Sure, you can handle it. But should you?
Let our experts manage the tech maintenance while you focus on your business.
Let our experts manage the tech maintenance while you focus on your business.
Configuration
Index Servlets
Introduction
Administrators can use index servlets to search for errors, make diagnoses and carry out troubleshooting. The following chapters describe the requirements for configuring an index servlet, as well as the configuration itself and the index servlets available.
Requirements
The following requirements must be met before an index servlet can be called:
- Functioning and activated index
- The setting “Disable Unrestricted Privileged Servlets” must be set to either “Enabled” or “Enabled (Debug)”.
You can configure or activate an index by opening the “Configuration” menu item in the Mindbreeze Management Centre and creating an index in the “Indices” tab with “+ Add Index”. If you want to use an existing index, activate it with “Enable”.
For the setting “Disable Unrestricted Privileged Servlets”, “Advanced Settings” must be activated. You will find the setting you are looking for in the section “Setup”. Make sure that “Enabled” or “Enabled (Debug)” is selected.
Depending on the servlet, the selection of a specific option is required. The following table lists all privileged servlets and the required option for the setting “Enable Unrestricted Privileged Servlets”. Those servlets that are not listed in this table can be reached with the option “Disabled”.
Servlet | Option „Enabled“ | Option „Enabled All (Debug)“ |
/aclcachecontrol | X | |
/aclconsistency | X | |
/aclstatistics | X | |
/dump | X | |
/qperf | X | |
/tokenize | X | |
/quit | X | |
/aggregate | X | X |
/documents | X | X |
/find | X | X |
/extractitems | X | X |
/processitems | X | X |
Attention: The option “Enabled All (Debug)” is only recommended for test systems and should not be activated for production systems.

You can now access a list of all index servlets at the following URL:
https://<Appliance>:8443/index/<IndexPortNr>
Index Servlets
Aggregate Document Properties (/aggregate)
You can use this index servlet to obtain aggregated values from documents, such as the number of different document titles.
You can access the servlet with the following URL:
https://<Appliance>:8443/index/<IndexPortNr>/aggregate

The following options can be configured:
Option | Description | Example/Default setting |
Column Name | Specifies the column names of the index that are used for the aggregation. | Example: mes:lang |
Query Constraint | Specifies various constraints for the query. For example, filtering by document date. The search is restricted to system metadata. | The search is limited to system metadata:
Beispiel: extension:html |
Aggregation operator |
| Four operators can be chosen:
Default setting: COUNT |
Concatenation max value count | Specifies the maximum number of values to be concatenated. | Default setting: 0 - unlimited |
Concatenation value order | Specifies how the values for the “CONCAT” function are sorted. | The following sorting options are available:
Default setting: UNORDERED |
Output Format | Specifies the output format. | The following formats are available:
Default setting: csv |
Expand Query | In case Expand Query is set to false (or not provided), the internal query expression transformers are not used. This can be helpful for the following use cases:
| Default setting: false |
Example
The „aggregate“ index servlet can be used to count how many HTML documents there are in the index in the respective languages. The following settings are required for this:
Setting | Option/Entry |
Column Name | mes:lang |
Query Constraint | extension:html |
Aggregation operator | COUNT (Default setting) |
Concatenation max value count | 0 – unlimited (Default setting) |
Concatenation value order | UNORDERED (Default setting) |
Output Format | csv (Default setting) |
Expand Query | false (Default setting) |
Depending on the index, the result may look like this:

Browse Document by ID or Key (/documents)
You can use this index servlet to search individual documents by their docID, their key or their UniformItemID.
You can access the servlet with the following URL:
https://<Appliance>:8443/index/<IndexPortNr>/documents

The following options can be configured:
Option | Description | Example/Default setting |
By docID | Here you can enter the docID of the desired document. The docID of a document can be found using the index servlet ‘Query Documents (/find)’. Attention: To obtain results from the index servlet, it is essential to specify a docID or a key. | Example: 148 |
By Key | Here you can enter the key of the desired document. The key of a document can be found in two ways:
Attention: To obtain results from the index servlet, it is essential to specify a docID or a key. | Example: https://inspire.mindbreeze.com/blog |
By UnifomItemID | Here you can enter the UniformItemID of the document. Unlike the dokID, the UnformItemID remains the same if the document receives an update, for example an additional chapter. The UniformItemID can be found as follows:
Note: docID and UniformItemID can have the same or a different value. | Example: 212 |
Output Format | You can select the format in which the document is to be output and what content is to be displayed. The following options are available:
| Default setting: DocumentAndContents |
Deleted documents | Here you can specify whether deleted documents should also be included in the search. | The following options are available:
Default setting: Exclude |
Example
The ‘Browse Document by ID or Key (/documents)’ index servlet can be used to view the access rights for the respective document, among other things. Using the ‘Query Documents (/find)’ index servlet, it was possible to find out that the docID for the desired document has the value ‘148’. The following settings are also required:
Setting | Option/Entry |
By docID | 148 |
Output Format | Item |
Deleted documents | Exclude (Default setting) |
In the output, you can now see the property ‘everyone’ under ‘principal’, which means that all users have access to the document with the docID 148:
Query Documents (/find)
You can use this index servlet to send search queries to search for documents.
You can access the servlet with the following URL:
https://<Appliance>:8443/index/<IndexPortNr>/find
The following options can be configured:
Option | Description | Example/Default setting |
Query | Specifies a search query like in the standard Mindbreeze search window. The search is restricted to system metadata:
| Example: category:web |
Query Protobuf Textual | Wird nur für interne Zwecke vom Mindbreeze Support verwendet. | - |
Order by | Specifies the criteria by which the documents are sorted. | Example: mes:key |
Order Direction | Specifies the direction by which the documents are sorted. Documents can be sorted by ascending or descending order. The following options are available:
| Default setting: descending |
Group by | Specifies if the documents should be grouped and according to which criteria. | - |
Group by Parent Reference | Enables the grouping by references. | - |
Group by Parent Reference Mode | Defines how far to reference. The following options are available:
| Default setting: disabled |
Summarize by property | Specifies the property by which documents are combined, such as a name or file extension. | Example: mes:lang |
Order summarized by | Specifies the sort order of the summary. | Example: mes:key |
Order direction | Specifies the direction of the sort order. Summary can be sorted by ascending or descending order The following options are available:
| Default setting: descending |
Output Format | Specifies the output format in which the results are displayed. The following options are available:
| Default setting: csv |
Expand Query | In case Expand Query is set to false (or not provided), the internal query expression transformers are not used. This can be helpful for the following use cases:
The following options are available:
| Default setting: false |
Diacritic Similar Terms | Specifies whether diacritical entries should also be included in a search. Diacritical marks are, for example, umlaut characters or the hash sign above certain letters. For example, a search for “possibel” will also include “possible.” By including diacritical marks, for example, a search for “possibel” will also include “possible”. This must be taken into account for documents that are written in German, Czech or Finnish, for example. The following options are available:
| Default setting: no_query_expansion |
Requested Properties (CSV) | Specifies which specific document properties are to be searched. When multiple properties are to be searched, the properties need to be separated by semicolons like for CSV. You can request additional system metadata. | Example: mes:lang |
Example
The index servlet ‘Query Documents (/find)’ can be used to search the index for specific documents, among other things. In this example, the ‘docID’ can be found for a certain document. It is known from the document that it is a job advertisement for the position of ‘Office Manager’. The following settings are required:
Setting | Option/Entry |
Query | Open positions |
Order by: | title |
Order direction: | ascending |
Group By Parent Reference Mode: | disabled (Default setting) |
Order direction: | descending (Default setting) |
Output Format: | csv (Default setting) |
Expand Query: | false (Default setting) |
Diacritic Similar Terms: | no_query_expansion (Default setting) |
By sorting the documents in descending order by title, the document you are looking for and the corresponding „docID“ can be found easily:
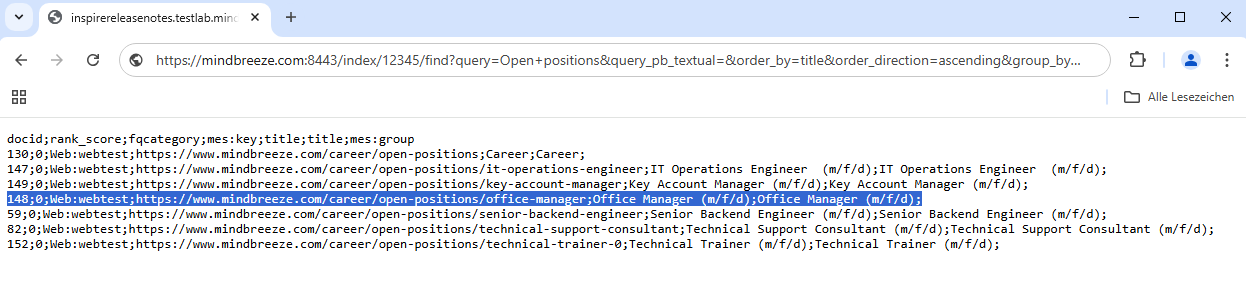
Statistics Information (/statistics)
This index servlet can be used to call up statistics on the current index.
You can access the servlet with the following URL:
https://<Appliance>:8443/index/<IndexPortNr>/statistics
The following options can be configured:
Option | Description | Example/Default setting |
Detail Level | You can specify the level of detail in which the statistics will be output. The following options are available:
| Default setting: basic |
Output Format | Here you can specify the format in which you want the statistics to be output.. The following options are available:
| Default setting: protobuf_textual |
Example
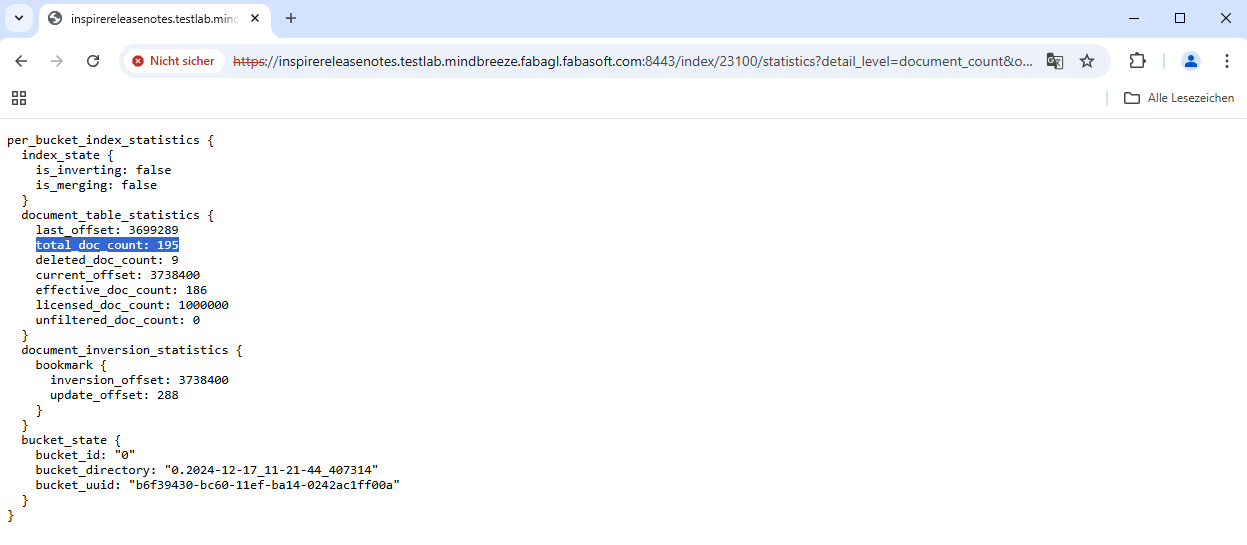
The index servlet „Statistics Information (/statistics)“ can be used to obtain clear statistics on the index. The following settings allow you to see the total number of documents and the number of deleted documents, among other things:
Setting | Option/Entry |
Detail Level: | document_count |
Output Format: | protobuf_textual |
The output shows that there are a total of 195 documents in the index and nine documents have been deleted:
Entity Recognition Workbench (/processitems)
This index servlet can be used to design rules for the „Entity Recognition“ feature and try them out with the currently active index. The rules are defined by a regex pattern.
Attention: When defining a rule, the regex pattern must be adapted slightly. You can find more information on this in the description of the ‘Rules’ setting.
You can access the servlet using the following URL:
https://<Appliance>:8443/index/<IndexPortNr>/processitems
The following options are available:
Setting | Description | Example/Default setting |
Rules | Defines the rule to be tested with a regex pattern. Note: The specification of a rule is mandatory. Attention: The following syntax must be followed for the regex pattern to function correctly: /myRegexPattern/. | Example: year=/[1-9][0-9][0-9][0-9]/. |
Query | Defines one or more document(s) for which the rule is applied. The rule is applied to the results of the query. | Example: Blog |
If a valid rule is defined and a query is optionally specified, the “process” input fields for the “Match on Extract” area appear.
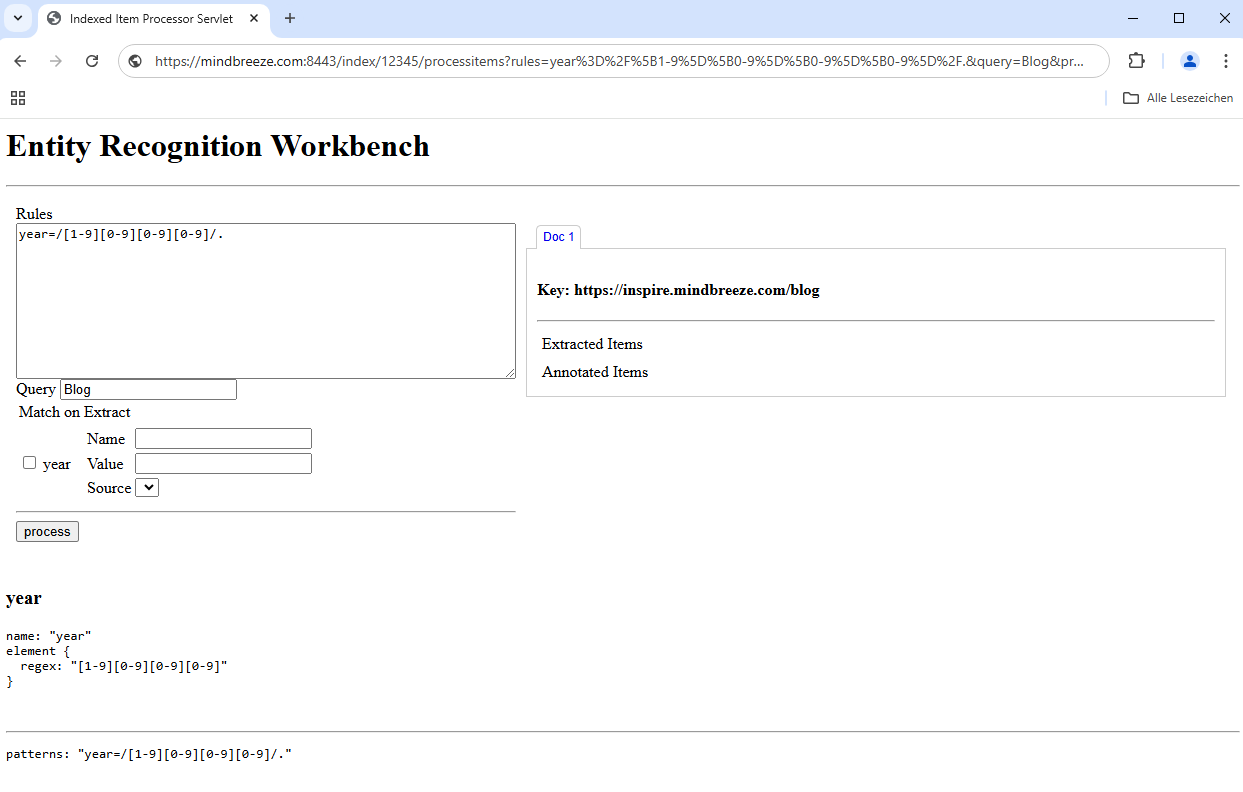
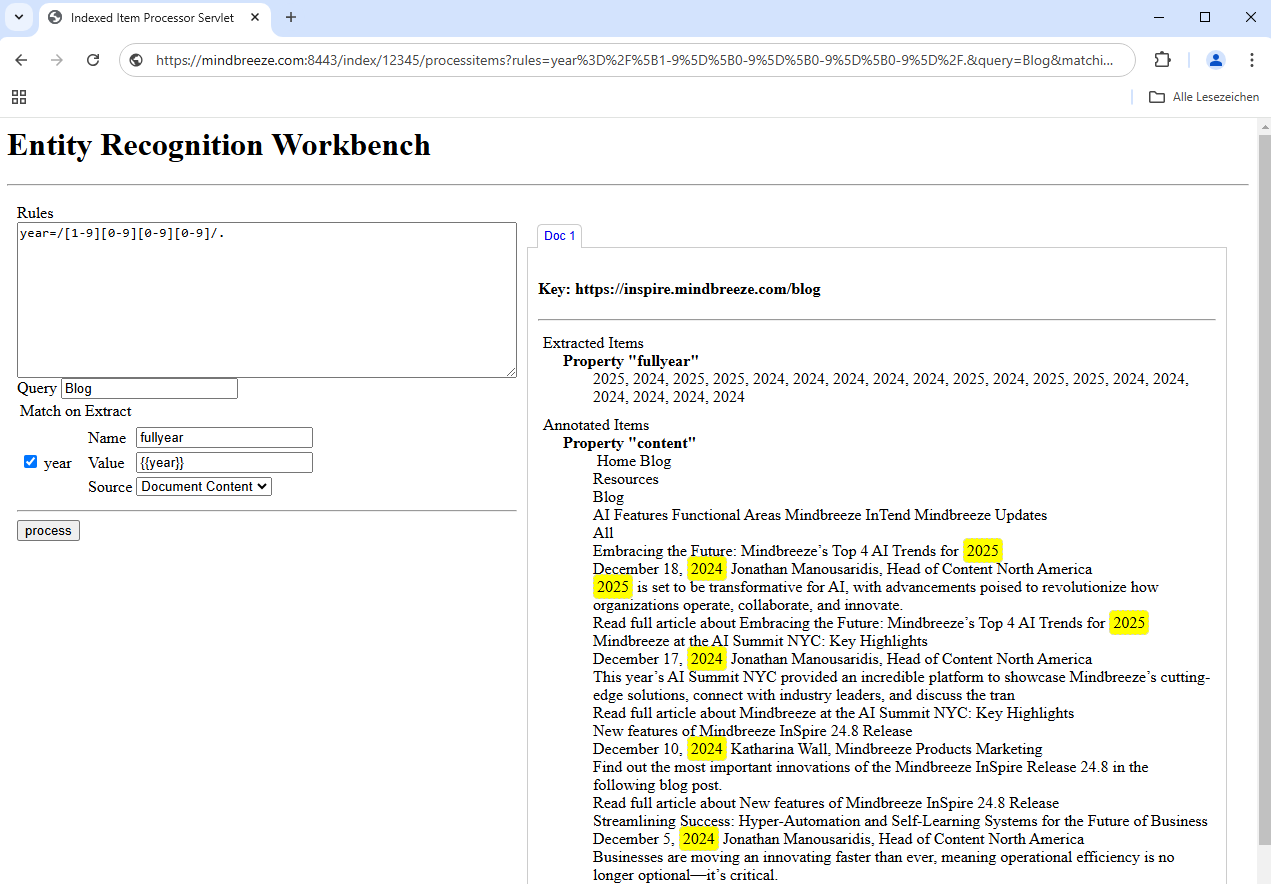
This can be used to test the extractors. These input fields can be configured as follows:
Element | Setting | Description | Example |
Element 1 | Name | Name of the property where the metadata is stored. | fullyear |
Value | Definition of what the value will look like. | {{year}} | |
Source | Defines where the metadata should come from. | Document Content |
Status request (/wait)
The servlet is used to check the status of the index, especially for scripts, as the connection to the servlet is maintained until the index is ready. The index configuration option "Wait for Event Servlet Update Status Interval (seconds)" determines in which intervals an update is sent. The content type of the response is "text/event-stream" and is set in the header.
You can reach the servlet with the following URL:
https://<Appliance>:8443/index/<IndexPortNr>/wait

The output consists of the following elements:
Element | Description | Example |
data | Is a JSON formatted plain text whose content "finished" will be “true” in the last message. | - |
invertingCompleteFraction | Indicate the completeness in fractions and are converted to percentages by the multiplication with 100. | Example: invertingCompleteFraction":0.5 The value „0.5“ means 50%. |
mergingCompleteFraction | Indicate the completeness in fractions and are converted to percentages by the multiplication with 100. | Example: mergingCompleteFraction":1.0 The value „1.0“ means 100%. |
totalBucketCount | Returns the number of buckets in the index. This can increase when new documents are being indexed | Example: totalBucketCount":2 |
totalCompleteFraction | Indicate the completeness in fractions and are converted to percentages by the multiplication with 100. | Example: totalCompleteFraction":0.5 The value „0.5“ means 50%. |
Examples:
data: {"event":"all_finished","finished":false,"invertingCompleteFraction":0.5,"mergingCompleteFraction":0.5,"totalBucketCount":2,"totalCompleteFraction":0.5}
data: {"event":"all_finished","finished":false,"invertingCompleteFraction":1.0,"mergingCompleteFraction":0.5,"totalBucketCount":2,"totalCompleteFraction":0.5}
data: {"event":"all_finished","finished":true,"invertingCompleteFraction":1.0,"mergingCompleteFraction":1.0,"totalBucketCount":2,"totalCompleteFraction":1.0}
The following URL parameters can be used:
URL Parameter | Description | Example/Default setting |
event | Restricts what the index should wait for. The values all_finished and inverting_finished are valid:
| Example: mindbreeze.com:8443/index/23100/wait?event=all_finished |
update_interval | Sets a timeout after which an update is written. If this parameter is not set, the "Wait for Event Servlet Update Status Interval (seconds)" from the index configuration is used. The minimum interval is 5 seconds. Hint: The query is not runtime intensive, but the threads must be synchronised (lock mutex), therefore it is recommended to set this option as high as possible. | Example: mindbreeze.com:8443/index/23100/wait?update_interval=5 |
Index Status (/indexingstatus)
The servlet sends regular information about the indexing status of the documents in the index.
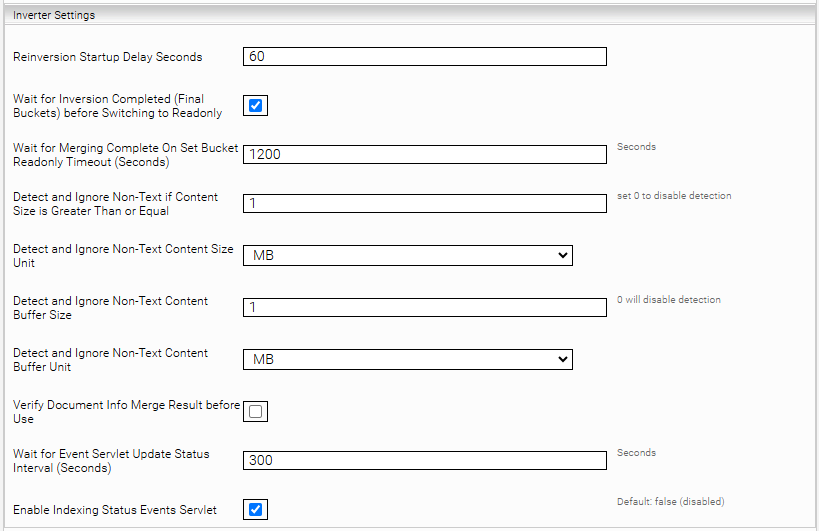
Attention: To use the “indexingstatus” servlet, the additional setting “Enable Indexing Status Events Servlet” must be activated. This setting can be found in the index if “Advanced Settings” are activated, in the “Inverter Settings” section. Activate the setting and save the change.
For more information, see Documentation - Mindbreeze InSpire - Index Service Settings.
You can reach the servlet with the following URL:
https://<Appliance>:8443/index/<IndexPortNr>/indexingstatus
The content type of the response is "text/event-stream" and is set in the header. The data is a sequence of text messages starting with “data“ followed by a JSON formatted message.
The messages are emitted when documents reach a new status. Currently, the following statuses are supported:
Status | Description |
LEVEL_SEARCHABLE | The document is stored, inverted and available for search and semantic search. |
LEVEL_SYNCED | In a Producer/Consumer setup, the document is “searchable” on at least some consumers. The number of consumers, where the document has to be “searchable” to fulfill this status, can be determined by the setting “Minimum Number of Successfully Synced Consumers Required for a Message”. This setting is by default set to 1. If there are no consumers, the documents are “synced” as soon as they are “searchable”. |
The emitted messages take the following form:
Message | Description | ||||
index | This message gives a summary of the status of some buckets of the index. It contains a field named “index”, whose value is a list of buckets, with information about their searchable documents.
| ||||
item | This message is emitted when new documents are searchable or synced, if no additional metadata are requested (see below). It contains a field named “item”, whose value contains a field named “itemHeaders”, whose value is a list of newly indexed documents (given with “key”, “category”, “category instance” and “document ID”). | ||||
detailedItem | This message is emitted when new documents are searchable or synced, if additional metadata are requested. This message contains a field named “detailedItem”, whose value contains a field named “items”. This field then contains a value that is a list of newly indexed documents. Each document in the list has a field named “header”, with the same value as above, and a field named “property”. The value of this field is a list of properties given by name and value. | ||||
idle | This message is sent after a period of inactivity, to make it easier for clients to keep the connection open. |
The following URL parameters can be used:
URL Parameter | Description | Example/Default setting |
level | Define the status level to wait for. The values LEVEL_SEARCHABLE and LEVEL_SYNCED are valid. | Example: ?level=LEVEL_SYNCED
LEVEL_SEARCHABLE |
requested_property | Add additional metadata to produce with the status notifications. This parameter can be repeated, if multiple metadata are requested. The metadata names should be URL-encoded if they contain non-alphanumeric characters. By default, the properties that can be requested are restricted to system metadata. A list for this can be found in the chapter Query Documents (/find). It is possible to override this list with the setting “Indexing Status Restricted Property Name Pattern”, which is a regular expression matching metadata that are authorized for request in the servlet. The requested metadata needs to be aggregatable. Aggregatable synthesized metadata are also available. | Example: ?requested_property=metadatum1&requested_property=metadatum2 Default setting: None |
idle_event_timeout_ms | Define the duration of the period after which an “idle” message is sent to keep the connection open. This is not resource intensive, you can set this value as low as necessary, in order for your SSE client to not automatically close the connection. | Example: ?idle_event_timeout_ms=10000 Default setting: 20,000 ms |
Example 1:
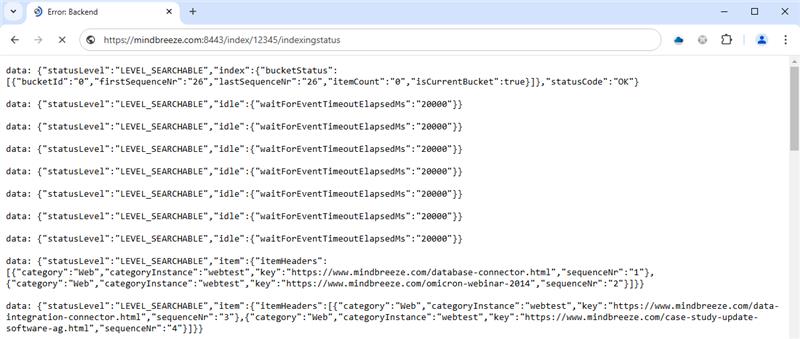
https://<Appliance>:8443/index/<IndexPortNr>/indexingstatus?idle_event_timeout_ms=20000
data: {"statusLevel":"LEVEL_SEARCHABLE","index":{"bucketStatus":[{"bucketId":"0","firstSequenceNr":"0","lastSequenceNr":"50","itemCount":"50","bucketNumber":"0", "isCurrentBucket":true}]},"statusCode":"OK"}
data: {"statusLevel":"LEVEL_SEARCHABLE","item":{"itemHeaders":[{"category":"Web","categoryInstance":"webtest","key":"https://www.mindbreeze.com/omicron-webinar-3","sequenceNr":"52"}]}}
data: {"statusLevel":"LEVEL_SEARCHABLE","item":{"itemHeaders":[{"category":"Web","categoryInstance":"webtest","key":"https://www.mindbreeze.com/reference-csc.html","sequenceNr":"54"},{"category":"Web","categoryInstance":"webtest","key":"https://www.mindbreeze.com/egovernment.html","sequenceNr":"56"}]}}
data: {"statusLevel":"LEVEL_SEARCHABLE","idle":{"waitForEventTimeoutEllapsedMs":"20000"}}
Example 2:
https://<Appliance>:8443/index/<IndexPortNr>/indexingstatus?idle_event_timeout_ms=20000&requested_property=mes%3Akey&requested_property=exampleprop
data: {"statusLevel":"LEVEL_SEARCHABLE","index":{"bucketStatus":[{"bucketId":"0","firstSequenceNr":"2","lastSequenceNr":"655","itemCount":"654","bucketNumber":"0","isCurrentBucket":true}]},"statusCode":"OK"}
data: {"idle":{"waitForEventTimeoutElapsedMs":"20000"}}
data: {"statusLevel":"LEVEL_SEARCHABLE","detailedItem":{"items":[{"header":{"category":"Web","categoryInstance":"Help","key":"document123","sequenceNr":"325"},"property":[{"name":"mes:key","value":[{"kind":"STRING","stringValue":"document123"},":[{"name":"exampleprop","value":[{"kind":"STRING","stringValue":"example value"}]}]}}
Example 3:
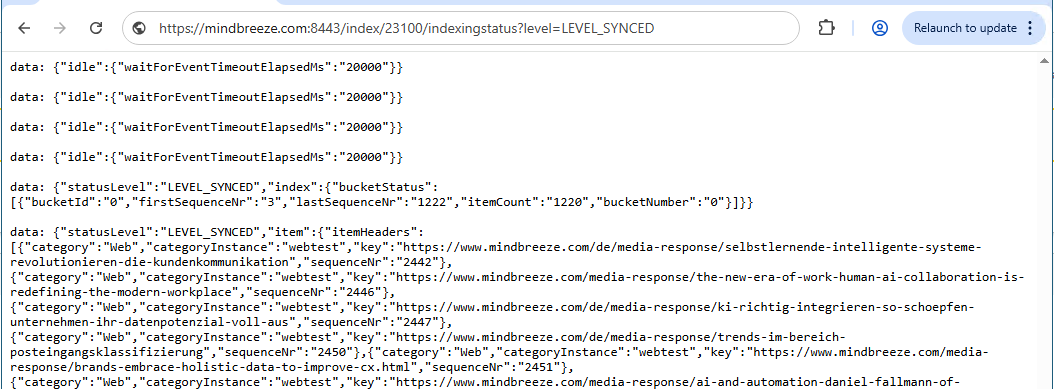
https://<Appliance>:8443/index/<IndexPortNr>/indexingstatus?level=LEVEL_SYNCED
data: {"idle":{"waitForEventTimeoutElapsedMs":"20000"}}
data: {"idle":{"waitForEventTimeoutElapsedMs":"20000"}}
data: {"statusLevel":"LEVEL_SYNCED","index":{"bucketStatus":[{"bucketId":"0","firstSequenceNr":"3","lastSequenceNr":"1222","itemCount":"1220","bucketNumber":"0"}]}}
data: {"statusLevel":"LEVEL_SYNCED","item":{"itemHeaders":[{"category":"Web","categoryInstance":"webtest","key":"https://www.mindbreeze.com/de/media-response/selbstlernende-intelligente-systeme-revolutionieren-die-kundenkommunikation","sequenceNr":"2442"},…]}}