
Sure, you can handle it. But should you?
Let our experts manage the tech maintenance while you focus on your business.
Let our experts manage the tech maintenance while you focus on your business.
Documentum Connector
Installation und Konfiguration
Installation
Bevor der Documentum Connector installiert wird, muss sichergestellt werden, dass der Mindbreeze Server bereits installiert ist und dieser Connector auch in der Mindbreeze Lizenz inkludiert ist.
Benötigte Crawling User Rechte
Der Documentum Connector erlaubt das Crawlen und Durchsuchen von Documentum Elementen und Objekten.
Um eine Documentum Datenquelle konfigurieren zu können, müssen folgende Voraussetzungen erfüllt sein
- Ein Superuser Name und Passwort
Konfiguration von Mindbreeze
Klicken sie auf “Indices” und auf das “Add new index” Symbol um einen neuen Index zu erstellen.
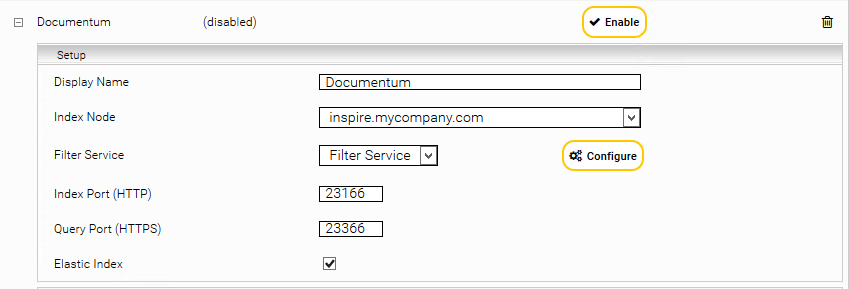
Eingabe eines neuen Index Pfades z.B, „/data/indices/documentum”. Falls notwendig muss der Display Name des Index Services und des zugehörigen Filter Services geändert werden.
Mit “Add new custom source” unten rechts kann eine neue Datenquelle hinzugefügt werden.
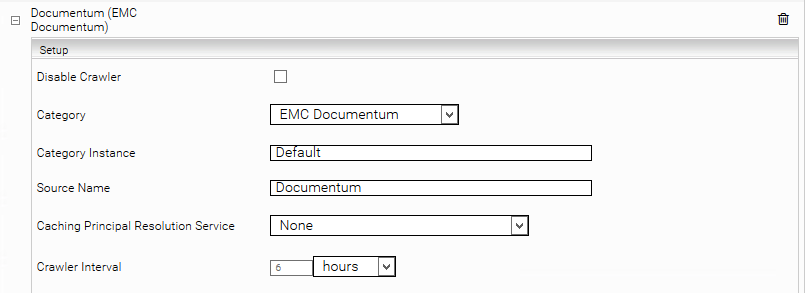
Konfiguration der Datenquelle
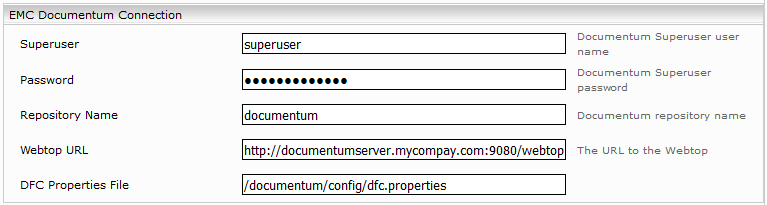
Documentum Connection
Diese Information wird nur für Basic Authentifizierung benötigt:
- Superuser: Username von einem Superuser.
- Password: das Passwort des Superusers.
- Repository Name: Repository Name.
- Webtop URL: URL zum Webtop. Z.B. http://documentum.myorganization.com:9080/webtop/
- DFC Properties File: Pfad zur DFS Properties Datei. Die Datei muss im config Verzeichnis von dfc.data.dir liegen. Das dfc.data.dir muss Schreibrechte mit dem Benutzer mes besitzen. Folgende Properties müssen konfiguriert sein. (Siehe dfc.properties Datei am Documentum Server)
- dfc.data.dir=/documentum
- dfc.docbroker.host[0]=documentum.myorganization.com
- dfc.docbroker.port[0]=1489
Hinweise zum Löschen von Dokumenten
Standardmäßig werden in Documentum gelöschte Dokumente mithilfe des Documentum Audit Trail automatisch aus dem Index entfernt. Falls der Audit Trail nicht verfügbar ist (z.B. wegen fehlenden Zugriffsrechten) gibt es folgende Möglichkeiten um Dokumente automatisch zu löschen:
- Trash Bin: Ein gewisser Ordner kann im Documentum als Papierkorb verwendet werden. Dokumente, welche in den Papierkorb verschoben werden, werden beim nächsten Crawl-Run aus dem Index gelöscht. Siehe Option „Trash Bin Path Pattern“.
- Delete Not Existing Documents: Regelmäßig wird der Index mit der Documentum-Datenbank abgeglichen um gelöschte Dokumente zu erkennen. Siehe Option „Delete Not Existing Documents Schedule“
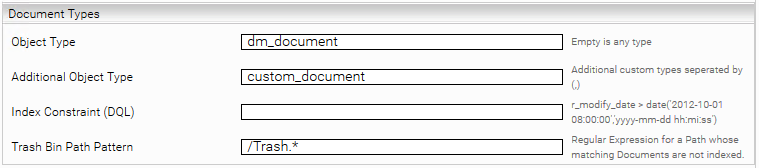
Dokumenttypen
Es ist möglich die zu crawlenden Daten für z.B. bestimmte Objekttype oder Dokumente mit bestimmten Eigenschaften einzuschränken.
- Object Type: Definiert das r_object_type des DQL Query, z.B. dm_document.
- DQL: SELECT * FROM dm_sysobject WHERE (r_object_type='dm_document')
- Wenn das Feld leer ist, wird dm_sysobject als r_object_type verwendet.
- DQL: SELECT * FROM dm_sysobject WHERE (r_object_type='dm_sysobject')
- Additional Object Type: Erweitert das DQL Query auf weitere Objekttypen.
- DQL: SELECT * FROM dm_sysobject WHERE (r_object_type='dm_document' OR r_object_type='custom_document')
- Index Constraint(DQL): Schränkt die Dokumente ein, z.B. Dokumente mit einem bestimmten Änderungsdatum.
- DQL: SELECT * FROM sysobject WHERE (r_object_type='dm_document' OR r_object_type='custom_document') AND (r_modify_date > date('2012-10-01 08:00:00','yyyy-mm-dd hh:mi:ss')).
- Trash Bin Path Pattern: Definiert einen Pfad zu einem Verzeichnis mit einem regulären Ausdruck (Java). Dokumente mit diesem Pfad werden nicht indiziert. Bestehende Dokumente werden aus dem Index gelöscht, wenn sie in diesen Pfad verschoben werden.
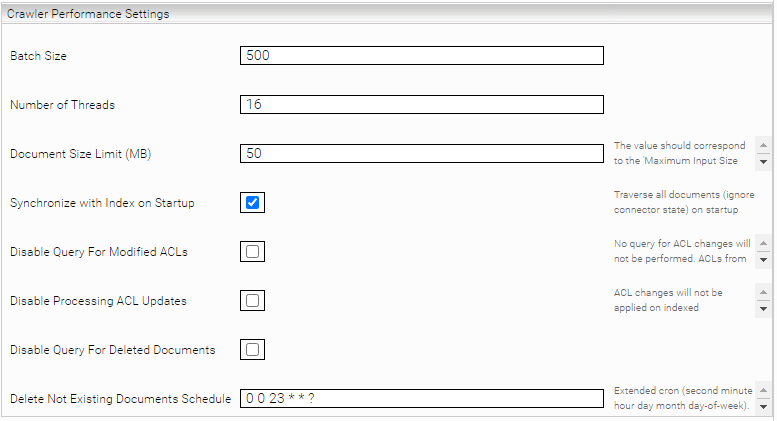
Crawler Performance Settings
- Batch Size: Die Anzahl von Dokumenten nach deren indizierung der Connector State (checkpoint) persistiert wird.
- Z.B. ein DQL Query für Batch Size 500:
- DQL: SELECT * FROM dm_sysobject WHERE (r_object_type='dm_document') ORDER BY r_modify_date, r_object_id ENABLE (return_top 500)
- Number of Threads: Die Anzahl von Threads die Parallel Dokumente indizieren. Dabei werden die Dokumente nach ihren IDs partitioniert, z.B. ein Thread übernimmt Dokumente deren IDs mit ‚1‘ enden. Dieser Thread führt folgende DQL Query durch.
- DQL: SELECT * FROM dm_sysobject WHERE (r_object_type='dm_document') AND (r_object_id LIKE ‘%1’)
- Synchronize with Index on Startup: Der Crawler speichert lokal sein Zustand vom letzten Lauf. Dadurch wird das abgleichen einzelner Dokumente im Index mit denen vom Documentum Server vermieden. Manchmal wegen Transport oder Filter Problemen kann es passieren, dass der Crawlerzustand von Indexzustand abweicht. Um diese Abweichung zu korrigieren, ist die „Synchronize with Index on Startup“ Option auszuwählen.
- Disable Query for Deleted Documents: Wenn ausgewählt werden gelöschte Dokumente nicht vom Index entfernt. Falls z.B. der Benutzer keine Berechtigung auf das Audit Trail hat, sollte diese Einstellung ausgewählt werden, um Fehler beim Crawlen zu vermeiden.
- Delete Not Existing Documents Schedule: Wenn konfiguriert, wird zu bestimmten Zeiten der aktuelle Index mit der Dokumentum-Datenbank abgeglichen und im Dokumentum gelöschte Dokumente auch im Index entfernt. Das Format ist eine extended cron expression. Beispiel: 0 0 22 1/1 * ? * (Täglich um 22:00) (Standardwert: nicht gesetzt). Eine Dokumentation und weitere Beispiele zu Cron Expressions finden Sie hier.
Aktualisierung von ACLs
Um die ACLs von indizierten Dokumente aktuell zu halten, werden die dm_save, dm_destroy und dm_saveasnew Events für den dm_acl Objekttype auditiert (Siehe Audit Management Referenz für Documentum). Der Crawler durchsucht die Einträge in der dm_audittrail_acl Tabelle nach diesen Events bei jedem Crawl-run.
- Disable Query For Modified ACLs: Erlaubt es, die ACL Updates zu deaktivieren. D.h. es werden keine Abfragen durchgeführt um die geänderten ACLs zu finden. Wenn diese Option ausgewählt ist, muss der Crawler neu gestartet werden um ACL Updates durchzuführen.
- Disable Processing ACL Updates: Erlaubt es, die ACL Updates zu deaktivieren. D.h. es werden keine weiteren Abfragen durchgeführt um die betroffenen Dokumente zu finden. Wenn diese Option ausgewählt ist, muss der Crawler neu gestartet werden um ACL Updates durchzuführen. Falls z.B. der Benutzer keine Berechtigungen auf das Audit Trail hat sollte diese Einstellung aktiviert werden, um Fehler beim Crawlen zu vermeiden.
Audit Trail Clean-up
Der Crawler verwendet die Ereignisse im Audit Trail (dm_audittrail) um gelöscht Dokumente zu erkennen. Um das Löschen dieser Ereignisse aus Audit Trail zu ermöglichen um Speicherplatz zu sparen, muss die Option „Enable Audit Trail Clean-up“ ausgewählt werden.

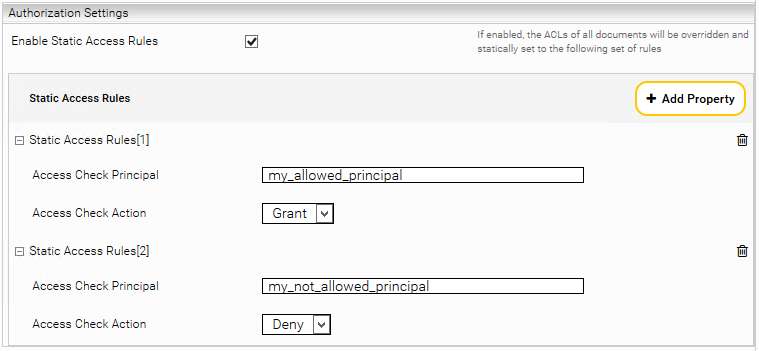
Statische ACLs
Bei Bedarf können die ACLs der Dokumente statisch überschrieben werden. Dazu aktivieren Sie oben die „Advanced Settings“. Im Abschnitt „Authorization Settings“ wird mit „Enable Static Access Rules“ wird die Funktion aktiviert. „Access Check Principal“ bestimmt den Namen des berechtigten oder nicht berechtigen Principals. Die „Access Check Action“ bestimmt, ob der Principal berechtigt ist, oder nicht.
Hinweis: Falls die Regeln geändert werden und bereits Dokumente im Index existieren, muss die Option „Synchronize with Index on Startup“ in den „Crawer Performance Settings“ aktiviert werden, damit beim Starten des Crawlers die Änderungen angewandt werden.
Principal Resolution Service
Wählen Sie im neuen oder bestehenden Service in der Einstellung „Service“ die Option Documentum Principal Resolution aus. Für mehr Informationen über das Erstellen und das grundlegende Konfigurieren eines Cache für einen Principal Resolution Service, siehe Installation & Konfiguration - Caching Principal Resolution Service.
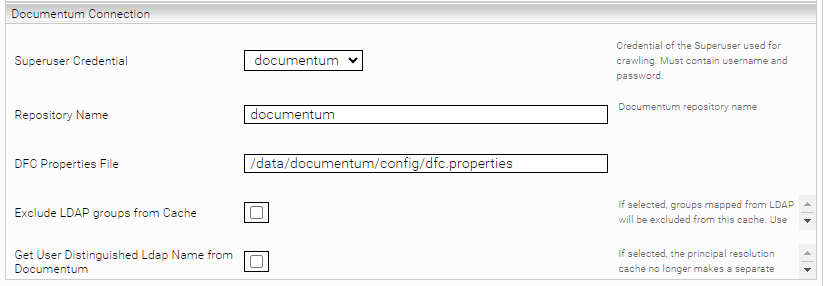
Konfiguration - Documentum Connection
Superuser Credential | Credential des Superusers, das für das Crawling verwendet wird. Muss den Benutzernamen und das Kennwort enthalten. Diese Anmeldeinformationen sollten mit den Anmeldeinformationen in den Documentum Connector-Einstellungen übereinstimmen. Im Gegensatz zum Connector müssen diese Anmeldeinformationen als Mindbreeze-Credential in der Registerkarte Network konfiguriert werden. |
Repository Name | Name des Documentum-Repository, zu dem eine Verbindung hergestellt werden soll. Muss mit den Anmeldeinformationen übereinstimmen, die in den Documentum Connector-Einstellungen festgelegt sind. |
DFC Properties File | Der Pfad zur „DFS Properties“ Datei. Muss mit dem Pfad übereinstimmen, der in den Documentum Connector-Einstellungen festgelegt wurde. Die Datei muss sich im config Verzeichnis von dfc.data.dir befinden. Das dfc.data.dir muss Schreibrechte mit dem Benutzer mes besitzen. Folgende Properties müssen konfiguriert sein (siehe dfc.properties Datei auf dem Documentum Server): dfc.data.dir=/documentum dfc.docbroker.host[0]=documentum.myorganization.com dfc.docbroker.port[0]=1489 |
Exclude LDAP groups from Cache (Advanced Setting) | Ist diese Option ausgewählt, werden über LDAP zugewiesene Gruppen von diesem Cache ausgeschlossen. Verwenden Sie diese Option nur, wenn Sie einen LDAP-Cache als Parent-Cache konfiguriert haben. Dabei ist es notwendig, dass die importierten LDAP-Gruppen in Documentum immer synchronisiert sind. |
Get User Distinguished Ldap Name from Documentum (Advanced Setting) | Ist diese Option aktiviert, stellt der Principal Resolution Cache nicht mehr für jeden Benutzer eine eigene LDAP-Anfrage. Dadurch kann die Performance verbessert werden. Dies funktioniert nur für Benutzer, die aus dem LDAP importiert wurden. Benutzer, die nicht aus dem LDAP stammen, finden weniger oder keine Dokumente. Dabei ist es notwendig, dass die importierten LDAP-Benutzer in Documentum immer synchronisiert sind. |
Allgemeine Informationen
Für die Authentifizierung von Benutzern verwendet das Principal Resolution Service folgende Benutzernamen-Alias:
- user_name aus Documentum (aus Datenbankspalte dm_user)
- user_login_name aus Documentum (aus Datenbankspalte dm_user)
- LDAP Distinguished Name(DN)über den LDAP Client. Wenn die Option Get User Distinguished Ldap Name from Documentum aktiviert ist, wird stattdessen der Wert user_ldap_dn aus Documentum (aus Datenbankspalte dm_user) verwendet.
Dies bedeutet, dass sich ein Mindbreeze Endbenutzer mit einem dieser drei Benutzernamen bei Mindbreeze authentifizieren muss, um Dokumente aus Documentum zu finden.