
Sure, you can handle it. But should you?
Let our experts manage the tech maintenance while you focus on your business.
Let our experts manage the tech maintenance while you focus on your business.
Installation und Konfiguration
Data Integration Connector
Wichtiger Hinweis
Das Softwareprodukt Talend Open Studio wurde am 31. Januar 2024 eingestellt. Daher kann der Data Integration Connector in der aktuellen Form nicht mehr weiterentwickelt werden und erhält nur noch Wartungsupdates.
Für Alternativen und Fragen zur Wartung von bestehenden Lösungen wenden Sie sich bitte an den Mindbreeze Support unter support@mindbreeze.com.
Erstellen eines „Data Integration Prozesses“
Sie können den Data Integration Connector in Verbindung mit Talend Open Studio verwenden, um selbst Datenquellen anzubinden. Talend Open Studio steht unter https://www.talend.com/products/data-integration/data-integration-open-studio/ zum Download zur Verfügung.
Ältere Versionen können unter https://www.talend.com/products/data-integration-manuals-release-notes/ heruntergeladen werden. Bitte beachten Sie, dass Sie keine Milestone Versionen (mit M1, M2, usw. am Ende der Versionsnummer) verwenden. Dies sind Beta-Versionen, die oft instabil sind.
Hinweis: Das Mindbreeze Java SDK unterstützt Java in der Version 11. Möglicherweise installiert Talend Open Studio automatisch eine andere Java Version auf ihrem System, was dann später zu Problemen mit dem Mindbreeze Java SDK führen kann. Stellen Sie sicher, dass Java in der Version 11 installiert ist, und dass die Umgebungsvariable JAVA_HOME auf das Java 11 JDK Installationsverzeichnis gesetzt ist.
Der Data Integration Connector enthält Komponenten für Talend Open Studio, die getrennt installiert werden müssen. Entpacken Sie die Datei components-<<VERSION>>.zip aus dem Data Integration Connector Installationspaket in ein beliebiges Verzeichnis (z.B. C:\custom-talend-components-12.03.123\). Wir empfehlen, die Versionsnummer im Verzeichnisnamen zu beinhalten.
Legen Sie nach der Installation von Talend Open Studio ein neues Projekt an.
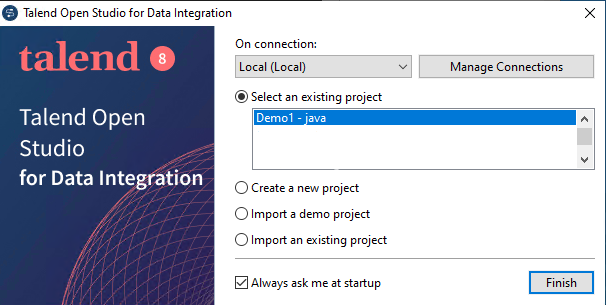
Öffnen Sie im Menü von Talend Open Studio Window -> Preferences:

Wählen Sie Talend -> Components aus und geben Sie im Feld „User component folder“ das Verzeichnis an, in das Sie die Komponenten entpackt haben.
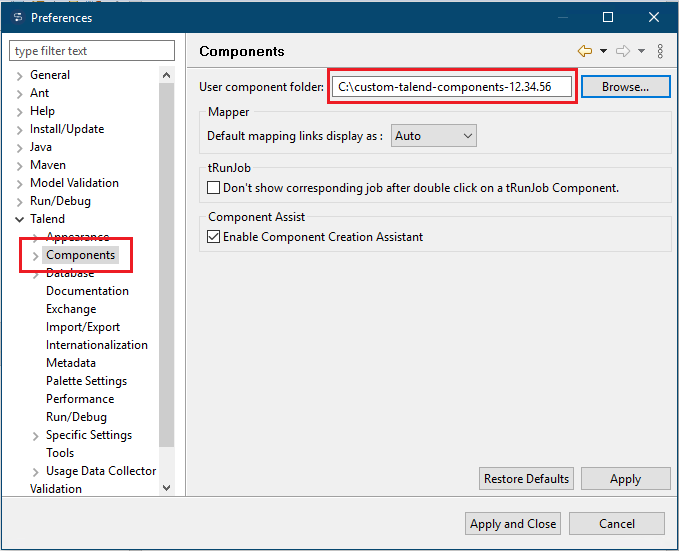
Wechseln Sie nun zu den Import/Export Einstellungen, und aktivieren Sie die Option „Add classpath jar in exported jobs“:
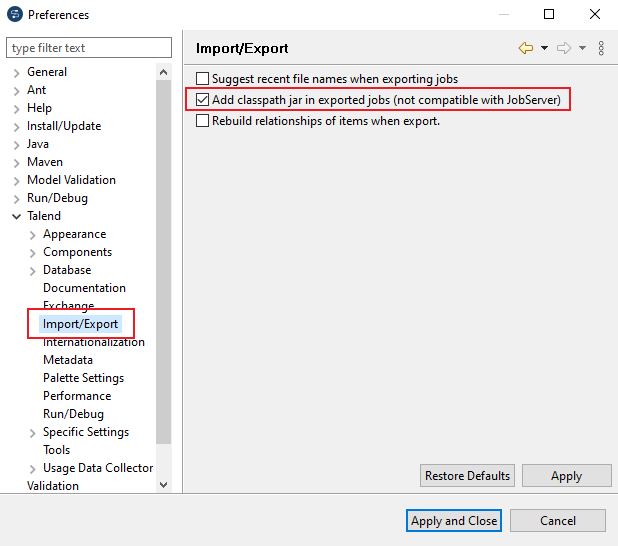
Jetzt können Sie einen neuen Job anlegen. Fügen Sie Datenquellen nach Ihren Bedürfnissen hinzu. Genauere Information zum Arbeiten mit Talend Open Studio erhalten Sie in der Dokumentation zu Talend Open Studio.
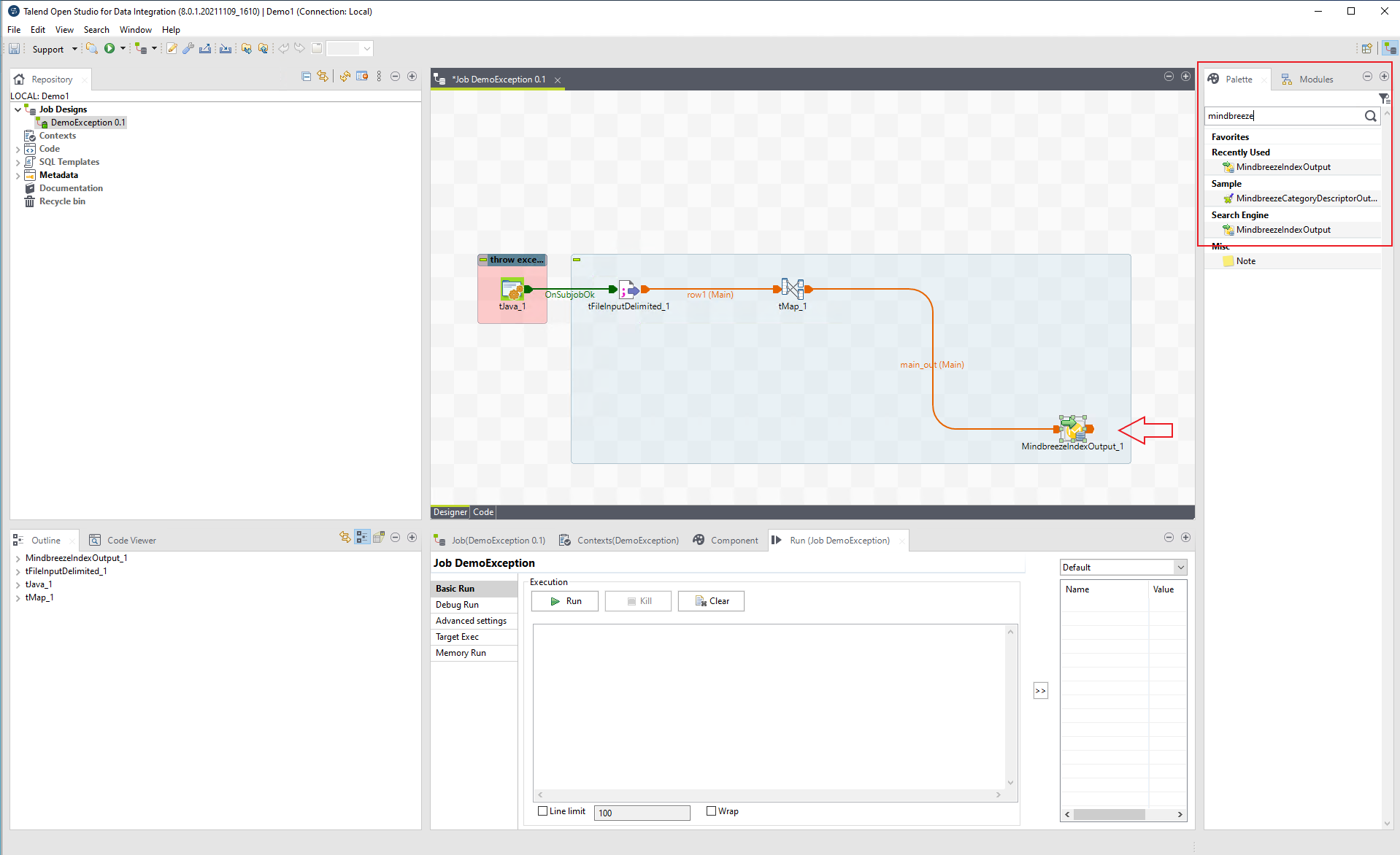
Als Ziel einer Verarbeitungskette muss immer die Komponente namens "MindbreezeIndexOutput" stehen.
Troubleshooting - Abhängigkeiten
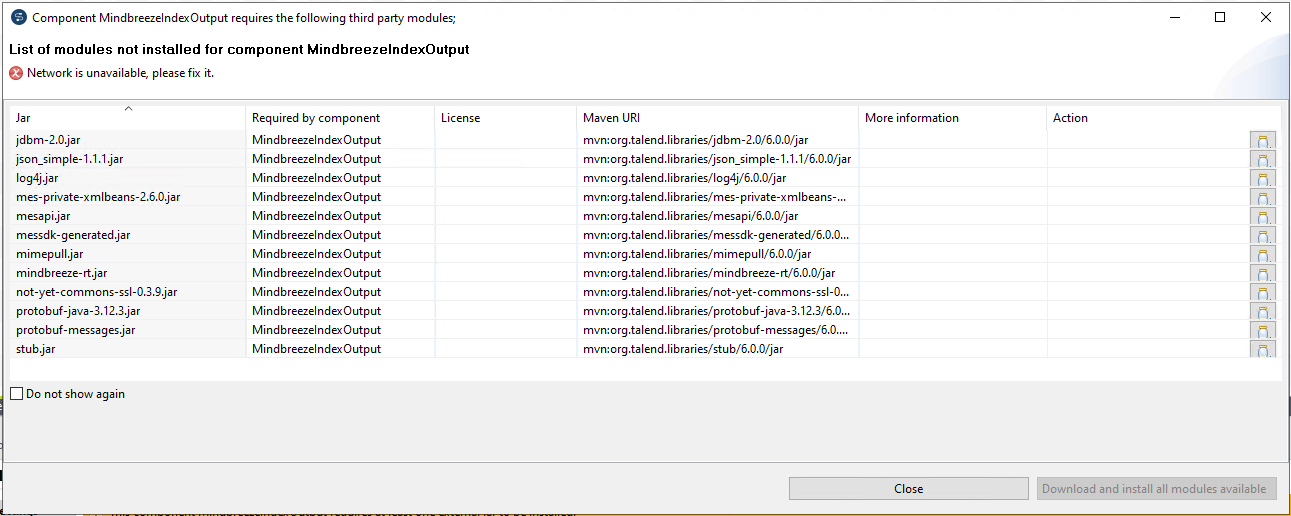
In neueren Versionen von Talend Open Studio kann es vorkommen, dass Abhängigkeiten der MindbreezeComponents nicht automatisch erkannt werden:
![]()
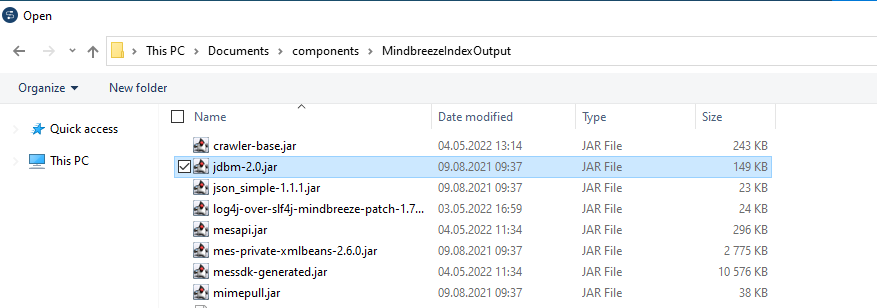
In diesem Fall müssen die JARs manuell ausgewählt werden:
- Click auf Button Install..
- Click auf jedes
 -Symbol
-Symbol - Zurordnen des gleichnahmigen JARs im Ordner MindbreezeIndexOutput
Aktualisieren der Mindbreeze Components
Um eine reibungslose Funktionalität zu gewährleisten, empfehlen wir, die Mindbreeze Components immer auf die gleiche Version wie die verwendete Mindbreeze InSpire Version zu aktualisieren.Die Aktualisierung funktioniert ähnlich zu der initialen Konfiguration, benötigt jedoch noch zusätzliche Schritte.
- Wie Abschnitt „Konfigurieren der Mindbreeze User Components“ erklärt, laden Sie die Mindbreeze Components von der Mindbreeze Website herunter und entpacken Sie das „components-<<VERSION>>.zip“ Archiv. Z.B an den Ort „C:\custom-talend-components-12.03.123“.
Wir empfehlen, den Pfad des User Component Folder in den Talend Einstellungen bei jedem Update zu ändern bzw. immer die Versionsnummer im Pfad zu verwenden. Dies liegt daran, dass Talend oft nicht erkennt, dass die User Components aktualisiert wurden. In diesem Fall verwendet Talend intern weiterhin die alten Versionen der Components, die im Cache gespeichert sind, ohne dass dies ersichtlich ist.
- Starten Sie Talend neu, bevor Sie fortfahren. Nur ein Neustart von Talend stellt sicher, dass die neue Version der Mindbreeze Components vollständig neu geladen wird. (Das automatische Neuladen bei geöffnetem Talend ist nicht ausreichend).
Verwendung der Mindbreeze Components
Beachten Sie weiters, dass für die korrekte Funktionsweise dieser Komponente folgende Felder im Schema definiert sein müssen, alle vom Typ "String":
- key
- title
- extension
- categoryClass
Zusätzlich können auch noch folgende optionalen Felder für die Weiterverarbeitung im Mindbreeze Index verwendet werden:
- acl (Liste von "String"-Werten) in folgendem Format: "TestUser1||GRANT"
- date (Typ "Date")
- modificationDate (Typ "Date")
- content (Typ "String")
Sollten weitere Felder im Schema definiert sein, so werden diese als Metadaten übernommen. Es ist auch möglich, Annotationen in folgendem Format zu definieren:
val1|||mes:annotated|||categoryclass=cc1|||value=v1
"val1" wird in diesem Beispiel mit der categoryClass "cc1" und dem Wert "v1" zu einer Annotation.
Sämtliche Felder vom Typ "Liste" werden zu Listen von Metadaten, alle anderen Felder automatisch zum Typ "String" konvertiert.
Testen und exportieren des „Data Integration Prozesses“
Testen mit Logging
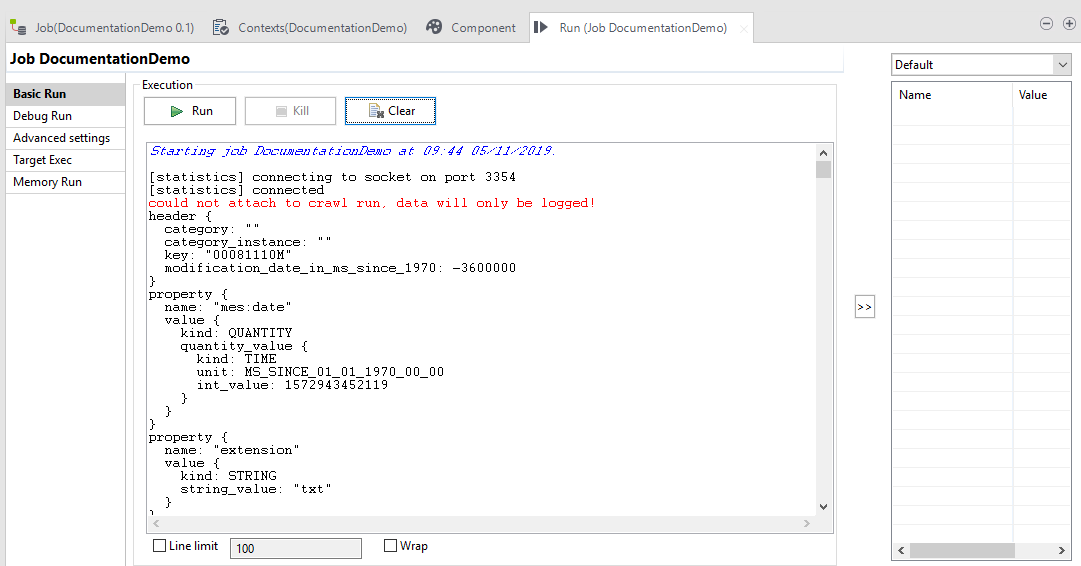
Sobald Sie den Job fertig konfiguriert haben, können Sie den Job ausführen, um die Funktionsweise zu testen. Die Daten werden nicht an einen Index gesendet, sondern in Talend Open Studio ausgegeben.
Testen als Pusher
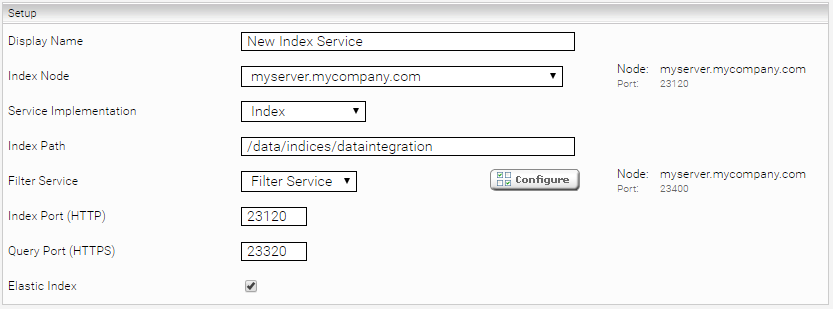
Sie können den Job auch so testen, sodass die Daten direkt in Mindbreeze indiziert werden, ohne den Job vorher exportieren zu müssen. Dazu müssen Sie zuerst einen neuen Index in Mindbreeze InSpire erstellen. Klicken Sie auf das „Indices“-Tab und danach auf das „Add new index“-Symbol.
Klicken Sie anschließend auf die Schaltfläche „Save“, um die Änderungen zu speichern. Folgendes Pop-Up wird von Ihrem Browser angezeigt, welches Sie mit „OK“ bestätigen müssen:

Den nächsten Schritt müssen Sie wieder im Talend Open Studio ausführen. Wählen Sie im Designer Ihre verwendete „MindbreezeIndexOutput“-Komponente aus und wählen Sie „Use as Pusher“ aus.
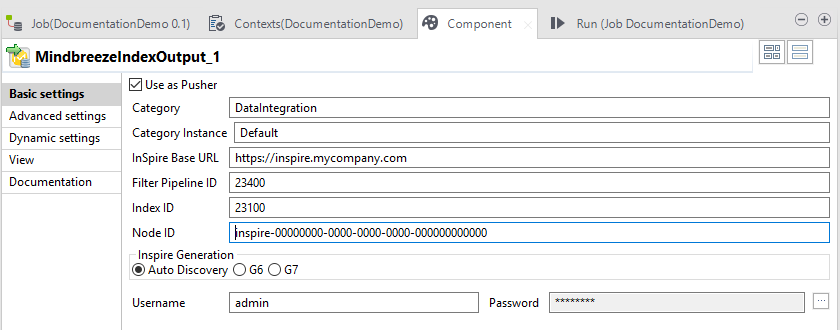
Folgende Felder müssen konfiguriert werden:
Einstellung | Beschreibung |
Category | Die Category. |
Category Instance | Die Category Instance. |
InSpire Base URL | Die URL, die zu Ihrer Mindbreeze InSpire-Installation führt. |
Filter Pipeline ID | Der Port des Filter-Service, standardmäßig 23400 |
Index ID | Der Port des Index-Service, den Sie vorher konfiguriert haben |
Node ID | Die Node ID (auch im vorher angelegten Index zu finden) |
Inspire Generation | Folgende Möglichkeiten stehen zur Auswahl:
|
Username | Der Username, der zum Indizieren verwendet wird. Ist ihre Appliance G6, muss „inspireapi“ verwendet werden. Haben Sie eine G7-Appliance, können Sie beliebige Benutzer verwenden, welche die Rolle „InSpire Index Writer“ haben. Für weitere Information siehe https://help.mindbreeze.com/de/index.php?topic=doc/Konfiguration---Backend-Credentials/index.htm. |
Password | Das Passwort des Benutzers, OHNE Anführungszeichen.
|
Haben Sie bei Inspire Generation das Optionsfeld G7 ausgewählt, stehen Ihnen weitere Einstellungen zur Verfügung:

Einstellung | Beschreibung |
Client ID | Die Client ID des OAuth2 Clients in Keycloak (standardmäßig mindbreeze-inspire-public). |
Client Secret | Ist standardmäßig leer und für den Client „mindbreeze-inspire-public“ nicht notwendig. |
Use external Auth URL | Verwenden Sie diese Option, wenn Sie eine externe Keycloak-Installation verwenden. |
External Auth URL | Die URL der externen Keycloak-Installation, bei dem man sich den Bearer-Token abholen kann: {base-url}/realms/{realm-name}/protocol/openid-connect/token |
Export
Sollte der Funktionstest problemlos verlaufen, ist es noch notwendig, den Job zu exportieren. Dies lässt sich mittels Klick auf das Kontextmenü des jeweiligen Jobs erledigen:
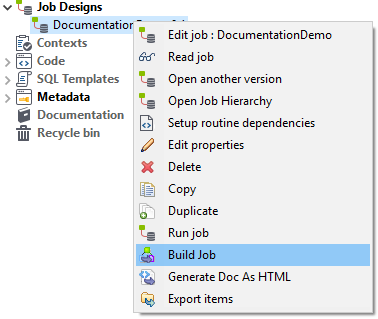
Wichtig ist hierbei, dass das generierte ZIP-File auch entpackt wird.

Die für die Konfiguration von Fabasoft Mindbreeze Enterprise notwendige "Main-Class" kann in dem generierten Batch-File nachgesehen werden.
Konfiguration von Mindbreeze
Aktivieren Sie die Einstellung „Advanced Settings“.
Klicken Sie auf das „Indices“-Tab und danach auf das „Add new index“-Symbol, um einen neuen Index zu erstellen.
Geben Sie den Indexpfad ein, z.B. „C:\Index“. Passen Sie gegebenenfalls den Display Name des Index Service und des zugehörigen Filter Service an:

Fügen Sie eine neue Datenquelle mit dem Symbol “Add new custom source” rechts unten ein.
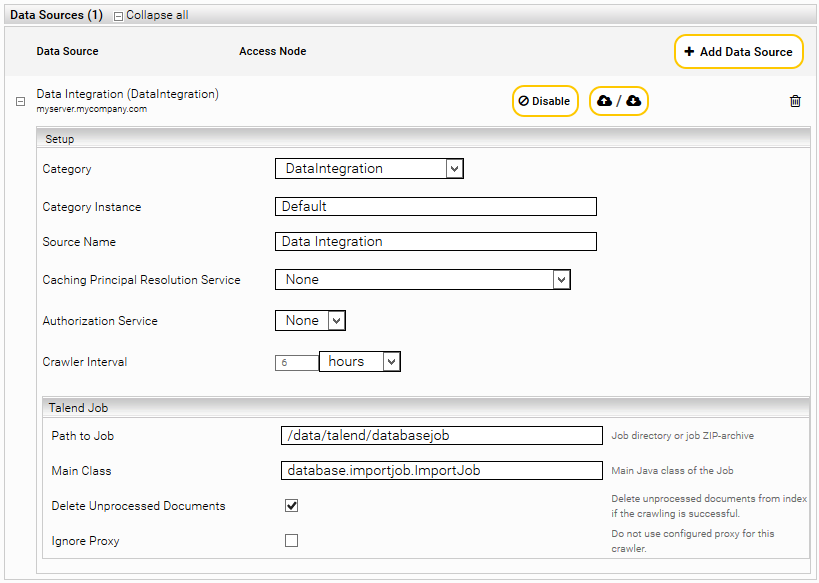
Zur Konfiguration des Crawler müssen Sie das Job ZIP-Archiv oder das extrahierte Job-Verzeichnis in „Path to Job“ und die Java-Klasse des Jobs in „Main Class“ eintragen. Bitte beachten Sie, dass Talend Job Zip-Archive erst ab Mindbreeze InSpire G7 unterstützt werden.
Wenn die Option „Delete Unprocessed Documents“ aktiviert ist, werden nicht-prozessierte Dokumente vom Index gelöscht, wenn das Crawling erfolgreich war. „Erfolgreich“ heißt, dass der exportierte Talend-Job mit Exit-Code 0 beendet wurde.