
Sure, you can handle it. But should you?
Let our experts manage the tech maintenance while you focus on your business.
Let our experts manage the tech maintenance while you focus on your business.
Whitepaper
Administration of Insight Services for Retrieval Augmented Generation
Motivation and overview
Retrieval Augmented Generation (RAG) is a natural language processing technique that combines the strengths of query-based and generative artificial intelligence (AI) models. In a RAG-based AI system, a query model is used to find relevant information from existing data sources. Meanwhile the generative model takes the queried information, synthesises all the data and transforms it into a coherent, contextual response.
Configuration of a Large Language Model (LLM)
Initial Setup
You can find the instructions on how to set up an LLM in Configuration - InSpire AI Chat and Insight Services for Retrieval Augmented Generation.
Integration of an LLM
To configure a Large Language Model (LLM) for your pipelines, switch in the menu item “RAG” to the area "LLMs".

Click on "Add" and select the respective LLM to configure it. There are currently four LLMs available for Integration:

The following settings can be configured for the respective LLM.
InSpire LLM
Connection
Setting | Description |
URL (required) | Defines the URL of the LLM Endpoint. You receive the URL from sales@mindbreeze.com. For more information, see Configuration - InSpire AI Chat and Insight Services for Retrieval Augmented Generation - Preparation. |
For the areas “General”, “Prompt” and “Test”, please see the chapter General Parts of the LLM Settings.
OpenAI
When creating an OpenAI LLM a Dialog opens that refers to the Data Privacy Disclaimer. To continue you have to accept this Disclaimer.
Attention: When using the OpenAI API, chat inputs from the user and information indexed by your organization are transmitted to the respective endpoints via prompts. The handling of the transmitted information is governed by the data protection regulations of the respective AI provider. Mindbreeze is not responsible for the further data processing. The AI provider is neither a vicarious agent nor a subcontractor of Mindbreeze. We would like to point out that, according to current assessments, the lawful use of AI services is not guaranteed (precautionary note pursuant to GDPR Art. 28 para. 3 sentence 3). For further information and risks, please refer to the relevant privacy policies of the respective AI provider.
For more Information visit https://openai.com/enterprise-privacy .
By confirming the checkbox, you as the Data Controller instruct Mindbreeze to carry out this transmission nevertheless and acknowledge the note as outlined above.
Connection
Description | |
API Key (required) | Defines the API key. You will receive the API key from Open AI when you use a model. |
Model (required) | The name of the OpenAI LLM to be used. |
Use custom LLM URL | If this setting is activated, you can specify an individual URL to an LLM in the following setting “URL”. This enables the use of an LLM that is not hosted directly by OpenAI but uses the OpenAI interface. Default setting: Deactivated |
URL | Here you can enter an individual URL to an LLM that is to use the OpenAI interface. |
With “Test Connection” you can check if the given values are valid and if a connection can be established.
For the areas “General”, “Prompt” and “Test”, please see the chapter General Parts of the LLM Settings.
Azure OpenAI
When creating an Azure OpenAI LLM a Dialog opens that refers to the Data Privacy Disclaimer. To continue you have to accept this Disclaimer.
Attention: When using the Azure OpenAI API, chat inputs from the user and information indexed by your organization are transmitted to the respective endpoints via prompts. The handling of the transmitted information is governed by the data protection regulations of the respective AI provider. Mindbreeze is not responsible for the further data processing. The AI provider is neither a vicarious agent nor a subcontractor of Mindbreeze. We would like to point out that, according to current assessments, the lawful use of AI services is not guaranteed (precautionary note pursuant to GDPR Art. 28 para. 3 sentence 3). For further information and risks, please refer to the relevant privacy policies of the respective AI provider.
For more Information visit https://learn.microsoft.com/en-us/legal/cognitive-services/openai/data-privacy
By confirming the checkbox, you as the Data Controller instruct Mindbreeze to carry out this transmission nevertheless and acknowledge the note as outlined above.
Connection
Description | |
URL (required) | Defines the URL of the LLM Endpoint. You receive the URL from Microsoft Azure when you use a model. |
API Key (required) | Defines the API key. You receive the API key from Microsoft Azure when you use a model. |
Model
Description | |
Azure Deployment (required) | Defines the name of the Microsoft Azure deployment. For more information, see Deployment Types. |
For the areas “General”, “Prompt” and “Test”, please see the chapter General Parts of the LLM Settings.
InSpire LLM (TGI)
The InSpire LLM (TGI) uses the Text Generation Inference (TGI for short) interface from Huggingface.
Connection
Setting | Description |
URL (required) | Defines the URL of the LLM Endpoint. You receive the URL from sales@mindbreeze.com. For more information, see Configuration - InSpire AI Chat and Insight Services for Retrieval Augmented Generation - Preparation. |
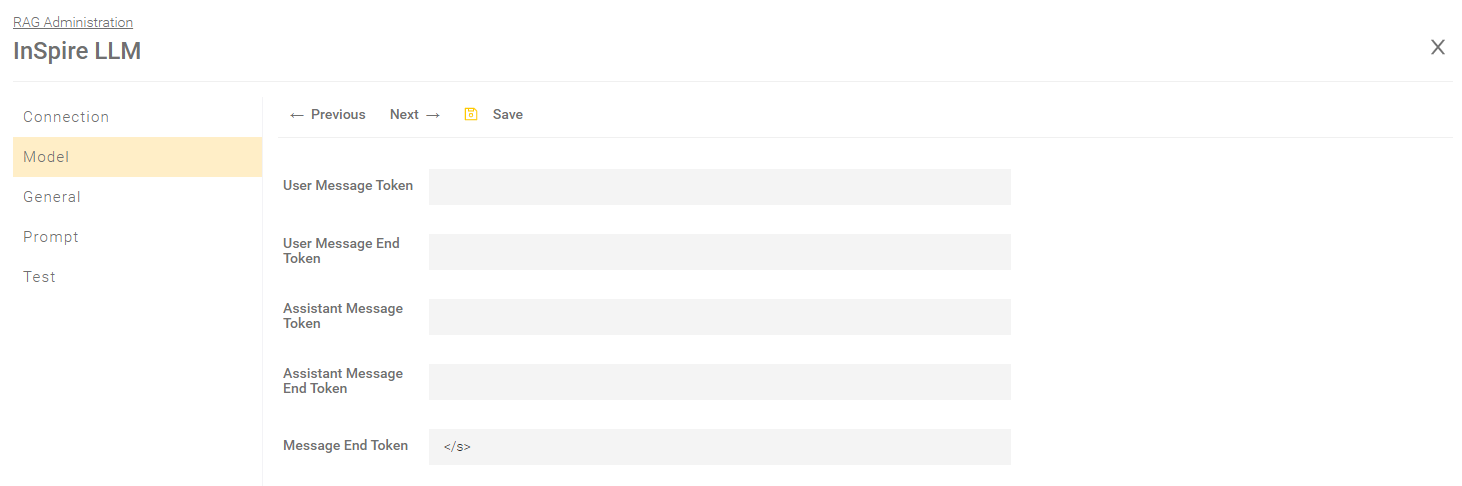
Model
Setting | Description |
User Message Token User Message End Token Assistant Message Token Assistant Message End Token Message End Token | To be filled in depending on the model, whereby the settings may vary depending on the model. Default: Only the Message End Token is used with the value “</s>” |
For the areas “General”, “Prompt” and “Test”, please see the chapter General Parts of the LLM Settings.
General Parts of the LLM Settings
General
Description | |
Name | The name for the Large Language Model. |
LLM Key | Defines the key with which the LLM can be uniquely identified. The LLM Key can be used as a model in the OpenAI proxy. For more information, see Configuration - InSpire AI Chat and Insight Services for Retrieval Augmented Generation - Configuration of the OpenAI proxy. |
Max Answer Length (Tokens) | Limits the amount of tokens generated (1 token ~ 1 word). By limiting the answer length, long responses can be avoided and the load on the LLM endpoint can be reduced. A value of “0” means that the tokens or the answer are not limited. Attention: Make sure that the length of the prompt and the maximum answer length are not greater than the length of the model's context. |
Overwrite Randomness (Temperature) | If activated, the default temperature of the LLM will be overwritten with the configured “Randomness of Output”. For more information about the randomness or temperature of an answer, see the description of the setting “Randomness of Output (Temperature)”. |
Randomness of Output (Temperature) | Controls the randomness or creativity of the generated answer (0 - 100%). Configuring the temperature affects the probability distribution that is created during the generation of the next token. Changing the probability distribution affects the model as follows:
|
Overwrite Repetition Penalty | If this setting is activated, the value from the setting "Repetition Penalty" is taken over as the LLM parameter. For more information on repetition penalties, see the description of the setting “Repetition Penalty”. |
Repetition Penalty | This parameter penalizes tokens based on how frequently they occur in the text (including the input prompt). A token that has already appeared multiple times is penalized more heavily than a token that has appeared only one time or never. The penalty consists of reducing the probability that a token that has already occurred in the text before will be generated again. The valid range of the repetition penalty depends on the used LLM. |
Overwrite Top P | If this setting is activated, the value from the setting "Top P" is taken over as the LLM parameter. For more information about Top P, see the description of the setting “Top P”. |
Top P | Top-P sampling can be used to control the diversity and randomness of generated text. The next token is selected from a “nucleus” of Top-P tokens. This nucleus is put together in one of two ways:
The specified Top P value determines the diversity of the output as follows:
The value entered for Top P must be greater than 0 but less than 1. |
Stop Sequences | If stop sequences are defined, the model ends the generation of a text immediately as soon as such a sequence has been generated by the model. Even if the output length has not yet reached the specified token limit, the text generation is terminated. |
Prompt
Description | |
Preprompt | A preprompt is used to apply specific roles, intents and limitations to each subsequent prompt of a Model. Example: I want you to act like a member of the Mindbreeze sales team. I will ask you questions and you will answer my questions in detail. Formulate your answers enthusiastically and excitingly, but stick to the facts. Particularly highlight the advantages of various Mindbreeze features. |
Prompt Examples | See the chapter Prompt Examples. |
Prompt Examples
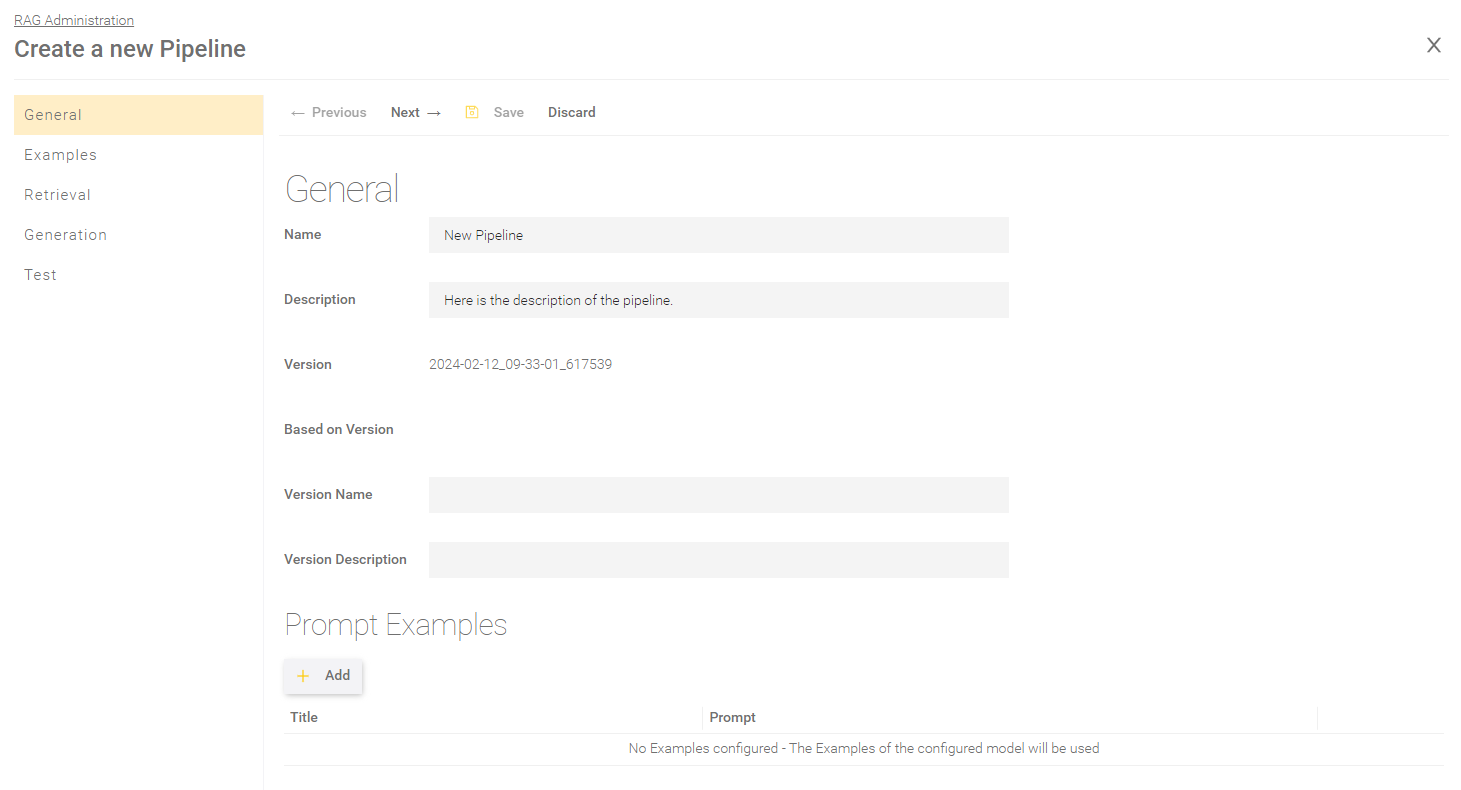
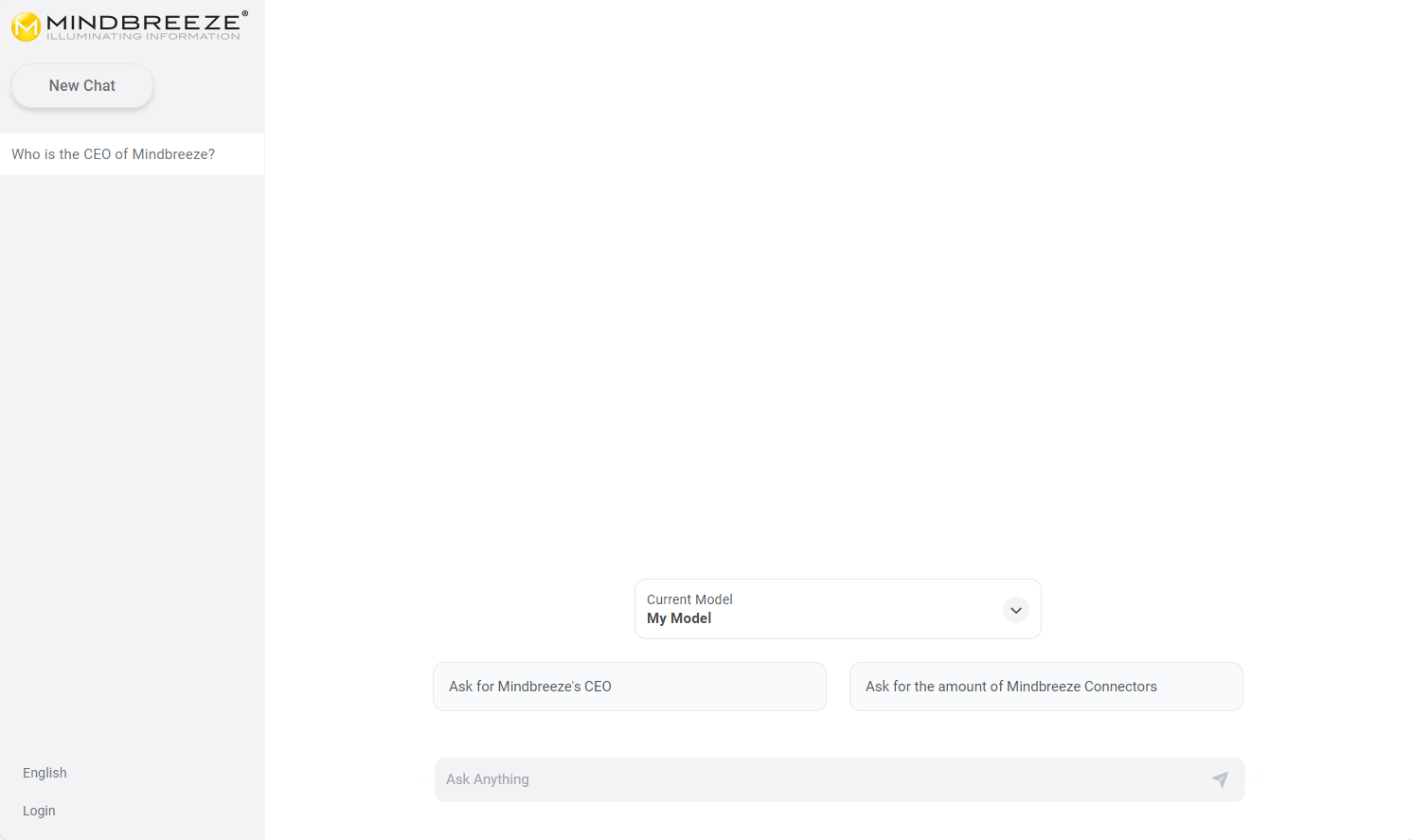
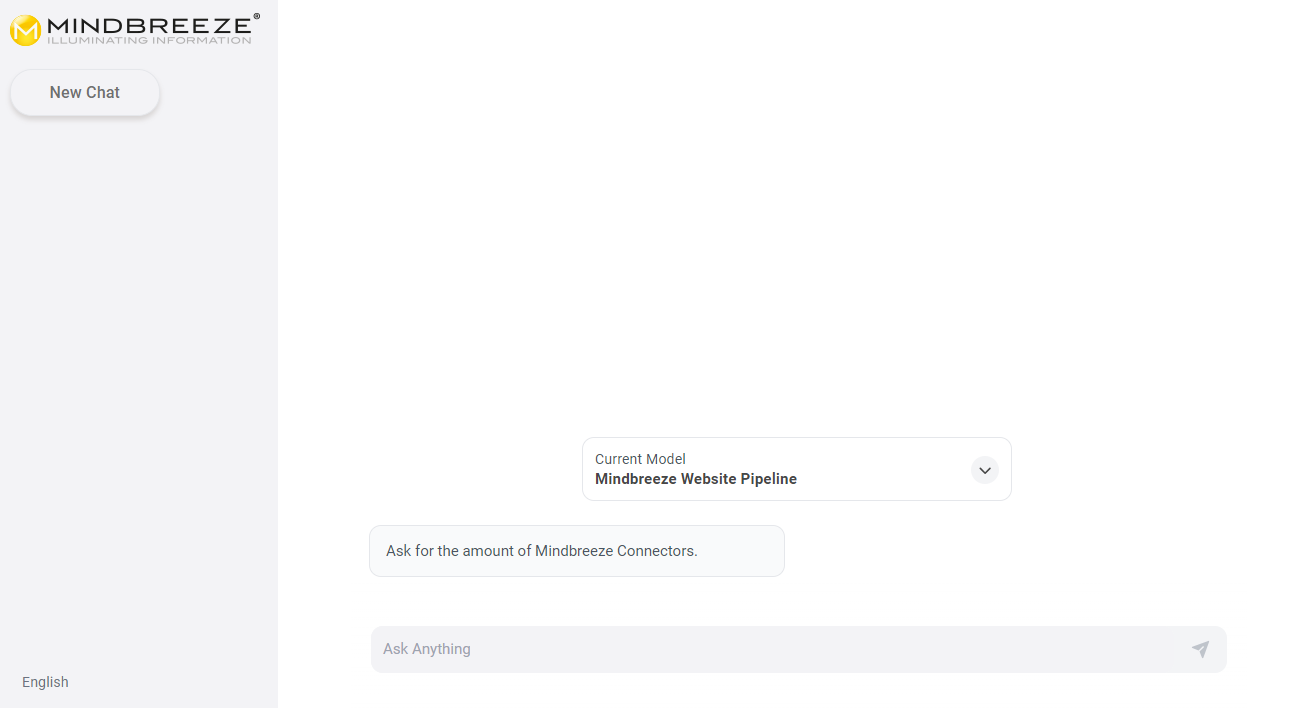
These examples are displayed in the Mindbreeze InSpire AI Chat as sample questions. Accordingly, frequently asked questions are suitable as prompt examples. By clicking on a prompt example, this question is automatically entered in the Mindbreeze InSpire AI Chat. A prompt example can be created by clicking on "Add" and filling in the following fields:
Setting | Description | Example |
Title | The title of the prompt example. This text is displayed in the Mindbreeze InSpire AI Chat. | Ask for the amount of Mindbreeze Connectors. |
Prompt | The question or instruction entered in the Mindbreeze InSpire AI Chat. | How many connectors does Mindbreeze provide? |
Click on "Save" to save the prompt example. Any number of prompt examples can be created. Once all prompt examples have been created, save the entire LLM to save the changes. Now you should see the prompt examples in the AI chat:
Data Privacy
If you are using an InSpire LLM, this section is not available. If you are using an LLM from OpenAI or Azure OpenAI, you can read the data privacy disclaimer here.
Test
On this page the configuration can be tested. If LLM parameters have been defined, these will be summarised here again. Keep in mind that the generated text is not based on retrieved documents.
After testing the LLM Settings click on “Save” to save the LLM.
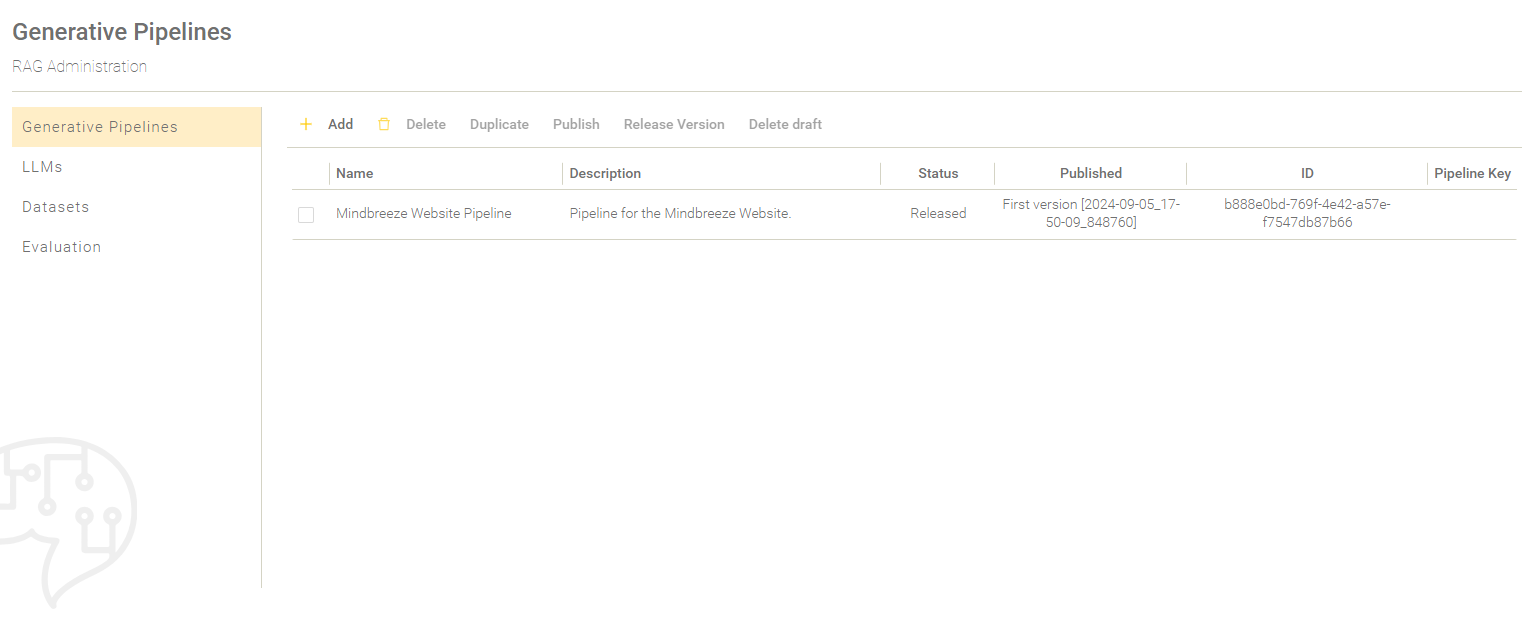
Creation of a pipeline
To create a pipeline, switch to the section "Generative Pipelines". Click on "Add" to start creating a new pipeline.
The creation of a pipeline is divided into five sections:
- General
- Examples
- Retrieval
- Generation
- Test
The individual sections are described in more detail in the following chapters.
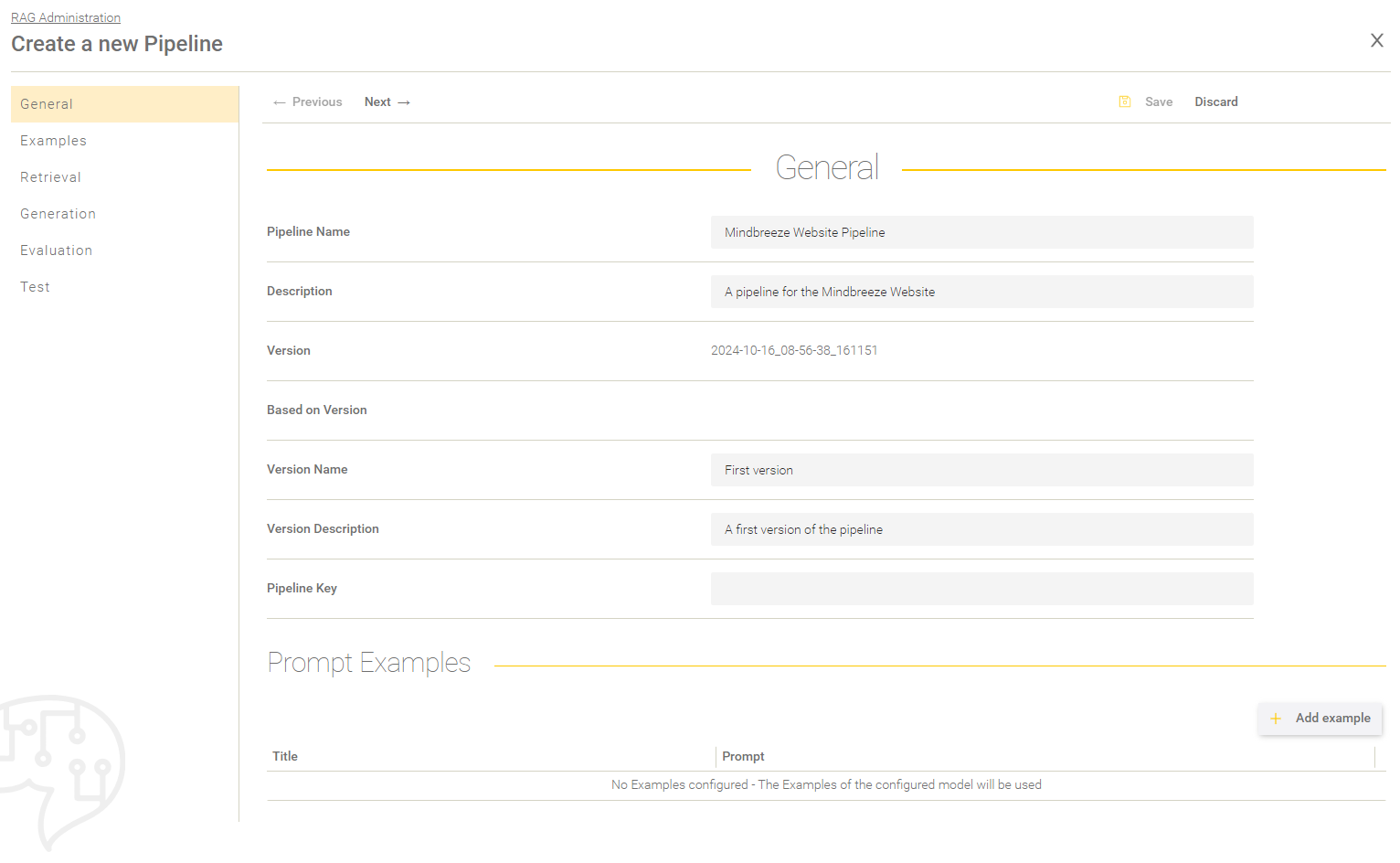
General
In the section “General”, the following general settings can be set:

Setting | Description |
Pipeline Name | Name that is displayed in the Mindbreeze InSpire AI Chat. |
Description | Description of the pipeline. |
Version | A generated Version ID. |
Based on Version | The previous version, on which this version is based. |
Version Name | When a pipeline is released, a version name must be specified. The version name is not displayed in the Mindbreeze InSpire AI Chat and is used to track changes to the pipeline. The version name should contain a short summary of the changes. |
Version Description | A more detailed description of the changes in the pipeline. |
Pipeline Key | Key to a pipeline (see Creation of datasets). |
In the section "Prompt Examples" example questions can be added to a pipeline that are displayed in the Mindbreeze InSpire AI Chat. If no example questions are defined in the pipeline, the example questions are taken from the LLM. If no example questions are defined in the LLM either, no example questions are displayed in the Mindbreeze InSpire AI Chat. For more information on prompt examples, see the chapter Creation of Prompt Examples.
Once the necessary settings have been made, you can continue to the next section by clicking "Next" or by clicking on the desired section in the navigation bar on the left.
Retrieval
The retrieval part of the RAG can be configured in the section “Retrieval”. Only indices that have the feature "Semantic Sentence Similarity Search" enabled can provide answers for generation in the AI Chat. The following settings are available:
Setting | Description |
Search Service | The client service to be used for the search. |
In the section "Constraints", the pipeline can be refined and customized to the respective requirements.
Setting | Description |
Allow Search Request Template Override | Only relevant if the API is used directly. Allows the values of the search query template to be overwritten via API requests. For more information, see api.chat.v1beta.generate Interface Description. |
Search Constraint | When searching using the search service, the value in this field (if any) is also used as a condition in the search. |
Include Data Source | If one or more data sources are included, all other data sources are automatically excluded. |
Exclude Data Source | If one or more data sources are excluded, all other data sources are automatically included. |
The section "Effective Data sources" provides an overview of the effective data sources of the selected search service.
Advanced Settings
Setting | Description |
Skip SSL Certificate Verification | If this is enabled, the verification of the SSL certificate will not be performed. Enabling this setting is recommended if an SSL certificate exists. |
Only Process Content | If this property is set, only responses from the content metadata will be used. Otherwise, responses from all metadata will be processed. |
Maximum Answer Count | The first n search results are processed and used for the prompt. Hint: When n = 0 and the prompt logging is disabled in app.telemetry, then the columns for the answers will have no header for the details of the answer in the CSV Logging. |
Minimal Answer Score [0-1] | Only answers are processed, which have a greater answer score. Hint: If the score in the pipeline is 0, the minimum score (if set) from the similarity search settings of the Client Service is used. |
Answer Size | Defines how long the answer should be that is displayed in the prompt template. The options "Standard" and "Large" are available. The option “Standard” depends on the “Sentence Transformation Text Segmentation” configuration. The option “Large” is a large block of text. For more information, see Documentation - Mindbreeze InSpire - Sentence Transformation. Default value: Standard. |
Strip Sentence Punctuation Marks | If this setting is activated, punctuation marks are removed from the user input before it is processed by the Similarity Search. The following punctuation marks are removed::
Default value: Activated Hint: Disabling this setting may potentially find better or more answers. This setting is activated by default to remain backwards compatible in case a deterioration in the quality of the answers is recognisable due to the omission of the punctuation marks. |
Use formatted Answers | Per default this setting is not active. The answers will be processed as plain text. If this setting is activated, HTML formatting is added to the received answers to reproduce the structure of the original document. For more information, see api.v2.search Interface Description - formatted_answers. |
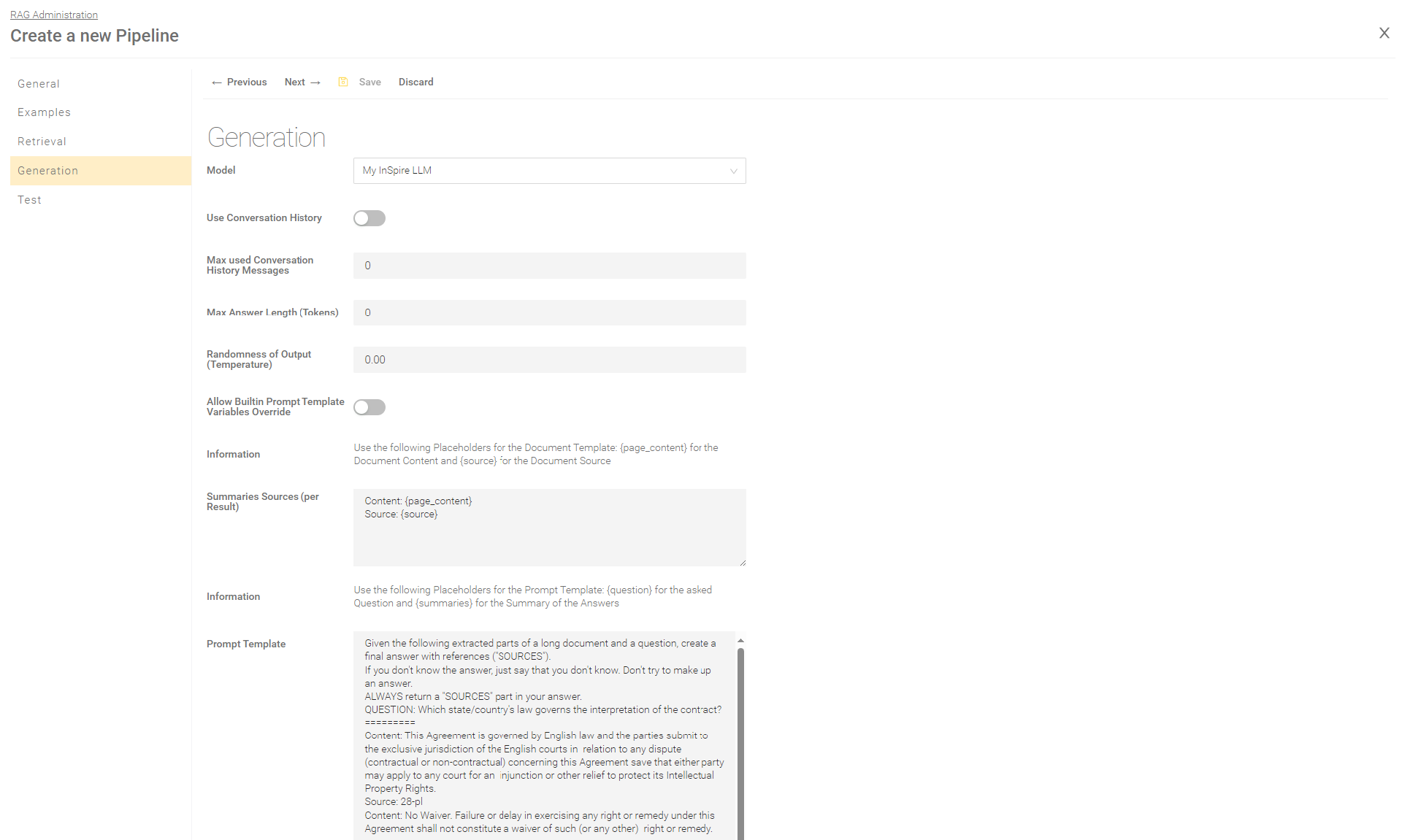
Generation
In the section “Generation”, you can configure the prompt generation, select the LLM and the prompt templates that are filled with the search results and then sent to the configured LLM.
Model
Select the LLM you have created in the setting "Model".

Setting | Description |
Model | Shows which LLM is selected. |
Advanced Settings
Setting | Description |
Max Answer Length (Tokens) | This setting overwrites the setting “Max Answer Length (Tokens)” of the LLM, if the value is greater than 0. By limiting the answer length, long responses can be avoided and the load on the LLM endpoint can be reduced. |
Randomness of Output (Temperature) | This setting overwrites the setting “Randomness of Output (Temperature)” of the LLM, if the value is greater than 0. For more information about the randomness or temperature of an answer, see the description of the setting “Randomness of Output (Temperature)” in the chapter General Parts of the LLM Settings. |
Use Conversation History | If this setting is activated, the content from the previous conversations is used for generating the next answer. This can potentially lead to better answers, for example in follow-up questions. |
Max used Conversation History Message | This setting is only effective if "Use Conversation History" is active. Limits the number of chat history messages that are used for generation. If the value is "0", all chat history messages are used. This setting ensures that the requests to the LLM do not become too large in the case of longer chats. Recommended values: 1 - 5. |
Allow Builtin Prompt Template Variables Override | Only relevant if the API is used directly. Allows the system prompt template variables ({question}, {summaries}) to be overwritten. For more information, see api.chat.v1beta.generate Interface Description. |
Prompts
The definition of prompts can be done in two ways:
- in a structured form
- as a pure text template
With the Mindbreeze InSpire 25.2 Release, the structured format is automatically applied to newly created pipelines. The text format is retained for already existing pipelines, although the format can be changed in the advanced settings.
Note: The use of the structured form for prompts is recommended.
Structured prompt format

The following settings can be made in “Chat Template” and “Chat Template (no Retrieval Results)”:
Setting | Description |
System Message Template | The system message defines the behaviour (personality, role) in the prompt, specifies restrictions and rules and provides background information for the LLM. The system message acts as a kind of „job description“ for the LLM. |
User Message Template | The user message defines the specific instructions, tasks or questions for the LLM. |
Prompt in text format
Advanced Settings
Setting | Description |
Use Chat Prompt Format | This setting can be used to convert an existing prompt in text format into a prompt in structured format. Attention: Prompts will not be converted when the format is changed. It is therefore recommended to save the prompts before changing the format. Default setting:
|
Prompt Template for generating the conversation title | |
Prompt Template for generating the conversation title | This prompt is sent to the LLM to generate the title of a conversation in the AI Chat. The following placeholder can be inserted:
|
Display Retrieved Sources | |
Display Retrieved Sources | If this setting is activated the last retrieved sources according to the setting “Max Retrieved Source Count” are attached at the end of the generated answer text. By default, the setting “Prompt Template” instructs the model to provide the relevant sources, independent of this setting. When this setting is active, it is recommended to adjust the setting “Prompt Template” to avoid duplicate sources in the generated answer. |
Retrieved Source Template | The Template defines how each source should be displayed. The following placeholder must be inserted: {source} for the source. |
Retrieved Sources Template | The template displays the retrieved source template summaries. The following placeholder must be inserted:
|
Max Retrieved Source Count | This setting defines how many retrieved sources should be displayed. |
Summary Settings for Answers
Setting | Description |
Information | This is a note for the setting “Summaries Sources (per Result)”. |
Summaries Sources (per Result) | The template which processes the received answers into a text for the prompt. Depending on the desired information from the answer, the following placeholders can be inserted:
Additional metadata for the individual documents can also be requested, e.g. {language}. If a metadata does not exist for the document, the placeholder is replaced with an empty value. |
Advanced Settings
Setting | Description | ||||
Summary Sources Separation Text | With this text the summary source templates from each result were concatenated. This setting can help optimizing the summaries part of the prompt. Default value: \n\n | ||||
Summary Normalization | With this setting the retrieved answer texts ({summaries}) can be normalized or edited before they are inserted in the prompt. By default the answers are normalized with the following setting
It is possible to set multiple entries for normalization. If multiple entries are made they will be processed in the given order. If a pattern is invalid or not found in the text, the entry will be ignored while the previous and following entries will be applied. |
Evaluation
In this section, settings can be made, for example, for a pipeline that was explicitly created for dataset refinement. In addition, it is also possible to generate queries and restrictions instead of answers for a dataset.
Setting | Description |
Target Property Name | Defines the selected property. The following options are available:
Default: Answer. |
Output Format | Defines the format in which the target properties are to be output. Default: Text |
Split Expression (when „Output Format“ is set to „Text“) | If "Text" has been selected as the output format, the generated text can be split using an expression (text or regular expression). |
JSON Path (when „Output Format“ is set to „JSON“) | Individual JSON entries can be parsed using JSON Path (https://goessner.net/articles/JsonPath/index.html#e2). This is useful, for example, if you have a dataset containing queries and constraints in a JSON format. With the output format “JSON Path”, you can define a path to extract the queries and constraints from the dataset. Example: { ‘query’: ‘This is my example query’ } The JSON Path to be configured is then “query”. |
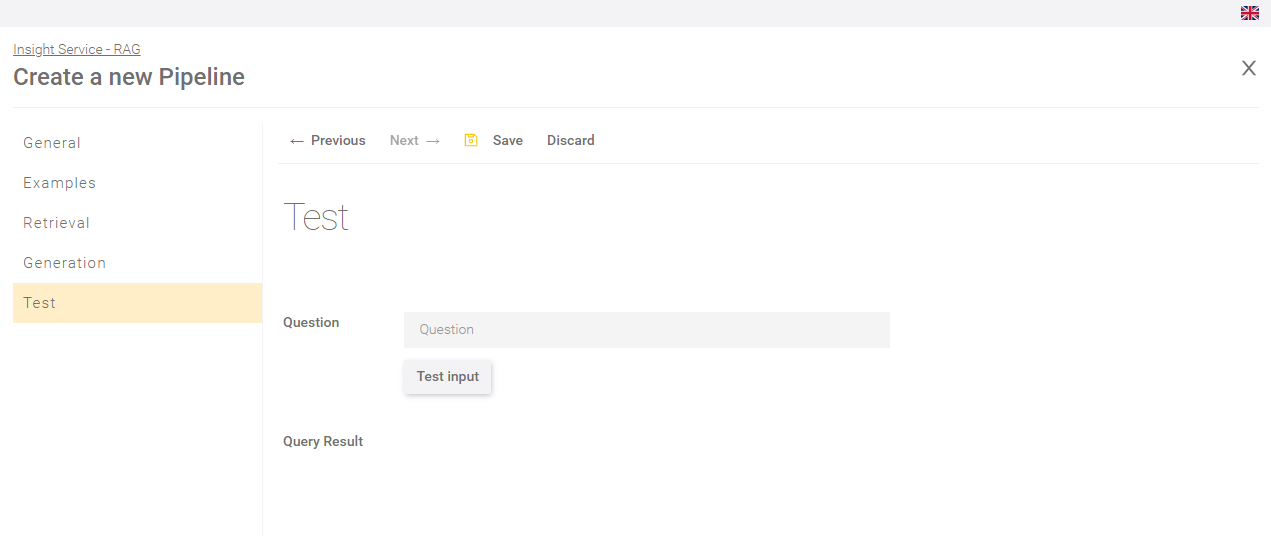
Test
In the "Test" section, you can test the pipeline settings and check whether the settings you have made fulfil the requirements.
Publication of the created pipeline
Pipeline status
A pipeline can have several versions and each of which has a status:
- Draft: This pipeline currently has a draft version. There can only be one draft version per pipeline. The draft version can be edited at any time.
- Released: A released version can no longer be changed retrospectively. If changes are subsequently made to a released version, a new draft version is automatically created if one does not yet exist.
- Published: Only one released version can be published per pipeline. It is also possible to publish an earlier released version. So, the last released version does not necessarily have to be published. Published versions can also be withdrawn by removing the publication.
Release of the pipeline version
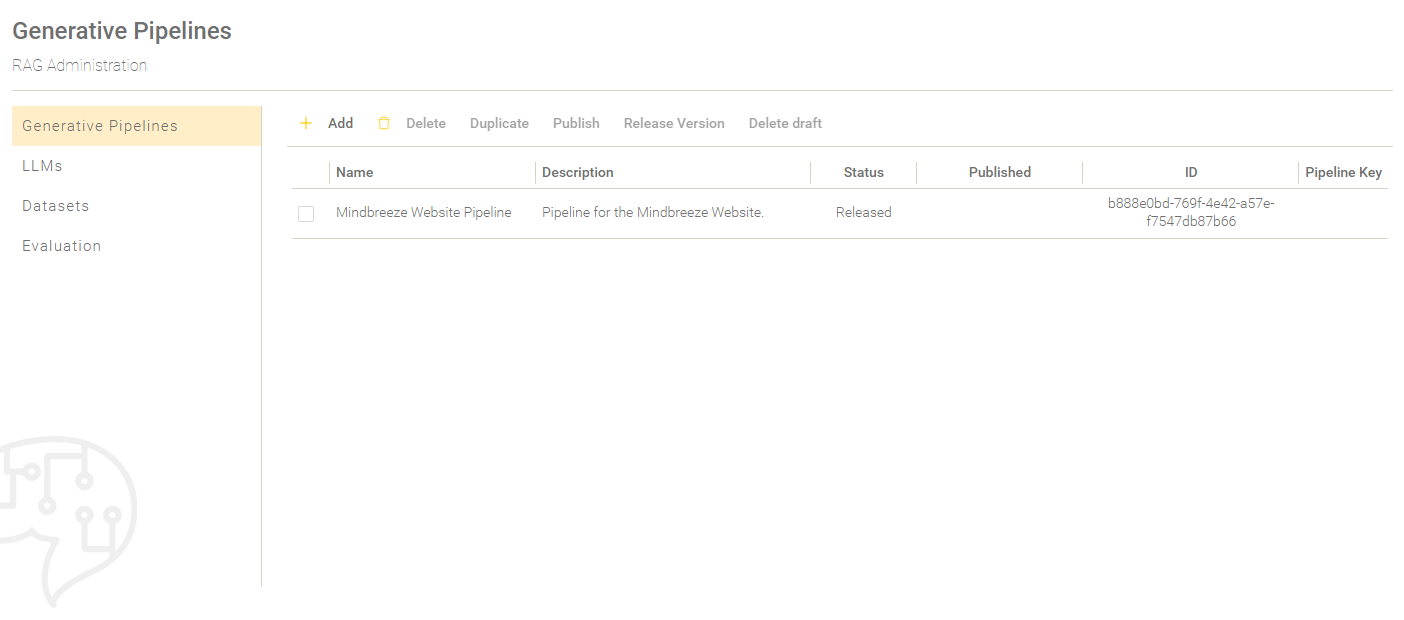
After a pipeline has been created or edited, there is a draft version for it. To finalise the draft version, it must be released. To do this, select the pipeline you created by placing a check mark next to the pipeline name. Enter a version name and optionally a version description. Then click on "Release Version".
The pipeline status is now “Released”.

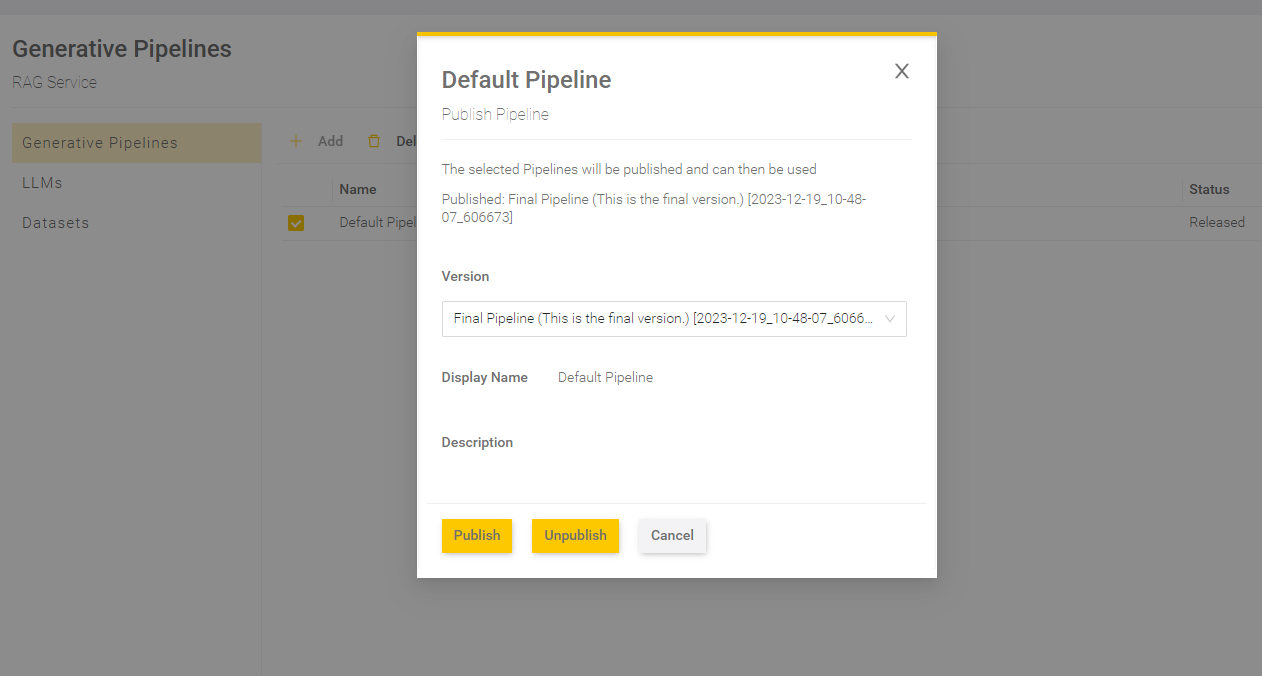
Publication of the pipeline version
To use a pipeline in Mindbreeze InSpire AI Chat, it is necessary to publish a version. To do this, select a pipeline with the status “Released” by placing a check mark next to the pipeline name. Then, click on "Publish". Only pipeline versions with the status “Released” can be published.
In the dialogue box, select a pipeline version that you want to publish and check the display name and description. If a version of the pipeline has already been published, you will find information on the published version of the pipeline above the selection field.
Then click "Publish" to publish the selected version.

After publishing, the version number of the published version should appear in the column "Published".
It is now possible to select and use the created pipeline in the Mindbreeze InSpire AI Chat.
Remove publication
Select a pipeline with a version number in the column “Published” by placing a check mark next to the pipeline name. Then click on "Publish". You will find information about the published version in the dialogue box. Then click on "Unpublish".

The pipeline should no longer have a version number for "Published" in the overview. The pipeline is now no longer available in the Mindbreeze InSpire AI Chat.

Producer Consumer Setup
If you have a Producer Consumer Setup, the RAG configuration can be synchronized to all Nodes by clicking “Sync to consumer”.
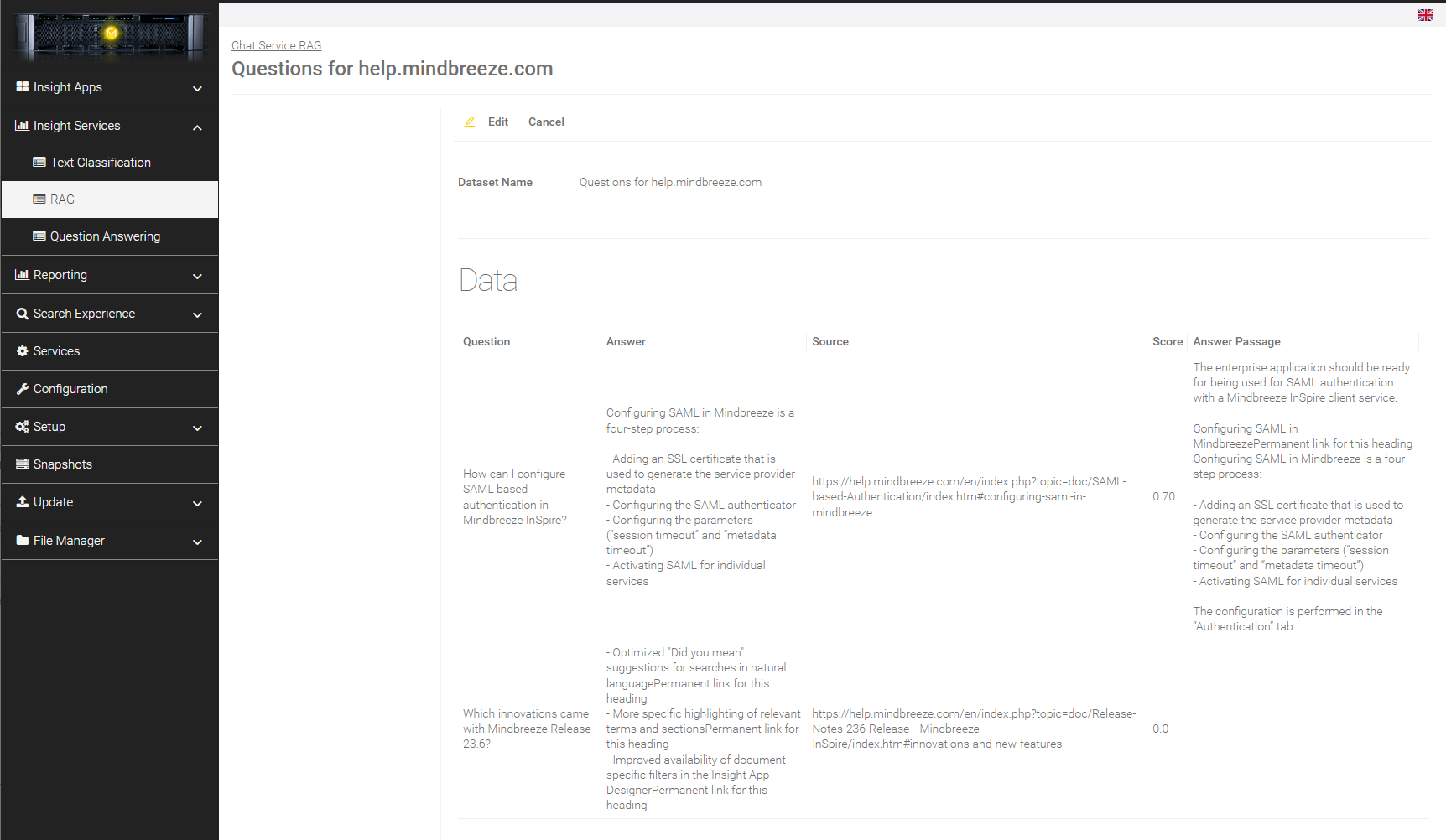
Creation of datasets
In this section, datasets can be created which are necessary for evaluating pipelines.
Creation of a new dataset
Adding data
Click on "Create new dataset" and give the dataset a name under "Name of dataset". Then add data to a dataset by clicking on "Add" in the section “Data”.

The following fields can be filled in:
Column name | Description |
Question | The question that is sent. |
Answer | The expected answer to the question. |
Queries | Each query must be written in a separate line. |
Query Constraints | Restrictions that are applied to the query during retrieval. Each restriction must be written in a new line. |
Pipeline Key | The pipeline key can be defined by the user independently. If a pipeline key is defined, you can select it and the question will be answered exclusively with the published version of the pipeline that is assigned to the key. |
Remark | Remark on the questions. |
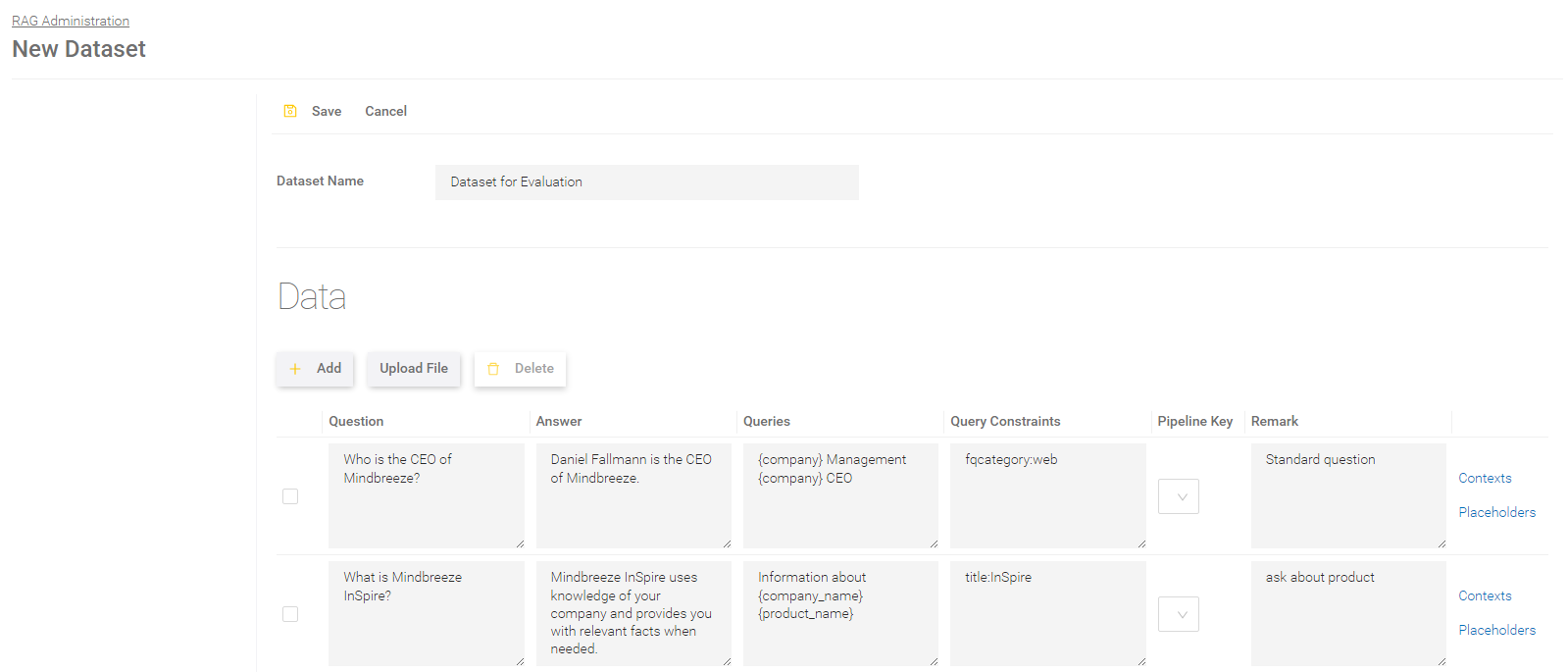
Contexts
The expected answers can be entered for each question in the contexts.
Field | Beschreibung |
Text | Defines the expected text, consisting of an answer and surrounding context. |
Source | Defines the expected source. |
Save the changes in the contexts by clicking on "Save" in the window below.
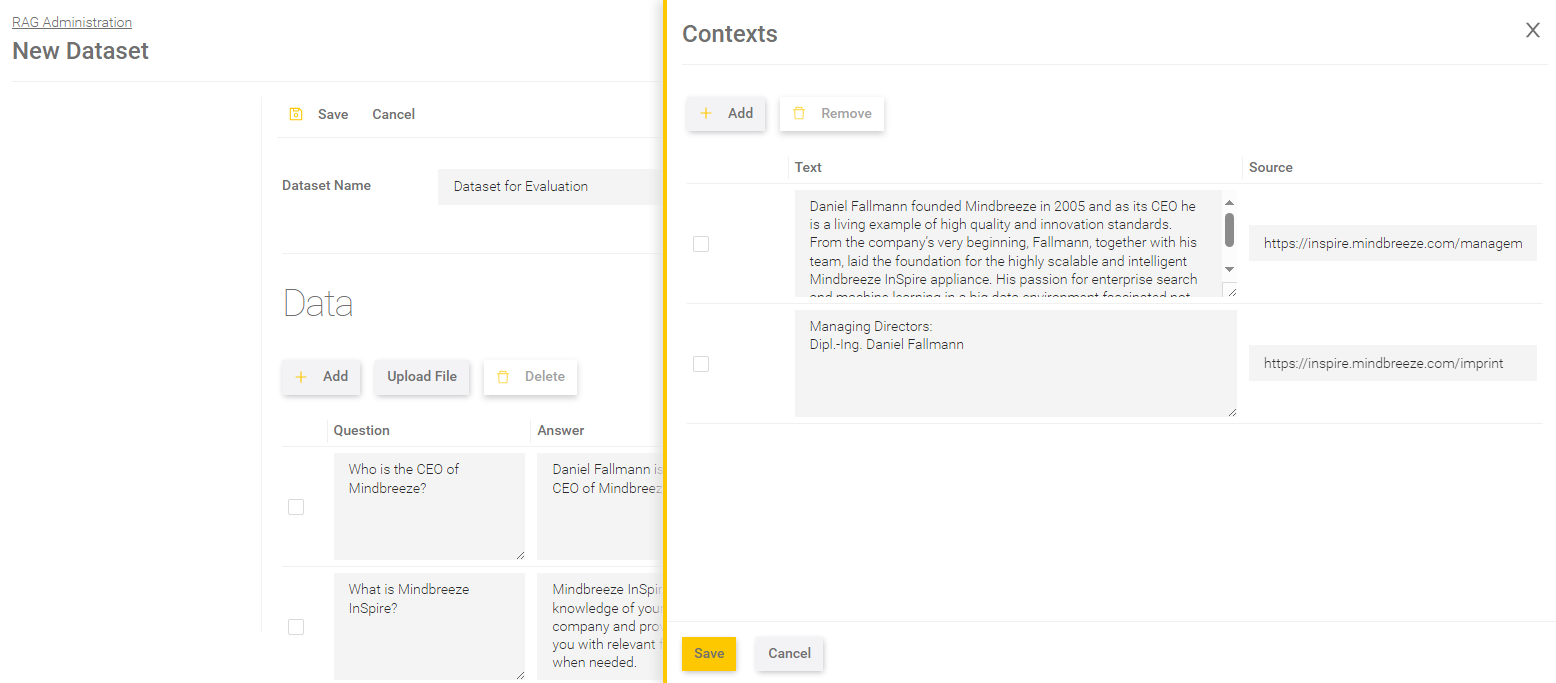
Placeholders
Placeholders can be defined for each question, where the value of the placeholder is to be inserted in the prompt. The comparison is carried out using the key.
Field | Description |
Key | The key is the ID defined in the prompt with curly brackets. For example, if the prompt says „{xyz}“, then the key is „xyz“. |
Value | The value can be defined as you like. For example, you can define the value „Mindbreeze“ for the key „company“. Hint: If a key is used again as a value (such as „{department}“), the value will no longer be changed. |
Save the changes in the placeholders by clicking on "Save" at the bottom of the window.
Finally, click on "Save" to save the data set.
Uploading a file
In addition to the manual creation of data, a file can also be uploaded. To do this, click on "Upload file". Use the setting “Already existing Entries” to specify whether the data from the file should be added to or overwrite the existing entries.
Please note that only one file can be uploaded. The file types JSON and CSV are compatible.
Once the file has been successfully loaded, click on "Add". Then save the dataset.
JSON Upload
The following values can be entered for each question:
Value | Description | ||||||
question | Defines the question. | ||||||
answer | Defines the expected answer. | ||||||
queries | List of queries for the retrieval. This allows questions of a dataset to be provided with additional information to support the retrieval process. Example: A dataset has prompts instead of questions. To support the retrieval process, suitable questions can be added as queries to the respective prompts:
| ||||||
query_constraints | List of query conditions. This can be used to define constraints for the retrieval process, such as the use of certain file formats or metadata. Example: the retrieval process should only process PDF documents for answering the questions:
| ||||||
pipeline_key | Defines the key of a pipeline. A pipeline key can be defined by the user and then selected. This allows, for example, key figures to be calculated from several pipelines by assigning questions for specific pipelines using pipeline keys. | ||||||
remark | A note with remarks. | ||||||
contexts | Expected contexts (see chapter Contexts). Always contains a text and a source element:
| ||||||
prompt_placeholders | Directory of keys for terms. By defining prompt_placeholders, the prompt sent to the LLM when generating the response can be customised and refined. A prompt_placeholder consists of a key and a value, which can be defined as required. The {key} placeholder in the prompt is then replaced by the user-defined key-value before the prompt is sent to the LLM. This makes it possible to modify the prompt for each question, for example for evaluation. Attention: Defined prompt_placeholders must not be used in the question or in the queries, as these are applied in the retrieval process, where the prompt_placeholders are not exchanged. |
Example of a JSON File:
{
"data": [
{
"question": "How can I configure SAML based Authentication in Mindbreeze InSpire?",
"answer": "Configuring SAML in Mindbreeze InSpire is a four-step Process.",
"remark": "This is a Remark for this Question",
"contexts": [
{
"text": "Configuring SAML in Mindbreeze is a four-step process: 1. Adding an SSL certificate that is used to generate the service provider metadata 2. Configuring the SAML authenticator 3. Configuring the parameter 4. Activating SAML for individual services",
"source": "https://help.mindbreeze.com/en/index.php?topic=doc/SAML-based-Authentication/index.html"
}
],
"pipeline_key": "special-pipeline",
"query_constraints": [
"extension:pdf",
"fqcategory:Web"
],
"queries": [
"What are Authentication Possibilities on {product}?",
"What is {authentication}?"
],
"promptPlaceholders": {
"authentication": "SAML",
"product": "Mindbreeze InSpire"
}
},
{
"question": "Another question"
}
]
}
CSV Upload
For the CSV file, make sure that the separator is a semicolon and that the file was saved in UTF-8 format, as the areas may not be read correctly or there may be errors when reading.
The file must have a header.
Value | Description |
question | Question |
answer | Expected Answer |
remark | Remark |
queries | List of queries for the retrieval. The individual queries must each be separated by a line break. |
queryconstraints | List of conditions for the query for the retrieval. The individual conditions must each be separated by a line break. |
context / source | The text and source of a context must be specified in direct succession with "context" and "source". If several contexts are required, a "context" and a "source" field must be created for each context. |
pipelinename | Key of a pipeline. |
pp_<key> | This setting is only relevant if you have specified your own placeholders in the prompt template. Each placeholder needs its own field starting with "pp_" and the placeholder key. |
Example of a CSV File:
question;answer;remark;queries;queryconstraints;context;source;context;source;pipelinename;pp_product_name;pp_authentication
How can I configure SAML based Authentication in Mindbreeze InSpire?; Configuring SAML in Mindbreeze InSpire is a four-step Process.;This is a Remark for this Question;"What are Authentication Possibilities on {product}?
What is {authentication}?";"extension:pdf
fqcategory:Web";Configuring SAML in Mindbreeze is a four-step process: 1. Adding an SSL certificate that is used to generate the service provider metadata 2. Configuring the SAML authenticator 3. Configuring the parameter 4. Activating SAML for individual services;"https://help.mindbreeze.com/en/index.php?topic=doc/SAML-based-Authentication/index.html";This is a second Context.;another_source.pdf; special_pipeline;Mindbreeze InSpire;SAML
Export of datasets
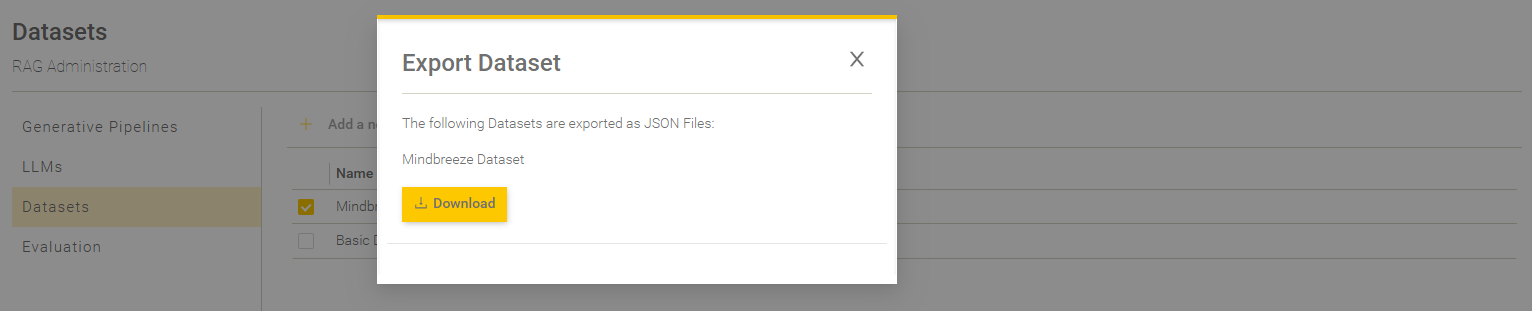
Data sets can be exported as a JSON or CSV file.
To export one or more datasets, the respective datasets must be selected. Tick the box next to the respective data sets to select them. If at least one data set is selected, you can select the file format in the drop-down menu under ‘Export’.

Click on the desired file format and you will then receive a pop-up window containing the download link for the exported data set.

If several datasets are selected at the same time, they are packaged in the selected format and exported in a ZIP file.
Hint: If no data set is selected, both file format options are greyed out and cannot be selected.
Evaluation of a pipeline
To test the effectiveness of a pipeline, it is possible to evaluate pipelines in this respect.
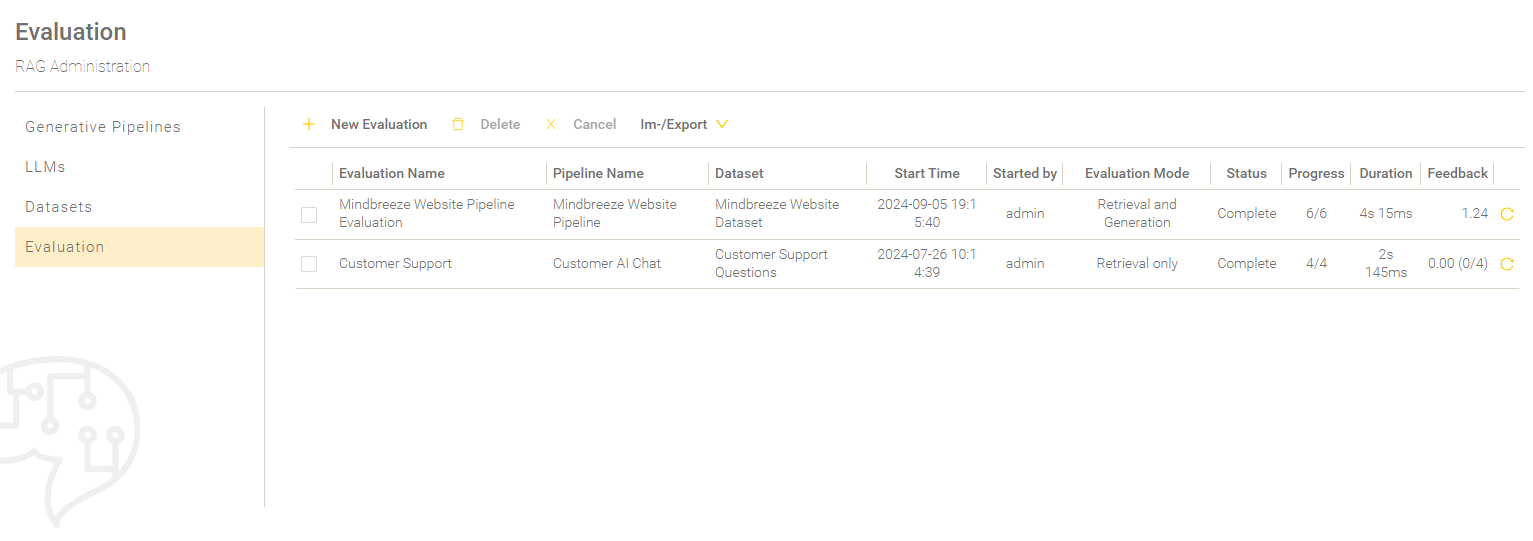
Overview
The evaluations are listed in the overview and listed according to the start time.
Setting | Description |
Evaluation Name | The name of the evaluation run. |
Pipeline Name | The name of the pipeline with which the Evaluation was made. |
Dataset | The name of the dataset which is used for the evaluation. |
Start Time | The date and time when the evaluation run was started. |
Started by | The user that started the evaluation run. |
Evaluation Mode | The chosen evaluation mode. For more information about the evaluation modes, see Create a new Evaluation. |
Status | The current status of the evaluation. The following statuses of the evaluation process are possible: “…” - The evaluation is pending. “Running” - The evaluation is in progress. “Incomplete” - At least one question has not the status “Completed”. “Complete” - All evaluated questions have the status “Completed“. |
Progress | The amount of already processed questions compared to the amount of all questions that must be processed. |
Duration | The duration of the evaluation run. |
Feedback | Shows the average rating of all rated questions. The number of rated questions compared to the total number of questions is shown in brackets. If all questions are rated, only the overall average rating is shown. |
Re-Run an Evaluation | As long as an evaluation is in progress, the last column of the table shows a loading icon. When an evaluation is finished, the last column shows a reload icon. When clicking on this icon, a new evaluation can be started which has initially already loaded the configuration of the picked evaluation. |
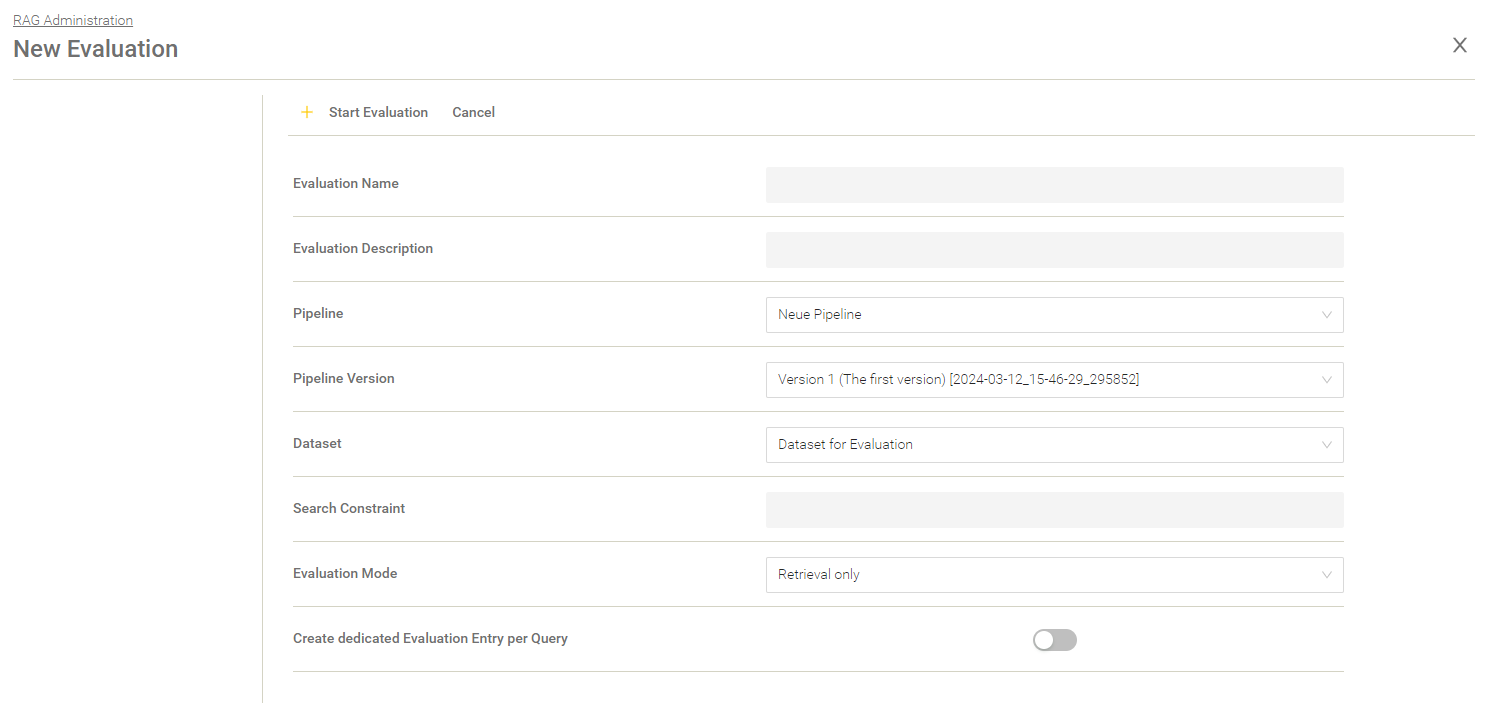
Create a new Evaluation
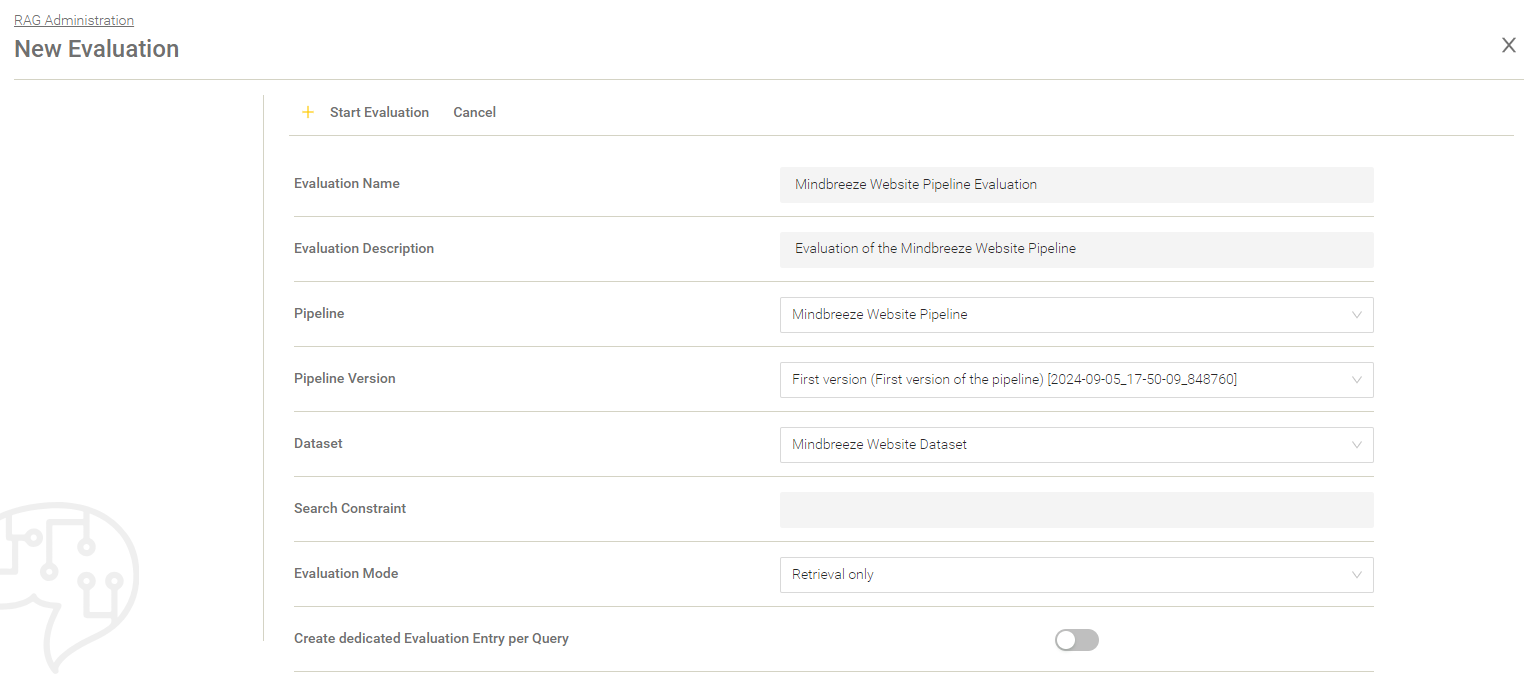
With “New Evaluation” a new evaluation can be created.

Setting | Description |
Evaluation Name | The name of the evaluation run. |
Evaluation Description | The description of the evaluation. Here you can explain what you want to evaluate or which setting has been changed or adjusted. |
Pipeline | The selection of the pipeline. |
Pipeline Version | The version of the chosen pipeline. |
Dataset | The dataset based on which the evaluation is to be done. |
Search Constraint | This value is used as a condition in the Retrieval Part for the whole evaluation run. |
Evaluation Mode | The following modes are available:
|
Create dedicated Evaluation Entry per Query (when “Evaluation Mode” is set to “Retrieval only”) | If activated, an own evaluation entry will be created for every query of your dataset. Default setting: Deactivated. |
Overwrite Pipeline LLM (when “Evaluation Mode” is set to “Generation only” or “Retrieval and Generation”) | If activated, you can use another LLM than the one set in the Pipeline for the generation. |
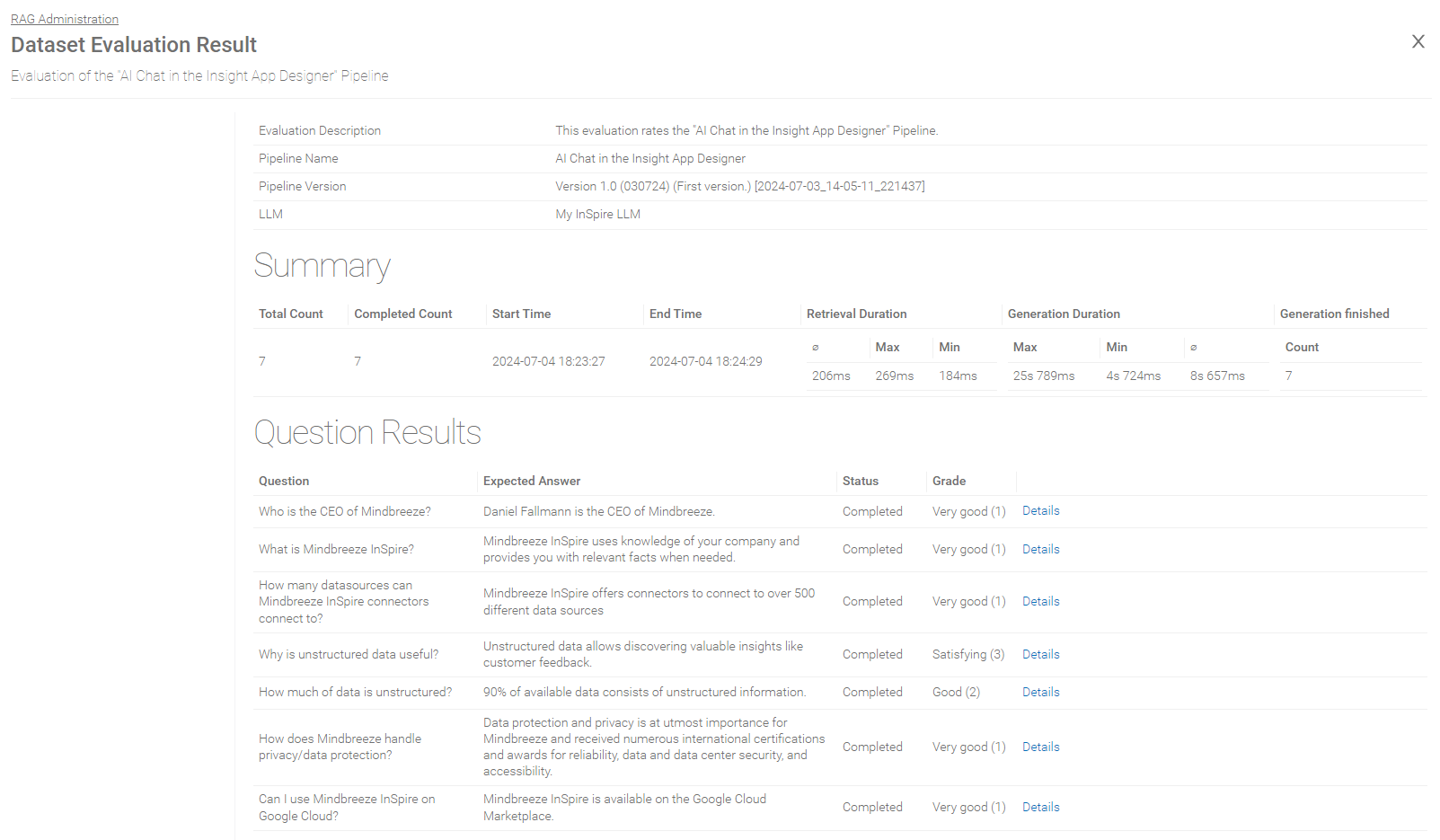
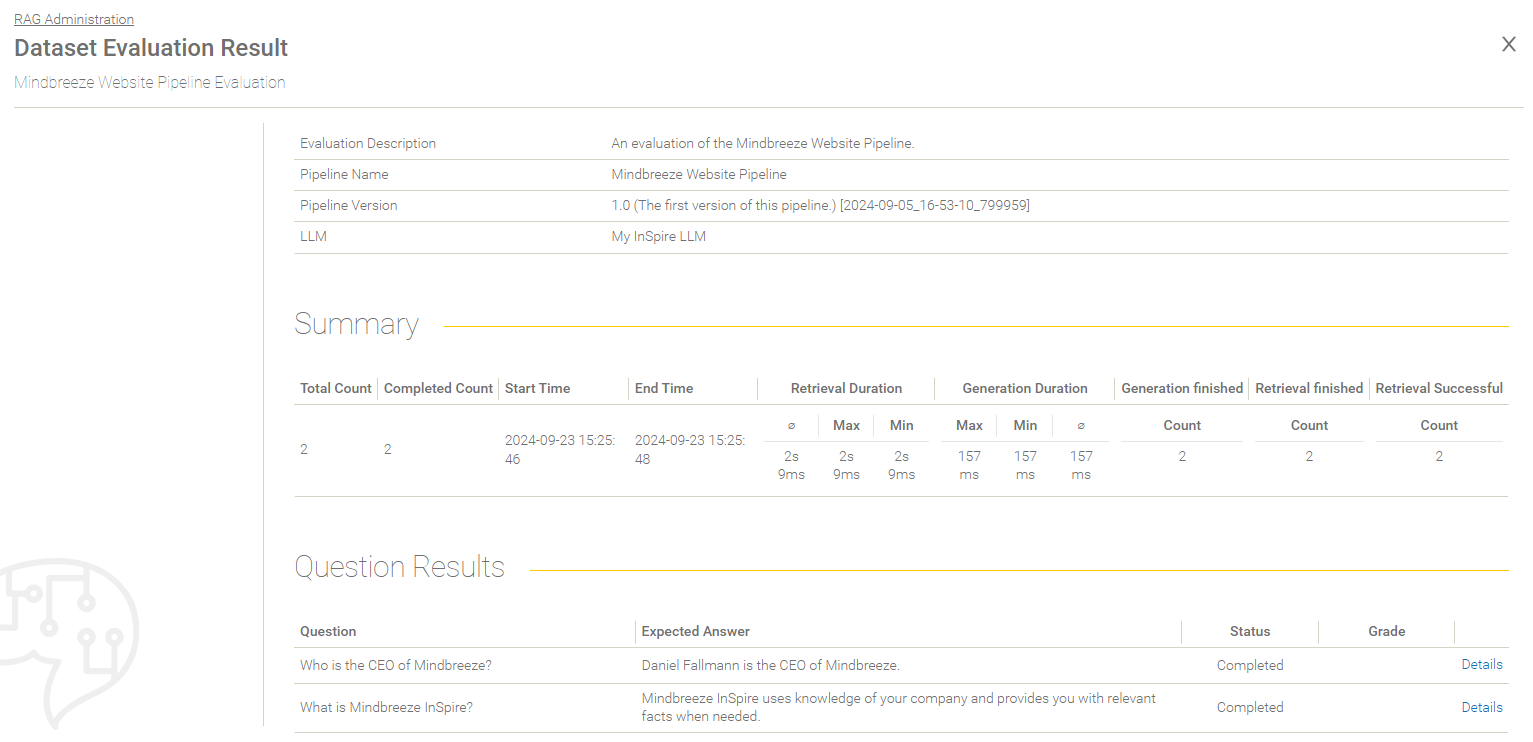
Evaluation Overview
Summary of the Evaluation Result

Setting | Description |
Total Count | The total amount of the questions to be processed. |
Completed Count | The amount of the already processed questions. |
Start Time | The date and time when the evaluation process was started. |
End Time | The date and time when the evaluation process ended. |
Retrieval Duration | The duration of the retrieval is determined using the following values:
|
Generation Duration | The duration of the generation is determined using the following values:
|
Generation finished | The number of requests for which generation was successfully completed. |
Retrieval finished | The number of requests for which the retrieval was finished. |
Retrieval Successful | The number of requests for which the retrieval was successful. |
Overview over the question results
Field | Description |
Question | The question defined in the dataset. |
Expected Answer | The expected answer defined in the dataset. |
Status | The evaluation status (for example „Completed“, „Failed“ and other). |
Grade | The grade based on the user review. |
Details | Here the details of the evaluation of a question can be found. |
Enriched dataset from an evaluation
For each evaluation, an enriched data set can be downloaded or saved as a new data set and used further. Depending on the evaluation mode, the dataset is enriched with different data:
Evaluation Mode | Enriched with… |
Retrieval and Generation |
|
Retrieval only | retrieved context. |
Generation only | generated answers. |
Saving the enriched dataset as new dataset
With “Save as Dataset” the enriched dataset can be saved as a new dataset.

Export of the dataset obtained from the evaluation
Enriched datasets can be downloaded as JSON or CSV file with “Export”.

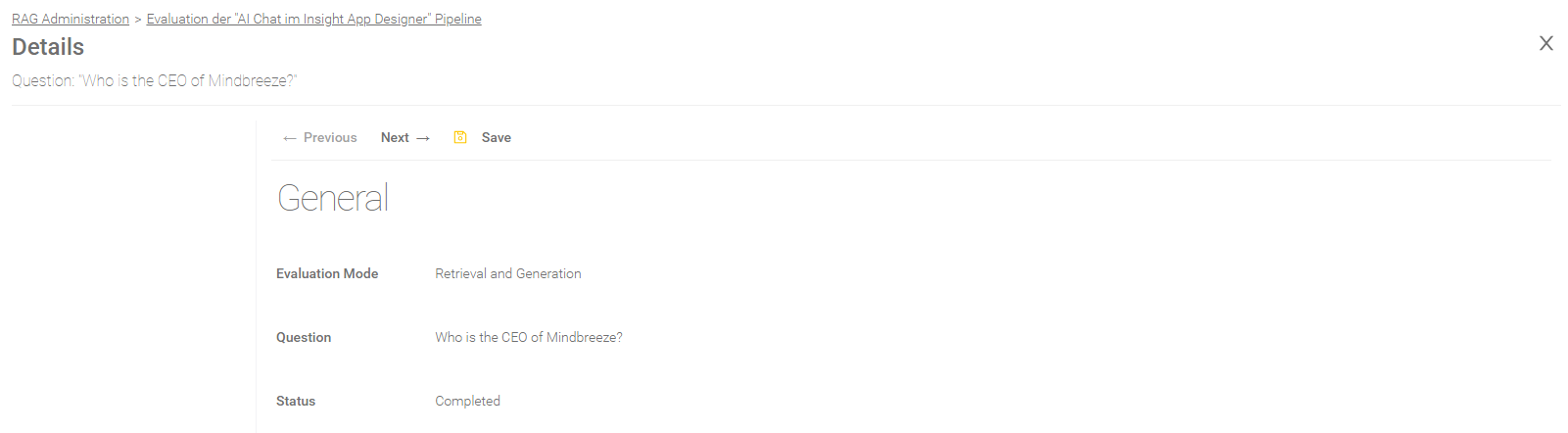
Question Result


General

Field | Description |
Evaluation Mode | The selected evaluation mode. For more information, see Create a new Evaluation. |
Question | The processed question. |
Status | The following status are possible: “Completed” – The evaluation process has been completed. “Retrieval” – The retrieval part is in progress. “Generation” – The generation is in progress. “…” - It is pending. “Canceled” - The user has canceled the evaluation process and the question hasn’t been processed until that. “Failed” - The evaluation process was canceled by the system. |
Error Message | If the status is “Failed”, you will find here further Information. |
Feedback
Here you get the possibility to give feedback on the evaluation result for a question.

Setting | Description |
Evaluation Grade | Here you can rate the evaluation result of a question from 1 (Very Good) to 5 (Insufficient). |
Label | A self-defined, individual label can be assigned here. |
Remark | Here you can add a remark. |
After you changed the feedback, you have to click on “Save” to save your feedback.
Generation
This section gives you Information about the answer generation.
Option | Description |
Show Prompt | The effective prompt is shown in a dialog. |
Show Generation Parameters | The LLM Parameters are shown in a dialog like temperature and other parameters. |
In the table below, there is the expected answer from the dataset compared to the generated answer from the LLM.
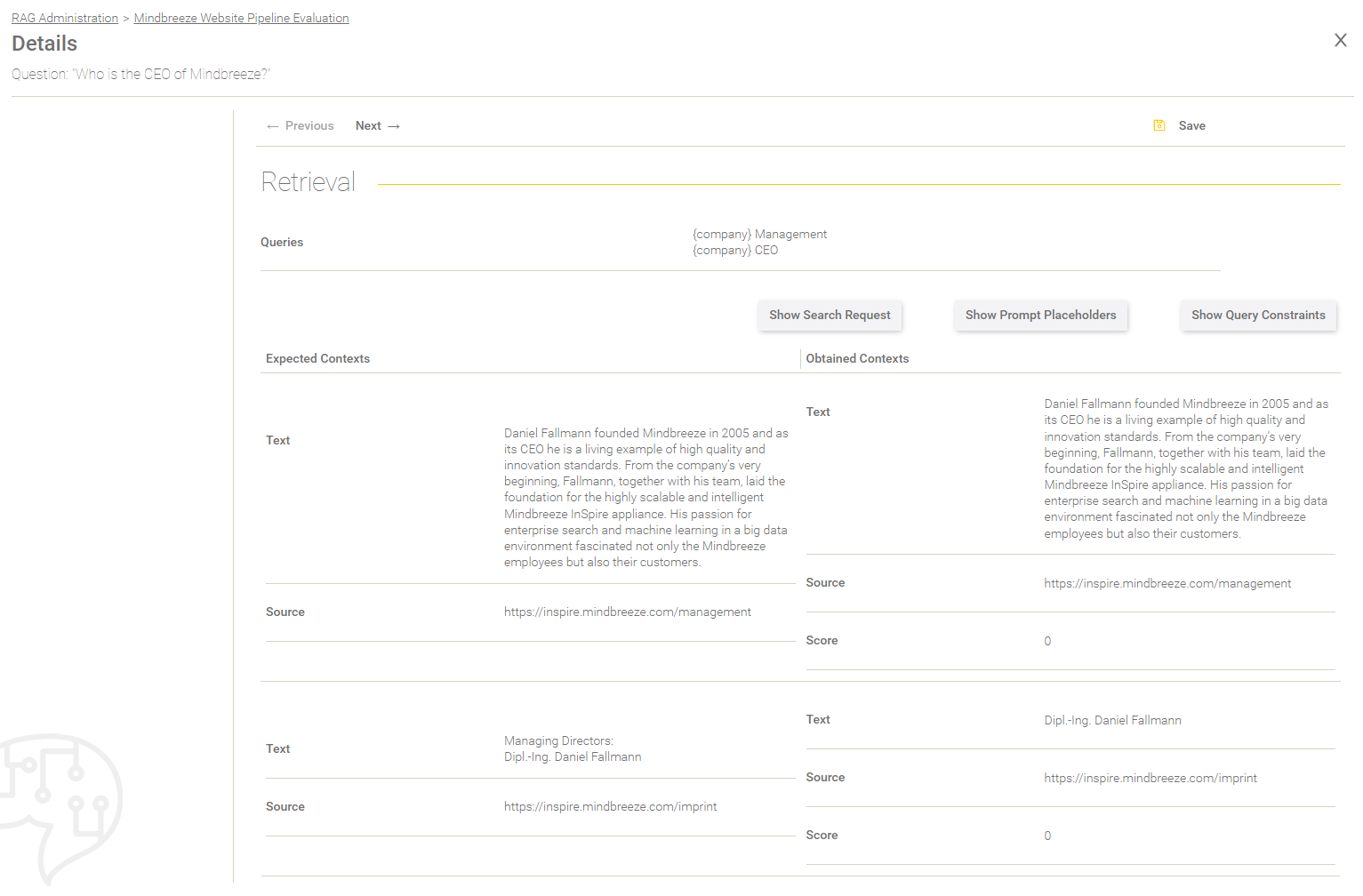
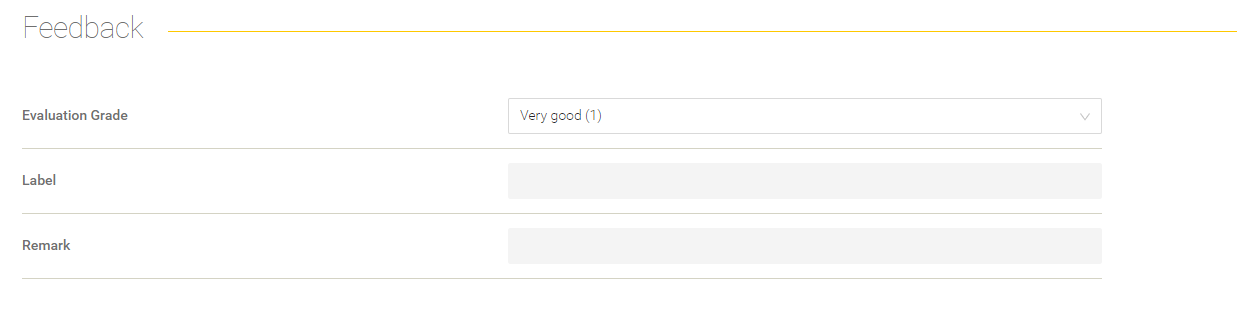
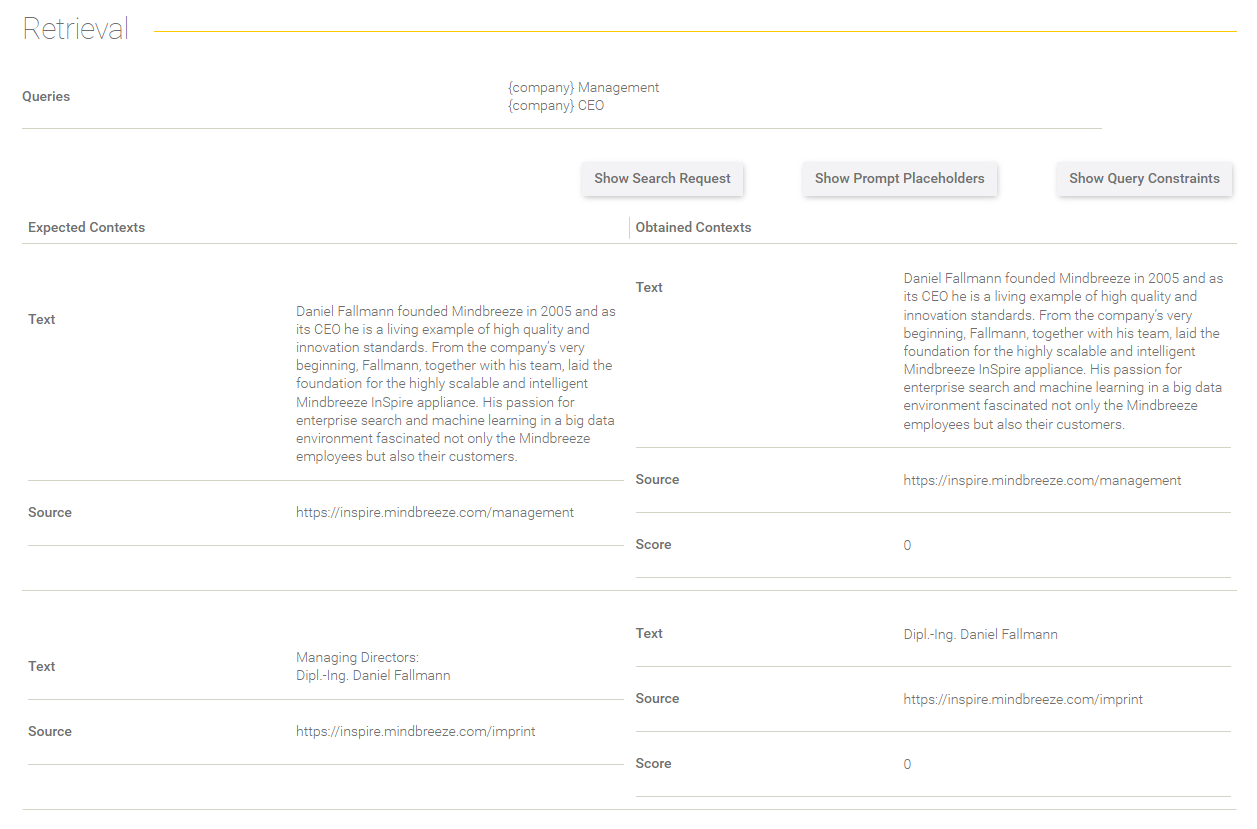
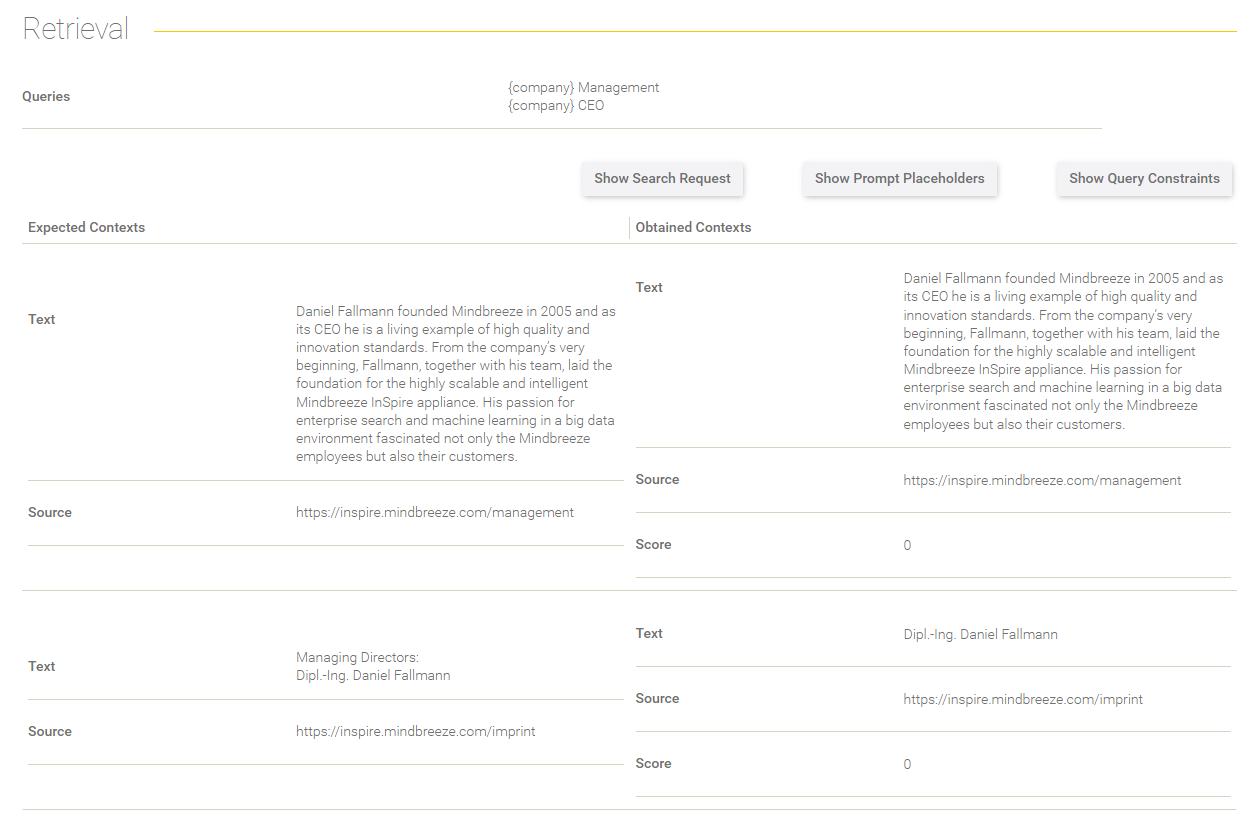
Retrieval
This section gives you Information about the retrieval process.

Field/Option | Description |
Queries | The queries are shown here that were used to process the search request. |
Show Search Request | The effective search request is shown here in a dialog that has been sent to the Client Service. |
Show Prompt Placeholder | The prompt placeholder from the dataset are shown here in a dialog. |
Show Query Constraints | The query constraints from the dataset entry are shown here in a dialog. |
In the table below, the expected contexts (defined in the dataset) are compared to the contexts you got in the retrieval process.
Export and import of Evaluations
Evaluations can only be exported as a JSON file.
Evaluations can be imported and exported using ‘Import/Export’.

Export
To export one (or more) evaluation(s), the respective evaluations must be selected. To do this, tick the box next to the respective evaluations to select them. If at least one evaluation is selected, you can select the ‘Export’ option under ‘Import/Export’. A pop-up window will then appear containing the download link for the exported evaluation.

If several evaluations are selected at the same time, they are exported as ZIP files.
Hint: If no evaluation is selected, the option “Export” is greyed out and cannot be selected.
Import
Exported evaluations can also be imported again as ZIP files in another RAG service. Imported evaluations from other RAG services are labelled with ‘[Imported]’ in front of the name in the overview table. They are sorted with the other (non-imported) evaluations based on the evaluation start.
