
Sure, you can handle it. But should you?
Let our experts manage the tech maintenance while you focus on your business.
Let our experts manage the tech maintenance while you focus on your business.
Release Notes for Mindbreeze InSpire
Version 21.3
Innovations and new features 
Mindbreeze shows context-specific results even if not all search terms match
In order to optimise the search experience even further, we have developed a feature as part of the new release that optimizes the retrieval of content. It enables Mindbreeze InSpire to now also provide content as results that does not contain every single search term, but is just as relevant in context. In order to make this transparent for the user, a corresponding note is displayed directly in the search result, which clarifies which terms do not appear in the search result.

By default, Mindbreeze InSpire finds content that contains at least two-thirds of the search terms. Specifically, this means: If a search query contains for example five search terms, one term may be missing from the result so that the result is still displayed due to contextual relevance. The screenshot shown above shows an example in which a document is found for the search query "Artificial Intelligence Human Interaction Article", which does not contain the term "Article".
Due to the enormous advantages, this feature is activated by default. However, it is possible to parameterize or even to deactivate it if necessary.
In this context, optimizations were also made to the query expression transformation pipeline and relevance. The expansion of search terms from synonym catalogs and the introduction of word aliases through morphological variants is now performed in such a way that the representation of the original search input is completely preserved. In this way, a higher hit quality can be guaranteed.
With regard to relevance, the individual search terms are now additionally weighted depending on the order in which they are entered. To increase the relevance of the results, the calculation of the proximity of the entered terms in the hit context has also been further optimized. This can also be parameterized or completely deactivated.
Workplace integration in Salesforce
As part of our 21.3 release, we have created the innovative option of seamlessly integrating Mindbreeze InSpire Insight Apps into your Salesforce application. Users can now access the full range of functions and services of Mindbreeze InSpire directly in their familiar working environment.
Among other things, this means that users do not have to leave the application to make a search query. If a search query is made, Mindbreeze InSpire automatically extracts both Salesforce-specific documents and content from external connected data sources.
Workplace integration of Mindbreeze InSpire in Salesforce thus creates the ideal basis for comprehensive interaction with the application. From the user's point of view, this opens up numerous opportunities to use the functionalities of Mindbreeze InSpire even more profoundly.
This could be, for example, the automated triggering of a search query when calling up a specific case. If this is implemented, navigation to a case stored in Salesforce ("customer transaction") automatically triggers a search ("zero term search"). In this way, users are provided with additional, context-relevant content.
Another example in this context is the possibility to attach search results to a case. If a user wants to save a specific document from the automatically triggered search results to the specific case, this would be possible by simply clicking on "Attach To Case".
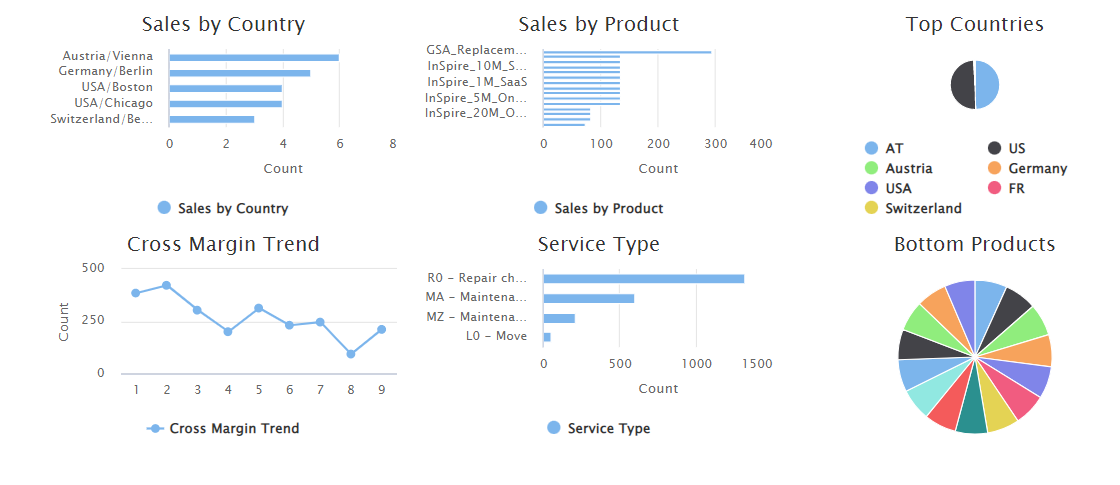
Optimization of in-memory computations for insight apps and analytics
With this feature, we were able to implement a significant performance optimization. Thanks to the use of in-memory calculations, Mindbreeze InSpire is able to process data for Insight App representations such as filters and charts much faster.
The necessary dimensional metadata, which is dynamically defined per document, is now processed significantly faster.
This way, for example, complex dashboards (as in the following screenshot shown) can be displayed much faster.
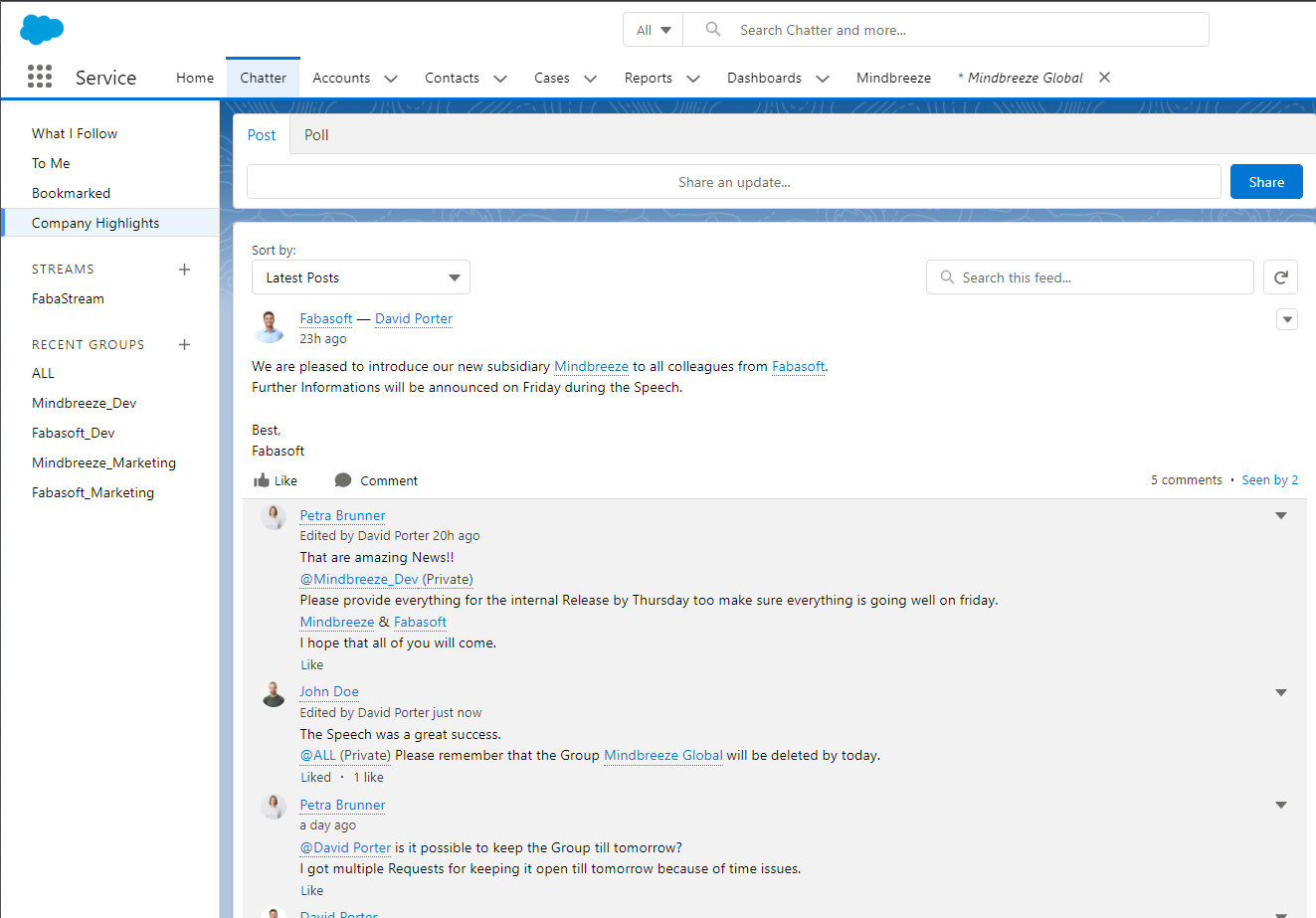
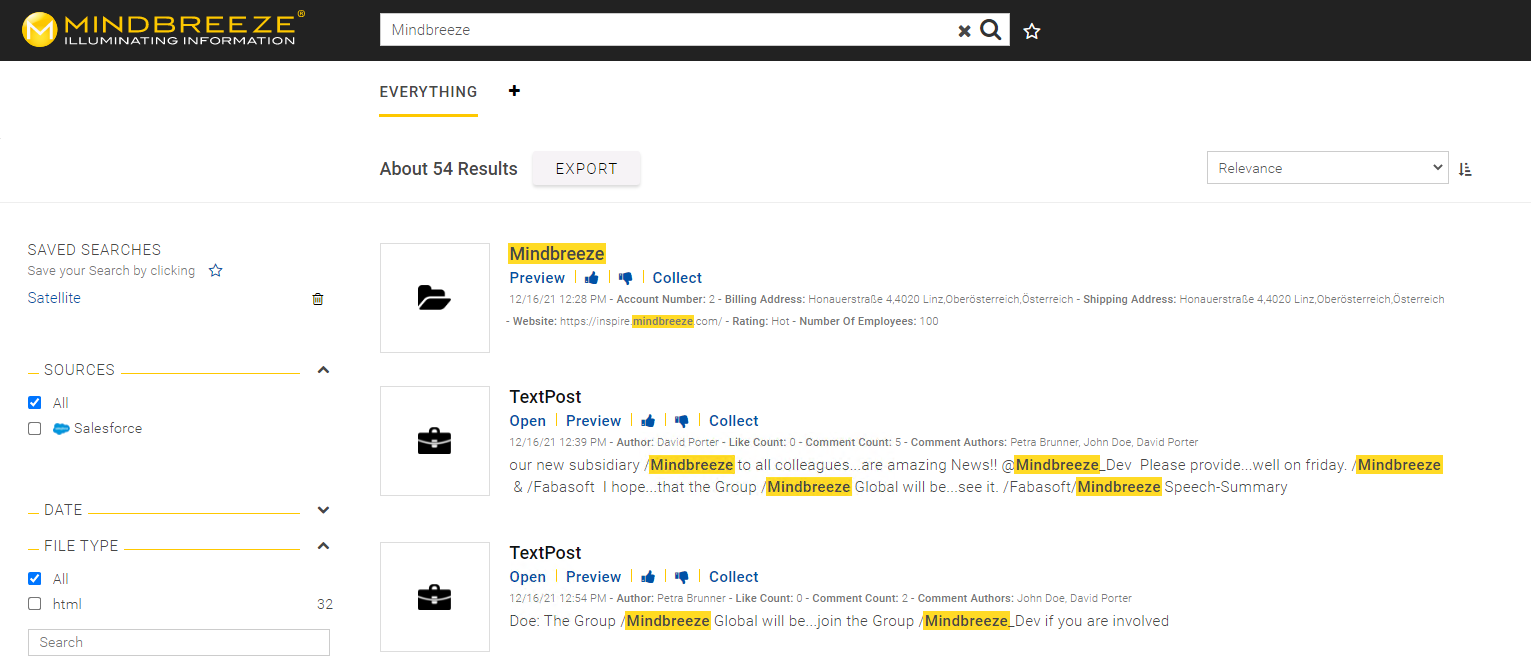
Advanced connectors
Salesforce connector supports the enterprise collaboration platform “Salesforce Chatter”
To enable you to link Salesforce even more extensively with Mindbreeze InSpire, we now also offer the option of including information from the social network “Salesforce Chatter”.
Thanks to the expansion of the Salesforce connector, contributions, messages and posts, so-called feed items of the corporate social media platform, can now also be indexed. This provides users with an even more comprehensive and deeper insight into the available information across all Salesforce systems used.
GitHub Wiki Pages
The new version of the GitHub connector now also supports crawling via Wiki Pages.
In this way, documentation of the source code can now also be searched easily and efficiently.
In addition, we have created the possibility to deactivate the indexing of issues and pull requests if desired, which among other things reduces crawling times to a minimum.
Incremental processing of documents Google Drive
Our Google Drive connector now supports the efficient incremental processing of documents. This primarily serves to optimise crawling times and ensures that the available data is always up to date. Mindbreeze InSpire only indexes files that have been changed, deleted or added, especially with a large number of documents.
Microsoft SharePoint Online Managed Metadata
An extension of the SharePoint Online connector now also supports the search of managed metadata. This is a special form of metadata that simplifies handling by categorising properties (e.g. the term department) and special values (marketing, sales, HR...).
If you want to use managed metadata, you can configure the corresponding option "Index Complex Metadata Types".
Technical extensions
Backend service authentication via service accounts
As part of the technical enhancements to our 21.3 release, we have given users the option to use JSON Web Token (JWT) with service accounts for backend authentication, in addition to other variants. This is now available to you as a standard variant due to its numerous advantages.
In addition to higher security through service accounts, this variant is more scalable and more robust against connection problems to the IDP. Furthermore, this variant offers the advantage of maintaining the IDP without affecting the search.
Appliance platform modernization
- Security is a top priority for Mindbreeze. To ensure that our solution is always at the cutting edge of developments and meets your high requirements, we continuously update the operating system of our appliances.
- In order to be able to offer the usual stability and the best possible support in the future, we have replaced the CentOS Atomic host operating system with the CoreOS platform as part of this release.
In addition to faster bug fixes, this change also ensures extensive optimization of performance. Furthermore, the change of the operating system enables in-place updates for existing appliances.
You can still roll back to Atomic Host, and all Atomic Host benefits will still be available to you.
Modernisation of the Insight Apps platform
Our 21.3 release is accompanied by a major modernization of the Insight Apps platform at the developer level. By moving to Webpack, we've created a resource-efficient, innovative, and straightforward way for developers to assemble Insight Apps. This means a number of benefits and optimizations.
In addition to an accelerated loading time of the Insight Apps, innovations and features (e.g. language features) can be implemented and used more quickly in the future with the use of Webpack. It also simplifies the reusability of existing code, enabling even faster development.
Important notes on the update
If all of the following points apply to your environment:
- Distributed Operation (Producer/Consumer)
- Update from a version older than 21.2 HF2 to version 21.2 HF2 or newer.
- In the case of sequential updates of the nodes (instead of simultaneous updates), older and newer versions are operated simultaneously for a short time.
- Notifications are activated in at least one client service.
follow these instructions to ensure a smooth update.
Security relevant changes
21.3.5.1708
- Mitigate CVE-2021-4034 in polkit
21.3.1.1583
- Update Apache Tomcat to 8.5.70 (CVE-2021-33037, CVE-2021-30640)
- Update Apache Ant to 1.9.16 (CVE-2021-36373, CVE-2021-36374)
- Fix for: ACL Internalization: ACL in Cache differs from DocInfo ACL
- httpd Security Update (CVE-2021-40438)
- Remove Log4j2
- NSS Security Update (CVE-2021-43527)
- Deactivate mod_lua (httpd CVE-2021-22790)
Additional changes
21.3.7.1714
- Fix für: Reverse references maz become incomplete during heavy updates
21.3.6.1711
- Fix for: Voting is displayed on the Client, even if disabled
21.3.5.1708
- Fix for: SharePoint Online: Delta token are saved even when error occour
- Preview can use a defined document property as URL for fetching documents from datasource
- Snapshots: Profile can be selected when creating a new snapshot
- Remove deprecated HANLP
- Automatically grow file systems and partitions according to disk size
- Fix for: Snapshot SDK Sample OAuth token request uses unencoded post body
- Snapshot uses resources referenced in config/MMC, development snapshot optionally includes all resources
- Authorized Search using Subquery Transformations.
- Mandatory Subqueries are configurable on the index
- Improved usability of Insight Apps Designer
- LDAP Principal Cache supports LDAPS (port 636)
- Sitemap Features: value format and aggregatable metadata
- Fix for: GitHub Connector: Crawling public repositories leads to IndexOutOfBoundsException
- Fix for: GitHub Connector: Wiki Page open link not working (404)
- Fix for: Salesforce Crawler and Principal Cache: 'INVALID_QUERY_LOCATOR'-Exception
- Fix for: Salesforce PermissionSetQuery queries inactive users
- Salesforce exclude automatically generated FeedItems
- Salesforce username authentication and frozen users
- Fix for: Salesforce: Crawling FeedItems leads to IllegalArgumentException
21.3.4.1600
- Fix for: Dates are aggregated as metric
21.3.3.1595
- Fix for: Reduced performance when running a large number of indices
21.3.2.1592
- Fix for: CSS issues with custom Insight Apps
- Fix for: Containers may not start in rare update cases
21.3.1.1583
- Fix for: Snapshots: invalid error response INCOMPLETE
- Improved updates in multi-node setups
- Accessibility: To change the ARIA implementation for Facets – Accordion
- Alerts: Suggest for 'Group' is not visible (overflow hidden)
- Detect binary/base64 content and ignore it from inverting
- Get CRM permissions gained through sharing
- GPU Container Support for Fedora CoreOS (manually installed)
- Insight Apps Designer: Computed Properties are editable via a table list
- Jira: Description of Jira tickets is should be indexed. Exclusion pattern for tickets should be definable
- Jira: Resolve "Project Roles" per project
- Jive Sitemap Generator: Reduce sitemap with filter criteria
- Limit Keycloak/Keycloak-HA authenticationSession Cache to 1000 Entries
- mes:docid:<docid> bzw. `mes:docid:[docid TO docid2]` is represented as bitset
- Microsoft Graph Connector crawls boolean fields
- Microsoft Dynamics CRM: Deny access for users with SystemUser.IsDisabled flag
- Mime Type Detection: Additional check of documents recognised as text for content bytes
- Multiple CSV Logger (e.g. SharePoint Online, Exchange) loose entries after backup
- OAuth authentication for Jive connector
- Plugins.xml and Documentation Performance Settings (Concurrent Filter and Index Dispatch Threads) for all Crawler
- Query Log API includes PREVIEW actions
- SharePoint Online: Usability improvement of endpoint mapping
- Sitecore Connector: Correct indexing of metadata-only objects
- Text Classification Service: Adding download dump Button for downloading labeled data
- Fix for: Cache Precomputation ACLs not shown as default true
- Fix for: Client Service Wrong database credentials for persisted resources lead to unresponsive Client Service (500 error)
- Fix for: Corrupt task history breaks Task and Node manager
- Fix for: CSV Export: Encoding issue of Special Characters when opened in Excel due to missing BOM
- Fix for: Documentum Connector: Use case insensitive username and restrict dm_world for Documentum users
- Fix for: Excel Export not working when not logged in
- Fix for: filteredfacet with data-dropdownfitler style duplicating title when using data-title property
- Fix for: FPDF-filter does not filter out the control character STX
- Fix for: Help Linktext is always rewritten to "Help" when the query parameter ?language=de is used
- Fix for: Index SIGSEGV in CachingAuthorizer with Sharepoint Online
- Fix for: Jira Cache: cache never finishes building
- Fix for: Jira Cache: Improve cache update progress logging
- Fix for: Jira: Crawler does not retry which can lead to unsuccessful crawl runs
- Fix for: Jira: Is not indexing all available issues. Documents are accessed multiple times with paging
- Fix for: JWT Authentication does not work for Resources in Additional Contexts
- Fix for: Label "Search App" is used in Query Performance Tests
- Fix for: LDAP Principal Resolution Cache: Very slow unreliable (Connection Timeouts)
- Fix for: Multiple searches are triggered when the stack is opened (Preview/Export)
- Fix for: MesUtil::BitSet is structured in 64bit chunks. setAll(start, length) will always set start till end of chunk
- Fix for: Microsoft File: Share Level ACLs causes STATUS_TOO_MANY_OPENED_FILES error and local groups resolution cannot be disabled
- Fix for: Microsoft Teams Delta Bad Request & NullPointer
- Fix for: Mindbreeze Configuration: With importing Client Service configuration (using the Export/import UI) attributes set to parameter are set to text value
- Fix for: MMC Tasks: After leaving "Tasks", the /find request is still triggered in the background
- Fix for: MultiLookupServicesDocumentIterator always uses source context form the 1st lookupServicesProvider
- Fix for: No Authorizer found for fqcategory ..." should be logged in the AlwaysRejectingAuthorizer if performAuthorization has to be done
- Fix for: PDF cannot be downloaded in the preview
- Fix for: Reconfigure Script is not robust enough if mesmaster starts too slowly
- Fix for: Reverse proxy timeouts are too low
- Fix for: SharePoint: With delta crawling, document changes are missed due to the batch size of ignored SystemUpdates
- Fix for: SharePoint: Crawler did stop working (Java process stuck)
- Fix for: SharePoint: Delta crawling not finishing (looping on same sites)
- Fix for: SharePoint Online Principal Cache High CPU and memory consumption. Add setting to skip check if cache is empty
- Fix for: Sitecore Connector: Error when expanding FieldValues on certain items
- Fix for: Sitecore Connector: Set Fallback for managed Metadata Attributes
- Fix for: Translations in the client are not complete
- Fix for: UPDATE_IN_PLACE updates the document even if there were no changes
- Fix for: ValueError for DateFilterConstraint
- Fix for: Web Connector: OAuth grant_type=password_credentials not working (401)