
Sure, you can handle it. But should you?
Let our experts manage the tech maintenance while you focus on your business.
Let our experts manage the tech maintenance while you focus on your business.
Schnittstellenbeschreibung
Java API
Unterstütze Java Versionen
Das Mindbreeze Java SDK unterstützt Java JDK Version 8 und 11 (Plugins werden in Java 8 Kompatibilitätsmodus gebaut).
Indizierung
Dieser Abschnitt behandelt das Senden von Objekten an Mindbreeze. Sie lernen die Bestandteile eines Crawler kennen und welche Daten für jedes gesendete Objekt bekannt sein müssen.
Objekte an Mindbreeze senden
Um Objekte suchen zu können, müssen zuerst Objekte im Index liegen. Dieses Kapitel erklärt, wie Sie Objekte Ihrer Datenquelle an Mindbreeze schicken können. Es ist sehr einfach ein Objekt suchbar zu machen, die folgenden Zeilen genügen, um ein Objekt mit dem Titel „title“ und dem key „1“ im Index abzulegen:
Indexable indexable = new Indexable();
indexable.setKey("1");
indexable.setTitle("title");
client.filterAndIndex(indexable);
Rund um diese Zeilen gibt es noch einige Dinge zu klären. Zuallererst müssen Sie sich Gedanken darüber machen, welche Dokumente aus Ihrer Datenquelle relevant für die Suche sind.
Welche Objekte gibt es in meiner Datenquelle?
Wenn man einen neue Datenquelle zur Suche hinzufügen möchte, sollte man sich immer Gedanken darüber machen, welche Inhalte für die Benutzer interessant sind. Dieses Beispiel verwendet beliebige CMIS-Services als Datenquelle. CMIS bietet vier unterschiedliche Objekttypen: Folders, Documents, Relationsships und Policies. Hier werden ausschließlich Dokumente gesendet.
Wie werden Objekte gesendet? Welcher Prozess kümmert sich darum?
Mindbreeze verwendet Crawler, um Objekte an den Index zu senden. Ein Crawler kennt die Datenquelle und sendet die darin enthaltenen Objekte zur Indizierung. Für jeden Datenquellentyp gibt es einen Crawler. Für Mindbreeze InSpire gibt es unter anderem einen Microsoft Exchange Crawler und einen Microsoft SharePoint Crawler. Wir bieten die gleiche Pluginschnittstelle, die wir für unsere Crawler verwenden, auch in unserem SDK an.
Als ersten Schritt sollten Sie den Beispielcrawler als Plugin paketieren und in Ihrer Appliance einspielen. Klicken Sie mit der rechten Maustaste auf die Datei build.xml und wählen Sie Run As > Ant Build aus.
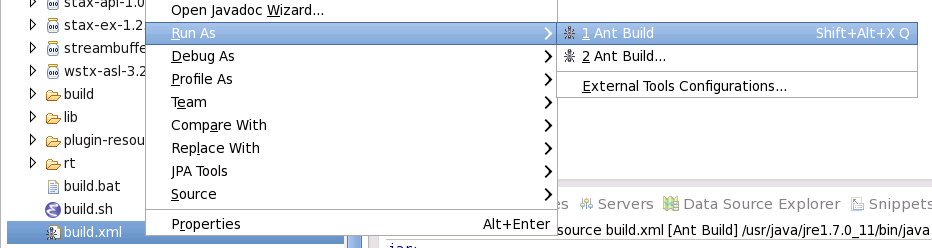
Dadurch wird im Verzeichnis build die das Plugin-Archiv cmis-datasource.zip angelegt.
Nun muss das Plugin noch in der Appliance hinterlegt werden. Öffnen Sie dazu die Konfigurationsoberfläche von Mindbreeze und wechseln zum Tab „Plugins“. Wählen Sie die Zip-Datei aus und bestätigen Sie mit „Upload“.

Nun ist das Plugin installiert und Sie können nun einen Index an und fügen Sie eine neue Datenquelle hinzu.
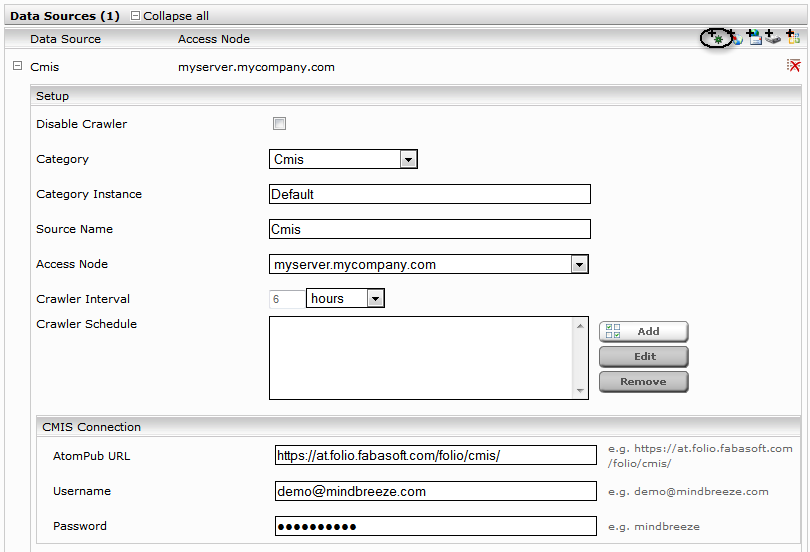
Weitere Informationen
Für weitere Informationen siehe https://www.mindbreeze.com/developer/basic-indexing.
Hinweise für Producer-Consumer Szenarien
Wenn ein Producer-Consumer Setup verwendet wird, synchronisieren sich die Indizes im regelmäßigen Abstand. Das Synchronisieren („SyncDelta“) benötigt je nach Datenmenge einige Sekunden bis Minuten. In dieser kurzen Zeit ist aus technischen Gründen der Index nur lesend („Read-Only“) verwendbar. (Der gleiche Effekt wird erreicht durch manuelles setzen des Index auf Read-Only).
Wenn in diesem Zeitfenster ein FilterAndIndexClient verwendet wird, z.B. client.filterAndIndex (indexable) so wird das indexable wird nicht indiziert. Durch die asynchrone Verarbeitung wird hier auch keine Exception geworfen.
Daher empfehlen wir folgende mögliche Strategien zur Fehlerbehandlung:
Automatisches Wiederholen
Hier wird im Fall, dass der Index gerade ein SyncDelta durchführt bzw Read-Only ist, das indexable automatisch wiederholt, solange bis es erfolgreich Indiziert wurde.
Dies muss mit dem Property repeat_on_503 in der Konfiguration aktiviert werden. Das Property muss auf true gesetzt werden.
In einem Crawler muss das Property als Option im plugins.xml gesetzt werden.
In einem eigenständigen Pusher muss das Property im Configuration-Objekt in beim Aufruf der Factory Methode von FilterAndIndexClientFactory gesetzt werden.
Manuelles Wiederholen
Um zu erkennen, ob die Verwendung von FilterAndIndexClient erfolgreich war, kann ein ProcessIndexableListener registriert werden:
client.addProcessIndexableListener(new ProcessIndexableListener() {
@Override
public void processed(ProcessIndexableEvent event) {
Indexable indexable = event.getSource();
boolean wasSuccessful = event.wasSuccessful();
Operation operation = event.getOperation(); // e.g. FILTER_AND_INDEX or DELETE
Throwable cause = event.getCause(); // if not successful, this is the exception
if (!wasSuccessful){
// Do error handling here
}
}
});
Dieser ProcessIndexableListener wird asynchron nach der Verwendung des FilterAndIndexClient aufgerufen.
Komplexe Metadaten
Wie einfache Metadaten, wie String und Date indiziert werden können ist hier beschrieben:
https://www.mindbreeze.com/de/developer/basic-indexing#data-types
Es können jedoch auch komplexere Datenstrukturen indiziert werden, wie dieser Abschnitt zeigt.
HTML Fragmente
Es können HTML Fragmente als Metadatum indiziert werden.
Folgendes Beispiel zeigt die Verwendung von ValueParser, mit dem ein HTML-Link als Metadatum gespeichert werden kann:
...
import com.mindbreeze.enterprisesearch.mesapi.filter.ValueParserFactory;
...
ValueParserFactory valueParser = ValueParserFactory.newInstance().newValueParser(null);
...
String htmlString = "<a href=\"http://example.com\">Click me</a>";
Item.Builder value = valueParser.parse(Format.HTML, null, htmlString);
indexable.putProperty(NamedValue.newBuilder().setName("my_html_meta").addValue(value));
Hinweis: Das HTML wird (in transformierter Form als XHTML) vollständig im Index gespeichert. Bei der Anzeige im Suchresultat als Metadatum werden jedoch viele HTML-Elemente und Attribute entfernt, um das Layout gegen unerwünschte Änderungen zu schützen. Folgende HTML Elemente werden im Suchresultat angezeigt: [a, span]. Folgende HTML Attribute werden angezeigt, alle außer [id, class, JavaScript-functions].
Falls Metadaten im Format XHTML vorliegen, kann auch das Format XHTML angegeben werden:.
Item.Builder value = valueParser.parse(Format.XHTML, null, xHtmlString);
Hinweis: Die parse()-Methode kann eine Exception werfen, wenn der übergebene String kein korrektes XHTML beinhaltet.
Diese Metadatum werden dann als HTML in den Suchresultaten angezeigt.
Dynamisch aggregierbare Metadaten
Damit ein Metadatum filterbar ist, muss es „aggregierbar“ sein. Statisch aggregierbare Metadaten können im categoryDescriptor.xml definiert werden.
Um jedoch zur Laufzeit entscheiden zu können, welche Metadaten filterbar sein sollen, gibt es dynamisch aggregierbare Metadaten. Im Gegensatz zu statisch aggregierbaren Metadaten kann die Aggregierbarkeit zur Laufzeit und pro Dokument bestimmt werden.
Folgendes Beispiel veranschaulicht, wie man bei einem Mindbreeze InSpire Dokument ein dynamisch aggregierbares Metadatum hinzufügt:
Indexable indexable = new Indexable();
indexable.putProperty(TypesProtos.NamedValue.newBuilder()
.setName("sample_meta")
.addValue(TypesProtos.Value.newBuilder()
.setStringValue("sample_value")
.setKind(TypesProtos.Value.Kind.STRING).build())
.setFlags(TypesProtos.NamedValue.Flags.INVERTED_VALUE |
TypesProtos.NamedValue.Flags.STORED_VALUE |
TypesProtos.NamedValue.Flags.AGGREGATED_VALUE)
);
Hinweise für Query Expression Transformation Service Plugins
Standard Reihenfolge
Da mehrere Query Expression Transformation Service Plugins konfiguriert werden können, ist die Reihenfolge wichtig in der diese Plugins nacheinander die Query Expression transformieren. Die Standard Reihenfolge kann mittels einer „priority“ im plugins.xml bestimmt werden. Diese „priority“ ist ein numerischer Wert und muss kleiner sein als 100.000. Die Plugins werden absteigend nacheinander ausgeführt (hohe Priortät zuerst).
Die Standard „priority“ kann pro Plugin im plugins.xml wie folgt gesetzt werden:
<!-- within the plugins.Plugin.code.Code section -->
<properties>
<KeyValuePair>
<key>priority</key>
<value>10000</value>
</KeyValuePair>
</properties>
Falls die standardmäßige Reihenfolge nicht den gewünschten Effekt zeigt, kann die Reihenfolge des Plugins mit den Pfeil-Knöpfen im Managementcenter verändert werden.
Required Plugins
Falls in einem Query Expression Transformation Service Plugin ein Fehler auftritt, (Exception oder Timeout), dann wird die Transformation übersprungen und die unveränderten Query Expression wird stattdessen verwendet.
Es gibt jedoch Plugins, die sensible Aufgaben übernehmen, wie z.B. sicherheitsrelevante Metadaten ein- und ausblenden oder beispielsweise Schlüsselwörter einer DSL auflösen. Wenn diese sensiblen Plugins defekt sind und es zu Fehlern kommen sollte, wäre ein Überspringen katastrophal, da eventuell sicherheitsrelevante Daten angezeigt werden, die bei einem korrekt funktionierenden Plugin nicht angezeigt werden würden.
Darum können Query Expression Transformation Service Plugins mit einem „required“-Flag markiert werden. Markierte Plugins werden bei einem Fehler nicht übersprungen, sondern stoppen die ganze Pipeline und es werden gar keine Ergebnisse bei der Suche angezeigt. („Fail-Fast“ Prinzip)
Das „required“ Flag kann pro Plugin im plugins.xml wie folgt gesetzt werden:
<!-- within the plugins.Plugin.code.Code section -->
<properties>
<KeyValuePair>
<key>required</key>
<value>true</value>
</KeyValuePair>
</properties>
Transform Non-Expandable Query Expressions
Query Expression Transformation Services transformieren nicht den gesamten Search Request, sondern die im Search Request enthaltenen Query Expressions. Üblicherweise können auch nicht alle Query Expressions transformiert werden, sondern nur Expandable Query Expressions. Dies kann dazu führen, dass in gewissen Situationen benötigten Daten nicht zur Transformation verwendet werden können.
Um dies zu umgehen, können Query Expression Transformation Services mit einem „transform_nonexpandable“-Flag markiert werden. Markierte Query Expression Transformation Services werden auch für das transformierten von nicht Expandable Query Expressions verwendet.
Das „transform_nonexpandable“-Flag kann pro Plugin im plugins.xml wie folgt gesetzt werden:
<!-- within the plugins.Plugin.code.Code section -->
<properties>
<KeyValuePair>
<key>transform_nonexpandable</key>
<value>true</value>
</KeyValuePair>
</properties>
Content Fetch Interface
Über das ContentFetch Interface können die Inhalte von verschiedenen Dokumenttypen bezogen werden:
public interface ContentFetch extends Closeable
Dabei müssen folgende Methoden implementiert werden:
public String getCategory();
Die Funktion getCategory() gibt die Kategorie der Datenquelle wie z.B. “Microsoft File” an, für die das content fetch verwendet werden kann.
public ContentData fetch(String category, String categoryInstance, String key,
String categoryClass, Principal identity,
Map<String, String> params);
Die Methode fetch() gibt das Datenobjekt des Suchergebnises beschrieben durch die Parameter zurück:
Parameter | Beschreibung |
category | Die Kategorie des Suchergebnisses. |
categoryInstance | Die Kategorie-Instanz des Suchergebnisses. |
key | Der Schlüssel des Dokuments im Suchergebnis. |
categoryClass | Die Kategorieklasse des Suchergebnisses. |
identity | Die Identität des Suchanwenders. |
params | Zusätzliche Parameter aus dem Kontext-Provider. Der Benutzer kann den mime Typ des Dokuments wie z.B. "mimetype" : “application/pdf“ in den params von fetch() angeben, um eine schnellere Verarbeitung zu erziehlen. Wenn der mime Typ nicht angegeben wird, dann muss er in der Implementierung der fetch() Methode aus dem Dokument ermittelt werden, was zusätzliche Laufzeit benötigt. public void close(); Die Methode close() räumt das content fetch Objekt auf. |