
Sure, you can handle it. But should you?
Let our experts manage the tech maintenance while you focus on your business.
Let our experts manage the tech maintenance while you focus on your business.
Microsoft SharePoint Connector
Installation und Konfiguration
Tutorial Video: Set up a Microsoft SharePoint Connector
In unserem Tutorial Video zeigen wir alle nötigen Schritte, die zur Einrichtung des Microsoft SharePoint Connectors nötig sind:
https://www.youtube.com/watch?v=yzTyTz1SpXo
Installation
Bevor der Microsoft SharePoint Connector installiert wird, muss sichergestellt werden, dass der Mindbreeze Server bereits installiert ist und dieser Connector auch in der Mindbreeze Lizenz inkludiert ist.
Benötigte Crawling-User Rechte
Der Microsoft SharePoint Connector erlaubt das Crawlen und Durchsuchen von Microsoft SharePoint Elementen und Objekten.
Um eine Microsoft Sharepoint Datenquelle konfigurieren zu können, müssen folgende Voraussetzungen erfüllt sein:
- Die verwendete Microsoft SharePoint Version muss von Mindbreeze InSpire unterstützt werden, siehe Produktinformation – Mindbreeze InSpire.
- Für eine Kerberos Authentifizierung des Service Benutzers auf dem Mindbreeze Node mit der SharePoint Datenquelle muss der Benutzer zumindest Full Read Rechte in der SharePoint Web Applikation besitzen. Kerberos muss als Authentifizierungs - Methode für diese Web Applikation ausgewählt sein.
- Für eine Basis Authentifizierung mittels Benutzernamen und Passwort eines Accounts mit vollen Leserechten auf der SharePoint Web Applikation muss dies in der Mindbreeze Manager Konfiguration unterstützt werden. Für diese Web Applikationen muss Basic Authentication als Authentifizierungsrichtlinie ausgewählt werden.
Ein Benutzer kann wie folgt zu den SharePoint Site Administratoren hinzugefügt werden:
- Central Administration -> Application Management -> Manage web applications
- Web Application -> User Policy (Siehe unten)
- Dem Service-Benutzer “Full Read”-Rechte geben.
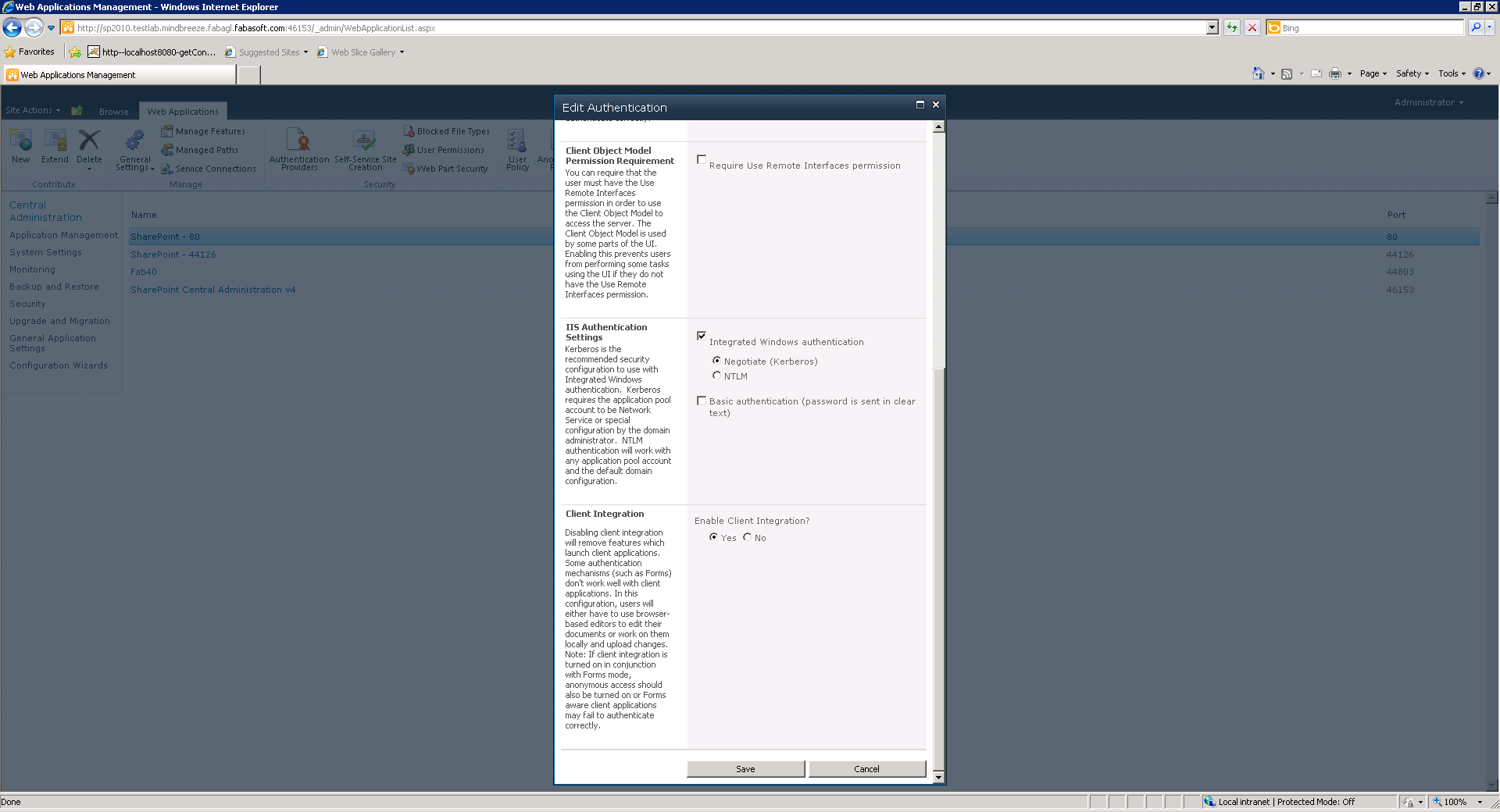
Konfiguration von “Authentication Provider”:
- Navigiere zu Central Administration -> Application Management
- Web Application auswählen
- Authentication Providers konfigurieren (Siehe unten)
- Für NTLM und Basic Authentication soll der Benutzer-Name und Passwort im Mindbreeze Konfiguration eingegeben werden. (Siehe Abschnitt 2.1)
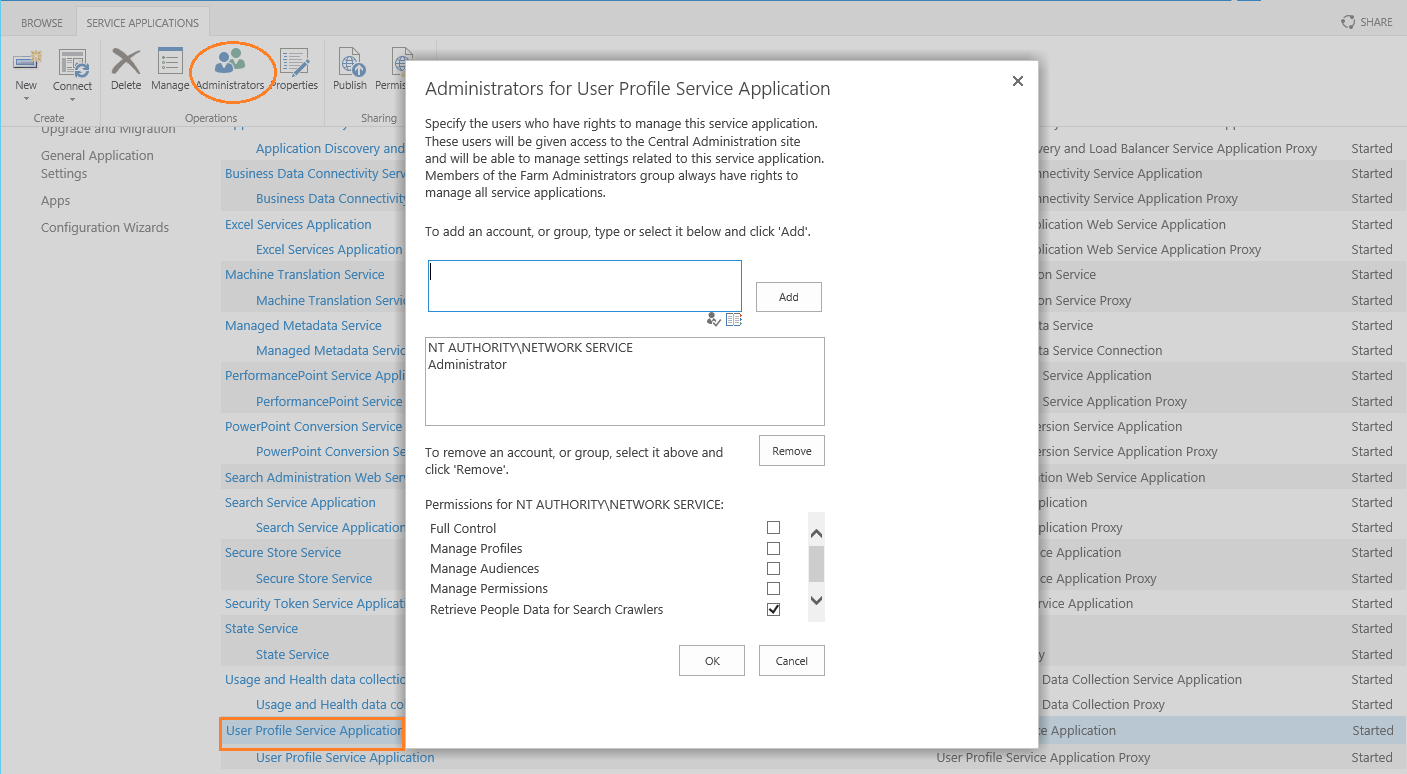
- Für das Crawlen von Benutzerprofile in SharePoint 2013 muss der Service Benutzer zur List der Search Crawlers hinzugefügt werden.
Dafür navigieren Sie zu Central Administratation Manage service application User Profile Service Application und fügen Sie den Service Benutzer zur Liste der Search Crawlers hinzu. (Siehe unten):

Installation von Services für Microsoft SharePoint
Die Services für Microsoft SharePoint müssen folgendermaßen installiert werden:
- Login auf dem SharePoint Server dessen Seiten vom Connector gecrawlt werden sollen.
- Öffnen des ISAPI Verzeichnisses in SharePoint. Wird die Standard Installation verwendet, lautet der Verzeichnispfad C:\Program Files\Common Files\Microsoft Shared\web server extensions\14\ISAPI (SharePoint 2010) und C:\Program Files\Common Files\Microsoft Shared\web server extensions\15\ISAPI (SharePoint 2013)
- Laden die das „Mindbreeze Microsoft SharePoint Connector.zip“ auf https://www.mindbreeze.com/inspire-updates.html herunter. Das ZIP enthält unter anderem die Prerequisites (Systemvoraussetzungen). Kopieren Sie diese Dateien aus den MicrosoftSharePointConnector-{{version}}-prerequisites.zip in den ISAPI Verzeichnispfad (siehe Schritt 2).
- Die Konnektivität des Web Servers kann mit folgenden URLs verifiziert werden:
http://mycomp.com/_vti_bin/GSBulkAuthorization.asmx
http://mycomp.com/_vti_bin/GSSiteDiscovery.asmx
http://mycomp.com/_vti_bin/GssAcl.asmx
http://mycomp.com ist die SharePoint Seiten URL. Nachdem die oben genannten URLs geöffnet wurden, sollten alle Web Methoden des Web Services sichtbar sein.
Installation des Sharepoint SSL Zertifikats für Java
Speichern Sie die SSL Zertifikat des Sharepoints z.B. in c:\temp\sharepointserver.cer:

Installation:
<jre_home>/bin>keytool -import -noprompt -trustcacerts -alias sharepointserver.cer -file /tmp/sharepointserver.cer -keystore ../lib/security/cacerts –storepass changeit
Konfiguration von Mindbreeze
Wählen Sie die “Advanced” Installation:
Klicken sie auf “Indices” und auf das “Add new index” Symbol um einen neuen Index zu erstellen.
Eingabe eines neuen Index Pfades z.B, “/data/indices/sharepointt”. Falls notwendig muss der Display Name des Index Services und des zugehörigen Filter Services geändert werden.
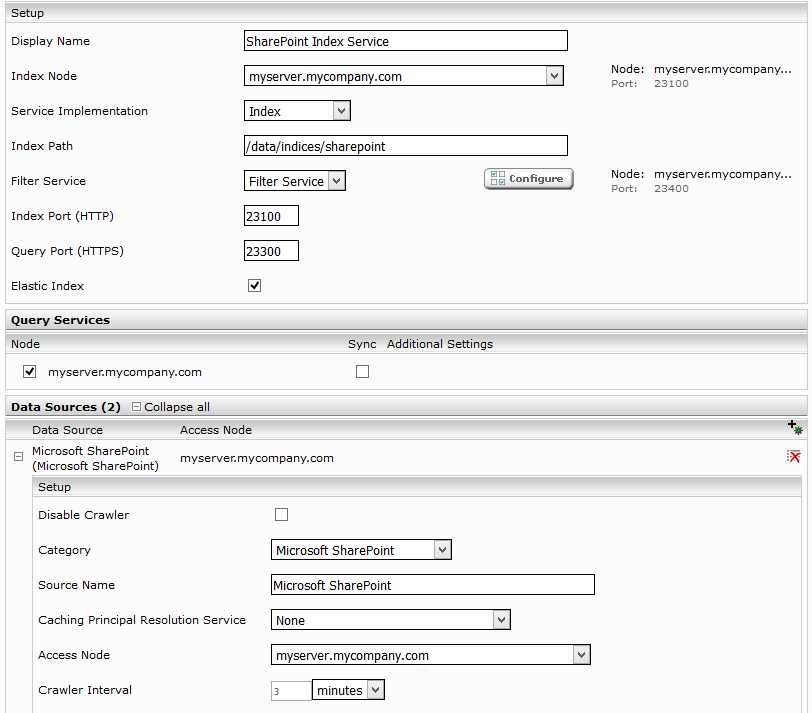
Mit “Add new custom source” unten rechts kann eine neue Datenquelle hinzugefügt werden.

Konfiguration der Datenquelle
Microsoft Sharepoint Connection
Diese Information wird nur für Basic Authentifizierung benötigt:
- SharePoint Server URL: Um den gesamten Inhalt von Microsoft SharePoint zu crawlen, muss der URL von Microsoft SharePoint Servers in das Feld eingegeben werden. Es ist auch möglich nur eine bestimmte SharePoint Site URL hier einzutrage. Damit wird nur diese Site gecrawlt. Die Anmeldedaten für diese Site sollen über Endpoints im Network Registerkarte konfiguriert werden wenn kein Kerberos Authentisierung vewendet wird. SharePoint Server URL und Location Feld im Endpoint müssen identisch sein.
- Logon Account For Principal Resolution, Domain und Password: Falls ein „Principal Resolution Cache“ Service oder Kerberos verwendet wird, sind diese Anmeldedaten nicht notwendig.
Wenn ein Sharepoint Principal Cache verwendet wird, können die Anmeldeinformationen nicht in der Datenquelle definiert werden. Sondern sie werden im Network-Reiter unter Credentials einmal konfiguriert und für mehrere SharePoint Server URLs unter Endpoints ausgewählt.

Beschreibung | |
Use Claims | Dadurch werden zusätzlich die Claims in ACLs hinzugefügt. Wenn Auto ausgewählt ist werden Claims nur bei Auswahl der Use WS-Federation Authentication Option zur ACLs hinzugefügt. |
Use WS-Federation Authentication | Dadurch werden Federation Authentication Cookies von SharePoint (ADFS) mit dem gegebenen Credentials erzeugt und für die Authentisierung zum SharePoint Server verwendet.
|
WS-Federation Authentication Token Renewal Interval | Nach diesem Intervall werden Federation Authentication Cookies erneuert und für Authentisierung verwendet. |
Webservice Timeout (seconds) | Ermöglicht clientseitige Timeoutkonfiguration für SharePoint Webservice Anfragen, die länger dauern könnten. Webservice Anfragen können zusätzlich von in IIS, SharePoint (web.config) und Loadbalancer konfigurierten Timeouts beeinflußt werden. |
Caching Principal Resoution Service
Hier kann einer der folgenden drei Caching Principal Resolution Services ausgewählt werden. SharepointACLReferenceCache wird nur für sehr große Datenmenge empfohlen.
- CachingLdapPrincipalResoution: wenn ausgewählt, wird es für das Auflösen der AD Gruppenmitgliedschaft eines Benutzers bei der Suche verwendet. Die SharePoint Gruppen in den ACLs müssen aber während des Crawlens aufgelöst werden. Dafür muss „Resolve Sharepoint Groups“ ausgewählt werden. „Use ACLs References“ darf nicht ausgewählt werden. „Normalize ACLs“ kann ausgewählt werden. Für die Konfiguration von LDAP Caching Principal Resolution Service siehe Caching Principal Resolution Service.

- SharepointPrincipalResolutionCache: wenn ausgewählt, wird es für das Auflösen der SharePoint Gruppenmitgliedschaft eines Benutzers bei der Suche verwendet. Dieser Service löst die AD Gruppenmitgliedschaft des Benutzers ebenfalls auf. Deswegen ist nicht mehr notwendig „Resolve Sharepoint Groups“ auszuwählen. „Use ACLs References“ darf dabei nicht ausgewählt werden. „Normalize ACLs“ kann ausgewählt werden (Siehe auch Abschnitt: Konfiguration von SharePointPrincipalResolutionCache).

- SharepointACLReferenceCache: wenn ausgewählt, werden während des Crawlens die URLs von SharePoint Site, SharePoint Liste und Ordner des Dokuments als ACL gespeichert um das Crawlen zu beschleunigen. „Use ACLs References“ muss dafür ausgewählt werden. „Resolve Sharepoint Groups“ und „Normalize ACLs“ dürfen nicht ausgewählt werden (Siehe auch Abschnitt: Konfiguration von SharepointACLReferenceCache).

Crawl URLs
Der SharePoint Crawler entdeckt am Anfang alle SharePoint Sites eines SharePoint Servers „SharePoint Server URL“. Alternative kann man in das Feld „Include Sites File“ den Pfad einer CSV Datei hinterlegen, wo nur bestimmte Sites (URLs) eingetragen sind, die indiziert werden sollen. Weiterhin ist es möglich die zu crawlenden Daten auf bestimmte Seiten (URLs) zu limitieren. Dafür kann man in das Feld “Included URL” diese Seiten (URLs) mit einer Regular Expression einschränken. Es ist auch möglich, Seiten (URLs) auszuschließen oder nicht zu crawlen. Diese Seiten müssen in das Feld “Excluded URL” mit eine Regular Expression eingeschränkt werden. Eine Regular Expression muss „regexp:“ oder „regexpIgnoreCase:“ Präfix haben.
Für das Crawlen von Benutzer Profilen muss „Crawl User Profile“ ausgewählt werden und die „MySite URL“ und „Collection Name for User Profiles“ entsprechend konfiguriert werden.
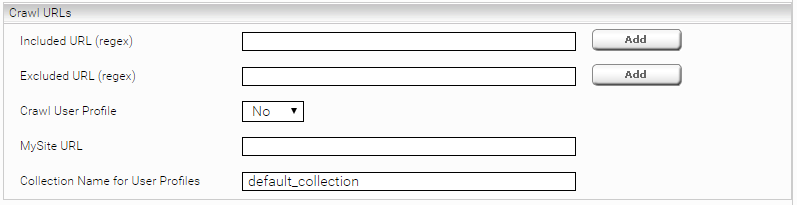
Sites Restrictions
Es ist zu beachten, dass folgende Einschränkungen nach der Anwendung von „Include URL“ und „Exclude URL“ angewendet werden. D.h. eine Site URL, die durch das Anwenden der „Exclude URL“ Regel exkludiert ist, wird nicht gecrawlt auch wenn es in dem „Include Sites File“ steht.

Beschreibung | |
All Sites File | Ist der Pfad zu einer CSV Datei mit den Site URLs, die gecrawlt werden. Die erste Zeil soll URL sein und weitere Zeilen SiteCollection URLs. Wenn dieses Feld leer ist, werden alle Sites durch das SiteDiscovery Service erkannt. |
Include Sites File | Ist der Pfad zu einer CSV Datei mit den Site URLs, die gecrawlt werden ohne der Congruence Class Berechnung, die zu einem Exklude der Site führen kann. Wenn dieses Feld leer ist, werden nur jene Sites gecrawlt, welche der Congruence Class dieses Crawlers entsprechen und nicht in der „Exclude Sites File“ Datei existieren. |
Exclude Sites File | Ist der Pfad zu einer CSV Datei mit den Site URLs, die nicht gecrawlt werden. Wenn dieses Feld leer ist, werden jene Sites gecrawlt, welche der Congruence Class dieses Crawlers entsprechen oder im „Include Sites File“ existieren. |
Congruence Modulus | Die Maximale Anzahl von den Crawlern die alle Sites untereinander verteilen. |
Congruence Class | Es werden nur Sites mit dieses Congruence Class (CRC des Site URLs Modulo Maximale Anzahl von den Crawlern) gecrawlt. |
Security Settings
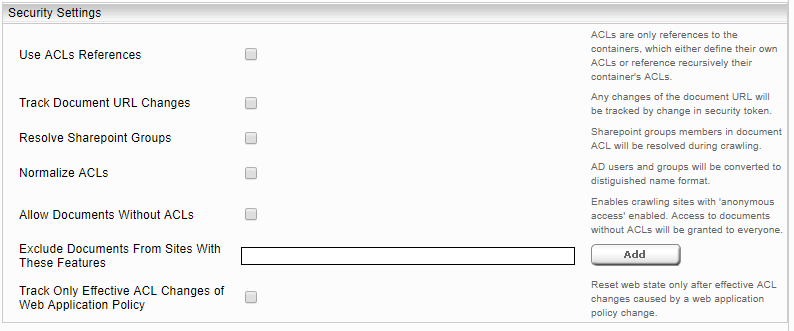
Die Option „Use ACLs References“ soll nur dann ausgewählt werden, wenn „SharepointACLReferenceCache“ als „Principal Resolution Service Cache“ ausgewählt ist (siehe Konfiguration von SharepointACLReferenceCache).
Durch das Verschieben von Dokumente von einem Verzeichnis zum anderen Verzeichnis ändern sich auch URLs dieser Dokumente. Um diese Änderungen auch im Index zu aktualisieren sollte die „Track Document URL Changes“ Option ausgewählt werden.
Wenn die Option „Track Only Effective ACL Changes of Web Application Policy“ nicht ausgewählt ist dann führt eine Änderung der Web Application Policy (z.B. Full Read statt Full Control) zu einer erneuerten Überprüfung der Berechtigung aller Dokumente der Web Application im Index.
„Resolve Sharepoint Groups“ sollte nicht ausgewählt werden, wenn „SharepointPrincipalCache“ als „Principal Resoution Service Cache“ ausgewählt ist (siehe Konfiguration von SharePointPrincipalResolutionCache). Mit der Konfiguration von „Normalize ACLs“ werden alle AD Benutzer und Gruppen in ACLs in Distinguished Name Format umgewandelt. Für das Crawlen von SharePoint Seiten mit anonymer Zugriffsrechten muss „Include Documents without ACLs“ ausgewählt werden. Um SharePoint Seiten durch aktivieren von bestimmten Feature vom Crawlen auszuschließen ist es notwendig die ID (GUID) von diesen Features im Feld „Exclude Documents From Sites With These Features“ einzutragen.
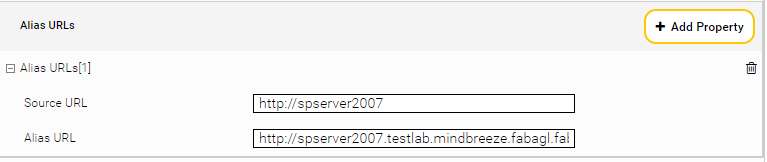
Alias URLs Mapping
„Alias URLs“ ermöglichen es, interne URLs von Sharepoint zu überschreiben und zu indizieren. Das ist nur dann notwendig wenn der Benutzer keine Zugriffsrechte auf diese interne URLs haben. Die Alias URLs sind entsprechend der „Alternative Access Mapping“ am Sharepoint Server zu konfiguriert.

In der SharePoint Konfiguration muss die externe URL konsistent als FQDN-Eintrag konfiguriert sein:
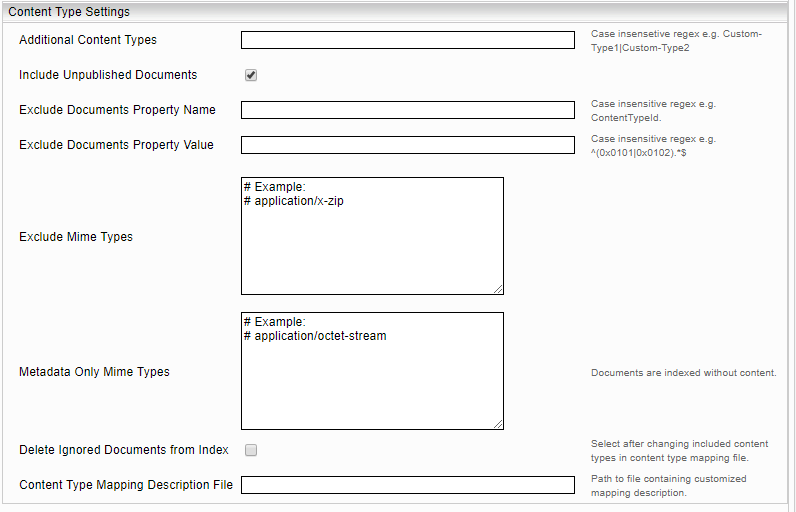
Content Type Settings
Um nicht publizierte Dokumente crawlen zu können, muss von „Include Unpublished Documents“ Auswahlliste „Enabled“ selektiert werden. Beim Auswahl von „Last Major Version“ werden der Inhalt und Metadaten der zuletzt publizierten Version der Draft Dokumente indiziert. Stellen Sie sicher, dass mindestens die Version 20.3 der Systemvorraussetzungen (Enthält MesLists.asmx) auf dem SharePoint-Server installiert ist.
Um weitere spezifische Inhaltstypen crawlen zu können, müssen diese dem „Additional Content Types“ Muster entsprechen. Der SharePoint Connector verwendet eine vorkonfigurierte Content Type Mapping Description XML Datei, die in der Connector Archivdatei vorhanden ist. Falls eine spezifische Änderung erwünscht ist kann diese Datei bearbeitet werden und in einem anderen Verzeichnis gespeichert werden. Um diese bearbeitete Konfiguration zu verwenden ist es notwendig im „Content Type Mapping Description File“ Feld der Pfad zur der bearbeitete Datei einzutragen. In Content Type Mapping Description Datei kann man Regeln für bestimmte Inhaltstypen definieren. Z.B. nur Dokumente von Inhaltstype „Document“ zu crawlen. Daher kann es sein, dass nach der Änderung von dieser Regel das Löschen von bereits indizierten anderen Inhaltstypen vom Index notwendig wird. Mit der Option „Delete Ignored Documents From Index“ können dann diese Dokumente vom Index gelöscht werden.
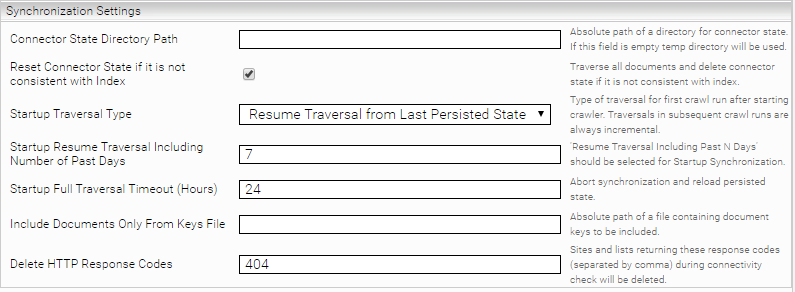
Synchronization Settings
Beschreibung | |
Connector State Directory Path | Ist der Pfad zu einem Verzeichnis in dem der Crawler den Zustand der bereits indizierten Dokumente persistiert, welcher nach einem Crawl-Run bzw. Neustarten des Crawlers verwendet wird. Wenn dieses Feld leer ist wird im /tmp ein Verzeichnis angelegt. |
Reset Connector State if it is not consistent with index | Wenn der crawler Status nicht konsistent mit dem Indexstatus ist, wird er gelöscht und ein voller Indizierungslauf gestartet. Wird diese Option deaktiviert, so wird der Status nicht gelöscht. |
Startup Traversal Type | Der crawler speichert lokal sein Zustand vom letzten Lauf. Dadurch wird das Abgleichen einzelner Dokumente im Index mit denen vom Sharepoint Server vermieden. Manchmal, wegen Transport oder Filter Problemen, kann es passieren dass dieser Zustand von Index abweicht. Um diese Abweichung zu korrigieren ist die „Full Traversal“ oder „Resume Traversal Including Past N Days“ Option auszuwählen und „Startup Resume Traversal Including Number of Past Days“ entsprechend konfigurieren, wenn „Full Traversal“ zu lange dauern würde. Die Sychronization gilt nur für den ersten Crawlrun nach dem starten des Crawlers. Alle weitere Crawruns benutzen den gespeicherten Zustand und sind inkrementell. |
Startup Resume Traversal Including Number of Past Days | |
Startup Full Traversal Timeout (Hours) | Gibt eine Anzahl von Stunden an, nach dem das Synchronisieren abgebrochen und er gespeicherte Zustand verwendet wird. |
Include Documents Only From Keys File | Ist der Pfad zu einer CSV Datei mit den Keys die nochmals indiziert werden. Dadurch werden ausschließlich nur diese Dokumente aus dem SharePoint gecrawlt und indiziert. Es wird empfohlen vorher das „Connector State“ Verzeichnis zu sichern. |
Delete HTTP Response Codes | Am Ende eines Crawl-Runs werden zusätzlich alle Sites bzw. Listen aus dem Index gelöscht, welche diese HTTP Response Codes nach einem HTTP Zugriff (connectivity check) liefern. |
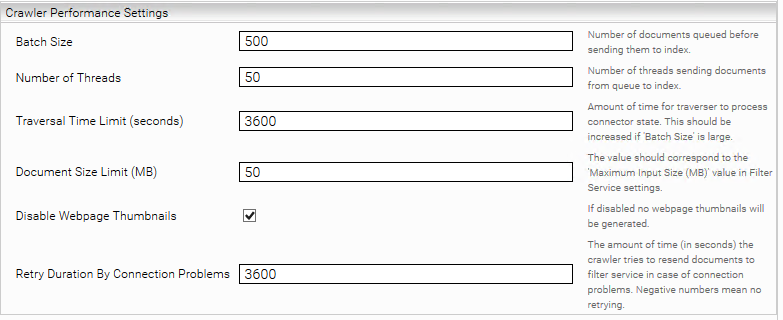
Crawler Performance Settings

Beschreibung | |
Bach Size | Definiert die Anzahl von Dokumente die von Sharepoint Server geholt werden, bevor sie zum Index geschickt werden. |
Number of Threads | Threads, die parallel die gesammlten Dokumente an Index schicken. |
Traversal Time Limit (seconds) | |
Document Size Limit (MB) | Dieses Wert muss „Maximum Input Size (MB)“ von Filter Service entsprechen. |
Disable Webpage Thumbnaiils | Falls ausgewählt werden für die Seiten keine Thumbnails generiert. |
Retry Duration On Connection Problems (Seconds) | Die maximale Anzahl an Sekunden, für die versucht wird bei Verbindungsproblemen bzw. wärend Syncdelta ein Dokument an den Filter/Index Service erneut zu schicken. |
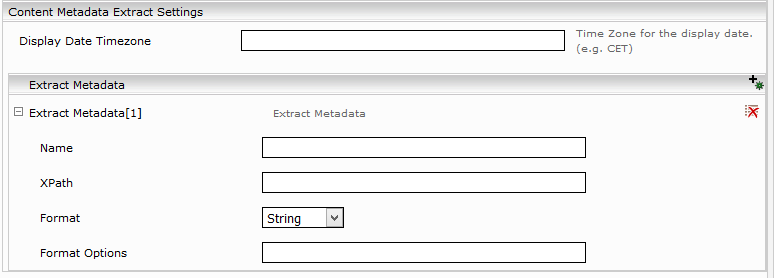
Content Metadata Extract Setting
Um Metadaten aus dem HTML Inhalt zu extrahieren wird folgende Konfiguration benötigt.
Beschreibung | |
Display Date Timezone | |
Extract Metadata | |
Name | Der Name des Metadatums. |
XPath | Der Pfad zum Metadatumswert. |
Format | String, Datum, URL, Path und Signatur. |
Format Options | Format Optionen, beispielsweise beim Datum das Simpledateformat. |
Debug Settings
Enthält Einstellungen für Diagnosezwecke.
Beschreibung | |
Threads Dump Interval (Minutes) | Bestimmt das Zeitintervall (in Minuten), in dem regelmäßig Thread Dumps in das Log-Verzeichnis abgelegt werden. Ein Wert kleiner 1 deaktiviert die Funktion. (Standardwert: -1) |
Bearbeiten von Microsoft Office Dokumenten im SharePoint
Beim Öffnen der Office Dokumente vom Suchresultat im Internet Explorer können die geöffneten Dokumente bearbeitet und im SharePoint gespeichert werden. Dafür werden Schreibrechte auf das Dokument benötigt. Bei der Verwendung anderer Browser werden die Dokumente schreibgeschützt geöffnet.
Konfiguration der integrierten Authentifikation des Microsoft SharePoint Crawlers
Windows:
Wenn die Installation auf einem Microsoft Windows Server durchgeführt wird, kann die Kerberos Authentifizierung des aktuellen Mindbreeze Services für den Microsoft SharePoint Crawler benutzt werden. In diesem Fall muss der Service Benutzer für die Microsoft SharePoint Web Services authentifiziert sein.
Linux:
Siehe Dokument: „Konfiguration - Kerberos Authentfizierung“
Caching Principal Resolution Service
In den folgenden Kapiteln wird die Konfiguration von SharepointPrincipalCache und SharePointACLReferenceCache erklärt. Für mehr Informationen über das Erstellen, das grundlegende Konfigurieren eines Cache für einen Principal Resolution Service und weitere Konfigurationsoptionen, siehe Installation & Konfiguration - Caching Principal Resolution Service.
Konfiguration von SharepointPrincipalCache
- Wählen Sie im neuen oder bestehenden Service in der Einstellung „Service“ die Option SharepointPrincipalCache aus.

- Geben Sie den „SharePoint Server URL“ an. Konfigurieren Sie die benötigte Anmeldeinformation im Karteireiter Network unter Endpoints. „Include URL“ und „Excluded Sites URL“ Felder sollen mit den gleichnamigen Felder von Crawler gleich sein.
- Use Claims ermöglicht es, dass zusätzlich die Claims in Sharepoint Groupenmitgliedern hinzugefügt werden. Wenn Auto ausgewählt ist werden Claims nur bei Auswahl der Use WS-Federation Authentication Option hinzugefügt.
- Use WS-Federation Authentication ermöglicht es, dass Federation Authentication Cookies von SharePoint (ADFS) mit dem gegebenen Credentials erzeugt werden und für die Authentisierung zum SharePoint Server verwendet.
- https://blogs.technet.microsoft.com/askpfeplat/2014/11/02/adfs-deep-dive-comparing-ws-fed-saml-and-oauth/
- https://msdn.microsoft.com/en-us/library/bb498017.aspx
- Mit WS-Federation Authentication Token Renewal Interval kann man das Intervall für das erneuern von Federation Authentication Cookies konfigurieren.
- Webservice Timeout (seconds) ermöglicht clientseitige Timeoutkonfiguration für SharePoint Webservice Anfragen, die länger dauern könnten. Webservice Anfragen können zusätzlichen von in IIS, SharePoint (web.config) und Loadbalancer konfigurierten Timeouts beeinflußt werden.

- Im “LDAP Persisted Cache Service Port” Feld geben Sie den bereits konfigurierte “Webservice Port” des LDAP Principal Resolution Service an. In der SharePoint Crawler Konfiguration sollte die Option „Resolve Sharepoint Groups“ nicht ausgewählt sein. Für die Konfiguration von LDAP Caching Principal Resolution Service siehe Caching Principal Resolution Service.

- Mit der Option „SharePoint Site Groups Resolution Threads“ wird die Anzahl der Threads die parallel die SharePoint Gruppen der Sites finden, konfiguriert. Die Option “SharePoint Site Group Members Resolution And Inversion Threads” legt die Anzahl von Threads die parallel die SharePoint Gruppenmitglieder finden fest. Die Option „Suppress External Service Calls“ verhindert, dass während der Suche externe Services z.B. LDAP oder SharePoint abgefragt werden.




- Mit folgenden Parametern ist es möglich die SharePoint Gruppen von nur bestimmten Sites zu speichern.
- All Sites File: Ist der Pfad zu einer CSV Datei mit den Site URLs, die gecrawlt werden sollen. Wenn dieses Feld leer ist, werden alle Sites durch das SiteDiscovery Service erkannt.
- Include Sites File: Ist der Pfad zu einer CSV Datei mit den Site URLs, die gecrawlt werden sollen.
- Exclude Sites File: Ist der Pfad zu einer CSV Datei mit den Site URLs, die nicht gecrawlt werden sollen.
LDAP Settings

Einstellung | Beschreibung |
Use LDAP Principals Cache Service | Ist diese Option aktiviert, werden die Gruppenmitgliedschaften aus dem Parent Cache zuerst berechnet und dessen Ergebnisse an den Child-Cache geliefert. Damit kann der aktuelle Cache die Ergebnisse des Parent Cache zum Nachschlagen nutzen. |
LDAP Principals Cache Service Port | Der Port der für die Option „Use LDAP Principals Cache Service“ verwendet wird, falls diese aktiviert ist. |
Konfiguration von SharepointACLReferenceCache
- Wählen Sie im neuen oder bestehenden Service in der Einstellung „Service“ die Option SharepointACLReferenceCache aus:
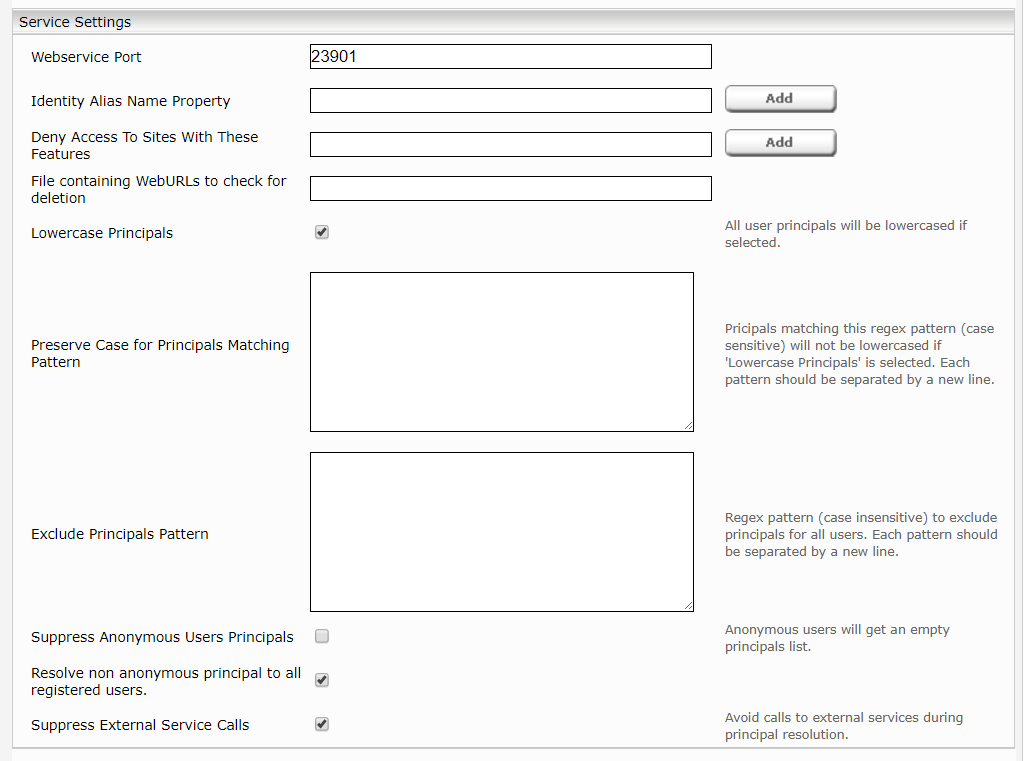
- Geben Sie den „SharePoint Server URL“ an. Konfigurieren Sie die benötigte Anmeldeinformation im Karteireiter Network unter Endpoints. „Include Sites File“, „Include URL“, „Excluded Sites URL“, Exclude Sites With These Features“, „Resolve Sharepoint Groups“ kann nur dann ausgewählt werden, wenn der Port von „CachingLdapPrincipalResolution“ Service im „Parent Service Port“ eingegeben ist. „Normalze ACLs“ Feld soll dann wie beim Crawler konfiguriert werden.
- Use Claims erlaubt, dass zusätzlich die Claims in ACLs hinzugefügt werden. Wenn Auto ausgewählt ist werden Claims nur bei Auswahl der Use WS-Federation Authentication Option zur ACLs hinzugefügt.
- Use WS-Federation Authentication erlaubt, dass Federation Authentication Cookies von SharePoint (ADFS) mit dem gegebenen Credentials erzeugt und für die Authentisierung zum SharePoint Server verwendet wird.
https://msdn.microsoft.com/en-us/library/bb498017.aspx
- WS-Federation Authentication Token Renewal Interval ermöglicht, dass nach diesem Intervall Federation Authentication Cookies erneuert werden.
- Webservice Timeout (seconds) ermöglicht clientseitige Timeoutkonfiguration für SharePoint Webservice Anfragen, falls sie länger dauern sollten. Webservice Anfragen können von zusätzlichen in IIS, SharePoint (web.config) und Loadbalancer konfigurierten Timeouts beeinflußt werden.

- Mit folgenden Parameter ist es möglich die SharePoint ACLs von nur bestimmten Sites zu speichern.
- All Sites File: Ist der Pfad zu einer CSV Datei mit den Site URLs, die gecrawlt werden sollen. Wenn dieses Feld leer ist, werden alle Sites durch das SiteDiscovery Service erkannt.
- Include Sites File: Ist der Pfad zu einer CSV Datei mit den Site URLs, die gecrawlt werden sollen.
- Exclude Sites File: Ist der Pfad zu einer CSV Datei mit den Site URLs, die nicht gecrawlt werden sollen.
- Im “Parent Service Port” Feld geben Sie den bereits konfigurierte “Webservice Port” des SharepointPrincipalResolutionCache Service an (siehe Kapitel: Konfiguration von SharepointPrincipalCache). Wenn “Resolve Sharepoint Groups” im Crawler ausgewählt ist, kann hier das LDAP Principal Resolution Service Port verwendet werden und die Option “Resolve Sharepoint Groups” muss ausgewählt werden.

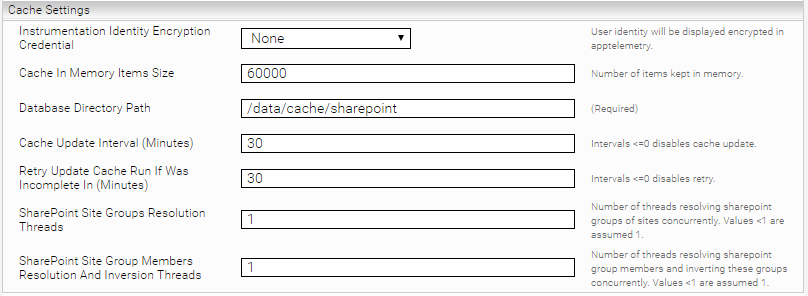
Database Settings
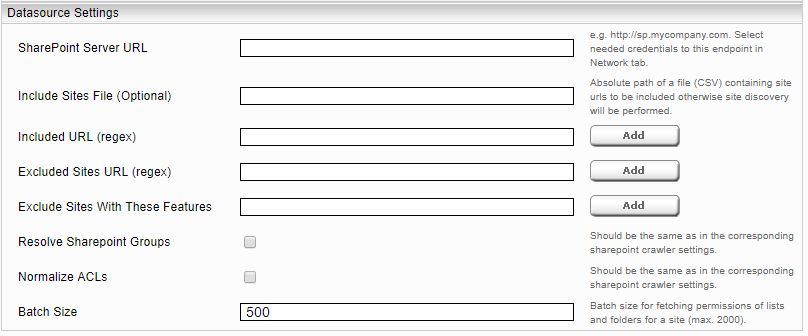
Einstellung | Beschreibung |
Identity Encryption Credential | Mit dieser Option kann man die Benutzeridentität verschlüsselt in der app.telemetry anzeigen lassen. |
Cache In Memory Items Size | Anzahl der im Cache aufbewahrten Items. Abhängig vom verfügbaren Speicherplatz der JVM. |
Database Directory Path | Definiert den Verzeichnispfad für den Cache. Beispiel: /data/principal_resolution_cache Falls man ein Mindbreeze Enterprise Produkt verwendet, muss ein Pfad gesetzt werden. Sollte ein Mindbreeze InSpire Produkt verwendet werden, muss der Pfad nicht gesetzt werden. Ist der Verzeichnispfad nicht definiert, wird unter Linux folgender Pfad definiert: /data/currentservices/<server name>/data. |
Group Members Resolution And Inversion Threads | Diese Option bestimmt die Anzahl der Threads, die parallel Gruppenmitglieder auflösen und diese Gruppen invertieren. Werte kleiner als 1 werden als 1 angenommen. |
In-Memory Containers Inversion Threshold (Advanced Setting) | Diese Option bestimmt die maximale Anzahl der Gruppen. Wird diese Anzahl überschritten, wird weiterer RAM Speicherverbrauch beim Invertieren durch die Verwendung von Festplatten vermieden. |
Problemlösungsmöglichkeiten
Allgemein können Probleme bei der Indizierung von SharePoint-Datenquellen zuallererst in den entsprechenden Logdateien des Mindbreeze Log-Ordners gefunden werden.
Im Mindbreeze Basis-Log-Ordner gibt es für den konfigurierten SharePoint-Crawler einen entsprechenden Unterordner der z.B. wie folgt heißen könnte:
C:\logs\current\log-mescrawler_launchedservice-Microsoft_SharePoint_Sharepoint+2007
Darin befindet sich dann für jeden Crawl-Lauf ein Datums-Unterordner und darin zwei Log-Dateien:
- log-mescrawler_launchedservice.log: Log-Datei mit allen relevanten Log-Informationen und möglichen Fehlern
- mes-pusher.csv: CSV-Datei mit SharePoint-URLs die vom Crawler gefunden wurden und deren Status
Sollte die Datei mes-pusher.csv nicht auftauchen, gibt es vermutlich ein Konfigurations- oder Berechtigungsproblem, welches anhand der Fehlermeldungen in der ersten Log-Datei analysiert werden muss.
Crawling User Unauthorized
Problem-Verhalten:
Der Crawler bekommt keine Dokumente von SharePoint und erzeugt auch keine Datei-Liste in der Logdatei mes-pusher.csv.
In der Logdatei log-mescrawler_launchedservice.log ist eine Fehlermeldung folgender Art zu finden:
com.mindbreeze.enterprisesearch.gsabase.crawler.InitializationException: Invalid connector config: message Cannot connect to the given SharePoint Site URL with the supplied Domain/Username/Password.Reason:(401)Unauthorized
oder:
com.mindbreeze.enterprisesearch.gsabase.crawler.InitializationException: Unable to set connector config, response message: Cannot connect to the Services for SharePoint on the given Crawl URL with the supplied Domain/Username/Password.Reason:(401)Unauthorized, status message:null, status code:5223 (INVALID_CONNECTOR_CONFIG)
oder:
enterprise.connector.sharepoint.wsclient.soap.GSBulkAuthorizationWS INTERNALWARNING: Can not connect to GSBulkAuthorization web service. cause:(401)Unauthorized
Problembeschreibung und -lösung:
Aufgrund von Berechtigungsproblemen ist es dem verwendeten Service-Benutzer nicht möglich Datei-Auflistungen von SharePoint abzufragen.
Folgende Punkte sind zu prüfen:
- Verwendete Authentisierungsmethoden bei SharePoint/IIS prüfen:
- Soll Integrated/Kerberos Authentisierung verwendet werden, muss das Mindbreeze Node Service unter diesem Benutzer-Account laufen.
- Für NTLM/Basic Authentisierung muss der Service-Benutzer in der Mindbreeze Konfiguration der SharePoint Datenquelle eingetragen sein.
- Berechtigungen des verwendeten Service-Benutzers in SharePoint prüfen
- GssSiteDiscovery.asmx und GSBulkAuthorization.asmx Webservice testen (siehe später)
- Testen Sie auch das Öffnen der SharePoint Dokument-Seiten sowie das Öffnen ausgewählter Dokumente aus SharePoint über einen Web-Browser ausgehend vom Mindbreeze Server mit dem konfigurierten Service-Benutzer
SharePoint URL
FQDN
Problem:
Der Crawler bekommt keine Dokumente von SharePoint und erzeugt auch keine Datei-Liste in der Logdatei mes-pusher.csv.
In der Logdatei log-mescrawler_launchedservice.log ist eine Fehlermeldung folgender Art zu finden:
com.mindbreeze.enterprisesearch.gsabase.crawler.InitializationException: Unable to set connector config, response message: The SharePoint Site URL must contain a fully qualified domain name., status message:null, status code:5223 (INVALID_CONNECTOR_CONFIG)
Problembeschreibung und Lösung:
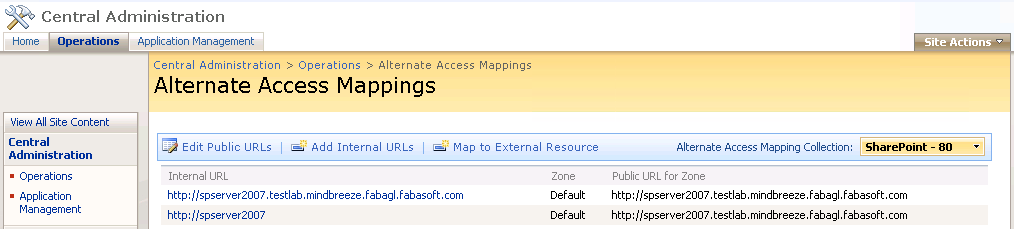
Für den Mindbreeze SharePoint Connector ist es essentiell, dass der SharePoint-Server über den FQDN-Hostnamen angesprochen wird.
- Sowohl in der SharePoint Konfiguration muss die externe URL konsistent als FQDN-Eintrag konfiguriert sein (siehe SharePoint „Operations“ > group „Global Configuration“ > „Alternate access mappings“)
- Auch in der Mindbreeze-Konfiguration muss diese externe (FQDN) URL als Crawling Root konfiguriert sein.
Alternate Access Mapping
Problem:
Der Fehler „ACL Change Detection failed“ wird beim ersten Crawl-Durchgang in SharePoint angezeigt. In der Regel bedeutet dies, dass der Such-Crawler Probleme beim Lesen oder Erkennen der Berechtigungen (Access Control Lists, ACLs) für den Inhalt hat.
In der Logdatei log-mescrawler_launchedservice.log ist eine Fehlermeldung folgender Art zu finden:
enterprise.connector.sharepoint.wsclient.soap.GSAclWS INTERNALWARNING: ACL change detection has failed. endpoint [ https://spse.testlab.mindbreeze.fabagl.fabasoft.com:28443/sites/mindbreeze/_vti_bin/GssAcl.asmx ]. cause:Server was unable to process request. ---> The Web application at https://spse.testlab.mindbreeze.fabagl.fabasoft.com:28443/sites/mindbreeze could not be found. Verify that you have typed the URL correctly. If the URL should be serving existing content, the system administrator may need to add a new request URL mapping to the intended application.
Problembeschreibung und Lösung:
In der SharePoint-Konfiguration muss für die vom Crawler genutzte URL eine Public URL konfiguriert werden, die idealerweise der „Default“-Zone oder einer speziell eingerichteten Zone (z. B. Custom) zugeordnet ist:

SharePoint Webservices mit SOAP-Calls mittels curl testen
Um Berechtigungsprobleme sowie Probleme mit den SharePoint Webservices zu analysieren kann man von der Kommandozeile aus SOAP-Calls mittels curl absetzen und das Ergebnis der einzelnen SOAP-Calls analysieren.
Das Kommandozeilen Tool curl wird mit Mindbreeze InSpire (für Microsoft Windows) in folgendem Ordner mit ausgeliefert: C:\setup\tools\curl\bin und muss nur mehr zur Microsoft Windows Umgebungsvariable PATH hinzugefügt werden um einfach verwendbar zu sein.
SOAP-Calls vorbereiten
Die Vorgehensweise zur Vorbereitung der SOAP-Calls für die einzelnen Tests ist immer die gleiche und wird hier einmalig anhand eines Beispiels beschrieben und kann für alle Checks analog angewandt werden.
Als Beispiel verwenden wir CheckConnectivity von GSSiteDiscovery.asmx
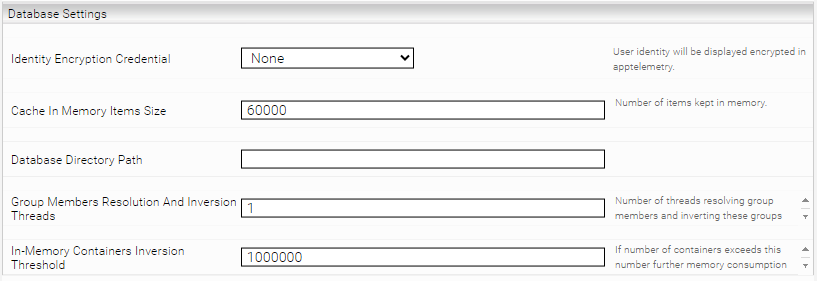
Das entsprechende SharePoint Webservice im Browser öffnen und die gewünschte Aktions-Methode für den Test auswählen um den Content der abgeschickt werden muss zu bekommen.
Der Einfachheit halber verwenden wir die Interface-Beschreibung für SOAP 1.2 und kopieren den XML-Content des ersten Blocks (Request Teil) in eine Datei und speichern den Inhalt unter einem frei wählbaren Namen (z.B. C:\Temp\sp-site-check.xml).
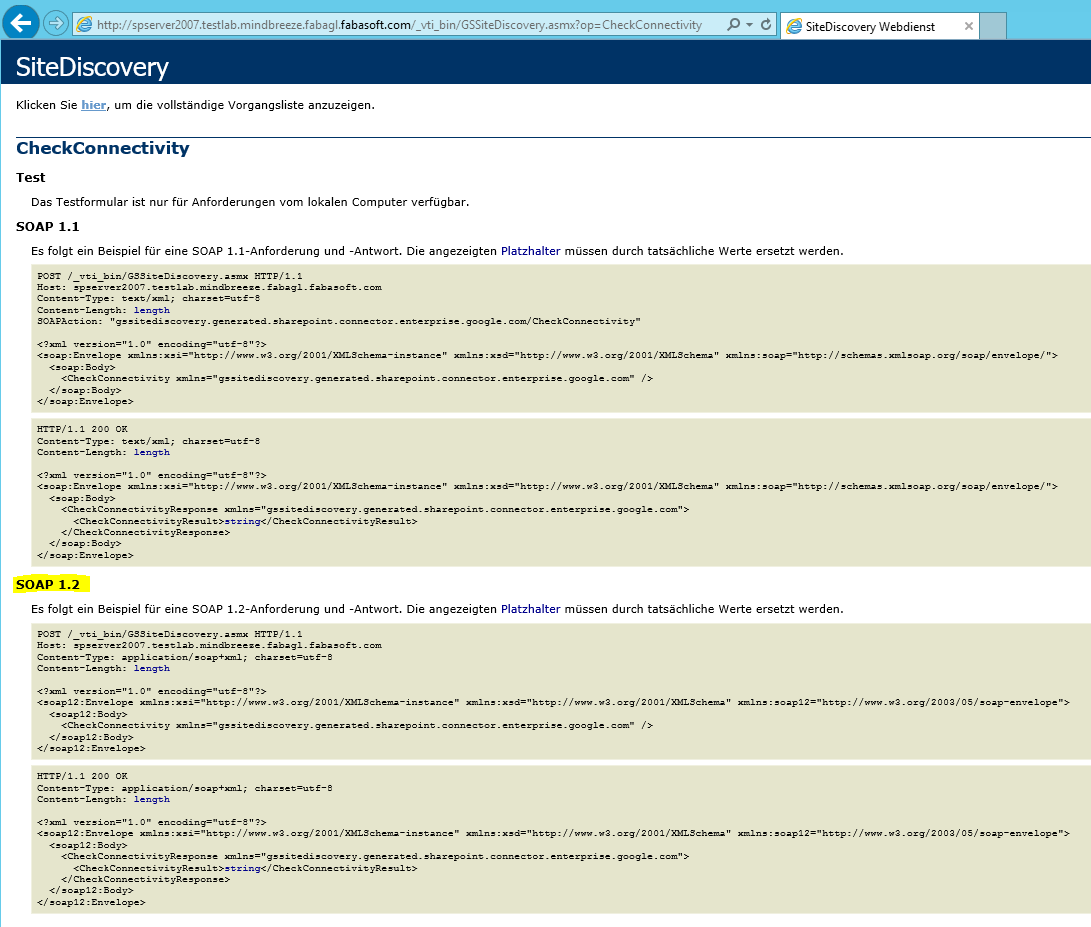
Je nach Interface-Definition müssen möglicherweise gewisse Werte im XML-Content an die eigene Infrastruktur angepasst werden.
SOAP-Calls testen
Aufbauend auf dem vorbereiteten Beispiel testen wir nun den SOAP-Call mittels curl in einem Commandline-Fenster:
Man wechselt in den Ordner, in dem auch die XML-Content-Datei liegt und führt das curl-Kommando analog zu folgendem Beispiel aus: (<Werte in spitzer Klammer> sind entsprechend zu ersetzen)
C:\Temp>curl --ntlm --user <testlab\domainsrv>:<MYPASSWORD> --header "Content-Type: application/soap+xml;charset=utf-8" --data @<sp-site-check.xml> http://<spserver2007.testlab...>/_vti_bin/GSSiteDiscovery.asmx
Die Ausgabe wird direkt angezeigt, kann aber auch in eine Datei umgeleitet werden: > out.xml
Folgende SharePoint Webservices und Methoden können Probleme relativ rasch aufdecken:
- http://<spserver2007.testlab>/_vti_bin/GSSiteDiscovery.asmx
- CheckConnectivity: sollte success zurückliefern
- GetAllSiteCollectionFromAllWebApps: benötigt einen SharePoint Admin-Account!
- http://<spserver2007.testlab>/_vti_bin/GSBulkAuthorization.asmx
- CheckConnectivity: sollte success zurückliefern
- http://<spserver2007.testlab>/Docs/_vti_bin/GssAcl.asmx (dieser Test sollte auf das Unterverzeichnis in dem die SharePoint-Dokumente liegen (Bsp.: /Docs) ausgeführt werden)
- CheckConnectivity: sollte success zurückliefern
- GetAclForUrls: das ist der erste Test bei dem die Content-XML-Datei angepasst werden muss (siehe unterhalb) … man gibt z.B. die Basis AllItems.aspx URL an, in der alle Dokumente enthalten sind, oder die SharePoint-URL eines ausgewählten Dokuments und sollte alle berechtigen Benutzer in der Antwort zurückbekommen …
GetAclForUrls Content-XML:
<?xml version="1.0" encoding="utf-8"?>
<soap12:Envelope xmlns:xsi="http://www.w3.org/2001/XMLSchema-instance" xmlns:xsd="http://www.w3.org/2001/XMLSchema" xmlns:soap12="http://www.w3.org/2003/05/soap-envelope">
<soap12:Body>
<GetAclForUrls xmlns="gssAcl.generated.sharepoint.connector.enterprise.google.com">
<urls>
<string>http://spserver2007.testlab.mindbreeze.fabagl.fabasoft.com/Docs/Documents/Forms/AllItems.aspx</string>
<string>http://spserver2007.testlab.mindbreeze.fabagl.fabasoft.com/Docs/Documents/testdoc2_server2007.rtf</string>
</urls>
</GetAclForUrls>
</soap12:Body>
</soap12:Envelope>
SOAP-Call mit curl:
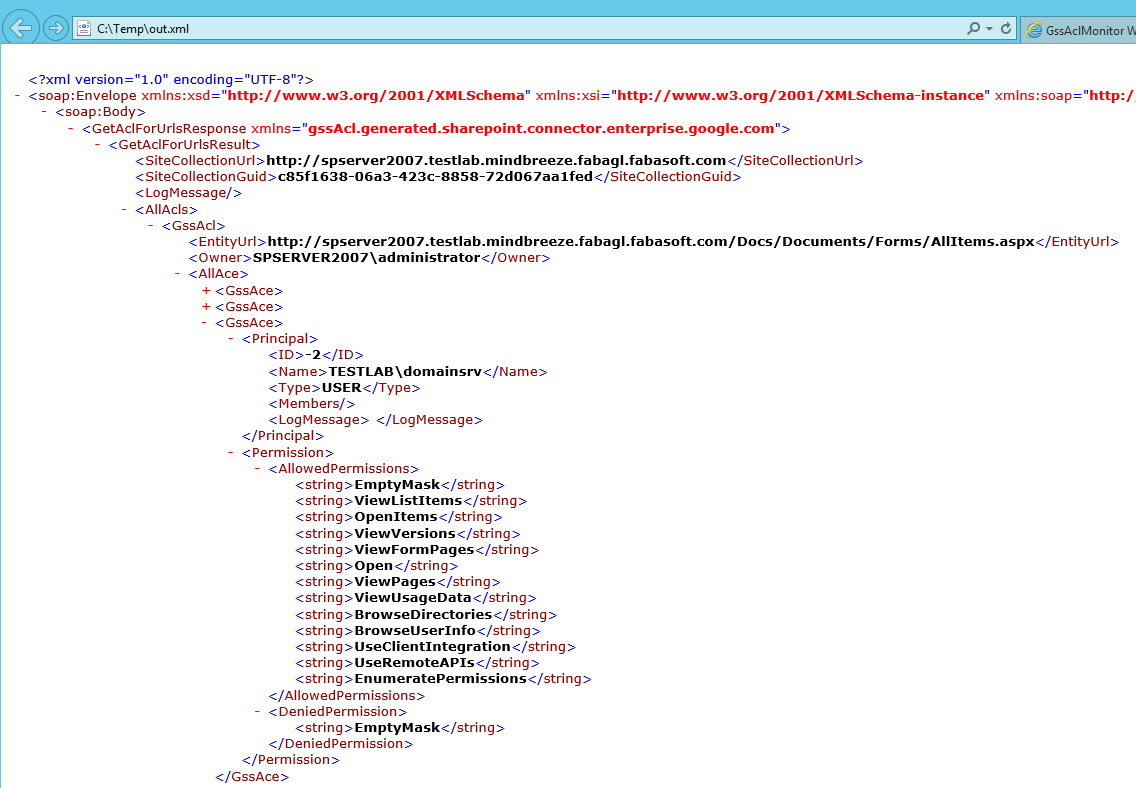
C:\Temp>curl --ntlm --user <testlab\domainsrv>:<MYPASSWORD> --header "Content-Type: application/soap+xml;charset=utf-8" --data @data.xml http://spserver2007.testlab.mindbreeze.fabagl.fabasoft.com/Docs/_vti_bin/GssAcl.asmx > out.xml
Das Ergebnis zeigt dann alle SharePoint-Berechtigungen zu den angegebenen URLs:

Dokumente von Crawler IGNORED
Werden die Dokumente von SharePoint korrekt ausgelesen aber gelangen trotzdem nicht in den Index, ist dies in der Logdatei mes-pusher.csv ersichtlich.
Zeigt die Spalte ActionType den Wert „IGNORED“ an, ist in der Spalte Message der Grund dafür zu finden.
Mögliche Ursachen und deren Lösung:
- IGNORED, property ContentType with value null not matched pattern …
- Haben die zu indizierenden SharePoint Dokumente einen Typ der nicht in der vom Standard-Connector vordefinierten Liste enthalten ist, werden diese ignoriert. Die Liste der zu indizierenden Dokumenttypen kann allerdings in der Mindbreeze Konfiguration mit der Eigenschaft „Additional Content Types“ erweitert werden.
- Unable to generate SecurityToken from acl null
- Können keine ACLs für ein Dokument von SharePoint ausgelesen werden, so wird das Dokument ebenfalls ignoriert. Hier ist zu prüfen ob die Berechtigungen des Service-Benutzers ausreichend sind und ob die gssAcl.asmx Webservice Calls einwandfrei funktionieren.
Konfiguration von Metadatenkonvertierungsregeln in der ConnectorMetadataMapping.xml Datei
Folgende Beispiele zeigen wie man bestimmte Regeln im ConnectorMetadataMapping.xml konfigurieren kann um neue Metadaten aus bestehende Metadaten zu generieren.
Content XPath Konfiguration
<ConversionRule class="HTMLContentRule">
<Arg>//*[@id='ArticleContent'] </Arg> <!-- include XPath -->
<Arg>//*[starts-with(@id, 'ECBItems_']</Arg> <!-- exclude XPath -->
</ConversionRule>
Referenzierung
<Metadatum join="true">
<SrcName>srcName</SrcName> <!—srcName should be item ID -->
<MappedName>mappedRef</MappedName>
<ConversionRule class="SharePointKeyReferenceRule">
<Arg>http://site/list/AllItems.aspx|%s</Arg>
</ConversionRule>
</Metadatum>
String Formatierung
Zusammenführung von Metadaten:
<Metadatum join="true">
<SrcName>srcName1,srcName2</SrcName> <!—join values with ‘|’ -->
<MappedName>mappedName</MappedName>
<ConversionRule class="FormatStringRule">
<Arg>%s|%s</Arg>
</ConversionRule>
</Metadatum>
Trennung von einem Metadatum:
<Metadatum split="true">
<SrcName>srcName</SrcName>
<MappedName>mapped1,mapped2</MappedName> <!-- split srcName value -->
<ConversionRule class="SplitStringRule">
<Arg>:</Arg>
</ConversionRule>
</Metadatum>
Ersetzung von Metadaten:
<Metadatum>
<SrcName>srcName</SrcName>
<MappedName>mappedName</MappedName>
<ConversionRule class="StringReplaceRule">
<Arg>.*src="([^"]*)".*</Arg> <!—regex pattern-->
<Arg>http://myorganization.com$1</Arg> <!-- replacement -->
</ConversionRule>
</Metadatum>