
Sure, you can handle it. But should you?
Let our experts manage the tech maintenance while you focus on your business.
Let our experts manage the tech maintenance while you focus on your business.
Entity Recognition
Konfiguration
Einführung
Dieses Dokument beschäftigt sich mit dem Konzept, dem Setup und den Troubleshooting Methoden für die Konfiguration von Entity Recogntition.
Konfiguration Entity Recognition
In diesem Kapitel wird das Konzept von Entity Recognition anhand eines einfachen Beispiels erklärt.
Führen Sie zum Einrichten folgende Schritte durch:
- Verbinden Sie sich zum Management Center
- Navigieren Sie zu jenem Index, den Sie mit Entity Recognition konfigurieren möchten.
- Aktivieren Sie die Advanced Settings und öffnen Sie diesen
- Suchen Sie nach der Einstellung "Entity Recognition Parameter" im Management Center
- Definieren Sie ihre Entity Recognition Regeln im Feld pattern-rules, die Ihrem Metadatum matchen sollen.
- Folgende Regelformate werden unterstützt: https://github.com/google/re2/wiki/Syntax
- In unserem konkreten Beispiel:
rule=/\// digits /\//.
digits=/\d+/.
Erklärung
Die erste Regel definiert, dass alle Zahlen zwischen zwei slashes matchen sollen (Regex).:
Beispiel: test/1234test1234/test/543/test (543 wird extrahiert) - Fügen Sie nun eine neue Metadata-Definition hinzu um die Regeln für Metadaten anzuwenden
- In diesem Beispiel sucht Mindbreeze im String des existierenden Metadatums In the "fullstring nach Zahlen zwischen 2 Slashes. Sind Zahlen zwischen 2 Slashes vorhanden, dann nimmt Mindbreeze den Teil der Matches heraus der in der Subregel „digits" konfiguriert ist und schreibt diesen als String in das neue Metadataum „myextractedVal“.
Beispiel:
fullstring: xyz/1234/herbert543/345test
Match der Regel “rule”: /1234/
Wert der Regel “digits”: 1234
Wert des Metadataums myextractedVal==1234
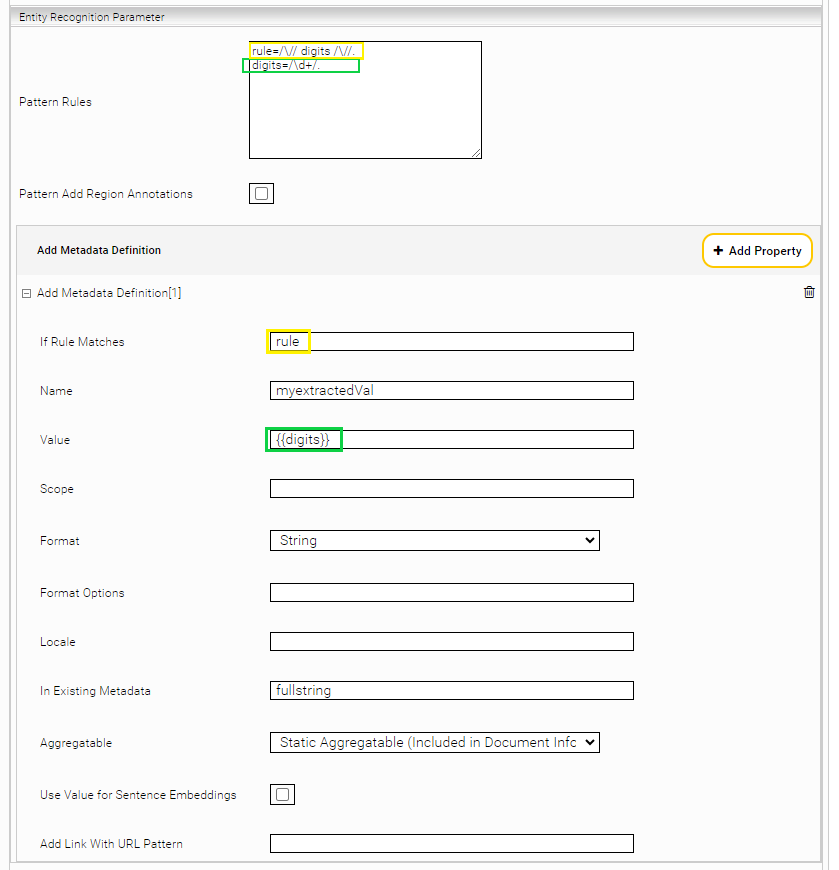
Entity Recognition Parameter
Die Konfiguration der Parameter für die Entity Recogniton ermöglicht es dem Index Service, Metadaten aus den Dokumentinhalten zu extrahieren. Die folgenden Einstellungen sind verfügbar:
Einstellung | Beschreibung |
Pattern Rules | Definiert eine Reihe von Regeln, die bei der Extraktion von Metadaten angewendet werden. Die Regeln werden mit einem Regex-Muster definiert. Bitte beachten Sie, dass die regulären Ausdrücke ebenfalls mit einem "/" umschlossen sein müssen. |
Pattern Add Region Annotations | Fügt den Wert der Einstellung "Link HREF-Muster verwenden" zur Annotation hinzu. |
Process HTML Attributes | Ermöglicht der Entity Recognition auch innerhalb von Link-Referenzen zu suchen. Wie <a href=link zu suchen.> Link </a> im HTML-Quelltext. |
HTML Attribute Name Pattern | Legt fest, welche Attributnamen durchsuchbar sein sollen. Es wird mit einem Regex-Muster definiert. In den meisten Fällen ist ein "href" ausreichend. Es kann auch einfach mit einem '|' ("OR") wie folgt erweitert werden: "href|link|..." . |
Im Abschnitt "Add Metadata Definition" können für jedes Metadatum Regeln definiert werden. Die folgenden Einstellungen sind verfügbar:
Einstellung | Beschreibung |
If Rule Matches | Eine Regel, die den Bereich im Inhalt definiert, aus dem Metadaten extrahiert werden sollen. Sie sollte den Namen der Regel tragen, die in der Einstellung "Pattern Rules" definiert ist. |
Name | Der Name der Metadaten, die einem Dokument hinzugefügt werden, wenn die definierte Regel zutrifft. |
Value | Eine Regel, die den Wert von Metadaten definiert. Der Wert der Regel {{month}} kann normaler Text oder zusammengesetzt sein. |
Scope | Eine Regel, die einen Bereich oder mehrere Bereiche mit einer Entity Recognition Regel definiert, in denen die Regeln für die Extraktion angewendet werden sollen. Dazu ist der Name der Regel zur Auswahl des/der Bereiche(s) anzugeben. Im Gegensatz zur Wertextraktion müssen Sie den Namen ohne "{{}}" eingeben. |
Format | Ermöglicht die Extraktion von typisierten Metadaten wie Datum aus String. Die bekannten Typen sind "String", "Date", "Number". Nur "Date" benötigt zusätzliche Parameter "Format Options" und "Locale". |
Format Options | Obligatorisch für Format "Datum". Option zur Einstellung der Formatierung der Ausgabe. Die genaue Definition finden Sie hier: https://github.com/unicode-org/icu/blob/main/docs/userguide/format_parse/datetime/index.md#datetime-format-syntax. Definieren Sie die Reihenfolge und was ausgegeben werden soll, z.B.: "jjjjj.MMMM.tt HH:mm" zum Drucken 2024.Juli.05 11:33. |
Locale | Wird nur für das Format "Datum" verwendet. Legen Sie das Gebietsschema "Locale" fest, wenn sich das Gebietsschema des Computers und des Benutzers unterscheiden. Wie ja_JP zur Anzeige im japanischen Standard-Datumsformat. Prüfen Sie https://github.com/unicode-org/icu/blob/main/docs/userguide/format_parse/datetime/index.md#datetimepatterngenerator. |
In Existing Metadata | Legt fest, für welche Metadaten diese Regeln gelten sollen. Zum Beispiel: content, title, datasource/mes:key, <ownmetadatum>, etc. |
Aggregateable | Wenn diese Option aktiviert ist, ist das erzeugte Metadatum statisch aggregierbar. |
Use Value for Sentence Embeddings | Wenn diese Einstellung aktiviert ist, können die erkannten Entitäten mit einer Sentence Similarity Search (NLQA) gefunden werden. |
Annotate As | Legt fest, wie die Entität zu den Metadaten hinzugefügt wird. Die folgenden Optionen sind verfügbar:
|
Add Link With URL Pattern | Definiert ein Muster für den Annotation-Link, wenn die Einstellung "Annotate As" auf "Link" oder "Entity And Link" gesetzt ist. Es kann die Regex-Definitionen aus der Einstellung "Pattern Rules" verwenden, die auf die gleiche Weise wie die Einstellung "Value" konfiguriert werden kann. Verwendet für etwas wie: www.mindbreeze.com/link_to_item?item={{RuleName}} |
Entity Label | Name der erstellten Entität, wenn die Einstellung "Annotate As" auf "Entity" oder "Entity And Link" gesetzt ist. |
Use Lookup | Ist die Einstellung aktiviert werden in der PDF-Vorschau nur Entitäten angezeigt, für die es auch mindestens ein Dokument im Index gibt. Damit das „Lookup“ funktioniert, müssen Hash Reference Target Metadata Keys konfiguriert werden. Zum Zeitpunkt der Suche wird dann nachgeschlagen, ob es ein Dokument gibt, das den extrahierten Entity Value in einen der „Hash Reference Target Metadata Key“ gesetzt hat. |
Entity Recognition (Beispiel Filesystem)
Dieses Kapitel beschäftigt sich mit der Einrichtung und Erklärung von Entity Recognition mit Mindbreeze unter Anlehnung an ein einfaches Beispiel.
Konfiguration von Entity Recognition für ein Filesystem:
Zuerst müssen die Regeln für die Extraktion angelegt werden:
share=/[^\\]+/.
directory=/[^\\]+/.
UNCPath="\\\\" host "\\" share "\\" directory "\\".
If Rule Matches: UNCPath
Name: Laufwerk
Value: {{share}}
In Existing Metadata: datasource/mes:key
If Rule Matches: UNCPath
Name: Projektpfad
Value: {{directory}}
In Existing Metadata: datasource/mes:key
Aggregated Metadata Keys (; separated)
Laufwerk;Projektpfad
Date-Formate für Entity Recognition basieren auf den ICU-Patterns (z.B. Locale … de_AT)
Konfiguration für Entity Recognition für Filesystem Pfade (Variante 2) – mit Ausnahmen:
Sind die Regeln mehrdeutig, kann über alternative Regeln und einer Reihung durch Benennung sowie die korrekte Reihung der mehrfachen Metadaten-Extraktion auch solch ein komplexer Fall erreicht werden. Der Pfad (path) als Metadatum ist lower-case und somit besser für CSV-Mapping.
Ein ODER (|) von Sub-Regeln funktioniert nicht!
> einfache Lösung ohne Ausnahme:
Pattern Rules:
LWPath=/\\\\[^\\]+\\[^\\]+\\[^\\]+\\[^\\]+/.
FilePath=/[^\\]+/.
FullPath=LWPath "\\" FilePath.
> Lösung mit einer Ausnahme (data\it):
Pattern Rules:
ASpecialPath="data\\it".
OtherPath=/[^\\]+/.
BaseShare=/\\\\[^\\]+\\[^\\]+\\[^\\]+/.
LWPathA= BaseShare "\\" ASpecialPath.
LWPathOther= BaseShare "\\" OtherPath.
FilePathA=/[^\\].*/.
FilePathOther=/[^\\].*/.
FullPathA=LWPathA "\\" FilePathA.
FullPathOther=LWPathOther "\\" FilePathOther.
Im nachstehenden Screenshot wird die Konfiguration der Regeln visualisiert.


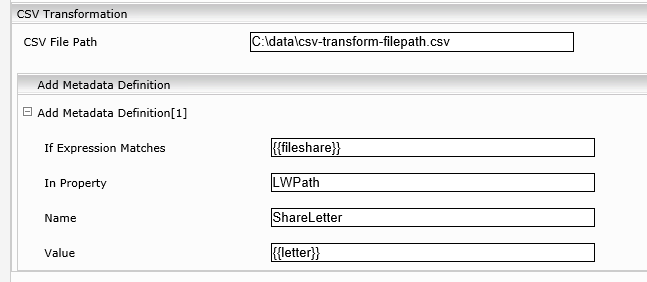


CSV-Transform: der extrahierte Wert (fileshare) muss case-sensitive matchen, somit sollte der path als Quell-Metadatum verwendet werden.
fileshare;letter
\\fileserver.myorganization.com\qa\fstest\projekte;U:
\\fileserver.myorganization.com\qa\fstest\vorlagen;T:
\\fileserver.myorganization.com\qa\fstest\allgemein;G:
\\fileserver.myorganization.com\qa\fstest\spezial;M:
\\fileserver.myorganization.com\qa\fstest\data\it;H:
\\fileserver.myorganization.com\qa\fstest\data;H:
\\fileserver.myorganization.com\qa\fstest\data-services;H:
\\fileserver.myorganization.com\qa\fstest\allgemein-retail;G:
Der Match auf mes:key ist in CSV-Transformation (sowie in ER-rules) nur möglich mit: In Property = datasource/mes:key.
Achtung: /documents-Servlet liefert keine Werte die nur über Index Re-Invert entstehen!
Troubleshooting Entity Recognition
Dieses Kapitel beschäftigt sich mit dem Troubleshooting der Entity Recognition Regeln.
Wichtige Hinweise
- In Mindbreeze InSpire werden die regulären Ausdrücke zusätzlich mit einem „/“ umschlossen.
- Dabei muss jeder Regeleintrag durch einen Punkt getrennt sein.
- Regelnamen dürfen keine „_“ beinhalten
- Regeln sind greedy (gierig – matchen so viel wie möglich Achtung bei „.*“ bzw. „.+“ Konfigurationen)
- Regeln werden alphabetisch abgearbeitet (Groß-/Kleinschreibung beachten!)
Zuerst kommen Großbuchstaben von A bis Z, danach Kleinbuchstaben a bis z. - Trifft eine Regel einen Bereich, so kann keine zweite Regel treffen Annahme: Befindet sich sowohl in Gremium als auch in Schlagwort das Wort „Vorstand“, so wird nur das Metadatum mit der Regel „Gremium“, das Wort „Vorstand“ beinhalten
- Entity Recognition Rules können nur pro Index, also über alle darin befindlichen Datenquellen angelegt werden.
Index
Index-Status prüfen über http://localhost:8443/index/<Indexport>/statistics
Privileged Servlets:
- Verbinden Sie sich zum Management Center
- Navigieren Sie zum Index
- Aktivieren Sie die Advanced Settings
- Öffnen Sie den Index für den Sie Entity Recognition testen möchten
- Deaktivieren Sie die Checkbox "Disable Unrestricted Privileged Servlets"
- Anschließend speichern Sie die Einstellungen und Starten Sie sie Services neu
- Nachdem die Services neugestartet sind:
- Öffnen Sie https://yourappliance:8443/index/Indexport (In unseren Beispiel 23101/processitems) https://yourappliance:8443/index/23101/processitems
- Auf dieser Seite können Sie die Regeln (Pattern-Rules) mit einer bestimmten Abfrage (z.B.: ALL) testen
- Klicken Sie dazu nach dem Ausfüllen auf process. Wenn Sie Syntax der Regeln richtig ist, haben Sie nach Betätigung des Knopfes mehr Optionen zum Testen zur Verfügung.
- Wählen Sie die Regel aus, die Sie matchen möchten und konfigurieren Sie die Werte der Regel(n).
- Klicken Sie anschließend auf process, um das Testen der Regel(n) anzustoßen:

Deaktivierung von gierigen Verhalten der Entity Recognition Regeln
Entity Recognition Regeln sind normalerweise gierig Im folgenden Beispiel werden die markierten Zeilen gematcht:
Regel
R1=/ (?s)(test)(?P<line>.+)\s+(.*Page) /.
Match:

Wird gierig deaktiviert würde jedoch nicht mehr alles gematchet werden, sondern nur jene Blöcke die mit test beginnen und mit Page enden:
Regel:
(?U)(?s)(test)(?P<line>.+)\s+(.*Page)(?U)
Match:

Häufige Fehlerursachen
Bei folgender Fehlermeldung ist ein Fehler beim Parsen der ER-Regeln aufgetreten:
“MesQuery::Text::RE2Tokenizer ERROR: Matched empty (epsilon) token, pattern is”
… z.B. wird ein „\“ am Ende einer Regex nicht unterstützt (LWPath=/\\\\[^\\]+\\/. … liefert Fehler besser: LWPath=/\\\\[^\\]+/ “\\“.).
Eventuell kann es auch zu Problemen mit “.*“ in Regeln kommen.
Entity Recognition Rules werden in alphabetischer Reihenfolge ausgewertet und der erste vollständige Match gewinnt.
Regex-Rules nach deutschen Wörtern treffen mit \w nicht alle Zeichen (Umlaute, etc.). Stattdessen können Sie mit \pL alle Unicode-Buchstaben matchen.
Keine Erkennung von Entitäten bei Inhalten
Wenn die Entity Recognition auf Inhalte angewendet werden soll, indem der Name auf „content“ oder „.*“ gesetzt wird, muss der Inhalt manuell als aggregierbar hinzugefügt werden. Dies kann mit einer der beiden Methoden geschehen:
1. Hinzufügen von „@content“ zu den Aggregated Metadata Keys
2. Oder fügen Sie ein Precomputed Synthesized metadata mit dem Name „@content“, Property Expression “""”, Transformation Pipeline Slot “Before Entity Recognition”, Merge Strategy “Replace Existing”, Aggregatable “Static Aggregatable” hinzu.
Typische Anwendungsfälle
Personal Information
SVNR
\d{4}(\s|\.|\-)\d{6}
Example
1237 010180
1237.010180
1237-010180
Telephone number
(\+)([\s.\(\)]*\d{1}){8,13}(-)?(\d{1,5})
Example
+43 732 606162-0
+43 732 606162-609
+49(732)606162-609
Number (With delimiters)
RegEx
z1=/\d/.z2=/\d/. (…)Dlmtr=/[\s\-_.:]?/.
z1 Dlmtr z2 Dlmtr z3 Dlmtr z4 Dlmtr z5 Dlmtr z6.
Example
12-34567
12 34 56-7
1-2 3456.7
Amount
((\d{1,3}(\.(\d){3})*)|\d*)(,\d{1,2})
Example
0,84
100.000,49
100.000,00
1.000.000.000.000,00
Datum
Handbuch zu den Datumsformaten: http://userguide.icu-project.org/formatparse/datetime
- dd(.|-|/)MM(.|-|/)yyyy
- RegEx
((0[1-9])|[1-9]|([1-3][0-9]))(\.|\/|-)((0[1-9])|[1-9]|10|11|12)(\.|\/|-)((19|20)\d{2}) - Beispiel
11.03.2014
11.3.2014
3.3.2014
03.2.2010
11/03/2014
11/3/2014
3/3/2014
03/2/2010
11-03-2014
11-3-2014
3-3-2014
03-2-2010
- RegEx
- dd. MMM yyyy
- RegEx
((0[1-9])|[1-9]|([1-3][0-9]))\..(|Januar|Februar|März|April|Mai|Juni|Juli|August|September|Oktober|November|Dezember).((19|20)\d{2}) - Example
3. Jänner 2014
4. Februar 2012
30. November 2013
- RegEx
- MMM yyyy
- RegEx
(Januar|Februar|März|April|Mai|Juni|Juli|August|September|Oktober|November|Dezember).((19|20)\d{2}) - Example
Februar 2014
September 2014
- RegEx
- MM(.|-|/)yyyy
- RegEx
(Januar|Februar|März|April|Mai|Juni|Juli|August|September|Oktober|November|Dezember).((19|20)\d{2})|((0[1-9])|[1-9]|10|11|12)(\.|\/|-)((19|20)\d{2}) - Example
03-2014
03.2014
03/2014
- RegEx
- yyyy(.|-|/)mm(.|-|/)dd
- RegEx
((19|20)\d{2})(\.|\/|-)((0[1-9])|[1-9]|10|11|12)(\.|\/|-)((([1-3][0-9]|0[1-9])|[1-9])) - Example
2014-03-21
- RegEx
- Datums-Regex Gesamt
((0[1-9])|[1-9]|([1-3][0-9]))(\.|\/|-)((0[1-9])|[1-9]|10|11|12)(\.|\/|-)((19|20)\d{2})|((0[1-9])|[1-9]|([1-3][0-9]))\..(Januar|Februar|März|April|Mai|Juni|Juli|August|September|Oktober|November|Dezember).((19|20)\d{2})|(Januar|Februar|März|April|Mai|Juni|Juli|August|September|Oktober|November|Dezember).((19|20)\d{2})|((0[1-9])|[1-9]|10|11|12)(\.|\/|-)((19|20)\d{2})|((19|20)\d{2})(\.|\/|-)((0[1-9])|[1-9]|10|11|12)(\.|\/|-)((([1-3][0-9]|0[1-9])|[1-9])) - Datums-Regex Gesamt II
((((0?[1-9]|[12]\d|3[01])[\.\-\/](0?[13578]|1[02])[\.\-\/]((1[6-9]|[2-9]\d)?\d{2}))|((0?[1-9]|[12]\d|30)[\.\-\/](0?[13456789]|1[012])[\.\-\/]((1[6-9]|[2-9]\d)?\d{2}))|((0?[1-9]|1\d|2[0-8])[\.\-\/]0?2[\.\-\/]((1[6-9]|[2-9]\d)?\d{2}))|(29[\.\-\/]0?2[\.\-\/]((1[6-9]|[2-9]\d)?(0[48]|[2468][048]|[13579][26])|((16|[2468][048]|[3579][26])00)|00)))|(((0[1-9]|[12]\d|3[01])(0[13578]|1[02])((1[6-9]|[2-9]\d)?\d{2}))|((0[1-9]|[12]\d|30)(0[13456789]|1[012])((1[6-9]|[2-9]\d)?\d{2}))|((0[1-9]|1\d|2[0-8])02((1[6-9]|[2-9]\d)?\d{2}))|(2902((1[6-9]|[2-9]\d)?(0[48]|[2468][048]|[13579][26])|((16|[2468][048]|[3579][26])00)|00)))) - Example
31.12.2005
12.12.12
1.2.2003
1.3.98
04-05-2004
Zeit
(([0-1]?[0-9])|([2][0-3])):([0-5]?[0-9])(:([0-5]?[0-9]))?
Example
11:00:23
12:30
Email
([a-zA-Z0-9_\-\.]+)@([a-zA-Z0-9_\-\.]+)\.([a-zA-Z]{2,5})
Example
david.porter@inspire.mindbreeze.com
IBAN
AT\d{18}
Example
AT002105017000123456
Kommagetrennte Liste von Inhalten
In diesem Beispiel wird eine Liste von Inhalten getrennt mit einem Beistrich als Liste in Mindbreeze interpretiert.
Input: Liste aus Wort, Wort,
Wert=/[^\s,][^,]*[^,\s]?/.
Regel=/\s*/value/\s*(,\s*|$)/.