
Egnyte Connector
Installation und Konfiguration
Copyright ©
Mindbreeze GmbH, A-4020 Linz, 2024.
Alle Rechte vorbehalten. Alle verwendeten Hard- und Softwarenamen sind Handelsnamen und/oder Marken der jeweiligen Hersteller.
Diese Unterlagen sind streng vertraulich. Durch die Übermittlung und Präsentation dieser Unterlagen alleine werden keine Rechte an unserer Software, an unseren Dienstleistungen und Dienstleistungsresultaten oder sonstigen geschützten Rechten begründet. Die Weitergabe, Veröffentlichung oder Vervielfältigung ist nicht gestattet.
Aus Gründen der einfacheren Lesbarkeit wird auf die geschlechtsspezifische Differenzierung, z.B. Benutzer/-innen, verzichtet. Entsprechende Begriffe gelten im Sinne der Gleichbehandlung grundsätzlich für beide Geschlechter.
Installation
Vor der Installation des Egnyte Connector muss sichergestellt werden, dass der Mindbreeze Server installiert und der Egnyte Connector in der Lizenz inkludiert ist. Zur Installation oder Aktualisierung des Konnektors verwenden Sie bitte das Mindbreeze Management Center.
Installation des Plugins via Mindbreeze Management Center
Zur Installation des Plugins öffnen Sie das Mindbreeze Management Center. Wählen Sie aus dem linken Menü den Punkt „Configuration“ aus. Anschließend navigieren Sie auf den Reiter „Plugins“. Im Abschnitt „Plugin Management“ wählen Sie die entsprechende Zip-Datei aus und laden sie durch Auswahl der Schaltfläche „Upload“ hoch. (Hinweis: Der Name des Plugins lautet „EgnyteWebRestConnector“.) Damit wird der Konnektor automatisch installiert oder gegebenenfalls aktualisiert. In diesem Zuge werden die Mindbreeze Dienste neugestartet.

Konfiguration von Index und Crawler
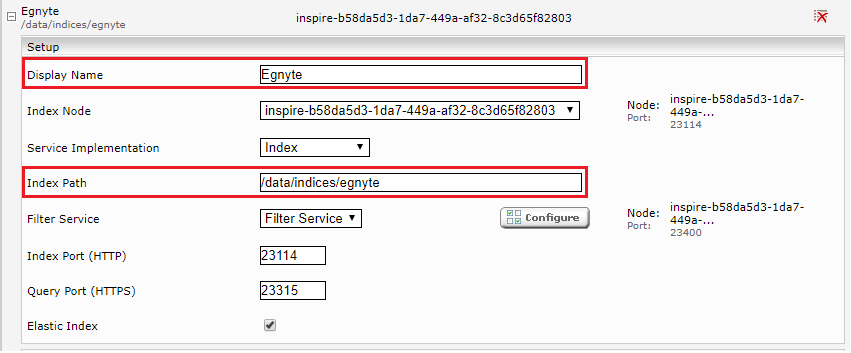
Navigieren Sie auf den Reiter „Indices“ und klicken Sie auf das Symbol „Add new index“ rechts oben, um einen neuen Index zu erzeugen.

Geben Sie den Pfad zum Index ein und ändern Sie gegebenenfalls den „Display Name“.
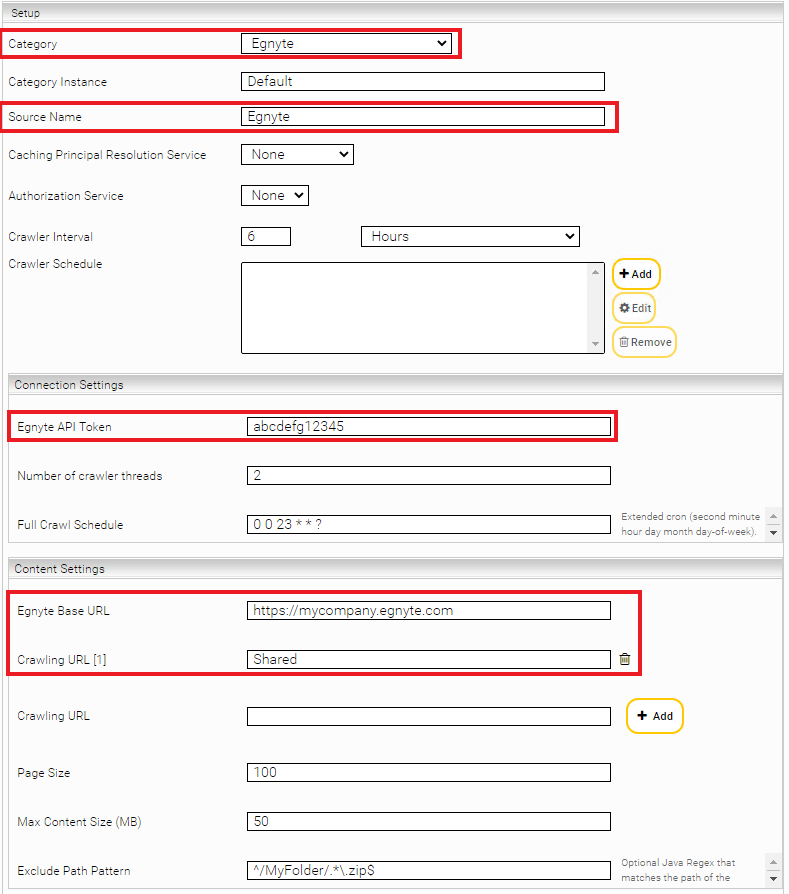
Fügen Sie eine neue Datenquelle durch Klick auf das Symbol „Add new custom source“ rechts oben hinzu. Wählen Sie die Category „Egnyte“ aus.
Konfigurieren Sie die Optionen wie folgt:
„Egnyte API Token“ | Das API Token für den Egnyte Webservice |
„Number of crawler threads“ | Anzahl der Threads, die parallel HTTP-Requests durchführen. Default: 2. |
„Full Crawl Schedule” | Extended Cron Expression der beim darauffolgenden Crawl Run einen Full-Crawl durchführt. (Optional) |
„Crawling URL“ | Pfad zum Verzeichnis, das indiziert werden soll. Mit dem Knopf „Add“ können Sie mehrere Pfade angeben. Hinweis: Der Pfad muss URL-encoded sein, Slashes (/) dürfen allerdings nicht URL-encoded werden. |
„Page Size“ | Max. Anzahl der Elemente, die bei einem Request heruntergeladen werden. Default 100. |
„Max Content Size (MB)“ | Max. Dateigröße, die zum Filter geschickt wird. Default: 50 MB. Bei größeren Dokumenten werden nur die Metadaten indiziert. |
„Exclude Path Pattern“ | Regulärer Ausdruck (Java), der auf den Pfad eines Dokument matched. Bei einem Match wird das Dokument nicht indiziert. Z.B. mit dem Ausdruck ^/MyFolder/.*\.zip$ wird das Dokument mit dem Pfad /MyFolder/test.zip nicht indiziert. (Optional) |
Hinweis:
Der Connector speichert kleine Datenmengen zwischen den Crawl-Runs im messervicedata-Verzeichnis (/data/messervicedata/<<service-guid>>/), dieses Verzeichnis kann bei Bedarf mit folgenden manuellen Property geändert werden: egnytepersistencedirectory .
Speichern Sie anschließend die Konfiguration und starten Sie neu.
Informationen über die Anzahl der Requests zu der Egnyte-API
Dieser Abschnitt beschreibt grob, wie viele HTTP-Requests der Connector im laufenden Betrieb an die Egnyte-API absetzt. Es wird unterschieden in Metadaten-Request, bei denen nur kompakte Metadaten, wie Titel, Autor oder Änderungsdatum abgerufen werden, und Content-Requests, bei denen der tatsächliche Inhalt der Dokumente, beispielsweise JPG oder PDF, abgerufen werden. Die hier beschriebene Anzahl der Request ist nur ein grobes Mengengerüst und dient zur Orientierung. Die tatsächliche Anzahl der Request kann möglicherweise abweichen.
Erstindizierung
Bei der Erstindizierung wird für jeden Ordner ein Metadaten-Request und für jede Datei ein Content-Request durchgeführt. Bei größeren Ordnern (größer als „Page Size“) wird für jede weitere Page ein weiterer Metadaten-Request durchgeführt.
Delta-Indizierung
Bei der Delta-Indizierung wird für jede neu hinzugefügte Datei ein Metadaten-Request und ein Content-Request durchgeführt. Für jede gelöschte Datei wird nur ein Metadaten-Request durchgeführt. Sind seit der letzten Delta-Indizierung viele Dateien hinzugefügt/gelöscht/geändert worden (mehr als „Page Size“), dann wird für jede weitere Page ein weiterer Metadaten-Request durchgeführt.
Vollindizierung (laut Full Crawl Schedule)
Bei einer Vollindizierung (mit bereits vollen Index) wird, wenn im Egnyte seit der letzten Vollindizierung nichts geändert hat, für jeden Ordner ein Metadaten-Request durchgeführt. Bei größeren Ordnern (größer als „Page Size“) wird für jede weitere Page ein weiterer Metadaten-Request durchgeführt. Content-Request werden nur dann durchgeführt, wenn aus den Metadaten ersichtlich ist, dass sich die Datei geändert hat. Dann wird für jede geänderte Datei ein Content-Request durchgeführt.