
Vokabulare für Synonyme und Autovervollständigung
Copyright ©
Mindbreeze GmbH, A-4020 Linz, 2024.
Alle Rechte vorbehalten. Alle verwendeten Hard- und Softwarenamen sind Handelsnamen und/oder Marken der jeweiligen Hersteller.
Diese Unterlagen sind streng vertraulich. Durch die Übermittlung und Präsentation dieser Unterlagen alleine werden keine Rechte an unserer Software, an unseren Dienstleistungen und Dienstleistungsresultaten oder sonstigen geschützten Rechten begründet. Die Weitergabe, Veröffentlichung oder Vervielfältigung ist nicht gestattet.
Aus Gründen der einfacheren Lesbarkeit wird auf die geschlechtsspezifische Differenzierung, z.B. Benutzer/-innen, verzichtet. Entsprechende Begriffe gelten im Sinne der Gleichbehandlung grundsätzlich für beide Geschlechter.
Einleitung
Vokabulare legen zu Suchbegriffen bevorzugte und alternative Begriffe fest. Diese können im Mindbreeze Management Center unter „Search Experience“ > „Vocabulary“ definiert werden.
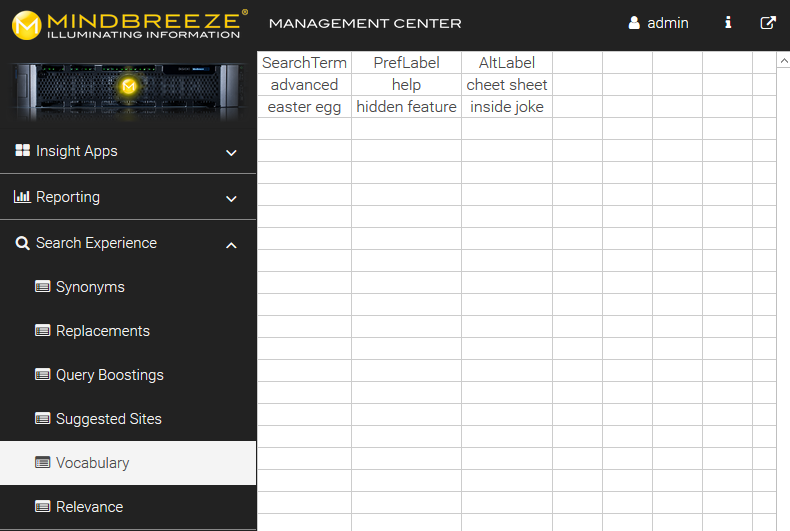
Dahinter liegt eine CSV-Datei, in der die Vokabulare definiert sind.
Ein Beispiel:
SearchTerm;PrefLabel;AltLabel
advanced;help;cheat sheet
easter egg;hidden feature;inside joke
Ist das VocabularySynonymTransformer-Plugin installiert, werden die Einträge als Synonyme behandelt. Die Suche nach advanced wird um help und cheat sheet erweitert. Dabei ist das prefLabel immer höher und das altLabel geringer gewichtet. Die Synonyme werden auch umgekehrt verwendet, eine Suche nach cheat sheet sucht auch nach advanced und help. Hierbei ist zu beachten, dass in den Synonym-Files keine Anführungszeichen verwendet werden dürfen.

Konfiguration
Das Plugin wird im Tab Plugins installiert (siehe Grafik):

Anschließend können Einstellungen im Indices-Tab sowie im Client-Service-Tab unter dem Punkt: „Query Transformation Services“ bzw. „Suggest Settings“ vorgenommen werden.
Unter dem Punkt Suggest Settings (Concept CSV) wird der Pfad zum CSV File angegeben.

Alternativ können Sie auch in „CSV File Pattern“ ein Pattern verwenden, um das CSV dynamisch auszuwählen. Dafür wird der „CSV File Path“ als Ordner interpretiert, und alle CSV-Dateien darin eingelesen. Wenn eine Suche einen SuggestRequest sendet, können Optionen mitgesendet werden, welche dann mit dem „CSV File Pattern“ das konkrete CSV-File auswählen, welches für die Suggest verwendet wird. Z.B. Wenn das „CSV File Pattern“ suggests_{{lang}}_{{source}}.csv gesetzt ist, ergibt SuggestRequest mit den Optionen lang:en, source:default die konkrete Datei suggests_en_default.csv. Diese Datei wird dann für Suggests dieses Request herangezogen.

Das Setting muss aktiviert werden:

Anschließend wird ein neues Query Transformation Service hinzugefügt (Indices-Tab).
(Dropdown-Value auswählen und „Add“ klicken)

Über das „+“-Symbol wird das neu hinzugefügte Service aufgeklappt und der File-Pfad zum Vocabulary File wird ausgegeben.
Es können mit dem Plugin auch spezielle Wörter „Stoppwörter“, oder andere ungewollte Wörter aus der Suche entfernt werden. Dazu muss in der Option „Stop Phrases File Path“ eine Datei mit Stop-Phrasen angegeben werden. Die Datei muss eine Textdatei sein, in der in jeder Zeile ein oder mehrere Wörter stehen.
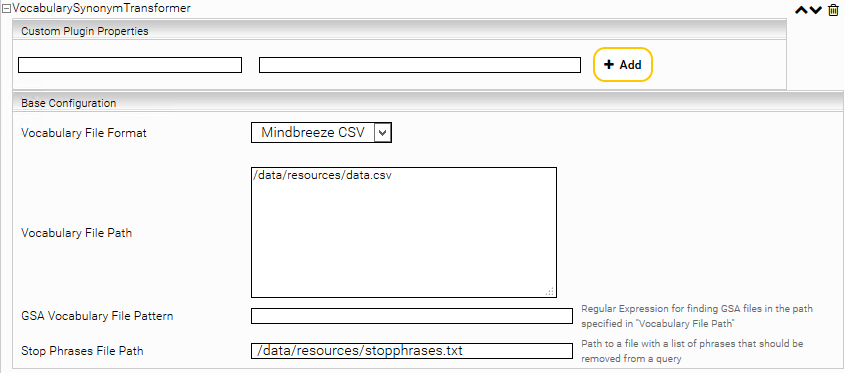
Beispiel für ein Vocabulary-CSV-File finden Sie im .
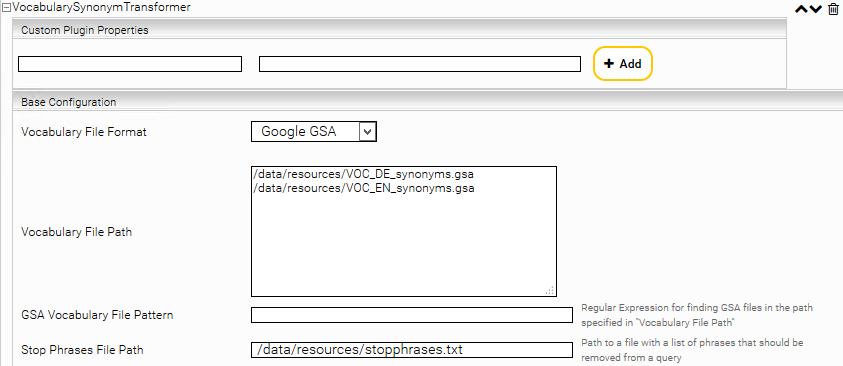
Alternativ zum CSV-File Format wird auch das Google-Search-Appliance (GSA) File Format unterstützt. Wählen Sie dazu bei „Vocabulary File Format“ Google GSA aus und geben sie bei „Vocabulary File Path“ die Vokabular-Dateien an. Sie können mehrere Dateien angeben.
Für GSA-Dateien können Sie alternativ auch ein Basisverzeichnis und einen regulären Ausdruck angeben. Alle übereinstimmenden Dateien, die unmittelbar im Basisverzeichnis liegen, werden geladen.
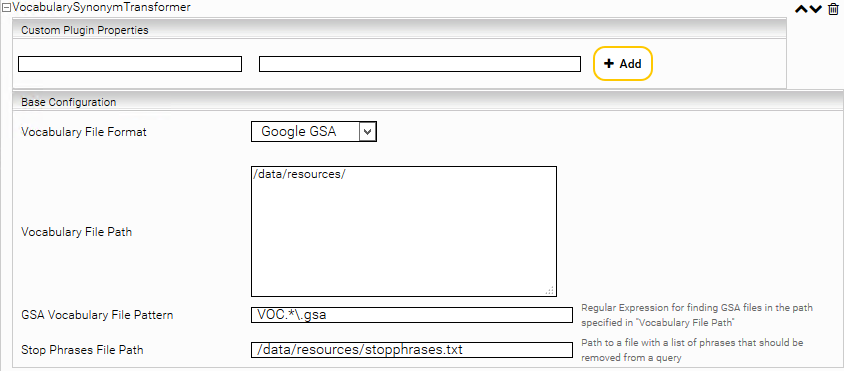
Wenn Sie einen regulären Ausdruck verwenden, werden neue Dateien nicht automatisch erkannt. Allerdings wird bei einer Änderung einer alten GSA-Datei die gesamte Liste der GSA-Dateien neu geladen (Inklusive möglicher neuen Dateien).
Sonderbehandlung von Akronymen
Akronyme sind Abkürzungen wie z.B. „IT“ für „Information Technology“. Es macht Sinn, Akronyme als Synonyme aufzunehmen, um die Suche zu verbessern. Ein Akronym besteht ausschließlich aus Großbuchstaben. Zur Verbesserung der Ergebnisqualität werden Akronyme exakt und unter Berücksichtigung der Groß- und Kleinschreibung gesucht. Das bedeutet, eine Suche nach z.B. „IT“ finden Dokumente wie „Information Technology“, jedoch nicht Dokumente wie „When it rains“ (da „it“ klein geschrieben ist.)
Dies gilt sowohl für CSV als auch für GSA-Dateien.
Behandlung von Terms mit numerischem Suffix
In speziellen Fällen möchte man bei der Suche nach z.B. event123 den ersten Teil (event) als Basis für die Synonym-Verarbeitung verwenden. Beispielsweise möchte man Dokumente mit appointment123 finden, indem ein Synonym von event auf appointment definiert wird. Damit dies möglich ist, muss die Option „Compound Split Numeric Suffixes“ aktiviert werden. Hinweis: das aktivieren dieser Funktion kann unerwartete Nebeneffekte hervorrufen und sollte nur in Ausnahmenfällen unter Vorsicht verwendet werden.
Entfernen von Stoppwörtern bei exakten Suchen
Standardmäßig werden Stoppwörter (definiert in „Stop Phrases File Path“) bei exakten Suchen (Quoted Terms) entfernt. Falls dies jedoch nicht durchgeführt werden soll, kann dies mit der Einstellung „Remove Stop Phrases from Quoted Terms“ deaktiviert werden.
In folgenden Beispiel macht es Sinn, diese Einstellung zu deaktivieren: Beispielsweise beim Stoppwort of wird bei der exakten Suche nach "Game of Life" nur das Dokument mit Game Life gefunden, nicht jedoch das erwartete Dokument mit Game of Life, da of entfernt wurde und nun effektiv eine exakte Suche nach "Game Life" durchgeführt wird.
Unterscheidung zwischen den Plugins Synonym Transformer und Vocabulary Synonym Transformer
Beide Plugins transformieren eine Suchanfrage damit auch nach Synonyme gesucht wird. Die Plugins unterscheiden sich jedoch in folgenden Punkten:
Synonym Transformer Plugin:
- Wird mit einer CSV-Datei konfiguriert
- CSV-Syntax: 2 oder mehr Spalten
- Alle Synonyme haben die gleiche Gewichtung
- Nur einzelne Wörter ohne Leerzeichen werden unterstützt
Vocabulary Synonym Transformer Plugin:
- Kann mit mehreren CSV-Dateien oder GSA-Dateien konfiguriert werden
- CSV-Syntax: 3 Spalten (effektiv)
- Je nach Spalte haben Synonyme schwächere Gewichtung
- Mehrwort-Ausdrücke werden unterstützt
Autovervollständigung
Erlaubt die Verwendung der Autovervollständigung in einem Eingabefeld. Es können u.a. die beliebtesten Suchen, die zuletzt durchgeführten Suchen und Begriffe aus Taxonomien vorgeschlagen werden.
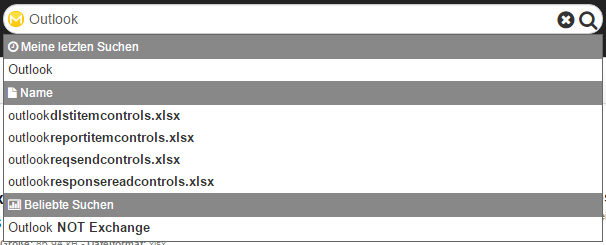
Beispiele:
<input data-template="suggest"
data-placeholder="search"
class="mb-query"
name="query"
type="search"
data-aria-label="search"
autofocus
data-source-id-pattern="database"
data-grouped="true"
data-show-onfocus="true">
Einstellungen
- property: das Metadatum, das für die Vervollständigung verwendet werden soll. Standardwert: title
- property-constraint: ein Suchbegriff zur Einschränkung der möglichen Werte. Standardwert: leer
- count: die Anzahl der Vorschläge. Standardwert: 4
- source: DOCUMENT_PROPERTY liefert Vorschläge aus Metadaten, QUERY_TERM von früheren Suchen und CONCEPT aus einem Konzeptindex. Für QUERY_TERM und CONCEPT sind zusätzliche Einstellungen in der Mindbreeze Konfiguration nötig. Standardwert: DOCUMENT_PROPERTY
- service: URL zu einem Suggest-Service. Standardwert: leer - gleich wie Suche
- disabled: Vorschläge sind deaktiviert. Standardwert: leer
- source-id-pattern: recent_query liefert Vorschläge aus den letzten Suchen
- grouped: Gruppiert die Autocomplete-Treffer zusammen (true/false) – Standardwert: true
- show-onfocus: Zeigt das Autocomplete beim Fokussieren des Textfeldes an (true/false) – Standardwert: false

Einstellen lassen sich die vorgeschlagenen Suchbegriffe im Konfigurator wie folgt:
- Similar Terms
Enable Suggesting of Similar Queries: Wenn angehakt, wird das Suggest über die ähnlichen Suchbegriffe aus der App.Telemetry Datenbank gelesen
ID: Eine ID kann für die jeweilige Suggestquelle vergeben werden (z.B. zum Stylen)
Source Name: Der Source Name kann z.B. „Popular Searches“ also beliebte Suchen, sein
Database JDBC URL: URL zur App.Telemetry Datenbank
Max Number Of Database Connections: Maximale Anzahl der Datenbankverbindungen. Standardwert: 10, Minimalwert: 2.
Table Name: Tabellenname aus der App.Telementry-Konfiguration
Table Column for Query: Auswahl der Anzahl der Ergebnisse – App Telemetry-Konfiguration
Table Column for Score: Auswahl des Spaltennamen der Ergebnisse aus der App Telemetry-Konfiguration (
Table Column for View ID: Auswahl des Spaltennamen der Abfragen aus der App Telemetry-Konfiguration
Additional WHERE Clause: Hier haben Sie die Möglichkeit, verschiedene „WHERE“-Klauseln zu erstellen und hinzuzufügen.
Suggest If User Query Is Empty: wenn „true“ aktiviert ist, werden Vorschläge ausgegeben, auch wenn der User noch nicht gesucht hat.
Concept CSV
Enable Suggesting from CSV File: Wenn angehakt, wird das Suggest über die ähnlichen Suchbegriffe aus einem CSV-File gelesen
ID: Eine ID kann für die jeweilige Suggestquelle vergeben werden (z.B. zum Stylen)
Source Name: Der Source Name kann z.B. „Words and Terms“ also Worte und Begriffe, sein
CSV File Path: Der Pfad zum CSV-File