
Sure, you can handle it. But should you?
Let our experts manage the tech maintenance while you focus on your business.
Let our experts manage the tech maintenance while you focus on your business.
Whitepaper
Natural Language Question Answering (NLQA)
Motivation and overview
The great popularity and many possible applications of OpenAI's ChatGPT solution show how relevant the topic of Generative AI based on Large Language Models (LLMs) is. Especially in the enterprise context, this technology can offer great added value. However, its use is hampered by issues such as hallucinations, issues with keeping data up-to-date, data security, critical questions regarding intellectual property and technical implementation for sensitive data. Mindbreeze offers a solution in the form of a combination of Insight Engine and LLMs that is able to compensate for exactly these weaknesses. The result is the ideal basis for Generative AI in the enterprise context.
This basis is called "Natural Language Question Answering", NLQA for short, and combines semantic search with "Question Answering". The semantic search makes it possible to work with complete sentences, which means that you can search for information by entering full, natural language sentences. Question Answering is responsible for generation of answers, whereby answers are rendered in natural language including surrounding context and source reference.
The following chapters explain how to perform the basic configuration for NLQA. For further questions about the configuration and usage of the feature, see the FAQ section in this document. Information about supporting custom language models and handling feedback can be found there.
Attention: A 100% complete and correct search cannot be guaranteed when using semantic search with trained models. Model customization is only supported for dedicated projects, where the labeled training and test data is provided by the customer environment. It should also be noted that considerably more computing power is used to process the data. Please note that the indexing time may take longer as a result. It is therefore not guaranteed that the full number of documents can be operated with this feature.
Configuration
This section describes the configuration steps necessary to enable Natural Language Question Answering (NLQA).
Index configuration
In Mindbreeze Management Center (MMC), navigate to the "Configuration" menu and switch to the "Indices" tab, then add a new index ("+ Add Index") and activate "Advanced Settings".
Configuration of Sentence Transformation
In the next step, activate the following options in the section "Semantic Text Extraction":
Activated | |
Enable Sentence Transformation | Activated |
Other recommended settings:
If zones other than “content” or “title” are to be available for NLQA. Recommended value: “content|title” (default value) | |
Sentence Transformer Restrict to Language Pattern | If only documents in certain document languages should be available for NLQA, you can restrict this here. For example, if German and English documents are to be processed: "en|de" Default value: be|bg|br|bs|ca|cs|cy|da|de|el|en|es|et|eo|eu|fi|fo|fr|fy|ga|gd|gl|gv| |
Data source configuration
Configure your data source. Documentation of the data sources supported by Mindbreeze InSpire can be found on help.mindbreeze.com in the "Data Sources" section.
Test
Wait until the indexing is complete. Test the configuration using the standard Mindbreeze InSpire Insight app.
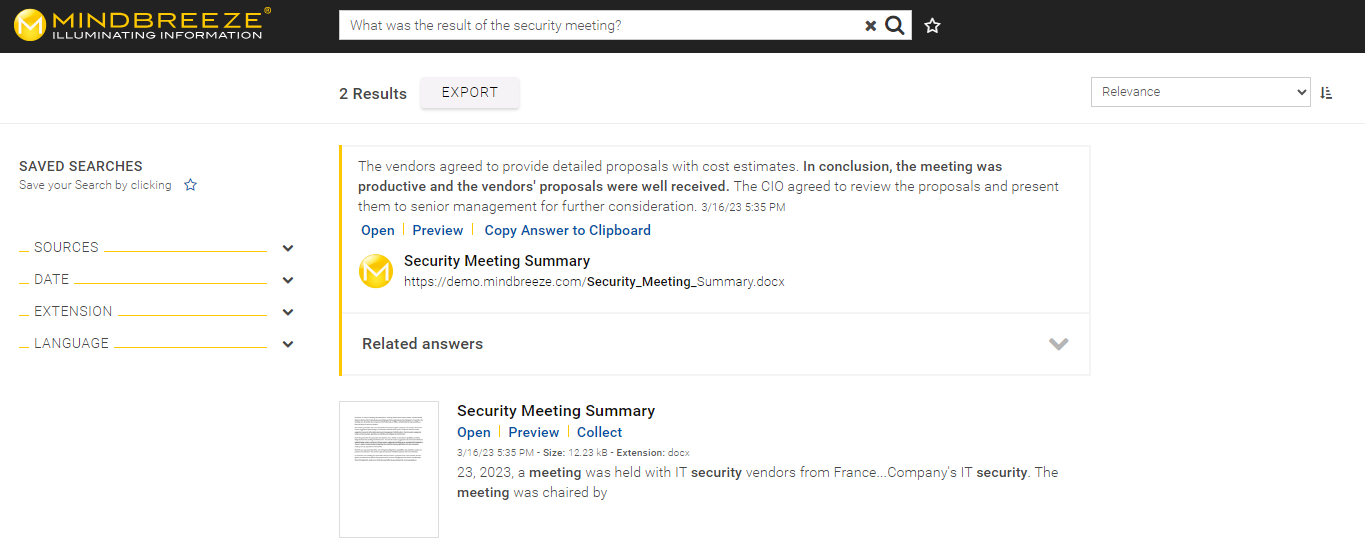
FAQ
Can I activate NLQA on an existing index?
Yes, you can enable NLQA on existing indexes as well. Configure "Named Entity Recognition (NER)" and "Sentence Transformation" as described above. Then, the index must be rebuilt. Perform one of the following steps:
- Re-indexing ("Reindex" button) or
- full re-inversion of the index
How can I integrate NLQA into my Insight app?
By default, the answers are displayed directly above the search results. In addition, the visualization of answers can be freely customized to your needs and also completely disabled. See Development of Insight Apps.
Can NLQA be used with my existing Mindbreeze InSpire license?
The NLQA feature can be used with the existing Mindbreeze InSpire license. For more information, please contact support@mindbreeze.com.
Support for Custom Sentence Transformer Models
The basis for the semantic search is formed by Transformer-Based-Language-Models in ONNX format. By using this open standard, pre-trained models or self-trained LLMs can be integrated into Mindbreeze InSpire. The configuration of Custom Sentence Transformer Models is described in the Documentation - Mindbreeze - Sentence Transformation.
Can I influence which answers are displayed?
There are several ways to influence the displayed responses:
Filtering responses based on quality or number:
Answers are sorted by similarity factor, with the best answer at the top. The minimum similarity factor for displaying an answer is 50% by default. This value as well as the maximum number of answers can be set in the respective index and client service configuration.
Order of answers can be influenced (boostings):
Mindbreeze components for influencing the relevance of search hits such as Term2DocumentBoost Transformer and Personalized Relevance can also be used for boosting answers. In addition, boosts defined in the api.v2.search interface are also applied to Answers relevance.
How can I get answers from metadata other than content?
By default, the sentence embeddings are only calculated for “content” and “title”, which is why the semantic search only returns answers from this metadata. To get answers from other metadata as well, configure the option “Static Sentence Transformer Restricted Zones Pattern”. E.G: Responses should also come from the metadata “description”, then “Static Sentence Transformer Restricted Zones Pattern” must be configured with the following value: “content|title|description”.
It is also important that the metadata is explicitly requested during the search (in our example “description”). There are two ways to do this if the metadata has not yet been requested:
- Request metadata via Mustach-Template:
<div class="media"><span class="hidden">{{description}}</span></div> - Via the application object:
modelDefaults: {
search: {
properties: { "description": { "formats": ["VALUE"]} }
}
}
(see Development of Insight Apps – The application object)
Are there advanced configuration options for NLQA?
Yes, there are advanced configuration options for NLQA in Mindbreeze InSpire - Sentence Transformation. These options are typically only relevant to you if you have specific use cases that require special configuration. Please contact support@mindbreeze.com if you need support for your data science project, e.g. if you want to use a different model than the Sentence Transformer model provided by default.
I am not satisfied with the inversion time and/or search performance. What can I do?
Basically, the more data is processed by the Sentence Transformers, the longer the inversion takes and the larger the (inverted) index becomes. The larger the index, the more computing effort is required at search time. This means that if the index is reduced in size, this normally has a positive effect on the inversion time and search performance. The following options are available in the index settings (Semantic Text Extraction section):
Setting | Description |
Sentence Transformers Model ID Setting | To achieve a better inversion time and search performance with a minimal loss of quality, we recommend using the model all-MiniLM-L6-v2 (quantized, optimized). |
Sentence Transformer Max Batches | If very large documents (with a lot of text) are indexed, this can also have a negative impact on performance. This option can be used to define the maximum number of sentence “batches” to be processed by the Sentence Transformer. For example: Sentence Transformer Batch Size: 10 |
Sentence Transformer Restrict to Language Pattern | If, for example, only English documents are relevant for the Similarity Search, this can be restricted here with “en”. |
Restricted Zones Pattern Static Sentence Transformer Restricted Zones Pattern, Dynamic Sentence Transformer Excluded Zones Pattern | By default, Sentence Embeddings are only calculated for “content” and “title” (default value Static Sentence Transformer Restricted Zones Pattern: “content|title”). It is not recommended to process all metadata with Sentence Transformers using “.*”. It is better to extend the “Static Sentence Transformer Restricted Zones Pattern” option, e.g. “content|title|description”, if “description” is a metadata with relevant information. |
For more information on these settings, see Configuration – Mindbreeze InSpire – Sentence Transformation.
Furthermore, in most cases, the following setting will improve inversion performance (section “Setup”):
Setting | Description |
Documents per Index Bucket | By default, a bucket is limited to 60,000 documents. Since buckets are inverted in parallel (maximum 1 thread per bucket), you can achieve more parallelism when inverting by reducing this value (e.g., to 10,000). If fragmentation is a problem, the setting „Periodic Delete Bucket if Deleted %“ can be reduced to 70%, for example. See also Documentation - Mindbreeze InSpire - Index Compactification. |
Can I get feedback from my users about the quality of responses?
The voting feature offers the possibility to get feedback from a user on an answer search result. This feedback is also recorded in app.telemetry. The InSpire beta version of NLQA does not currently support automatic adjustment of the relevance of answers for users based on their feedback.
In addition, other user interactions with Answers are recorded in app.telemetry, for example, when a user clicks on the Answer source document. These interactions, as well as user feedback, can be graphically displayed and evaluated in the app.telemetry Insight App Reporting Dashboard.
Can I use the Mindbreeze Query Language to influence the search with NLQA?
Yes, there are extensions to the Mindbreeze Query Language for NLQA.
If NLQA is activated, a so-called "Similarity Search" is automatically performed for every search. This default behaviour can be adjusted in the index configuration. For this, see the setting "Transform Terms to Similarity" in Documentation - Mindbreeze InSpire - Sentence Transformation.
To explicitly perform a similarity search using the Mindbreeze Query Language (regardless of the setting "Transform Terms to Similarity"), the following syntax can be used:
~"<Question>"
Example: ~"How many connectors does Mindbreeze InSpire offer?"
The similarity search can also be used in combination with the Metadata Search:
<Metadata>:~"<Question>"
Example: content:~"How many connectors does Mindbreeze InSpire offer?"
The similarity search also supports options, whereas several options can be specified in one query:
~[<Option>:<Value> ...]"<Question>"
Examples:
- ~[minscore:0.5]"How many connectors does Mindbreeze InSpire offer?"
- ~[minscore:0.5 region:large]"How many connectors does Mindbreeze InSpire offer?"
The following options are available:
- minscore - Overwrites the configured "Minimum Score". For more information about the "Minimum Score", see Documentation - Mindbreeze InSpire - Sentence Transformation.
- Valid values: Decimal number between 0 and 1 (for example, 0.5).
- region - Overwrites the configured setting “Text Region”. Defines the size of the answer. Here, the values „default" and "large" are available.
- default: Is the default size and depends on the configured "Sentences Transformation Text Segmentation" settings. For more information, see Documentation - Mindbreeze InSpire - Sentence Transformation.
- large: Is a large text block, depending on the following settings in the configuration area “Sentences Transformation Text Segmentation”:
- Large Text Segment Max Size
- Large Text Segment Overlap Size
- Large Text Segment Min Size
- Hint: The score of the answers tends to be lower with this option, which is why it is recommended to also specify the option minscore (e.g. with the value 0.3).