
Sure, you can handle it. But should you?
Let our experts manage the tech maintenance while you focus on your business.
Let our experts manage the tech maintenance while you focus on your business.
Release Notes for Mindbreeze InSpire
Version 20.4
Innovations and new features
Per document dynamic metadata as filter
Metadata can now be dynamically set to be usable as filters during indexing or in the Semantic Pipeline.
Until now there have only been static defined filters. These filters were global per index. The new dynamically defined filterable metadata are much more flexible, because they can be defined per document. This also has the following advantage: If you add another data source to an already existing index, the filterable properties of the new documents are immediately available.
Currently this feature is only used for Web-Connector sitemaps, but it is also available in the SDK. Precomputed Synthesized Metadata now also supports dynamic filters.
Link to documentation for Web-Connector Sitemaps
Link to documentation for Precomputed Synthesized Metadata
Automatic deployment of changes in CI/CD pipelines
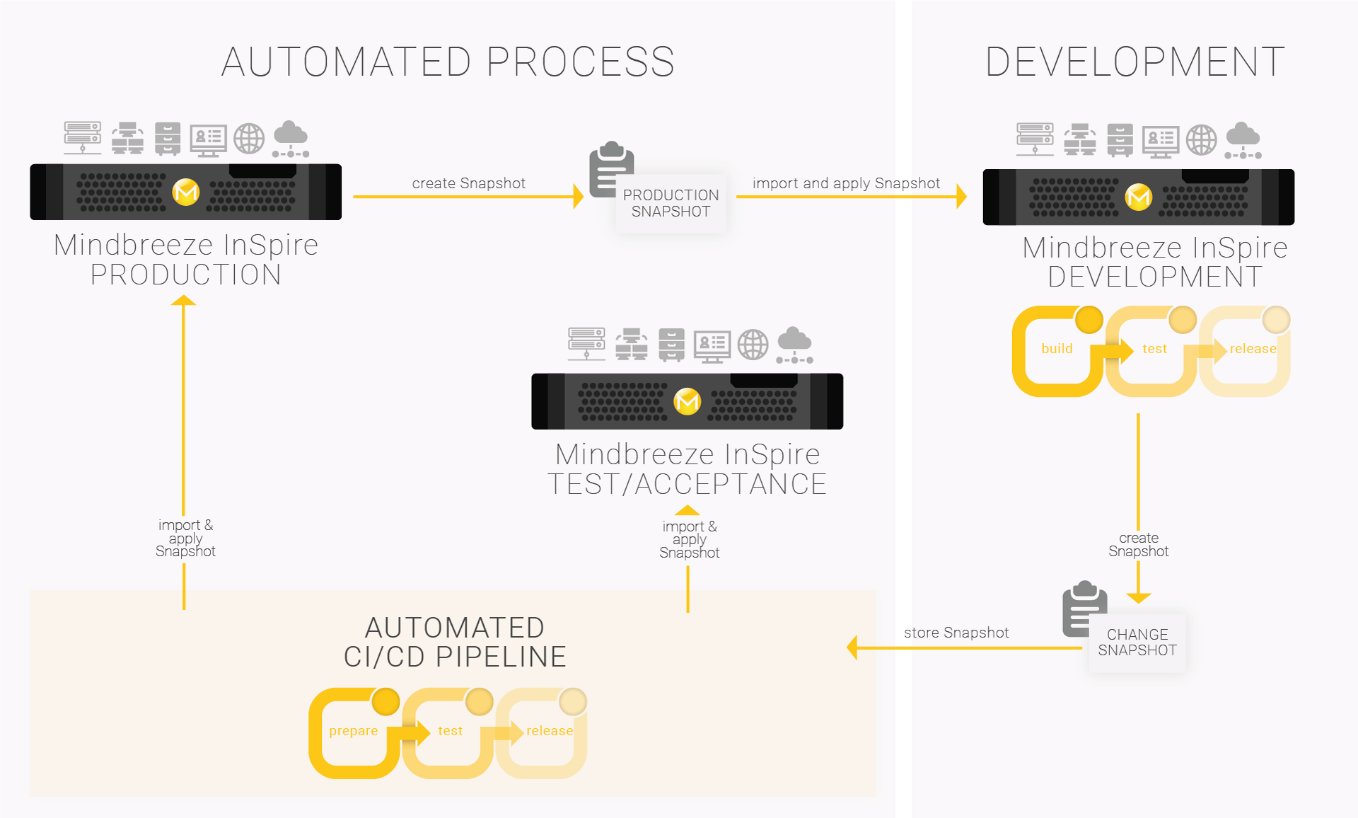
Through the introduction of configuration parameters and so-called developer snapshots, adjustments to
- the Mindbreeze Service configuration (add/remove and customize connectors, indexes, filters, client services, ...)
- of the semantics pipeline,
- of the Query Transformation Pipeline,
- InSpire Search Apps and
- any resource files like boostings, relevance parameters
can be exported as a snapshot and then automatically transferred to production.
Any settings (such as the source systems to be indexed) can be overwritten locally as parameters on the respective environment. This ensures that the production data sources are indexed in the production system and the developer data sources in the development system. Credentials and certificates are not stored in the snapshot and are preserved.
If you are interested, please contact us for a detailed white paper on how to use this new technology for your pipelines. Further information.
Extended connectors
Microsoft SharePoint Online: Enhanced support for user-based authentication
Delta Crawling and Site Discovery in SharePoint Online are now supported with user-based authentication. For Site Discovery, a new configuration option "Site Discovery Strategy" has also been added, which allows you to select the Site Discovery variant - Link to documentation
Atlassian Confluence: Support for custom properties
The Atlassian Confluence Sitemap Generator add-on now supports content properties so you can now search them with Mindbreeze InSpire. Link to documentation
Support for Atlassian Confluence 7.4 (LTS)
Atlassian Confluence 7.4 is the latest long term support version that you can now connect to Mindbreeze InSpire.
Technical extensions
JSON metadata processing
If Mindbreeze documents contain JSON metadata, new metadata can be generated from the individual elements of the JSON expression. For example, you can process an address in JSON format and generate individual metadata from it.
Raw JSON metadata:
{
"street": "Honauerstraße",
"house_number": "2",
"zip_code": "4020",
"city": "Linz"
}
The following metadata, for example, can be generated from it:
- address_street: Honauerstraße
- address_house_number: 2
- address_zip_code: 4020
- address_city: Linz
- full_address: Honauerstrasse 2, 4020 Linz
This is made possible by json_parse of the Property Expression Language (Link to documentation) and an extension in the "Precomputed Synthesized Metadata" (Link to documentation for Precomputed Synthesized Metadata). The generated metadata can also be made filterable and can now be added in the editor (Link to documentation).
Read PDF preview from file system
In order to optimize the size of the index, the Microsoft File Connector from 20.4 on offers the possibility to load the PDF contents from the file system (data source) when opening the preview instead of storing them in the index.
Information about configuration: Link to Documentation Microsoft File Connector, Link to documentation PDFFilter
Security relevant changes
- Update Google protobuf library to version 3.12.3 (CVE-2015-5237)
- OpenJDK Security Update 8u262 (Important/Moderate) : CVE-2020-14583, CVE-2020-14593, CVE-2020-14556, CVE-2020-14578, CVE-2020-14579, CVE-2020-14621, CVE-2020-14577
- jQuery CVEs: CVE-2020-11022
- Update Keycloak and Keycloak-HA to version 10.0: CVE-2019-10157, CVE-2019-10169,CVE-2019-10170, CVE-2019-10199, CVE-2019-10201, CVE-2019-14820, CVE-2019-14832, CVE-2019-14837, CVE-2019-3868, CVE-2019-3875, CVE-2020-1697, CVE-2020-1698, CVE-2020-1714, CVE-2020-1718, CVE-2020-1724, CVE-2020-1727, CVE-2020-1728, CVE-2020-1744, CVE-2020-1758
- Fix for: XSS in mustache.js
Additional changes
20.4.4.451
- Fix for: SIGSEGV due to race condition in _threadedFlushAndReleasePoolWriter
20.4.4.448
- Fix for: Snapshot API: Snapshot can be created with included mesconfig that cannot be restored because of missing version attribute in <Config>
- Optionally Rewrite Destination URL of FilterIndexRequest before sending it ito index
- api.v2.personalization supports global href actions
- Fix for: Principal Resolution Service Bulking: getBulkedNestedContainers is only called on startup
- Fix for: Multiple references in a single property are resolved to the same uniform_doc_id
- Custom Reporting Properties via QueryLogs REST-API
- SharePoint Online Principal Cache Attempt to resolve every group with Graph
- SharePoint Online Principal Cache Graph Resolution Improve Logging
- Fix for: Issues in app.telemetry instrumentation in SharePoint OnPremise
- SharePoint Online Principal Cache Optimizations
- GSA Feed Adapter: Feed record can trigger metadata update.
20.4.4.435
- Fix for: Microsoft File connector maxDocumentSize must be positive exception if FileSize is set to 2500
- SharePoint Crawler: Sync On Start up can include changes from the past N days.
- IBM Lotus Notes Connector: Principal Cache can use user properties as aliases.
- Fix for: Permissions of the log directory of the ClientService of the current symlink are root:root
- Outlook Add-In: CSS update with slimmer design
- DynamicQueryExpr can be used as QueryExpression in Search Requests
- Highcharts updated to version 8.1.2
- Fix for: SharePoint Online Connector deletes documents on OutOfMemoryException
- SharePoint Online Connector uses paging for API calls with large responses
- SnapshotParameterization and Resource Profiles
- Configuration UI can use parameters from the Node Environment
- Microsoft Dynamics Online CRM Principal Resolution Service: LDAP msDS PrincipalName resolution is configurable
- Fix for: SharePoint Online delta crawling does not work for very large lists
- Documentation: SAML Authentication with Microsoft Azure (Client Service)
- SharePoint Online/OneDrive: New configuration option "Grant Site Owner", with which the site owner always gets permission to the items of his page viaACLs
- SharePoint Online: Support for Delta Crawling with User Based Authentication
- SharePoint Online: Support for Site Discovery via Search with User Based Authentication
- Confuence Sitemap Generator Support for changing custom properties
- Fix for: Web Connector IOException after 100 crawl runs
- Client Service TrustedPeer Authentication with HTTP header supports setting a mail attribute.
- SharePoint Online Connector: Get author metadata from document properties
- Confluence Crawler: Spaces and elements (ID based) are removable
- Fix for: Filesystem Crawler terminates root traversal (STATUS_ACCESS_DENIED (0xc0000022))
- Upload of plugins > 1GB is possible
- ClientService: Alerting uses resolve principals for Identity
- Fix for: Inspire Nodes: Nodes overview is not reloaded automatically
- Fix for: SharePoint Connector does not index document libraries with more than 5000 sub-elements.
- Precomputed Synthesized Properties support MERGE_ON_ROOT_ITEM_USING_NAME_AS_PREFIX
- Property expression for parsing JSON to values: `json_parse(str)`
- Metadata can be set to be aggregatable by document at index time
- Unnecessary volumes are no longer mapped into the Webmin container
- Fix for: Openstreetmap map component queries tiles via http (mixed content)
- Fix for: RECONFIG_REMOTE_SERVICE_REGISTRATION Changes are ignored by ClientService
- Fix for: Filemanager: saving is not possible at the same time as search/filtering
- Client Service Alerting: Mail can be used from the identity properties.
- Support for Atlassian Confluence 7.4.3
- Fix for: Confluence Sitemap creation takes too long
- Fix for: Stop words are also removed from phrases
- Confluence/Web: Unneccesary HTTP-Requests if `Cleanup non matching URL-s from Index` and `Sitemap Based Complete` are active
- Fix for: alternative/user_query is no longer included in search-response
- Fix for: SameSite option on HTTP ClientServices causes some browsers not to accept the session cookie