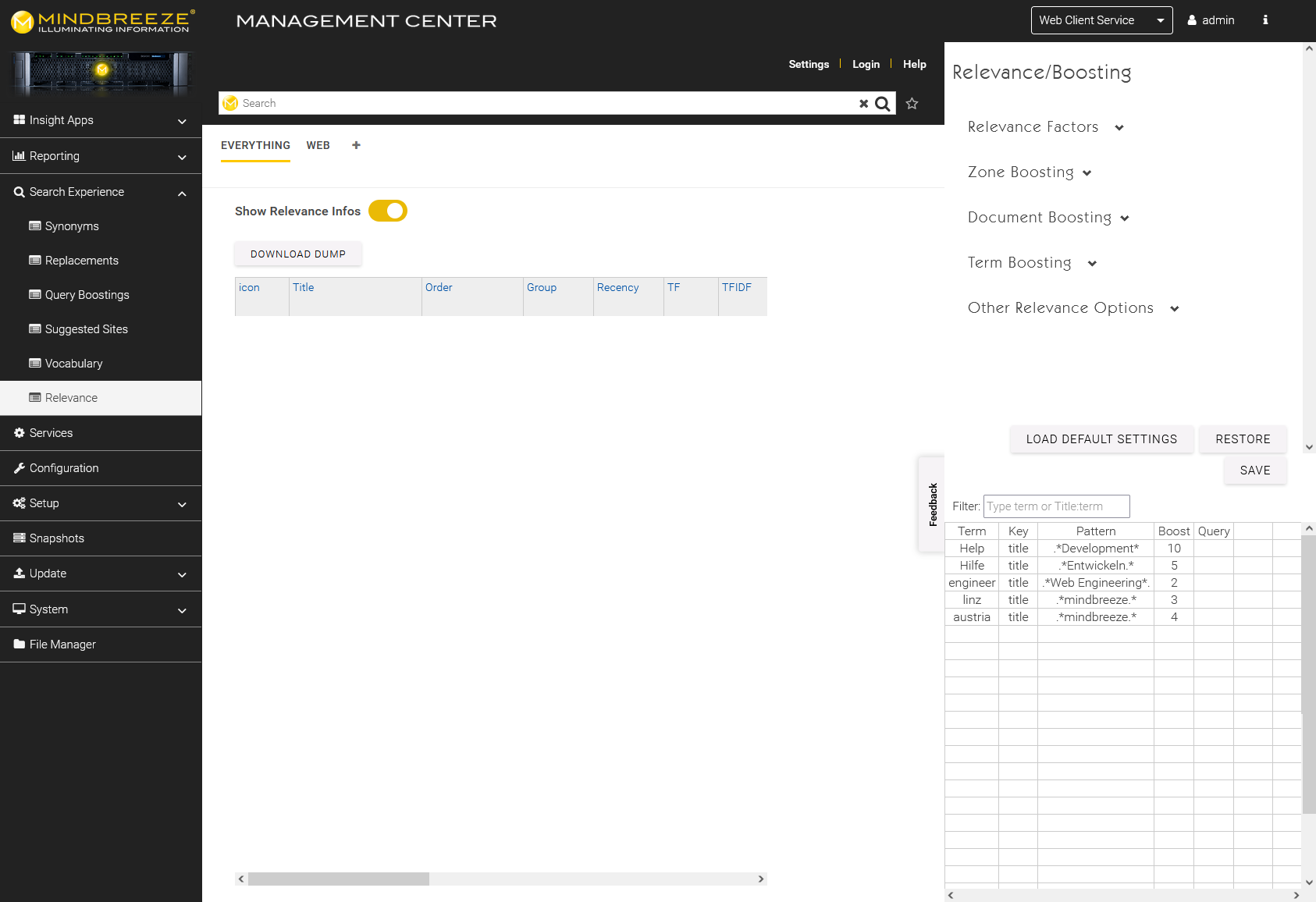
Relevance factors (term frequency, document frequency)
- The individual entries can be used to determine how the relevance parameters influence the relevance ranking. The relative share of the individual factors is the percentage share of this parameter.
Serial | The influence of recency (document date mes:date) on the relevance. Documents from the last two years (25 months) are considered “recent”. Anything older than two years is generally treated as not recent. |
Term frequency | Absolute frequency of words |
Doc frequency | Relative frequency of words in the document – TF-IDF |
Term proximity | Distance between the hit terms in the text |
Term inverse zone frequency | Maximum relative frequency of words in individual zones – max TF-IZF |
Zone boost exponent | Influence of document property boosting on relevance ranking (0 means it will be ignored) |
Term boost exponent | Influence of search term boosting on relevance ranking (0 means it will be ignored) |
Doc boost exponent | Influence of mes:boost property on relevance ranking (0 means it will be ignored) |
Term match exponent | Influence of the matching of terms (interesting for the OR function) mes:boost property on relevance ranking (0 means it will be ignored) |
Constant | Particularly if Term boosting/Document boosting/Zone boosting is used exclusively and you do not want to use the remaining components (e.g. Term proximity, Serial). |
Term boost IDF exponent | IDF = Inverse document frequency. The frequency of the occurrence of a term in many documents should have an effect on the calculation of the term boost. A high exponent means: less frequent words are weighted more strongly. A low exponent means: frequent words are weighted more weakly. 0 means that this option will be ignored. |
Zone boosting (metadata boosting)
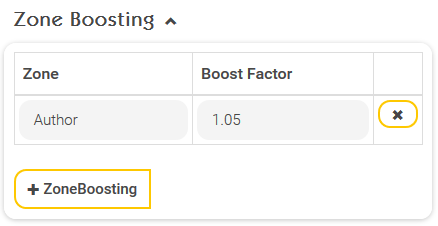
Zone boosting is another way to change the order of the search results. Boost factors can be configured for so-called zones. A zone is nothing more than a piece of document metadata. If you want documents that are found based on a certain metadata to be ranked higher in the search results, you can define a boost factor for this metadata (= zone). In the above example, documents found on the basis of the metadata “Author” are classified as more relevant by a factor of 1.05. Valid values of the boost factor are real numbers greater than or equal to one with a decimal separator “.” (≥ 1.0).
Document boosting (alternative to Term to Document Boost CSV)
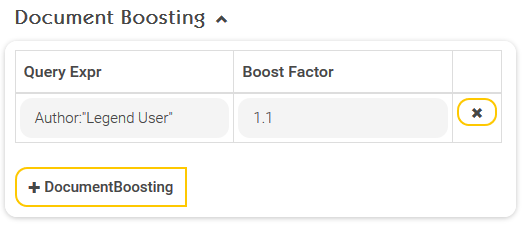
Using “Document boosting,” you can also change the relevance of certain documents. The relevance of documents that are found based on a search query can be changed by the “Boost factor” for all documents that match the “Query Expr”. In the above example, documents found that originate from the author “Legend User” are rated more relevant by a factor of 1.1.
Valid values of the Boost factor are:
- To decrease weighting: real numbers greater than zero and less than one (> 0.0 ∧ < 1.0) with decimal separator “.”
- To increase weighting: real numbers greater than one (> 1) with decimal separator “.”
- The Boost factor 1 has no impact
Term boosting (term and Ngram boosts)
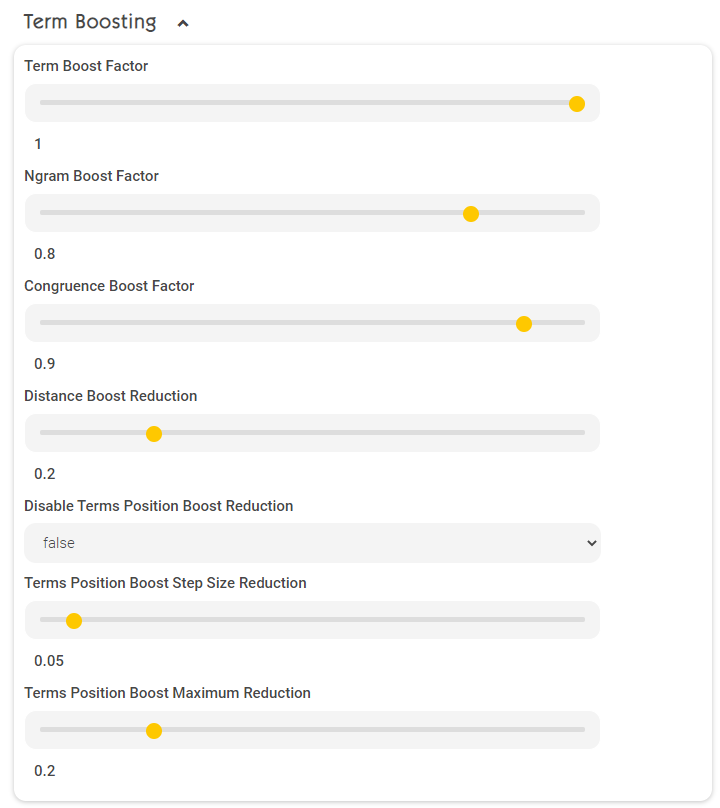
Term boost factor | Boost factor for exact matches (1.0) |
Ngram boost factor | Boost factor for partial word matches (1.0). This option is only relevant if the following settings are enabled in the Management Center under “Configuration” -> “Client Services” -> “Enable Character NGRAMs” (“Advanced Settings” must be enabled). This option is already enabled by default. |
Congruence boost factor | Boost factor for character congruence (e.g. “a” vs. “ä”). This option is only relevant if the following settings are enabled in the Management Center under “Configuration” -> “Client Services” -> “Query Expansion for Diacritic Term Variants” (“Advanced Settings” must be enabled). This option is already enabled by default. |
Distance boost reduction | Boost decrease for each change = Edit distance (e.g. “Mindbreze” vs. “Mindbreeze”). This option is only relevant if the following settings are enabled in the Management Center under “Configuration” -> “Client Services” -> “Enable Query Expansion for Similar Term” (“Advanced Settings” must be enabled). However, this option is enabled by default. |
Disable Terms Position Boost Reduction | If set to "true", "Terms Position Boost Step Size Reduction" and "Terms Position Boost Maximum Reduction" are deactivated. |
Terms Position Boost Maximum Reduction | Maximum value by which the boosting of a term can be reduced. Example: Note: "Terms Position Boost Maximum Reduction" works only if Optional Terms is enabled in Client Services (enabled by default). |
Terms Position Boost Step Size Reduction | Step size by which each following value is reduced. Example with 0.1 and "Terms Position Boost Maximum Reduction "=0.2 and search input of "My name is John" results in the following term boosting: Note: “Terms Position Boost Step Size Reduction” works only if Optional Terms is enabled in Client Services (enabled by default). |
Other Relevance Options
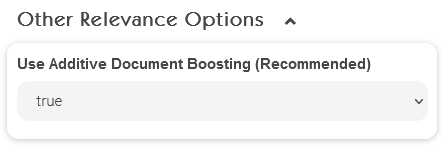
Using Additive Document Boosting (Recommended) | Defines the boosting strategy for multiple boostings of one document. By default, Additive Document Boosting is enabled, which considers all boostings on a document for calculating relevance. If the setting is disabled, only the highest boosting is used to calculate relevance. |
Export Dump
The current dump can be saved and downloaded as Excel file by clicking the button "Download Dump".

MetadataQueryTransformer Plugin
(formerly "MetadataTransformer" plugin) This plugin manipulates search queries for metadata searches. It is used for users who search with colon notation (e.g. name:John), but do not mean the metadata "name". The plugin is configured with a CSV file consisting of rules.
installation
- Install the plugin with the Manager UI
- Activate the plugin for each desired index using the Manager UI:
- Switch to the "Indices" tab and activate "Advanced Settings".
- Scroll down to the "Query Transformation Services" section.
- Select the "MetadataQueryTransformer " plugin and click "Add".
configuration
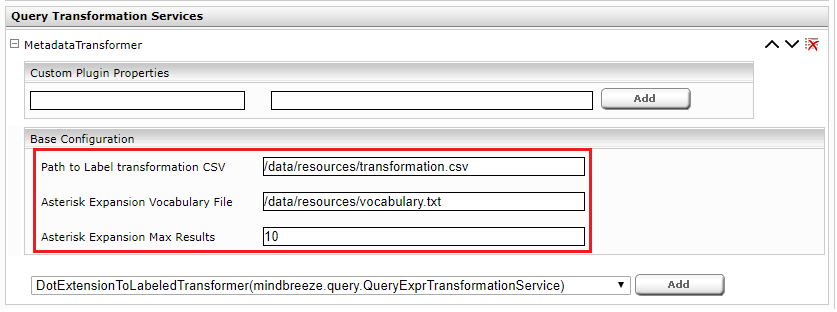
The following parameters can be configured:
"Path to Label transformation CSV" | Path to CSV file (see next section) |
"Asterisk Expansion Vocabulary File" | Path to vocabulary file (see next section) |
"Asterisk Expansion Max Results" | Maximum number of words that the asterisk symbol expands. |
Label Transformation CSV Syntax
This file contains the transformation rules. One rule per line. 2 or more columns without column caption. Meaning of the columns:
Label | Name of the label in the search query to which this rule applies. The asterisk symbol (*) can also be used for any name. |
Rule type | "PHRASE," "NEAR," "IGNORE," "REGEX_PATTERN" or "ASTERISK_PATTERN" |
Options | Depending on the rule type |
Basically, a search is performed directly in the metadata and an alternative search condition is added.
Note: For the REGEX_PATTERN or ASTERISK_PATTERN types, the property searched should be regexmatchable or aggregatable. This can be defined in the Category Descriptor or in the Index Configuration.
"PHRASE" | Creates a phrase search (normal search). e.g.: rule name;PHRASE , search for "name:John" finds documents with "name John" in the content |
"NEAR" | Creates a near search, the distance can be defined via an option. e.g. rule temperature;NEAR;3 , search for "temperature:20" finds documents with "the temperature is about 20 degrees" in content |
"IGNORE" | Creates a Neutral Search that does not return any results itself. e.g. rule operation:IGNORE This rule allows a selective exception of transformations, if a standard transformation was previously introduced by means of *. |
"ASTERISK_PATTERN" | Transforms a metadata search into an asterisk pattern search, synonyms can be defined via options. e.g. rule number;ASTERISK_PATTERN;id;nb , search for "number:A42*" finds documents whose property "id" or "nb" begins with A42. |
"REGEX_PATTERN" | Creates a Regex pattern search, synonyms can be defined via options e.g. rule number;REGEX_PATTERN;id;nb , search for "number:A.*" finds documents whose property "id" or "nb" matches the regular expression A.*. |
Vocabulary File Syntax
Regardless of label transformation, the plugin also provides the ability to transform normal search terms containing asterisk symbols (*). These search terms are replaced by similar terms from a defined vocabulary.
The "Vocabulary File" is a text file with terms, one term per line.
For example, a vocabulary file with the following content:
superprint
printomatic
fastprint
a search for "*print" searches for the following terms: "superprint" and "fastprint".
DotExtensionToLabeledTransformer Plugin
This plugin makes it easier to search for a file extension. Search queries in the form “.pdf:searchterm” will be converted to the form “extension:pdf searchterm”.
Example: A search for the term "Invoice" and the file extension "pdf" normally looks like this:
"extension:pdf Invoice"
With this plugin the search can be simplified on
".pdf:Invoice"
Installation
- Install the plugin with the manager UI
- Activate the plugin for each desired index using the Manager UI:
- Switch to the "Indices" tab and activate "Advanced Settings".
- Scroll down to the "Query Transformation Services" section.
- Select the " DotExtensionToLabeledTransformer" plugin and click "Add".
- Finally, save the changes and restart the Mindbreeze Node for the changes to take effect.
Configuration
This plugin does not require any configuration.
QueryExprLabelTranslation Plugin
The plugin allows you to search for metadata in the original language. For example, the metadata with the ID "title" in German is translated as "Name". If you want to search for documents with the name "Rechnung", you have to enter the following search query without this plugin – "title:Rechnung" – to get the desired results. With the QueryExprLabelTranslation Plugin it is now possible to make a search query in the original language: "Name:Rechnung". The used label "Name" is translated back to "title" by the plugin and the search query returns the desired results.
Installation
The QueryExprLabelTranslation plugin is already built-in and requires no installation.
Configuration
The QueryExprLabelTranslation plugin is active for each index by default and requires no configuration. The translations are loaded from the CategoryDescriptor by the metadatum tags.
Additional Features
Did you mean?
If you don’t find any results and only misspelled the word in the search term Mindbreeze offers an alternative search term (based on some internal index statistics and analysis) that would find better results. This feature is called “Did you mean?”.
Entity Recognition
Entity recognition can be used to extract metadata from the document content or from other metadata properties of the documents which may be used for more efficient searches afterwards.
This topic is described in detail in “Documentation – Mindbreeze Inspire”. For details please read the documentation on “Indices tab”.
CSV Transformation
To extend indexed documents with additional metadata for easier finding results the CSV transformation allows the mapping of well-defined values to other value columns stored in a CSV file.
This feature can be quite helpful to extend your index with technical terms, abbreviations, topics or even short descriptions for your documents in special use cases.
Example: a city ZIP code directory
ZIP;City;Province
4020;Linz;Central Upper Austria
1020;Vienna;Capital City of Austria
9861;Krems;Forest Quarter
4400;Steyr;Traun Quarter
The first line of this sample CSV contains the head line defining the column names to map the data. The other lines contain the values for each mapping column. So if you are searching for the term “quarter” you will find search results for the two cities Steyr and Krems.
Another example would be the mapping of technical product data stored in a CSV file to the base articles on your web site. The mapping could be accomplished using the product ID extracted from the product web site and the CSV file contains a set of columns describing the article (product ID, category, price, dimensions, etc.).
Configuration
As this feature is part of the Mindbreeze base product you don’t have to install any additional plugins but you only have to configure it.
- Switch to “Indices”-tab, activate “Advanced Settings”
- Scroll down to the section “CSV Transformation”
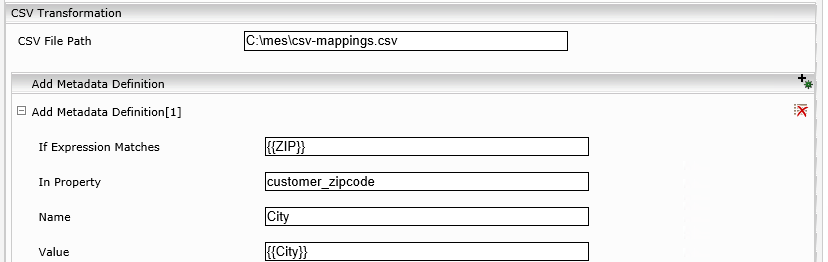
- Specify the path to the CSV file containing the data mappings (either as local file system path or as network path appropriate for the used operating system)
- Example 1: CSV File PathC:\data\csv-mappings.csv
- Example 2: CSV File Path\\fileserver.x.y\config\csv-mappings.csv
For every metadata property (column) you want to extract from the CSV file add a new metadata definition with following property settings:
- If Expression Matches:{{ZIP}}… this is the name of the mapping column in the CSV file (header name of the column containing the keys to map the documents)
- In Property:customer_zipcode … this is the source document metadata property from the indexed document used to map the results (this could also be mes:key or any other property)
- Name:City… this is the desired metadata name of the new property to extract (will be available for searching and if listed in the categoryDescriptor also visible in the results)
- Value:{{City}}… this is the name of the desired target column in the CSV file (header name of column to be extracted)
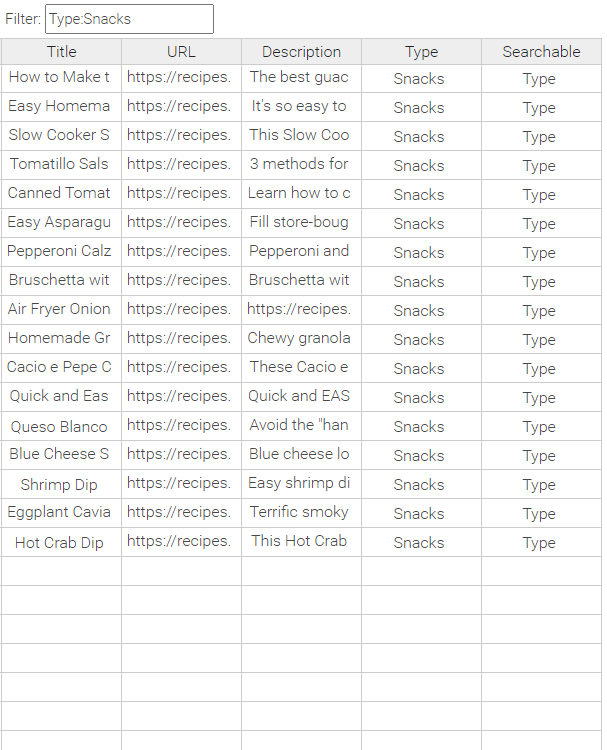
Filtering in CSV Editors
Saving a CSV Editor table data while filtering will save the whole table data, including non-filtered records.
You can filter by typing a case insensitive search term which will search in all the columns. Furthermore, you can narrow the search scope by searching in a specific column. This can be achieved by the following search format: Columname:searchterm. Both the column name and search term are case insensitive.
Example 1: No filtering of the data
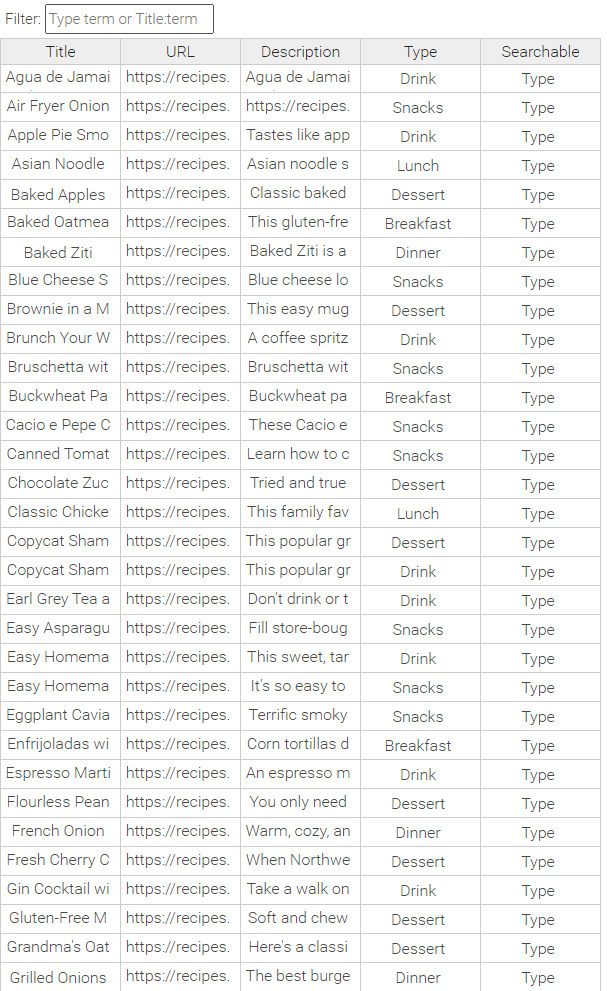
Example 2: All records with Type "Snacks" are displayed