
Sure, you can handle it. But should you?
Let our experts manage the tech maintenance while you focus on your business.
Let our experts manage the tech maintenance while you focus on your business.
Whitepaper
Text Classification Insight Service
Motivation and Overview
Text classification with Mindbreeze InSpire has never been easier. Tag a portion of your documents with predefined labels. With the help of Mindbreeze Insight Services and Machine Learning, Mindbreeze InSpire is able to expand your knowledge and store it for future use cases. Based on this knowledge, all other documents can subsequently be classified fully automatically.
Labeling can be done easily and directly via the Insight app - even without a predefined data set.
The main steps to perform this use case are:
- Preparing the training dataset
- Define the possible labels for the documents.
- Manual labeling via the Insight App for documents and creation of the dataset to train the classification model.
- Training a classification model
- Labeling of documents from an index using the classification model in Semantic Pipeline (Item Transformation).
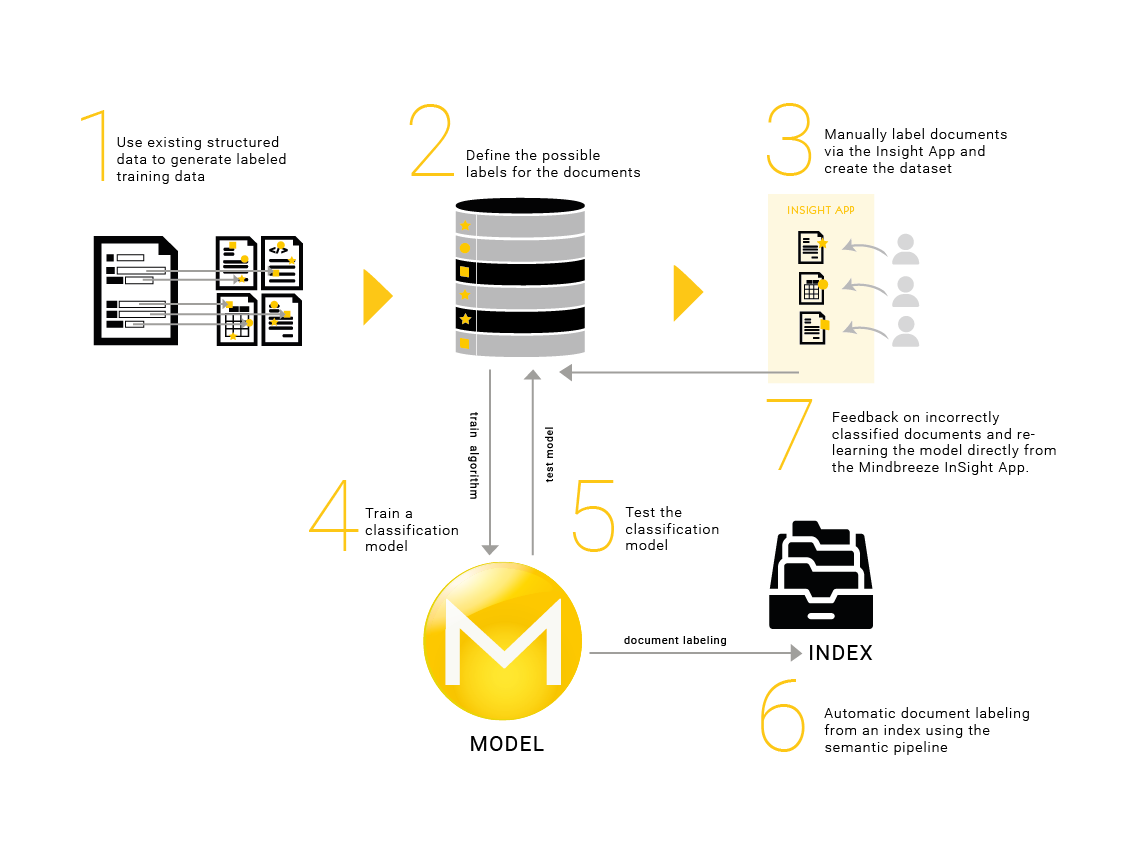
Preparation
Overview of the required Services
In order to use text classification, certain configuration steps are necessary. Configure the following services:
- Prediction Service
- Text Classification Insight Service
In addition, you still need to make configuration adjustments in the Client Service and Index Services.
Details can be found in the next sections.
Configuring the Prediction Service
In Mindbreeze Management Center, navigate to the "Configuration" menu and switch to the "Indices" tab, then add a new service.
Assign a “Display Name” and select “PredictionService” under “Service”.

For the additional minimal configuration, fill in the following fields in the following configuration sections:

Setting | Description |
Base Path | This parameter specifies the path to be used by the Prediction Service to get the training/test data and where the models learned by the service should be stored. The basepath is freely selectable. |
Bind Port | Specifies the TCP port on which the Prediction Service will be accessible. It is important that the port is not already in use by another service (e.g. principal resolution, index or client service). |
Dump Requests/Responses | This option enables enhanced troubleshooting and logs requests and responses to the index path under the “mesindex-debug-dumps” directory. The setting "On Error" logs every time a request produces an error. If the default setting "Never" is chosen, no logging occurs, "Always" logs each request. Note: Do not activate “Always” permanently in production mode. |
Dump Path | Here you can define the path where the dumps are written. Here it is only to be noted that these data lie in the "/data/" partition. The subfolders are self-definable. |
If you have more specific use cases, see the Detailed Configuration of Prediction Service section for more information.
Configuring the Text Classification Insight Service
Now add the "Text Classification Insight Service". Assign a "Display Name" again and select the "TextClassificationInsightService" under "Service".
For a minimal configuration, fill in the following fields in the following configuration sections:
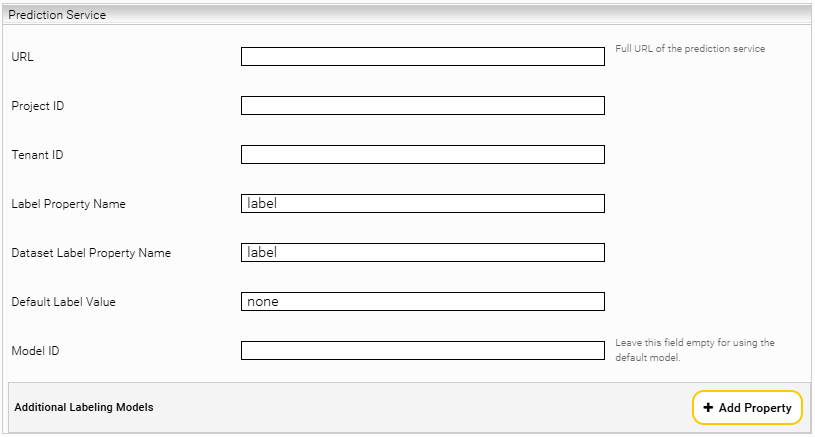
Description | |
URL | The URL of the prediction service. E.g. http://localhost:23910 if you have selected 23910 as "Bind Port" for the Prediction Service. |
Project ID | The name of the classification project |
Tenant ID | For example, the company name or the organizational unit |

Setting | Description |
Dataset Index Ports | The ports of the indexes in which the documents to be classified are located. |
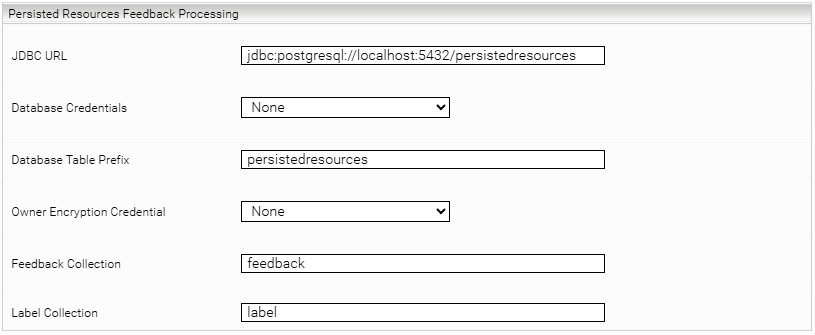
Setting | Description |
JDBC URL | Configure the same value as in "Resource Persistence Settings" in the Client Service. |
Database Credentials | Configure the same value as in "Resource Persistence Settings" in the Client Service. |
Database Table Prefix | Configure the same value as in "Resource Persistence Settings" in the Client Service. |
If you have more specific use cases, see the Detailed Configuration of Text Classification Insight Service section for more information.
Other required Configuration Changes
In addition to the Prediction Service and the Text Classification Insight Service, you still need changes in the configuration of the Client Service and the Index Services.
Client Service
To enable users to label documents in the standard Insight app, you still need to make configuration changes in the client service.
Activate the Advanced Settings and configure the Resource Persistence Settings. Then enable Document Labeling. You only need to change the other options in the section "Document Labeling" if you have changed certain default values in the Text Classification Insight service:
Setting | Description |
Enable Document Labeling | Enables labeling in the Insight app. Default: disabled |
Label Property | The same value as for the setting "Label Property Name" in the Text Classification Insight Service. |
Labeling Feedback Collection | The same value as for the setting "Feedback Collection" in the Text Classification Insight Service. |
Available Labels Collection | The same value as for the setting "Label Collection" in the Text Classification Insight Service. |
Index Service(s)
Documents are classified as they pass through the Semantic Pipeline - more specifically, in the "Item Transformation" step.
Add the previously created "Text Classification Insight Service" to the index at the "Item Transformation Services". If you are using multiple indexes, repeat this step on all index services.
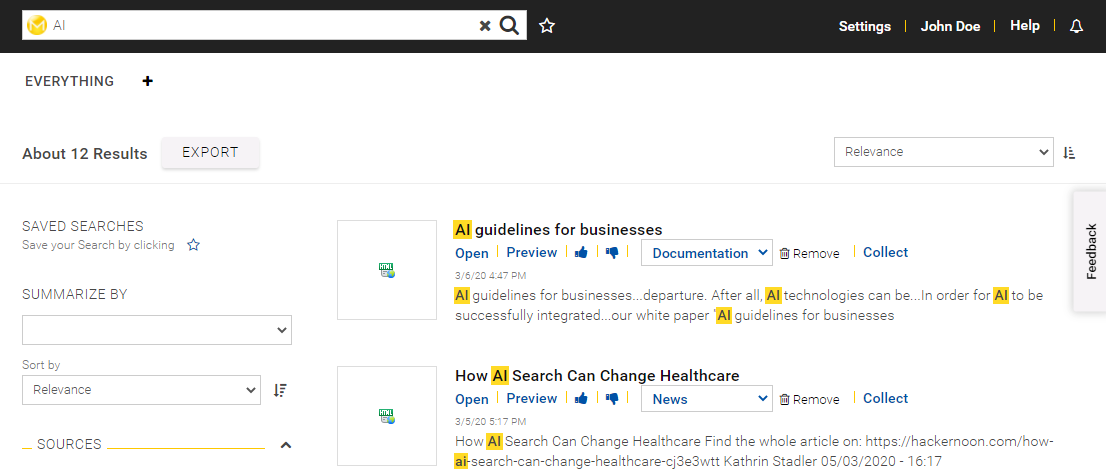
Definition of Labels and Manual Labeling
When the configuration is complete, you can define labels. These labels can be used by users to identify documents in the Insight App.
Defining the Labels
In the Mindbreeze Management Center, navigate to the "Insight Services" "Text Classification" menu. Then click on "Edit" at "Label Definitions".
Now define your labels according to which you want to classify your documents.
Define translations for the languages you want to support in your Insight app. If there is no translation for languages, the ID will be used for display in the Insight app. With the "Save" button you can confirm your entries.
More details:
- If "Ignored" is checked, documents with this label will be ignored when training the model.
- You can delete labels with the trash icon.
- Please note that you do not change the ID of labels if they are already assigned to certain documents. (The assigned label IDs on the document remain unchanged, which leads to negative effects).

Manual Labeling
Now users have the option to label documents with the labels they have just defined. After searching in the Insight app, the found documents can be labeled by selecting the desired label from the drop-down menu.
Logged in users can read and assign labels. Anonymous users who are not logged in to the Insight app can read (automatically assigned) labels. (Manually assigned labels are not visible to anonymous users).
If multiple users assign labels for the same document, all assignments are saved, but effectively only the label of the last assignment is used.
Users also have the option to remove their own feedback again (trash icon). If the document was previously labeled by another user, the previous label is now effective.
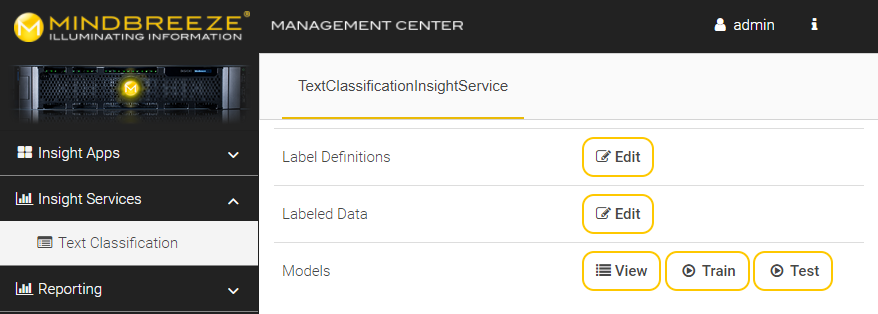
Creating / Updating the Training Dataset
If the required documents have now been marked with labels, you can create the training data set that will later be used as the data basis for creating the model. To do this, navigate to the "Insight Services" "Text Classification" menu in the Mindbreeze Management Center. Then click on "Edit" at "Labeled Data".
You can now check whether the users have manually labeled the documents correctly. If labels were assigned incorrectly, these assignments can be changed here or even ignored. Then click on "Create or Update Dataset" to save your changes and create the training dataset.

Preparing Models for Text Classification
In the next steps, a model can now be created and tested from the training dataset.
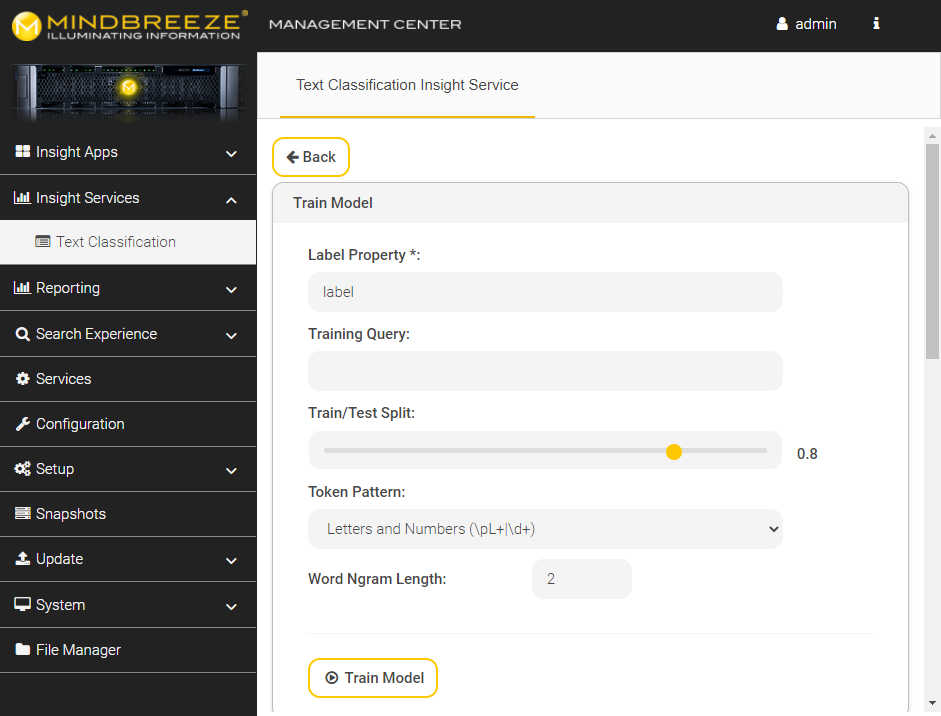
Train the model
In the Mindbreeze Management Center, navigate to the "Insight Services" "Text Classification" menu. Then click on "Train" under "Models".

Now click on "Train Model" to train a model. The default parameters are sufficient for most use cases. However, you can also fine-tune them if your use case requires it.
The following parameters can be adjusted:
Parameter | Description |
Label Property | Must only be changed if the Dataset Label Property Name option has been changed in the Text Classification Insight Service configuration. The value specified here must match the one in the configuration. |
Training query | A search query to filter documents in the training dataset, which are then used to train the model. If empty, all documents that have content are used for training. |
Train/Test Split | The division of the data set into training and testing data. E.g.: "0.8" means that 80% of the data is used for training, 20% for testing. |
Token Pattern | See MindbreezePredictionService - Train and validate a model "token_pattern". If "Custom Regex" is selected, the "Custom Pattern" field appears, in which a custom regex can be specified |
Word Ngram Length | See MindbreezePredictionService - Train and validate a model "ngram_length". |
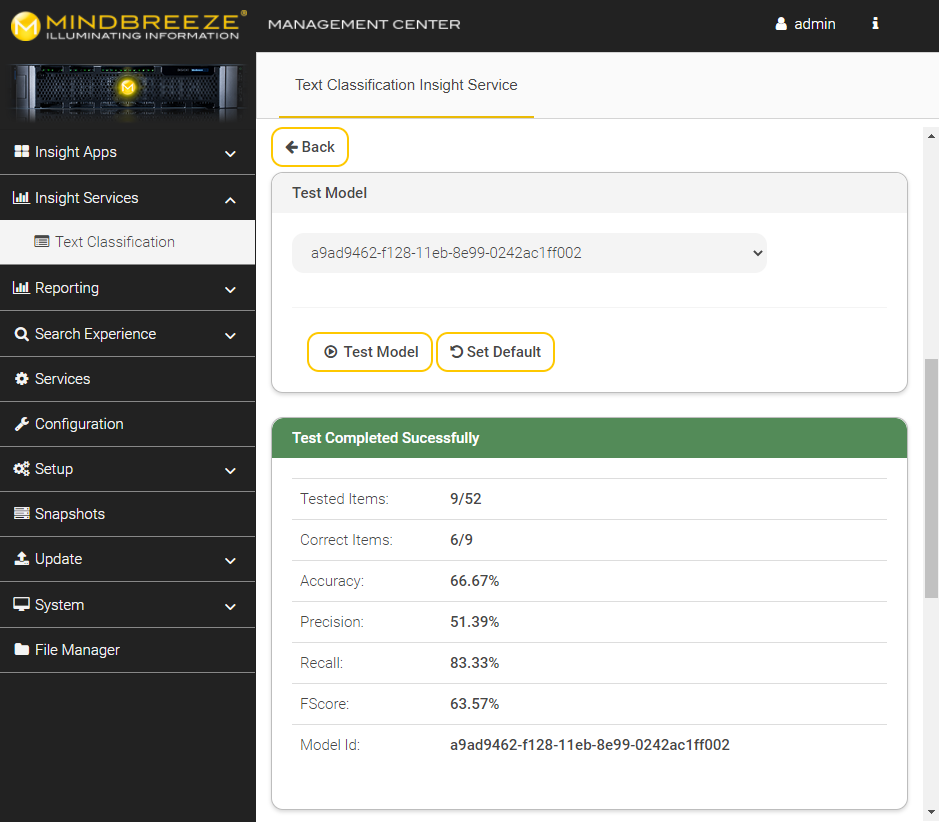
Test and use the model
In the next step, you can now test the model to get information about the quality of the model you just trained. Scroll to "Test Model". The model you just trained should already be selected. If you now click on "Test Model", the model will be tested with the test data and you will receive key figures that give you information about the quality of the model, such as "Accuracy".
Then click on "Set Default" so that this model is used for classification.
Automated Document Labeling
As already mentioned, the documents are automatically classified when they pass through the SemanticPipeline - more precisely in the Item Transformation step. Unless explicitly configured otherwise in the service configuration, the default model that you set in the previous step with "Set Default" is used for classification.
Since the Semantic Pipeline is only run through completely for new or changed documents, only new or changed documents are classified. However, to ensure that documents that have already been indexed are also classified, you have two options, which are described in more detail in the next sections:
- Reindex: recommended for small indexes where complete indexing is very fast (e.g. on test systems)
- Reinvert: recommended for large indexes, where a complete indexing takes a long time
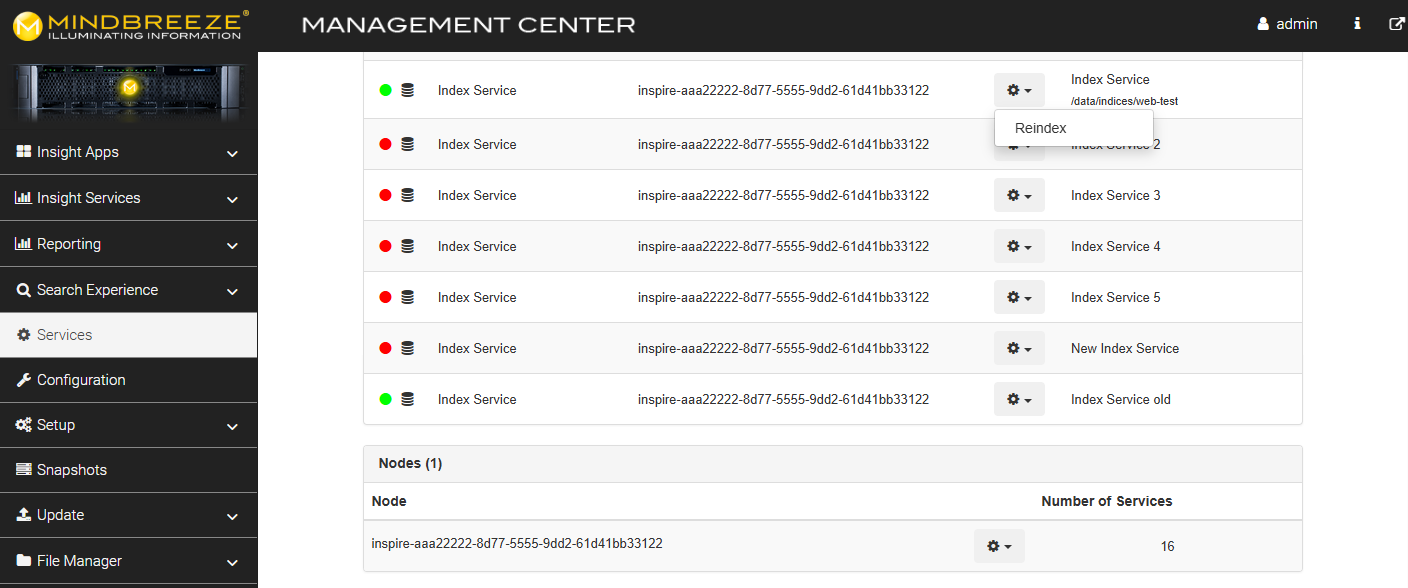
Reindex
If the index is small and a full indexing can be performed very quickly, a re-indexing is recommended to trigger a classification of all documents. To do this, navigate to "Services" in the Mindbreeze Management Center. Then click on the gear icon for the index you want to re-index and then click on "Reindex". As soon as the re-indexing is successfully completed, your documents are classified.
Reinvert
If the index is large and a complete indexing takes a long time, a re-inversion is recommended to trigger a classification of all documents. To do this, navigate to "Configuration" in the Management Center and switch to the "Indices" tab. Activate the "Advanced Settings" and change the "Aggregated Metadata Keys". Changing this option will automatically re-invert the index. For example, you can specify "label" which will result in filtering by label in the Insight app. However, you can also specify a non-existent metadatum key, such as "V1".

Save the configuration afterwards. Once the re-inversion is successfully completed, your documents are classified.
Appendix
Iterative Improvement of the Model
Once your documents are classified, users can also provide feedback widely in the Insight app and change the labeling of the documents if, for example, the automatic classification was inaccurate and in some cases incorrect (see also ManualLabeling).
This feedback can then be used to update the training dataset (see Create / Update Training Dataset).
Afterwards, a new model can be trained (see Train Model), tested and used (see Test and Use Model).
If a document now changes or a new document is indexed, the new, just trained model is already used for the classification. If you want to classify all documents, including the already indexed documents, with the new, improved model, you must trigger a reindex or reinvert.
You can perform these steps to iteratively improve the model as many times as you like until you are satisfied with the quality of your classification model.
Detailed Configuration of the Text Classification Insight Service (Advanced Use Cases)
This section describes all the options available in the Text Classification Insight service. This section is relevant to you only if you have special use cases that require special configuration.
Base Configuration
Setting | Description |
The TCP port of the service | |
Max Request Handling Threads | Maximum number of threads used to process the HTTP server requests. |
Max Feedback Processing Threads (advanced) | Number of threads used to process the user feedbacks ("Labeled Data"). |
Prediction Service
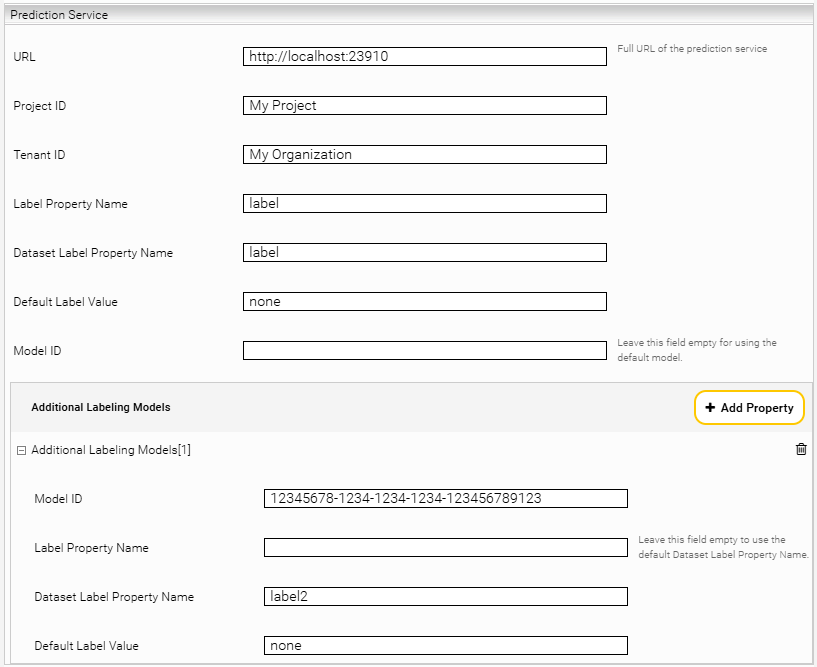
Setting | Description | ||||||||
URL | The URL of the Prediction Service. E.g. http://localhost:23910 if you have selected 23910 as "Bind Port" for the Prediction Service. | ||||||||
Project ID | The project ID used to structure records in the Prediction Service. Stored in: <PredictionService-Data-Directory>/tenants/<TenantID>/projects/<ProjectID>. | ||||||||
Tenant ID | The tenant ID used to structure records in the Prediction Service. Stored in: <PredictionService-Data-Directory>/tenants/<TenantID> /projects/<ProjectID> | ||||||||
Label Property Name | The name of the metadatum used for the label property on the document. | ||||||||
Dataset Label Property Name | The name of the property in the dataset | ||||||||
Default Label Value | Documents that are excluded from classification for certain reasons (e.g. because the "Minimum Content Length" has not been reached) are assigned a default value as a label. This default value can be defined here. | ||||||||
Model ID (optional) | If empty, the "Default Model" is used (can be set in the Management Center under "Text Classification" "Models"). However, a model ID can also be explicitly specified here, which will then be used for the classification. | ||||||||
Additional Labeling Models (optional) | Here you can specify additional models that will be used in the classification.
|
Text Classification Sources
Setting | Description | ||||||||
Content Length Limit (Characters) | The maximum number of characters of the document content that will be used for classification. If the number of characters exceeds this configured value, the characters beyond it are not used during classification for performance reasons. The value "0" or an empty value disables the character limit. | ||||||||
Minimum Content Length (Characters) (optional) | The minimum number of characters of the document content that is required for the document to be classified. Documents that do not meet this requirement are classified with the configured "Default Label Value". The value "0" or an empty value disables this filter. | ||||||||
Source Metadata Keys (optional) | By default, only the document content is classified. Additional metadata can be specified here, which will be included in the classification. | ||||||||
Add annotations | Should always be enabled | ||||||||
Training Link Extraction (optional) | Links in documents (HTML anchor tags) are not included in training and classification by default. In order to include certain links that are meaningful for labeling, rules can be defined here.
|
Rule Based Labels (optional)
Here you can define rules to label certain documents without calling the Prediction Service. For example, you can use it to classify all documents as "Documentation" that contain "Doc" or "Documentation" in the title.
The first rule that matches a document is always applied. If no rule matches, then the prediction service is used to set the label.

Setting | Description |
Property Name | To select the documents to which the rule will be applied. Those documents are selected for which the "Value Pattern" matches the value of the metadata with the "Property Name" key. |
Value Pattern (Regex) | See above. Value Pattern is a case-sensitive Java regex (ignored if the pattern starts with (?i)). |
Action | Which action is to be performed:
|
Label Value | Only relevant if "Action" is set to "Set Label" (see above) |
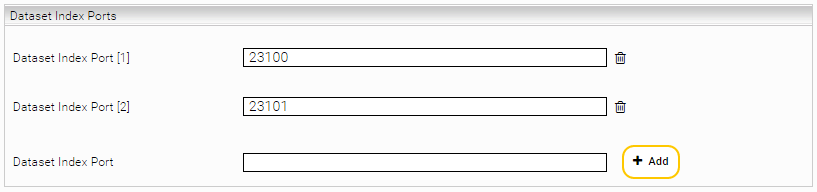
Dataset Index Ports
Setting | Description |
The ports of the indices in which the documents to be classified are located |
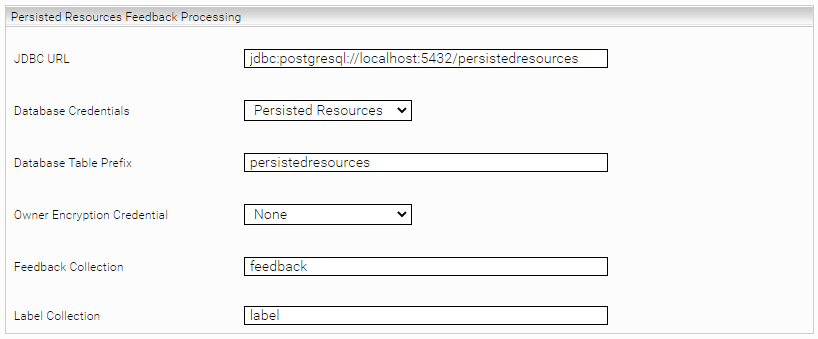
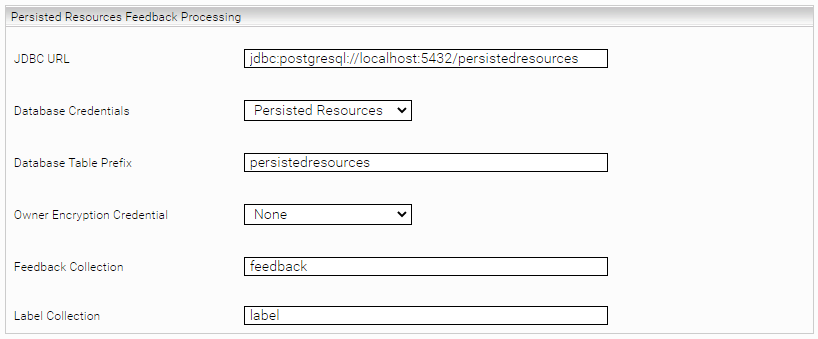
Persisted Resources Feedback Processing
Configure the same values for the following options as for "Resource Persistence Settings" in the Client Service: "JDBC URL", "Database Credentials", "Database Table Prefix".
See also Resource Persistence Settings.
Setting | Description |
JDBC URL | See Client Service. |
Database Credentials | See Client Service. |
Database Table Prefix | See Client Service. |
Owner Encryption Credential | If you use Identity Encryption in the Client Service, you must select a credential here. In this case, please select the same credential as in the client service option "Identity Encryption Credential". |
Feedback Collection | The name of the collection in the "itemdata" persisted resources where user label feedback is stored. |
Label Collection | The name of the collection in the "labeldefinition" persisted resources where the label definitions are stored. |
CSV Feedback Processing (optional)
In addition to user feedback (via the Insight app), a CSV file can be used to set labels for documents. These labels are not displayed in the Insight app, but can be used to train the classification model.
Example:
Fqcategory;Key;LabelValue;IgnoreFeedback
Web:helpmindbreeze;http://help.mindbreeze.com/de/index.php?topic=doc/Konfiguration---Microsoft-File-Connector/index.htm;performancetest;false
Web:helpmindbreeze;http://help.mindbreeze.com/de/index.php?topic=doc/Installation--Konfiguration---Caching-Principal-Resolution-Service/index.htm;performancetest;false

Setting | Description |
Enable CSV Processing | To activate the CSV feedback processing |
CSV File Path | The path to the CSV file (write permissions required) |
Detailed Configuration of the Prediction Service (Advanced Use Cases)
This section describes all other special options that are available in the Prediction Service besides the mandatory fields. This section is only relevant for you if you have special use cases that require special configuration. Also, in this section, those options that are not marked by "(Mandatory)" or "(Advanced)" are automatically considered as Advanced.
Prediction Service Parameter
Setting | Description |
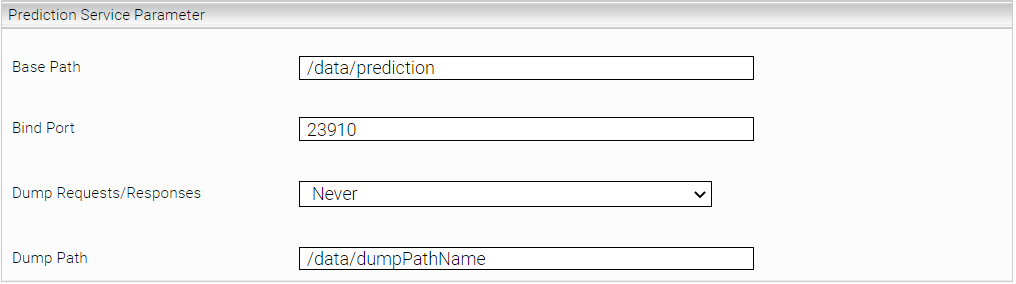
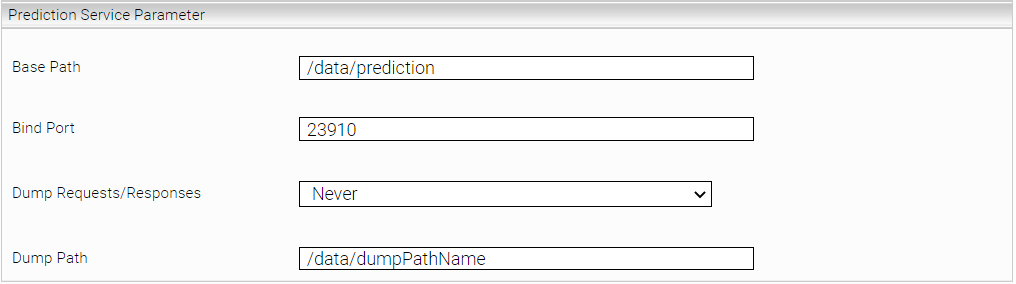
Base Path (Mandatory) | This parameter specifies the path to be used by the prediction service to get the training/test data and the path where the models learned by the service should be stored. The basepath is freely selectable. |
Bind Port (Mandatory) | Specifies the TCP port on which the Prediction Service will be accessible. It is important that the port is not already in use by another service (cache, index, client,... service). |
Dump Request/Responses (Advanced) | This option enables enhanced troubleshooting and logs requests and responses to the index path under the “mesindex-debug-dumps” directory. The setting "On Error" logs every time a request produces an error. If the default setting "Never" is chosen, no logging occurs, "Always" logs each request. Note: Do not activate “Always” permanently in production mode. |
Dump Path (Advanced) | Here you can define the path where the dumps are written. Here it is only to be noted that these data lie in the "/data/" partition. The subfolders are self-definable. |
Dataset Settings
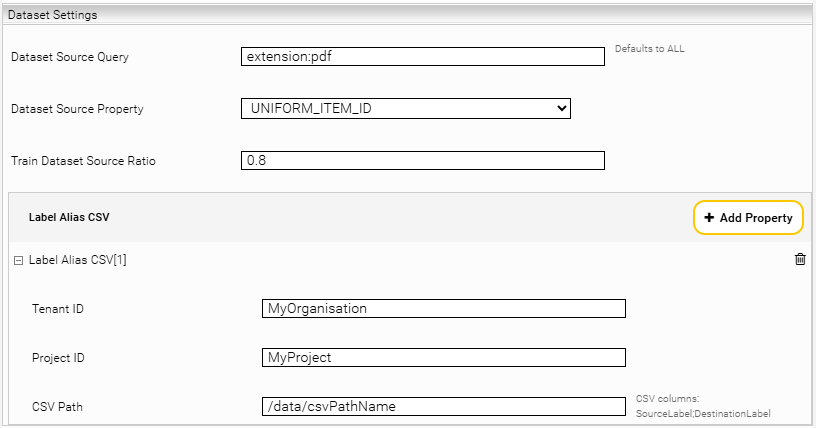
Setting | Description | ||||||||
Dataset Source Query | This can be used to restrict the training set with a query (e.g.: PDFs only). If the Text Classification Insight Service is used, this setting should be left empty. | ||||||||
Dataset Source Property | Currently only “UNIFORM_ITEM_ID” can be selected. | ||||||||
Train Dataset Source Ratio | Defines what % of all documents are used for training. If the Text Classification Insight Service is used, this setting should be left empty. | ||||||||
Label Alias CSV (optional) | With this extension you can translate the label values if the dataset contains a different value than needed for the classification.
|