
Sure, you can handle it. But should you?
Let our experts manage the tech maintenance while you focus on your business.
Let our experts manage the tech maintenance while you focus on your business.
Google Search Appliance Feed Indizierung mit Mindbreeze InSpire
Konfiguration und Indizierung
Google Search Appliance Feeds
Der Mindbreeze InSpire GSA Feed Adapter ermöglicht Google Search Appliance Feeds mit Mindbreeze InSpire zu indizieren.
Der Feed ist eine XML-Datei, die URLs enthält. Ein Feed kann außerdem auch den Inhalt der Dokumente, Metadaten und zusätzliche Informationen wie Datum der letzten Änderung enthalten. Die XML-Datei muss dem von gsafeed.dtd definierten Schema entsprechen. Diese Datei befindet sich auf der Google Search Appliance unter http://< APPLIANCE - Host-Name>:7800/gsafeed.dtd.
Die GSA Feed XML Dokumente sollten mit einem HTTP Post Request auf den GSA Feed Adapter Service Port geschickt werden. Wenn der Feed erfolgreich empfangen und bearbeitet wurde, sendet der Service den Text „Success“ mit dem Status 200.
Ein Beispiel für ein Post Request mit curl:
curl -X POST -F "data=@<feed_xml_path>" http://<mindbreeze_inspire_server>:19900/xmlfeed
Feed Speicherung
Die empfangenen GSA Feeds können für eine konfigurierten Zeitintervall gespeichert werden. Aktivieren Sie dazu die Option “Enable Feed Storage” im Abschnitt “Feed Storage Settings”. Die Option sollte als Default aktiv sein.

Wenn mit “Override Feed Storage Directory” kein Verzeichnis für die Feed Lagerung konfiguriert ist, werden die Feeds in /data/messervicedata/<serviceuid>/ abgelegt.
Mit “Cleaning up old feeds Schedule” kann mittels einer Extended Cron Expression bestimmt werden, wann bzw. in welchem Intervall die veralteten Feeds gelöscht werden sollen. Eine Dokumentation und Beispiele zu Cron Expressions finden Sie hier.
Basiskonfiguration des GSA Feed Adapter Services
In der Mindbreeze Konfiguration öffnen Sie den „Indices“ Tab. Fügen Sie einen neuen Service mit dem Symbol „Add new Service“ hinzu.
![]()
Setzen Sie den „Display Name“ und wählen Sie den Service Type „GSAFeedAdapter“ aus.
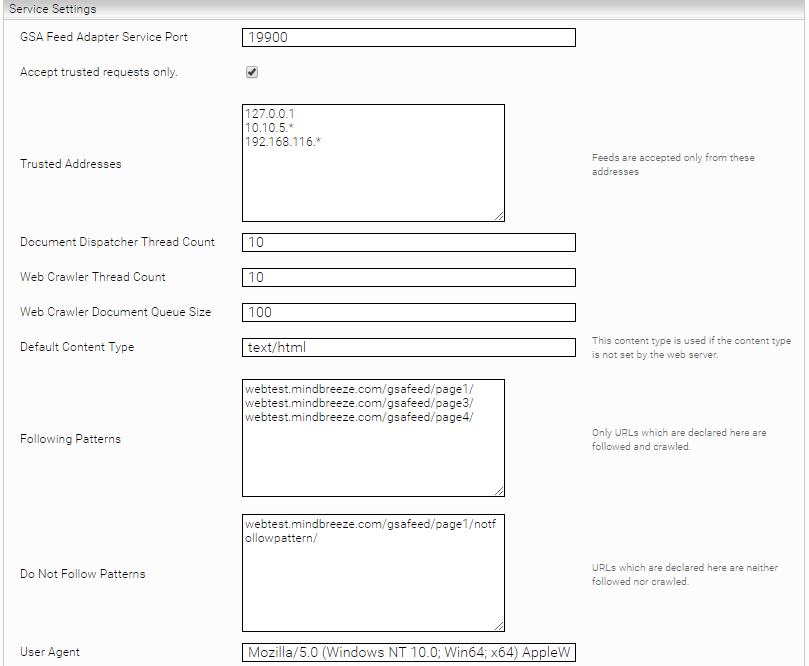
Service Settings:
- GSA Feed Adapter Service Port: HTTP Port an den die Feed Dokumente geschickt werden können
- „Accept Trusted Requests Only“: Wenn aktiviert, werden Feeds nur von IP Addressen welche in „Trusted Addresses“ konfiguriert sind akzeptiert.
- „Trusted Addresses“: Enthält eine Liste von vertrauenswürdigen IP-Adressen. Wildcards werden ebenfalls unterstützt, z.B.: 192.168.116.*
- „Use Secure Connection“: Wenn aktiviert, wird HTTPS für die Feed Services verwendet. Um HTTPS aktivieren zu können muss ein Credential mit SSL Zertifikat verfügbar sein.

- „Server Certificate Credential“: Hier sollte das Server Zertifikat Credential für HTTPS ausgewählt werden
- „Use Client Certificate Authentication“: Wenn aktiviert, werden Feeds nur mit Client Zertifikat Authentisierung akzeptiert. Die Client Zertifikate werden mit den installierten CA Zertifikaten validiert.
- „Trusted CA Certificate Subject Pattern“: Regulär Ausdruck der für weitere Einschränkung der vertrauenswürdige CA Zertifikate verwendet werden kann. Es werden nur jene installierte CA Zertifikate verwendet die eine passende „Subject Distinguished Name“ Eigenschaft besitzen.
- „Following Patterns“: Link Patterns, die nachverfolgt werden sollen
- „Do Not Follow Patterns“: Link Patterns, die nicht nachverfolgt werden sollen
- „Exclude Mime Types“: Kann eine Liste von Mime Typen enthalten die nicht indiziert werden sollen. Die Liste kann auch Regexp Patterns enthalten. Wenn Dokumente in Metadaten und URL Feeds mit diesen Mime Typen gefunden werden, werden sie nicht an der Index geschickt.
- Document Dispatcher Thread Count: Anzahl der Threads die heruntergeladenen Dokumente bearbeiten und an die Mindbreeze Indizes weiterschicken.
- Web Crawler Thread Count: Anzahl der Threads die URLs besuchen und um Dokumente herunterzuladen.
- Web Crawler Queue Size: Größe des Web Crawler Dokument Queue
- Enable FeedState CSV Logging: Wenn aktiv wird der Feed Status auch als CSV files im aktuellen Service Log Verzeichnis geloggt. Folgende CSV Files werden angelegt:
- received-feeds.csv: Ankommende Feeds mit Feed File Path
- processed-feeds.csv: Prozessierte Feeds mit Status
- processed-outlinks.csv: Prozessierte URL Records mit der Anzahl von gefundenen Links
- Full Feed Filter and Indexing Client Shutdown Timeout Seconds: Maximale Wartezeit für Full Feed Filter und Index Client Stop.
- Connection Timeout Seconds: Maximale Wartezeit für Antworten bei HTTP-Requests.
- Time until revisit Seconds: Zeitspanne, bis bereits besuchte URLs erneut gecrawled werden. Diese Option sollte nicht zu niedrig gesetzt werden, da sonst eine Gefahr auf Loops besteht.
- User Agent: Hier kann ein User Agent konfiguriert werden. Der konfigurierte User Agent wird für alle http Anfragen verwendet.
- Ignore robots.txt Rules for Matching URLs: mit einem regulären Ausdruck kann hier bestimmt werden für welche URLs die robots.txt Regeln nicht berücksichtigt werden.
- Minimum Delay in Milliseconds Between Consecutive HTTP Requests: Minimum Anzahl der Millisekunden zwischen aufeinanderfolgenden http Anfragen.
- Maximum Delay in Milliseconds Between Consecutive HTTP Requests: Maximum Anzahl der Millisekunden zwischen aufeinanderfolgenden http Anfragen.
- Try to Parse Record Metadata as Date Values: Wenn aktiv, wird es versucht mit Java Datumsformat, konfiguriert in „Parsable Date Formats (Ordered)“, ein Datumswert aus den Feed Metadaten zu extrahieren. Die Region für die Extrahierung kann mit ein IETF BCP 47 Locale gesetzt werden in „Locale String for Date Parsing“
- Do not replace crawler metadata with HTML meta tags: Wenn aktiv, werden die Metadaten die vom GSA Feed Adapter Service gesetzt werden nicht vom HTML Filter mit automatisch extrahierten Metadaten (HTML Meta Tags) überschrieben.
- Remove inaccessible URLs from Index: Wenn aktiv, werden beim Start des GSA Feed Adapters alle nicht mehr erreichbaren Seiten vom Index entfernt. Diese Option entspricht einer einmaligen Ausführung des Invalid Documents Deletion Schedule.
- Invalid Documents Deletion Schedule: Gibt an, wann bzw. in welchem Intervall der Index nach nicht mehr erreichbaren Seiten überprüft und von diesen bereinigt werden soll. Für die Konfiguration muss eine Extended Cron Expression verwendet werden. Eine Dokumentation und Beispiele zu Cron Expressions finden Sie hier.
Die „Following“ bzw. „Do Not Follow“ Patterns können mit der Syntax von Google URL Patterns definiert werden:
https://www.google.com/support/enterprise/static/gsa/docs/admin/72/gsa_doc_set/admin_crawl/url_patterns.html
Collections, und Destination Mappings
Collections
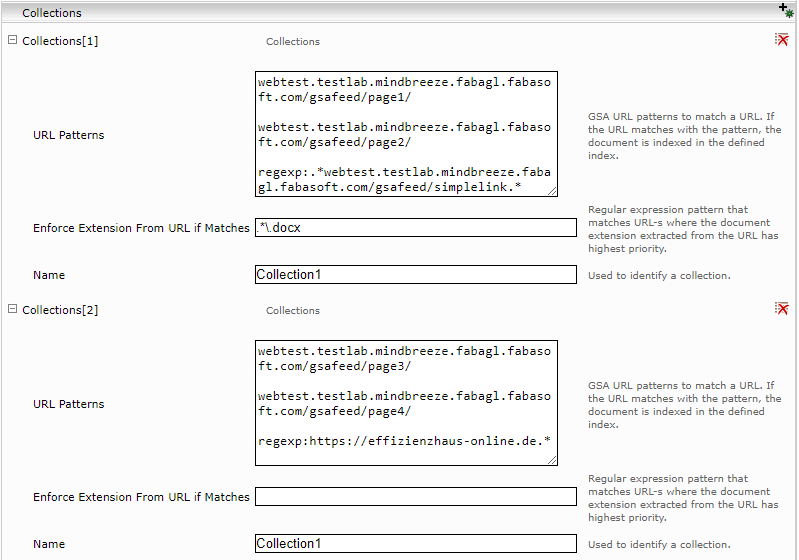
Im Abschnitt „Collections“ der GSA Feed Adapter Service Konfiguration, ist es möglich URL Gruppen anhand von URL Patterns zu definieren. Ein Dokument kann zu mehreren Collections gehören, indiziert wird es aber nur einmal pro Category und Category Instance.
Die Namen von allen Collections die ein Dokument enthalten werden in das Metadatum „collections“ gespeichert.
Wenn ein Regulär Ausdruck als „Enforce Extension from URL if Matches“ Parameter gesetzt ist, wird für Dokumente mit passende URL-s die Erweiterung aus der URL abgeleitet anstatt von „Content-Type“ http Header.
Wenn eine große Anzahl von Collections oder zusätzliche Collection Eigenschaften nötig sind, können die Collections auch mit einer CSV-formatierten Konfiguration definiert werden. Die Collection Konfiguration kann aus einem File eingelesen oder direkt als Text konfiguriert werden.
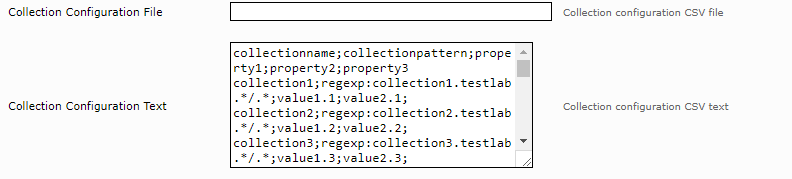
Die Collection Konfiguration muss einen CSV Header mit den Eigenschaften „collectionname“ und „collectionpattern“ enthalten. Weitere Eigenschaften können auch definiert werden wie in unserem Beispiel „property1“, „property2“ und „property3“.
Die CSV Zeilen werden gruppiert nach „collectionname“. Wenn eine Collection mit mehrere URL Patterns definiert werden soll, kann die folgende Schreibweise verwendet werden:
collectionname;collectionpattern;property1;property2;property3
collection1;regexp:server1.testlab.*/.*;value1.1;value2.1;value3.1
collection1;regexp:server1.mindbreeze.*/.*
Destination Mappings
Damit URLs in den Collections indiziert werden können, muss mindestens ein Destination Mapping definiert werden. Klicken Sie dazu auf das Symbol „Add Composite Property“ im Bereich „Destination Mapping“.
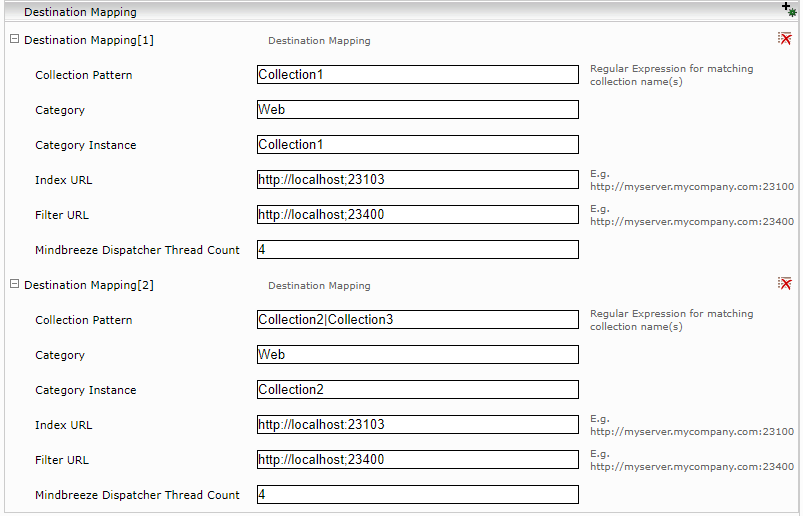
Referenzieren Sie eine oder mehrere Collections im hinzugefügte Destination Mapping („Collection Pattern“). Sie können dafür einen regulären Ausdruck angeben der auf die gewünschten Collection Namen passt.
Weiterst müssen hier die für die Indizierung verwendeten Category und Category Instance Eigenschaften definiert werden. Für Web Inhalte ist zum Beispiel die „Category“ „Web“. Die „Category Instance“ kann frei gewählt werden. Die Category Instance kann Referenzen auf definierte Collection-Eigenschaften, URL Teile und Feed Parameter enthalten.
Zuletzt ist eine Index URL und eine Filter URL wohin die Daten geschickt werden sollen.
Mit „Mindbreeze Dispatcher Thread Count“ kann man die Anzahl der Threads bestimmen die Dokumente an die konfigurierte Index- und Filter Services schicken.
Full Feed Destination Mappings
Die Full Feed Destination Mappings sind ähnlich zu Collection-basierte Destination Mappings. Wenn Full Content Feeds indiziert werden sollen, muss die Feed Datasource als Category Instance in einem Mindbreeze Index definiert werden.
Die GSA Full Content Feeds enthalten alle Dokumente einer Datenquelle, definiert mit dem Feed „Datasource“ Eigenschaft. Es werden alle Dokumente die sich nicht in dem Feed befinden und vorher in diese Datenquelle indiziert wurden gelöscht.
Ein Full Feed Destination Mapping hat folgende Attribute:
- Datasource: Die Feed Datasource welche an den hier konfigurierten Index geschickt werden soll. Die Dokumente werden mit dieser Category Instance indiziert.
- Category: die Category welche für die Indizierung verwendet werden soll.
- Index URL: Mindbreeze Index Service interne URL (http://localhost:<index_port>)
- Filter URL: Mindbreeze Filter Service interne URL (http://localhost:<filter_port>)
- Mindbreeze Dispatcher Thread Count: die Anzahl der Threads die Dokumente an die konfigurierte Index- und Filter Services schicken.
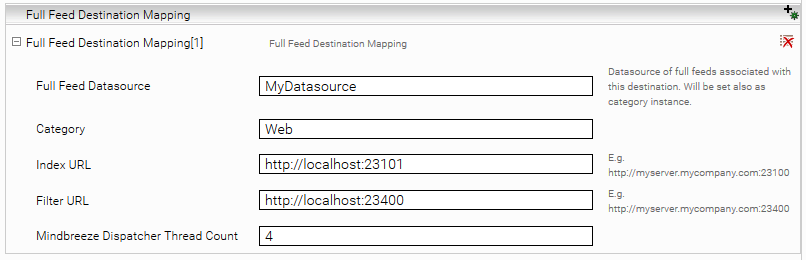
Wenn keine Full Feed Destination Mappings definiert sind, werden alle Feeds als inkrementell behandelt.
Metadaten Extrahierung
Wenn Dokumente mit dem GSA Fassadendienst indiziert werden, ist es möglich benutzerdefinierte Metadaten für die Dokumente auf verschiedene Weise zu definieren:
Metadaten definiert im Feed,
Metadaten hinzugefügt vom HTTP-Header,
Im Falle von HTML-Dokumenten, benutzerdefinierte Metadaten aus dem Inhalt.
Robots Metatags
Metadaten und URL Feeds
Die in den URL-Records definierten Metadaten werden automatisch extrahiert und indiziert. In diesem Beispiel werden die Metadaten „meta-keywords“, „targetgroup“ und „group“ indiziert.
<record url="http://website.myorganization.com/newsletter" action="add" mimetype="text/html" lock="true" crawl-immediately="true">
<metadata>
<meta name="meta-keywords" content="Newsletter, My Organization"/>
<meta name="targetgroup" content="fachkunde"/>
<meta name="group" content="public"/>
</metadata>
</record>
Die Metadaten der Records werden nur für die Record URLs indiziert und nicht für die Unterseiten.
HTTP Headers
Zusätzlich zu den Metadaten aus den http Records werden für alle URLs die Metadaten aus dem X-gsa-external-metadata http Header extrahiert. Der Header enthält eine, durch Komma getrennte Liste von Werte. Alle Werte haben den Form meta-name=meta-value. Die „meta-name“ und „meta-value“ Elemente sind URL-kodiert (http://www.ietf.org/rfc/rfc3986.txt, Section 2).
ACL
Der Mindbreeze InSpire GSA Feed Adapter unterstützt ACL-s aus Feeds mit folgenden Einschränkungen:
- ACL-s müssen per Record gesetzt sein
- Geerbte ACL-s werden nicht unterstützt.
- ACL-s aus X-google-acl Headers werden derzeit nicht berücksichtigt.
ACLs aus X-Gsa-Doc-Controls http Header werden extrahiert. Hier werden auch nur per URL gesetzte ACLs unterstützt.
Achtung! Dokumente die geerbte ACL-s in X-Gsa-Doc-Controls haben, werden per Default nicht indiziert. Wenn diese Dokumente auch indiziert werden sollen, muss die Konfigurationsoption „Index Documents with Partial Header ACL“ aktiviert werden.
Metadaten Extraktion aus dem Inhalt
Für HTML Dokumente ist es möglich benutzerdefinierte Metadaten auch aus dem Inhalt zu extrahieren, analog zum Mindbreeze Web Connector.
Wie beim Metadatum Mapping, ist es möglich für URL Collections auch “Content Extractoren“ und „Metadata Extractoren“ zu definieren.
Ein Content Extractor hat ein Collection Pattern wo ein regulärer Ausdruck konfiguriert werden kann. Auf alle URLs von allen passenden Collections werden die Regeln für Inhalt und Titel Extrahierung angewendet.

Metadata Extraktoren können auch für die Collections definiert werden. Hier ist es möglich benutzerdefinierte Metadaten mit verschiedenen Formaten und Formatierungsoptionen zu extrahieren.

Die Metadata Extraktoren verwenden XPath Ausdrücke für das Extrahieren von textuellen Inhalten. Diese können dann formatspezifisch bearbeitet, und zum Beispiel als Datum interpretiert werden.
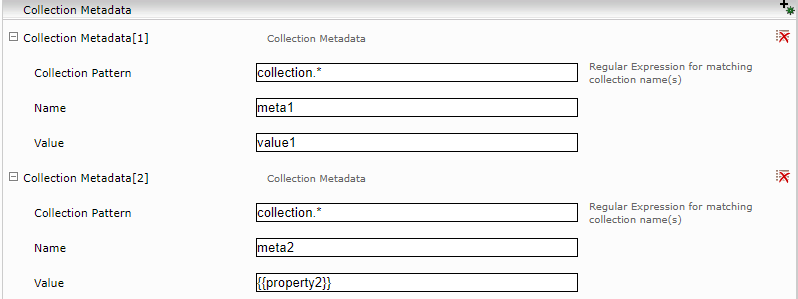
Collection Metadaten
Pro Collection ist es möglich Metadaten zu definieren, die für alle zugehörige Dokumente gesetzt werden. Die Metadatenwerte können Referenzen auf definierte Collection-Eigenschaften enthalten. Im folgendem Beispiel wird der Wert für „meta2“ auf den Wert von Eigenschaft „property2“ der Collection gesetzt. Ein Collection Metadatum hat ebenfalls ein Collection Pattern indem ein regulärer Ausdruck konfiguriert werden kann. Auf allen Dokumenten von allen passenden Collections werden die Metadaten gesetzt.
Die Metadaten können auch Referenzen auf die folgende URL Komponente und Feed Parameter enthalten:
- Hostname: {{urlhost}}
- Port: {{urlport}}
- Pfad: {{urlpath}}
- Feed Datasource: {{datasource}}
- Feed Type: {{feedtype}}
Collection ACL
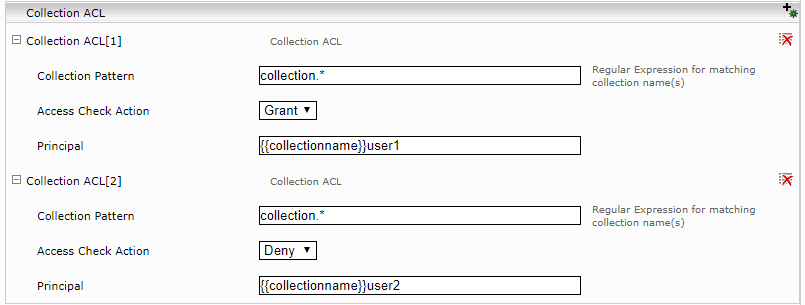
Analog zu Collection Metadaten ist es möglich ACL Einträge auf Collection-basis zu definieren. Die ACL Principals können ebenfalls Referenzen auf Collection-Eigenschaften enthalten. Die ACL Einträge haben auch eine „Collection Pattern“ Eigenschaft womit definiert werden kann, für welche Collections die ACL Einträge definiert werden sollen. Collection ACLs werden nur dann verwendet, wenn noch keine Feed ACL für die Dokumente definiert ist.
Die ACL Einträge können Referenzen auf die folgende URL Komponente und Feed Parameter enthalten:
- Hostname: {{urlhost}}
- Port: {{urlport}}
- Pfad: {{urlpath}}
- Feed Datasource: {{datasource}}
- Feed Type: {{feedtype}}
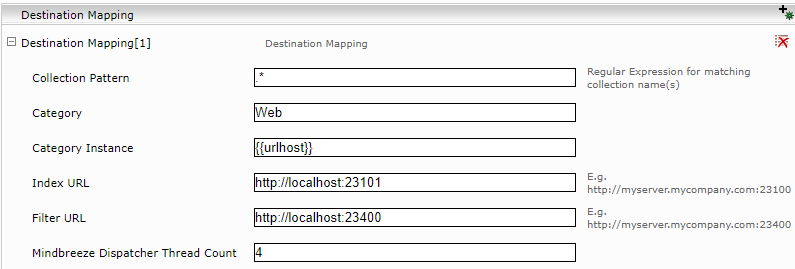
URLs mit mehreren Collections
Wenn ein Dokument anhand der Collection Konfiguration zu mehreren Collections gehört, werden die Collection Metadaten und Collection ACL Elemente von den passenden Collections zusammengeführt.
Es ist möglich den „Category Instance“ des Dokuments auch anhand der Collection Zugehörigkeit oder URL zu definieren. Für die Eigenschaft „Category Instance“ in der „Destination Mapping“ Konfiguration ist es möglich auch die Referenzen auf Collection Eigenschaften und URL Komponenten zu verwenden, wie in diesem Beispiel gezeigt:
Metadata Updates
Der GSA Feed-Adapter kann eine Metadatenaktualisierung für einen Feed-Record auslösen, wenn der Records „action“ Attribut auf "update" gesetzt ist:
<record url="http://website.myorganization.com/newsletter" action="update" mimetype="text/html" lock="true" crawl-immediately="true">
<metadata>
<meta name="meta-keywords" content="Newsletter, My Organization"/>
</metadata>
</record>
In diesem Fall wird das Dokument mit dem im URL-Attribut angegebenen Schlüssel mit den Feed Record Metadaten aktualisiert.
Login Settings
Form Login und Session Verwaltung mit Cookies kann für gegebene URL Patterns mittels einer Konfiguration im CSV-format definiert werden. Die Login Konfiguration kann von einem File eingelesen oder direkt als Text konfiguriert werden.
Die Login Konfiguration muss mit folgendem Header beginnen:
urlpattern;actiontype;actionurl;logindata;followredirects;sessionlifetime;parameters
Die Login-Konfigurationszeilen enthalten Login-Aktion-Definitionen die mit der „urlpattern“ Eigenschaft gruppiert sind.
Wie in dem Header definiert, hat eine Login-Aktion folgende Eigenschaften:
- urlpattern: ein Google URL Pattern definiert auf welche URLs die Aktion angewendet werden soll.
- actiontype: Login-Aktionstyp. Unterstützte Werte sind: GET, POST, AWS_SIGN, OAUTH.
- actionurl: URL gegen die die Logindaten gesendet werden.
- logindata: Zusätzliche Login Daten (Formularinhalt für Post oder Application Credentials für AWS_SIGN).
- followredirects: „true“ oder „false“. Bestimmt ob die zusätzliche http Weiterleitungen automatisch verfolgt werden sollen.
- sessionlifetime: die Lebenszeit der Sitzung in Sekunden (es gilt der erste Wert pro „urlpattern“).
- parameters: zusätzliche/optionale Parameter die für den Anmeldevorgang benötigt werden. (zurzeit wird nur „scope“ für OAUTH unterstützt).
Die unterstützte Login Aktionstypen sind:
- POST: http Post Request auf eine URL mit einem definierten Formularinhalt. Der Text muss URL-Formkodiert sein.
Beispiel:
regexp:confluence.myorganization.com;POST;http://confluence.myorganization.com /dologin.action;os_username=user&os_password=mypassword&login=Anmelden&os_destination=%2Findex.action;false;60
- GET: http Get Request auf eine URL.
Beispiel:
- regexp:myserver.myorganization.com;GET;http://myserver.myorganization.com /sessionvalidator;;false;60
- AWS_SIGN: Amazon Web Services Signature Version 4 für Amazon REST URLs.
Beispiel:
- regexp:s3.eu-central-1.amazonaws.com;SIGN_AWS;;eu-central-1:<Access Key ID>:<Secret Key>;false;0
- OAUTH: OAuth Authentifizierung via Access Tokens und Client Credentials (client-id und client-secret)
Beispiel:
regexp:myserver.myorganization.com/protected;OAUTH;https://auth.myserver.myorganization.com/auth/realms/master/protocol/openid-connect/token;cloaktest:acf868e4-4272-42e7-aa2d-b7c63d2ec769;false;60;
Anmerkung: Die Spalte “parameters” unterstützt zur Zeit nur den Parameter „scope“ für die Generierung des Bearer Token mittels OAUTH. Der Wert wird URL encodiert.
regexp:myserver.myorganization.com/protected;OAUTH;https://auth.myserver.myorganization.com/auth/realms/master/protocol/openid-connect/token;cloaktest:acf868e4-4272-42e7-aa2d-b7c63d2ec769;false;60;scope=openid%20email
Wenn mehrere Login Aktionen für ein URL Pattern definiert werden sollen, muss man für die Login Aktionen dasselbe „loginpattern“ setzen.
Beispiel:
urlpattern;actiontype;actionurl;logindata;followredirects;sessionlifetime
regexp:myserver.myorganization.com;POST;http://myserver.myorganization.com /dologin.action;username=user&password=mypassword;false;60
- regexp:myserver.myorganization.com;GET;http://myserver.myorganization.com /sessionvalidator;;false;60
Einschränkungen
Wenn Sie die Anmeldeaktion SIGN_AWS verwenden und Ihre Dateinamen ein Pluszeichen (+), Komma (,) oder Prozentzeichen (%) enthalten, müssen diese Zeichen in der XML-Datei des GSA-Feeds encodiert sein (URL-Encoding). Andernfalls gibt AWS_SIGN als Ergebnis den HTTP-Statuscode 403 (= Zugriff verboten) aus und diese Dokumente werden nicht indiziert.
Robots-Meta-Tag
Das Robots-Meta-Tag ermöglicht eine detaillierte, seitenspezifische Herangehensweise, um festzulegen, wie eine bestimmte Seite indiziert und den Nutzern in Suchergebnissen angezeigt werden soll. (https://developers.google.com/webmasters/control-crawl-index/docs/robots_meta_tag?hl=de).
Das Robots Meta Tag ist im <head> Abschnitt der jeweiligen Seite platziert:
<!DOCTYPE html>
<html>
<head>
<meta name="robots" content="noindex" />
(…)
</head>
<body>(…)</body>
</html>
Der Mindbreeze InSpire GSA Feed Adapter Service berücksichtigt den folgenden Robots-Meta-Tag Werte:
noindex: Diese Seite nicht wird nicht indiziert.
nofollow: Den Links auf dieser Seite wird nicht gefolgt.
none: Entspricht noindex, nofollow.
Collection Statistics Servlet
Auf können Statistiken zu den Collections abgeholt werden. „host“ steht dabei für den Hostnamen vom Mindbreeze InSpire Server, „port“ steht für einen freien Port, der für das Collection Statistics Servlet automatisch ausgewählt wird. Dieser kann in den Logs gefunden werden und steht zusätzlich auch im Log-Verzeichnis unter statistics_servlet_port_<port>.
Schaltfläche „Create Statistics“
Benutzeroberfläche
Ruft man die oben genannten URL im Browser auf, bekommt man folgende Benutzeroberfläche im Browser.

Um eine Berechnung der Statistiken angestoßen, muss die Schaltfläche „Create Statistics“ geklickt werden.
Zusätzlich können im Feld „Category Instances“ weitere Category Instances angegeben werden (mit Zeilenumbruch getrennt). Der Grund für dieses Feld ist, dass Destination Mappings, die für die Category Instance Platzhalter verwenden (z.B. {{urlhost}}), vom Collection Statistic Servlet nicht prozessiert werden können. Um jedoch trotzdem Statistiken für die betroffenen Destination Mappings bzw. Collections erstellen zu können, gibt es die Möglichkeit, das Feld „Category Instances“ im Collection Statistic Servlet zu verwenden, um von allen Destination Mappings alle Dokumente mit den angegebenen Category Instances für die Berechnung der Statik einbeziehen zu können. Klicken Sie anschließend auf die Schaltfläche „Create Statistics“, um die Berechnung der Statistiken anstoßen zu können.
URL-Parameter
Folgende URL Query Parameter können unter /collections gesetzt werden, um die Statistiken ohne Benutzeroberfläche erstellen zu können:
action=create | Erstellen der Statistiken |
categoryInstance | Parameter kann mehrfach angegeben werden, um Category Instances als Parameterwerte angeben zu können, die anstatt der oben genannten Destination Mappings Platzhalter verwendet werden, z.B. /collections?action=create&categoryInstance=mindbreeze.com&categoryInstance=fabasoft.com |
Schaltfläche „Refresh Status“
Benutzeroberfläche
Mithilfe der Schaltfläche „Refresh Status“ kann der aktuelle Status vom Statistikerstellungsprozess abgeholt werden.

Bei der Berechnung der Statistik wird einerseits der sogenannte Crawlerstatus für alle Dokumente geholt – dies dauert, je nach Anzahl der Dokumente im Index, mehrere Minuten bis evt. sogar Stunden. Anschließend werden die Statistiken erstellt; die Anzahl der insgesamt zu verarbeitenden Dokumente (in diesem Falls 4484) ist jedoch nur ein Schätzwert. 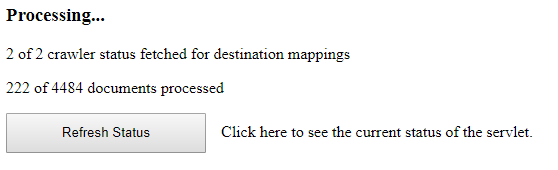
URL-Parameter
Folgender URL Query Parameter kann unter /collections gesetzt werden, um den aktuellen Status der Statistiken ohne Benutzeroberfläche abfragen zu können:
action=refresh | Abholen des Status der Berechnung der aktuellen Statistik |
Schaltfläche „Download Statistics“
Benutzeroberfläche
Wenn die Berechnung fertig ist, wird die Schaltfläche „Download Statistics“ angezeigt. Wenn diese Schaltfläche „Download Statistics“ geklickt wird, wird die CSV-Statistik heruntergeladen. Die CSV-Datei kann dann beliebig oft heruntergeladen werden. Für jede Collection ist eine Zeile in der CSV-Datei enthalten. Die heruntergeladene Datei enthält folgende Spalten:
CollectionName | Name der Collection |
Category | Category (im zugehörigen Destination Mapping konfiguriert) |
CategoryInstance | Category Instance (im zugehörigen Destination Mapping konfiguriert) |
IndexURL | Index URL (im zugehörigen Destination Mapping konfiguriert) |
FilterURL | Filter URL (im zugehörigen Destination Mapping konfiguriert) |
DocumentCount | Anzahl der Dokumente in der Collection |
Timestamp | Zeitstempel (Format in ISO 8601), von welcher Zeit / Datum die Daten stammen |
URL-Parameter
Folgender URL Query Parameter kann unter /collections gesetzt werden, um die CSV Collection Statistik herunterzuladen:
action=download | Download der CSV Collection Statistik |
Konfiguration des Index Services
Klicken Sie auf den Reiter “Indices” und dann auf das Symbol “Add new service”, um ein Index zu erstellen (optional).

Geben sie den Indexpfad (“Index Path”) ein. Falls nötig, passen Sie den Anzeigenamen („Display Name“) vom Index Service, die Index Parameter und den zugehörigen Filter Service an.
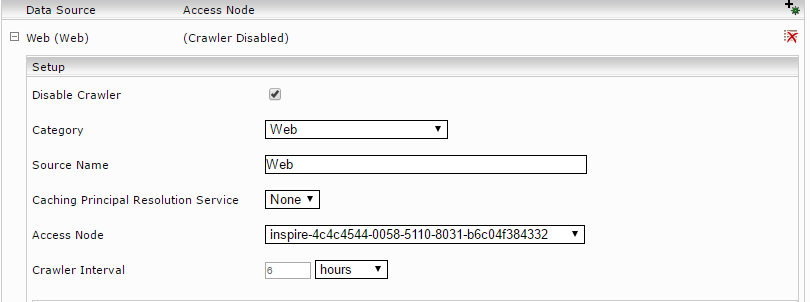
Zur Erstellung von Datenquellen für einen Index klicken Sie im Abschnitt „Data Sources“ auf „Add new custom source“.

Hier sollte für alle Kategorien die im GSA Feed Adapter Service für diesen Index zugeordnet sind eine Datenquelle konfiguriert werden (Siehe dazu das Kapitel „Basiskonfiguration des GSA Feed Adapter Services“). Da die Datenquellen nur für die Suche verwendet werden, sollten die Crawler deaktiviert werden. Dazu aktivieren Sie den „Advanced Settings“ Modus und aktivieren Sie die Option „Disable Crawler“ für die konfigurierten Datenquellen:
GSA Transformer
Der GSA Transformer ermöglicht dem Client Service, Google Search Appliance XML Anfragen zu verstehen und Google Search Appliance kompatible XML Antworten zu liefern.
Details dazu finden sich unter Google Search Appliance: Search Protocol Reference
Die Abfragen können an folgende URL gestellt werden: https://appliance/plugin/GSA/search?q=<query>
Konfiguration des GSA Transformers
Konfiguriert wird der GSA Transformer im Client Service. Metadaten, welche immer geliefert werden sollen, können hier definiert werden.
Das Plugin wird zuerst unter „API V2 Search Request Response Transformer“ im Tab Client-Service hinzugefügt.
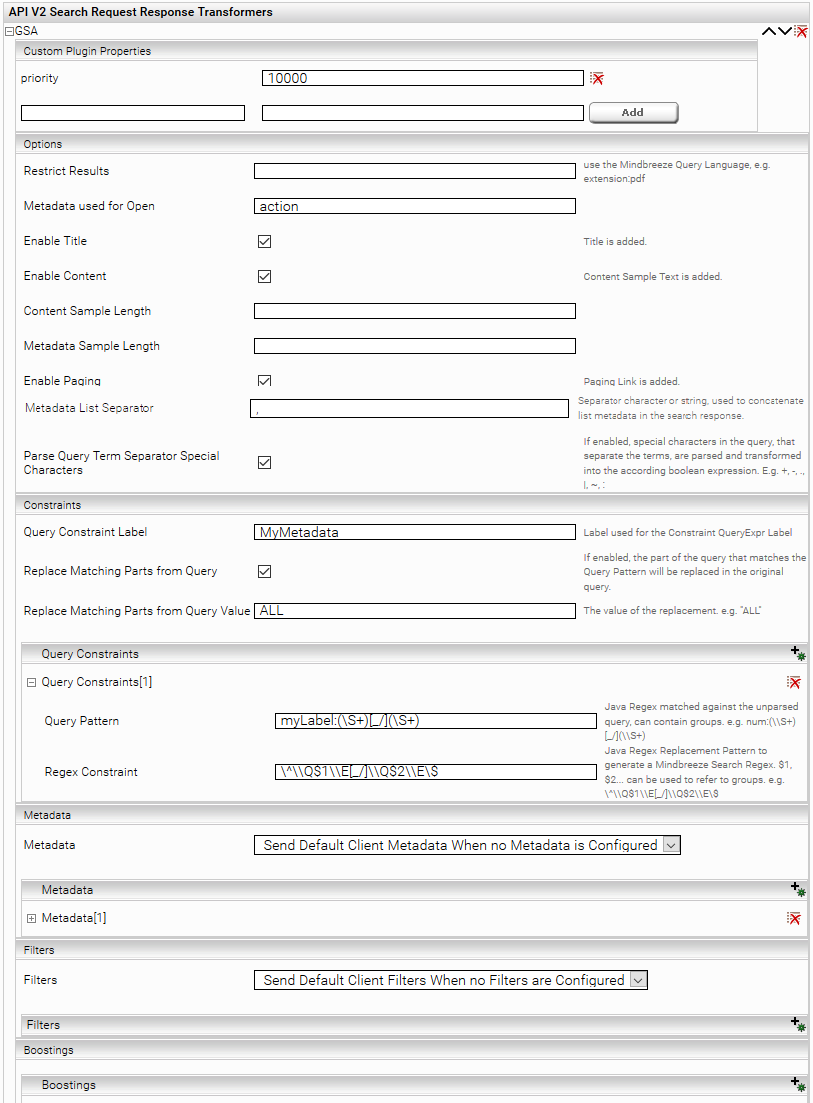
Konfiguration Options
Einstellung Name | Beschreibung |
„Restrict Results“ | Mithilfe der Mindbreeze Query Language können Suchresultate eingeschränkt werden (z.B. extension:pdf) |
„Metadata used for Open“ | |
„Enable Title“ | Wenn aktiv, ist der Titel der Dokumente im Suchresultat vorhanden |
„Enable Content“ | Wenn aktiv, ist der Sample Text der Dokumente im Suchresultat vorhanden |
„Content Sample Lenght“ | Die maximale Länge des Sample Textes. Nur wirksam, wenn „Enable Content“ aktiv ist. |
„Metadata Sample Lenght“ | Die maximale Länge der Metadaten im Suchresultat. |
„Enable Paging“ | Wenn aktiv, werden im Response Informationen zum Blättern in den Suchresultaten zur Verfügung gestellt. |
„Metadata List Separator“ | Zeichen oder Zeichenkette, welche als Trennsymbol verwendet wird, um Listen-Metadaten im Response zu einer Zeichenkette zu konkatenieren. |
„Parse Query Term Separator Special Character“ | In der Query können spezielle Zeichen enthalten sein, welche die Terms voneinander trennen und logische Bedeutung haben. Diese Zeichen werden, wenn diese Option aktiv ist, geparst und die Query wird in Mindbreeze-kompatible logische Ausdrücke transformiert. Weitere Informationen dazu finden Sie weiter unten. |
Konfiguration Query Constraints
Es können auf den Query-String reguläre Ausdrücke (Regex) angewendet werden, um Query Constraints zu setzen. Die Query Constraints sind reguläre Ausdrücke, es werden Back-Referenzen unterstützt.
Beispiel eines möglichen Anwendungsfalles ist z.B. die Suche nach Dokumenten mit Autorennummer in unterschiedlichen Schreibweisen, die mit Constraints noch stärker eingeschränkt werden soll.
Folgende Dokumente existieren:
Document 1: author:abc_12,def_45 authorid:abc_12
Document 2: author:abc_12,def_45 authorid:abc/12
Document 3: author:abc_12,def_45 authorid:def_45
Folgende Querys werden abgesetzt
Query 1: author:abc_12
Query 2: author:abc/12
Beide Querys sollen trotz der unterschiedlichen Schreibweisen nur folgende 2 Dokumente geliefert werden:
Document 1: author:abc_12,def_45 authorid:abc_12
Document 2: author:abc_12,def_45 authorid:abc/12
Die Idee ist, mit Regex die als Trennzeichen den Unterstrich oder den Schrägstrich erkennen, zu arbeiten.
Dazu ist notwendig 3 Einstellungen zu konfigurieren:
„Query Contraints Label“ auf authorid setzen. Hinweis: Das Metadatum muss “Regex-Matchable” sein.
„Query Pattern“ auf author:(\S+)[_/](\S+) setzen
„Regex Constraint“ auf \^\\Q$1\\E[_/]\\Q$2\\E\$ setzen
Es kann auch nach nichtexistierende Metadaten gesucht werden, z.B
Query 1: writer:abc_1
Normalerweise liefert diese Query keine Resultate, da es kein Dokument mit dem Metadatum writer gibt. Das Plugin kann auch so konfiguriert werden, dass die Query selbst manipuliert wird. Dazu muss die Einstellung „Replace Matching Parts from Query“ aktiviert werden. Und die Einstellung „Replace Matching Parts from Query Value“ auf ALL gesetzt werden. Dadurch wird die Query wie folgt transformiert:
Query 1‘: ALL
Da die Constraints wie bisher gesetzt sind, werden jetzt die korrekten Dokumente geliefert.
Einstellung Name | Beschreibung |
„Query Contraints Label“ | Name für das Query Expression Label (Name des zu Filternden Metadatums) Hinweis: das Metadatum muss „Regex-Matchable“ sein. Die Eigenschaft muss im Category-Descriptor oder in den „Aggregated Metadata Keys“ festgelegt werden, ansonsten funktioniert der Constraint nicht. |
„Replace Matching Parts from Query“ | Wenn aktiv, werden Teile der Query, die Matchen durch einen String ersetzt. Default: inaktiv |
„Replace Matching Parts from Query Value“ | Der Wert, der die matchenden Teile ersetzt. Default: leer. z.B. ALL |
„Query Pattern“ | Regulärer Ausdruck (Java) mit den die Query gematcht wird. Es können Gruppen verwendet werden. Z.B. myLabel:(\S+)[_/](\S+) |
„Regex Constraint“ | Regulärer Ausdruck (Mindbreeze) für den Query Constraint Regex. Referenzen auf gematchte Gruppen sind möglich mit $1 $2 … . Das Alleinstehende Sonderzeichen $ muss mit \ escaped werden. Z.B. \^\\Q$1\\E[_/]\\Q$2\\E\$ |
Konfiguration Standard Metadaten und Metadaten Formate
Im Abschnitt „Metadata“ können die Standardmäßig angeforderten Metadaten konfiguriert werden.
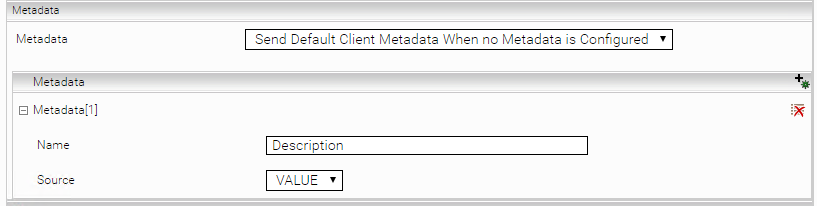
Einstellungs Name | Beschreibung |
„Metadata“ | Bestimmt den Metadaten-Modus. „Disable“ fordert standardmäßig keine Metadaten an. „Send Only Configured Metadata“ fordert die konfigurierten Metadaten an. „Send Default Client Metadata When no Metadata is Configured“ fordert, wenn keine Metadaten konfiguriert sind, die Standard-Metadaten der Datenquelle an, ansonsten die konfigurierten Metadaten. |
Metadata „Name“ | Name des Metadatums |
Metadata „Source“ | Format des Metadatums. „VALUE“ oder „HTML“. „HTML“ ist die empfohlene Einstellung für Insight Apps, da dieses Format gut angezeigt werden kann. „VALUE“ liefert den rohen Wert des Metadatums. |
Konfiguration Standard Filter
Im Abschnitt „Filters“ können die Standardmäßig angeforderten Filter konfiguriert werden.
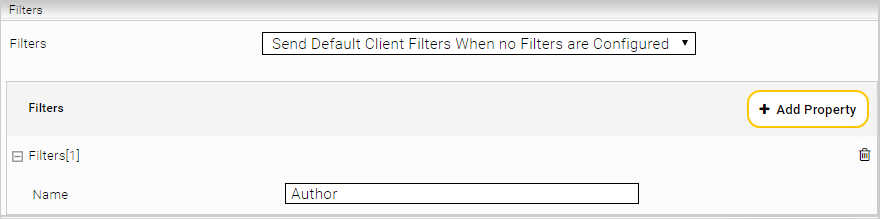
Einstellungs Name | Beschreibung |
„Filters“ | Bestimmt den Filter-Modus. „Disable“ fordert standardmäßig keine Filter an. „Send Only Configured Filters“ fordert die konfigurierten Filter an. „Send Default Client Filters When no Filters are Configured“ fordert, wenn keine Filter konfiguriert sind, die Standard-Filter der Datenquelle an, ansonsten die konfigurierten Filter. |
Filters „Name“ | Name des Filters, der angefordert werden soll |
Konfiguration von Boostings
Im Abschnitt „Boostings“ kann die Relevanz von Dokumenten (Reihenfolge beim Suchresultat) beeinflusst werden.
Einstellungs Name | Beschreibung |
„Query Label“ | Name des Metadatums, welches mit der „Query Regex“ verglichen werden soll |
„Query Regex“ | Regex, welches mit dem Metadatum mit dem Namen aus „Query Label“ verglichen werden soll. |
„Factor“ | Boosting Factor, der auf die Relevanz aller gefundener Dokumente angewendet wird, wenn die Regex auf mit dem besagten Metadatumswert übereinstimmt.
|
Boosting – Anwendungsfall Best Bets
Dokumente der Kategorie „BestBets“ würden ohne Boosting nicht immer an erster Stelle beim Suchresultat erscheinen. Möchte man jedoch Dokumente der Kategorie „BestBets“ beim Suchresultat an erster Stelle haben, kann ein Boosting dafür konfiguriert werden. Der folgende Screenshot und die Tabelle beschreiben, wie diese Werte konfiguriert werden müssen.

Einstellungs Name | Wert | Anmerkung |
„Query Label“ | datasource/category | |
„Query Regex“ | ^BestBets$ | |
„Factor“ | 10 | Der optimale Wert hängt vom konkreten Anwendungsfall (Suche und indizierte Dokumente) ab der Wert „10“ ist nur ein Beispiel |
Features der GSA XML Suchabfrage
Zusätzlich unterstützt der GSA Transformer folgende neuen Features der GSA XML Suchabfragen:
Request Fields
start
num
getfields
requiredfields
query operators
filter
paging
Query Term Separator Special Characters
sort
Hinweise zu getfields
Der getfields Parameter bestimmt, welche Metadaten angefordert werden. Wird der getfields Parameter nicht verwendet, oder ist der getfields Wert "*", dann bestimmt die Konfiguration der Metadaten (siehe Abschnitt oben), welche Metadaten angefordert werden.
Werden mit dem getfields Parameter explizit Metadaten angefordert, z.B. mit getfields=Author.Description.Revision dann werden nur diese Metadaten angefordert, unabhängig von den konfigurierten Metadaten. Diese Metadaten werden standardmäßig im Format „HTML“ angefordert.
Das Format der angeforderten Metadaten können allerdings mit den konfigurierten Metadaten geändert werden. Ist beispielsweise das Metadatum Description mit dem Format „VALUE“ konfiguriert, dann werden mit getfields=Author.Description.Revision Metadaten in folgenden Formaten angefordert: Author in HTML, Description in VALUE, Revision in HTML.
Hinweise zu Query Term Separator Special Characters
In der Query können spezielle Zeichen enthalten sein, welche die Terms voneinander trennen und logische Bedeutung haben. Diese Zeichen werden geparst und die Query wird in Mindbreeze-kompatible logische Ausdrücke transformiert. Beispiele für mögliche Transformationen sind:
Query | Resultat |
tree|house | tree OR house |
tree -garden | tree NOT garden |
tree.garden | tree AND garden |
inmeta:tree | tree |
description~tree | description:tree |
Dieses Verhalten lässt sich deaktivieren, indem die Konfigurationsoption „Parse Query Term Separator Special Characters“ deaktiviert wird. Dadurch wir die originale Query für die Suche verwendet.
Hinweise zu sort
In Google Search Appliance: Search Protocol Reference – Request Format – Sorting wird beschrieben, welche Query-Parameter bei einer Suche mitgeschickt werden können, um die Sortierung der Suchresultate beeinflussen zu können. Mindbreeze InSpire unterstütz jedoch nur eine Teilmenge der Features, die in der oben genannten Seite beschrieben sind. In den folgenden Unterabschnitten wird beschrieben, welche Sortiermodi von Mindbreeze unterstütz werden
Sortierung nach Datum
Parameter: sort=date:<direction>:<mode>:<format>
<direction> Wert | Unterstützt? | Fallback |
A | Ja | |
D | Ja |
<mode> Wert | Unterstützt? | Fallback |
S | Nein | R |
R | Ja | |
L | Ja |
<format> Wert | Unterstützt? | Fallback |
d1 | Ja |
Sortierung nach Metadatum
Parameter: sort=meta:<name>:<direction>:<mode>:<language>:<case>:<numeric>
Alle Werte nach <name> sind optional und können somit leer gelassen werden. Wenn Sie z.B. nur den Namen und den Modus bestimmen wollen, können Sie folgendes Format verwenden:
meta:<name>::<mode>::: oder
meta:<name>::<mode>
<name> Wert | Unterstützt? | Fallback |
beliebige Zeichenkette | Ja |
<direction> Wert | Unterstützt? | Fallback |
A | Ja | |
D | Ja |
<mode> Wert | Unterstützt? | Fallback |
E | Ja | |
ED | Nein | E |
S | Nein | E |
SD | Nein | E |
<language> Wert | Unterstützt? | Fallback |
beliebiger ISO 639-1 code | Nein |
<case> Wert | Unterstützt? | Fallback |
D | Ja | |
U | Nein | D |
L | Nein | D |
<numeric> Wert | Unterstützt? | Fallback |
D | Nein | Y |
Y | Ja | |
F | Nein | Y |
N | Nein | Y |