Sure, you can handle it. But should you?
Let our experts manage the tech maintenance while you focus on your business.
Let our experts manage the tech maintenance while you focus on your business.
Microsoft File Connector (Legacy)
Installation und Konfiguration
Installation
Bevor der Microsoft File Connector installiert wird, muss sichergestellt werden, dass der Mindbreeze Server bereits installiert ist und dieser Connector auch in der Mindbreeze Lizenz inkludiert ist.
Benötigte Crawling-User Rechte
- Der Benutzer benötigt die “Read”-Berechtigung.
Konfiguration von Mindbreeze
Klicken sie auf “Indices” und auf das “Add new index” Symbol um einen neuen Index zu erstellen.
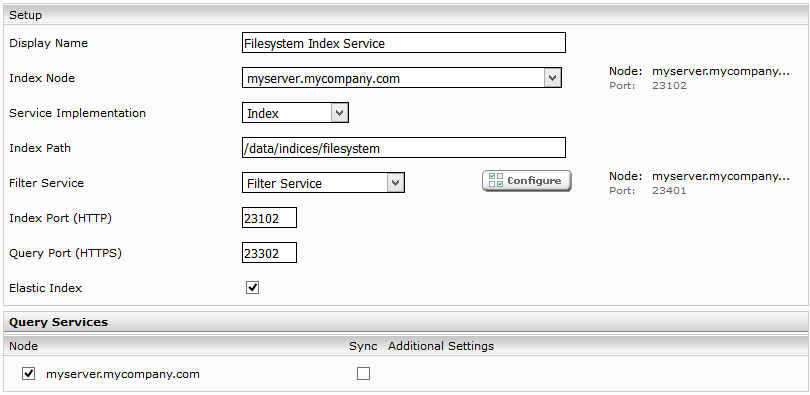
Eingabe eines neuen Index Pfades z.B, “/data/indices/fileshare ”. Falls notwendig muss der Display Name des Index Services und des zugehörigen Filter Services geändert werden.
Mit “Add new custom source” unten rechts kann eine neue Datenquelle hinzugefügt werden.

Konfiguration der Datenquelle
Die Dateisystem-Datenquelle ermöglicht Ihnen einen Ordner mit seinen Unterordnern durchsuchbar zu machen.
Zur Erstellung einer Dateisystem-Datenquelle, gehen Sie wie folgt vor:
- Klicken Sie auf das Symbol
 , es erscheint die Konfigurationsmaske für eine Dateisystem-Datenquelle.
, es erscheint die Konfigurationsmaske für eine Dateisystem-Datenquelle. - Geben Sie im Feld „Source name“ einen beliebigen Namen für diese Datenquelle ein.
- Im Feld „Access Node“ kann der Rechner ausgewählt werden, von dem aus auf die Daten dieser Datenquelle zugegriffen werden soll.
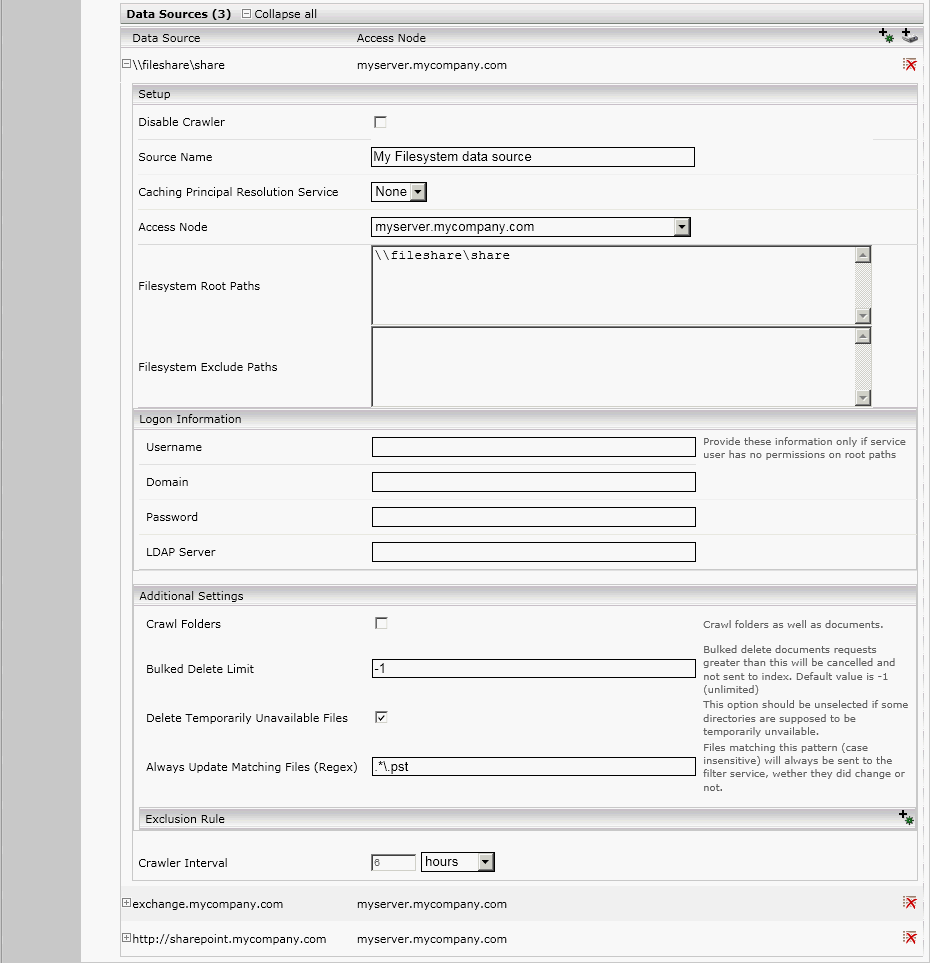
- Das Feld „Filesystem Root Path“ spezifiziert das Fileshare, das als Ausgangspunkt für die Suche nach zu indizierenden Dateien dient. Dieser Ordner und alle Unterordner werden durchsucht. Der Ordner muss von allen Rechnern, die in diesem Index suchen dürfen, erreichbar sein. Ansonsten können Suchergebnisse später nicht geöffnet werden.
- Im Unterabschnitt „Path Exclusion Rules“ können Dateisystem-Pfade ausgenommen werden, indem man eine „Exclusion Rule“ mit dem Plus-Symbol hinzufügt.
Dabei gibt es drei Möglichkeiten, Pfade auszunehmen:- Stellt man das „Format“ auf „Absolute Path“ ein, kann als „Excluded Value“ ein absoluter Pfad angegeben werden, der bei der Indizierung ausgenommen wird.
- Stellt man das „Format“ auf „Path Component“ ein, kann als „Excluded Value“ eine Pfadkomponente (Name eines Zwischenverzeichnisses oder einer Datei) angegeben werden.
- Stellt man das „Format“ auf „Regular Expression“ ein, kann als „Excluded Value“ ein regulärer Ausdruck angegeben werden, der auf den absoluten Pfad angewandt wird.
- Im Feld „Crawler Interval“ wird ein Zeitintervall angegeben, innerhalb dessen der Index seine Informationen über den Inhalt dieses Ordners und seiner Unterordner nach einem abgeschlossenen Durchlauf aktualisiert.

Um genauere, zusätzliche Einstellungen der Datenquelle durchzuführen, klicken Sie am oberen rechten Rand das Feld neben „Advanced Settings“ an.
Es erscheint folgender Konfigurationsschirm, in dem Sie folgende zusätzliche Einstellungen treffen können:

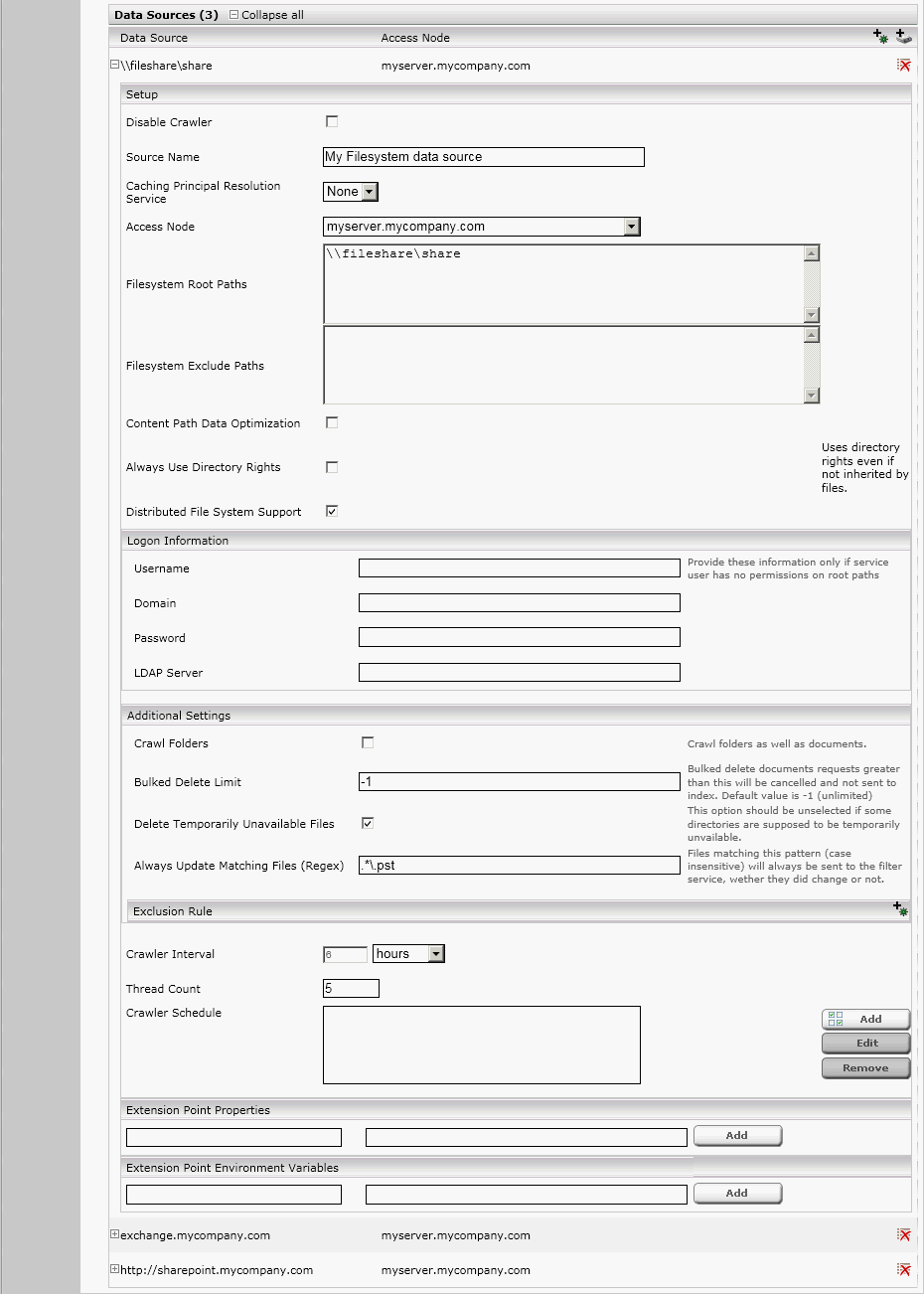
- Das Feld “Content Path Data Optimization” legt fest, ob der Dateisystem-Crawler Dateinhalte direkt an den Filter sendet oder nur Verweise (d.h. UNC-Pfade) zu den einzelnen Dateien sendet. Wenn angehakt, werden nur Referenzen übertragen, was unter Umständen die Geschwindigkeit von Crawler und Filter verbessert, aber nur funktioniert, wenn der Filter genauso wie der Crawler Zugriff auf alle Dateiverweise hat.
- Im Feld „Thread Count“ können Sie die Anzahl der parallel den weiter oben angegebenen Ordner nach Dateien durchsuchenden Threads angeben. Die Anzahl der Threads wirkt sich direkt auf die Geschwindigkeit aus, mit der der Ordner durchsucht wird. Gleichzeitig steigt mit höherer Threadanzahl die Belastung der Fileserver.
- Das Feld „Crawler Schedule“ bietet die Möglichkeit, die Zeiten, zu welchen der entsprechende Crawler laufen soll, festzulegen. Ausführlichere Informationen entnehmen Sie bitte dem Kapitel über Crawler-Zeitplanung dieses Benutzerhandbuches.
- Die Felder „Logon Information“ sind nur dann zu konfigurieren, wenn der Service Benutzer keine Lese Rechte auf den Fileshare hat. Der LDAP Server ist nur dann zu konfigurieren, wenn dieser anders sein soll als unter dem „Network Confiuration“ angegebene LDAP Server.
Um die durchgeführten Änderungen dauerhaft zu speichern drücken Sie den „Save“-Knopf rechts oben.
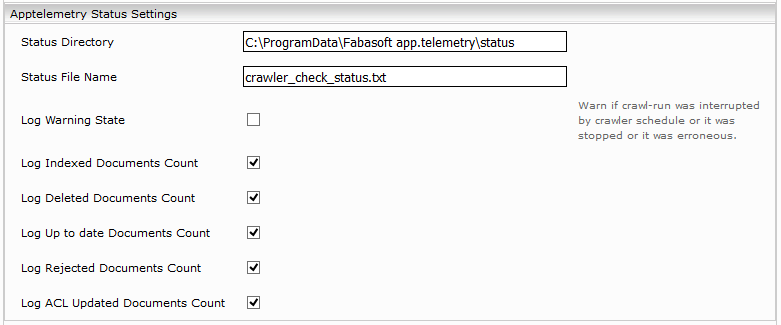
Apptelemetry Status Settings
Damit können Informationen über beendete crawling-runs für die apptelemetry in einer „Service Check Counter“ Datei zur Verfügung gestellt werden. Siehe (Service Check Konfiguration).
Service Check Konfiguration (app.telemetry)
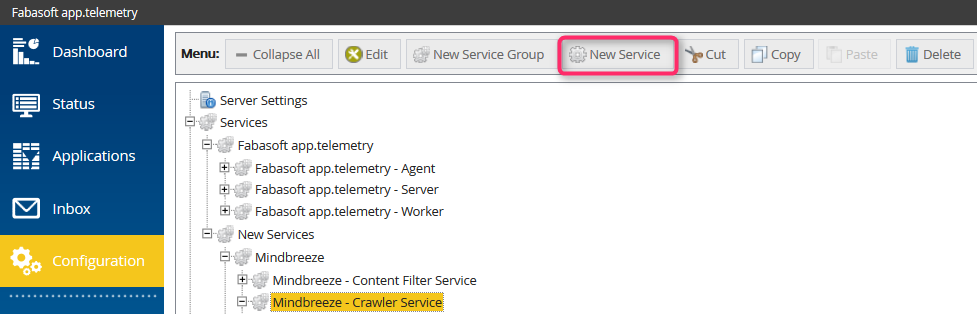
Durch die folgenden Schritte wird dem Mindbreeze Crawler Service ein Service Check hinzugefügt, es kann sich aber auch um ein neues oder ein anderes Service handeln .
- Neuen Dienst für Mindbreeze hinzufügen – Crawler Service.
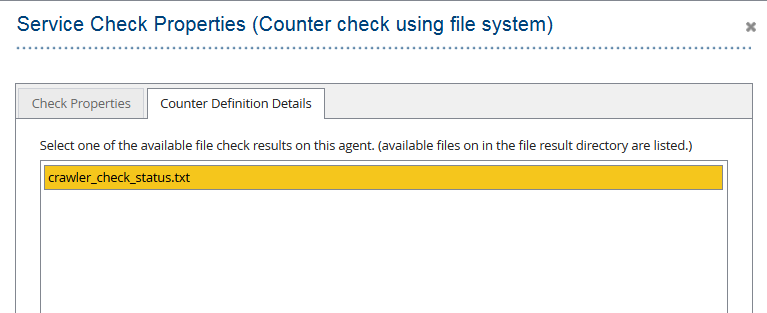
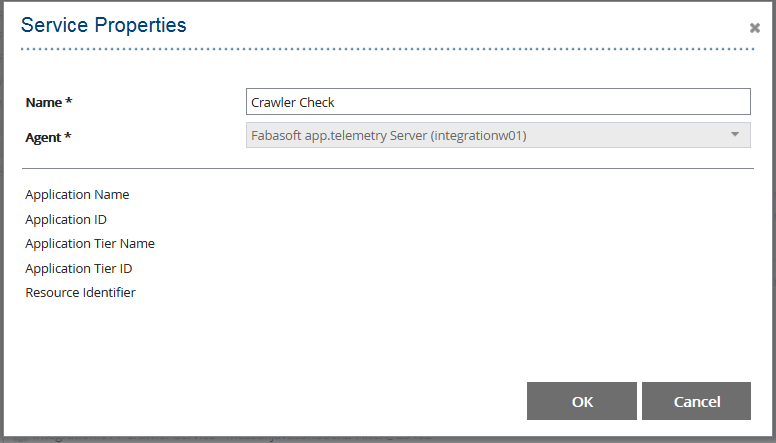
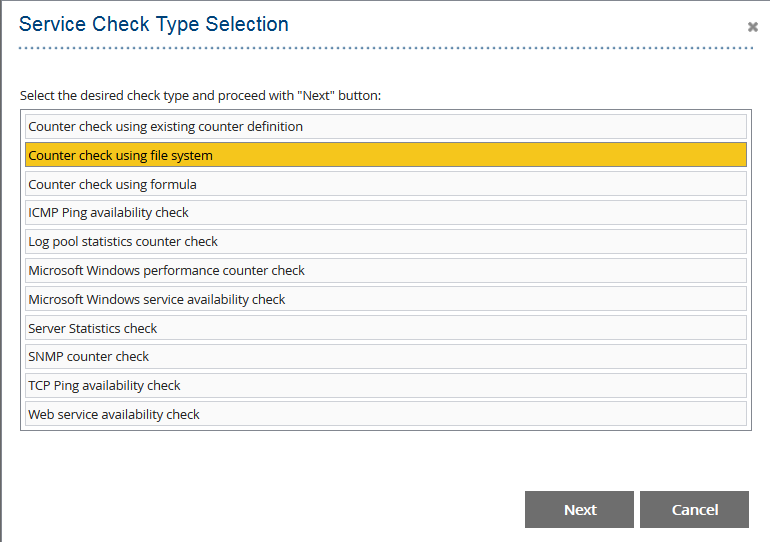
- Service Check (Counter check using file system) hinzufügen.
- Definieren Sie das Prüfintervall (z. B. 1 Stunde) und den Warngrenzwert. Ein Wert größer als 0 im Feld „Warngrenzwert“ gibt die Anzahl der Crawler an, die einen Crawl-Durchlauf nicht abschließen konnten. Es ist wichtig, dass die Prüfdatei innerhalb der Prüfintervalle regelmäßig aktualisiert wird, um einen korrekten Status zu erhalten.

- Die im “Apptelemetry Status Settings” konfigurierte Datei auswählen:
Service Check Status
- Die Spalte „Value“ gibt die Anzahl der Crawler an, die keinen vollständigen Crawl-Durchlauf durchführen konnten.
- Die Spalte „Message“ enthält die IDs der überwachten Crawler.
Beispiel für den Status erfolgreicher Crawler-Durchläufe: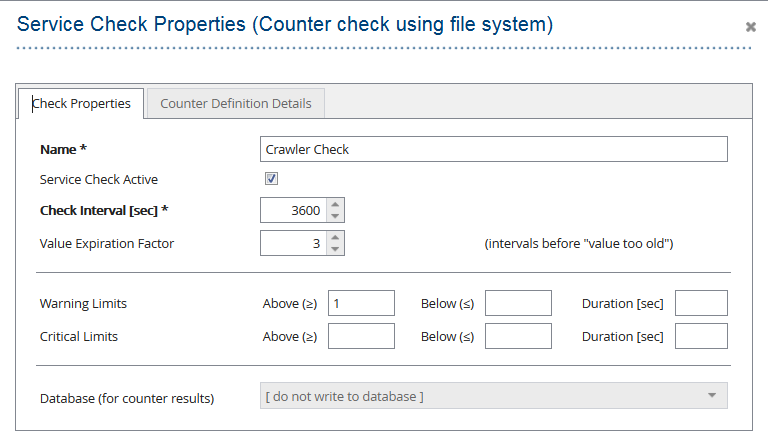
Beispiel für einen nicht erfolgreichen Crawler-Durchlauf: