
Sure, you can handle it. But should you?
Let our experts manage the tech maintenance while you focus on your business.
Let our experts manage the tech maintenance while you focus on your business.
Atlassian Confluence Connector
Installation und Konfiguration
Installation
Vor der Installation des Atlassian Confluence Connector Plugins muss sichergestellt werden, dass der Mindbreeze Server installiert ist und dieser Connector auch in der Mindbreeze Lizenz inkludiert ist. Auf dem Mindbreeze InSpire Server ist der Atlassian Confluence Connector standardmäßig installiert. Wenn Sie den Connector manuell installieren oder aktualisieren möchten, verwenden Sie dazu das Mindbreeze Management Center.
Konfiguration von Mindbreeze
Konfiguration von Index und Crawler
Klicken Sie auf den „Indices“-Tab und danach auf das „Add new index“-Symbol, um einen neuen Index zu erstellen.
Geben Sie den Indexpfad ein, z.B. „/data/indices/confluence“. Passen Sie gegebenenfalls den Display Name des Index Service und des zugehörigen Filter Service an.
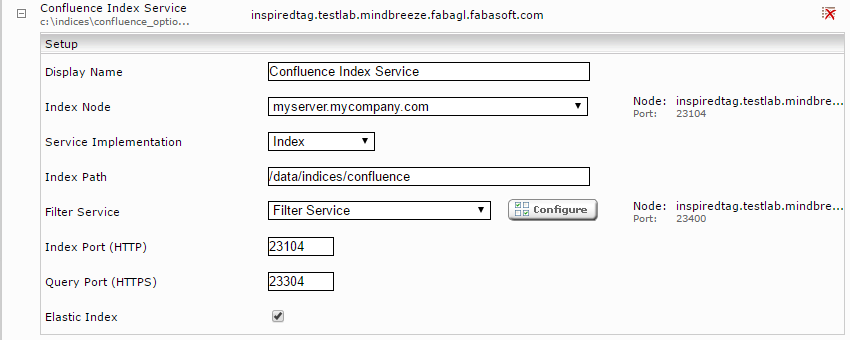
Fügen Sie eine neue Datenquelle mit dem Symbol „Add new custom source“ rechts unten ein.
Wenn nicht bereits ausgewählt, selektieren Sie „Atlassian Confluence“ bei der Schaltfläche „Category“.
Über die Einstellung „Crawler Interval“ konfigurieren Sie die Zeitspanne, die zwischen zwei Indizierungsdurchläufen gewartet wird.
Web Page
Im Feld Crawling Root können Sie eine URL angeben, über den eine Atlassian Confluence Sitemap erreichbar ist. Wenn Sie das Mindbreeze Sitemap Generator Add-On auf ihren Atlassian Confluence Server installiert haben und eine Sitemap erzeugt ist, sollte hier die URL <Atlassian Confluence URL>/plugins/servlet/sitemapservlet?jobbased=true eingetragen werden.
Im Feld „URL Regex” können Sie einen regulären Ausdruck bestimmen, der ein Muster für die Links vorgibt, die indiziert werden sollen.
Sollen bestimmte URLs vom Crawlen ausgenommen werden, so können diese mit einem regulären Ausdruck unter „URL Exclude Pattern“ konfiguriert werden.
Mit der Option „Include URL By Metadata“ bzw. „Exclude URL by Metadata“ können beim Crawlen mit Sitemaps, gewisse Seiten anhand der Metadaten in der Sitemap ausgenommen werden. Das Feld „Metadata Name“ spezifiziert den Namen des Metadatums und das Feld „Pattern“ den regulären Ausdruck, gegen den der Wert des Metadatums gematcht wird.
Werden „URL Regex“, „URL Exclude Pattern“ und „Include/Exclude URL by Metadata“ gleichzeitig verwendet, wird zuerst „URL Regex“ angewendet, dann die Seiten mit „URL Exclude Pattern“ ausgeschlossen und letztendlich die restlichen Seiten mit „Include/Exclude URL by Metadata“ gefiltert.
Mit der Option „Convert URLs to lower case“ werden alle gefundene URLs auf Kleinschrift konvertiert.
Sollte aus netzwerktechnischen Gründen die DNS-Auflösung bestimmter Webserver nicht klappen, kann man mit dem „Additional Hosts File“ die IPs vorgeben.
Möchte man bestimmte HTTP Header hinzufügen (beispielsweise Accept-Language), so kann man das über die „Accept Headers“ einstellen.
Falls Confluence Sitemaps gecrawlt werden, können die Inhalte von Seiten mit der Option „Use Rest API for Page Content“ Performance-schonend und ohne die Ausführung von Macros bezogen werden.
Mit der Option „Confluence Rest API Base Path“ kann ein Basispfad konfiguriert werden, auf dem die Confluence Rest API erreichbar ist.
Mit der Option “Confluence Rest Content Representation” kann bestimmt werden, in welchem Format der Inhalt der Confluence Seiten abgeholt werden soll. Der Standardwert „Storage“ ist Performance-schonend, da keine Macros am Confluence Service ausgeführt werden, jedoch kann der Inhalt in gewissen Situationen unvollständig oder inkorrekt sein. Mit der Option „Export View“ werden Macros ausgeführt, was zu verbesserter Darstellung führen kann, jedoch die Performance beeinträchtigen kann. Für weitere Informationen zu diesen Optionen siehe https://docs.atlassian.com/atlassian-confluence/6.5.2/com/atlassian/confluence/api/model/content/ContentRepresentation.html.
Mit der Option „Confluence Rest Content Extension” kann die Extension der indizierten Mindbreeze Dokumente bestimmt werden. Dies hat Einfluss auf den konkreten Filter, der verwendet wird.
Um die Verwendung von Macros tatsächlich zu verhindern, sollte zusätzlich das HTML Thumbnailing deaktiviert werden. Wenn die Option „Disable Web Page Thumbnail Generation“ aktiv ist, wird auf alle Dokumente das Metadatum „htmlfilter:skipthumbnailgneneration“ gesetzt. Im Filter Service müssen dann noch zusätzliche Optionen konfiguriert werden (siehe Absatz nach Screenshot).
Mit der Option „Max Retries“ wird bestimmt, wie oft der Connector versucht ein Dokument herunterzuladen, wenn temporäre Fehler (z.B. Socket Timeouts) auftreten. Der Standardwert ist 0. (Kein weiterer Herunterladeversuch). Wenn über ein instabiles Netzwerk gecrawlt wird (das Timeouts verursacht), sollte dieser Wert auf z.B. 10 erhöht werden. Wenn die Timeouts durch eine überlastete Datenquelle entstehen, sollte der Wert auf 0 belassen werden, damit die Datenquelle nicht zusätzlich belastet wird.
Mit der Option „Retry Delay Seconds“ wird die Wartezeit (in Sekunden) bestimmt, die zwischen den Herunterladeversuchen vergehen (siehe „Max Retries“). Der Standardwert ist 1.

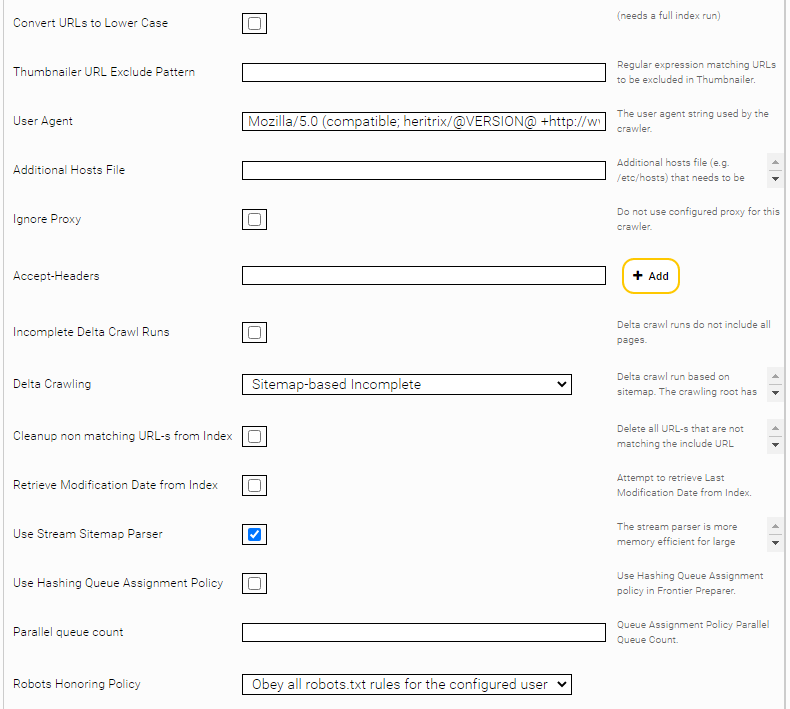
Um HTML Thumbnailing zu deaktivieren, setzen Sie im Filter Service für das Filter Plugin „JerichoWithThumbnails“ die Option „Disable Thumbnails Metadata Pattern“ auf „htmlfilter:skipthumbnailgeneration“. Dadurch werden die HTML Dokumente wo das Metadatum „htmlfilter:skipthumbnailgeneration“ gesetzt ist, ohne Thumbnail indiziert.
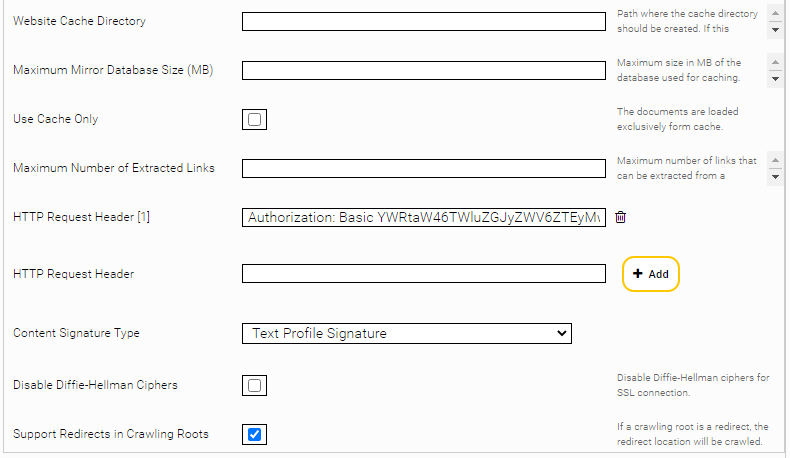
Sitemap basiertes Crawlen
Um Confluence Sitemaps bearbeiten zu können, aktivieren Sie “Delta Crawling” und geben Sie die Confluence Sitemap URL als Crawling Root an.
In diesem Modus liest der Connector die Webseiten exklusiv aus den Sitemaps aus. Hier wird die Eigenschaft lastmod der Seiten der Sitemap mit den indizierten Seiten verglichen. Mittels einer präzisen Sitemap können sehr hochfrequente Indizierungsstrategien angewendet werden.
Für den „Sitemap-based Delta Crawling“ Modus sind zwei Optionen verfügbar:
- „Sitemap Based Incomplete“: die URL-s von den konfigurierten Sitemaps sind indiziert, die schon indizierten Dokumente, die nicht in den Sitemaps enthalten sind, bleiben im Index.
- „Sitemap Based Complete“: die URL-s von den konfigurierten Sitemaps sind indiziert, die schon indizierten Dokumente, die nicht in den Sitemaps enthalten sind, werden gelöscht.
Mit der „Use Stream Parser“ Option wird ein Stream Parser für die Bearbeitung der Sitemaps verwendet. Diese Option ist für Sitemaps mit sehr vielen URLs geeignet.
Resource Parameters
In diesem Abschnitt (nur verfügbar, wenn „Advanced Settings“ ausgewählt ist) kann noch die Crawl-Geschwindigkeit adjustiert werden.
Mit der Anzahl der Crawler-Threads („Number Of Crawler Threads“) kann definiert werden, wie viele Threads gleichzeitig Webseiten vom Webserver abholen.
Das „Request Interval“ definiert die Anzahl an Millisekunden, die der Crawler(-Thread) zwischen den einzelnen Requests warten soll. Eine „Crawl-Delay“ Robots-Anweisung wird jedoch auf alle Fälle berücksichtigt und überschreibt diesen Wert.

Proxy
Im Tab „Network“ können Sie einen Proxy Server eintragen, falls Ihre Infrastruktur dies erfordert.
Confluence Login
In diesem Abschnitt werden die verschiedenen Authentisierungsmethoden für den Atlassian Confluence Connector beschrieben. Der Abschnitt beleuchtet dabei jene Methoden die verwendet werden können, um Inhalte, die sich hinter einem Login befinden, indizieren zu können.
Basic Autorisierung
Wenn die Atlassian Confluence Sitemap und Dokumente mittels HTTP Basic Autorisierung erreicht werden können, so kann dieser als „HTTP Request Header“ konfiguriert werden.
Formularbasiertes Login
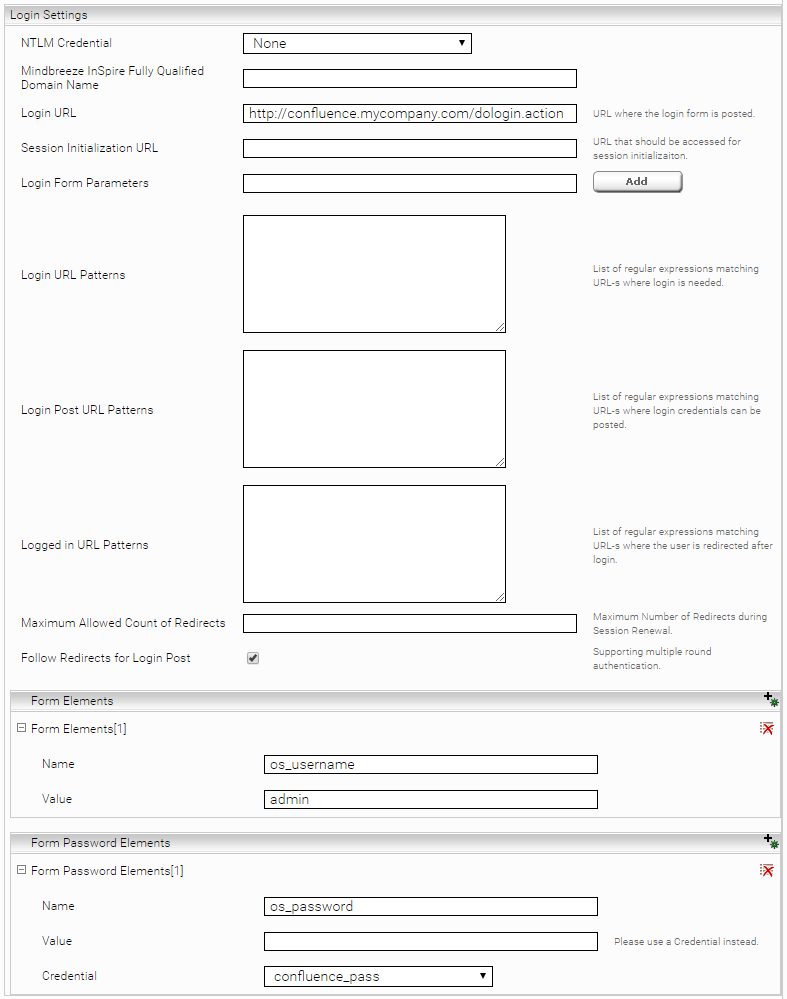
Wenn die Atlassian Confluence Sitemap mit formularbasiertem Login erreichbar ist, können die Login Parameter im Abschnitt „Form Based Login“ folgendermaßen konfiguriert werden:
- Login URL: die Atlassian Confluence URL, an die das Login Formular geschickt werden soll: z.B. http://<confluence_url>/dologin.action
- Form Elements: hier muss ein Element mit Name „os_username“ hinzugefügt werden. Der Wert („Value“) soll der Benutzername sein, der dazu berechtigt ist, die Sitemap runterzuladen.
- Form Password Elements: hier muss ein Element mit Name „os_password“ hinzugefügt werden. Der Wert („Value“) soll das Passwort für den zuvor angegebenen Benutzer sein.

Der formularbasierte Login wird nur bis Confluence Version 8 unterstützt.
Komplexes formularbasiertes Login
Wenn das vorherige Szenario nicht ausreicht, können folgende Einstellungen verwendet werden:
- Session Initialization URL: Diese URL wird zu Beginn aufgerufen um danach dynamisch weitergeleitet zu werden. Die dabei erhaltenen Cookies werden für die Session beibehalten.
- Login Form Parameters: Wenn beim Login-Formular versteckte Felder gesetzt werden, können diese hier aufgelistet werden. Diese werden extrahiert und beim Login-Request mitgesendet. Ein typisches Beispiel dafür ist die dynamisch generierte FormID, die als hidden Parameter vom Webserver zurückgesendet wird.
- Login Form Parameters: Wenn beim Login-Formular versteckte Felder gesetzt werden, können diese hier aufgelistet werden. Diese werden extrahiert und beim Login-Request mitgesendet. Ein typisches Beispiel dafür ist die dynamisch generierte FormID, die als hidden Parameter vom Webserver zurückgesendet wird.
- Login URL Patterns: Alle Redirects, die den hier angegebenen regulären Ausdrücken entsprechen, werden beim Loginvorgang verfolgt
- Login Post URL Patterns: Beim Folgen von Redirects, die den hier angegebenen regulären Ausdrücken entsprechen, werden alle gesammelten Formularparameter mittels HTTP-POST-Request mitgesendet.
- Logged in URL Patterns: Wird auf eine URL weitergeleitet, die den hier angegebenen regulären Ausdrücken entspricht, dann gilt der Loginvorgang als erfolgreich.
- Maximum Allowed Count of Redirects: Hiermit kann die maximale Tiefe der verfolgten Redirects festgelegt werden.
NTLM
Um NTLM Authentisierung zu verwenden, müssen zuerst User, Passwort und Domain im Network Tab als Credential konfiguriert werden:
Danach muss dieses Credential im Atlassian Confluence Connector bei der Einstellung „NTLM Credential“ ausgewählt werden.
Im Feld „Mindbreeze InSpire Fully Qualified Domain Name“ muss zusätzlich der „Fully Qualified Domain Name“ des Mindbreeze InSpire-Servers angegeben werden.

Hinweis: Wenn NTLM Authentisierung verwendet wird, funktionieren die Thumbnails in Mindbreeze InSpire nicht.
NTLM Authentisierung wird nur bis Confluence Version 8 unterstützt.
Konfiguration von „Access Check Rules“
Ein Access Check Rule besteht aus:
- „Access Check Principal”, die Benutzernamen können im Format „username@domain“, „domain\username“ oder „distinguished name“ sein. Die Gruppennamen können nur im Format distinguished name sein. Weiters kann hier ein Verweis auf eine Capture-Group in der Selection Pattern verwendet werden.
- „Access Check Action”, Grant order Deny.
- „Metadata Key for Selection”, ein Metadatenname, kann leer sein (alle Dokumente werden selektiert)
- „Selection Pattern”, eine Regularexpression, kann leer sein (alle Dokumente werden selektiert).
Atlassian Confluence Principal Resolution
Wählen Sie im neuen oder bestehenden Service in der Einstellung „Service“ die Option CachingConfluencePrincipalResolutionService aus. Für mehr Informationen über weitere Konfigurationsoptionen und über das Erstellen und das grundlegende Konfigurieren eines Cache für einen Principal Resolution Service, siehe Installation & Konfiguration - Caching Principal Resolution Service.
Falls die Option nicht sichtbar ist, muss sichergestellt werden, dass ConfluenceAccessx.x.x.zip im Reiter „Plugins” installiert wurde.

- Geben Sie die „Confluence Server URL” an.
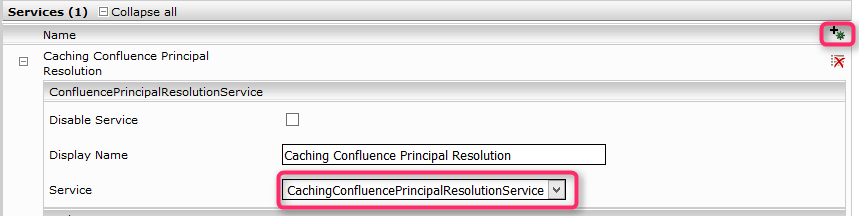
Die notwendigen Anmeldeinformationen, um auf die „Confluence Server URL” zugreifen zu können, müssen im Reiter „Network“ konfiguriert und auf den „Confluence Server URL“ Endpunkt abgebildet werden.

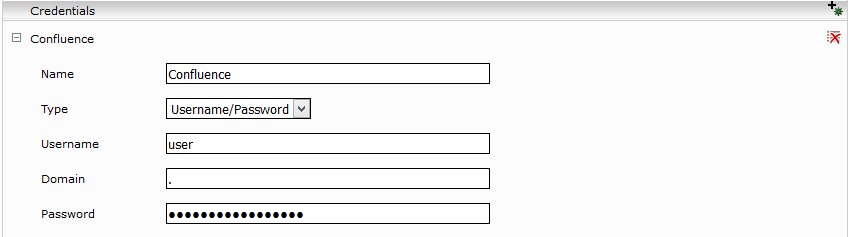
Geben Sie den Verzeichnispfad für den Cache im „Database Directory Path“ Feld an und ändern Sie, wenn notwendig, die „Cache In Memory Items Size“, abhängig vom verfügbaren Speicherplatz der JVM. Im „Cache Update Interval (Minutes)“ Feld geben sie die Zeit (Minuten) an, die gewartet wird bevor der Cache aktualisiert wird. Beim ersten Starten des Service wird diese Zeit ignoriert. Beim nächsten Starten des Services, wird diese Zeit berücksichtigt. Die Einstellungen „Health Check Interval“, „Health Check max. Retries On Failure“ und „Heath Check Request Timeout“ ermöglichen es, dass dieser Service neugestartet wird falls es z.B. dauerhafte Verbindungsprobleme gibt.

Wenn Benutzer bei einer Suchanfrage nicht aufgelöst werden können, wird eine Anfrage direkt an Confluence abgesetzt, wenn die Option „Supress Confluence Service Calls“ nicht aktiviert ist. Aus Performancegründen wird jedoch empfohlen, diese Option zu aktivieren, sodass keine Live-Anfragen an Confluence gestellt werden.
Service Settings
Lowercase Principals | Mit dieser Option werden die vom Cache gelieferten Principals kleingeschrieben. Dies sollte aktiviert werden, wenn der Konnektor Principals in Kleinbuchstaben ausliefert. Achtung: Diese Option ist standardmäßig deaktiviert. |
Achtung: Bitte verändern sie nicht die Standardeinstellung. Für mehr Informationen zu der Einstellung „Lowercase Principles“ siehe Installation & Konfiguration - Caching Principal Resolution Service - Service Settings.
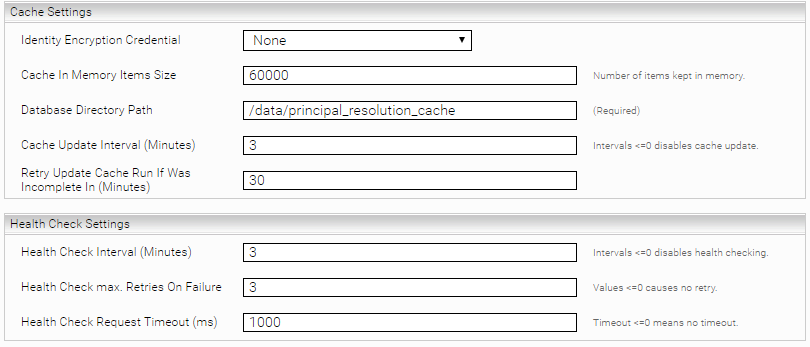
Confluence Settings

Confluence Server URL | Die URL des Confluence Servers z. B. https://confluence.myorganization.com |
HTTP Request Header | Zusätzliche HTTP Header, die mit jedem Request mitgesendet werden sollen. Das Format ist HeaderName:HeaderValue . |
Use Form Login | Ist diese Option aktiviert, schickt der Service ein Login Request an den Confluence Server. Ansonsten wird ein Basic Authentication Header verwendet. |
Form Login NTLM Credential | Das NTLM Credential, wie im Abschnitt NTLM beschrieben. |
Read Timeout (Minutes) | Definiert den Read Timeout für ausgehende Verbindungen. |
Connect Timeout (Minutes) | Definiert den Connect Timeout für ausgehende Verbindungen. |
Wenn diese Option aktiviert ist, wird der Principal Resolution Cache geupdated, auch wenn die Auflösung mancher Gruppen fehlschlägt. Dies kann zu Inkonsistenzen zwischen der Mindbreeze Suche und Confluence führen. Aktivieren Sie diese Option nur, um temporär einen beständigen Fehler zu umgehen. | |
Ignore Containers Pattern | Regex-Pattern, welches definiert, welche Confluence Container vom Principal Resolution Service nicht aufgelöst werden sollen. |
Parent Principals Are Unique IDs | Diese Option darf nicht ausgewählt werden, falls die aufgelösten Benutzer Principals Aliasnamen enthalten. |
Wenn diese Option aktiviert ist und in Atlassian Confluence unter "Global Permissions" der Zugriff für anonyme Benutzer erlaubt ist, werden alle angemeldeten Benutzer so behandelt, als hätten sie globale Nutzungsrechte für Atlassian Confluence. Wenn diese Option deaktiviert ist, haben anonyme Benutzer keinen Zugriff. Achtung: Es ist möglich Atlassian Confluence so zu konfigurieren, dass eingeloggte Benutzer keinen Zugriff auf Dokumente haben, anonyme Benutzer aber schon. In diesem Fall, wenn diese Einstellung aktiviert ist, finden Benutzer möglicherweise mehr Dokumente in Mindbreeze als in Atlassian Confluence. |
Für zusätzliche Informationen, siehe Installation & Konfiguration - Caching Principal Resolution Service.
Confluence Authorization Service
Bei der Suche setzt der Confluence Authorization Service pro Objekt einen Request an Confluence ab. Damit soll herausgefunden werden, ob der jeweilige User tatsächlich Zugriff auf dieses Objekt hat. Da dies teilweise viel Zeit benötigt, sollte der Authorization Service nur für Testzwecke verwendet werden. Im Normalfall müssen alle Checks des Authorization Service ohnehin positiv sein. Damit lässt sich leicht herausfinden, ob es Probleme mit den Berechtigungen gewisser Objekte gibt.
Um den Authorization Service bei der Suche zu verwenden, muss man Advanced Settings aktvieren und im Index die Option „Approved Hits Reauthorize“ auf „External Authorizer“ setzen. Danach muss im Crawler unter „Authorization Service“ der erstellte Authorization Service ausgewählt werden.
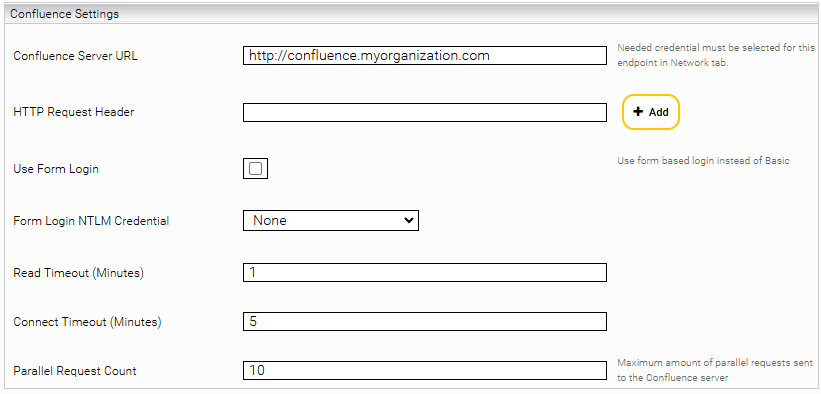
Confluence Settings
Confluence Server URL | Die URL des Confluence Servers z. B. https://confluence.myorganization.com |
HTTP Request Header | Zusätzliche HTTP Header, die mit jedem Request mitgesendet werden sollen. Das Format ist HeaderName:HeaderValue . |
Use Form Login | Ist diese Option aktiviert, schickt der Service ein Login Request an den Confluence Server. Ansonsten wird ein Basic Authentication Header verwendet. |
Form Login NTLM Credential | Das NTLM Credential, wie im Abschnitt NTLM beschrieben. |
Read Timeout (Minutes) | Definiert den Read Timeout für ausgehende Verbindungen. |
Connect Timeout (Minutes) | Definiert den Connect Timeout für ausgehende Verbindungen. |
Parallel Request Count | Definiert die maximale Anzahl an Requests, die gleichzeitig an den Confluence Server geschickt werden. |
Troubleshooting
Fehlende Dokumente in der Suche aufgrund der Sitemap Generator Version
Sollte es vorkommen, dass Dokumente nicht mehr gefunden werden, obwohl sie im Index vorhanden sind, wird die Überprüfung der Logs des Principal Resolution Services als erster Schritt empfohlen.
Dabei könnte folgende Fehlermeldung in den Logs gefunden werden:
"The installed version (x.x.x.x) of the Confluence Sitemap Generator is unsafe. Please upgrade to the newest version of the Sitemap Generator."
Ist dies der Fall, so ist eine unsichere Version des Sitemap Generator installiert. Dementsprechend muss der Sitemap Generator auf eine sichere Version aktualisiert werden. Bis die Aktualisierung durchgeführt wurde, ist davon auszugehen, dass die Suche nicht mehr funktioniert.
Behebung des Status Code 401 nach Passwortänderung
Wenn alle Anfragen den Status Code 401 zurückgeben, ist der Crawler oder der Principal Resolution Service möglicherweise auf den Captcha Sicherheitscheck von Confluence gestoßen.
Dies kann passieren, wenn z. B. das Passwort geändert und der Dienst nicht aktualisiert wurde.
Mit dem Captcha Sicherheitscheck kann der Administrator eine Anzahl von Anmeldeversuchen festlegen. Wird die Anzahl der Versuche überschritten, muss der- Benutzer ein Captcha lösen, um sich anzumelden.
Diese Einstellung finden Sie unter "<Ihre-confluence-url>/admin/viewsecurityconfig.action".
Dort ist es möglich, die Einstellung zu deaktivieren oder einzuschränken: "CAPTCHA on login".
Um den Dienst ordnungsgemäß neu zu starten, muss das falsche Passwort in der Konfiguration geändert und das Captcha manuell auf der Website gelöst werden.