
Sure, you can handle it. But should you?
Let our experts manage the tech maintenance while you focus on your business.
Let our experts manage the tech maintenance while you focus on your business.
Microsoft SharePoint Connector
Installation and Configuration
Tutorial Video: Set up a Microsoft SharePoint Connector
In our tutorial video you will find all necessary steps to set up the Microsoft SharePoint Connector:
https://www.youtube.com/watch?v=yzTyTz1SpXo
Installation
Before installing the Microsoft SharePoint Connector ensure that the Mindbreeze Server is already installed and this connector is included in the Mindbreeze license.
Needed Rights for Crawling User
The Microsoft SharePoint Connector allows you to index and search in Microsoft SharePoint items and objects.
The following requirements must be met before configuring a Microsoft SharePoint data source:
- The Microsoft SharePoint version used must be supported by Mindbreeze InSpire, see Product Information - Mindbreeze InSpire.
- For Kerberos Authentication the service user on the Fabasoft Mindbreeze Enterprise node with the SharePoint data source must have at least Full Read permissions on SharePoint Web Applications. Kerberos must be selected as authentication policy for these Web Applications.
- For Basic Authentication username and password of the account that has Full Read permission on SharePoint Web Applications should be provided in Mindbreeze Manager Configuration. Basic Authentication must be selected as authentication policy for these Web Application
Adding a user to the SharePoint site administrators can be done as follows:
- Navigate to Central Administration -> Application Management and then click on Manage web applications
- Select Web Application and then click on User Policy (see screenshot below)
- Give the service user “Full Read” permission.

Selecting authentication policy for Web Applications can be done as follows:
- Navigate to Central Administration -> Application Management and then click on Manage web applications
- Select Web Application and then click on Authentication Providers (see screenshot below)
- Choose desired authentication policy
- If NTLM or Basic authentication is selected, the username and password should be provided in Mindbreeze configuration. (See 2.1.1)
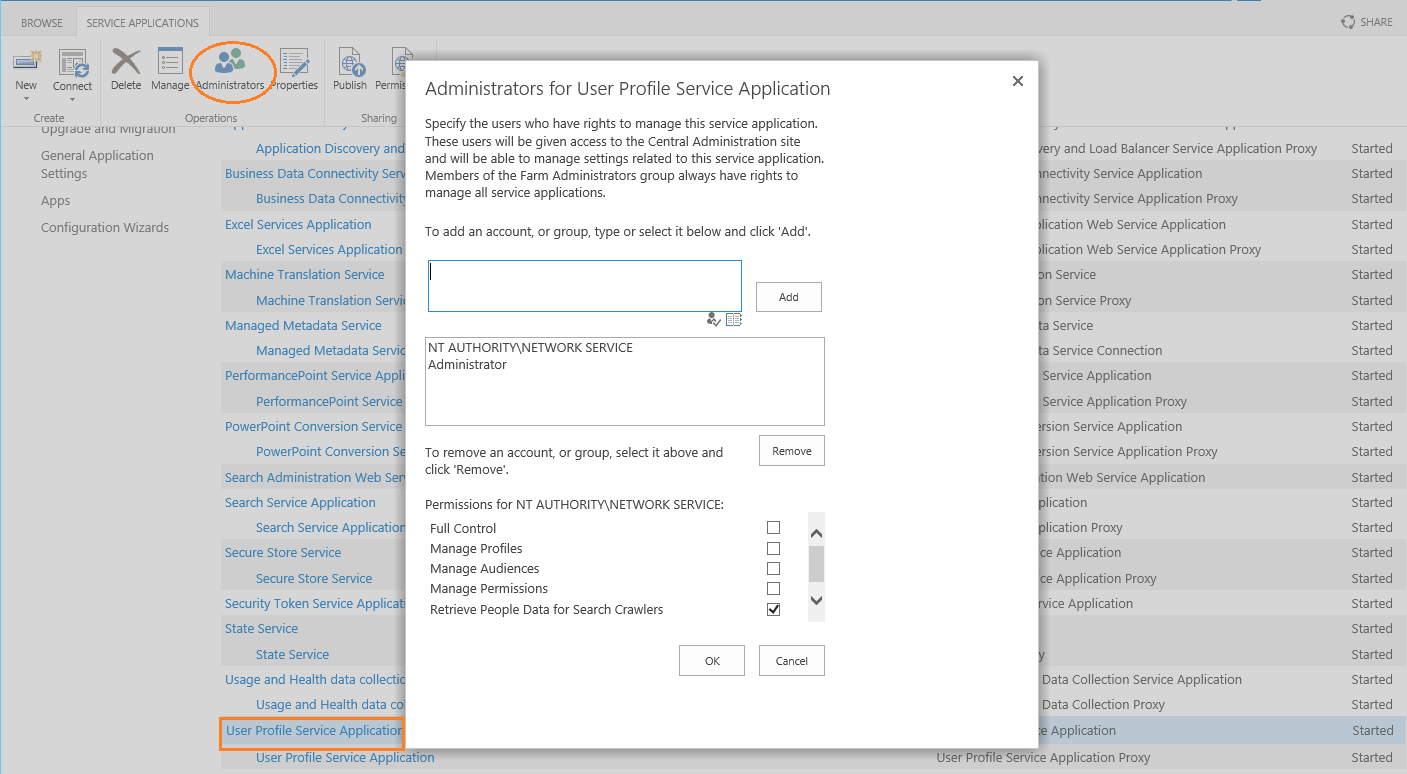
- In order to crawl user profiles in SharePoint 2013 the service user must be in the list of search crawlers of User Profile Service Application.
Navigate to Central Administration Manager service application User Profile Service Application:

Installation of Services for SharePoint
The services for SharePoint must be installed as follows:
- Login to the SharePoint server whose sites are to be crawled by the connector.
- Go to the ISAPI directory of SharePoint. If you are using the standard default installation, path of this directory would be C:\Program Files\Common Files\Microsoft Shared\web server extensions\14\ISAPI (SharePoint 2010) and C:\Program Files\Common Files\Microsoft Shared\web server extensions\15\ISAPI (SharePoint 2013).
- Download the "Mindbreeze Microsoft SharePoint Connector.zip" from https://www.mindbreeze.com/inspire-updates.html . Among other things, the ZIP contains the prerequisites (prerequisites). Copy these files from the MicrosoftSharePointConnector-{{version}}-prerequisites.zip into the ISAPI directory (see step 2).
- GSBulkAuthorization.asmx
- GSBulkAuthorizationdisco.aspx
- GSBulkAuthorizationwsdl.aspx
- GSSiteDiscovery.asmx
- GSSiteDiscoverydisco.aspx
- GSSiteDiscoverywsdl.aspx
- GssAcl.asmx
- GssAcldisco.aspx
- GssAclwsdl.aspx
- MesAcl.asmx
- MesAcldisco.aspx
- MesAclwsdl.aspx
- MesLists.asmx
- The connectivity of web services can be verified using following URLs:
http://mycomp.com/_vti_bin/GSBulkAuthorization.asmx
http://mycomp.com/_vti_bin/GSSiteDiscovery.asmx
http://mycomp.com/_vti_bin/GssAcl.asmx
Where http://mycomp.com is the SharePoint site URL. After opening the above URL(s), you should be able to see all the web methods exposed by the web service.
Installation of SharePoint SSL Certificate for Java
Save the SharePoint SSL certificate in for example c:\temp\sharepointserver.cer file:

Installation:
<jre_home>/binkeytool -import -noprompt -trustcacerts -alias sharepointserver –file /tmp/sharepointserver.cer -keystore ../lib/security/cacerts –storepass changeit
Configuration of Mindbreeze
Click on the “Indices” tab and then on the “Add new index” symbol to create a new index.
Enter the index path, e.g. “/data/indices/sharepoint”. Change the Display Name of the Index Service and the related Filter Service if necessary.

Add a new data source with the symbol “Add new custom source” at the bottom right.

Configuration of Data Source
Microsoft Sharepoint Connection
This information is only needed when basic authentication is used:
- “SharePoint Server URL“: To crawl all sharepoint sites this URL can be without port and site path, which will cause that alle sharepoint sites will be crawled. For example “http://myorganization.com” would cause that all sharepoint sites with “http://myorganization.com:<any port>/<any site>” URL will be crawled. The needed credentials must be configured in Network tab under Endpoints. The “Location” Field of the Endpoint and “SharePoint Server URL” must be identical.
- Logon Account For Principal Resolution, Domain and Password: These fields should not be configured if a “Principal Resolution Cache Service” is selected or in case of Kerberos authentication.
If the Sharepoint Principal Cache is used, it is possible to configure credential information in the Network tab (section Endpoints).

Setting | Description |
Use Claims | This additionally adds the claims to ACLs. If Auto is selected, claims are added to ACLs only when the Use WS-Federation Authentication option is enabled. |
Use WS-Federation Authentication |
|
WS-Federation Authentication Token Renewal Interval | After this interval the FedAuth cookies renewed and used for authentication to SharePoint server. |
Webservice Timeout (seconds) | Timeout for SharePoint Webservice calls on client side. Additional timeout configurations like in IIS, SharePoint Site web.config and load balancer should also be considered if connector fails because of connection timeouts. |
Caching Principal Resolution Service
You can select one of the following three caching principal resolution services to be used.
CachingLdapPrincipalResoution: If selected, it is used to resolve a user’s AD group membership when searching. However, the SharePoint groups in the ACLs must be resolved while crawling. To do this, select "Resolve SharePoint Groups”. Do not select “Use ACLs References”. “Normalize ACLs” can be selected. For details on configuring the caching principal resolution service, see Caching Principal Resolution Service.

SharePointPrincipalResolutionCache: If selected, it is used to resolve a user’s SharePoint group membership when searching. This service also resolves the user’s AD group membership. Therefore, it is no longer necessary to select "Resolve SharePoint Groups". Do not select "Use ACLs References” in this case. “Normalize ACLs” can be selected (Also see section Configuration of SharePointPrincipalCache).

SharePointACLReferenceCache: When selected, the URLs from the SharePoint site, SharePoint list, and folder of the document are saved as ACLs during crawling to speed up the crawl. “Use ACLs References" must be selected in this case. “Resolve SharePoint Groups” and “Normalize ACLs” may not be selected (Also see section Configuration of SharepointACLReferenceCache).

Crawl URLs
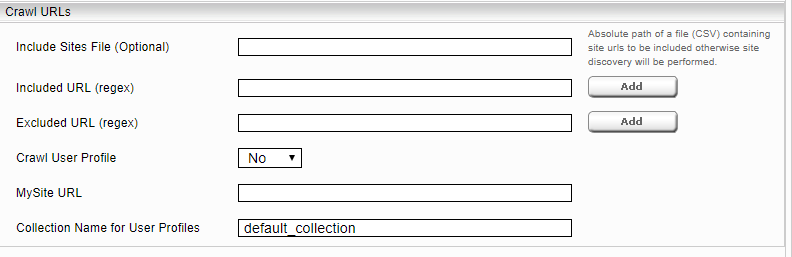
The SharePoint crawler initially detects all SharePoint sites of a SharePoint server “SharePoint Server URL.” Alternatively, you can enter the path of a CSV file in the field “Include Sites File”, in which only certain sites (URLs) that should be indexed are entered. It is also possible to limit the data to be crawled to specific pages (URLs). To do this, you can restrict these pages (URLs) with a regular expression in the field "Included URL". It is also possible to exclude pages (URLs) or not to crawl certain pages. These pages must be restricted to the field "Excluded URL" with a regular expression. A regular expression must have a "regexp:" or "regexpIgnoreCase:" prefix.
For crawling user profiles,"Crawl User Profile" must be selected and the "MySite URL" and "Collection Name for User Profiles" must be configured accordingly.
Sites Restrictions
Please note that the following restrictions apply after using “Include URL” and “Exclude URL”. This means that a site URL that is excluded by applying the "Exclude URL" rule will not be crawled even if it is in the "Include Sites File".

Setting | Description |
All Sites File | The path to a CSV file containing the site URLs that are to be crawled. The first line should be URL and other lines should SiteCollection URLs. If this field is empty, all sites are detected by the SiteDiscovery service. |
Include Sites File | The path to a CSV file containing the site URLs that are to be crawled without the congruence class calculation, which can lead to an exclusion of the site. If this field is empty, only those sites are crawled that correspond to the congruence class of this crawler and do not exist in the "Exclude Sites File" file. |
Exclude Sites File | The path to a CSV file containing the site URLs that are not crawled. If this field is empty, the sites that correspond to the congruence class of this crawler or exist in the "Include Sites File" are crawled. |
Congruence Modulus | The maximum number of crawlers that distribute all sites among themselves. |
Congruence Class | Only sites with this congruence class (CRC of the site URL modulo maximum number of crawlers) are crawled. |
Security Settings
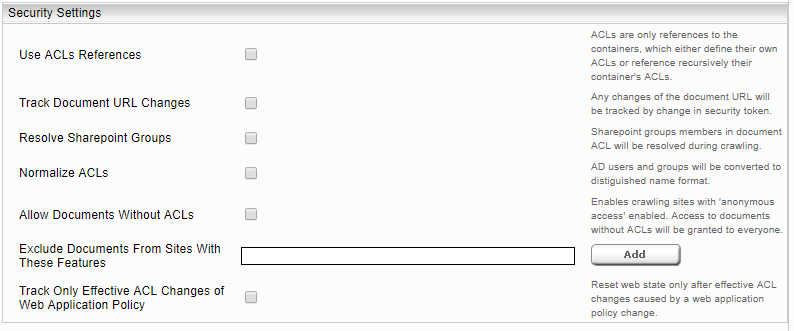
The option "Use ACLs References" should only be selected if "SharePointACLReferenceCache" is selected as the "Principal Resolution Service Cache" (see: Configuration of SharepointACLReferenceCache).
Moving documents from one directory to another also changes the URLs of these documents. To update these changes in the index, select the “Track Document URL Changes” option.
If “Track Only Effective ACL Changes of Web Application Policy” option is not selected any change in the permissions of web application policy (changing permission from Full Read to Full Control for a user) which may not effectively change granting permission in Mindbreeze will cause recrawling and rechecking of ACLs of all documents in all sites of that web application.
The option "Resolve SharePoint Groups" should not be selected if "SharePointPrincipalCache" is selected as the "Principal Resolution Service Cache" (see: Configuration of SharePointPrincipalCache). By configuring “Normalize ACLs,” all AD users and groups are converted to ACLs in “Distinguished Name” format. To crawl SharePoint pages with anonymous access rights, select "Include Documents without ACLs". If you want to exclude SharePoint pages from crawling by activating certain features, it is necessary to enter the ID (GUID) of these features in the field "Exclude Documents From Sites With These Features".
Alias URLs Mapping
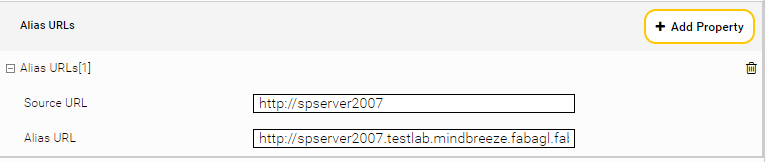
In order to provide documents with open URLs according to „Alias URLs“ configuration the „Rewrite Open URL“ must be selected. If the service user has not access to internal download URLs of documents. These URLs can be rewritten by URLs configured in „Alias URLs“ configuration.

The external URLs in SharePoint Alternative Access Mapping configuration should be in FQDN format:
Content Type Settings
A regular expression pattern to match additional content types is needed in “Additional Content Types (regex)” field in order to crawl content type which are not crawled per default
For crawling documents with unpublished state select “Enabled” from “Include Unpublished Documents” dropdown list and “Last Major Version” for crawling last major version of unpublished documents. Make sure that at least version 20.3 of the prerequisites (includes MesLists.asmx) is installed on the SharePoint Server.
The SharePoint Connector contains a preconfigured content mapping file (XML) which provides necessary rules to be applied on documents according to their content type. Sometimes it is necessary to change these rules and save this mapping file in separate location. In order to use this modified mapping file it is necessary to write this file’s location in “Content Type Mapping Description File”. One of the important rules in this mapping file is to include or exclude documents with some specific content types. By selecting “Delete Ignored Documents from Index” the documents already crawled with a different mapping rules will be deleted from index if they are not included anymore.
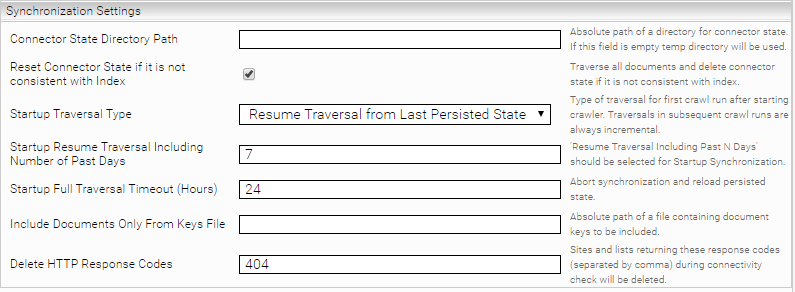
Synchronization Settings

Setting | Description |
Connector State Directory Path | The path to a directory in which the crawler persists the status of the documents already indexed, which is used after a crawl run or restart of the crawler. If this field is empty, a directory is created in /tmp. |
Reset Connector State if it is not consistent with index | If the crawler status is not consistent with the index status, it is deleted and a full indexing run is started. If this option is disabled, the status will not be deleted. |
Startup Traversal Type | The crawler stores its status from the last run locally. This avoids matching individual documents in the index with those on the Sharepoint Server. Sometimes this status can deviate from the index due to transport or filter problems. To correct this deviation, select the “Full Traversal” option or “Resume Travesal Including Past N Days” and configure “Startup Resume Traversal Including Number of Past Days” accordingly if “Full Travesal” is not necessary. |
Startup Resume Traversal Including Number of Past Days | |
Startup Full Traversal Timeout (Hours) | Specifies a number of hours for synchronization. After this amount of time, the crawler is aborted and the stored state is reused. |
Include Documents Only From Keys File | The path to a CSV file with the keys that are to be indexed again. This means only these documents from SharePoint are crawled and indexed. We recommend backing up the “Connector State” directory beforehand. |
Delete HTTP Response Codes | At the end of a crawl run, all sites and lists that supply these HTTP response codes after HTTP access (connectivity check) are also deleted from the index. |
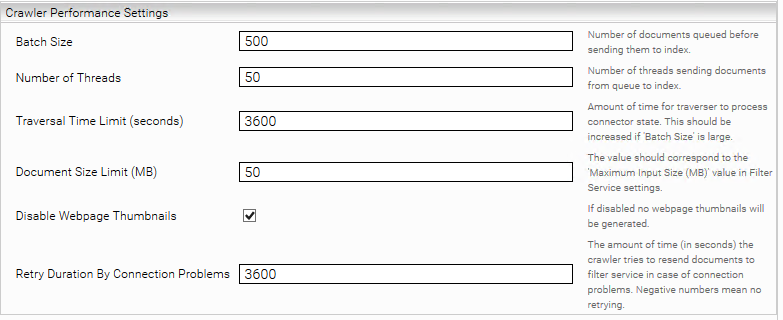
Crawler Performance Settings

Setting | Description |
Bach Size | Defines the number of documents that the SharePoint server retrieves before sending them to the index. |
Number of Threads | Threads that send the collected documents to the index simultaneously. |
Traversal Time Limit (seconds) | |
Document Size Limit (MB) | This value must correspond to “Maximum input size (MB)” from the filter service. |
Disable Webpage Thumbnaiils | If selected, no thumbnails are generated for these pages. |
Retry Duration On Connection Problems (Seconds) | The maximum number of seconds that the system will attempt to resend a document to the filter/index service in the event of connection problems or during syncdelta. |
Content Metadata Extract Settings
To extract metadata from HTML content the following configuration is needed.
Setting | Description |
Display Date Timezone | |
Extract Metadata | |
Name | Defined name for the metadata. |
XPath | XPath locating the metadata value in content. |
Format | String, URL, Path, Number, Signature and Date. |
Format Options | Format options, for example for the date the Simpledateformat. |
Debug Settings
Contains settings for diagnostic purposes.
Setting | Description |
Threads Dump Interval (Minutes) | Specifies the time interval (in minutes) at which regular thread dumps are created inside the log directory. A value less than 1 disables the function. (Default value: -1) |
Editing Microsoft Office Documents in SharePoint
When opening Office documents from the search result in Internet Explorer, the opened documents can be edited and saved in SharePoint. This requires write permissions to the document. When using other browsers, the documents are opened read-only.
Configuring the integrated Authentication of the Microsoft SharePoint Crawler
Windows:
If the installation is made on a Microsoft Windows Server, the Kerberos authentication of the current Mindbreeze Service user can also be used for the Microsoft SharePoint Crawler. In this case, the Service user must be authorized to access the Microsoft SharePoint Web Services.
Linux:
Find the documentation for Linux here: Configuration - Kerberos Authentication
Caching Principal Resolution
In the following chapters the configuration of SharepointPrincipalCache and SharePointACLReferenceCache will be explained. For more information about additional configuration options and how to create a cache and how to do the basic configuration of a cache for a Principal Resolution Service, see Installation & Configuration - Caching Principal Resolution Service.
Configuration of SharepointPrincipalCache
- In the new or existing service, select the SharepointPrincipalCache option in the Service setting.

- Specify the “SharePoint Server URL”. Configure the required login information in the Network tab under Endpoints. The “Include URL” and “Excluded Sites URL” fields should be the same as the crawler fields of the same name.
Use Claims allows you to add additional claims to Sharepoint group members. When Auto is selected, claims are only added when the Use WS-Federation Authentication option is selected. - Use WS-Federation Authentication allows federation authentication cookies from SharePoint (ADFS) with the given credentials to be generated and used for authentication to the SharePoint server.
- https://blogs.technet.microsoft.com/askpfeplat/2014/11/02/adfs-deep-dive-comparing-ws-fed-saml-and-oauth/
- https://msdn.microsoft.com/en-us/library/bb498017.aspx
Using WS-Federation Authentication Token Renewal, you can configure the interval for the renewal of federation authentication cookies. - Webservice Timeout (seconds) enables configuration timeout for SharePoint Webservice calls on client side. Additional timeout configurations like in IIS, SharePoint Site web.config and load balancer should also be considered if connector fails because of connection timeouts.

- In the “LDAP Persisted Cache Service Port” field, enter the previously configured “Web Service Port” of the LDAP Principal Resolution Service. In the SharePoint Crawler configuration, the option “Resolve SharePoint Groups” should not be selected. For details on configuring the caching principal resolution service , see Caching Principal Resolution Service.

- The option “SharePoint Site Groups Resolution Threads” configures the number of threads that find the SharePoint Site Groups of the sites at the same time. The “SharePoint Site Group Members Resolution And Inversion Threads” option specifies the number of threads that SharePoint Group members will find parallel to each other. The “Suppress External Service Calls” option prevents external services such as LDAP or SharePoint from being queried during the search if no SharePoint groups are found in the cache for a user. For further configuration parameters see: Caching Principal Resolution Service.




- It is possible to save the SharePoint groups of only certain specific sites by using the following parameters.
- All Sites File: The path to a CSV file containing the site URLs that are to be crawled. If this field is empty, all sites are detected by the Site Discovery service.
- Include Sites File: The path to a CSV file containing the site URLs that are to be crawled.
- Exclude Sites File: The path to a CSV file containing the site URLs that should not be crawled.

LDAP Settings

Setting | Description |
Use LDAP Principals Cache Service | If this option is enabled, the group memberships from the parent cache are calculated first and the results are passed to the child cache. This allows the current cache to use the results of the parent cache for lookups. |
LDAP Principals Cache Service Port | The port used for the "Use LDAP Principals Cache Service" option if enabled. |
Configuration of SharepointACLReferenceCache
- In the new or existing service, select the SharepointACLReferenceCache option in the Service setting:
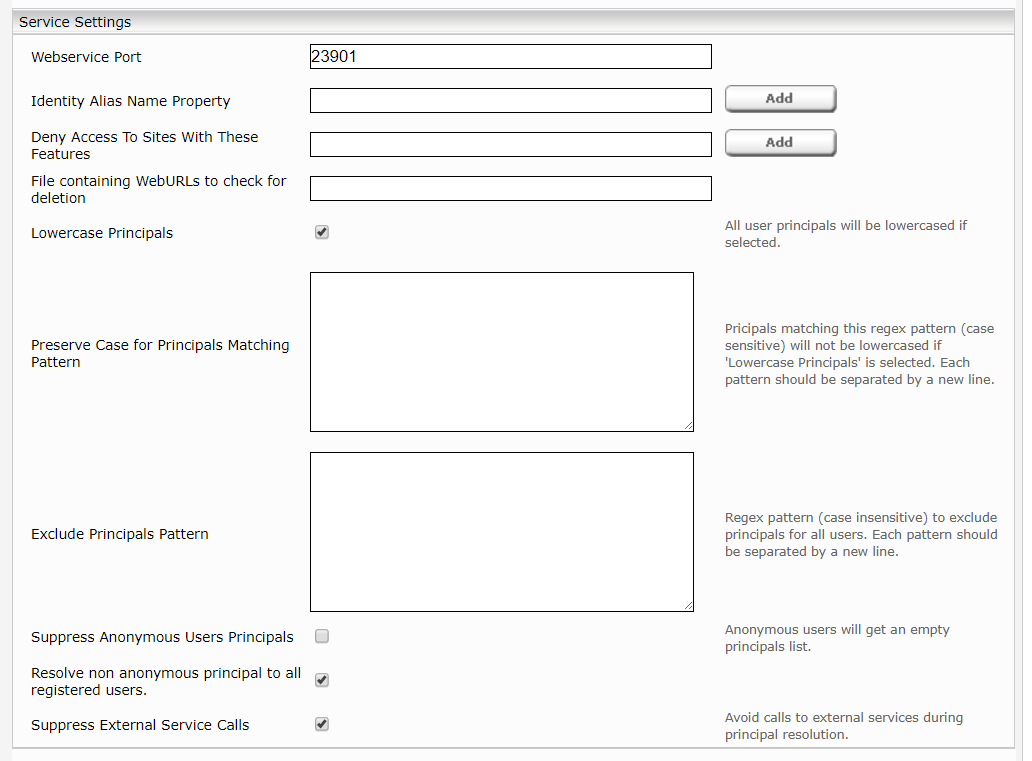
- Specify the “SharePoint Server URL”. Configure the required login information in the Network tab under Endpoints. “Include Sites File”, “Include URL”, “Excluded Sites URL”, “Exclude Sites With These Features”, and “Resolve SharePoint Groups” can only be selected if the port of “CachingLdapPrincipalResolution” service is entered in the “Parent Service Port.” The “Normalize ACLs” field should then be configured as in the crawler.
Use Claims allows the claims in ACLs to be added as well. When Auto is selected, claims are added to ACLs only when the Use WS-Federation Authentication option is checked. - Use WS-Federation Authentication allows federation authentication cookies from SharePoint (ADFS) with the given credentials to be generated and used for authentication to the SharePoint server.
https://msdn.microsoft.com/en-us/library/bb498017.aspx
- WS-Federation Authentication Token Renewal Interval allows federation authentication cookies to be renewed after this interval.
- Webservice Timeout (seconds) enables configuration timeout for SharePoint Webservice calls on client side. Additional timeout configurations like in IIS, SharePoint Site web.config and load balancer should also be considered if connector fails because of connection timeouts.

- You can use the following parameters to save the SharePoint ACLs of only certain sites.
- All Sites File: The path to a CSV file containing the site URLs that are to be crawled. If this field is empty, all sites are detected by the Site Discovery service.
- Include Sites File: The path to a CSV file containing the site URLs that are to be crawled.
- Exclude Sites File: The path to a CSV file containing the site URLs that should not be crawled.
- In the “Parent Service Port” field, enter the previously configured “Web Service Port” of the SharePointPrincipalCache service. If "Resolve SharePoint Groups" is selected in the crawler, the CachingLdapPrincipalResolution Service Port can be used here and the option "Resolve SharePoint Groups" must be selected.

Database Settings
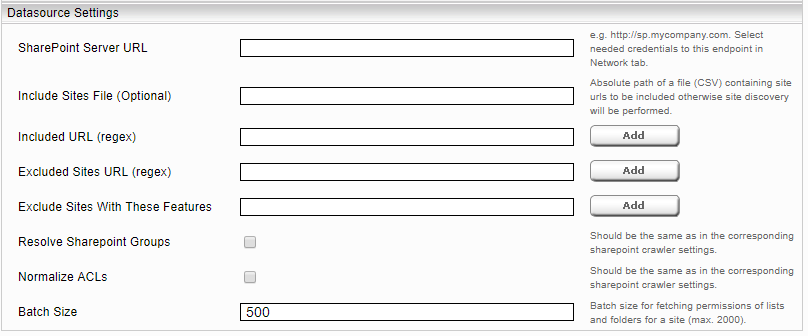
Setting | Description |
Identity Encryption Credential | This option allows you to display the user identity in encrypted form in app.telemetry. |
Cache In Memory Items Size | Number of items stored in the cache. Depends on the available memory of the JVM. |
Database Directory Path | Defines the directory path for the cache. Example: /data/principal_resolution_cache If a Mindbreeze Enterprise product is used, a path must be set. If a Mindbreeze InSpire product is used, the path must not be set. If the directory path is not defined, the following path is defined under Linux: /data/currentservices/<server name>/data. |
Group Members Resolution And Inversion Threads | This option determines the number of threads that will resolve group members at the same time and invert those groups. Values less than 1 are assumed to be 1. |
In-Memory Containers Inversion Threshold (Advanced Setting) | This option sets the maximum number of groups. If this number is exceeded, further RAM consumption during inversion is avoided by using hard drives. |
Troubleshooting
Generally, if you are having troubles indexing a SharePoint data source you should primarily look at the Mindbreeze log-folders.
Inside the Mindbreeze base log-folder there is also a sub-folder for the SharePoint-crawler located which is called similar to the following example:
C:\logs\current\log-mescrawler_launchedservice-Microsoft_SharePoint_Sharepoint+2007
This folder will contain several date-based sub-folders each containing two main log files:
- log-mescrawler_launchedservice.log: basic log file containing relevant information about what is going on as well as possible error messages occurred during crawling the data source.
- mes-pusher.csv: CSV-file containing the SharePoint-URLs that have been crawled including status information about success or errors.
If the file mes-pusher.csv does not appear, there may be basic configuration or permission troubles preventing the crawler from retrieving documents from SharePoint, which should be recorded in the base log file mentioned above.
Crawling User Unauthorized
Problem Cause:
The crawler does not retrieve any documents from SharePoint and therefore does not create the log file mes-pusher.csv.
The log file log-mescrawler_launchedservice.log may contain error message similar to the following ones:
com.mindbreeze.enterprisesearch.gsabase.crawler.InitializationException: Invalid connector config: message Cannot connect to the given SharePoint Site URL with the supplied Domain/Username/Password.Reason:(401)Unauthorized
Or:
com.mindbreeze.enterprisesearch.gsabase.crawler.InitializationException: Unable to set connector config, response message: Cannot connect to the Services for SharePoint on the given Crawl URL with the supplied Domain/Username/Password.Reason:(401)Unauthorized, status message:null, status code:5223 (INVALID_CONNECTOR_CONFIG)
Or:
enterprise.connector.sharepoint.wsclient.soap.GSBulkAuthorizationWS INTERNALWARNING: Can not connect to GSBulkAuthorization web service. cause:(401)Unauthorized
Problem description and solution:
The used service user is not allowed to obtain the file listings from SharePoint. Either because the login fails or the permissions inside SharePoint are not enough.
The following issues have to be checked:
- Check the user authentication method configured inside SharePoint/IIS:
- If you are using Integrated/Kerberos authentication, the Mindbreeze Node service must be configured to run as the service user.
- For NTLM/Basic authentication, the service user must be configured in the Mindbreeze Configuration UI der SharePoint Data Source.
- Check the permissions of the service user inside SharePoint
- Test the following web services GssSiteDiscovery.asmx and GSBulkAuthorization.asmx (for details see below)
- You should also verify a simple open of SharePoint document-pages or content documents from a web browser on the Mindbreeze server using the service account.
FQDN
Problem:
The crawler does not retrieve any documents from Microsoft SharePoint and therefore does not create the log file mes-pusher.csv.
The log file log-mescrawler_launchedservice.log may contain an error message similar to the following:
com.mindbreeze.enterprisesearch.gsabase.crawler.InitializationException: Unable to set connector config, response message: The SharePoint Site URL must contain a fully qualified domain name., status message:null, status code:5223 (INVALID_CONNECTOR_CONFIG)
Problem description and solution:
In order to use the Mindbreeze SharePoint Connector it is important that the target SharePoint server is accessed using the FQDN-hostname.
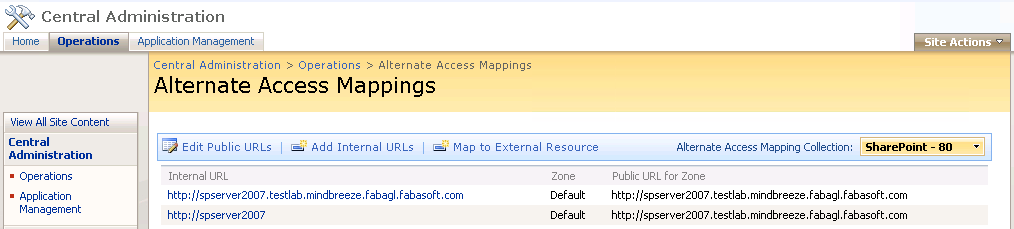
- Either in the SharePoint configuration the external URL must be configured correctly to the FQDN-hostname (see SharePoint „Operations“ > group „Global Configuration“ > „Alternate access mappings“)
- Also, in the Mindbreeze configuration, the external (FQDN) URL must be defined as crawling root.
Alternative Access Mapping
Problem:
The error "ACL Change Detection failed" is displayed during the first crawl in SharePoint. Usually, this means that the search crawler has problems reading or detecting the permissions (Access Control Lists, ACLs) on the content correctly.
The log file log-mescrawler_launchedservice.log may contain an error message similar to the following:
enterprise.connector.sharepoint.wsclient.soap.GSAclWS INTERNALWARNING: ACL change detection has failed. endpoint [ https://spse.testlab.mindbreeze.fabagl.fabasoft.com:28443/sites/mindbreeze/_vti_bin/GssAcl.asmx ]. cause:Server was unable to process request. ---> The Web application at https://spse.testlab.mindbreeze.fabagl.fabasoft.com:28443/sites/mindbreeze could not be found. Verify that you have typed the URL correctly. If the URL should be serving existing content, the system administrator may need to add a new request URL mapping to the intended application.
Problem description and solution:
In the SharePoint configuration, a public URL must be configured for the URL that is used by the crawler, which is ideally assigned to the “Default” zone or a specially configured zone (e.g., Custom):

Testing SharePoint Web Services with SOAP-Calls and curl
In order to analyze and solve permission problems or other problematic issues regarding the SharePoint web services you could use the command line tool curl to perform simple SOAP-calls.
The command line tool curl is already present on Mindbreeze InSpire (for Microsoft Windows) and is located in the following folder: C:\setup\tools\curl\bin. For a more convenient utilization, you should add the folder path value to the Microsoft Windows environment variable PATH.
The procedure of preparing the SOAP-Calls is quite similar for every test case and will be explained based on following example: CheckConnectivity from GSSiteDiscovery.asmx
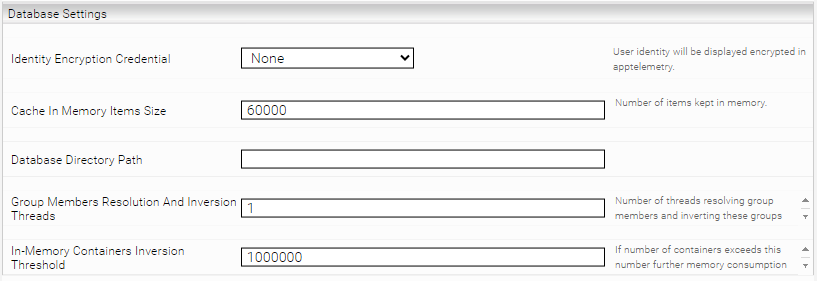
The first step is to open the desired SharePoint web service in a web browser window and follow the link to the desired action method to get the interface description and the template for the content to be sent later on.
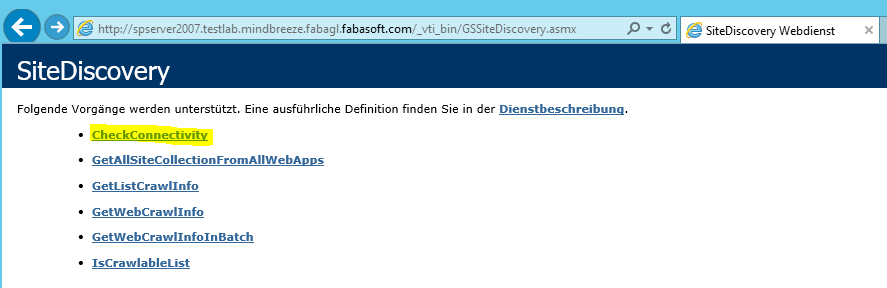
For simplicity, we take the interface description based on SOAP 1.2 and copy the XML-content of the first block (request part) into a file in a local temporary folder (e.g. C:\Temp\sp-site-check.xml).
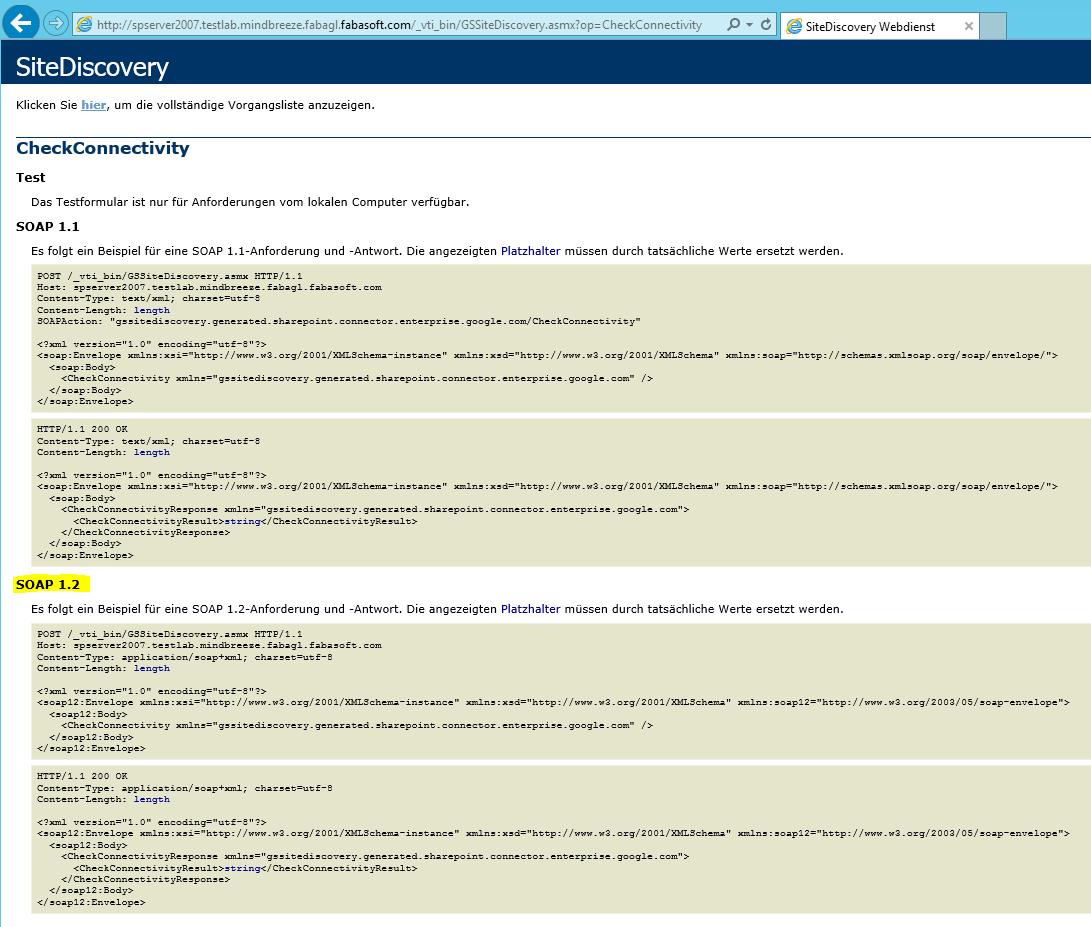
Based on the interface definition some property values must be replaced by custom values from the own SharePoint infrastructure.
Based on the previous example will are now going to test the SOAP calls using curl in a command line window.
Switch to the file system folder containing the prepared XML content file and run the curl-command similar to the following example: (<Values in angle brackets> have to be replaced with own values)
C:\Temp>curl --ntlm --user <testlab\domainsrv>:<MYPASSWORD> --header "Content-Type: application/soap+xml;charset=utf-8" --data @<sp-site-check.xml> http://<spserver2007.testlab...>/_vti_bin/GSSiteDiscovery.asmx
The output will be displayed directly or could also be redirected for easier reading into an output file: > out.xml
The following SharePoint web services and methods are quite useful for detecting problems:
- http://<spserver2007.testlab>/_vti_bin/GSSiteDiscovery.asmx
- CheckConnectivity: should return success
- GetAllSiteCollectionFromAllWebApps: requires a SharePoint admin account!
- http://<spserver2007.testlab>/_vti_bin/GSBulkAuthorization.asmx
- CheckConnectivity: should return success
- http://<spserver2007.testlab>/Docs/_vti_bin/GssAcl.asmx (this test should be invoked on the subdirectory URL containing the SharePoint-documents - e.g.: /Docs)
- CheckConnectivity: should return success
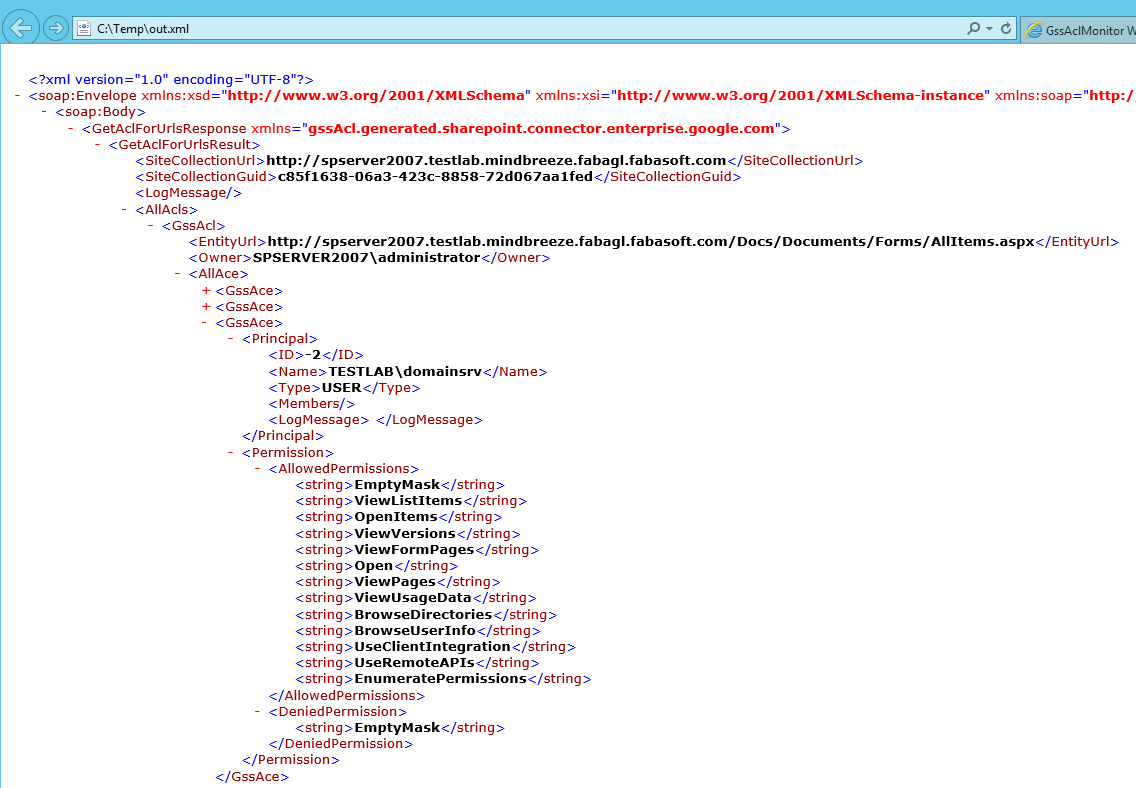
- GetAclForUrls: this is the first test requiring to change the content XML file (see below) … you could specify the URL to the basic documents overview page e.g. AllItems.aspx, or the SharePoint URL of a chosen document. This test should return all permitted user accounts for the chosen documents …
GetAclForUrls Content-XML:
<?xml version="1.0" encoding="utf-8"?>
<soap12:Envelope xmlns:xsi="http://www.w3.org/2001/XMLSchema-instance" xmlns:xsd="http://www.w3.org/2001/XMLSchema" xmlns:soap12="http://www.w3.org/2003/05/soap-envelope">
<soap12:Body>
<GetAclForUrls xmlns="gssAcl.generated.sharepoint.connector.enterprise.google.com">
<urls>
<string>http://spserver2007.testlab.mindbreeze.fabagl.fabasoft.com/Docs/Documents/Forms/AllItems.aspx</string>
<string>http://spserver2007.testlab.mindbreeze.fabagl.fabasoft.com/Docs/Documents/testdoc2_server2007.rtf</string>
</urls>
</GetAclForUrls>
</soap12:Body>
</soap12:Envelope>
SOAP-Call with curl:
C:\Temp>curl --ntlm --user <testlab\domainsrv>:<MYPASSWORD> --header "Content-Type: application/soap+xml;charset=utf-8" --data @data.xml http://spserver2007.testlab.mindbreeze.fabagl.fabasoft.com/Docs/_vti_bin/GssAcl.asmx > out.xml
The result shows all SharePoint-permissions for the specified URLs:

The documents are retrieved correctly from SharePoint by the crawler (as listed in the main log file) but are still not inserted into the index you should check the following log file mes-pusher.csv.
If the column ActionType contains the value „IGNORED“ there is another column called Message showing the cause why the document was ignored.
Possible causes and solutions:
- IGNORED, property ContentType with value null not matched pattern …
- Some basic document content types are already predefined in the standard SharePoint connector. However, your SharePoint installation may use other content types for documents you also want to be indexed. You could extend the list of indexed document types by simply defining your own list of content types in the following property of the Mindbreeze Configuration: “Additional Content Types“
- Unable to generate SecurityToken from acl null
- If the crawler is not able to obtain the current ACLs for a given document from SharePoint, this document will be ignored and not sent to the index for further processing. In this case, you have to check if the permissions of the service user are enough and you could also test the SharePoint web service gssAcl.asmx on behalf of the used service user (as already described above).
Configuration of Metadata Conversion Rules in the File: ConnectorMetadataMapping.xml
The following examples show, how Rules in the file ConnectorMetadataMapping.xml can be used to generate metadata from existing metadata.
Content XPath Konfiguration
<ConversionRule class="HTMLContentRule">
<Arg>//*[@id='ArticleContent'] </Arg> <!-- include XPath -->
<Arg>//*[starts-with(@id, 'ECBItems_']</Arg> <!-- exclude XPath -->
</ConversionRule>
References
<Metadatum join="true">
<SrcName>srcName</SrcName> <!—srcName should be item ID -->
<MappedName>mappedRef</MappedName>
<ConversionRule class="SharePointKeyReferenceRule">
<Arg>http://site/list/AllItems.aspx|%s</Arg>
</ConversionRule>
</Metadatum>
String Formatting
Joining Metadata:
<Metadatum join="true">
<SrcName>srcName1,srcName2</SrcName> <!—join values with ‘|’ -->
<MappedName>mappedName</MappedName>
<ConversionRule class="FormatStringRule">
<Arg>%s|%s</Arg>
</ConversionRule>
</Metadatum>
Splitting Metadata:
<Metadatum split="true">
<SrcName>srcName</SrcName>
<MappedName>mapped1,mapped2</MappedName> <!-- split srcName value -->
<ConversionRule class="SplitStringRule">
<Arg>:</Arg>
</ConversionRule>
</Metadatum>
Generation of Metadata using regular Expressions:
<Metadatum>
<SrcName>srcName</SrcName>
<MappedName>mappedName</MappedName>
<ConversionRule class="StringReplaceRule">
<Arg>.*src="([^"]*)".*</Arg> <!—regex pattern-->
<Arg>http://myorganization.com$1</Arg> <!-- replacement -->
</ConversionRule>
</Metadatum>