
Sure, you can handle it. But should you?
Let our experts manage the tech maintenance while you focus on your business.
Let our experts manage the tech maintenance while you focus on your business.
Spracherkennung
LanguageDetector Plugin
Einleitung
Mindbreeze bietet eine Spracherkennung für Dokumente. Dazu wird beim Indizieren das LanguageDetector ItemTransformer Plugin verwendet.
LanguageDetector Plugin
Um die Spracherkennung zu nutzen, muss das LanguageDetector zu Ihrer Mindbreeze-Installation hinzugefügt werden, indem das entsprechende Plugin geladen wird (die Item Transformation Services werden mit dem Paket “ Mindbreeze Item Transformation Plugins” ausgeliefert).
Das Plugin muss auch in Ihrer Mindbreeze Lizenz inkludiert sein.
Konfiguration
- Aktivieren Sie das Plugin für jeden gewünschten Index mithilfe der Manager UI:
- Wechseln Sie zum Reiter „Indices“ und aktivieren Sie „Advanced Settings“
- Scrollen Sie runter zum Abschnitt „Item Transformation Services”
- Wählen Sie das “TextPlugin.LanguageDetector” Plugin und klicken Sie auf „Add“

- Language Probability Threshold: Legt fest, ab welcher Wahrscheinlichkeit eine Sprache als erkannt gilt.
- Source Property Pattern: Legt das Metadatum fest welches zur Spracherkennung herangezogen wird.
- Language Target Property: Legt das Metadatum fest in dem das Ergebnis der Spracherkennung festgehalten wird. Um nach diesem Metadatum filtern zu können, muss dieses aggregierbar sein. Aktivieren Sie dazu die Advanced Settings und fügen Sie das Metadatum in der Option Aggregated Metadata Keys in der Indexkonfiguration hinzu.
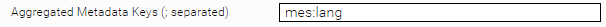
- Language Property: Legt das Metadatum fest in dem die Sprache bereits angegeben ist. Dadurch wird keine Spracherkennung durchgeführt und das Metadatum Language Target Property wird direkt gesetzt.
- Language Property Pattern: Legt alle gültigen Sprachen vom Language Property Metadatum fest. Falls Language Property einen ungültigen Wert hat wird die Spracherkennung durchgeführt und das Metadatum Language Target Property gesetzt.
- Included Languages: Legt die Sprachen für Spracherkennung fest (verwenden Sie die Sprachkürzel, siehe Tabelle unten im Appendix Abschnitt, mit Beistrichen getrennt, z.B. en,de). Falls keine Sprachen angegeben werden, versucht das Plugin alle unterstützten Sprachen zu erkennen. Es wird empfohlen, die benötigten Sprachen anzugeben, da dies die Qualität der Spracherkennung deutlich verbessert.
- Force Included Languages: Wenn aktiviert, werden die Warscheinlichkeiten nur auf Basis der „Included Languages“ berechnet. (und nicht auf Basis aller unterstützten Sprachen) Wenn nur wenige Sprachen in „Included Languages“ konfiguriert sind, wird empfohlen diese Option zu deaktivieren.
- Short Text Algorithm Text Length: Bei kurzen Texten kann die Qualität der Spracherkennung verbessert werden, wenn der „Short Text Algorithm“ verwendet wird. Diese Einstellung bestimmt die maximale Länge des Textes (in Buchstaben) für den der „Short Text Algorithm“ verwendet wird. Längere Texte werden mit dem „normalen“ Algorithmus analysiert.
- Max Text Length (Characters): Bestimmt die maximale Länge des Textes (in Anzahl von Buchstaben), der für die Analyse verwendet wird. Aus Performanzgründen werden bei längeren Texten nur die ersten Buchstaben zur Analyse verwendet, der Rest wird übersprungen. Zur Länge des Textes zählen aufsummiert der Inhalt aller Metadaten, die mit dem Source Property Pattern gefunden werden. Standardwert: 100000
- No Language found set Property Key und No Language found Property Value: Wenn die Spracherkennung keine Sprache ermitteln konnte, kann ein Metadatum mit einem Namen (Key) und einen Wert (Value) gesetzt werden. Dies kann nützlich sein, um Dokumente ohne erkannter Sprache explizit zu markieren.
Betrieb als eigenständiger Service
Das LanguageDetector Plugin kann nicht nur als Item Transformation Service genutzt werden, sondern auch als eigenständiger Service. Dies kann bei großen Installationen mit mehreren Indizes Performancevorteile bringen, da nur ein einzelner LanguageDetector Service für alle Indizes betrieben wird und nicht je Index eine Instanz.
Um das LanguageDetector Plugin als eigenständigen Service zu betreiben, installieren Sie das Plugin MetadataTransformationService-<version>.zip. Fügen Sie im „Indices“-Tab in der Sektion „Services“ einen neuen Service hinzu und wählen Sie „ItemTransformationServicePlugin.LanguageDetector“ aus. In den Einstellungen des neuen Service setzen Sie einen sprechenden „Display Name“, sowie den „Bind port“ auf einen freien TCP-Port. Die restlichen Einstellungen sind laut dem Abschnitt „Konfiguration“ zu setzen. Zuletzt wechseln Sie im „Indices“-Tab in die Sektion „Indices“ und fügen Sie bei dem betreffenden Index einen Item Transformation Service hinzu und referenzieren Sie den angelegten Service.
Appendix
Sprachprofile
Hier finden Sie eine Liste an Sprachprofile, die vom LanguageDetector unterstützt werden. Die angeführten Sprachen können in der Konfiguration des LanguageDetectors (Option „Included Languages“) verwendet werden. Die Option „Short Text Algorithm Text Length“ definiert dabei, für welche Textlängen das Lang- oder Kurztextprofil der jeweiligen Sprachen ausgewählt wird.
Sprache | Langtextprofil | Kurztextprofil | |
af | Afrikaans | X | |
an | Aragonisch | X | |
ar | Arabisch | X | |
ast | Asturisch | X | |
be | Weißrussisch | X | |
br | Bretonisch | X | |
ca | Katalanisch | X | |
bg | Bulgarisch | X | |
bn | Bengalisch | X | |
cs | Tschechisch | X | X |
cy | Walisisch | X | |
da | Dänisch | X | X |
de | Deutsch | X | X |
el | Griechisch | X | |
en | Englisch | X | X |
es | Spanisch | X | X |
et | Estnisch | X | |
eu | Baskisch | X | |
fa | Persisch | X | |
fi | Finnisch | X | X |
fr | Französisch | X | X |
ga | Irisch | X | |
gl | Galicisch | X | |
gu | Gujarati | X | |
he | Hebräisch | X | |
hi | Hindi | X | |
hr | Kroatisch | X | |
ht | Haitianisch | X | |
hu | Ungarisch | X | |
id | Indonesisch | X | X |
is | Isländisch | X | |
it | Italienisch | X | X |
ja | Japanisch | X | |
km | Khmer | X | |
kn | Kannada | X | |
ko | Koreanisch | X | |
lt | Litauisch | X | |
lv | Lettisch | X | |
mk | Mazedonisch | X | |
ml | Malayalam | X | |
mr | Marathi | X | |
ms | Malaysisch | X | |
mt | Maltesisch | X | |
ne | Nepali | X | |
nl | Niederländisch | X | X |
no | Norwegisch | X | X |
oc | Okzitanisch | X | |
pa | Punjabi | X | |
pl | Polnisch | X | X |
pt | Portugiesisch | X | X |
ro | Rumänisch | X | X |
ru | Russisch | X | |
sk | Slowakisch | X | |
sl | Slowenisch | X | |
so | Somalisch | X | |
sq | Albanisch | X | |
sr | Serbisch | X | |
sv | Schwedisch | X | X |
sw | Suaheli | X | |
ta | Tamilisch | X | |
te | Telugu | X | |
th | Thailändisch | X | |
tl | Tagalog | X | |
tr | Türkisch | X | X |
uk | Ukrainisch | X | |
ur | Urdu | X | |
vi | Vietnamesisch | X | X |
yi | Jiddisch | X | |
zh-cn | Vereinfachtes Chinesisch | X | |
zh-tw | Traditionelles Chinesisch | X |