
Sure, you can handle it. But should you?
Let our experts manage the tech maintenance while you focus on your business.
Let our experts manage the tech maintenance while you focus on your business.
Web Connector
Installation and Configuration
Copyright ©
Mindbreeze GmbH, A-4020 Linz, .
All rights reserved. All hardware and software names used are registered trade names and/or registered trademarks of the respective manufacturers.
These documents are highly confidential. No rights to our software or our professional services, or results of our professional services, or other protected rights can be based on the handing over and presentation of these documents.
Distribution, publication or duplication is not permitted.
The term ‘user‘ is used in a gender-neutral sense throughout the document.
Video Tutorial „Set up a basic Web Connector”
This video describes how to configure a basic Web Connector to index a website for both with and without a sitemap: https://www.youtube.com/watch?v=-Le3J0NOoMI
Configuration of Mindbreeze
Configuration of Index and Crawler
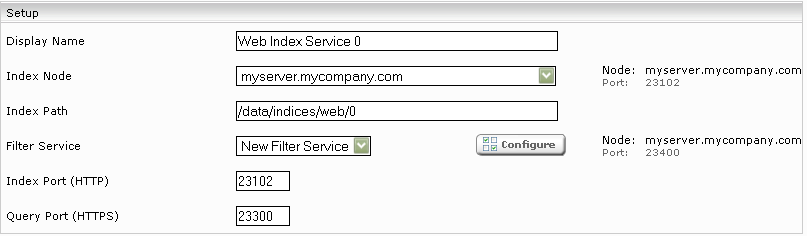
Click on the “Indices” tab and then on the “Add new index” symbol to create a new index.

Enter the index path, e.g. “C:\Index”. Adapt the Display Name of the Index Service and the related Filter Service if necessary
Add a new data source with the symbol “Add new custom source” at the bottom right.
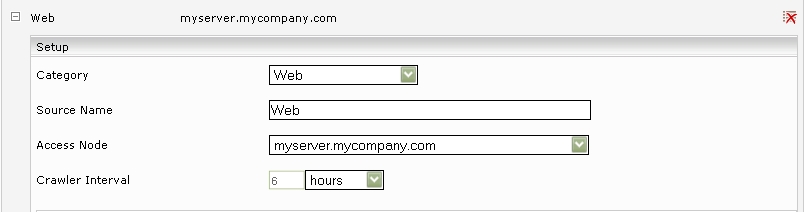
If necessary, choose “Web” in the “Category” field. With the “Crawler Interval” setting you are able to configure the interval between two crawl runs.
Web Page
You can specify a regular expression for the links to follow with the field “URL Regex”. If you leave the field empty, all pages with the same host and domain parts as the “Crawling Root” will be indexed (e.g. de.wikipedia.org when the “Crawling Root” is http://de.wikipedia.org).
You can also specify a pattern for the URLs that need to be excluded using the “URL Exclude Pattern” field. The URLs matched by this pattern will not be crawled and hence not be used for further link extraction. The pattern has to match the whole URL (including URL parameters).
With the option "Include URL By Metadata" or "Exclude URL by Metadata", certain pages can be excluded (when crawling sitemaps) based on the metadata in the sitemap. The Metadata Name field specifies the metadata name and the Pattern field specifies the regular expression against which the metadata value is matched.
If "URL Regex", "URL Exclude Pattern" and "Include/Exclude URL by Metadata" are used simultaneously, "URL Regex" is applied first, then the pages are excluded with "URL Exclude Pattern" and finally the remaining pages are filtered with "Include/Exclude URL by Metadata".
With the option “Convert Document Keys to Lower Case” set, the document keys (header/mes:key) of the documents are converted to lower case.
You can add an arbitrary number of crawling roots editing the “Crawling Root” field and pressing the “Add” button. The added crawling roots are displayed in the list above (e.g. Crawling Root[1]). You can remove existing crawling roots by clicking on the “Remove” button besides them.
With the “Maximum Link Depth” field you can set the maximum count of hops from the crawling roots for the URLs that are crawled. URLs having a higher hop count will be ignored.
If you want to set additional HTTP headers while crawling (e.g. for setting the Accept-Language header), do so using the Accept Headers parameter.
With the option “Incomplete Delta Crawl Runs” enabled, pages that are not reachable from the current “Crawling Root” are not deleted from the index at the end of the crawl run. To minimize the load of subsequent crawl runs on your site, you can provide a crawling root with links to updated pages only.
IMPORTANT: the option “Incomplete Delta Crawl Runs” must not be used with sitemap-based delta crawling. For this see section “Sitemap Crawling Strategy”.
If a regular expression is set as an “Enforce extension from URL if matches” parameter, the extension is derived from the URL instead of from the “Content type” http header for documents with matching URLs.
If the "Enable Default ACLs" option is active (active by default), ACLs are set for Web documents if they do not have any explicitly defined ACLs (e.g. via sitemaps with <mes:acl>). Which ACLs are set in these cases is determined with the option "Default ACL Principals". Several "Default ACL Principals" can be specified separated by line breaks. If this field is left empty and "Enable Default ACLs" is active, "everyone" is used by default as "Default ACL Principals".
The “Inherit Crawling Root Query Parameter Pattern” option lets you inherit URL query parameters from the crawling root to the children's URLs. The use case is, for example, web pages that provide different content depending on the query parameters. For example, The following crawling roots https://mysite.com/events?location=us and https://mysite.com/events?location=en provide different content. Likewise, child pages provide different content: https://mysite.com/events/sponsored?location=us and https://mysite.com/events/sponsored?location=en. That the query parameter location, which comes from the crawling root, also applies to the child pages, the option "Inherit Crawl Root Query Parameter Pattern" must be set to the value location. The value can be any regular expression matched against the query parameter name. If a child page has already set query parameters of the same name, these are overwritten by the crawling root query parameter.
The “Max Retries” option determines how often the connector tries to download a document when temporary errors (e.g. socket timeouts) occur. The default value is 0. (No further download attempts). If you are crawling across an unstable network (that causes timeouts), this value should be increased to 10, for example. If the timeouts are caused by an overloaded data source, the value should be left at 0 so that the data source is not loaded even further.
The option “Max Document Size (MB)“ sets the maximum allowed file size of documents that are downloaded. The default value is 50. If a document is larger than this value, the document is truncated. A value of 0 means that no maximum file size is set.
With the option "Process Canonical Link" you can define a regular expression that determines for which URLs the crawler should try to read the URL from the "canonical" tag and set it as index key and URL metadata.
The option “Encode Canonical Links” determines whether URLs extracted from the “canonical” tag should be encoded before being stored in the index. To ensure that this setting is applied correctly, we recommend that you clean and re-index the index. This is useful because the URLs are then stored in the index in the same format as when you copy them from the browser, which usually automatically encodes the URLs.

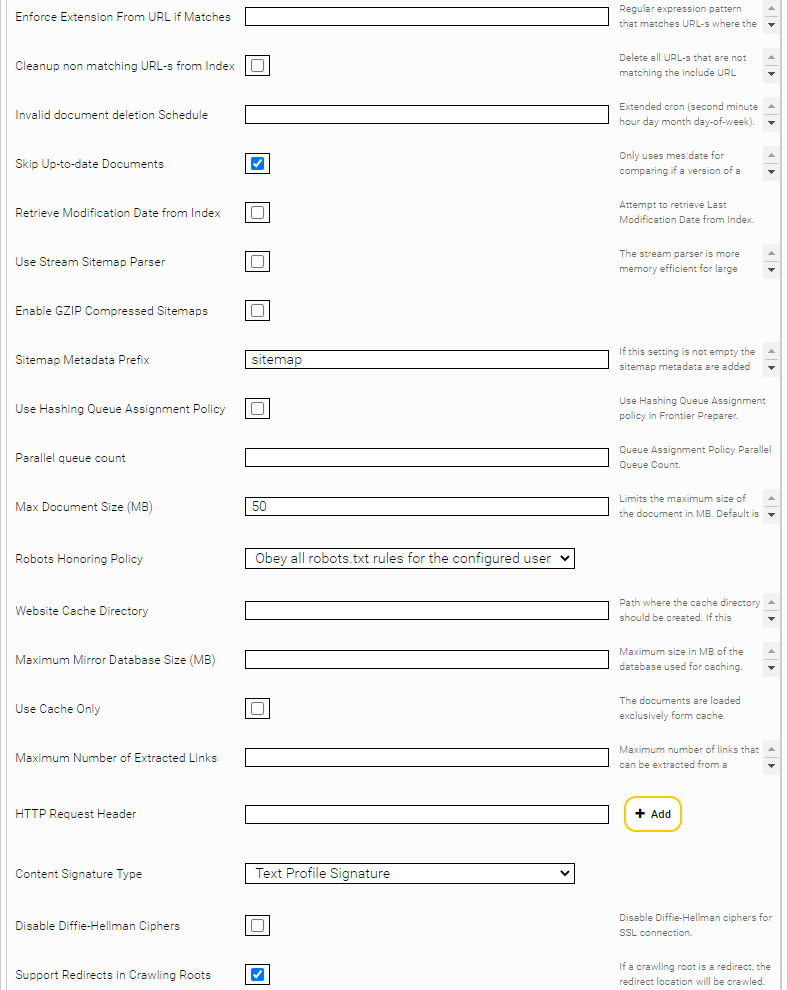
Skip Up-to-date Documents
When this option is enabled, a document will only be fully processed (content extracted, checked for content changes, etc.) if either mes:date (see here) or the access information has changed since the last crawl run.
Sitemap Crawling Strategy
In order to use sitemaps according to the Sitemaps.org protocol, check “Delta Crawling” and locate the site’s root sitemap as the crawling root.
In this scenario the crawler retrieves the web pages that are listed in the sitemap exclusively. The lastmod property of a sitemap URL entry is compared with the modification date of the already indexed web page (if exists). Furthermore the changefreq is interpreted between crawling runs. With a precise sitemap a high-frequent recrawling strategy can be employed.
Two “Delta Crawling” options are available:
- “Sitemap-based Incomplete”: with this option enabled, the URL entries from the configured sitemaps will be crawled and the already indexed URL-s which are not found in the sitemaps are left in the index.
- “Sitemap-based Complete”: with this option enabled the URL entries from the configured sitemaps will be crawled and the already indexed URL-s which are not found in the sitemaps are deleted from the index.
If the “Pass Sitemap ACL and Metadata to Redirect Target URLs” option is enabled and http redirects are allowed in root URLs, the sitemap metadata and ACLs are also applied to the redirect target URLs.
- The option “Use Stream Sitemap Parser” is enabling a stream-based parsing of the sitemaps. This is more memory-efficient in case of large sitemap XML-s but is also less tolerant to XML errors in the sitemaps
The Option “Sitemap Metadata Prefix”: adds the configured prefix to each metadata extracted from the sitemap.
Sitemaps from the local filesystem are also supported if a Delta Crawling mode is selected. Enter the File-URL as Crawling Root. Only File URLs pointing to the data directory are permitted. E.g file:///data/sitemap.xml.
Mindbreeze-Extension of the Sitemaps.org Protocol
With the Sitemaps.org protocol, web sites can be defined in a sitemap that should be crawled, e.g:
<?xml version="1.0" encoding="UTF-8"?>
<urlset xmlns="http://www.sitemaps.org/schemas/sitemap/0.9">
<url>
<loc>http://www.example.com/</loc>
<lastmod>2005-01-01</lastmod>
<changefreq>monthly</changefreq>
<priority>0.8</priority>
</url>
</urlset>
To define additional metadata and ACLs, there is a Mindbreeze extension. The following XML tags are additionally available:
<mes:meta> | optional | Can be defined multiple times within an <url> tag to define metadata. The following attributes are available:
|
<mes:value> | required | Can be defined multiple times within a <mes:meta> tag to define one or more values for a metadata
|
<mes:annotated> | optional | Can be defined multiple times within a <mes:meta> tag to define one or more annotated values for a metadata |
<mes:value> | required | Must be defined once within a <mes:annotated> tag to define the value being annotated. For annotated values, only string values are supported. |
<mes:ctx-annotation> | optional | Can be defined multiple times within a <mes:annotated> tag to add annotations to the value. The following attributes are available:
|
<mes:ref-annotation> | optional | Can be defined multiple times within a <mes:annotated> tag to add reference annotations to the metadata. The following attribute is available:
|
<mes:acl> | optional | Can be used within a <mes:meta> tag to define ACLs. Note that this tag is only considered if the option "Enable Default ACLs" is activated (active by default). Please note that ACLs from sitemaps are not compatible with “Access Check Rules”. |
<mes:grant> | optional | Can be defined multiple times within a <mes:acl> tag to grant access for a principal |
<mes:deny> | optional | Can be defined multiple times within a <mes:acl> tag to deny access for a principal |
<mes:require> | optional | Can be defined multiple times within a <mes:acl> tag to define in which groups a user must be. <mes:require> generally does not grant access, but denies access if the user is not in the group. Thus, after the last <mes:require> tag an additional <mes:grant> tag is necessary to grant access. |
Example:
<?xml version="1.0" encoding="UTF-8" ?>
<urlset xmlns="http://www.sitemaps.org/schemas/sitemap/0.9"
xmlns:xsi="http://www.w3.org/2001/XMLSchema-instance"
xsi:schemaLocation="http://www.sitemaps.org/schemas/sitemap/0.9
http://www.sitemaps.org/schemas/sitemap/0.9/sitemap.xsd"
xmlns:mes="tag:mindbreeze.com,2008:/indexing/interface">
<url>
<loc>https://www.mindbreeze.com</loc>;
<lastmod>2020-08-22T09:03:56+00:00</lastmod>
<!-- additional metadata -->
<mes:meta key="breadcrumb">
<mes:value>Mindbreeze</mes:value>
<mes:value>Home</mes:value>
</mes:meta>
<mes:meta key="keywords" aggregatable="true">
<mes:value>Search Appliance</mes:value>
<mes:value>InSpire</mes:value>
<mes:value>Semantic Search</mes:value>
<!-- more -->
</mes:meta>
<mes:meta key="article_ean" aggregatable="true">
<mes:value format="number">4104420230262</mes:value>
<mes:value format="number">0883298182906</mes:value>
<mes:value format="number">4056489314097</mes:value>
<!-- more -->
<mes:meta key="parent">
<mes:annotated>
<mes:value>Main parent</mes:value>
<mes:ctx-annotation metakey="related" aggregatable="false">Fabasoft</mes:ctx-annotation>
<mes:ref-annotation metakey="parentkey">abcd.1.2.3.4</mes:ref-annotation>
</mes:annotated>
</mes:meta>
<!-- ACL -->
<mes:acl>
<mes:require>cn=domain users,cn=users,dc=mycompany,dc=com</mes:require>
<mes:deny>unauthorized</mes:deny>
<mes:grant>cn=marketing,cn=users,dc=mycompany,dc=com</mes:grant>
</mes:acl>
</url>
</urlset>
Default Content Type
The option “Default Content Type” can be used to set the MIME-Type for those documents for which the MIME-Type cannot be extracted from the HTTP-Header.
![]()
Resource Parameters
This section is visible only when the “Advanced Settings” mode is activated on the “Indices” tab.

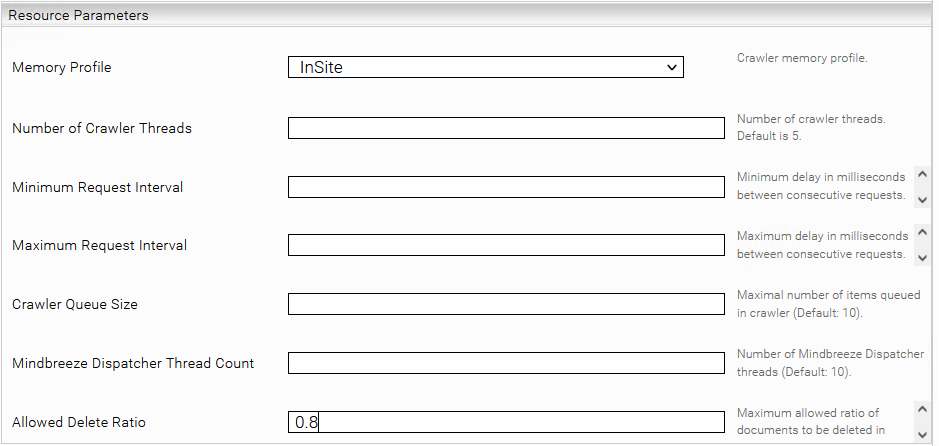
Memory Profile | The InSpire profile is standard, if required, the resource-saving InSite profile can be used. |
Number of Crawler Threads | The number of threads crawling the specified web page and allowed subpages in parallel. |
Minimum Request Interval | Minimum delay in milliseconds between consecutive requests. |
Maximum Request Interval | Maximum delay in milliseconds between consecutive requests. |
Crawler Queue Size | Maximum number of documents in the queue that will be sent to the index. |
Mindbreeze Dispatcher Thread Count | The number of threads that send data to the index in parallel. |
Allowed Delete Ratio | Maximum allowed ratio of documents to be deleted in proportion to the number of documents in the index. Default value: 0.8. This is a function to prevent data loss in case of network failures or unintentional configuration changes. (e.g., if more than 0.8 (80%) of the document set would be deleted in a crawl run, the crawl run is automatically aborted to prevent data loss). |
General JavaScript Settings
By default, the Web Connector downloads HTML documents and extracts the content directly. If web pages load the content dynamically with JavaScript, the content is not included in the original HTML document. By default, JavaScript is ignored and therefore the content cannot be extracted.
General
With the “Enable JavaScript” setting, content from web pages that use JavaScript to render content can be indexed.
Note: When “Enable JavaScript” is enabled, the connector requires significantly more resources. This leads to slower crawling and higher memory consumption. Therefore, it is recommended to activate the "Enable JavaScript" option only for a single crawler and to restrict JavaScript processing with the "Include/Exclude JavaScript URL Regex Pattern" options to only those URLs that actually require JavaScript.
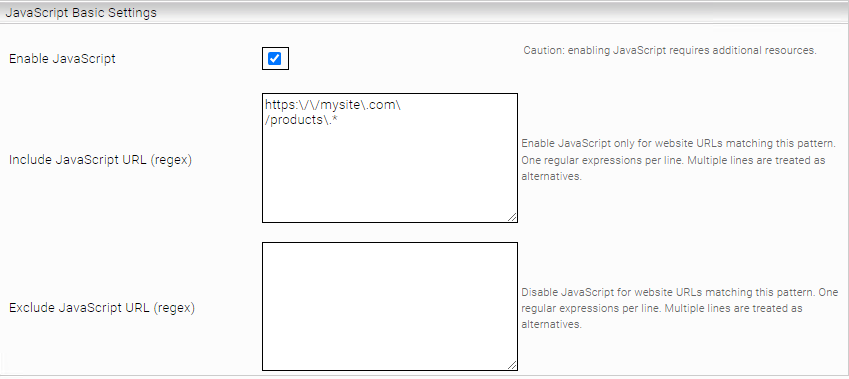
For example, the web pages https://mysite.com/products and https://mysite.com/internal are to be indexed. https://mysite.com/products requires JavaScript, https://mysite.com/internal does not require JavaScript for indexing. In this case, "Include JavaScript URL Regex Pattern" must be configured as follows: https:\/\/mysite\.com\/products\.*
Security mechanisms and security exceptions
Since web pages can contain arbitrary JavaScript code and the code is executed in the connector, the usual security mechanisms known from web browsers, such as sandboxing and CORS, are used. Furthermore, the networking interfaces of the JavaScript code are strongly limited for security reasons.
In particular, only network requests to URLs with the same hostname are allowed. This should not be a problem for most use cases. For example, if the page https://mysite.com/products (hostname mysite.com) is indexed, which should load the page JavaScript from external URLs, e.g. https://ajax.googleapis.com/ajax/libs/angularjs, then the network requests to the hostname ajax.googleapis.com will be blocked, since this is a different hostname. All blocked (and successful) network requests are displayed in app.telemetry. To view this, navigate to the "Network Requests" log pool in Management Center > Reporting > Telemetry Details > Applications. Make sure that the columns "URL", "Status" and "Status Description" are displayed.
If external network requests are absolutely necessary to display the content of the web page, it is possible to define security exceptions using the "Additional Network Resources Hosts" setting (Advanced Setting). This setting can define a list of hostnames that are allowed in any case. In the example from above you can set the value ajax.googleapis.com for "Additional Network Resources Hosts". This will now allow network requests such as https://ajax.googleapis.com/ajax/libs/angularjs.
Limitations of the "Enable JavaScript" option
- Indexing web pages with "Enable JavaScript" activated is associated with various functional limitations. Currently, the following features cannot be used together with the "Enable JavaScript" option:
- Network proxy with authentication (user, password).
- Indexing web pages with NTLM or Kerberos authentication
- Indexing of single-page applications (SPA) that use URL anchors
- Indexing of webpages that load a high number of resources (Maximum “Page Load Timeout” 20 Seconds)
- Indexing of webpages which are secured with 2-factor-authentication.
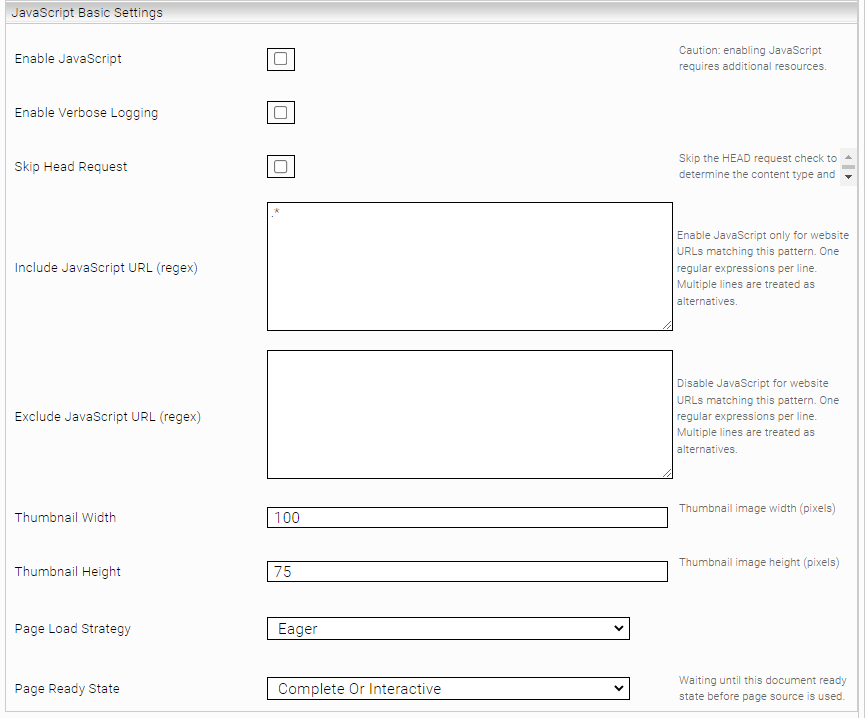
Option | Description |
Enable JavaScript | Enables JavaScript processing (see description above), Warning: requires increased system resources (default value: disabled). |
Enables advanced logging for diagnostic purposes (default: disabled). | |
Skip Head Request | Skip the HEAD Request which is used to determine if the JavaScript of a website should be handled. (per default JavaScript is only handled for text/html) |
List of regular expressions defining the URLs where JavaScript is processed (see description above) (default value: .*) | |
Exclude JavaScript URL (regex) | List of regular expressions defining the URLs where JavaScript must not be processed |
Thumbnail Width | Width of the generated thumbnails in pixels (default value: 100). |
Thumbnail Height | Height of the generated thumbnails in pixels (default value: 75) |
Page Load Strategy | Determines with which strategy web pages are loaded. This value is for internal use and should not be changed. (Default value: "Eager") |
Page Ready State | Specifies how to determine whether a page has finished loading. This value is for internal use and should not be changed (default value: “Complete Or Interactive“). |
Javascript Script Settings
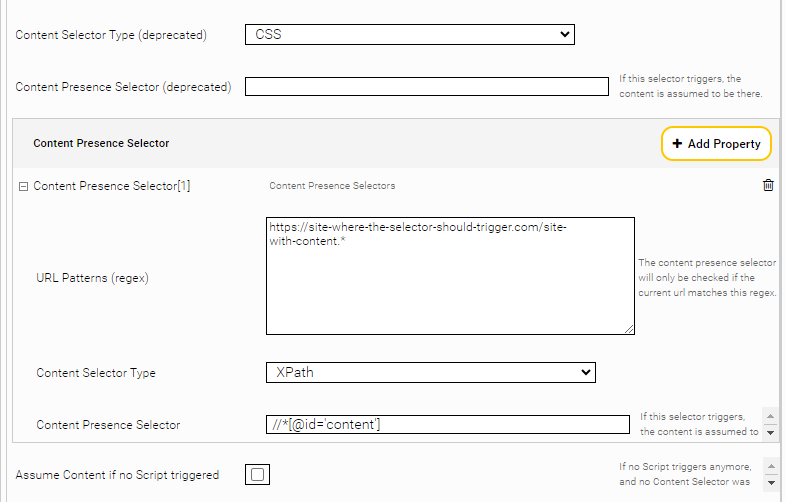
Option | Description |
Content Selector Type (deprecated) | Same behavior as the field ‘Content Selector Type’. |
Content Presence Selector (deprecated) | Same behavior as the field ‘Content Presence Selector’. |
URL Patterns (regex) | Defines the regex patterns to match against website URLs. The Content Presence Selector is only applied if there is a match. |
Content Selector Type | Defines the type of the ‘Content Presence Selector’. The default value is CSS, but XPath is also possible as a value. |
Content Presence Selector | A CSS or XPath expression, which is used to determine, if the requested content exists. Must not be used in combination with Assume Content if no Script triggered. Must be specified in single quotation marks (') and not in double quotation marks ("). |
Assume Content if no Script triggered | If this setting is enabled, the content is assumed to be loaded, although no Script Trigger Selector is active. Must not be used with Content Presence Selector. |
Scripts

| A custom name for the script which is used to identify it in the logs. |
URL Patterns (regex) | The script will only run on web pages where the URL matches one of these regex patterns. If the field is empty, it will be interpreted as '.*'. |
Script Selector Type | Defines the type of the ‘Script Trigger Selector’ |
Script Trigger Selector | Expression (CSS or XPath) which is used to trigger the script. Must be specified in single quotation marks (') and not in double quotation marks ("). |
Script | Defines the script to be executed when the ‘Script Trigger Selector’ is active. |
Credential Scripts
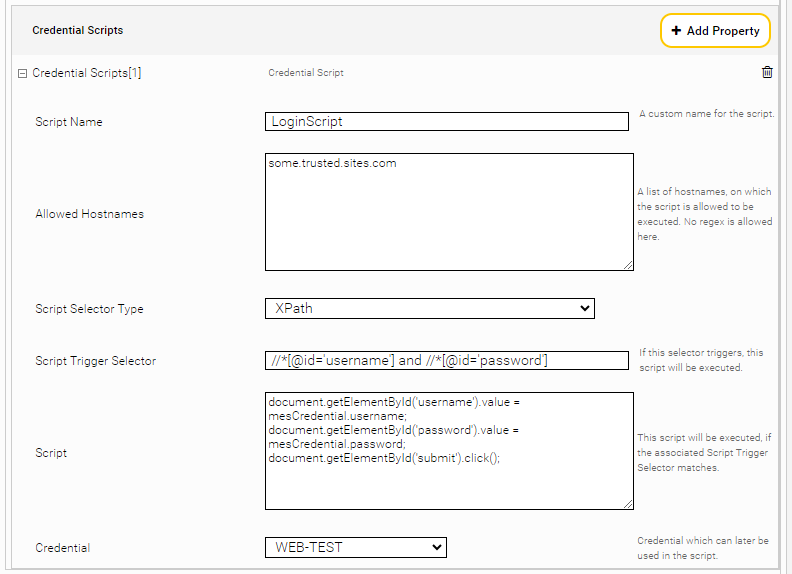
| A custom name for the script (is used for identification in the logs). |
Allowed Hostnames | The script will only run on pages where the hostname matches one of these hostnames. Patterns cannot be used here. |
Script Selector Type | Defines the type of the ‘Script Trigger Selector’. The default value is CSS. |
Script Trigger Selector | Expression that is used to trigger the script, which is defined in CSS or XPath. Must be specified in single quotation marks (') and not in double quotation marks ("). |
Script | Defines the Script which is to be executed when the Script Trigger Selector matches. In contrast to normal scripts, a provided object 'mesCredential' can be used. It has the variables 'domain', 'username' and 'password' defined depending on the Credential selected. let password = mesCredential.password; let username = mesCredential.username; let domain = mesCredential.domain; |
Credential | Here you can select any credential from the ‘Network’ tab, which is then used in the script. Currently the only supported credential types are ‘Password’ and ‘Username/Password’. |
Javascript Security Settings
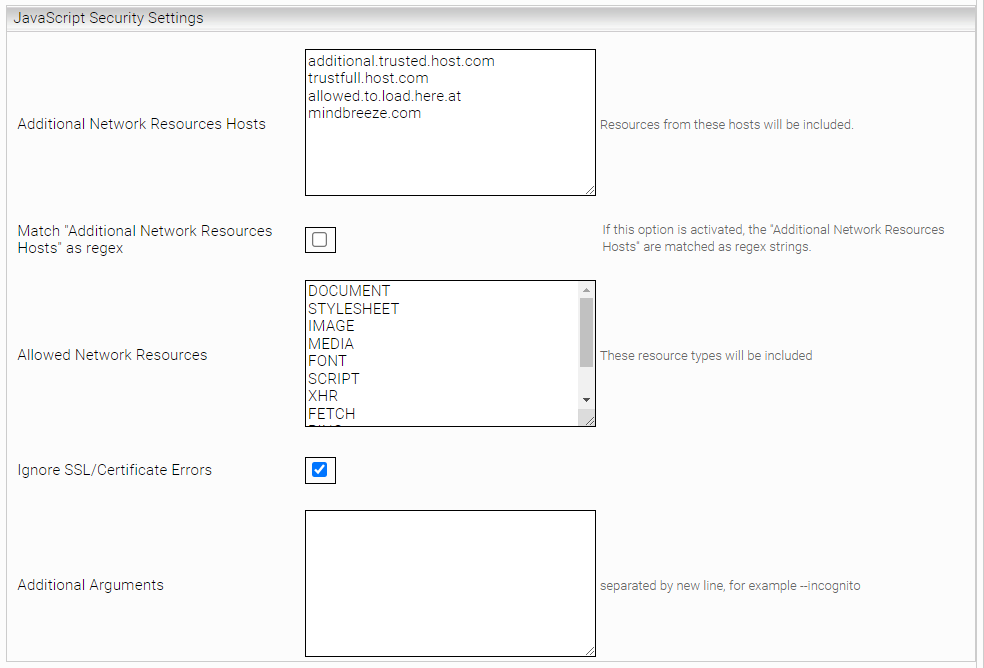
Option | Description |
Additional Network Resources Hosts | List of hostnames to which network requests are allowed. Patterns cannot be used here, unless Match "Additional Network Resources Hosts" as regex is activated. |
Match "Additional Network Resources Hosts" as regex | If this option is enabled, the 'Additional Network Resources Hosts' will be used as regex patterns. Here, at least one URL pattern must be defined for each script. |
Allowed Network Resources | List of network resources to which requests are allowed. |
Ignore SSL/Certificate Errors | If enabled, HTTPS SSL or certificate errors will be ignored. For security reasons, this setting may only be enabled in test systems. |
Additional Arguments | This value is for internal use and should not be changed. (Default value: empty) |
JavaScript Performance Settings

Option | Description |
Page Load Timeout | Time in seconds for loading and executing JavaScript on a website. If this time is exceeded, the processing is aborted. (Default value: 10, maximum value: 20) |
Network Timeout | Time in seconds that the Connector waits for a response from the website. |
Browser Recycle Threshold | Number of websites that are processed with a single internal browser instance before the instance is automatically stopped and restarted to conserve system resources. (Default value: 1000) |
Proxy
In the “Proxy” section you can enter a proxy server if required in your infrastructure. To do this, enter the computer name and the port of the proxy server in “Proxy Host” and “Proxy Port”.
The Web Connector can register on the proxy server with HTTP-BASIC. Enter the user in the field “Proxy User” and the password in “Proxy Password” if the connections are to be made by an authentication-enabled proxy.

Authentication
This chapter describes the various authentication methods for the Web Connector. The methods that can be used to index content that is located behind a login are also discussed.
Form-based authentication
This section deals with the mechanism of the form-based login, which is essentially a mechanism that allows you to perform a login using a login form and to manage user sessions using HTTP cookies.
Form-based login simulates the user behavior and browsing behavior required to automate such logins.
In this chapter, two scenarios are described. Both scenarios are based on the settings shown in the figure below.
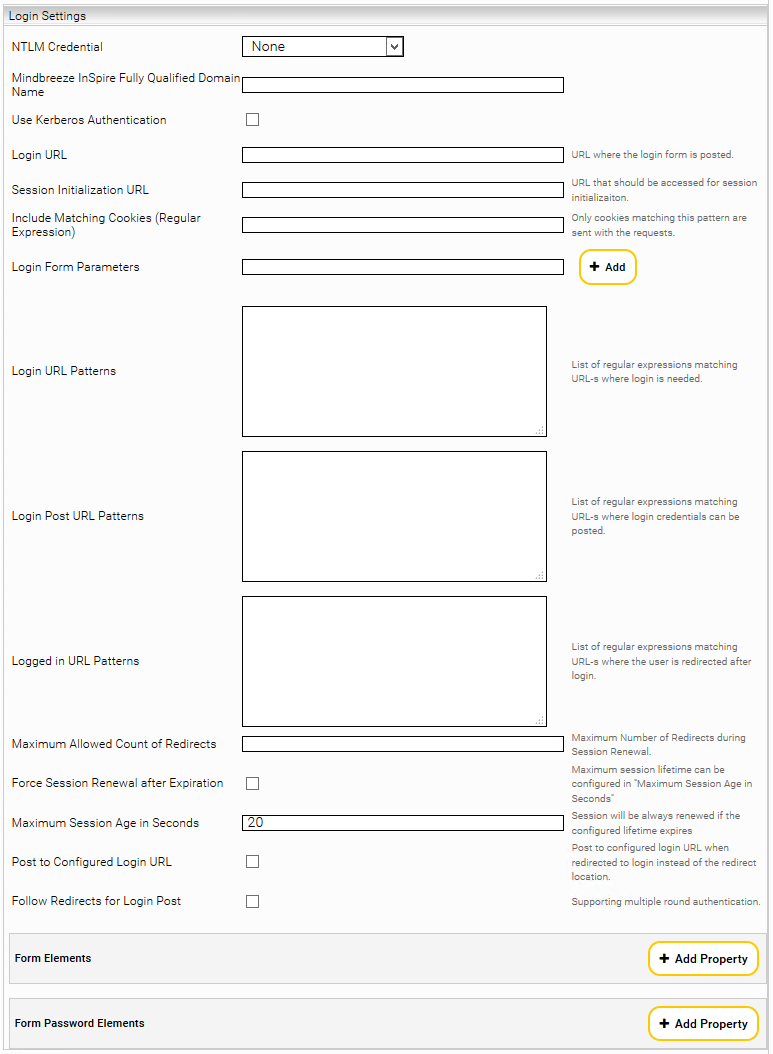
Static form-based login with session management
In this scenario, a POST request is sent to a specific URL to trigger the authentication. The URL to be used for this purpose is entered under Login URL. For instance, this URL can be determined using the debugging functions of the web browser. The various options are explained below:
- Session initialization URL
In some cases it is necessary to retrieve a dynamically generated cookie from a specific URL and send it along already with the form-based login. An HTTP GET request is executed on the URL entered here and the cookies generated from this are sent along with the actual login.
- Include matching cookies (regular expression)
This can be used to restrict which cookies are to be stored for session management. This field must contain a regular expression that applies to the names of the cookies that are to be enabled and used for the session.
- Form and password elements
The names and values of the elements that are used in the HTTP POST request on the login URL have to be specified in this setting. In doing this, the name of the HTML form field should be entered. All password fields have to be entered under Password Elements.
- Follow redirects for login post
If this option is enabled, all redirects are tracked after the HTTP POST request to the login URL, and all cookies are collected until no further redirect is requested or the authentication is successful.
No further settings are required for this scenario.

Complex form-based authentication
If the previous scenario is not sufficient, the following settings can be used:
- Session initialization URL
This URL is opened at the beginning so that it can then be dynamically redirected. The cookies received in the process are retained for the session.
- Login form parameters
If hidden fields are set in the login form, they can be listed here. They are extracted and sent along with the login request. A typical example of this is the dynamically generated FormID, which is returned as a hidden parameter from the Web server.
- Login URL patterns
All redirects that correspond to the regular expressions specified here are tracked during the login process.
- Login post URL patterns
When tracking the redirects that correspond to the regular expressions specified here, all collected form parameters are sent using an HTTP POST request.
- Logged in URL patterns
If you are forwarded to an URL that matches the regular expressions specified here, the login process was successful.
- Maximum allowed count of redirects
This can be used to set the maximum depth of the tracked redirects.
- Post to configured login URL
If this option is enabled, redirects to a "Login Post URL" are replaced by an HTTP POST request to the URL configured under "Session Initialization URL".
- Reset Session Before Login
If this option is set, old session cookies are not used to create a new session when a session expires.
- Force Session Renewal After Expiration
If this option is set, the login process is always re-executed if the session is older than the configured maximum session age (maximum session age in seconds). This option only works if “Post to configured login URL” is enabled.
- Maximum Session Age in Seconds
Maximum session age in seconds.

NTLM
To use NTLM authentication, the user, the password, and the domain need to be configured as credentials in the Network tab:

After this, this credential has to be selected in the Web Connector in the "NTLM Credential” setting:

OAuth2
To use OAuth authentication, a credential of type OAuth2 must be created in the Network tab:
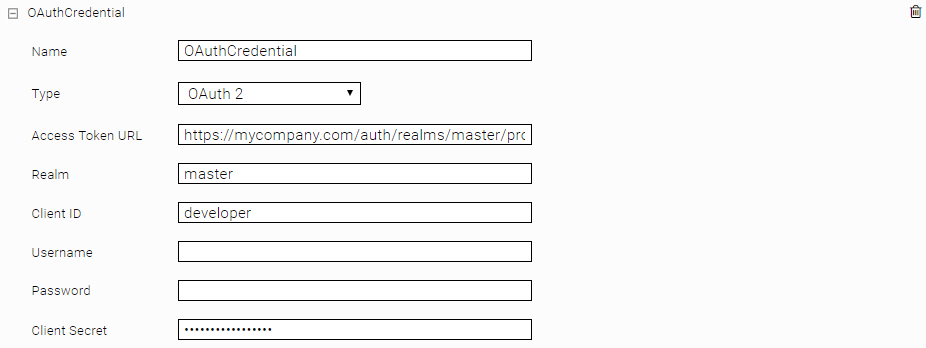
For the grant type client credentials it is sufficient to configure Realm, Client ID and Client Secret. For the grant type password you also have to configure the username and password.
This credential must then be selected in the Web Connector in the "OAuth Credential" setting: 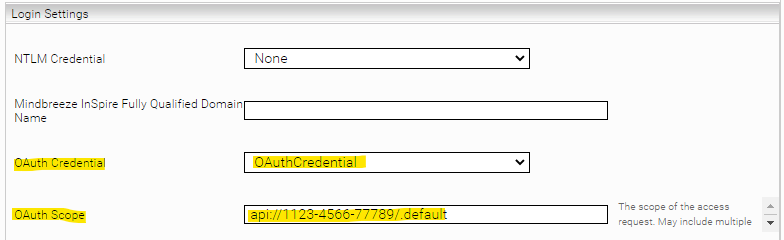
The “OAuth Scope” setting can be used to request specific permissions for OAuth authentication.
Authorization basic header
The basic authentication following RFC 2617 is the most common type of HTTP authentication. The Web server requests an authentication using
WWW-Authenticate: Basic realm="RealmName"
where RealmName is a description of the protected area. The browser then searches for the username/password for this URL and queries the user if necessary. The browser then sends the authentication Base64-encoded and in the form Username: Password to the server using the authorization header.
Example:
Authorization: Basic d2lraTpwZWRpYQ==
To set the header specified in the example above, it has to be configured in the HTTP Request Header option as shown in the following screenshot:

Kerberos Authentication
Kerberos authentication uses the Negotiate protocol to authenticate HTTP requests. The Web connector is thus able to index websites that can only be accessed with Kerberos authentication. The following steps are required to activate Kerberos authentication:
- Make sure there is a working Kerberos setup on the appliance. See Kerberos Authentfizierung for this.
- Generate a “Connector” keytab and assign it to the Web connector. See Connector Authentifizierung Kerberos
- Enable the option “Use Kerberos Authentication” in den Web connector settings.
Note: Kerberos does not currently support web thumbnails; they are automatically disabled.
Content Extraction
Excluding pages from indexing
With the option "URLs Excluded from Filtering" already found pages can be excluded from indexing by means of a regular expression. A possible use case is, for example, if you want to index certain pages that can only be reached via detours and you do not want to index the detours themself. In this case, you can use "URLs Excluded from Filtering" to specify a regular expression that excludes the detours.
Here is an overview of the options that influence the crawling direction:
- "Crawling Root" determines which URL is used to start crawling
- "URL Regex" determines which URLs are followed up
- "URL Exclude Regex" determines which URLs are excluded and not followed up
- "URLs Excluded from Filtering" determines which crawled documents are finally indexed
Extract Metadata
Within the Section “Extract Metadata” put in as Name: “bulletPoints” and as XPath: “//li”
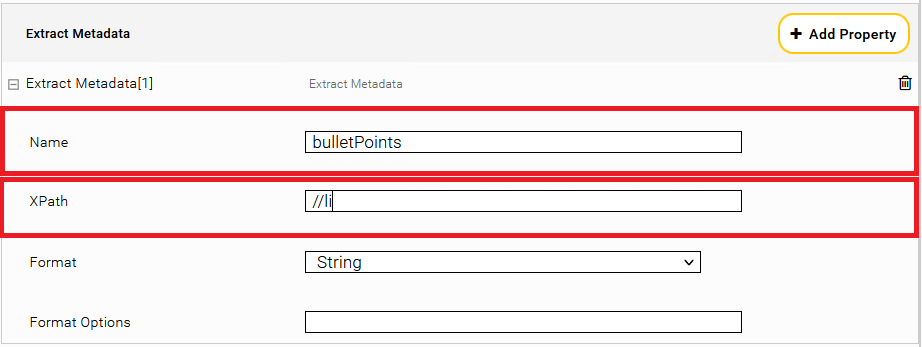
Afterwards you have to reindex.
Filter Configuration
There are multiple environment variables.
Cache Settings for Thumbnail Generation
The variable MES_THUMBNAIL_CACHE_LOCATION specifies a directory for the network cache used during thumbnail generation. The maximal cache size can be defined using the variable MES_THUMBNAIL_CACHE_SIZE_MB. Only if both variables are set, a cache is created and used.
Example (Linux):
export MES_THUMBNAIL_CACHE_LOCATION=/tmp/thumbcache
export MES_THUMBNAIL_CACHE_SIZE_MB=20
On Windows, the variables can be defined in the Control Panel.
Timeout Settings for Thumbnail Generation
Using the variable MES_THUMBNAIL_TIMEOUT a timeout value for thumbnail generation can be redefined. Otherwise the default value of 50 seconds will be used.
Example (Linux):
export MES_THUMBNAIL_TIMEOUT=10
On Windows, the variables can be defined in the Control Panel.
Extract Main Content with alternative Filter-Mode
Crawling of e.g. news sites often indexes useless content like menus or footers. The HTML-Filter can be switched in an alternative Mode, which can index only meaningful content, using heuristics.
There are multiple ways for configuration:
Filter Plugin Properties
Click on the “Filters”-Tab and activate “Advanced Settings”.
![]()
In the section “Global Filter Plugin Properties” select “FilterPlugin.JerichoWithThumbnails(…)” and click on “Add”.

Expand the new Entry “FilterPlugin.JerichoWithThumbnails” and set the Value “Use Boilerpipe Extractor” to the Value “Article”.
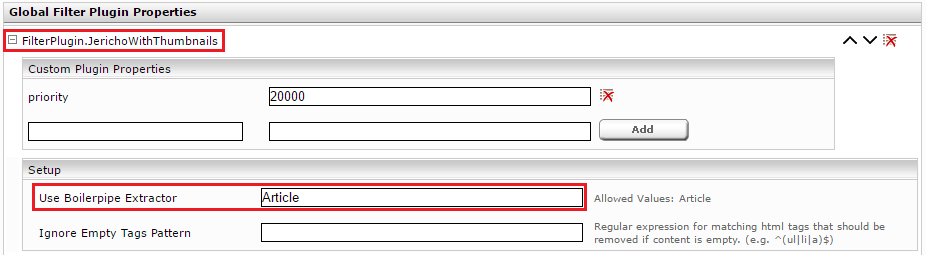
Afterwards you have to reindex.
Datasource XPath Metadata
Extract the affected Index. In section “Data Source”, subsection “Extract Metadata” click on the plus symbol “Add Property”.

Within the new section “Extract Metadata” put in as name: htmlfilter:extractor and XPath: "Article" (Important: with double quotes).
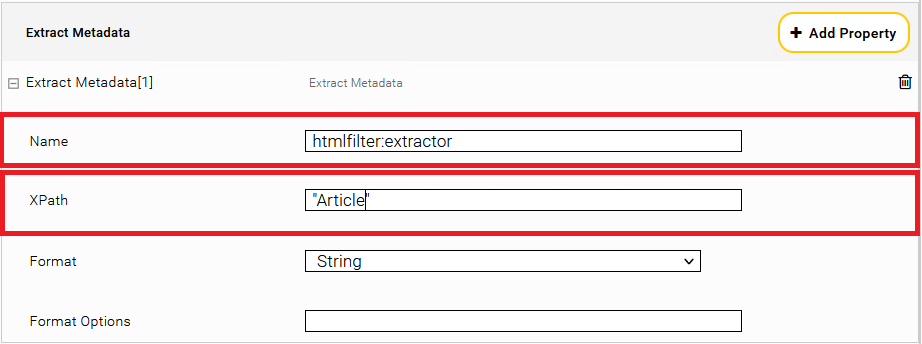
Afterwards you have to reindex.
Ignore empty HTML Elements
If documents with empty HTML-elements appear within the index, you can define a regular Expression to remove these elements while filtering.
There are multiple ways for configuration:
Filter Plugin Properties
Click on the “Filters” Tab and activate “Advanced Settings”.
![]()
In Section “Global Filter Plugin Properties” select “FilterPlugin.JerichoWithThumbnails(…)” and click on “Add”.
Expand the new Entry “FilterPlugin.JerichoWithThumbnails” and set the Value “Ignore Empty Tags Pattern” to e.g. the Value “^(ul|li|a|div)$”. This means that empty HTML-elements ul, li, a and div will be removed, if empty. 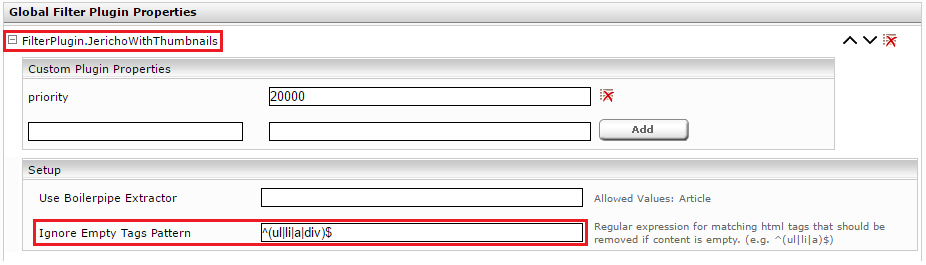
Afterwards you have to reindex.
Datasource XPath Metadata
In the Tab “Indices” activate “Advanced Settings”.
![]()
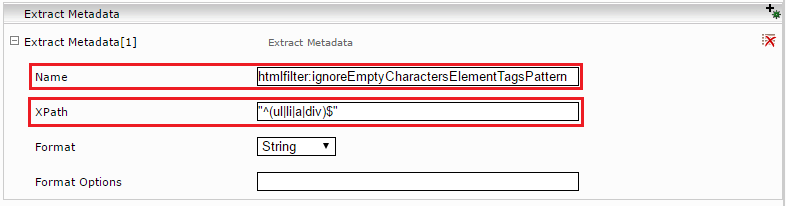
Expand the affected index. In section “Data Source”, Subsection “Extract Metadata” click on the plus-symbol “Add Composite Property”.
![]()
In the new Section “Extract Metadata” put in as Name: htmlfilter:ignoreEmptyCharactersElementTagsPattern and as XPath: "^(ul|li|a|div)$" (Important: double Quotes). This means that empty HTML-elements ul, li, a and div will be removed, if empty.
Afterwards you have to reindex.
Using Googleon/Googleoff tags
Google GSA defines a mechanism in order to be able to mark and designate certain sections as "non-searchable" within a single HTML site. Consequently, these designated sections are not indexed, although the rest of the page is. The marks take the form of HTML comments that are set in pairs.
The following tags are supported:
There are several options for configuration.
System-wide use with global filter plugin properties
To enable this function, click on the "Filters" tab and then click "Advanced Settings".
![]()
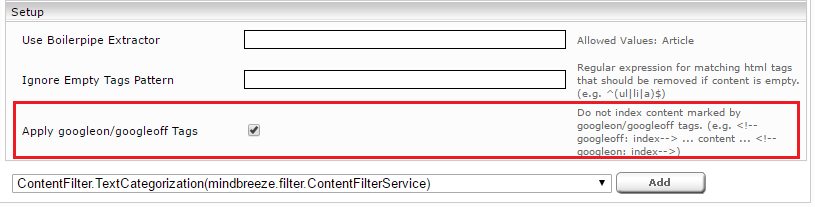
Under "Global Filter Plugin Properties", select "FilterPlugin.JerichoWithThumbnails (...)" and click "Add".
Expand the new entry "FilterPlugin.JerichoWithThumbnails" and tick the "Apply googleon/googleoff tags" setting. Then re-index.
Use in Web Connector
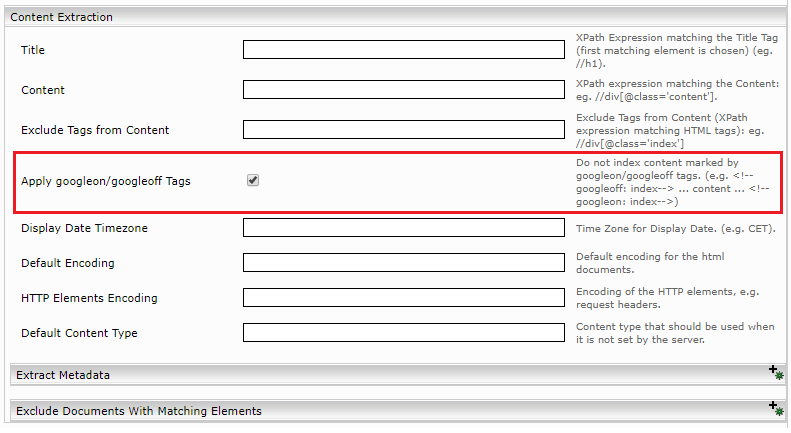
In the Web Connector settings under “Content Extraction“, check the "Apply googleon/googleoff Tags" setting. Then re-index.
Crawler-specific use with Datasource XPath Metadata
Enable "Advanced Settings" in the “Indices“ tab.
![]()
Expand the relevant index. In the "Data Source" section, "Extract Metadata" sub-section, click the "Add Composite Property" plus-sign icon.
![]()
In the new section "Extract Metadata", enter the name: htmlfilter:applygoogleonoff and set the XPath to: "true" (important: in quotation marks).
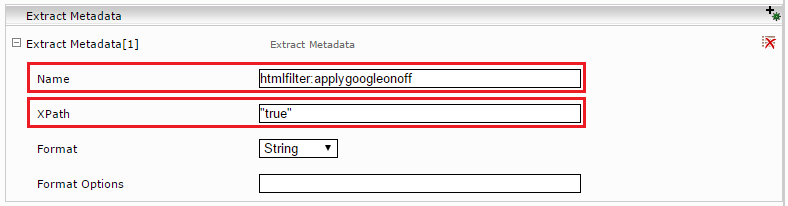
Then re-index.
Extracting Text from CDATA Sections
Optionally the Jericho HTML filter can extract Text from CDATA sections of HTML documents. One can activate this feature either globally on the filter service level by setting global filter properties, or pro document, by setting a specific metadata by the crawler.
System-wide use with global filter plugin properties
To enable this function, click on the "Filters" tab and then click "Advanced Settings".
![]()
Under "Global Filter Plugin Properties", select "FilterPlugin.JerichoWithThumbnails (...)" and click "Add".
Expand the new entry "FilterPlugin.JerichoWithThumbnails" and tick the "Extract CDATA contents" setting. Then re-index.
Crawler-specific use with Datasource XPath Metadata
Enable "Advanced Settings" in the “Indices“ tab.
![]()
Expand the relevant index. In the "Data Source" section, "Extract Metadata" sub-section, click the "Add Composite Property" plus-sign icon.
![]()
In the new section "Extract Metadata", enter the name: htmlfilter:extractcdatacontent and set the XPath to: "true" (important: in quotation marks).
Normalizing special characters
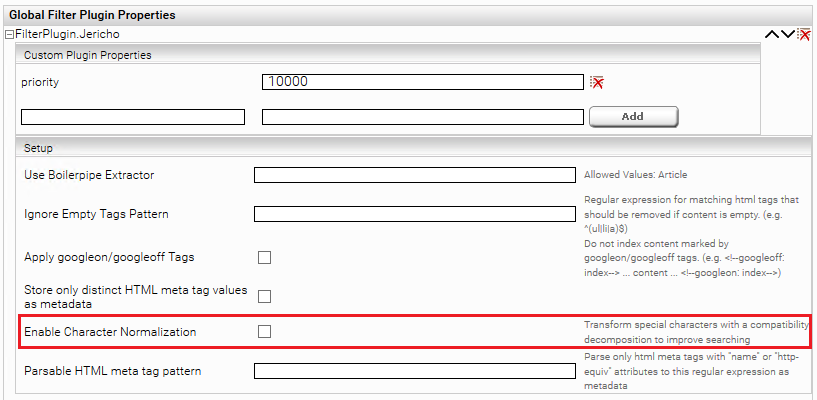
Using the "Enable Character Normalization" option, special characters such as ü,â are transformed into a normal format (compatibility decomposition), which facilitates searching. This option can produce better results if the client service option "Query Expansion for Diacritic Term Variants" does not deliver the desired quality.
Authorization
Configuring authorization settings are only possible through “AuthorizedWeb” category. In order to configure these settings the category of data source should be change from “Web” to “AuthorizedWeb”. The rest of settings in “AuthorizedWeb” category are similar to those described in previous chapters.

Configuring Access Rules
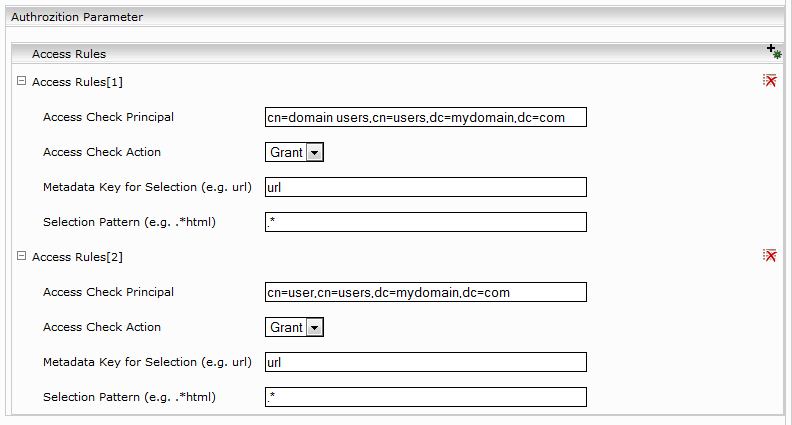
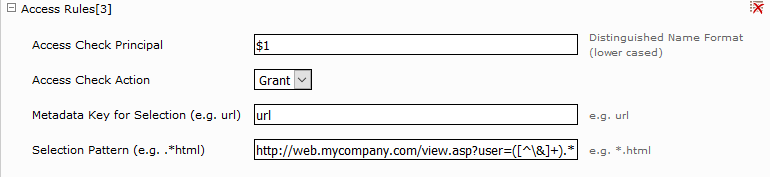
An Access Rule is defined by:
“Access Check Principal”, which should be either in username@domain or domain\username or distinguished name format for users or only in distinguished name format for user groups. Additionally a capture group from the selection pattern can be referenced here (See Access Rules[3]).
“Access Check Action”, which controls access type (Grant or Deny).
“Metadata Key for Selection”, should be a metadata name used by access rule or empty (selects all documents)
“Selection Pattern”, should be a regular expression or empty (matches all documents).
Access Check Rules are only applied if there are no ACLs defined in the Sitemap (If Sitemaps are used).
If there are Access Check Rules which refer to metadata other than ‘url’ then all documents that may inlcude ACL changes may be crawled again in a delta run.
Parallel Processing of URLs

The option „Use hashing queue assignment policy“ enables the hash based distribution of input URLs to processing queues. The number of queues is determined by the „Parallel Queue Count“ setting.
Without the option „Use hashing queue assignment policy“ URLs are distributed by hostname.
High priority removal of documents
![]()
At the end of a crawl-run inaccessible documents are removed from the index. This deletes all documents that were not successfully downloaded and indexed.
If the option "Incomplete Delta Crawl Runs" is active, no documents will be deleted at the end of the crawl run.
Additionally, the option “Invalid document deletion Schedule” can be used to define a schedule which is used to remove inaccessible documents from the index independent of crawl runs.
To do this, an extended cron expression must be entered in the field. Documentation and examples of cron expressions can be found here.
The example schedule: “0 */45 * * * ?” means a deletion run every 45 minutes.
This schedule is only active if the crawler schedule permits it.
The following documents are deleted during the crawl run:
- Not found documents (HTTP Status 404, 310)
- Redirections to those documents (e.g. HTTP Status 301, 307)
If “Cleanup non matching URL-s from Index” is activated, the following documents will be removed additionally:
- According to „URL Exclude Pattern“ ignored Documents:
- Redirections to those documents (e.g. HTTP Status 301, 307)
If the option "Cleanup non matching URL-s from Index" is active and no "Invalid document deletion Schedule" has been defined, the deletion process is started with each crawl run. If it is a delta crawl run, only documents ignored according to the "URL Exclude Pattern" will be deleted, otherwise inaccessible documents will also be deleted (HTTP status 404, 410, 301, 307). It is a delta crawl run if the option "Incomplete Delta Crawl Runs" is active or if "Sitemap-based Incomplete" is selected for the "Delta Crawling" option.
Appendix A
Heritrix Status Codes
Each crawled URI gets a status code. This code (or number) indicates the result of a URI fetch in Heritrix. Codes ranging from 200 to 599 are standard HTTP response codes. Other Heritrix status codes are listed below.
Code | Meaning |
1 | Successful DNS lookup |
0 | Fetch never tried (perhaps protocol unsupported or illegal URI) |
-1 | DNS lookup failed |
-2 | HTTP connect failed |
-3 | HTTP connect broken |
-4 | HTTP timeout |
-5 | Unexpected runtime exception. See runtime-errors.log. |
-6 | Prerequisite domain-lookup failed, precluding fetch attempt. |
-7 | URI recognized as unsupported or illegal. |
-8 | Multiple retries failed, retry limit reached. |
-50 | Temporary status assigned to URIs awaiting preconditions. Appearance in logs may be a bug. |
-60 | URIs assigned a failure status. They could not be queued by the Frontier and may be unfetchable. |
-61 | Prerequisite robots.txt fetch failed, precluding a fetch attempt. |
-62 | Some other prerequisite failed, precluding a fetch attempt. |
-63 | A prerequisite (of any type) could not be scheduled, precluding a fetch attempt. |
-404 | Empty HTTP response interpreted as a 404. |
-3000 | Severe Java Error condition occured such as OutOfMemoryError or StackOverflowError during URI processing. |
-4000 | "Chaff" detection of traps/content with negligible value applied. |
-4001 | The URI is too many link hops away from the seed. |
-4002 | The URI is too many embed/transitive hops away from the last URI in scope. |
-5000 | The URI is out of scope upon reexamination. This only happens if the scope changes during the crawl. |
-5001 | Blocked from fetch by user setting. |
-5002 | Blocked by a custom processor. |
-5003 | Blocked due to exceeding an established quota. |
-5004 | Blocked due to exceeding an established runtime |
-6000 | Deleted from Frontier by user. |
-7000 | Processing thread was killed by the operator. This could happen if a thread is a non-responsive condition. |
-9998 | Robots.txt rules precluded fetch. |
Supported compression types
The Mindbreeze WebConnector supports documents that are compressed with the following compression types (content encoding):
- gzip
- x-gzip
- deflate
- identity
- none
How is mes:date determined?
The value for mes:date is determined in the following order:
- It is checked if the XML-attribute "Last-Mod" was extracted during the crawlrun. (Only available for sitemaps)
- It is checked if the XML-attribute "Publication Date" was extracted during the crawlrun. (only available for sitemaps)
- If the two previous two attributes are not available (e.g. if a normal website and not a sitemap is crawled), the more recent date from the following two values is used:
- The Last-Modified date from the response headers.
- If a <meta> tag with the attribute “http-equiv” (<meta http-equiv="Last-Modified" content="...">) is found inside the HTML document, the date is extracted from this tag. The function of this tag is equivalent to the "Last Modified" header.
If no mes:date could be set (e.g. if response header parsing failed), the current timestamp while retrieving the document is used as a fallback.