
Betrieb
Index Betriebskonzepte
Copyright ©
Mindbreeze GmbH, A-4020 Linz, 2024.
Alle Rechte vorbehalten. Alle verwendeten Hard- und Softwarenamen sind Handelsnamen und/oder Marken der jeweiligen Hersteller.
Diese Unterlagen sind streng vertraulich. Durch die Übermittlung und Präsentation dieser Unterlagen alleine werden keine Rechte an unserer Software, an unseren Dienstleistungen und Dienstleistungsresultaten oder sonstigen geschützten Rechten begründet. Die Weitergabe, Veröffentlichung oder Vervielfältigung ist nicht gestattet.
Aus Gründen der einfacheren Lesbarkeit wird auf die geschlechtsspezifische Differenzierung, z.B. Benutzer/-innen, verzichtet. Entsprechende Begriffe gelten im Sinne der Gleichbehandlung grundsätzlich für beide Geschlechter.
Einleitung
In diesem Dokument wird auf die Konzepte von Mindbreeze InSpire eingegangen. Diese Konzepte beziehen sich einerseits auf den Standalone-Betrieb (mit nur einer Appliance), aber auch auf den verteilten Betrieb (mit mehreren Appliances).
Glossar
Aggregatable
Ist ein Metadatum aggregatable (aggregierbar), ist es automatisch auch regexmatchable, mit der zusätzlichen Eigenschaft, dass das Metadatum als Facette (Filter) zur Verfügung steht. Man unterscheidet zwischen:
- Static Aggregatable: pro Metadatum global für den ganzen Index im Index-Schema definiert. Eine Index-Schema-Änderung erfordert eine Re-Invertierung des Index.
- Dynamic Aggregatable: pro Metadatum und pro Dokument definiert. Da dies nicht im Index-Schema definiert wird, ist keine Re-Invertierung notwendig. Somit können Metadaten für bestimmte Dokumente ganz flexibel „aggregatable“ gemacht werden.
Aggregated Metadata Keys
Die „Aggregated Metadata Keys“ können pro Index konfiguriert werden, wobei die „Advanced Settings“ aktiviert sein müssen, damit diese Option sichtbar ist. Damit ist es möglich, Metadaten als „aggregatable“ zu markieren. Änderungen in dieser Option ziehen eine Änderung des Indexschemas nach sich.
Built-In Metadata Keys
Folgende Metadata Keys sind für Built-In Metadaten reserviert:
Name | Typ |
mes:docid | Integer |
mes:key | String |
mes:size | Integer |
category | String |
fqcategory | String |
categoryclass | String |
categoryscope | String |
mes:date | String |
title | String |
datasource/mes:key | String |
datasource/category | String |
datasource/fqcategory | String |
extension | String |
mes:boost | Float |
mes:uniformdocid | Integer |
Regexmatchable
- Regexmatchable Metadaten können mittels RegEx durchsucht werden (relevant für Custom Search Clients, siehe api.v2.search)
Category / Category Instance / Fully Qualified Category
Die „Category“, „Category Instance“ und die „Fully Qualified Category“ werden in der untenstehenden Tabelle beschrieben:
Name | Metadatum | Beschreibung |
Category | datasource/category | Dokumente, die von einem bestimmten Crawler indiziert werden, haben immer die gleiche Category. Diese ist also nicht konfigurierbar. |
Category Instance | datasource/categoryinstance | Die Category Instance kann bei den meisten Crawlern konfiguriert werden, sodass diese die Category Instance für ihre gecrawlten Dokumente setzen. |
Fully Qualified Category | datasource/fqcategory | Die Fully Qualified Category wird generiert, indem die Category und Category Instance zusammengesetzt wird (mit einem Doppelpunkt in der Mitte, z. B. Web:Default). Diese muss für jeden Crawler eindeutig sein, falls jeder Crawler im Search Client einen eigenen Filter-Wert für den Filter Quelle erhalten soll. |
Index Document Info
Als Document Info wird jener Teil des Index benannt, der In-Memory für Analyse zur Verfügung steht. Die Steuerung der Document Info Zonen (Eigenschaften) kann über den Category Descriptor, die Semantic Pipeline oder die Aggregated Metadata Keys erfolgen.
Index Document Info Schema (Index Schema)
Die Ausprägung welche Eigenschaften via der Document Info zur Verfügung stehen, wird auch Document Info Schema genannt.
Index Konfiguration
Die Index Konfiguration umfasst alles was den Index konfiguriert. Die Index Konfiguration ist im Index Dateisystem abgelegt.
Index Schema-Änderung
Eine Schema-Änderung zieht eine Document Info-Reinvertierung nach sich. In der folgenden Liste finden Sie Beispiele, die eine Schema-Änderung verursachen:
- Änderungen in „Aggregated Metadata Keys“
- Änderungen im Category Descriptor (in Bezug auf aggregatable und regexmatchable)
- Precomputed Synthesized Metadata (wenn aggregateable)
- Entity Recognition
Index Invertierung / Re-Invertierung
Nachdem ein gefiltertes Dokument im Index abgelegt wird, wird es invertiert, sodass es durchsuchbar wird („Index Invertierung“). Außerdem werden Dokumente während der Invertierung mit Metadaten angereichert (beschrieben in der Semantic Pipeline).
Bei einer Schema-Änderung wird der Index automatisch bezüglich der Document Info neu invertiert.
Vollständige Re-Invertierung
Bei der vollständigen Re-Invertierung wird nicht nur die Dokumentinfo neu invertiert, sondern der gesamte invertierte Index neu aufgebaut.
Dazu kann das Skript /opt/mindbreeze/scripts/move_inverted_index.sh benutzt werden.
Dabei wird der invertierte Index in das angegebene Backupverzeichnis verschoben und beim nächsten Indexstart neu aufgebaut.
Der betroffene Index muss dabei gestoppt sein. Nach dem Starten ist der Index erst nach Abschluss der Re-Invertierung wieder verfügbar.
./move_inverted_index.sh
--basedir INDEX_DIRECTORY
--destdir BACKUP_DIRECTORY
[--category CATEGORY]
[--bucket BUCKET_NR]
[--overwrite]
| --help | -h
Wird weder die category noch ein bucket angegeben, so wird der invertierte Index aller „Categories“ in allen „Buckets“ verschoben.
Der Parameter category beschränkt das auf die spezifizierte „Category“.
Der Parameter bucket beschränkt das auf das angegebene „Bucket“.
Multi Index Layout
Eine spezielle Form des Aufbaus eines Index. Standardmäßig wird für alle Indizes das „Multi Index Layout“ verwendet, was vor allem für den verteilten Betrieb mit mehreren Mindbreeze InSpire Appliances wichtig ist. Siehe auch Handbuch – Verteilter Betrieb (G7) – Index Layout.
Semantic Pipeline
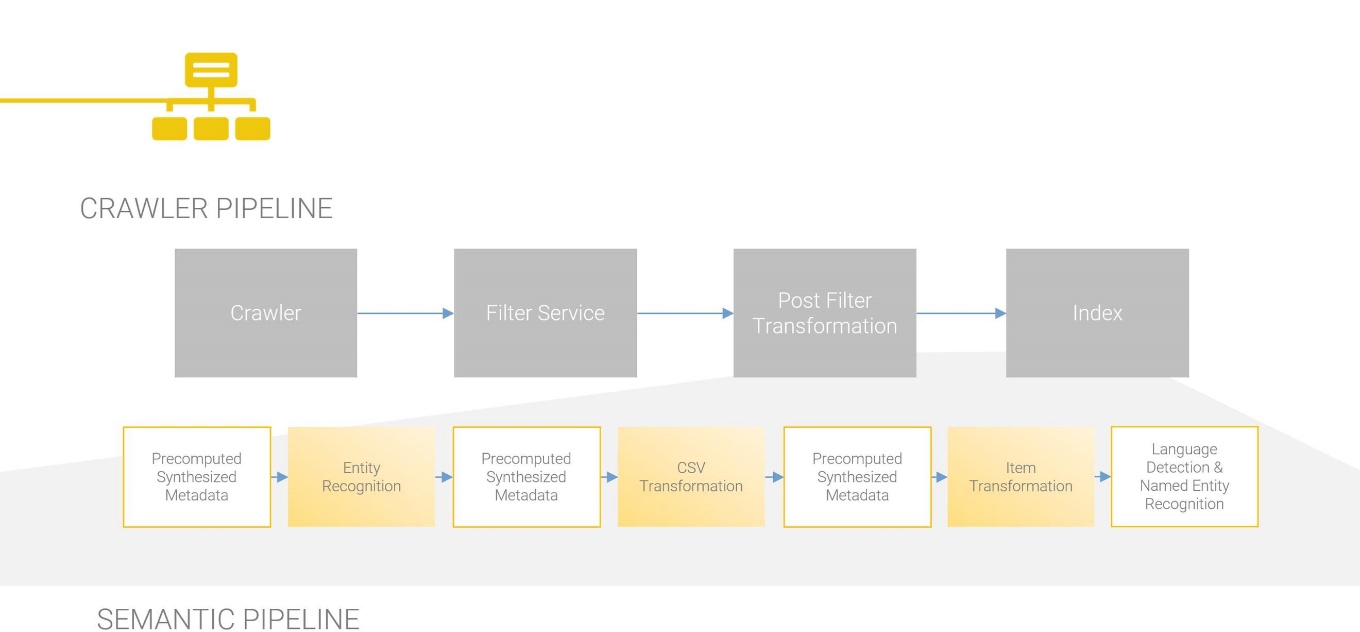
Dokumente werden vom Crawler oder Pusher in der Semantic Pipeline verarbeitet und anschließend indiziert. Folgende Schritte werden dabei durchgeführt:
Filter / Content Filter
Der Filter schickt je nach Datei-Typ Dokumente weiter an die jeweiligen Content Filter. Die gefilterten Dokumente werden wieder an den Filter zurückgeschickt, um möglicherweise die gefilterten Dokumente nochmal an die jeweiligen Content Filter zu schicken. Ein Beispiel hierfür sind ZIP-Dokumente, die zuerst mit einem Content Filter entpackt werden müssen und anschließend mit weiteren Content Filtern prozessiert werden. Filter können im Mindbreeze Management Center unter „Configuration“ im Reiter „Filter“ konfiguriert werden und im Reiter „Indizes“ für die jeweiligen Indizes ausgewählt werden.
Post Filter
Mithilfe von Post Filter kann der Inhalt von bereits gefilterten Dokumenten prozessiert und verändert werden, bevor das Dokument zum Index gesendet wird.
Precomputed Synthesized Metadata
Mithilfe von „Precomputed Synthesized Metadata” können neue Metadaten auf Basis von anderen Metadaten generiert werden. Der Zeitpunkt, wann diese Metadaten generiert werden sollen (in der Semantic Pipeline), kann mit der Option „Transformation Pipeline Slot“ bestimmt werden. Eine ausführliche Dokumentation finden Sie hier.
Entity Recognition
Mithilfe von „Entity Recognition“ können Metadaten generiert werden, indem gewisse Muster aus einem Text erkannt werden (mithilfe von Regex). So können Beispielsweise Datum, UNC-Pfade, etc. erkannt werden. Eine ausführliche Dokumentation finden Sie hier.
CSV Transformation
Mithilfe der „CSV Transformation“ können auch Metadaten generiert werden. Dabei ist es möglich einen Wert eines Metadatums mit einem Wert einer bestimmten Spalte im CSV zu vergleichen. Stimmt der Wert aus dem Metadatum mit dem Wert aus der Spalte überein, kann man den Wert einer anderen Spalte aus derselben Zeile in ein neues Metadatum schreiben und dem Resultat anfügen. Weitere Informationen können in der Dokumentation Konfiguration – Metadaten Anreicherung gefunden werden.
Item Transformation
Eine weitere Möglichkeit, um Dokumente mit Metadaten anreichern zu können, sind Item Transformatoren. Mindbreeze InSpire bietet dabei verschiedene Item Transformatoren, wie z. B. das LanguageDetector Plugin.
Language Detection & Named Entity Recognition
Mithilfe der im Index integrierten „Language Detection“ kann die Sprache eines Dokuments ohne zusätzliches Plugin erkannt werden.
Die anschließende „Named Entity Recognition (NER)“ kann Entitäten sowohl im Inhalt als auch in den Metadaten eines Dokuments identifizieren und klassifizieren. Eine ausführliche Dokumentation finden Sie hier.