
Sure, you can handle it. But should you?
Let our experts manage the tech maintenance while you focus on your business.
Let our experts manage the tech maintenance while you focus on your business.
Konfiguration
CJK Text Tokenizer Plugin
Einleitung
Dieses Dokument beschäftigt sich mit dem CJK Tokenizer Plugin. Dieses ermöglicht Mindbreeze InSpire chinesische und japanische Inhalte zu crawlen und zu verstehen. So können in etwa Sätze in einzelne zusammengehörige Teile (Token) zerteilt werden, um eine optimierte Sucherfahrung zur Verfügung zu stellen. Das Tokenizer Plugin unterstützt mehrere Tokenizer. Es wird auch ein externer Tokenizer Service unterstützt (nicht enthalten).
Voraussetzungen
Falls ein externer Tokenizer Service genutzt werden soll, muss dieser Service bereits konfiguriert sein.
Setup
Um den CJK Tokenizer zu aktivieren müssen folgende Schritte durchgeführt werden:
- Setup des Postfilters
- Setup des QueryTransformationServices
- Reindizierung der Inhalte, die bereits vor der Tokenizer-Installation indiziert wurden
Setup des Launched Service
Das CJK Tokenizer Plugin wird als einzelnes Launched Service konfiguriert. Nur so kann eine hohe Leistung erreicht werden. Dieses Launched Service wird nach der Konfiguration als Postfilter- und QueryTransformationService referenziert.
Zur Einrichtung des CJK Tokenizer Plugin Launched Service wechseln Sie in der Konfiguration in den „Index“ Tab und fügen Sie im Abschnitt „Services“ einen neuen Service hinzu.

Base Configuration
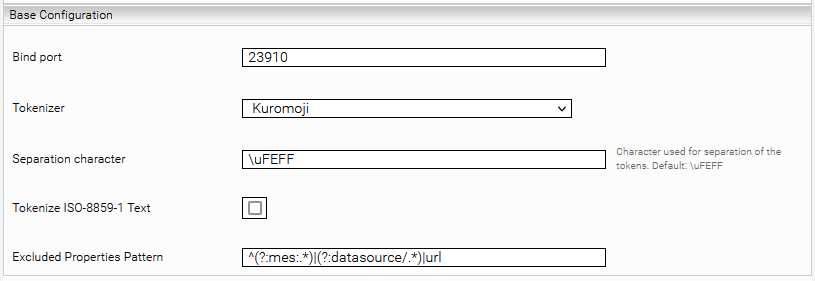
Bind port | Ein freier TCP-Port auf der Appliance, auf dem er Launched Service läuft. | ||||||
Tokenizer | Wählt den Tokenizer Modus. Unterstützt werden die Modi:
| ||||||
Separation character | Zeichen, welches zur Trennung der Token verwendet wird. Der Standardwert ist \uFEFF. Zum Testen kann dieser Wert auch geändert werden. Damit die Suche korrekt funktioniert muss jedoch der Standardwert beibehalten werden. | ||||||
Tokenize ISO-8859-1 Text | Wenn diese Option aktiviert ist, wird auch ISO-8859-1 enkodierter Text durch den Tokenizer bearbeitet | ||||||
Enable Text Normalization | Text wird normalisiert, sodass z.B. Dokumente mit Full-Width-Characters gefunden werden können, obwohl bei der Suche normale westliche Buchstaben verwendet wurden. Die verwendete Normalisierungsform ist NFKC. | ||||||
Excluded Properties Pattern | Die hier mittels regular Expression konfigurierten Properties werden nicht vom Tokenizer bearbeitet. |
Jieba Configuration
Anmerkung: nur relevant, wenn bei Tokenizer der Wert Jieba ausgewählt wird.

Das Wörterbuch, welches für das Tokenizing verwendet wird:
| |||||
Segmentation Mode | Je nachdem, ob das Service als QueryExprTransformation Service oder als Post-Filter verwendet wird, können unterschiedliche Einstellungen verwendet werden. Der Standardwert „Index“ ist jedoch für beide Servicearten ausreichend.
|
HANLP Configuration (Deprecated)
Anmerkung: nur relevant, wenn bei Tokenizer der Wert HANLP ausgewählt wird.

EndPoint URL | URL des /parse servlets des Tokenizer Services |
Kuromoji Configuration
Anmerkung: nur relevant, wenn bei Tokenizer der Wert Kuromoji ausgewählt wird.

Kuromoji Tokenizer Modus, siehe auch Javadoc |

Setup des Postfilters
Der Postfilter dient beim Tokenizer dazu, die Inhalte zur Crawlingzeit zu tokenizen (zerlegen), bevor sie in den Index gespeichert werden.
- Navigieren Sie dazu zum Management Center
- Wählen Sie den Tab Filter aus, aktivieren Sie die „Advanced Settings“ und öffnen Sie den gewünschten Filter, der die chinesischen Inhalte tokenizen soll:
- Suchen Sie danach nach der Option Post Filter Transformation Services und fügen Sie die Referenz auf das CJK Tokenizer PostFilter Plugin (TextPlugin.CJKTokenizer) hinzu (Erkennbar am „@“ im Namen):

Setup des Query Transformation Services
Das Query Transformation Service dient beim Tokenizer dafür, dass auch der vom Endbenutzer in das Suchfeld eingegebene Text vor der Abfrage „tokenized“ wird. Ist dies nicht der Fall, stimmt die Tokenization des Indexes nicht mit der des Suchqueries überein. Dies würde denselben Effekt haben, als hätten Sie keinen Tokeinzer konfiguriert.
- Navigieren Sie dazu zum Management Center
- Wählen Sie den Tab Indices
- Aktivieren Sie die „Advanced Settings“ und öffnen Sie den Index, der die chinesischen Inhalte enthält. Wählen Sie jenen Filter aus, auf dem Sie den Postfilter konfiguriert haben:
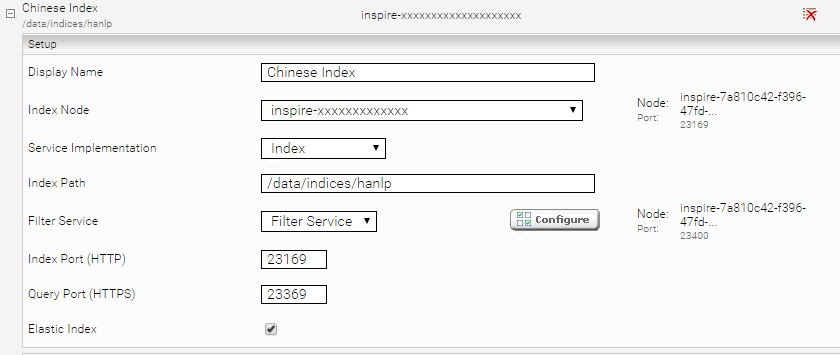
- Suchen Sie nach der Einstellung Query Transformation Services und fügen Sie die Referenz auf das CJK Tokenizer QueryTransformation Plugin (TextPlugin.CJKTokenizer) hinzu (Erkennbar am „@“ im Namen):

Reindizierung der Inhalte
Sind in Ihrem Index bereits Dokumente vorhanden, so müssen diese neu indiziert werden, da die bereits vorhandenen Dokumente noch nicht „tokenized“ wurden.
Fehlerdiagnose
Das CJK Tokenizer Plugins betreibt auf dem BindPort ein Test-Servlet, welches zur Diagnosezwecke verwendet werden kann. Sie können Beispielsweise im Webbrowser beliebigen Textfragmente „tokenizen“ lassen.
Z.B. ergibt der Aufruf:
https://myappliance:8443/index/{{BindPort}}/tokenize?text=清洁技术
das Resultat:
清洁{{Separation character}}技术
Hinweis: Der Standard Separation Character ist nicht sichtbar. Um diese Trennzeichen sichtbar zu machen, können Sie das Resultat in einen Editor kopieren.