
Sure, you can handle it. But should you?
Let our experts manage the tech maintenance while you focus on your business.
Let our experts manage the tech maintenance while you focus on your business.
Atlassian Jira Connector
Installation und Konfiguration
Installation
Vor der Installation des Atlassian Jira Connector muss sichergestellt werden, dass der Mindbreeze Server installiert und der Atlassian Jira Connector in der Lizenz inkludiert ist. Zur Installation oder Aktualisierung des Konnektors verwenden Sie bitte das Mindbreeze Management Center.
Konfiguration von Index und Crawler
Navigieren Sie auf den Reiter „Indices“ und klicken Sie rechts oben auf „+ Add Index“, um einen neuen Index zu erzeugen.

Fügen Sie eine neue Datenquelle durch Klick auf „Add Data Source“ rechts oben hinzu. Wählen Sie die Category „Atlassian Jira“ aus.
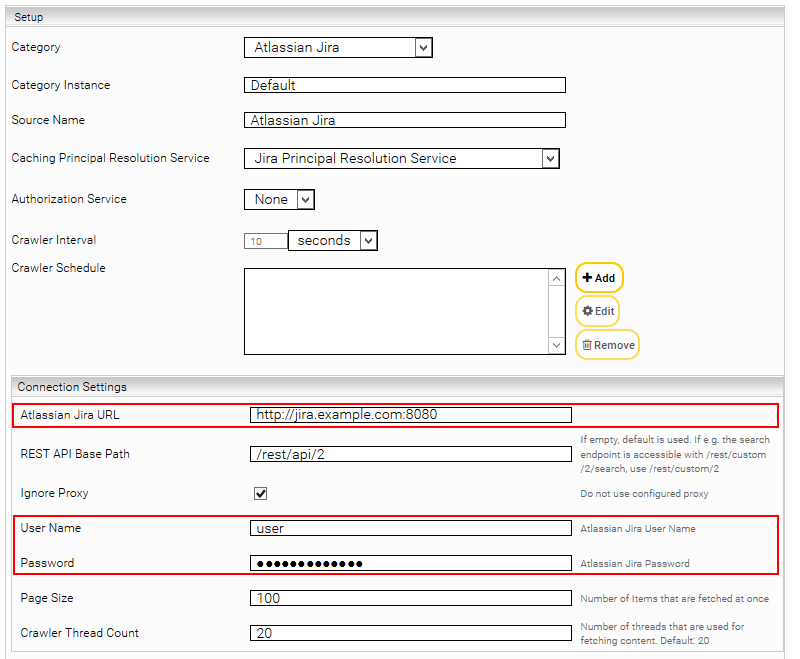
Setzen Sie folgende notwendige Einstellungen:
Benutzername eines Jira-Benutzers der Leserechte auf die REST-API besitzt. ACHTUNG: Dieser Benutzer muss dieselbe Zeitzonen Präferenz gesetzt haben, wie die Zeitzone des Jira Servers. Wenn „Disable ACLs“ gesetzt ist, können die Felder „User Name“ und „Password“ leer gelassen werden. Für weitere Informationen zu „Disable ACLs“ siehe weiter unten. | |
„Password“ | Passwort des Benutzers Wenn Sie eine Jira Cloud-Instanz indizieren möchten, muss hier stattdessen das API-Token gesetzt werden. Wie Sie diesen erstellen, erfahren Sie im nächsten Abschnitt. |
„Atlassian Jira URL“ | URL unter der die Jira REST-API erreichbar ist |
Um ein API-Token zu erstellen, gehen Sie auf https://id.atlassian.com/manage-profile/security/api-tokens und melden Sie sich mit dem Jira-Benutzer an, der für das Crawlen verwendet werden soll. Klicken Sie anschließend auf „Create API token“ um das Token zu erstellen, zu benennen und dann zu kopieren.
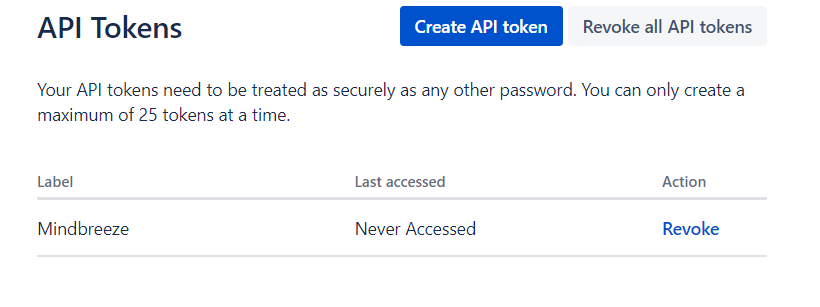
Folgende Einstellungen sind optional:
„REST API Base Path“ (Advanced Setting) | Normalerweise befindet sich die REST API auf <Atlassian Jira URL>/rest/api/2. Wenn der Pfad zu Ihrer API ein anderer als „rest/api/2“ ist, können Sie diesen hier angeben. |
„Is Cloud“ | Aktivieren Sie diese Option beim Indizieren einer Jira Cloud-Instanz. |
„Ignore Proxy“ | Verwendet keinen HTTP-Proxy, unabhängig was im „Network“-Tab konfiguriert ist. |
„Page Size“ (Advanced Setting) | Setzt die Anzahl der Elemente, die gleichzeitig abgerufen werden. Standardwert: 100 (Hinweis: höhere Werte können den Durchsatz erhöhen, erhöhen jedoch auch den Arbeitsspeicherverbrauch) |
„Crawler Thread Count“ (Advanced Setting) | Anzahl der Threads, die zum Herunterladen von Inhalten verwendet werden. Standardwert: 20 |
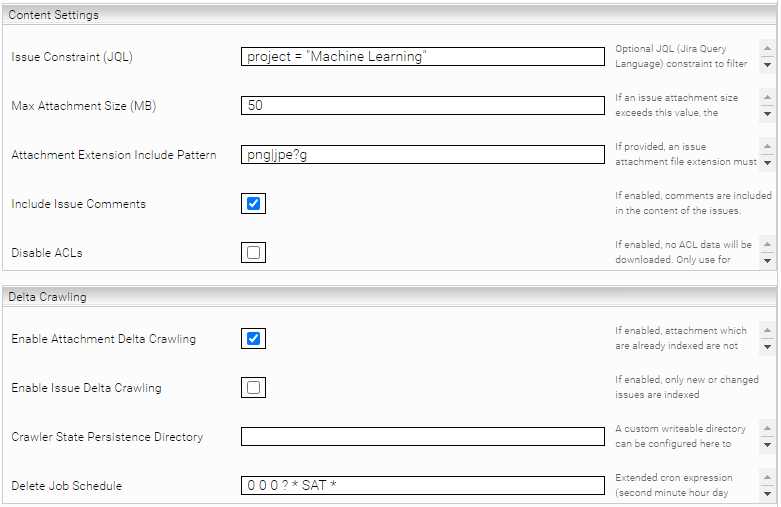
„Issue Constraint (JQL)“ | Eine JQL (Jira Query Language) Query, welche die zu crawlenden Issues einschränkt. Z.B.: project = "Machine Learning". Sie können in der Jira-Oberfläche die „Advanced Search“ verwenden, um eine passende JQL Query zu erstellen. Hier finden Sie auch die offizielle Jira-Dokumentation zur JQL Syntax. Hinweis: die Keywords „ORDER BY“ dürfen nicht verwendet werden, da dies der Crawler selbst verwendet. Eine Änderung dieser Option erfordert einen Re-Index. Standardwert: nicht gesetzt (Alle Issues werden gecrawlt) |
„Max Attachment Size (MB)“ | Wenn gesetzt, werden größere Anhänge nicht indiziert. (Hinweis: ein Wert von 0 indiziert gar keine Anhänge) |
„Attachment Extension Include Pattern“ | Wenn gesetzt, werden nur Anhänge indiziert, dessen Dateinamenerweiterungen auf diesen regulären Ausdruck matchen. (Java Regex) z.B. odt|xls|doc|docx |
„Include Issue Comments“ | Wenn gesetzt, werden Kommentare zu Issues als HTML-Content gesetzt. |
„Disable ACLs“ | Wenn gesetzt, werden keine ACL-Informationen Indiziert. Nur für öffentliche Server verwenden. Aktivieren Sie außerdem in der Index-Konfiguration die Option „Unrestricted Public Access“ (Advanced Setting) und deaktivieren Sie die Option „Enforce ACL Evaluation“. ACHTUNG: Alle Dokumente am Index sind anschließend für jeden Benutzer einsehbar) |
Im Normalfall ist diese Option nicht aktiviert und alle (Jira-)Issues, bei denen „Issue Level Security“ gesetzt ist, sind aus Sicherheitsgründen für niemanden zugänglich. Wenn diese Option aktiviert wird, werden ebenfalls alle Issues, die die Eigenschaft „Issue Level Security“ besitzen gecrawlt und die relevanten Projekt-Berechtigungen werden verwendet. ACHTUNG: Wenn Sie diese Option aktivieren, können Benutzer möglicherweise Issues sehen, die sie in Jira nicht sehen sollen. Verwenden Sie diese Option nur, wenn das für Ihren Anwendungsfall kein Problem darstellt. | |
„Issue Level Security Override“ | Die Projektrollen (eine pro Zeile), welche auf alle Issues Zugriff haben sollen, bei denen „Issue Level Security“ gesetzt ist. ACHTUNG: Wenn Sie diese Option aktivieren, können Benutzer möglicherweise Issues sehen, die sie in Jira nicht sehen sollen. Verwenden Sie diese Option nur, wenn das für Ihren Anwendungsfall kein Problem darstellt. |
Custom Metadata Mapping Path (Advanced Settings) | Der Pfad zu einer benutzerdefinierten Metadaten-Mapping-Datei. Das benutzerdefinierte Metadaten-Mapping wird, sofern konfiguriert, mit dem Standard-Mapping kombiniert und steuert, welche Metadaten für die Dokumente festgelegt werden. |
Wenn Ihre Jira Instanz eine große Menge an Daten enthält, wird empfohlen, Delta Crawling zu aktivieren:
„Enable Attachment Delta Crawling“ | Wenn aktiv, werden nur Anhänge heruntergeladen, die noch nicht indiziert worden sind |
„Enable Issue Delta Crawling“ | Wenn aktiv, werden nur neue oder geänderte Issues heruntergeladen. Issues, die in Jira gelöscht wurden, werden bei einem Delta Crawl Run nicht gelöscht. Um auch gelöschte Issues aus dem Index zu entfernen, müssen Sie einen „Delete Job Schedule“ konfigurieren (siehe Beschreibung weiter unten). |
„Crawler State Persistence Directory“ | Wenn „Enable Issue Delta Crawling“ aktiv ist, wird ein Verzeichnis benötigt, um Statusinformationen zum letzten Delta Crawl Run (oder Delete Crawl Run) abzulegen. Wenn kein Verzeichnis angegeben wird, werden diese Statusinformationen standardmäßig in „/data/servicedata/<service-id>“ abgelegt. |
„Delete Job Schedule“ | Wenn „Enable Issue Delta Crawling“ aktiv ist, wird empfohlen, hier eine Extended Cron Expression anzugeben (eine Dokumentation und Beispiele zu den cron expressions finden Sie hier). Wird der Cron Job getriggert, wird direkt nach dem nächsten Delta Crawl Run ein Delete Crawl Run gestartet, um Issues und Attachments zu löschen, die nicht mehr in Jira vorhanden sind. Bitte beachten Sie, dass ein Delete Crawl Run bei großen Datenmengen sehr lange dauern kann. |
Speichern Sie anschließend die Konfiguration und starten Sie neu.
Konfiguration des Principal Resolution Service
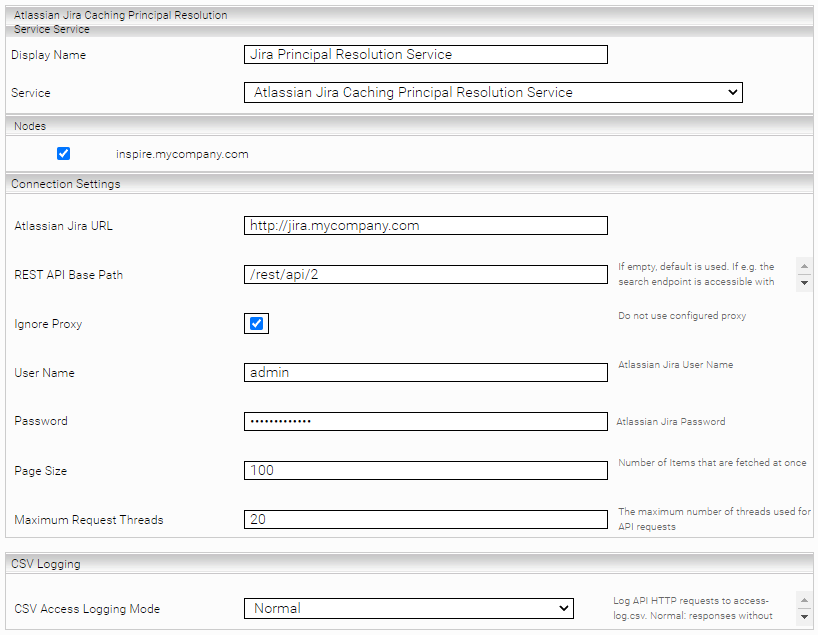
Wählen Sie im neuen oder bestehenden Service in der Einstellung „Service“ die Option Atlassian Jira Caching Principal Resolution Service aus. Für mehr Informationen über das Erstellen, das grundlegende Konfigurieren eines Cache für einen Principal Resolution Service und weitere Konfigurationsoptionen, siehe Installation & Konfiguration - Caching Principal Resolution Service.
Setzen Sie folgende notwendige Einstellungen:
„User Name“ | Benutzername eines Jira-Benutzers der Leserechte auf die REST-API besitzt. |
„Password“ | Passwort des Benutzers |
„Atlassian Jira URL“ | URL unter der die Jira REST-API erreichbar ist |
Folgende Einstellungen sind optional:
„REST API Base Path“ (Advanced Setting) | Normalerweise befindet sich die REST API auf <Atlassian Jira URL>/rest/api/2. Wenn der Pfad zu Ihrer API ein anderer als „rest/api/2“ ist, können Sie diesen hier angeben. | ||||||
Aktivieren Sie diese Einstellung beim Indizieren einer Jira Cloud-Instanz. | |||||||
„Ignore Proxy“ | Verwendet keinen HTTP-Proxy, unabhängig was im „Network“-Tab konfiguriert ist. | ||||||
„Page Size“ (Advanced Setting) | Setzt die Anzahl der Elemente, die gleichzeitig abgerufen werden. Standardwert: 100 (Hinweis: höhere Werte können den Durchsatz erhöhen, erhöhen jedoch auch den Arbeitsspeicherverbrauch) | ||||||
„Maximum Request Threads“ | Die maximale Anzahl von Threads, die für Jira API-Anfragen verwendet werden. Ein höherer Wert kann die Cache-Update-Dauer verkürzen, führt jedoch zu einer höheren Last am Jira-Server. | ||||||
„CSV Access Logging Mode“ | HTTP Anfragen zur Jira API werden in access-log.csv im Log-Verzeichnis protokolliert. Mit dieser Option kann gesteuert werden, wie detailliert diese protokolliert werden. Folgende Auswahlmöglichkeiten stehen zur Verfügung:
|
Standardmäßig indizierte Metadaten
Standardmäßig werden die folgenden Jira Felder pro Issue heruntergeladen und zu Metadaten konvertiert:
Jira Feld Name | Anmerkungen |
Zusammenfassung | Der Titel (“Zusammenfassung”) des Jira Issue. Wird als Titel des Mindbreeze Dokuments verwendet. |
Erstellt Aktualisiert | Die Jira Felder “Erstellt” und „Aktualisiert“. Werden als Erstellungs- und als Änderungsdatum für das indizierte Mindbreeze Dokument verwendet. |
Beschreibung Kommentare | Diese Jira Felder werden für den Dokumenteninhalt verwendet. Die Kommentare werden nur indiziert, wenn sie in der Crawler-Konfiguration aktiviert sind. |
Typ | - |
Priorität | - |
Stichwörter | - |
Komponente(n) | - |
Status | - |
Ersteller Autor Bearbeiter | - - - |
Lösungsversion(en) betrifft Version(en) | - |
Projekt | - |
Anhänge | Wird als eigener Dokumententyp indiziert. |
Wenn weitere Jira Felder indiziert, heruntergeladen und eventuell zu Metadaten konvertiert werden sollen, befolgen Sie die Anweisungen in Konfiguration - Jira Connector.
Indizierung von benutzerdefinierten Metadaten
Überblick
JIRA ermöglicht es seinen Nutzern, benutzerdefinierte Felder zu erstellen, sie in der Benutzeroberfläche anzuzeigen und diesen Feldern Werte zuzuweisen, entweder beim Erstellen oder Bearbeiten von Issues.
In manchen Fällen möchten Sie die Werte dieser Felder als Metadaten in den indizierten Issues in Mindbreeze InSpire haben. Dies ist mit den folgenden Schritten möglich:
- Ermitteln Sie den eindeutigen Bezeichner der benutzerdefinierten Felder in JIRA (siehe Auffinden der Feld-ID von benutzerdefinierten JIRA-Feldern)
- Erstellen Sie eine YAML-Datei für benutzerdefiniertes Metadaten-Mapping
- In den meisten Fällen müssen Sie hier nur den eindeutigen Bezeichner (Feld-ID) im Abschnitt „indexedFields“ angeben. Mehr Informationen zum Format des Metadaten-Mappings und dem Abschnitt „indexedFieldsr“ finden Sie im Kapitel Benutzerdefiniertes Metadaten-Mapping.
- Das Ergebnis dieses Schrittes sollte eine YAML-Datei sein, wie zum Beispiel customMetadataMapping.yaml .
- Laden Sie das benutzerdefinierte Mapping auf Mindbreeze InSpire hoch
- Dies kann im Mindbreeze InSpire Management Center im Menüpunkt "File Manager" ausgeführt werden. Zum Beispiel im Ordner /data/resources/mapping (existiert standartmäßig nicht).:

- Konfigurieren Sie den JIRA-Crawler
- Erstellen Sie einen JIRA Crawler und passen Sie die Konfiguration an Ihre Bedürfnisse an. Mehr Informationen über die Konfiguration des Index und Crawlers finden Sie im Kapitel Konfiguration von Index und Crawler.
- Setzen Sie zusätzlich bei der Konfiguration die erweiterte Einstellung "Custom Metadata Mapping Path" auf beispielsweise /data/resources/mapping/customMetadataMapping.yaml.
Achtung: Die Angabe eines benutzerdefinierten Metadaten-Mapping setzt das Standard-Mapping NICHT außer Kraft. Vielmehr erweitert sie das Standard-Mapping.
Auffinden der Feld-ID von benutzerdefinierten JIRA-Feldern
Es gibt zwei Möglichkeiten, die Feld-ID eines benutzerdefinierten JIRA-Feldes aufzufinden. Entweder über die JIRA-GUI oder über die Mindbreeze Crawler Logs.
JIRA-GUI
Öffnen Sie die Jira Administration und klicken Sie auf den Menüpunkt „Issues“.
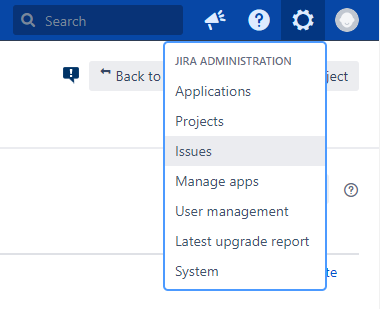
Auf der linken Seite, klicken Sie auf den Menüpunkt „Custom Fields“.
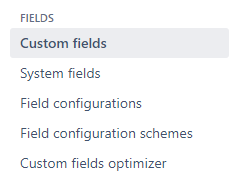
Gehen Sie anschließend auf das gewünschte Feld und klicken Sie auf "Configure".

Sie finden die Field-ID in der URL der Website.
![]()
Die vollständige Field-ID für dieses Feld lautet „customfield_10601“.
Mindbreeze Crawler Logs
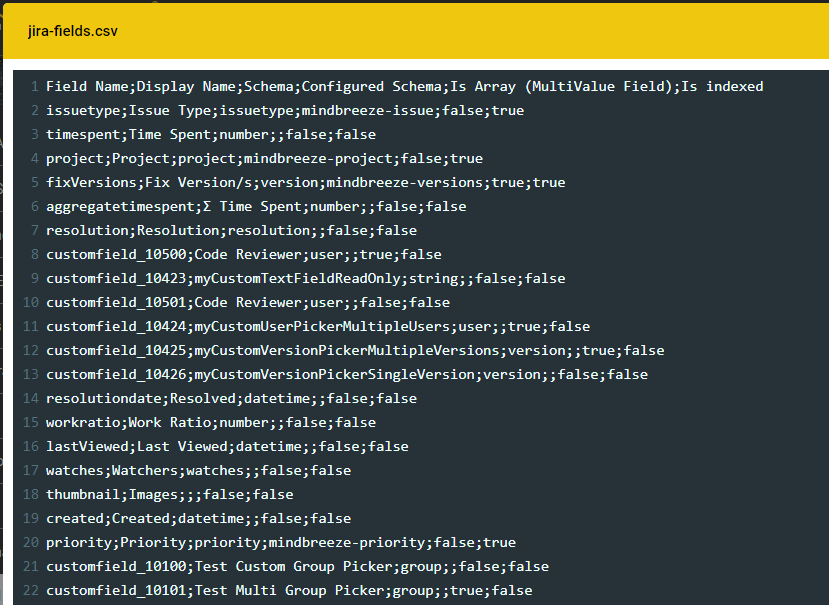
Die Field-ID kann auch im Crawler-Log-Verzeichnis in Mindbreeze aufgefunden werden. Dort ist die Datei jira-fields.csv zu finden, die einen Überblick über alle JIRA-Felder gibt.
Die folgenden Informationen sind dort zu finden:
- Field-ID
- Anzeigename (in JIRA)
- Schema (laut JIRA)
- Konfiguriertes Schema (laut dem Standard- und dem benutzerdefinierten Metadaten-Mapping)
- Einen oder mehrere Werte im Feld
- Ist das Feld derzeit so konfiguriert, dass es indiziert wird (Metadaten werden extrahiert) oder nicht?
Benutzerdefiniertes Metadaten-Mapping
Überblick
Das Metadaten-Mapping wird im YAML-Format definiert und besteht aus 2 Hauptabschnitten - den Schemata und den indexedFields.
Das Metadaten-Mapping beschreibt, welche Felder indiziert werden sollen (Abschnitt "indexedFields") und wie diese Metadaten erstellt werden sollen (Abschnitt "schemas").
Da alle JIRA-Feldtypen (JIRA-Schemata) bereits im Standard Metadaten-Mapping vordefiniert sind und das benötigte Schema für ein JIRA-Feld automatisch erkannt werden kann, ist es in den meisten Anwendungsfällen ausreichend, nur das indizierte Feld anzugeben, wie im Kapitel Automatische Schema-Erkennung dargestellt. Dies muss im Abschnitt indexedFields durchgeführt werden. Siehe dazu das Kapitel Vollständiges Beispiel für ein komplettes mapping.yaml.
IndexedFields
Ein indiziertes Feld spezifiziert ein JIRA-Feld, aus dem Metadaten generiert werden sollen und welches Schema verwendet werden soll.
Ein indiziertes Feld besteht immer aus der Field-ID und optional aus zusätzlichen Attributen.
Achtung: In den meisten Fällen ist die Angabe von optionalen Attributen nicht notwendig. Die wichtigen Attribute (schema, metadataBaseName und multiValueField) werden automatisch von JIRA abgefragt.
Optionale Attribute
schema | string | Legt das Schema fest, das für die Verarbeitung des Feldes verwendet werden soll. |
metadataBaseName | string | Gibt den Basisnamen (Basispräfix) für die erstellten Metadaten an. Wenn dieses Attribut gesetzt ist, wird dieser Name verwendet. Andernfalls wird der JIRA-Anzeigename des Feldes in „Snake Case“ (Kleinbuchstaben mit Unterstrich statt Leerzeichen) umgewandelt und als Basisname verwendet. Wenn aus irgendeinem Grund der Anzeigename für dieses Feld nicht abgerufen werden kann und kein metadataBaseName angegeben ist, wird die Field-ID als Basisname verwendet. |
customNameDelimiter | string | Legt das Trennzeichen fest, das bei der Erstellung hierarchischer (mit Präfix versehener) Metadatennamen verwendet wird. Standardwert: "_" . |
multiValueField | boolean | Gibt an, ob dieses Feld ein Array ist. Dies kann verwendet werden, wenn ein Schema, das für ein einwertiges Feld vorgesehen ist, auch für ein mehrwertiges Feld verwendet wird. Standardwert: “False”. |
ignoreField | boolean | Gibt an, ob dieses Feld ignoriert werden soll. Dies hat zur Folge, dass keine Metadaten für dieses Feld extrahiert werden. Dies kann verwendet werden, um die Erstellung von Metadaten für Felder zu überspringen, die im Standard-Metadaten-Mapping angegeben sind. |
Beispiele
Automatische Schema-Erkennung
Aufgabe: In Ihrem JIRA-Setup haben Sie einen benutzerdefinierten Multi-User-Picker mit der Field-ID „customfield_10401“ und dem Anzeigenamen "Involved People". Aus diesem Feld sollen Metadaten extrahiert werden.
Das folgende Field-Mapping würde den Zweck erfüllen:
customfield_10401: {}
Mit dieser Angabe würde der Crawler über das JIRA-Fields-Endpoint automatisch herausfinden, dass das konfigurierte Feld ein mehrwertiges Feld mit dem Schema "user" und dem Metadaten-Basisnamen "involved_people" ist. In diesem Fall muss das "user"-Schema nicht manuell angegeben werden, da fast alle JIRA-Standardschemata bereits im Standard Metadaten-Mapping definiert sind.
Wenn der Metadaten-Basisname "involved_people" nicht erwünscht ist, kann über die folgende Konfiguration ein anderer Name angegeben werden:
customfield_10401:
metadataBaseName: 'my_custom_base_name'
Achtung: Das Schema muss nicht angegeben werden.
Mehrwertfeld
Aufgabe: Sie möchten für das Feld "Involved People" ein anderes Schema als das Standard-Benutzerschema verwenden. Um dies zu erreichen, muss das Schema manuell angegeben werden. Wenn ein Schema manuell angegeben wird, muss auch das Attribut "multiValueField" manuell angegeben werden:
customfield_10401:
schema: 'my-custom-user-schema'
multiValueField: True
4.3.2.2.3 Feld ignorieren
Aufgabe: Mindbreeze gibt das Feld "reporter" standardmäßig als indiziertes Feld an. Dies wollen Sie vermeiden, da diese Metadaten nicht benötigt werden (nur im Beispiel).
Um dies zu erreichen, muss das Feld in der benutzerdefinierten Konfiguration auf „ignorieren“ gesetzt werden:
reporter:
ignoreField: True
Schemata
Schemas beschreiben, wie verschiedene JIRA-Felder (aus der API im JSON-Format) behandelt werden sollen, welche Eigenschaften (JSON-Keys) es gibt und wie man daraus Metadaten erstellt. Ein Schema besteht aus einer Eigenschaftsdefinition, die verschiedene Attribute haben kann. Diese Attribute werden im folgenden Kapitel beschrieben.
Eigenschaftsdefinition
property | string | Definiert einen Key in einem JSON. In dem JSON {"demo_key": "demo_value"} wäre "demo_key" das „property“. |
name | string | Gibt den Namen der aktuellen Eigenschaft an. Der definierte Name wird bei der Erstellung des Metadatennamens verwendet. Wird kein Name angegeben, so wird der Name (=Key) der Eigenschaft (siehe Reihe “property”) als Name verwendet. |
searchable | boolean | Gibt an, ob ein Metadatenwert durchsuchbar sein soll oder nicht. Dieses Attribut wird nur wirksam, wenn eine Eigenschaft keine verschachtelten Untereigenschaften hat. Andernfalls wird es ignoriert. Standardwert: True. |
multiValue | boolean | Gibt an, ob die aktuelle Eigenschaft ein Array ist. Standardwert: False. |
prefixName | boolean | Gibt an, ob der Name eines extrahierten Metadatums hierarchisch vorangestellt werden soll oder ob der Name des Metadatums nur der Eigenschaftsname sein soll. Standardwert: True. |
parsingStrategy | enum value | Gibt an, ob und wie eine Eigenschaft geparst werden soll. Wird nichts angegeben, ist der Wert der resultierenden Metadaten vom Typ String. Dieses Attribut wird nur wirksam, wenn eine Eigenschaft keine verschachtelten Untereigenschaften hat. Andernfalls wird es ignoriert. Mögliche Werte:
|
properties | nested (array) property definitions | Beim Umgang mit einem JSON-Objekt legen die Eigenschaften fest, wie das Objekt behandelt werden soll und welche Untereigenschaften extrahiert werden sollen. |
Beispiele
Um die Beispiele leichter zu verstehen, betrachten wir zunächst das folgende benutzerdefinierte JIRA-Feld. Angenommen, Sie haben ein benutzerdefiniertes Feld namens "Code Reviewer" erstellt, das ein "SingleUserPicker" ist.

Wenn die JSON-Datei von Mindbreeze abgerufen wird, sieht das Feld mit seinem Wert (der einen einzelnen Benutzer darstellt) wie folgt aus (beachten Sie, dass der Name der ID dieses benutzerdefinierten Feldes von JIRA erstellt wird. In diesem Beispiel lautet die ID "customfield_10413"):
"self": "http://jira.url/rest/api/2/user?username=john.doe",
"name": "john.doe",
"key": "john.doe",
"emailAddress": "john.doe@email.com",
"avatarUrls": {
"48x48": "http://jira.url/secure/useravatar?avatarId=10122",
"24x24": "http://jira.url /secure/useravatar?size=small&avatarId=10122",
"16x16": "http://jira.url/secure/useravatar?size=xsmall&avatarId=10122",
"32x32": "http://jira.url/secure/useravatar?size=medium&avatarId=10122"
},
"displayName": "John Doe",
"active": true,
"timeZone": "Europe/Vienna"
}
Beispiel eines einfachen Benutzerschemas
Aufgabe: Erzeugung von Metadaten für die Werte "displayName", "emailAddress" und "key". Zusätzlich sollen die Namen der Metadaten leicht abgeändert werden.
Dazu muss das Schema wie folgt aussehen (das Standardschema, wenn ein Feld des Typs „user“ angetroffen wird):
properties:
- property: 'displayName'
name: 'name'
- property: 'emailAddress'
name: 'email'
- property: 'key'
Zunächst wird der Name des Schemas definiert, in diesem Fall lautet der Name „my-user-schema“. Der Wert eines Schemas ist bereits eine Eigenschaftsdefinition. Daher können alle in der Tabelle definierten Attribute hier verwendet werden.
Da der Wert von customfield_10413 ein (JSON-)Objekt ist, müssen die Untereigenschaften dieses Objekts definiert werden.
In dem gezeigten Beispiel sind die gewünschten Eigenschaften:
- displayName (der Name ist überschrieben zu name)
- emailAddress (der Name wird überschrieben mit email)
- key
Da für keine dieser Eigenschaften andere Attribute angegeben sind (zum Beispiel „prefixName“ oder „parsingStrategy“), würden die resultierenden Metadaten wie folgt aussehen:
Name | Datentyp | Wert |
code_reviewer_name | string | John Doe |
code_reviewer_email | string | john.doe@email.com |
code_reviewer_key | string | john.doe |
Beispiel eines erweiterten Benutzerschemas
Aufgabe: Erzeugung von Metadaten für die Werte "displayName", "emailAddress" und "key". Zusätzlich sollen die Namen der Metadaten leicht abgeändert werden. Des Weiteren soll ein Metadatum für die Avatar-URL in der Größe 48 x 48 Pixel erstellt werden und es soll nicht suchbar sein. Damit es nicht gefunden wird, wenn zum Beispiel nach der Zahl "10122" gesucht wird.
Das folgende Schema erfüllt diese Aufgabe:
properties:
- property: 'displayName'
name: 'name'
- property: 'emailAddress'
name: 'email'
- property: 'key'
- property: 'avatarUrls'
properties:
- property: '48x48'
searchable: False
Da das avatarUrls in der JSON-Datei auch ein Objekt als Wert hat, müssen die Untereigenschaften dieses Objekts wiederum über das Attribut properties definiert werden.
Die resultierenden Metadaten werden wie folgt aussehen:
Name | Datentyp | Wert |
code_reviewer_name | string | John Doe |
code_reviewer_email | string | john.doe@email.com |
code_reviewer_key | string | john.doe |
code_reviewer_avatarUrls_48x48 | string | http://jira.url/secure/useravatar?avatarId=10122 |
Wenn der Name code_reviewer_avatar_url und nicht code_reviewer_avatarUrls_48x48 lauten soll, kann die Eigenschaft wie folgt angegeben werden:
name: ''# when creating the hierarchical name, empty names are skipped
properties:
- property: '48x48'
name: 'avatar_url'
searchable: False
Eine andere Möglichkeit, dies zu erreichen, wäre die Verwendung der folgenden Methode:
- property: 'avatarUrls'
properties:
- property: '48x48'
name: 'code_reviewer_avatar_url'
prefixName: False # defines that this name should not be prefixed
searchable: False
Achtung: Diese Methode wird nicht empfohlen, da dieses Schema nur in Kombination mit einem „Code Reviewer“ Feld Sinn macht und nicht mit zum Beispiel „SingleUserPicker“. Außerdem kann es bei dieser Methode leichter zu Namenskonflikten kommen.
Vollständiges Beispiel
Aufgabe:
- Hinzufügen der Avatar-URL für alle standardmäßig indizierten Benutzer-Metadaten.
- Hinzufügen eines benutzerdefinierten Schemas, das ein Datumsfeld nicht in einen Kalender-Metadatum umwandelt, sondern den Wert direkt als String hinzufügt und dieses Schema für einen benutzerdefinierten JIRA-Date-Picker-Feld verwendet.
- Hinzufügen des JIRA-Felds „betrifft Version(en)“ als neues Metadatum.
- Das Metadatum (Feld) "reporter" ignorieren.
Avatar-URL für Benutzer hinzufügen
Um dies zu erreichen, muss das Schema "mindbreeze-user" überschrieben werden. Dieses Schema ist das Standardschema für die Felder "reporter", "assignee" und "creator".
Dazu muss zunächst eine Kopie des Standardschemas erstellt werden, um keine bereits vorhandenen Metadaten zu verlieren. Dann muss die Eigenschaft "avatarUrls" mit ihrer Untereigenschaft "48x48" zum Schema hinzugefügt werden, um die URL für die größte verfügbare Avatar-URL zu erhalten. Falls gewünscht, können auch die Namen angepasst werden.
Das Schema sollte folgendermaßen aussehen:
properties:
- property: 'displayName'
name: 'name'
- property: 'key'
- property: 'emailAddress'
name: 'email'
- property: 'avatarUrls'
name: ''
properties:
- property: '48x48'
name: '_avatar_url'
Neues Schema für ein von Menschen lesbares Datum
Das Standardschema für Felder vom Typ "date" sieht wie folgt aus:
date:
parsingStrategy: TO_CALENDAR
Das Ziel besteht nun darin, den Parsing-Schritt zu vermeiden. Dies kann leicht erreicht werden, indem keine Parsing-Strategie angegeben wird. Das neue Schema sollte wie folgt aussehen:
string_date: {}
Das Schema kann nun für Datumsfelder (z. B. benutzerdefinierte Date-Picker Felder) verwendet werden:
customfield_10401: # example custom date picker field
schema: 'string_date'
Das Feld "reporter" ignorieren
Wie in einem früheren Beispiel gezeigt, kann dies mit einer einfachen Feldspezifikation erreicht werden:
reporter:
ignoreField: True
Hinzufügen des Feldes "Affects Version/s"
Die Feld-ID für dieses Feld ist "versions", da das von JIRA definierte Standardschema sowie der Anzeigename ausreichen. Geben Sie das Feld "versions" einfach in den indexedFields an.
versions: {}
Da die JIRA-Namen (Anzeigenamen wie in der JIRA-Benutzeroberfläche angezeigt) in Groß- und Kleinschreibung umgewandelt werden, wenn sie als Metadatennamen verwendet werden, wird den endgültigen Metadaten das Präfix "affects_versions" vorangestellt (Sonderzeichen, wie in diesem Fall „/“, werden ebenfalls entfernt).
Abschließendes Mapping
Wenn alles zusammengefügt ist, sollte das abschließende Mapping der benutzerdefinierten Metadaten wie folgt aussehen:
schemas:
string_date: {}
mindbreeze-user:
properties:
- property: 'displayName'
name: 'name'
- property: 'key'
- property: 'emailAddress'
name: 'email'
- property: 'avatarUrls'
name: ''
properties:
- property: '16x16'
name: '_avatar_url'
indexedFields:
versions: {}
customfield_10401:
schema: 'string_date'
reporter:
ignoreField: True
Auswirkungen einer benutzerdefinierten Mapping-Konfiguration anzeigen
Die Crawler Log-Dateien geben einen Überblick über die Auswirkungen der benutzerdefinierten Mapping-Konfiguration beim Start:
Found custom metadata mapping at: '/data/resources/mapping/metadataMapping.yaml'. This will have the following effects:
- Schemas:
- Newly added:
- string_date
- Overridden:
- mindbreeze-user
- Indexed Fields:
- Newly added:
- customfield_10401
- versions
- Ignored (removed):
- reporter
Appendix
Einschränkungen
- Jira Permission Schemes mit “Group custom field value” in den “Browse projects” Permission werden nicht unterstützt.
- Jira Issue-Level Security wird nicht unterstützt. Jira Issues mit gesetztem Security Level können in der Suche nicht gefunden werden, wenn ACLs aktiviert sind.
- Damit der Principal Resolution Service für einen Benutzer die jeweiligen Projekt-Rollen oder Gruppen auflösen kann, muss die E-Mail-Adresse des Benutzers öffentlich sichtbar sein. Sie können das hier konfigurieren. Setzen Sie dafür die Spalte „Wer kann das sehen?“ auf „Jeder“ für die E-Mail-Adresse des Benutzers..
Troubleshooting
“ERROR: CrawlRun was unsuccessful” mit URL Pfad “/search” und “status code 400”
Höchstwahrscheinlich ist ein "Issue Constraint (JQL)" konfiguriert, welche den Fehler verursacht
- Überprüfen Sie die konfigurierte "Issue Constraint (JQL)" mithilfe der Funktion "Advanced Search" in Jira direkt. Die JQL muss jedenfalls innerhalb von Jira funktionieren.
- Prüfen Sie, ob es in der JQL keine unerlaubten Schlüsselwörter gibt, wie z.B. "ORDER BY". Entfernen Sie diese Schlüsselwörter.
- Der Crawler verwendet nicht die eingegebene JQL direkt, sondern transformiert diese noch, bevor damit Jira-API-Requests durchgeführt werden. Die eingegebene JQL wird in Klammern gesetzt und es werden noch weitere Einschränkungen und Sortierungen durchgeführt. Die transformierte JQL wird dann als URL-Parameter bei den Jira-API-Requests übergeben. In der Fehlermeldung wird dann die effektive URL angezeigt.
Z.B.: https://jira.myorganization.com/ rest/api/2/search?jql=%28proect+%3D+%22Big+Data%22%29+AND+updated+%3E%3D+%272020-06-17+17%3A10%27+ORDER+BY+updated+ASC&startAt=100&maxResults=100&fields=key,updated,description...
Dies entspricht decodiert z.B. der effektiven JQL: (proect = \"Big Data\") AND updated >= '2020-06-17 17:10' ORDER BY updated ASC
Wenn Sie die effektive URL aus der Fehlermeldung in einem Browser aufrufen, bekommen Sie eine detaillierte Fehlermeldung, was genau mit der effektiven JQL nicht stimmt. Z.B.: "Field 'proect' does not exist or you do not have permission to view it."
Crawl-Run wird nicht abgeschlossen oder gewisse Issues wurden nicht indiziert
Wenn die Zeitzonenpräferenz des Benutzers der zum Crawlen verwendet wird und dem Jira Server unterschiedlich sind, kann es zu verschiedenen Fehlern kommen. Zum Beispiel ist es möglich, dass der Crawl-Run nie fertiggestellt wird oder gewisse Issues übersprungen werden.
Den ersteren Fall kann man erkennen, indem man das Log des Crawlers überprüft. Wenn immer wieder dieselben URLs aufgerufen werden, kann der Grund dafür an der Zeitzone des Benutzers liegen.
Deshalb sollte immer sichergestellt werden, dass die Zeitzone des Users mit der des Servers übereinstimmt. Diese kann im Profil des Users eingestellt werden.
Ein Benutzer findet zu wenige Dokumente und das Kommando ‚checkprincipals‘ gegen den Principal Resolution Service liefert keine Projektrollen oder Gruppen zurück
Wie in Abschnitt 4.1 Einschränkungen beschrieben, kann der Principal Resolution Service die Projektrollen oder Gruppen von Benutzern nur auflösen, wenn deren Email Adresse öffentlich sichtbar ist. Sie können das hier konfigurieren. Setzen Sie dafür die Spalte „Wer kann das sehen?“ auf „Jeder“ für die E-Mail-Adresse des Benutzers.