
Sure, you can handle it. But should you?
Let our experts manage the tech maintenance while you focus on your business.
Let our experts manage the tech maintenance while you focus on your business.
Anleitung zur Datenintegration mithilfe eines SQL Datenbank-Beispiels
Einführung
Dieses Handbuch soll helfen, um eine SQL Datenbanktabelle in Mindbreeze Enterprise Search zu integrieren. Mithilfe einer Demo-Datenbanktabelle, die auf einem Microsoft SQL Server gehostet ist, soll der Prozess des Aufsetzens eines Talend Job in diesem Dokument gezeigt werden. Am Ende des Handbuchs werden noch Tipps zur Fehlerbehebung gezeigt.
Vorbereitung
Um das Beispiel zum Laufen zu bringen, müssen folgende Vorbedingungen erfüllt sein:
- Mindbreeze-Installation ist vorhanden (dieses Beispiel wird auf einer Mindbreeze-Installation gezeigt, die auf Microsoft Windows läuft).
- Die Mindbreeze-Lizenz beinhaltet den Data Integration Connector.
- Talend Open Studio >= 5.0.2 (selbe Version wie auf der Mindbreeze Inspire Appliance) mit der Konfiguration der Mindbreeze User Components wird benötigt. Für Details siehe Handbuch „Konfiguration – Data Integration Connector“.
- Ein erreichbarer Microsoft SQL Server, der die zu crawlende Datenbanktabelle beinhaltet, ist verfügbar.
- Der SQL Service-Benutzer kann sich zum Microsoft SQL Server verbinden und hat Leserechte in der gewünschten Datenbank.
Voraussetzungen auf dem Microsoft SQL Server
Um sich vom Talend Open Studio aus mit dem Microsoft SQL Server verbinden zu können, müssen folgende Verbindungs-Eigenschaften (Connection-Properties) eingeschaltet werden:
- SQL Server Browser (dieses Service muss laufen und wird gebraucht, um Datenbank-Schemas zu erhalten)
- SQL Server Protocols: TCP/IP (dieses Protokoll wird benötigt, um sich vom Talend Connector aus verbinden zu können).
- SQL Server Authentication: der “SQL Server Authentication mode” wird benötigt, um sich vom Talend Connect aus verbinden zu können).
- Der Service-Benutzer, der zum Verbinden zur SQL Datenbank um Daten zu crawlen benutzt wird, muss Login-Rechte und vollen Lesezugriff in der Zieldatenbank besitzen (zumindest „Select“- und „View Definition“-Rechte in der Zieltabelle).
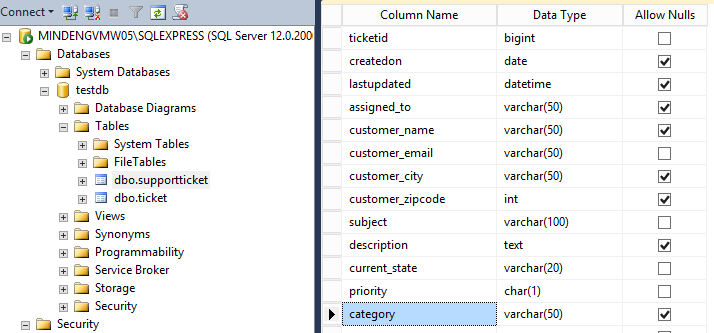
Beschreibung des Beispiels
Die in diesem Handbuch verwendete Beispiels-Datenbanktabelle “supportticket” ist dafür bestimmt, Basisdaten für Support-Tickets zu speichern und ist am SQL Server folgendermaßen definiert:
Konfiguration des Talend Job zur Datenintegration
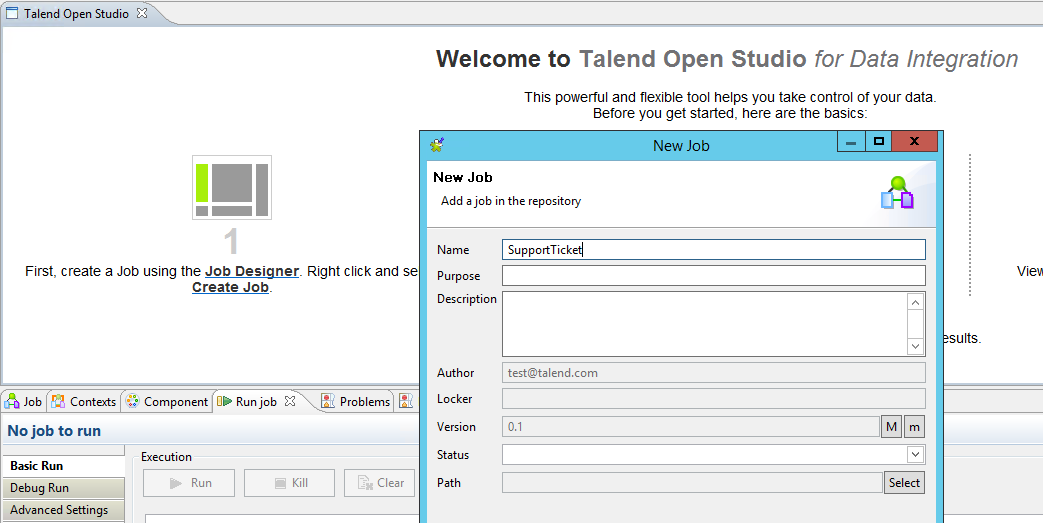
Nachdem alle Vorbedingungen erfüllt sind, können Sie damit anfangen, einen neuen Talend Job zum Crawlen der SQL Datenbanktabelle und das Abbilden der benötigten Tabellenspalten auf die extrahierten Metadatenattribute für die Mindbreeze Suche zu erstellen.
Starten Sie das Talend Open Studio for Data Integration (z.B. C:\TOS_DI-r78327-V5.0.2\TOS_DI-win-x86_64.exe). Öffnen Sie entweder ein existierendes Mindbreeze Demo Projekt (von der Mindbreeze InSpire Appliance) oder erstellen Sie ein neues Projekt.
Der nächste Schritt ist, einen neuen Job zu erstellen (definieren Sie die Input Source, das Column Mapping und die resultierenden Output Properties) und spezifizieren sie den Job Namen.
Einrichten der Datenbankverbindung
Erstellen Sie eine neue Datenbankverbindung zu Ihrem Microsoft SQL Server, indem Sie im Repository Fenster zu „Metadata“ > „db Connections“ navigieren und vom Kontextmenü den Eintrag „Create connection” auswählen. Weisen Sie anschließend einen Verbindungsnamen zu (ohne Leer- und Sonderzeichen).

Wählen sie den DB Type „Microsoft SQL Server” und füllen Sie die Verbindungseigenschaften aus:
- Login:<myTestuser>
- Password:<myPassword>
- Server:localhost
- Port:1433
- Database:<testdb>
- Schema:(blank)
- Additional parameters:instance=SQLEXPRESS

Nun können Sie die Verbindung mithilfe der Schaltfläche „Check” testen.
Importieren des Tabellen-Schemas der Datenbank
Der nächste Schritt ist, das Tabellen-Schema der Datenbank für die gewünschte Tabelle (supportticket) zu importieren.
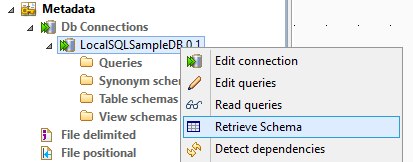
Wählen Sie „Retrieve Schema“ vom Kontextmenü Ihrer Datenbankverbindung aus. Sie können alle Filtereinschränkungen (Filter Descriptions) auslassen und mit „Next“ zum Abschnitt des Tabellen Schemas der Datenbanktabelle fortfahren.

Nachdem sie ein Schema für eine Tabelle ausgewählt und die Schaltfläche „Finish“ bestätigt haben, wird dieses importiert und ist als Daten-Input-Quelle für den Job in „Table schemas“ Ihrer „DB Connections“ sichtbar.
Sie sollten die Datentypen der Spalten in der Schemadefinition kontrollieren und möglicherweise anpassen (speziell für die Datentypen date und datetime), indem Sie das Schema editieren („Edit Schema“ vom Kontextmenü).
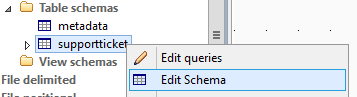
Überprüfen Sie, ob das Datum-Parser-Format für die Werte aus der Datenbank korrekt sind und ändern Sie gegebenenfalls das „Date Pattern“.
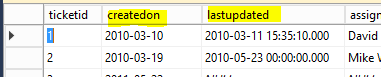
In unserem Beispiel müssen wir das „Date Pattern“ vom Standardwert „dd-MM-yyyy” auf das Pattern der Datenrepräsentation in unserer Datenbanktabelle (wie im obigen Screenshot zu sehen ist) ändern: „yyyy-MM-dd”. Der Zeit-Teil für datetime-Werte wird direkt übergeben und ohne spezieller Definition erkannt.
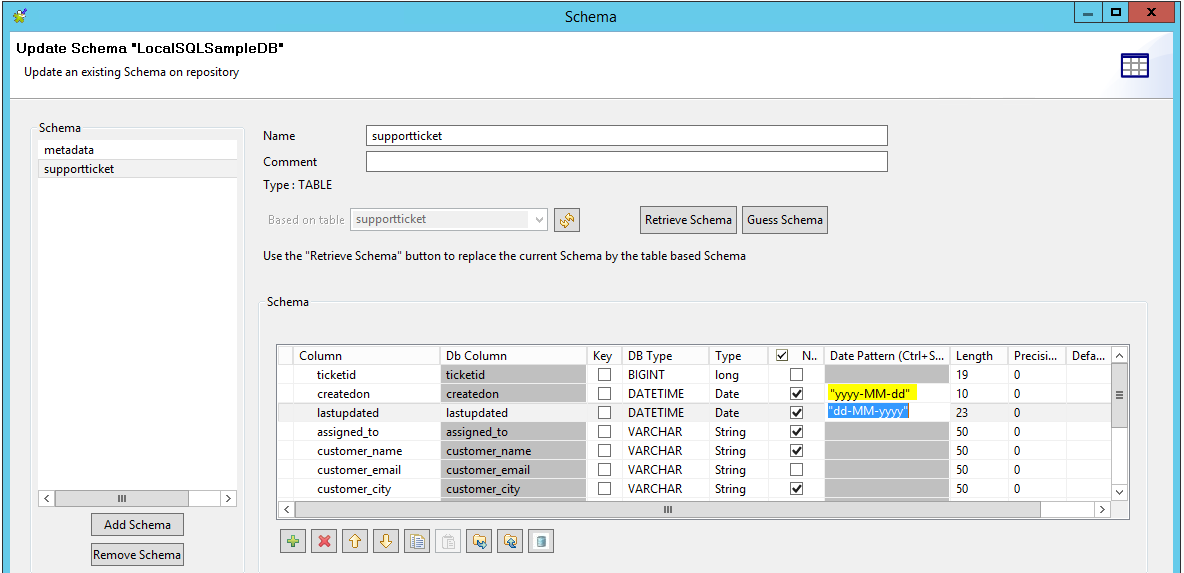
Dieser Screenshot zeigt das korrekt adaptierte Pattern der Spalte createdon. Die nächste Spalte wurde bis jetzt noch nicht geändert, aber muss auch auf den gleichen Wert gesetzt werde: „yyyy-MM-dd“.
Speichern Sie letztendlich die geänderten Schemaeinstellungen.
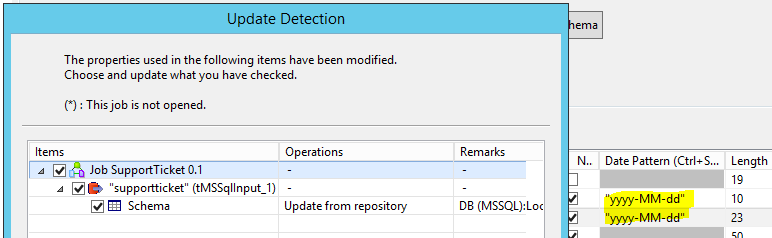
Konfiguration des Talend Job
Ein einfacher Talend Job besteht normalerweise aus 3 Objekten:
- Die Input-Datenquelle, woher also die Daten kommen (in diesem Beispiel ist dies der SQL Datenbank-Input).
- Die Ouput-Datenquelle, wohin also die Daten gesendet werden sollen (für Mindbreeze Data Integration Jobs ist dies immer „MindbreezeIndexOutput“).
- Prozessierungsinstruktionen, wie die Input-Daten auf die Output-Daten abgebildet werden sollen (die „tMap“ ist ein häufig verwendetes Element um solch ein Mapping zu definieren).
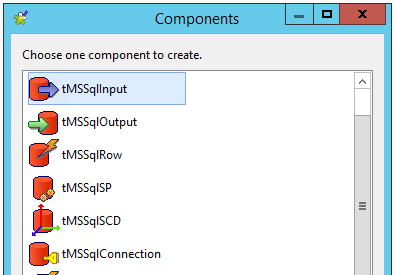
Einrichten des SQL-Inputs
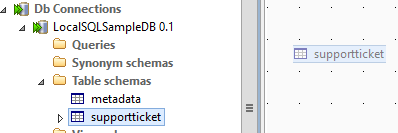
Ziehen Sie das Tabellenschema der Datenbanktabelle „supportticket” mittels Drag and Drop vom linken Baum zum Job Workspace und wählen Sie „tMSSqlInput“ als Type der Komponente, die erstellt werden soll.
Einrichten des Mindbreeze Index-Outputs
Der nächste Schritt ist das Hinzufügen der Output-Datenquelle, indem nach dem Begriff „Mindbreeze” in der Palette der Talend-Komponenten gesucht wird. Ziehen Sie anschließend das Element „MindbreezeIndexOutput” auf die rechte Seite Ihres Workspace.
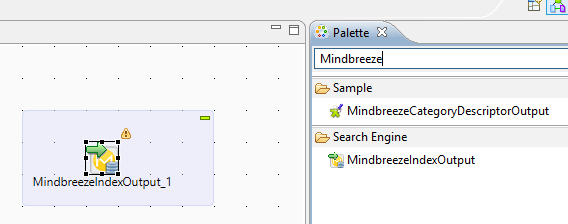
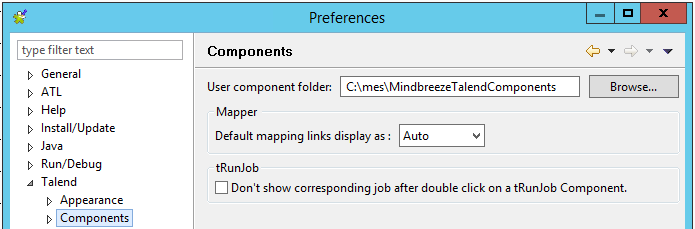
Anmerkung: Wenn Sie keine Mindbreeze-Komponenten in der Palette finden, wurden die User-Components nicht richtig in den globalen Talend Preferences installiert.
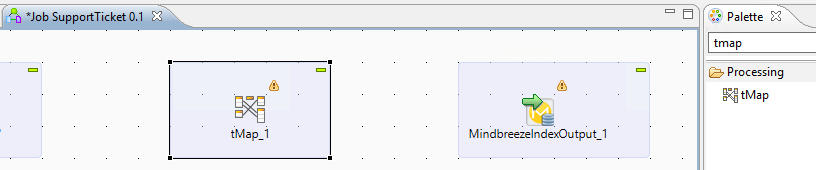
Einrichten des Column Mappings (tMap)
Der letzte aber wichtigste Schritt ist, das Mapping der Input-Daten auf die Output-Daten, die vom Mindbreeze Crawler benötigt werden, zu konfigurieren. Dazu suchen wir nach dem Begriff „tmap” in der Palette und ziehen die Komponente „tMap” in die Mitte unseres Workspace.
Um die Konfiguration des Jobs abzuschließen, müssen wir die 3 Komponenten miteinander verbinden, indem wir eine Verbindungslinie mit der rechten Maustaste vom Input zur tMap und von der tMap zum Output ziehen.
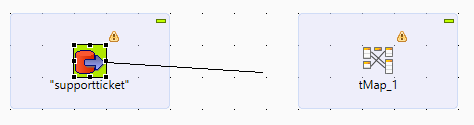
Letztendlich sollte es folgendermaßen aussehen:
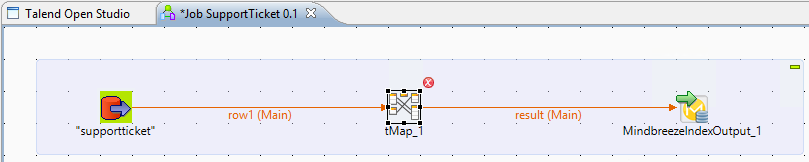
Nun müssen wir „nur“ noch das Spalten Mapping konfigurieren, in dem wir die tMap-Properties mit einem Doppelklick öffnen.
Für alle Data Integration Jobs brauchen wir zumindest 4 Properties, die vom Mindbreeze Crawler benötigt werden:
- key: … sollte auf eine Spalte mit einer eindeutigen ID dieser Datenquelle abgebildet werden. Der Typ muss ein “String” sein.
- title: … die Spalte oder der Inhalt dieser Property wird als Titel in den Suchresultaten verwendet.
- extension: … normalerweise sollte der Wert auf „txt“ gesetzt werden, um damit Mindbreeze mitzuteilen, den textuellen Inhalt als Text zu filtern.
- categoryClass: … kann verwendet werden, um das Ergebnis dieser Datenquelle von anderen Ergebnissen zu trennen.
Anmerkung: Diese internen Properties müssen einen gültigen Wert haben und dürfen nicht „null” sein; überprüfen Sie deswegen mit IF-like Ausdrücken, ob „null”-Werte vorkommen und weisen Sie alternative Werte in diesen Fällen zu.
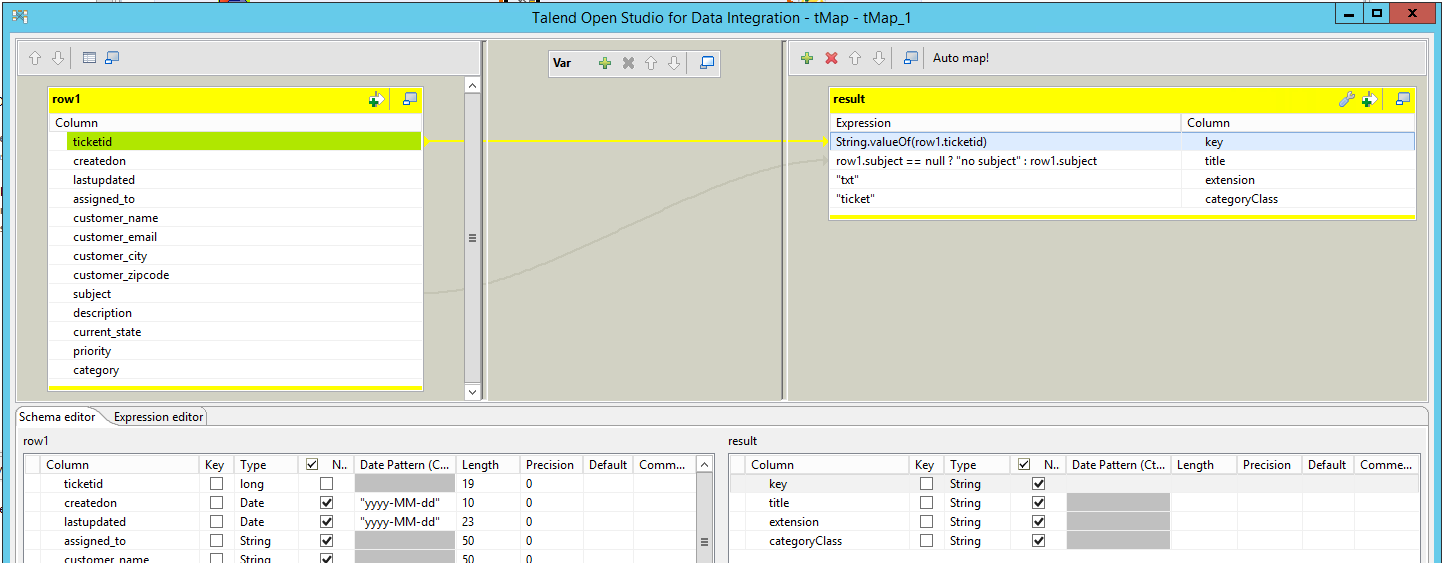
Sie können das Ergebnis des momentanen Mapping immer testen, indem Sie die Änderungen sichern und einen Testlauf (Test Run) des Jobs starten. Da wir nur diese vier Spalten abgebildet haben, bekommen wir nur diese Daten im Ergebnis des Testlaufs.

Erweitern wir nun das Mapping, um alle wichtigen Spalten im Output zu bekommen.
Es gibt zusätzliche Mindbreeze-interne Spalten, die verwendet werden könne, um zusätzliche Properties abzubilden:
- acl: (Liste von String-Werten) im Format: "TestUser1||GRANT"
- date: (Typ "Date") … wird als interne Datumseigenschaft der Suchresultate verwendet und normalerweise in den Ergebnissen angezeigt.
- modificationDate: (Typ "Date") … wird beim Aktualisieren der indizierten Dokumente verwendet (wird normalerweise in den Suchergebnissen nicht angezeigt).
- content: (Typ "String") … wird verwendet, um den indizierten Text des Suchresultats zu speichern.
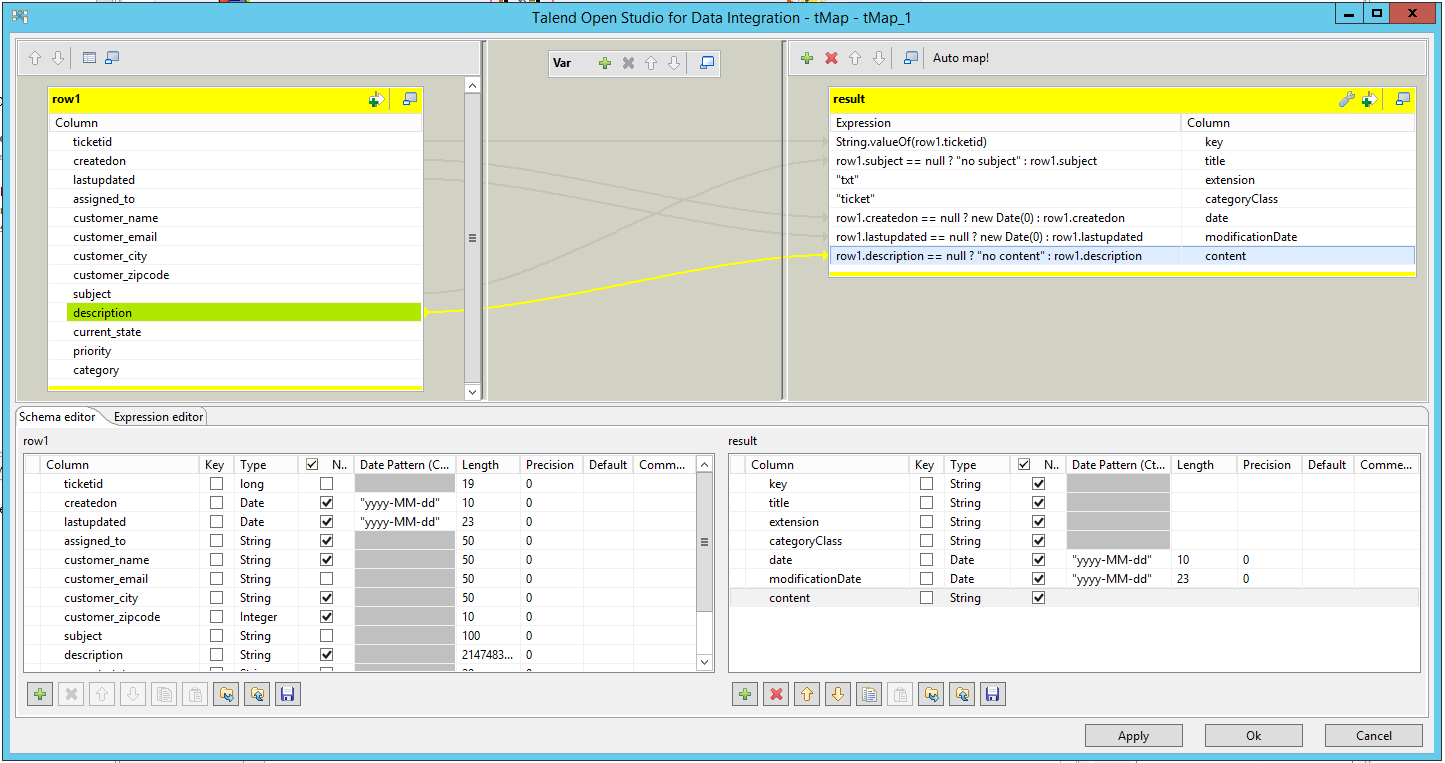
Nun haben wir das Mapping mit optionalen internen Spalten erweitert und wir werden einen erweiterten Output vom Testlauf bekommen, der auch die Datumseigenschaften beinhaltet (Sie können diese auf Korrektheit mithilfe der originalen Datenbankdaten vergleichen). Zusätzlich bekommen wir den Inhalt (content) als Binärdaten angezeigt – dieser sollte Werte beinhalten, wenn die originale Datenquelle für den entsprechenden Eintrag Text enthält.

Nun können wir alle übrig gebliebenen Properties der Datenbank (möglicherweise brauchen wir nicht jede Spalte) auf einen Property-Namen unserer Wahl abbilden (es kann der gleiche Wert oder sogar ein Besserer vergeben werden).
Nach Bedarf können Sie Property-Werte modifizieren, indem Sie einen Java-Ausdruck verwenden, wie das folgende Beispiel zeigt:
row1.subject == null ? "no subject" : row1.priority + ": " + row1.subject
Anmerkung: Sie sollten Null-Werte immer vermeiden, um das Fehler-Logging zu reduzieren.
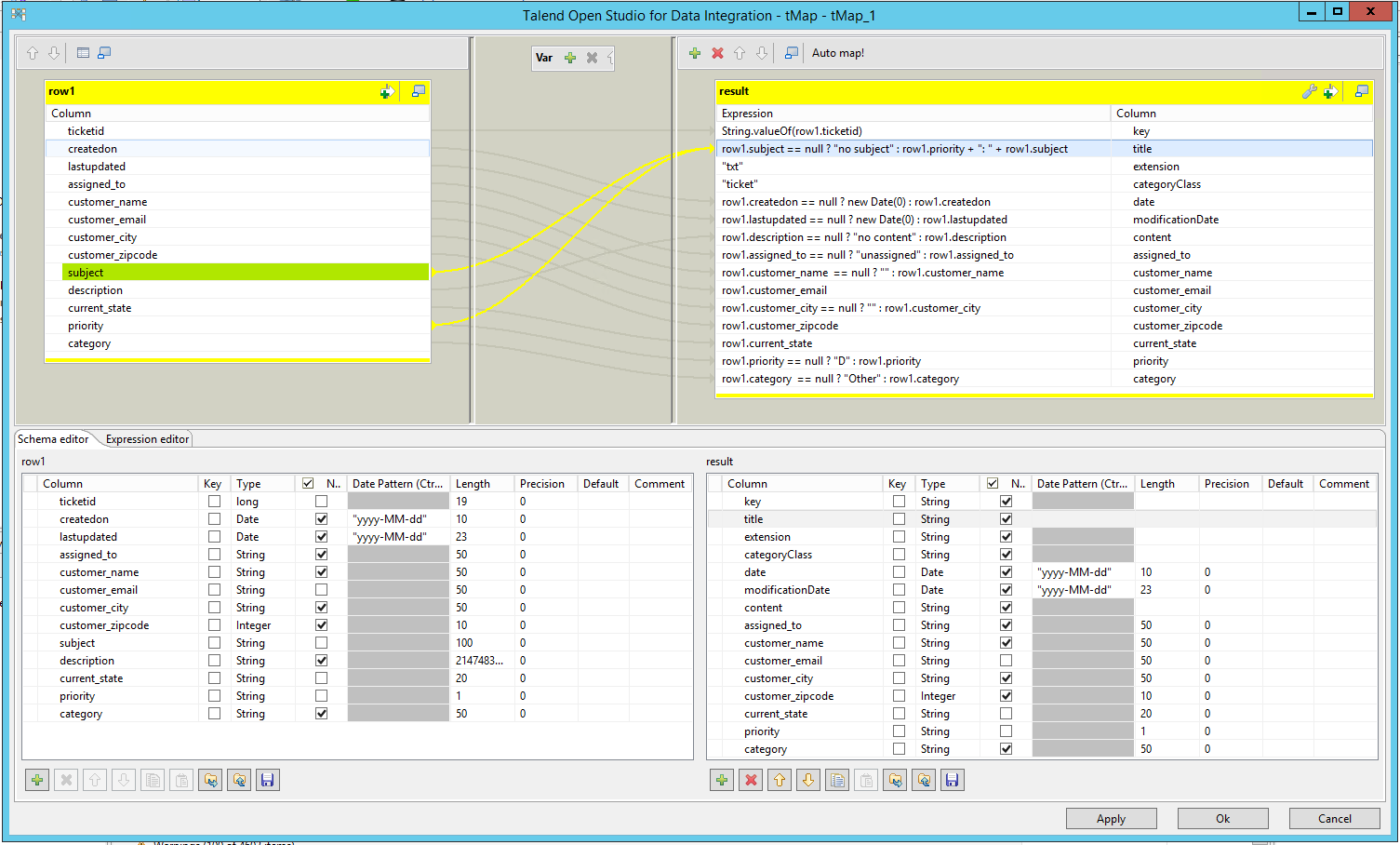
Wenn wir nun den Job laufen lassen, bekommen wir hoffentlich alle gewünschten Properties, die auch später in der Mindbreeze Suche verfügbar sein werden.
Exportieren des Talend Jobs
Letztendlich können wir unseren Talend Job speichern und exportieren.
Stellen Sie ein, dass der exportierte Job extrahiert werden soll und merken Sie sich das Zielverzeichnis des Exports.
Ermitteln Sie den exportierten Pfad zum Job im Dateisystem und suchen Sie den generierten Klassenname im Run Script:
C:\mes\TalendJobs\SupportTicket_0.1\SupportTicket\SupportTicket_run.bat

Zur Konfiguration des Talend Jobs in Mindbreeze brauchen Sie den Basispfad zum Job (der den „lib“-Ordner enthält: “C:\mes\TalendJobs\SupportTicket_0.1”) und den Klassennamen, der im Run Script gefunden wurde: “mindbreeze.supportticket_0_1.SupportTicket”.
Konfiguration von Mindbreeze
Erstellen Sie einen neuen Index mit einem sinnvollen Anzeigenamen (Display Name) und einen angemessenen Indexpfad (Index Path) im Dateisystem.
Erstellen Sie anschließend eine neue Datenquelle (Data Source) und wählen Sie als Kategorie „DataIntegation” aus (Anmerkung: wenn diese Option nicht verfügbar ist, haben Sie vergessen, das Data Integration Plugin zu installieren). Wählen Sie noch einen Namen für die Datenquelle (Source Name), der in der Insight App angezeigt werden soll.
Zu guter Letzt müssen Sie noch die Talend Job Properties definieren:
- Directory of Job: … der Basispfad zum exportierten Talend job (der den „lib“ Ordner beinhaltet)
- Main Class: … der Name der Java Main Class aus dem Run Script

Speichern Sie die Änderungen und starten Sie den Mindbreeze Node Service neu.
Wenn alles richtig aufgesetzt wurde, sollten Sie eine Log-Nachricht im Mindbreeze Log vom Data Integration Crawler bekommen, wie das folgende Beispiel zeigt (z.B. C:\mes\logs\current\log-mescrawler_launchedservice-DataIntegration_Support+Tickets\2015-02-27_12-44-48.581290\log-mescrawler_launchedservice.log):
2015-02-27 12:44:57.394226 [5268] com.mindbreeze.enterprisesearch.connectors.commons.crawlerbase.CrawlRun INFO: Finished crawling run 1 successfully - statistics: itemsFound: 8
Überprüfen Sie schließlich, ob Sie Suchresultate in der Insight App bekommen.
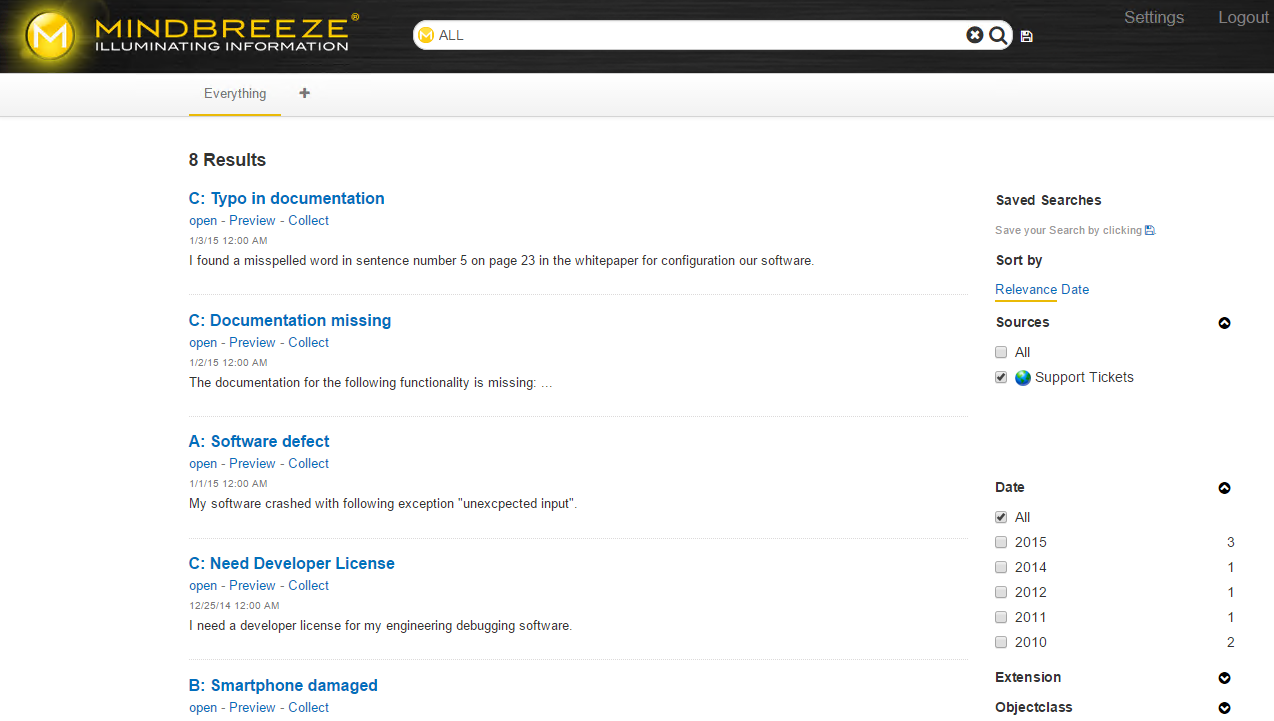
Die voreingestellte Präsentation der benutzerdefinierten Data Integration Quelle zeigt schon Titel, Datum und den Inhalt, jedoch wollen wir auch andere Eigenschaften angezeigt bekommen, weswegen wir die categoryDescriptor.xml vom Data Integration Plugin anpassen müssen.
Anmerkung: Wenn Sie den Talend Job später ändern müssen und dabei größere Änderungen gemacht haben, sollten Sie den Index vom Dateisystem löschen und neu anlegen.
Anpassen der categoryDescriptor.xml
Als guter Anhaltspunkt beim Erstellen einer eigenen categoryDescriptor.xml bietet sich die originale Datei aus dem Data Integration Plugin ZIP-file, die dann nach Ihren Bedürfnissen angepasst werden kann.
Die standardmäßige categoryDescriptor.xml vom Data Integration Connector schaut in etwa folgendermaßen aus:
<?xml version="1.0" encoding="UTF-8"?>
<category id="DataIntegration" supportsPublic="true">
<name>Data Integration</name>
</category>
Beim Vornehmen der Anpassungen können Sie sich jedoch an der categoryDescriptor.xml anderer Basis Plugins, die mit dem Produkt mitgeliefert werden, orientieren. Z. B. beinhaltet das WebConnector-Plugin schon eine Liste von übersetzten Metadaten-Properties und eine spezifische Open Action.
Hinzufügen von eigenen Metadaten Spalten
Eine Metadaten-Definition könnte folgendermaßen aussehen:
<metadata>
<metadatum aggregatable="true" id="current_state" visible="true">
<name xml:lang="en">Ticket State</name>
<name xml:lang="de">Ticket State</name>
</metadatum>
...
</metadata>
Die ID stellt das Mapping dar, um die Spalte zu identifizieren, die in der tMap beim Output Spaltennamen definiert wurde.
Die folgenden Properties können zusätzlich zu den sprachspezifischen Spaltennamen definiert werden:
- aggregateable: wenn diese Option auf true gesetzt ist, wird die Spalte als Filter Property verfügbar sein (soll nur für Properties definiert werden, bei denen die Werte eine Gruppierung der Ergebnisse zulassen – bei einzigartigen Werten, die also im Suchergebnis jeweils nur einmal vorkommen können, macht aggregatable keinen Sinn).
- visible: definiert, ob die Spalte in der standardmäßigen Ergebnispräsentation angezeigt wird.
Ersetzen der Icons
- Das kleine Icon in der Datenquelle-Liste der Insight App wird von der Datei „categoryIcon.png” im ZIP-Archiv vom Plugin bestimmt. Sie können das Icon mit einem 16x16 Icon Ihrer Wahl ersetzen.
- Sie können ein Icon auch direkt im categoryDescriptor.xml mit dem Icon-Tag definieren. Es benötigt eine eindeutige id, Größenattribute (height und width) und das Bild selbst (value), codiert als Base64-Wert.
<context>
<Icon alt="Ticket" height="16" width="16"
id="tag:mindbreeze.com,2007/contextitems/contexticon;ticket"
mimetype="image/png"
type="tag:mindbreeze.com,2007/contextitems/contexticon"
value="
iVBORw0KGgoAAAANSUhEUgAAABAAAAAQCAYAAAAf8/9hAAAABmJLR0QA/wD/AP+gvaeTAAAACXBIWXMAAAsTAAALEwEAmpwYAAAAB3RJTUUH3wIXECgw/xAFagAAAS1JREFUOMvFkz1uwkAUhL/nNV4Zesw9wgUILYq4gymCgCiRIG3gCkAOEnMFTgMNFT8W65cCpOAIAqmY8knzaTQ7C/eWvA8Gpd1uN3HOPQFyo0+NMYm1tkcrjmuzJNH/apYk2orjmu+c88tRxHq91tVqJSJ/hBBhu9kQRZGWo0icc74PoFmGqspkPMZae9G/3W55brdJ01Q0ywA4AIAgCPgYDi+agyAAYL/fIyLo8e4fKlEKhQKf0+nZBM45ur1eDoTqCeCo17e36/WrctpTDtDtdAjD8KzROUej0eCxXs/dc4DhaJSjh2FIsVi8nkA8D0Dn87kU/B9mpVLhoVr99ZICoOJ5AuAbY/bLxQJAms3mzQteLhYYY5wM+v1SmqbT45S5ecqe9xVY+3L3z8g3o1Sele9r3SQAAAAASUVORK5CYII= " />
</context>
Hinzufügen von benutzerdefinierten Actions
Es ist möglich, benutzerdefinierte Aktionen, die auf spezifischen Metadaten basieren, hinzuzufügen. Z. B. um ein Ticket-Suchresultat in einer benutzerdefinierten Ticket Webanwendung zu öffnen.
<context>
<Menu>
<Action name="Open" pattern="http://intranet.myorganization.com/ticketing/show.html?ticketid={{mes:key}}">
<name xml:lang="en">Open Ticket</name>
<name xml:lang="de">Ticket Öffnen</name>
</Action>
</Menu>
</context>
Damit die Änderungen wirksam werden, können Sie das Plugin ZIP-Archiv mit dem modifizierte categoryDescriptor.xml über die Mindbreeze Konfigurationsoberfläche hochladen.
Anmerkung: es wird empfohlen, modifizierte Plugins mit einem eigenen Namen umzubenennen, um Änderungen in Produktupdates besser erkennen zu können.

Eine andere Möglichkeit, um die Änderungen in der categoryDescriptor.xml wirksam zu machen, bietet das Kommandozeilenwerkzeug mesextension (kann zum Testen hilfreich sein):
C:\ >mesextension --interface=categorydescriptor --category=DataIntegration
--file=C:\Temp\categoryDescriptor.xml --overwrite install
Anschließend müssen Sie den Mindbreeze Node Service neustarten. Als Ergebnis erhalten Sie eine schöne Repräsentation der Suchresultate mit allen zusätzlichen Metadaten-Properties (auch bei den Filtern auf der rechten Seite, falls aggregatable definiert wurde).
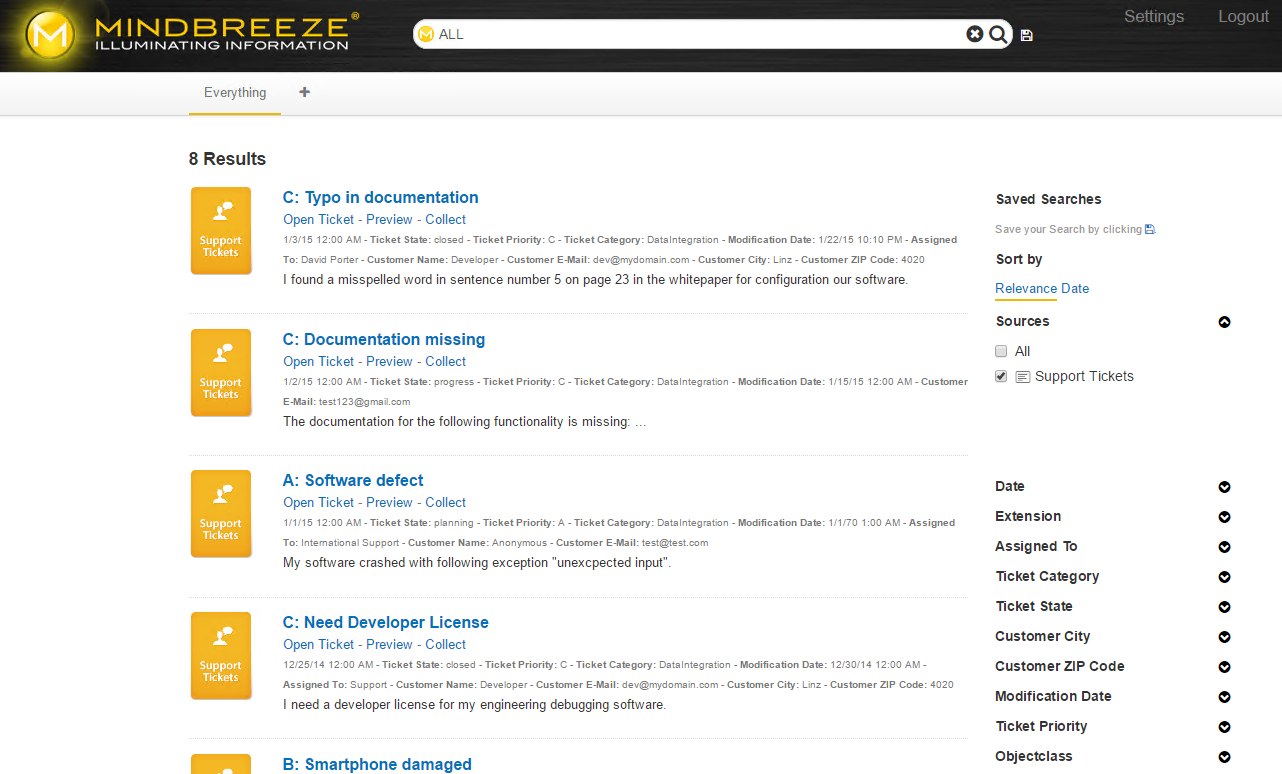
Fehlerbehebung
Talend Job Probleme
Als erstes müssen wir sicherstellen, dass der Talend Job nicht im Talend Open Studio läuft. Als nächstes müssen wir überprüfen, ob jede Property, nach der wir in Mindbreeze suchen wollen, bereits im Resultat des Test-Runs vom Talend Job verfügbar ist. Ansonsten wird Mindbreeze diese Daten zum Prozessieren gar nicht bekommen.
Talend Job Test-Run läuft nicht
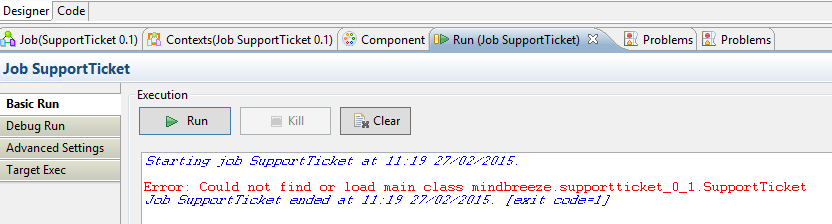
Wenn der Talend Job nicht läuft, überprüfen Sie die „Problems”-Ansicht.
Anmerkung: es gibt zwei verschiedene Problem-Ansichten – eine allgemeine von Eclipse und eine von Talend – Sie können diese Ansichten in „Window > Show view…“ vom Menü aus öffnen).

Ein Grund, wieso Probleme beim Talend Job auftreten können, ist eine unsaubere Umgebung. Sie können versuchen, den Workspace zu aktualisieren (refresh). Falls dies nicht hilft, versuchen Sie, das Talend Studio zu schließen, temporäre Dateien vom Dateisystem zu löschen und das Talend Studio erneut zu starten.
Datentypfehler
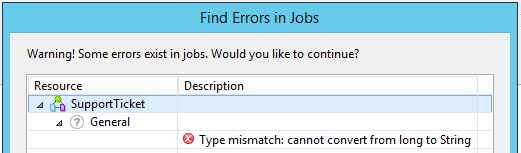
Falls Sie den Fehler „Type mismatch” bekommen, sollten Sie als erstes das Mapping zwischen Input- und Output-Daten überprüfen. Oft ist der Fehler, dass eine ID-Spalte mit einem numerischen Wert vom Input erhalten wird, wobei auf der Output-Seite ein String-Wert erwartet wird. Um dieses Problem zu lösen, konvertieren Sie den Wert mit einem Java-Ausdruck.

Probleme mit Mindbreeze Suchergebnissen
Keine Suchergebnisse
Falls Sie keine Suchergebnisse erhalten (mit einer „ALL“-Suche in der neuen Data Integration Quelle), sollten Sie die folgenden möglichen Gründe überprüfen:
- Überprüfen Sie die Log-Datei vom Data Integration Crawler
Möglicherweise sehen Sie eine ähnliche Fehlernachricht in der Log-Datei, wie im folgenden Beispiel:
2015-02-27 12:37:32.643950 [812] com.mindbreeze.enterprisesearch.connectors.commons.crawlerbase.CrawlRun ERROR: CrawlRun was unsuccessful, cause:
java.lang.ClassNotFoundException: Mindbreeze.supportticket_0_1.SupportTicket
Dieser Fehler wurde durch einen Tippfehler verursacht, bei dem ein Großbuchstabe anstatt eines Kleinbuchstaben verwendet wurde: mindbreeze.supportticket_0_1.SupportTicket
Starten Sie den Mindbreeze Node Service neu und überprüfen Sie die neue Log-Datei.
- Überprüfen Sie die Zugriffseinschränkungen auf diesem Index (“Unrestricted Public Access”)
Keine Inhalte in den Suchergebnissen
Wenn in den Suchergebnissen unter den Properties keine textuellen Inhalte angezeigt werden, wurde möglicherweise nicht richtig gecrawled. Dies kann folgende Gründe haben:
- Die Quelldaten sind nicht auf die interne Spalte „content“ abgebildet
- Die “extension” Property wurde falsch gesetzt (für textuellen Inhalt müssen Sie den Wert „txt” setzen)
Properties werden in den Suchergebnissen nicht angezeigt
Wenn sich eine gewünschte Property nicht in den internen Basis-Properties befindet, wird sie standardmäßig nicht angezeigt. Sie müssen die Property entweder im categoryDescriptor.xml als sichtbare Meterdaten oder in der Insight App explizit definieren.
Sie sollten auch überprüfen, ob die Property vom Talend Job im Testlauf richtig abgeholt wurde.
Anhang
categoryDescriptor.xml
Hier finden Sie den kompletten Inhalt des categoryDescriptor.xml, das in diesem Beispiel verwendet wurde.
<?xml version="1.0" encoding="UTF-8"?>
<category id="DataIntegration" supportsPublic="true">
<name>Data Integration</name>
<metadata>
<metadatum aggregatable="true" id="current_state" visible="true">
<name xml:lang="en">Ticket State</name>
<name xml:lang="de">Ticket Status</name>
</metadatum>
<metadatum aggregatable="true" id="priority" visible="true">
<name xml:lang="en">Ticket Priority</name>
<name xml:lang="de">Ticket Priorität</name>
</metadatum>
<metadatum aggregatable="true" id="category" visible="true">
<name xml:lang="en">Ticket Category</name>
<name xml:lang="de">Ticket Kategorie</name>
</metadatum>
<metadatum aggregatable="true" id="datasource/modificationDate" visible="true">
<name xml:lang="en">Modification Date</name>
<name xml:lang="de">Änderungsdatum</name>
</metadatum>
<metadatum aggregatable="true" id="assigned_to" visible="true">
<name xml:lang="en">Assigned To</name>
<name xml:lang="de">Zugeordnet zu</name>
</metadatum>
<metadatum aggregatable="false" id="customer_name" visible="true">
<name xml:lang="en">Customer Name</name>
<name xml:lang="de">Kundenname</name>
</metadatum>
<metadatum aggregatable="false" id="customer_email" visible="true">
<name xml:lang="en">Customer E-Mail</name>
<name xml:lang="de">Kunden E-Mail</name>
</metadatum>
<metadatum aggregatable="true" id="customer_city" visible="true">
<name xml:lang="en">Customer City</name>
<name xml:lang="de">Wohnort des Kunden</name>
</metadatum>
<metadatum aggregatable="true" id="customer_zipcode" visible="true">
<name xml:lang="en">Customer ZIP Code</name>
<name xml:lang="de">ZIP Code des Kunden</name>
</metadatum>
</metadata>
<context>
<Menu>
<Action name="Open" pattern="http://intranet.myorganization.com/ticketing/show.html?ticketid={{mes:key}}">
<name xml:lang="en">Open Ticket</name>
<name xml:lang="de">Ticket Öffnen</name>
</Action>
</Menu>
<Icon alt="Ticket" height="89" width="64"
id="tag:mindbreeze.com,2007/contextitems/contexticon;ticket"
mimetype="image/png"
type="tag:mindbreeze.com,2007/contextitems/contexticon"
value="
iVBORw0KGgoAAAANSUhEUgAAAEAAAABZCAYAAACOsCKNAAAABmJLR0QA/wD/AP+gvaeTAAAACXBIWXMAAAsTAAALEwEAmpwYAAAAB3RJTUUH3wIXEDUVS3i9MQAAD5JJREFUeNrtnHmMXfV1xz/nd+/b583m8czYDrjBxGZx2IrNYgoYJ5TERVCRNBVNgUBSElAjqmZppBJVUVUSIaIWpdAk2KFJEUsbKASbpXEgbAWCHMM0LAEZb/GCl7Hn7cv9nf5x73vvvmXGpmWZN/hKV3rvrr9zfud8z/ec3+/+BCCTyZBOpykWi2mP6JKSiFPyyCtYwpvSHZvQ2mwVSyVSLee1fGDj8PBwqe3SfD4/XLbR8/P3LZqVcPNfM44zFxEQmfTB03YLd5QqKFjP25Ir6o2bT9nw4KaxR7b+2Wcv8wBkz549xOOxeKVqP2XXHPs3TsQcD4IYQQVEpC64dIkGtKYBBVVFFNQqoHhVfeXSu85d8sgDd+TqfTo+UTwhe9/ik9OJ4u0iooiIGjBiQNS/THzFShd0vtStQEEFqxaxgKqqqkzkzOVHfm7LvwHWBciV3WRPNP8P4PhdbgQxNCwgUIB0k/trwwNEg6MWQSGd8L4D/ATAV0BJ82nHzMUIakBMILgRFAHRrjH/uvyioAYRH8rVaGAdgmBGa9e5AJ6nFgn7fCC8iI+DGBRtwsNpLbyCwaCiqPrWjPXFUmmWww0bj+AL7Pt747dv/uL7RDe4gWmAoICvBAn+tFiy2+Q8hpDEimCCJwBGuicMImDVt+aABNQ7z2hTmDQdUSTocZXgStNd/h9us9bwSzqHMBMWXHyQbEZU7ULhG0jYJHMNBMMHzUFY5IzaOslm+IBvhxXwQVeAO70IjIc4CSQ2ijgJwKKVCWxxhw9f7wITc6eP8Er0w1cTW/T15qQGsIWd5J++AK1m33ElTAsXUFslceq/Elv0dVS1DbFNYpTU8uegUnjHizLTQgEmtQB3aBmoTtrD4sSIzL/mHY/T5v3p8RLqFer/nVlnBFJOLZ2kFna/AlSVxNK7SC57GGfgDNQrUN31aCONm2Lzdj/f3WFQVYn+3pW4s87E9B5PYumPSX38Vajsp/zm7SBSx4Cm3BbwMpsov3Fbl2OALeMMnRNYu2/L4qaQxOmUXvs7Sq/cVD+utoraCrY0TnnT/WTuX4IzNHRQK5nmYdAikXSzX4vgDC7FTqzDGTgOgNxT11DZ8h9+MuM6mFQCd3Z/UN+SblbAZCmJ4ox8kvIbd5FddzVOr4M7q6/dFbqeCEkEm30d07u4KdxVtj4M+jKI4A7FJrn33clT31MMEONSeuVbYL2GU+Tfwk6MIY6DmPc+Kr/3b6xmKY79VT0qTPz0RExfpB39Z6oCFA8TGw4B4HFNUWFmKkAVVQ8ifTi9JxA79vr6qZ6VP8ekF4Hb618z09JhVUXcJKkzH8Qkj+wQE4TUsjU+2dn3AvlfXQpq3zOLMO+28E7/SaRWbMAkj5zSz1UVZ/BUes5/DZHYO0543icXsMQWfxsRc1A/rzNDEZzhz8BMsABUcXqOfvt+OWf5zMAAMS6Zn83Gy5bf9n1O/+DMAEGJ9uMOMm23w2Xxwwo4rIDDCjisgA+8AtTaDvFrBkkpkx91AWwwmxJLY0qMDdmH0j3TZMPiaZ2RN2Sw9ePSToTkbWuxO62hdY6QqpUPoPs3LKCRpobHZLVdXV27aaffgj8nNFBADQeaHH4mCR/IpTTVGlosYBKZdYYYvU7mAlYnV1oLAKpa0Gr9hJhI13R+BwzwXcBaT+ohYsr6hsUZupDUx18mvXILiaX3o15xGkjqgJM6tNJ6IwyadiYoUylTcYc/TXLpP1H+7YNkH/sG3v7daKb8vosfXfQVksufxWbG3zYpCizA1q2khoe07hYiR1wMQGnsOjR/N+XX/gJJ9yDps4id9ENwB9FqkejCbxH9yDdRr0xkwfW4876Ae8QXSZ79CyILrkerOdR6RBZ8E3fe53GPuDY497doNedjlfVw5/81yXMeI3byj8AZ9tvhDBI78fuoVyRxxhrcOVfgjnwCMRESp92JJE8Gq23tD+O8NmSvRwHp5D4a9HztE5TiyzcAkL5oPc7sP0ZtFgRM/ENE5izH5hXFYgZOwfSfjlbKuMNnElv8FST+UQrrbyO28HJii28FPNzhZcQWfxWJHUth/SpiC68gdvz3UFskcdp9xI/7Erlnrgf6SH3sKVRGwLhE5q4gteJ/sPki1fGd2FIOsHjj26m8tbep3VOQ2HAYtG3hwf9URhsmI2DzY+SevhRvYpzk0ptILnsC9TL1V2ib6vz/Yhzyz34O78Aqylt+hjNyLraQq58rPHcl3oEfUt66FmfkPJQB3KGTmHjoKjT7GIXnViLGEJl/Rb15ld89T+6X52EzD+CNPw6epTh2LSaxMWg7jW9nJBzltIkKBy6gjWnSNVuxIe4c7KIGu/85Cs8uJ/fkl3FnHYtJX95wLBviEmHuDZiUQSSO5l/FuHFsvtywxZSDSAItvIZEEmjJAcDbsQaJuKB5tFxAIgMNBbz5c0xPL2IiiDi1AiSCA1Ya7a7zf613cCCrNFPhqRIe8ftTYsPg9IKJAHvqL7WFTb4gsWEwCUxitP0R7gBazePMXonNv4U4ofDp9vnnhi7A5naC9SdQxU+5CbUVTO8ZSDRBZfsLoQea+hR4VQvGAYmh2EmnxreERAHk0IhQsMUX34g756z6/+r4Jiobb8UdGUKrRdKfXOsbQmFv28BGeuVLaCWDifWSeejzmN506NwYWsliYmkm1l6JxEsUXrqZ+IlfJnrU2Ti9R1Dd/TqVjbcQ+dDiNjj39o4hCyIMfHYX+Wf+kuq+NZ0HYToQIQF4cv22k0747em/xhjfJoz/3ZDUIqUJLEBc7EQaZ/RCKlvuQUwGZyDaIEXxS6hsvRfTZ/H2lXAHhdS563AGF7L/zlHcOddSfuN7OP1xJAaps9bhDBzN/jvn4M65pn7OxP0kVUtg+i6hsn0t4hzA6fPfZXPgZYu4wzFEfOMVMw/cJVS33oEznPQVYP3ArzUXsIFrW0vfn24bBHLNFqCd9NOwF7VVTHofNns7zqAg4o/rC/6XGVq4G3fIV54ZjTaN9krMwWZW4Y6k/I+XQpMkTMs5UH9GTAxs4R6cgca7fMwAk4rVu1UUsFvR0pZA+BYaK9opvQlngwEGSIgMWMDRWqDw7wiUEjYvkbC+TBt4VH63hsq29QimPkZYu7Gy7UEqW0d8a2u5t/7ctvdPRm46TKb2ey0Egk1KaGCArZXEtFYSkmbAkA6gWM11BgzjIs4o6r2FSJTyxu+CteBG/e/3tIozazl4ecobb/LPOdGD0vB3IPlpMKIQEQq5gDYzY5mcPmo1Q+pjY5hoT8AhLGJccKIUN/wjiVO/RvbxL6CZdYhEmgm3VyS55BZsaTf5X5530LKsqiLRYUx8FG9iQyPkvR0FSGsZwLbUBK2VtsypVhPsVBORKKVXV6OFMrGFl+CMHE/+qRtAoLrjP5HEPCpvPoQ7FA1qDV7IlAS1ZfDKgYBeMAXOCVmhDdzJgC2SPPNutFQiu+50nOSAT7FqzxTjx/6plGA7UPsWKnwQLTbfLSaKt+M2vPFV2OI2UIu3azV23yqcvkGi81cQO+ZTqFXE6SF5+n30XrSV1HnPoZVsSNFKfPHNpM55AhP/MGLSJH7/J/RetJX44psRDLFj/h6TmoPTP5/0BWNoeQJxekid99/0XrSV2ILrfYXSIYE5hOTQ1C2gPQno/NCwiai2MwwTw/SMYgsGiQ74Md4mGF/9EfJP3oAWG3mpM3g+0aMuIrP2M3jjG0ie+zBeZhfjq+fjzD6DyDG3Ut25Dpvfh5fdReFXt+DtK5Fa8STegV2M/2CE4qv/5TO/qdqqHWsCLRbQETBqN0pAL1t2naT0DOBViR51HWo9sg+djzNYgfL9mGTS96LkKMmzvs/EvZdgnO24cy7E6ZmLt/t14idfjbfnBeILz8cbfxaqE2gxh/fWv+AM9YGCO7yI+KnXITzu409b26SlI9uwoYkK+8esbSCldMqdWvaDVB4kMRfUYlLR4KNs01iMwU2g1QrJc26EqOvTbCByxDk4s/4QzDDlzS+gRa8R/4xBHJfco6dR2fwMiVO+QfzE1aiWpm6b0Mjxg9S/yQJ8EFSsSJ0s1Xv0/1owF5fqtn8H4+IMnYtWM02lNzuxmdyjF+POOgp35E/wdvk0urLpp+SfWEb+qbMpPHsxEq2CVjGp2Wil5Mf72FxKL15C8cVbiR69EpvJTT0GEFABq2BFaq5r2nIBCY8GBV+QY3WKxELBRBHjBgrWxmIFJoK3ey3e3lfoWbEaLRfATXDgjiiYBLgxbPllqjtfIHnmd8g+MkbxlVWkln8XrXwbsJQ3/YLS2BepbFtD/KNfpf+yDPt/nKL/sjfRUg6JpSis/xGYeHtds27qwYfgYVdtzQUeWPfikrO3f+J5xIBD/UtxPzKZKWO1VnJUd2VxhmZh4i6qHt7efUAcdyjtz/nPxHH6z6ay7T6cwV7QCbzxCpF5s1FbprprP5g4kZEUXqaI0/dHVMd/A4VXcYYH/J6x89DKAFr4NZKoIvELqO54CJOM4PTHOyN+LReoRWGr4Pmhtv/Pty8AdrudKZNSXzTkIFmiuCki81L1awQHd9bsxn+J4PRWQR8jMi+Y808/JlE7HyUyOly/3ulJgn0Mtw/oHawXPdXswMR3orG4H4p5isictG+99uBDYB0EaCJCfr5QSxpUmnv9/z04Ki1M7FCvDR+VUIGqcc0hLe0hoaII9QJRCwjSUha3XT5ApC1MkDYMaAFBVd/3tQUi1HbvyLC2pMO1qGa1QzpMiP/XtOZ0w8pBh6AF20LY6JQOa0j4+uojtXJwN1uANoiQhpPBkAs0xXVo0Eg5RNzqmrFB7VwRCidDdRasBx1cnN6btIN4C8MPgaC1qFWsARMKMQr++jvdagXSPMzn459irLYMjkp7+NMaNa5VU7tts35kExtKCG2njMUfGfIrQh6oqwEGWD8X0OBjBq+bIoIGvd+YEeIPfwZUmDYQ9LWlQr24UCurGxsaGZLusIT6CnKB8dbXE7TBiGXrFJlypeLhESyhp4gqeII4YFVALCa8yNJ0nDvV0iYPGyykpL71ajDW0DxBwreAveMTB3IluzMeM6M1zq2Oby4SLKio0l044DfX1tN0PF94tUqhbPfg571VA/Dyb8a2P7yh9IMA8BRPUU8RD197wa6h39N1b22jeDSOWd8MHtlQ/ufA+g+YtWvXktj7TOaq1RO3Z3O6Gaui1r/Ren4urTaskOm91wT22+zLIF4NA1SyOd18xaoD64BtNcTzR34jSLHC8fd8qf+qPzgmcnkqJgO+l0j3McImAueDX7ak40+/Vrn907fsvxeYAF6aTKQhYBhIMvOm05eA7cDu2oH/BTw+CdV54/GjAAAAAElFTkSuQmCC" />
</context>
</category>