
Sure, you can handle it. But should you?
Let our experts manage the tech maintenance while you focus on your business.
Let our experts manage the tech maintenance while you focus on your business.
Microsoft File Connector
Installation und Konfiguration
Video Tutorial „Set up a Microsoft File Connector”
Dieses Video beschreibt, wie der Microsoft File Connector konfiguriert wird. Erfahren Sie, welche Voraussetzungen notwendig sind und wie Sie den Index konfigurieren. Zusätzlich wird auf Active Directory Based Authentication sowie LDAP eingegangen und Sie erfahren, wie man gecrawlte Dokumente und Crawl-Runs in app.telemetry analysiert:
https://www.youtube.com/watch?v=S2JCrM98W30
Konfiguration von Mindbreeze
Klicken sie auf “Indices” und auf das “Add new index” Symbol um einen neuen Index zu erstellen.
Eingabe eines neuen Index Pfades z.B, “/data/indices/fileshare ”. Falls notwendig muss der Display Name des Index Services und des zugehörigen Filter Services geändert werden.
Mit “Add new custom source” unten rechts kann eine neue Datenquelle hinzugefügt werden.


Einstellung | Beschreibung |
Ignore Category Instance | Wenn mehrere File Crawler auf einem Index konfiguriert sind, wird bei der Suche nicht auf konkrete Category Instances eingeschränkt. |
Authorization Service | Aktuell wird für Microsoft File kein Authorization Service zur Verfügung gestellt. |
Konfiguration der Datenquelle
Caching Principal Resoution Service
Als Caching Principal Resolution Service kann ein CachingLdapPrincipalResoution ausgewählt werden. Es wird dann für das Auflösen der AD Gruppenmitgliedschaft eines Benutzers bei der Suche verwendet.
Für die Konfiguration von Caching Principal Resolution Service siehe Caching Principal Resolution Service.
Bereich „Sources“
Konfigurieren Sie die folgenden Einstellungen im Bereich „Sources“ in der Datenquelle:


Einstellung | Beschreibung |
In dieser Option können Sie festlegen, welche Verzeichnisse gecrawlt werden sollen. Hinweise:
Achtung: Stellen Sie sicher, dass der angegebene Pfad mit einem umgekehrten Schrägstrich bzw. „Backslash“ endet. Ist dies nicht der Fall, wird der angegebene Pfad nicht anerkannt. | |
Supports SMBv2/v3 | Wenn deaktiviert, wird nur das SMBv1 Protokoll verwendet. Wenn aktiviert, werden ebenfalls SMBv2/v3 Protokolle verwendet. |
Disable SMB Packet Signing | Wenn aktiviert, wird für gesendete SMB-Pakete keine Signatur erzeugt und für empfangene Paketen wird die Signatur nicht verifiziert. |
Encrypt Data (Advanced Setting) | Aktiviert die Datenverschlüsselung. Stellen Sie sicher, dass “Maximum SMB2 Dialect” entweder Auto oder einer der folgenden SMB2-Dialekte ist: 3.0.0, 3.0.2, 3.1.1. |
Disable SMB2 Multi-Protocol Negotiate | Wenn aktiviert, können dadurch bessere Fehlermeldungen ausgegeben werden falls der Server nur SMBv1 unterstützt. |
Minimum SMB2 Dialect (Advanced Setting) | Unterstützte SMB2-Dialekte sind 2.0.2, 2.1.0, 3.0.0, 3.0.2 und 3.1.1. Dieser Wert sollte kleiner oder gleich dem „Maximum SMB2 Dialect“-Wert sein. Der tatsächlich verwendete SMB2-Dialekt wird durch das Ergebnis der „SMB2 Protocol Negotiation“ mit dem Dateifreigabeserver bestimmt. |
Maximum SMB2 Dialect (Advanced Setting) | Unterstützte SMB2-Dialekte sind 2.0.2, 2.1.0, 3.0.0, 3.0.2 und 3.1.1. Dieser Wert sollte kleiner oder gleich dem „Maximum SMB2 Dialect“-Wert sein. Der Standardwert ist Auto. Für Azure Fileshares wird der Wert auf 3.1.1 gesetzt. Für alle anderen Fileshares wird der Wert auf 3.0.2 gesetzt. Der tatsächlich verwendete SMB2-Dialekt wird durch das Ergebnis der „SMB2 Protocol Negotiation“ mit dem Fileshare-Server bestimmt. |
SMB Client Transaction Timeout | Hier kann der Thread-Timeout (in Sekunden) für SMB Verbindungen festgelegt werden. |
SMB Client Socket Timeout | Hier kann der Socket-Timeout (in Sekunden) für SMB Verbindungen festgelegt werden. |
Crawl Last Modified Directory Files First | Wenn aktiviert, werden während der Traversierung eines Verzeichnisses, die Dateien und Unterverzeichnisse nach Änderungsdatums sortiert. Dadurch werden die zuletzt geänderten Dateien und Verzeichnisse zuerst gecrawlt. |
Root Traversal Threads Count | Hier kann die Anzahl von Threads festgelegt werden, die die Verzeichnisse vom “Root Directories” Feld parallel traversieren. |
Documents Dispatcher Threads Count | Hier kann die Anzahl von Threads festgelegt werden, die die Verzeichnisse und deren Dokumente, die sich in der „Documents Dispatcher Queue“ befinden, parallel an den Index senden. |
Documents Dispatcher Queue Size | Hier kann die maximale Anzahl der Verzeichnisse und deren Dokumente festgelegt werden, die sich in der Warteschlange befinden sollen, bevor diese durch „Document Dispatcher Threads“ von der Warteschlange entfernt und an Index geschickt werden. |
Directory Files Lister Threads Count | Hier kann die Anzahl von Threads festgelegt werden, welche die Dateien, Unterverzeichnisse und die ACLs eines Verzeichnisses vom Filesystem Share mittels SMB abrufen. Die Unterverzeichnisse werden in der „Directory Files Lister Queue“ abgelegt. Die Verzeichnisse und deren Dateien werden in der „Document Dispatcher Queue“ abgelegt. |
Directory Files Lister Queue Size | Hier kann die maximale Anzahl der Verzeichnisse für welche noch keine Dateien, Unterverzeichnisse und ACLs vom Filesystem Share abgerufen worden sind festgelegt werden, die in der Warteschlange stehen sollen. |
Document Size Limit (MB) | Hier kann die maximale Dokumentengröße eingestellt werden. Dokumente, die größer als dieser Wert sind, werden ignoriert. Hinweis: Wenn dieser Wert verändert wird, sollten auch die Optionen „Document Size Limit (MB)“ und „Filter RPC Timeout (non-streamed)“ im Filter Service angepasst werden. |
Maximum Crawled Content Length in MB. | Wenn Dokumente die in dieser Option festgelegte Größe (in MB) überschreiten, werden sie mit leerem Inhalt an den Filter gesendet. |
Includes (Regexp) | Wenn diese Option konfiguriert wird, werden nur jene Dateien und Verzeichnisse indiziert, welche dem angegebenen Muster (Regular Expression) entsprechen. Excludes haben höhere Priorität als Includes (d.h wenn ein Dokument sowohl inkludiert, als auch exkludiert wird, wird es nicht indiziert). |
Excludes (Regexp) | Wenn diese Option konfiguriert wird, werden jene Dateien und Verzeichnisse ignoriert, welche dem angegebenen Muster (Regular Expression) entsprechen. Excludes haben höhere Priorität als Includes (d.h wenn ein Dokument sowohl inkludiert, als auch exkludiert wird, wird es nicht indiziert). |
Include Patterns | Es werden nur jene Dateien und Verzeichnisse indiziert, welche dem angegebenen Muster (Regular Expression) entsprechen. Im Unterschied zum „Includes (Regexp)“ Feld, hat man hier die Möglichkeit mit der Verwendung von „regexpIgnoreCase:“, „case-insensitive“ und „regexp:“ „case-sensitive“ Muster (Reqular Expression) zu definieren oder mit dem „#“ Zeichen am Anfang der Zeile das Muster auskommentieren. |
Exclude Patterns | Es werden jene Dateien und Verzeichnisse ignoriert, welche dem angegebenen Muster (Regular Expression) entsprechen. Im Unterschied zum „Includes (Regexp)“ Feld, hat man hier die Möglichkeit mit der Verwendung von „regexpIgnoreCase:“, „case-insensitive“ und „regexp:“ „case-sensitive“ Muster (Reqular Expression) zu definieren oder mit dem „#“ Zeichen am Anfang der Zeile das Muster auskommentieren. |
Exclude Directories | Wenn aktiviert, werden Verzeichnisse nicht indiziert |
Full Traversal Interval (Hours) | Hier kann das Intervall (in Stunden) zwischen zwei vollständigen Traversierungen aller Dokumente im Fileshare definiert werden. Die Standardeinstellung (-1) ist für die meisten Anwendungsfälle ausreichend und es ist eine vollständige Traversierung aller Dokumente im Abstand „Crawler Interval“. Bei sehr großen Fileshares kann es sinnvoll sein die inkrementelle Traversierung durchzuführen um sie zu beschleunigen. Dabei werden Dokumente die wegen Filter Probleme nicht indiziert wurden sind ignoriert. Modifizierte Dokumente werden bei der inkrementellen Traversierung im Abstand von „Crawler Interval“ indiziert. Die Aktualisierung der Berechtigungen (ACLs) sowie die Entfernung von gelöschten Dokumenten von Index werden am Ende der inkrementellen Traversierung durchgeführt. |
Remove Deleted Documents From Index | Wenn aktiviert, werden die Dokumente die vom Fileshare gelöscht wurden, am Ende einer vollständigen Traversierung aus dem Index gelöscht. |
Remove Old Documents From Index (Number Of Years) | Wenn konfiguriert, werden Dokumente, deren Änderungsdatum älter als ein bestimmtes Datum ist, am Ende eines Traversals aus dem Index entfernt. Dieses Datum errechnet sich aus dem Startdatum des Crawlers minus der Anzahl der Jahre, die in diesem Feld definiert wurden. Beispiel: Das Änderungsdatum eines Dokuments ist der 20.09.2020 und die Einstellung „Remove Old Documents From Index (Number Of Years)” ist mit dem Wert “3” konfiguriert. Dementsprechend wird das Dokument am 21.09.2023 aus dem Index entfernt. |
Content Location Optimization | Die Beschreibung dieser Option, finden sie hier. |
Bereich „Access Rights Settings“
Konfigurieren Sie die folgenden Einstellungen im Bereich „Access Rights Settings“ in der Datenquelle:

Einstellung | Beschreibung |
ACL Security Level | Folgende Optionen stehen zur Verfügung:
|
Permission Mapping (Advanced Settings) | Folgende Optionen stehen zur Verfügung:
Der Crawler verweigert den Zugriff auf die Datei für Benutzer oder Gruppen, die für eine der oben genannten erweiterten Zugriffsberechtigungen den Zugriffstyp "Verweigern" haben. Die anderen erweiterten Zugriffsberechtigungen werden vom Crawler ignoriert. |
Permission Mapping Validation (Advanced Settings) | Wenn diese Option konfiguriert ist, wird eine Protokolldatei im aktuellen Logverzeichnis vom Crawler erstellt, um das ausgewählte „Permission Mapping“ mit einem anderen zu vergleichen.
|
Normalize ACLs (Advanced Settings) | Wenn die Checkbox aktiviert ist, werden die ACLs im „Distinguished Name“ Format gespeichert. Wenn die Checkbox nicht aktiviert ist, bleiben die ACLs im SID Format. In diesem Fall ist es wichtig, dass die „objectsid“ Attribute in den “User Alias Name LDAP Attribute” und “Group Alias Name LDAP Attribute”-Felder der ausgewählen LDAP principal resolution service konfiguriert sind. |
Resolve Local Group Members (Advanced Settings) | Manchmal beinhalten die ACLs von Dokumenten auch lokale Gruppen. Um die Domänenbenutzer oder Domänengruppen in diesen lokalen Gruppen aufzulösen, wird ein Zugriff auf LSA (Local Security Authority) und SAM (Service Account Manager) mittels RPC-SMB Protokoll benötigt. Falls der Crawler Service Benutzer die benötigten Rechte für LSA und SAM nicht hat, kann das Auflösen des Lokalen Gruppen hier deaktiviert werden. Dies wird jedoch grundsätzlich nicht empfohlen und sollte nur in Ausnahmefällen deaktiviert werden. |
LSA/SAM Desired Access (Advanced Settings) | Die bevorzugte Zugriffsberechtigung des Crawler Service Benutzers auf LSA und SAM. Maximum allowed, Generic all, Generic execute, Generic Read oder Read Control. Für das Crawlen von NetApp Shares sollte Read Control als LSA/SAM Desired Access ausgewählt werden. Wenn der Zugriff mit der ausgewählten Berechtigung nicht erfolgreich ist, werden die anderen Zugriffsberechtigungen ausprobiert. |
Resolve All Domains (Advanced Settings) | Um die Dateiberechtigungen (ACLs) verschiedener Domänen richtig zuordnen zu können muss die Option Resolve All Domains ausgewählt werden. Dafür ist es notwendig, dass entweder die LDAP Server dieser Domänen direkt unter „LDAP Server“ konfiguriert werden oder über DNS SRV Records von AD mittels LDAP aufgelöst werden können. Dafür sollen die Domänen im Network Tab unter LDAP Setting konfiguriert werden. Falls „Resolve All Domains“ nicht ausgewählt ist, werden nur die ACLs von der Domäne des File Share Servers richtig aufgelöst. |
Bereich „Trustee Information Settings“

Einstellung | Beschreibung |
Trustee Information File Path | Der Pfad zur Trustee Information Datei, welche in einem Freigegebene Ordner (UNC Pfad) oder in einem lokalen Ordner gespeichert sein kann. |
Trustee Volume Path | Der Volume-Pfad in der Trustee Information Datei zu konfiguriertes Root-Verzeichnis. Dieses Feld soll nicht konfiguriert werden, wenn das Root-Verzeichnis dem Volume-Pfad entspricht. |
Bereich „Extensions“ (Index File Lister)
Dabei handelt es sich um Plugins die von Mindbreeze zur Verfügung gestellt werden können um spezielle Anwendungsfälle abzudecken. Dabei werden die Files nicht durch klassiches „browsen“ durch die Dateibäume indiziert, sondern eine Datei oder eine Datenbank oder ähnliches angebunden, das eine Liste an zu indizierenden Dateien enthält. Es werden also nur die URLs Dateien dieser Listen indiziert anstelle durch alle Bäume zu „browsen“. Dieser Mechanismus ist ähnlich zu Sitemaps im Web Connector.
Um nur die Dokumente, die in einer Indexdatei gelistet bzw. mit zusätzlichen Attributen bereichert sind, zu indizieren bietet der Connector die IndexFileListerPlugin Schnittstelle in index-filelister-spi.jar. Diese SPI Datei wird mit dem Connector gemeinsam geliefert. Für die Implementierung werden noch zusätzlich die Dateien der Java Service API (protobuf-java-3.0.0.jar und messdk-generated.jar)benötigt.
public interface IndexFileListerPlugin {
boolean isIndexFile(ReadonlyFile file);
void init(Properties properties);
Collection<Map.Entry<ReadonlyFile, TypesProtos.Item>> listIndexFile(FilesystemContext context, ReadonlyFile indexFile);
}
Eine Implementierung der IndexFileListerPlugin Schnittstelle kann durch den Pfad Eingabe der JAR Datei im „Index File Lister Plugin“ Feld und optionalen Properties in den „Index File Lister Plugin Property“ Feldern, wie im folgenden Bild konfiguriert werden.
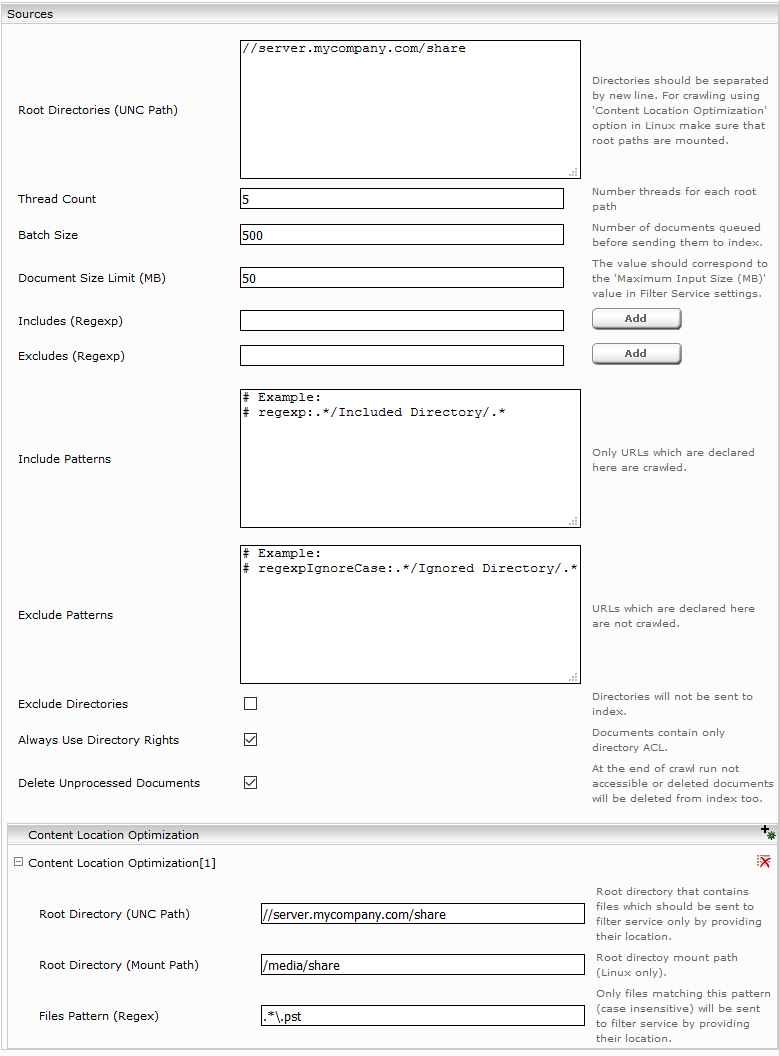
Die Index Dateien werden während des Traversierens der Verzeichnisse in einem Queue abgelegt „Queue Size“, die dann von mehreren Threads „Thread Count“ abgearbeitet werden. Die Option „Skip unchanged Index File Listing during Incremental Traversal“ soll nur dann ausgewählt werden, wenn die Option „Full Traversal Interval“ ebenfalls konfiguriert ist (einen Wert größer als 0 hat). Dadurch werden während des inkrementelles Traversals „Crawler Interval“ nur die geänderte Index Dateien behandelt.
Der Microsoft File Connector verwendet eine vorkonfigurierte Content Type Mapping Description XML Datei für die Extraction von File System Metadaten, die in der Connector Archivdatei vorhanden ist. Falls eine spezifische Änderung erwünscht ist kann diese Datei bearbeitet werden und in einem anderen Verzeichnis gespeichert werden. Um diese bearbeitete Konfiguration zu verwenden ist es notwendig im „Content Type Mapping Description File“ den Pfad zu diesen Datei zu konfigurieren.
Bereich „Content Location Optimization“
Beim Indizieren von großen Dateien ist es sinnvoll die Content Location Optimization im Bereich „Sources“ zu verwenden. Zum Beispiel bei Outlook PST-Dateien.
Konfigurieren Sie den Einhängepunkt (mount point) nach dem Muster im obigen Screenshot.
Folgende Einstellungen sind dazu notwendig:

Einstellung | Beschreibung |
Root Directory (UNC Path) | Verwenden Sie hier denselben Pfad wie bei der Crawling Root. |
Root Directory (Mount Path) | Der Lokale Pfad an dem das Netzwerkdateisystem eingehängt ist. |
Files Pattern (Regex) | Ein regulärer Ausdruck der jenen Dateien entspricht für die Content Location Optimization verwendet werden soll. |
Um Content Location Optimization zu verwenden, muss das Netzwerkdateisystem, das indiziert werden soll, lokal auf der Appliance eingehängt werden. Das kann über das Managementcenter konfiguriert werden:
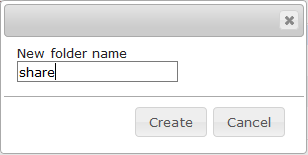
- Erstellen Sie einen lokalen Ordner mittels Filemin:

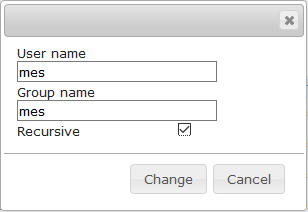
- Machen sie den Mindbreeze Benutzer (mes) zum Besitzer des Ordners:

- Fügen Sie einen CIFS mount mittels des “Disk and Network Filesystems” Moduls hinzu:
![]()
- Konfigurieren sie den Einhängepunkt (mount point):
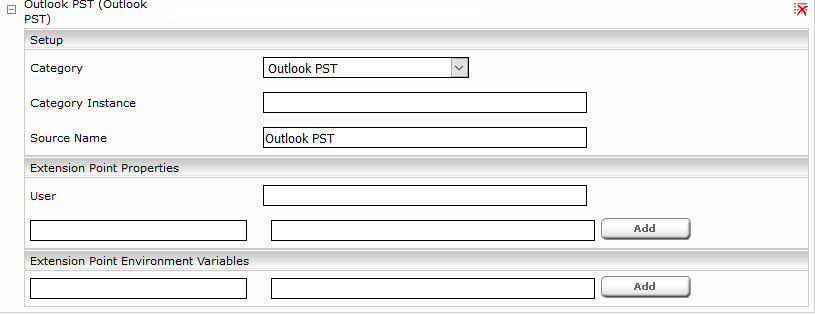
- Nach einem Klick auf „create“ wird das Netzwerkdateisystem eingehängt und ist Betriebsbereit.
Indizieren von Outlook PST Dateien
Zusätzlich zur Konfiguration des Crawlers (siehe oben) ist es notwendig eine Outlook PST Datenquelle hinzuzufügen und „Default“ Category Instance löschen, um Outlook PST Dateien zu indizieren:

Zum Schluss ist es noch wichtig zu überprüfen ob ein Filter Plugin für die .pst Endung ausgewählt worden ist.


Credentials
Der Benutzer muss für das freigegebene Verzeichnis, das gecrawlt werden soll Leserechte besitzen. Die Credentials dazu können im folgenden Bereich „Credentials“ konfiguriert werden.
|
|
|
|
|
|
|
|
(Advanced Setting) |
Standardmäßig wird die NTLM-Authentisierung verwendet. Dazu ist es erforderlich, dass „Username“, „Domain“ und „Password“ konfiguriert werden müssen. Falls Kerberos-Authentisierung ausgewählt ist, muss für den Crawler ein Kerberos Keytab und Principal im „Authentication“-Tab ausgewählt werden. Weitere Informationen dazu finden sie hier. Alternativ können auch dafür „Username“, „Domain“ und „Password“ konfiguriert werden, was jedoch für diese Authentifizierungsmethode nicht empfohlen wird. |
Additional Settings

Einstellung |
|
Dry Run (Advanced Settings) |
|
Content Type Mapping Description File |
|
Always Update Files Matching Regex |
|
Ignore Content of Documents without Extension | Ist diese Einstellung aktiviert, wird keine automatische Mimetype-Erkennung bei Dokumenten, die keine Extension haben, durchgeführt. Die Inhalte dieser Dokumente werden nicht indiziert. |
Disable Default Extension | Ist diese Einstellung aktiviert, bleiben Dokumente, die keine Extension haben und wo die automatische Mimetype-Erkennung fehlgeschlagen ist, ohne Extension. Ist diese Einstellung deaktiviert, wird eine Default Extension verwendet. |
Fetch Preview Content from Datasource | Um eine PDF Vorschau für PDF Dokumente zu ermöglichen werden PDF Dokumente als binäre Dateien im Index gespeichert. Ist diese Einstellung aktiviert, werden die binären Dateien stattdessen von der Datenquelle direkt geladen. Dadurch kann das Speichern der PDF Inhalte im Index in der Filter Konfiguration deaktiviert werden, womit der Speicherplatzbedarf des Index reduziert wird. |
Enable Heap Dump On OutOfMemory | Wenn der Crawler mehr Speicher benötigt als im Plugins.xml <vm_arg> konfiguriert wurde, wird ein Heap Dump im Logverzeichnis für weitere Analysen erstellt. Wieviel Speicher der Crawler zur Verfügung hat, steht im Connector Plugins.xml unter <vm_arg>. |
Max. Retry Duration by Filter Connection Problems | Die maximal erlaubte Zeit in welcher der Crawler versucht ein Dokument wiederholt an den Filter Service zu senden, während Verbindungsprobleme bestehen. |
Retry Interval during Repository Connection Problems | Die Menge an Zeit, die der Crawler wartet, bevor er versucht sich wieder mit der Datenquelle zu verbinden, während Verbindungsprobleme bestehen. |
Max. Retry Duration during Repository Connection Problems | Die maximal erlaubte Zeit in welcher der Crawler versucht sich wieder mit der Datenquelle zu verbinden, während Verbindungsprobleme bestehen. |
Disable logging for excluded documents (Advanced Settings) | Ist diese Einstellung aktiviert, werden ausgeschlossene Dokumente nicht in den Crawler-Logs und im app.telemtry Service Log-Pool aufgenommen. Dies ist nur dann notwendig, wenn viele Dokumente durch die Einstellung "Exclude Patterns" ausgeschlossen werden. |
Öffnen von Suchresultaten
Suchresultaten aus einer Microsoft File Quelle (Microsoft Word, Microsoft Excel und Microsoft Powerpoint) werden ab Windows 10 direkt im jeweiligen Programm geöffnet, wenn der aktuelle Benutzer am jeweiligen Dateiserver angemeldet ist und Microsoft Office 2019 installiert ist.