
Sure, you can handle it. But should you?
Let our experts manage the tech maintenance while you focus on your business.
Let our experts manage the tech maintenance while you focus on your business.
Handbuch
Installation und Konfiguration von Mindbreeze InSpire
Einleitung
Dieses Dokument beschreibt die Installation und Konfiguration von Mindbreeze InSpire in einer Microsoft Windows-Systemumgebung.
Mindbreeze InSpire besteht aus:
- Der Mindbreeze InSpire Node dient dazu, an zentraler Stelle Indizes anzulegen, die von Benutzern für ihre Abfragen genutzt werden können.
- Über den Mindbreeze InSpire Management Node können die im Netzwerk verteilten Mindbreeze InSpire Nodes über eine grafische Benutzeroberfläche administriert und konfiguriert werden.
Diese Komponenten können je nach Infrastruktur auf verschiedenen Rechnern installiert werden.
In Kapitel 9 wird die Abfragesprache von Mindbreeze InSpire erklärt.
Softwarevoraussetzungen
Die Informationen in diesem Dokument beziehen sich auf eine Mindbreeze InSpire Systemumgebung und Mindbreeze InSpire 2017 Winter Release.
Voraussetzungen:
- Bitte entnehmen Sie die aktuellen Softwarevoraussetzungen der Software Produkt Information
Die benötigten Installationsprogramme für die genannten Produkte werden auf der Mindbreeze InSpire ZIP/ISO Datei im Ordner Prerequisites mitgeliefert.
Konfiguration von Mindbreeze InSpire
Nach der Installation von Mindbreeze InSpire wird die Benutzeroberfläche zur Konfiguration von Mindbreeze InSpire in einem Webbrowser angezeigt.
Nach der Konfiguration und die Änderungen in einem späteren Zeitpunkt wird es empfohlen die Option „Apply changes and restart on save“ auszuwählen bevor diese Änderungen gespeichert werden. Da die Prozesse dabei neugestartet werden, sollten diese nur während den Wartungszeiten durchgeführt werden.

Registerkarte „Overview“
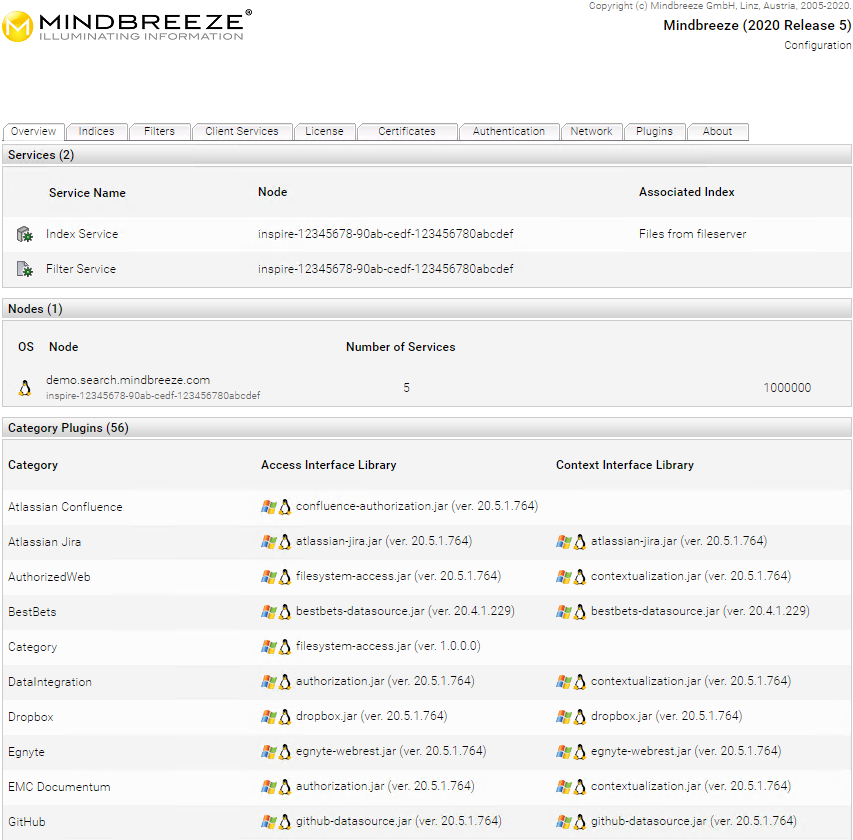
Auf der Registerkarte „Overview“ wird ein Überblick über die aktuell konfigurierten Services, Nodes und Kategorieerweiterungen (Category Plugins) angezeigt.

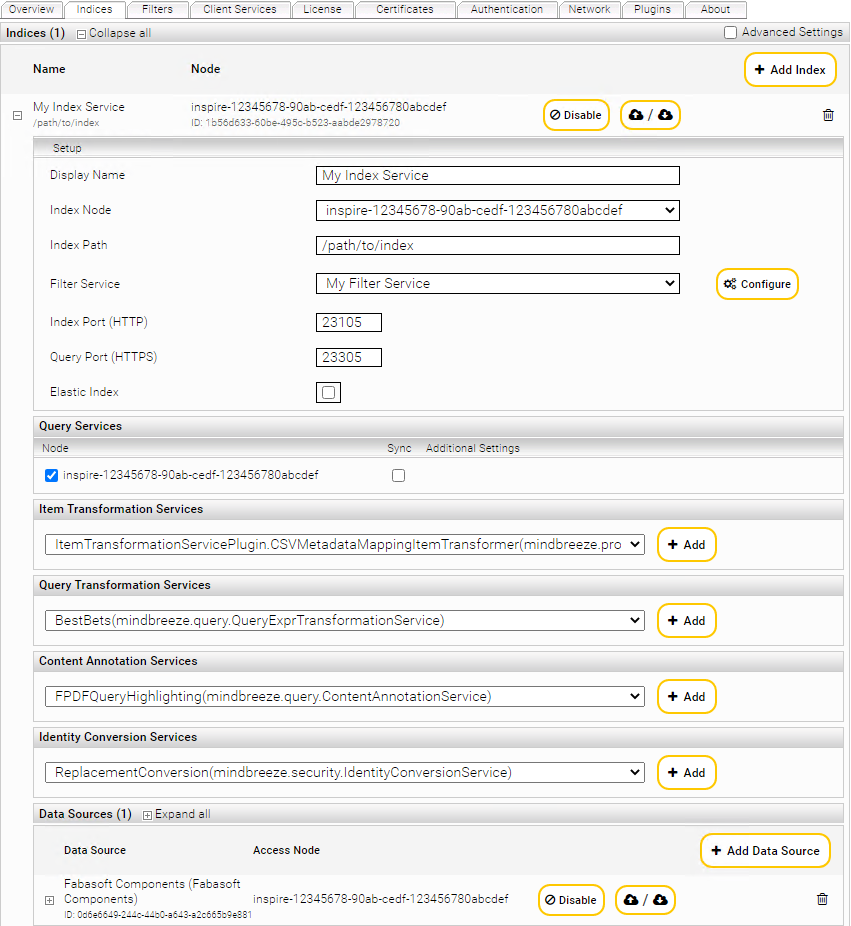
Registerkarte „Indices“
Die Registerkarte „Indices“ dient zur Verwaltung von Index Services. Auf dieser Registerkarte werden alle bestehenden Index Services angezeigt. Diese können bearbeitet und gelöscht werden. Zusätzlich können neue Index Services erzeugt werden.
Einstellungen für ein Index Service können direkt aus einem bereits existierenden Index importiert bzw. exportiert werden. Weitere Details finden Sie im Kapitel Import/Export von Einstellungen.
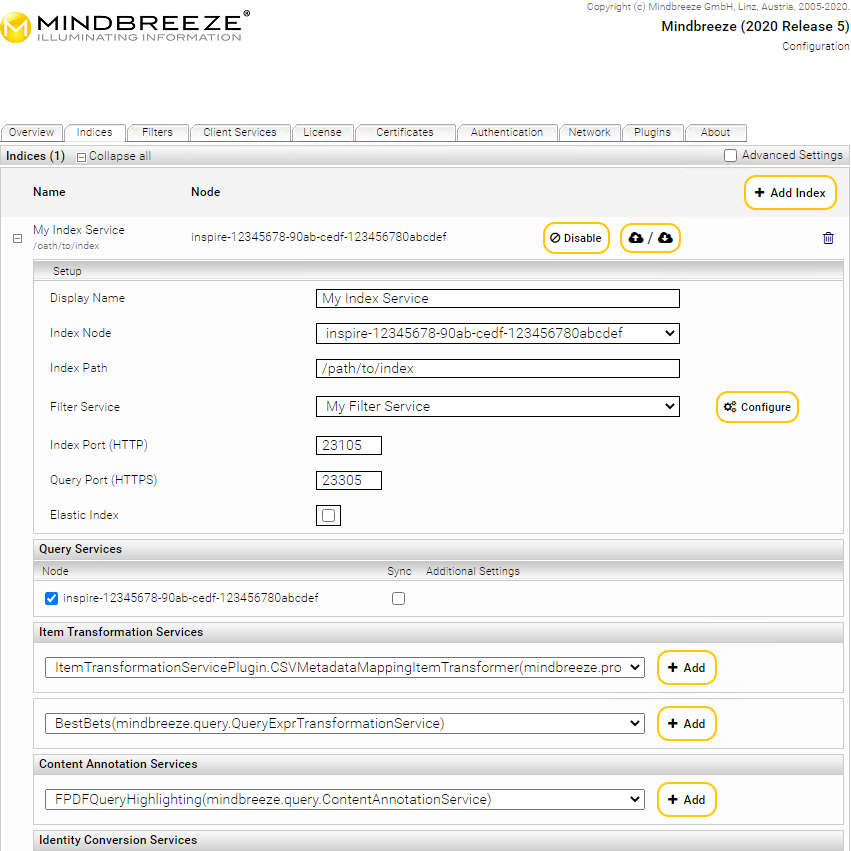
Um im Feld „Indices“ ein neues Index Service zu erzeugen, gehen Sie folgendermaßen vor:
- Klicken Sie auf „+ Add Index“ rechts außen im Kopfbereich der Liste.
- Wählen Sie im folgenden Fenster einen „Index Node“, einen Client Service und eine Datenquelle aus. Bestätigen Sie ihre Auswahl mit „Apply.

Weiters können Sie nun den „Display Name“ und andere Einstellungen vornehmen. Diese Einstellungen werden nachfolgend im Detail erklärt. Speichern Sie mit „Save“, um die Änderungen zu sichern.
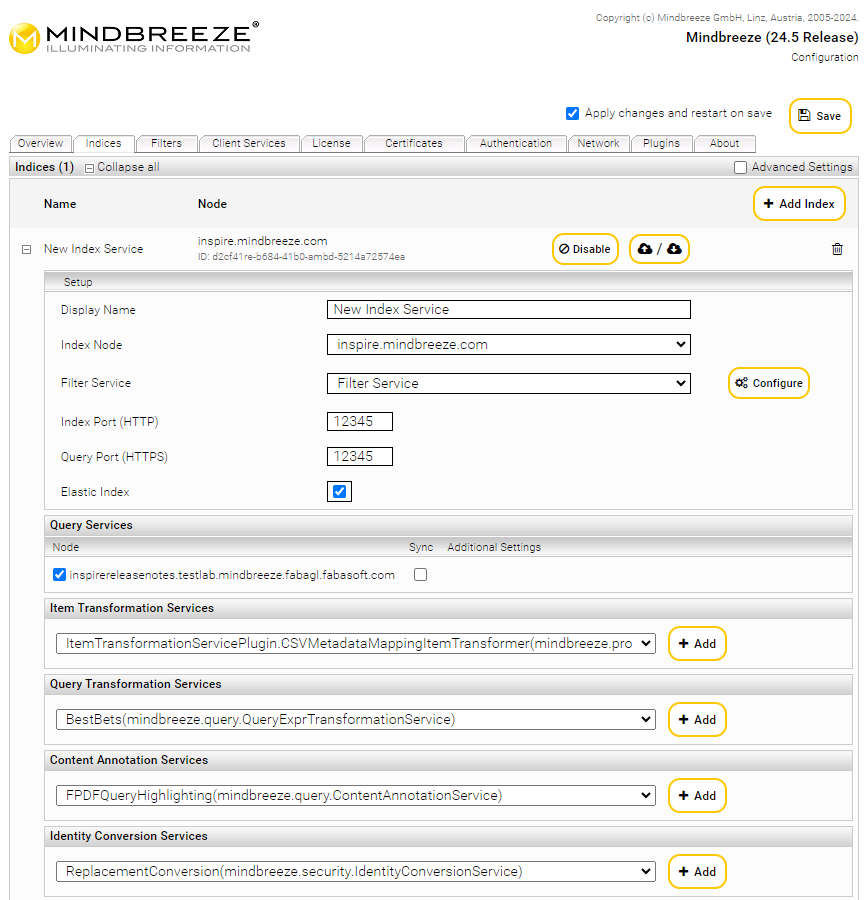
Hinweis: Bei Anklicken von „Enable“ bzw „Disable“ kann man einen bereits erstellten Index temporär ein- oder ausschalten.
Index Service Einstellungen
Im Bereich „Setup“ stehen standardmäßig die Optionen „Display Name“, „Index Node“, „Index Path“ und „Filter Service“ zur Verfügung. Folgende Eigenschaften können über diese Felder konfiguriert werden:
Beschreibung | |
Display Name | In diesem Feld kann ein Name für das Index Service konfiguriert werden. |
Index Node | In diesem Feld wird der Rechner angegeben, auf dem das Index Service ausgeführt wird. |
Index Path | In diesem Feld wird der Pfad zum Indexverzeichnis definiert, in dem die Dateien des Index gespeichert werden. Dieser Pfad befindet sich auf dem Rechner der mit „Index Node“ definiert wurde. |
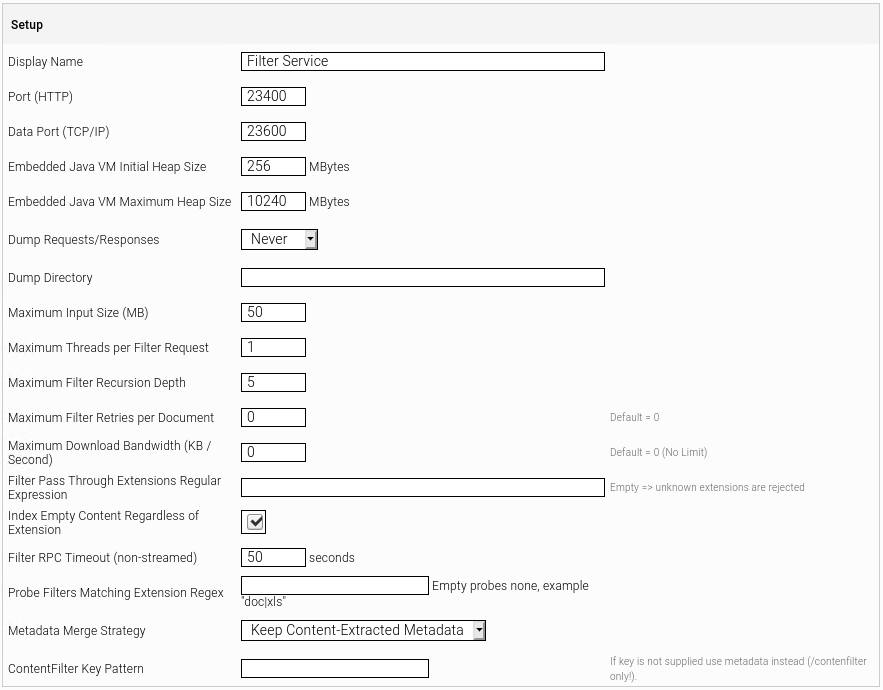
Filter Service | In diesem Kombinationslistenfeld kann ein Filter Service ausgewählt werden, das die zu indizierenden Dateien spezifiziert. Klicken Sie auf die Schaltfläche „Configure“, um das zugehörige Filter Service zu konfigurieren. Sie wechseln automatisch auf die Registerkarte „Filters“. Das zu konfigurierende Filter Service wird dort im Bearbeitungsmodus geöffnet. Mehr zum Thema Filter finden Sie im Abschnitt Registerkarte „Filters“.
Hinweis: Bei Bedarf können über das Kontrollkästchen Advanced Settings weitere Optionen eingeblendet werden. |
Query Services | Im Bereich „Query Services“ können aus allen bestehenden Query Services jene ausgewählt werden, über die das Index Service zur Verfügung gestellt werden soll. |
Data Sources | Im Bereich „Data Sources“ kann eine Datenquelle angegeben werden, die indiziert werden soll. Mehr zu diesem Thema im folgenden Unterabschnitt. |
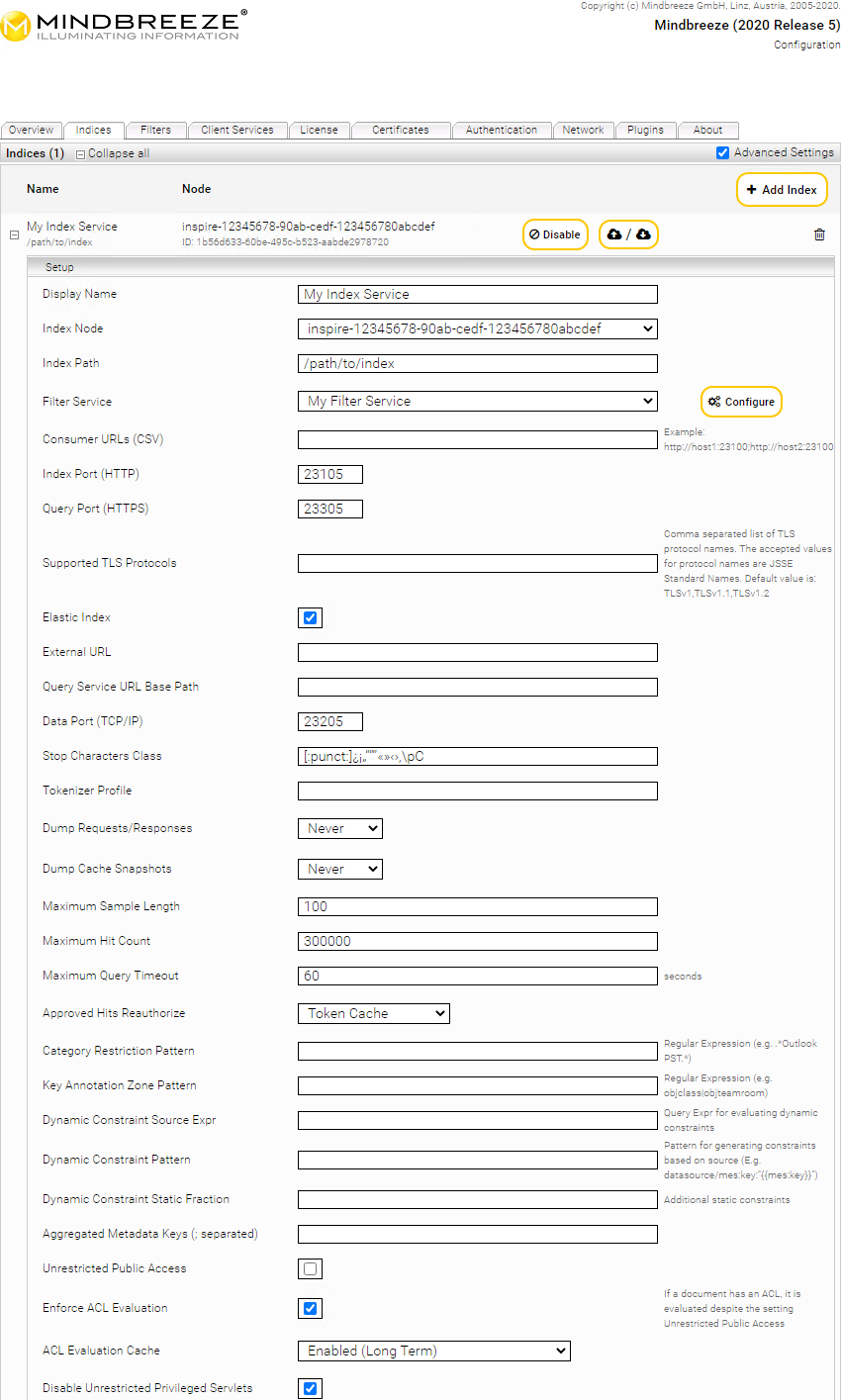
Um zusätzliche Einstellungsmöglichkeiten für einen Index zu erhalten, klicken Sie nun wieder auf die Registerkarte „Indices“ und klicken Sie rechts oben auf das Feld „Advanced Settings“.
Sie erhalten folgende zusätzliche Einstellungsmöglichkeiten:
Bereich: Setup | |||||||||||
Einstellung | Beschreibung | ||||||||||
Supported TLS Protocols | Erlaubt die vom Query Service unterstützten TLS Protokolle zu konfigurieren. Hier kann eine, mit Beistrich getrennte Liste von JSSE Protokollnamen angegeben werden. | ||||||||||
External URL | Sollte das Query Service hinter einem Load Balancer, der unter einem anderen Hostnamen erreichbar ist, betrieben werden, so ist hier die externe URL des Loadbalancers inklusive des Pfades (siehe „Query Service URL BASE PATH“) einzutragen. | ||||||||||
Query Service URL Base Path | Erlaubt der Query Service URL eine andere URL als den Default Root („/“) Basispfad zu benutzen. Das wird vor allem benötigt, wenn ein Query Service hinter einem zentralen Reverse Proxy, der URL-Pfade nicht umschreiben kann, verwendet wird. | ||||||||||
Data Port (TCP/IP) | TCP-Port, der zur Kommunikation mit Subsystemen verwendet wird. | ||||||||||
Stop Character Class | Dient zur Definition von Trennzeichen für die Worttrennung für diesen Index. Standardmäßig definiert sind alle in Unicode als Trennzeichen definierten Symbole. Sollten Sie diese Einstellung nicht ausfüllen, wird ein werkseitiger Standardsatz von Stoppzeichen verwendet, welcher aus den folgenden Zeichen besteht: [:punct:] ¿ ¡ „ “ ‘ ” ’ « » ‹ › ‚ \pC
! ' # S % & ' ( ) * + , - . / : ; < = > ? @ [ / ] ^ _ { | } ~ Falls dieses Feld nicht leer gelassen wird, werden die hier definierten Stoppzeichen zusätzlich zu den Unicode-Trennzeichen zur Trennung von Wörtern verwendet. Bitte beachten Sie, dass in der Mindbreeze InSpire nach Stoppzeichen nicht gesucht werden kann. | ||||||||||
Tokenizer Profile | Erlaubt die Konfiguration des Worttrennungsverfahrens durch ein Profil. Derzeit stehen zwei Profile zur Auswahl:
| ||||||||||
Dump Requests /Responses | Erlaubt eine erweiterte Fehlersuche und loggt Anfragen und Antworten in das „mesindex-debug-dumps“ Verzeichnis unterhalb des Indexverzeichnis. Bei der Option „On Error“ werden bei jedem auftretenden Fehler automatisch Log-Dateien angelegt. Bei der vorkonfigurierten Option „Never“ werden keine Dumps erzeugt und bei „Always“ für jede Anfrage. Achtung: Aktivieren Sie „Always“ nicht dauerhaft im Produktionsbetrieb. | ||||||||||
Maximum Sample Length | Gibt die maximale Länge eines indizierten Wortes in Zeichen definiert. Das bedeutet, längere Wörter werden nur bis zu dieser Anzahl von Zeichen indiziert. | ||||||||||
Maximum Hit Count | Gibt die maximale Anzahl der intern verarbeiteten Treffer im Index für eine Suchanfrage an. | ||||||||||
Approved Hits Reauthorize | Gibt an ob eine Reautorisierung durch die externe Datenquelle oder den internen Token Cache zu erfolgen hat:
| ||||||||||
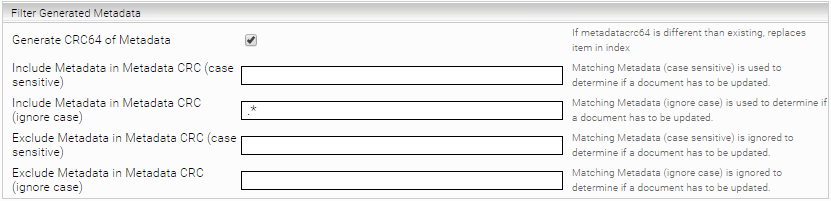
Aggregated Metadata Keys | Konfiguriert jene Metadaten die für den Benutzer zur Aggregation aufbereitet werden sollen. | ||||||||||
Unrestricted Public Access | Bei Aktivierung sind Abfragen auf diesen Index ohne Authentifizierung möglich. Standardeinstellung: Deaktiviert | ||||||||||
„Access Control Lists“, kurz „ACLs“, dokumentieren, welche Rollen und Gruppen welche Rechte auf das jeweilige Dokument haben. Beim Suchen von Dokumenten werden die Rollen und Gruppen des Nutzers mit den ACLs der Dokumente verglichen und in die Suchergebnisse in- oder exkludiert. In Kombination mit der Einstellung „Unrestricted Public Access” ergeben sich folgende, sinnvolle Situationen:
Hinweis: Das gleichzeitige Aktivieren/Deaktivieren der Einstellungen Unrestricted Public Access und Enforce ACL Evaluation ist möglich, kann aber unübliche oder problematische Verhaltensweisen erzeugen. Dies wird daher nicht empfohlen. Standardeinstellung: Aktiviert | |||||||||||
ACL Evaluation Cache | Mit dieser Option kann der ACL-Evaluierungscache konfiguriert werden:
| ||||||||||
Suppress Identity Conversion | Keine Benutzernameänderung wird durchgeführt auch keine interne Normalisierung. | ||||||||||
Suppress Internal Identity Conversion | Deaktiviert die Normalisierung von Benutzernamen. Hier wird unter Windows eine Konvertierung von UPN Konvention in NETBIOS Benutzernamen durchgeführt. Sollte dies nicht notwendig sein, kann diese Option deaktiviert werden. | ||||||||||
Use Authentication Cache | Ist standardmäßig deaktiviert und erlaubt das Cachen von zwischenspeicherbaren Autorisierungsergebnissen innerhalb eines “Authentication Cache Flushing Intervals”. | ||||||||||
Enable Security Token Authentication Cache (Deprecated) | Aktiviert das Zwischenspeichern von Security Token. Diese Option ist veraltet und standardmäßig deaktiviert. | ||||||||||
Authentication Cache Flushing Interval | Die Zeit, die man bei dieser Option einstellen kann, gibt die maximale Lebensdauer eines Eintrages für zwischengespeicherte Ergebnisse eines Access-Checks an. | ||||||||||
SyncDelta Wait For Index Production Finished Attempts | In diesem Feld kann für den SyncDelta Vorgang konfiguriert werden, wie oft (im Abstand von 5s) maximal geprüft wird, ob der Index bereits fertig invertiert ist. Bei Überschreiten dieser Maximalanzahl wird der SyncDelta Versuch abgebrochen. | ||||||||||
Documents per Index Bucket | Die maximale Anzahl der Dokumente pro „Bucket“. Wenn diese Einstellung nicht konfiguriert ist, also leer bleibt, wird der Standardwert 60000 angenommen. | ||||||||||
Query Threads per Index | Definiert die maximale Anzahl der Threads, die zum Bearbeiten einer Suchanfrage verwendet wird. Beim Wert 0 wird die Hälfte der CPU-Cores verwendet. Standardwert: 0 | ||||||||||
Term Boost Factor | Hier kann die Relevanzbewertung von Terms gesteuert werden. | ||||||||||
NGram Boost Factor | Hier kann die Relevanzbewertung von NGrams gesteuert werden. | ||||||||||
Use Term Lexicon | Bei Deaktivierung wird das Term Lexicon nicht länger beim Indexaufbau und der Suche berücksichtigt.
| ||||||||||
Embedded Java VM Args (-Xms..) | Erlaubt der Java VM spezifische Werkzeuge wie zum Beispiel "Garbage Collection Control Information" in die JVM einzubinden. | ||||||||||
RPC Request Timeout | Die Zeit die man in dieser Option eingeben kann, gibt die maximale Dauer einer internen RPC Anfrage an, bevor diese abgebrochen wird. | ||||||||||
Bereich: Document Insertion | |
Einstellung | Beschreibung |
Include Modification Date in Document Replacement | Bei abweichender Änderungszeit wird das Dokument ersetzt. |
Include Metadata CRC64 in Document Replacement | Bei abweichender Checksumme über die Metadaten wird das Dokument ersetzt. |
Include Content CRC64 in Document Replacement | Bei abweichender Checksumme über den Content wird das Dokument ersetzt. |
Update Documents In-place | Bei Änderung des Dokumentes wird versucht, das Dokument anstelle des alten Dokuments zu ersetzen, sofern es sich um sicherheitsrelevante Änderungen handeln bzw. die Änderungen den invertierten Index nicht betreffen. |
Wenn diese Option aktiviert ist, werden aktualisierte Dokumente erst dann im Index entfernt, sobald die neue Version gefunden werden kann. Werden mehr als „Maximum Number of Tracked Replaced DocIDs” erreicht, und die neue Version ist noch nicht suchbar, dann ist das Dokument gelöscht, bis die neue Version findbar ist. Mit dieser Option kann gesynct werden, während ein Dokument laufend Updates erhält und ohne dass die Option „Wait for Inversion Completed before Synchronization“ aktiviert werden muss. Siehe auch Verteilter Betrieb (G7) – Index Synchronization Settings. | |
Maximum Number of Tracked Replaced DocIDs | Gibt die maximale Anzahl der Versionen eines Dokuments an, solange ein Dokument weich gelöscht ist, d.h. nicht als gelöscht invertiert wird. Nur wirksam, wenn „Disable Inversion of Replaced Documents“ aktiviert ist. |
Wird ein Dokument innerhalb der in Invert Replaced Document Max Age Seconds konfigurierten Zeit oft ersetzt, wird es trotzdem als ein nicht gelöschtes Dokument invertiert. Wie oft es innheralb dieser Zeit ersetzt werden muss, kann mit Maximum Number of Consecutive Replacements konfiguriert werden. Nur wirksam, wenn „Disable Inversion of Replaced Documents“ aktiviert ist. | |
Invert Replaced Document Max Age Seconds | Siehe Maximum Number of Consecutive Replacements |
Bereich: Indexed Objects Settings | |||||||||
Einstellung | Beschreibung | ||||||||
Hier kann man festlegen, welche Objekte der Index dem Crawler als Gesamtmenge der indizierten Dokumente mitteilt:
Achtung: Diese Einstellung sollte nur für interne Zwecke von Entwicklern und Consultants verwendet werden, wenn man die InSpire Pipeline umändern und testen möchte. Der Grund dafür ist, dass dies eine ineffiziente Art ist, einen vollständigen Crawl Run herbeizuführen. Daher ist die Verwendung dieser Einstellung nur für Testumgebungen geeignet. | |||||||||
Bereich: Inverter Settings | |
Einstellung | Beschreibung |
Reinversion Startup Delay Seconds | Verzögert die Invertierung, damit alle Services, z.B. Item Transformation Service, Zeit haben um sich am Index zu registrieren. |
Wait for Inversion Completed (Final Buckets) before Switching to Readonly | Wenn dieses Setting aktiv ist, wird der Index erst dann readonly gesetzt, sobald alle Buckets, die sich im finalisierenden Zustand befinden (also abgeschlossene Buckets, bei denen lediglich der Inverter läuft), komplett abgeschlossen sind. |
Wait for Merging Complete On Set Bucket Readonly Timeout (Seconds) | Wenn Option Wait for Inversion Completed before Synchronization“ deaktiviert ist, werden nicht-finale Buckets während dem Synchronisieren readonly gesetzt, um sicherzustellen, dass diese in einem stabilen Zustand sind. Nach dem Stoppen des Inverters wird zusätzlich noch gewartet, bis das Mergen der bereits invertierten Dokumente durchgeführt wurde. Standardmäßig wird 20 Minuten (1200 Sekunden) gewartet, bis das Merging abgeschlossen ist. Verstreicht das Timeout, wird eine Warning geloggt und das Bucket dennoch readonly gesetzt. |
Detect and Ignore Non-Text if Content Size is Greater Than or Equal | Um die Erkennung nur für Non-Text Content größer als X zu aktivieren. 0 deaktiviert das Feature. |
Detect and Ignore Non-Text Content Size Unit | Unit Type für „Detect and Ignore Non-Text if Content Size is Greater Than or Equal” Megabyte oder Kilobyte. |
Detect and Ignore Non-Text Content Buffer Size | Buffer Größe für die Erkennung von Non-Text Content setzen. 0 deaktiviert das Feature. |
Detect and Ignore Non-Text Content Buffer Unit | Unit Type für „Detect and Ignore Non-Text Content Buffer Size” Megabyte oder Kilobyte. |
Verify Document Info Merge Result before Use | Wenn aktiviert, wird geprüft, ob das Mergen der Document Info korrekt verlaufen ist. |
Wait for Event Servlet Update Status Inverval (Seconds) | Definiert die maximale Zeit nach dem am Wait-Servlet ein Update versendet wird. Dies kann am Servlet überschrieben werden mit dem Parameter update_interval. Siehe Konfiguration - Index Servlets - Wait |
Enable Indexing Status Events Servlet | Wenn aktiviert, ist das Indexierungsstatus-Servlet, das neu indexierte Dokumente meldet, verfügbar. Siehe Konfiguration - Index-Servlets - Index-Status (/indexingstatus). |
Regulärer Ausdruck, der die Eigenschaften einschränkt, die mit dem Servlet „Index-Status“ angefordert werden können. Wenn das Feld leer bleibt (Standard), sind nur System-Metadaten zulässig. Für mehr Informationen, siehe Konfiguration - Index-Servlets - Index-Status (/indexingstatus). | |
RPC Script to execute on new indexing status events | Legt den Pfad zu einem Skript fest, das als Transformator für neue „Indexing Status Events“ ausgeführt werden soll. Achtung: Die Verwendung eines inkompatiblen Skripts kann die Funktionalität des Index-Servlets „Index-Status“ beeinträchtigen. Ändern Sie diese Einstellung daher nicht ohne Rücksprache mit dem Mindbreeze Support. Weitere Informationen zum Index-Servlet „Index-Status“ finden Sie unter Konfiguration - Index-Servlets - Index-Status (/indexingstatus). |
Bereich: Alternatives Query Spelling Settings | |
Einstellung | Beschreibung |
Alternatives Query Spelling Max Estimated Count | Bei weniger Treffern als in dieser Option eingetragen, werden alternative Suchbegriffe vorgeschlagen. |
Force Alternatives Query Spelling Max Estimated Count | Wenn diese Option ausgewählt ist, kann die Option "Alternative Query Spelling Max Estimated Count" nicht durch Optionen in der vom Client-Dienst gesendeten Suchanfrage überschrieben werden. |
Bereich: Query Expansion Settings | |
Einstellung | Beschreibung |
Disable Query Expansion for Diacritic Term Variants | Mit dieser Option kann die Ausweitung der Suche auf diakritische Varianten des Suchwortes für das Query Service unterbunden werden. |
Bereich: Reference Settings | |
Einstellung | Beschreibung |
Inverted Reference Metadata Keys | Kann konfiguriert werden, um inverse Referenzen mithilfe der Mindbreeze Property Expression Language aufzulösen. Falls mehrere Metadata Keys konfiguriert werden sollen, müssen diese mit Strichpunkten getrennt werden. |
Hash Reference Target Metadata Keys | Kann konfiguriert werden, um inverse String-Referenzen mithilfe der Mindbreeze Property Expression Language aufzulösen. Geben Sie hier die Metadata Keys (mit Strichpunkt getrennt) an, auf die referenziert werden. Die hier angegeben Metadata Keys müssen aggregierbar sein (z.B. via Aggregated Metadata Keys). Konfigurieren Sie auch die Inverted Hash Reference Metadata Keys. |
Inverted Hash Reference Metadata Keys | Kann konfiguriert werden, um String-Referenzen mithilfe der Mindbreeze Property Expression Language aufzulösen. Geben Sie hier die Metadata Keys (mit Strichpunkt getrennt) an, von denen aus auf andere Dokumente referenziert werden. Zum Beispiel: „Dokument 1“ referenziert Person „Max Mustermann“ mit Metadatum author_email: max.mustermann@example.com. Die Person „Max Mustermann“ hat das Metadatum email: max.mustermann@example.com. Damit (inverse) String-Referenzen funktionieren, konfigurieren Sie folgende Optionen:
Bitte beachten Sie, dass die hier angegeben Metadata Keys aggregierbar sein müssen (z.B. via Aggregated Metadata Keys). |
Enable Find All References For Source | Optimierung für String-Referenzen. Ist nur wirksam, wenn Inverted Hash Reference Metadata Keys konfiguriert ist. |
Forced Reference Target Properties | Standardmäßig werden Forward-Referenzen (nicht String-Referenzen) via Metadata Key mes:key aufgelöst. Mit dieser Option kann pro FQCategory der Metadata Key überschrieben werden, der zum Auflösen der Referenzen verwendet wird. Zum Beispiel: Forced Reference Target Properties: Web:mindbreeze:page_id, dann werden alle Referenzen bei Dokumenten mit FQCategory: Web:mindbreeze mit dem Metadatum page_id statt mes:key aufgelöst. |
References Repair Bulk Update Size | Die Anzahl an Updates, die innerhalb einer Transaktion durchgeführt werden, wenn repairreferences aufgerufen wird. Standard: 100 Siehe auch Reparatur von Referenzen. |
Bereich: Query Transformation Service Settings | |
Einstellung | Beschreibung |
Query Transformation Service Plugin Processing Timeout (ms) | In dieser Option kann für Query Transformation Services ein zeitliches Limit für Transformationen gesetzt werden. Standardmäßig ist das Limit auf 200ms gesetzt, d.h. bei einer Suche wird auf jede Transformation maximal diese Zeit gewartet. Benötigt eine Transformation länger als das Timeout, dann wird diese Transformation übersprungen. Das Timeout gilt für alle Query Transformation Plugins pro Transformation. Ein Wert kleiner oder gleich 0ms bedeutet, dass kein Limit konfiguriert ist. |
Einstellung | Beschreibung | ||||||
Use Additive Doc Boosting | Bestimmt die Boosting-Strategie bei mehrfachen Boostings eines Dokuments. Standardmäßig ist das „Additive Doc Boosting“ aktiviert, welche alle Boostings auf einem Dokument zum Berechnen der Relevanz berücksichtigt. Falls die Einstellung deaktiviert ist, wird nur das jeweils höchste Boosting zum Berechnen der Relevanz verwendet. | ||||||
Default Restricted Categories for Did You Mean | “Did You Mean”-Vorschläge werden nur aus den hier angegebenen Categories berechnet. Wenn leer, werden alle Dokumente aus allen Categories miteinbezogen. Trennen Sie die Categories mit Zeilenumbrüchen oder Strichpunkten. Zum Beispiel: Web;Microsoft File | ||||||
Query Timeout Percentage for Did You Mean | Hier können Sie das „Did You Mean“-Timeout festlegen, nach dem dieses abgebrochen werden soll.
Beispiel:
Gültige Werte: ]0.0,1.0] | ||||||
Max Query Timeout ms for Did You Mean | Obergrenze für das effektive Timeout für "Did You Mean" in Millisekunden. Standardwert = 500 (0 = unbegrenzt, nur "Query Timeout Percentage for Did You Mean" wird verwendet). Beispiel:
| ||||||
Disable Did You Mean Term Count Threshold | “Did You Mean” wird nur dann durchgeführt, wenn die Anzahl der Terme in der Suchanfrage (abzüglich Stopp-Wörtern, falls konfiguriert) den konfigurierten Wert nicht überschreitet. Folgende Werte haben eine spezielle Bedeutung:
| ||||||
Query Performance Einstellungen
Die Einstellungen in diesem Abschnitt dienen zur Verbesserung der Query Performance:

Einstellung | Beschreibung | ||||||||
Ist diese Option aktiv, so werden gelöschte Dokumente früher ausgeschlossen. | |||||||||
Enable Precomputed ACLs | Mit dieser Option werden Dokumente früher ausgeschlossen für die der abfragende Benutzer keine Berechtigungen hat. Dies ist nur dann möglich, wenn keine ACL-Referenzen verwendet werden. Mögliche Werte:
| ||||||||
Number of ACL Precomputation Threads | Diese Einstellung legt fest, wieviele Threads für diese Optimierung verwendet werden. Ist das Feld leer, so wird der Wert der Einstellung “Query Threads per Index” verwendet. | ||||||||
Use ACL Document Filter if Authorized Ratio is Less Than | Die Precompute ACL Optimierung wird nur angewendet, wenn in einem Index weniger als dieser Prozentwert (0.0-1.0) für den abfragenden Benutzer via ACL autorisiert sind. | ||||||||
Reject Empty ACLs | Dokumente mit leeren ACLs werden abgelehnt bei der ACL Vorberechnung. | ||||||||
Wenn Dokumente andere Dokumente referenzieren, kann auf die Metadaten der referenzierten Dokumente zugegriffen werden. Standardmäßig werden dabei die ACLs der referenzierten Dokumente nicht geprüft. Wenn jedoch die Option „Use Precomputed ACLs for DocInfo Access“ aktiviert ist, werden die ACLs der referenzierten Dokumente zusätzlich zur normalen ACL-Prüfung überprüft. Bitte beachten Sie, dass diese Option nur aktiviert werden kann, wenn „Enable Precomputed ACLs“ aktiv ist. | |||||||||
Content Position Sampling Optimization | Mit dieser Option wird ein optimierter Algorithmus für das Sampletexting verwendet. |
Aggregationen Einstellungen

Einstellung | Beschreibung |
Für diese Metadata Keys wird die Aggregation nicht abgebrochen. | |
Collected Aggregation Results Limit | Die Aggregierung wird hier nach Erreichen der hier konfigurierten Anzahl nicht abgebrochen, jedoch nur maximal soviele Resultate zurückgegeben. |
Index-Synchronisierung
Diese Einstellungen sind relevant, wenn Sie Mindbreeze InSpire im Verteilten Betrieb (G7) verwenden.
Einstellung | Beschreibung |
Lässt Sie ein benutzerdefiniertes temporäres Directory festlegen, das für ausgehende Synchronisationsvorgänge verwendet wird. | |
Maximum Number of Final Buckets To Copy | Lässt Sie die Standardanzahl der Buckets, die innerhalb eines Synchronisationsvorgangs kopiert werden, überschreiben. |
Enable Task History Cleanup | Wenn aktiv, werden die letzten Taskstatus-Dateien beim Starten des Index gelöscht. Die maximale Anzahl an gelöschten Dateien kann mit der Option „Maximum Number of Initial Cleaned-Up Task History Entries” verändert werden und liegt standardmäßig bei 500 000. |
Maximum Number of Persistent Task History Entries | Lässt Sie die maximale Anzahl der persistenten Taskstatus-Dateien festgelegen, die lokal abgespeichert werden. Diese Dateien werden durch den Task History Cleanup nicht gelöscht. Standardwert: 10 000 |
Maximum Number of Initial Cleaned-Up Task History Entries | Lässt Sie die maximale Anzahl an Taskstatus-Dateien konfigurieren, die während dem Task History Cleanup gelöscht werden können. Standardwert: 500 000 |
Maximum Number of Synchronization Threads | Lässt die Begrenzung der Anzahl der für einen Synchronisationsvorgang verwendeten Threads zu. |
Wait for Inversion Completed before Synchronization | Wenn aktiv, wird vor dem Synchronisationsvorgang auf die aktuellen Invertierungsvorgänge gewartet, damit die synchronisierten Daten vollständig sind. Standardwert: Aktiviert |
Resolve Index Conflicts on Synchronization | Wenn aktiv, wird versucht, Konflikte bei der Indexsynchronisation implizit aufzulösen. Standardwert: Aktiviert |
Update Non Final Timestamp Strategy | Legt das Verhalten für den Umgang mit aktuell ungenutzten Ressourcen während der Synchronisierung fest. Die folgenden Optionen stehen zur Verfügung:
Achtung: Das Ändern der Standardeinstellung kann zu Leistungseinbußen führen und sollte unter normalen Umständen nicht geändert werden. |
Kompaktifizierung des Index
Werden häufig Dokumente zu einem Index hinzugefügt bzw. entfernt, so kann die Performance auf Dauer darunter leider. Deshalb können Index Buckets mit bereits gelöschten Dokumenten entfernt werden. Die noch vorhandenen Dokumente werden in ein neues Bucket verschoben.
Automatische Kompaktifizierung
Einstellung | Beschreibung |
Permanent Delete Buckets | Wird diese Einstellung deaktiviert, so werden Buckets nicht komplett gelöscht, sondern nur in Sicherungsordner verschoben |
Enable Periodic Delete Buckets | Aktiviert das automatische Kompaktifizieren. |
Periodic Delete Buckets Schedule | Legt den Zeitplan (als Extended Cron Expression) für die automatische Kompaktifizierung fest. Der Wert „0 0 0 * * *“ bedeutet zum Beispiel einen Durchlauf jeden Tag um Mitternacht (eine Dokumentation und Beispiele zu Cron Expressions finden Sie hier). |
Periodic Delete Buckets Max Duration | Der Kompaktifizierungslauf wird nach der angegebenen Anzahl von Minuten abgebrochen. Beim nächsten Durchlauf wird an dieser Stelle fortgesetzt. |
Periodic Delete Bucket if Deleted % | Es werden nur jene Buckets für das Kompaktifizieren herangezogen, deren Anzahl an gelöschten Dokumenten diesen Prozentsatz übersteigt. Es sind nur Werte größer oder gleich 60 % zulässig. |
Periodic Clean Documents in Updates Bucket Service | Wenn diese Einstellung auf Deleted gestellt ist, werden bereits gelöschte Buckets auch aus der doc-info gelöscht. Das spart zum einen unnötige Ressourcen und kann zum anderen die Synchronisationszeit von Producer und Consumer verbessern. Wenn diese Einstellung auf Deleted and Obsolete Revisions gestellt ist, werden zusätzlich auch alte Revisionen von Dokumente gelöscht, die durch Updates und Änderungen am Dokument, gespeichert wurden. |
Periodic Clean Documents in Updates Bucket Service Cron Expr | Legt den Zeitplan (als Extended Cron Expression) für die automatische Kompaktifizierung der doc-info fest. Der Wert „0 0 2 * * *“ bedeutet zum Beispiel einen Durchlauf an jeden Tag um 2:00 (eine Dokumentation und Beispiele zu Cron Expressions finden Sie hier). Der Zeitpunkt bezieht sich auf die lokale Zeit. |
Periodic Clean Documents in Updates Bucket Service Max Start Window | Definiert das Zeitfenster (in Minuten) in dem der doc-info Kompaktifizierungslauf ausgelöst wird.
|
Periodic Clean Documents in Updates Bucket Service Max Duration | Definiert die Zeitüberschreitung vom Task. Nach Ablauf der Zeitüberschreitung wird der Task abgebrochen. |
Manuelle Kompaktifizierung
Es ist ebenfalls möglich die Kompaktifizierungs-Tasks auf der Kommandozeile zu starten. Dazu ist das „mescontrol“-Interface verfügbar.
bucketsinfo | Gibt den aktuellen Füllstand der Buckets aus. | ||||||||||
listtasks | Gibt alle aktuell laufenden Tasks aus. | ||||||||||
taskcancel <taskid> | Bricht den angegebenen Task ab. | ||||||||||
taskwait <taskid> | Der Befehl wartet bis der angegebene Task abgschlossen wurde. | ||||||||||
taskstatus <taskid> | Gibt den aktuellen Status den angegebenen Tasks aus. | ||||||||||
deletebuckets [--sync] [--min-percent-deleted-docs=<0..1>] [<bucketid_1>… <bucketed_n>] [--log-unreferenced-unfiltered-documents] [--cleanup-unreferenced-unfiltered-documents] | Löscht die angegebenen Buckets und verschiebt die verbliebenen Dokumente in neue Buckets.
|
Netzwerk Eigenschaften
Man kann unter Netzwerk-Eigenschaften auswählen ob man das HTTP keep-alive für Item-Transformationen verwendet. Dadurch wird die Anzahl von offenen Verbindungen zu den statischen Resourcen vermindert, bzw. die Verbindungen werden wiederverwendet. Dieses Feature ist per Default deaktiviert.
Item Transformation Service Plugin Timeout: Item Transformation Requests werden nach diesem Timeout abgebrochen und das Dokument ohne diese Transformation invertiert.
Entity Recognition Parameter
- Diese Parameter erlauben das Extrahieren von bestimmten Metadaten aus dem Inhalt von den Dokumenten. Für mehr Informationen, siehe Konfiguration - Entity Recognition - Entity Recognition Parameter.
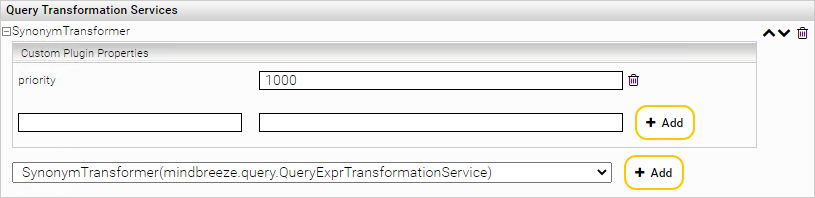
Falls Query Transformation Plugins installiert sind wird im „Advanced Settings“ Mode folgender Abschnitt der Index Service Konfigurationsoberfläche hinzugefügt:

Benützen Sie die Drop-Down Box um verfügbare Query Transformation Plugins auszuwählen. Verwenden Sie die Add Schaltfläche, um das Plugin für das aktuelle Index Service zu aktivieren.
Die bereits aktivierten Plugins werden darüber dargestellt. Durch Bestätigen der „Expandieren“ Schaltfläche eines aktiven Plugins wird ein Abschnitt mit den Plugin Properties angezeigt. Hier haben Sie die Möglichkeit Properties in Form von Schlüssel – Wert Paaren für das aktuelle Plugin zu definieren. Mit der entsprechenden „delete“ Schaltfläche können Sie diese benutzerspezifischen Plugin Properties wieder löschen.
Ein Klick auf eine weitere „delete“ Schaltfläche rechts neben dem Pluginnamen entfernt das ganze Plugin mitsamt aller benutzerspezifischen Properties, sodass dieses nicht mehr vom aktuellen Index Service verwendet wird.
Globale Konfiguration von Query und Item Transformation Plugins
Im „Global Index Settings“ Bereich kann man die bereits installierten Query und Item Transformation Plugins für alle Indices global konfigurieren. Diese Plugins werden auch für einen neuen hinzugefügten Index automatisch übernommen Die globale Konfiguration gilt nur für die Indices für die keine Plugins konfiguriert sind bzw. kein Plugin das per Default aktiv ist entfernt worden ist.
Reparatur von Referenzen
Mittels “repairreferences“ ist es möglich Referenzen zu korrigieren, die auf inkorrekte uniformitemids verweisen. Werden dabei Korrekturen vorgenommen wird automatisch ein Reinvertierung der DocumentInfo durchgeführt.
Die Reperatur erfolgt in folgenden Schritten:
- Scannen aller Dokumente im index um sicherzustellen, dass die DocIDs eindeutig sind
- Reperatur der Dokumenteinträge im Reference Index.
- Reperatur der Referenzen in allen Dokumenten
Anwendung:
Die Reperatur wird mit dem mescontrol Kommandozeilen-Tool “repairreferences” gestartet. Dabei ist es notwendig, dass die Option “Disable Unrestricted Privileged Servlets” deaktiviert ist.
mescontrol http://<INDEXHOST>:<INDEXPORT> repairreferences [--bulk-update-size=0] [--skip-uniformitemid-check] [--dry-run] [<docid> ... <docid>]
Optionale Parameter:
- --bulk-update-size: Die Anzahl an Updates die innerhalb einer Transaktion durchgeführt werden. Überschreibt die Indexoption “References Repair Bulk Update Size”. Standardwert: 100
- --skip-uniformitemid-check: Schritt 1 wird übersprungen.
- --dry-run: Am Ende von Schritt 3 werden die Dokumente nicht aktualisiert
- docid ... docid: Liste von Dokumenten die repariert werden sollen
Index Backups freischalten
Das Freischalten von Index Backups erfolgt im “Global Index Settings” Bereich unterhalb des Service Konfiguration Bereichs im “Indices” mittels der Option „Enable Index Backups“.
Im Feld „Allowed Backup Path Pattern (Regex)“ wird ein Regulärer Ausdruck angegeben, mit dem beschränkt wird, welche Verzeichnisse als Zielpfade eines Backup-Vorganges erlaubt sind.
Hinweis: Backslashes zur Pfadtrennung müssen dabei escaped werden: \\
Ein Backup kann mit dem Kommandozeilen-Tool mescontrol gestartet werden:
mescontrol http://<INDEXHOST>:<INDEXPORT> backup <BACKUPZIELPFAD>
Ebenso kann ein laufendes Backup auf Bedarf abgebrochen werden:
mescontrol http://<INDEXHOST>:<INDEXPORT> stopbackup
Support Mode Aktivieren
Das Aktivieren der “Advanced Settings” Checkbox zeigt auch den “Support Mode” Bereich unterhalb des Service Konfiguration Bereichs im “Indices”, “Filter”, wie auch im “Client Services” Tab. Support Mode zeichnet detaillierte Informationen über die verschiedenen Services in Logdateien auf, die im Standardfall im temporären Verzeichnis des Mindbreeze Service Benutzers unter Windows und im /var/opt/mindbreeze/log Verzeichnis unter Linux Plattformen gespeichert werden. Vom Standard abweichende Logverzeichnisse können in dem Abschnitt „Log Location“ eingestellt werden.
Hinweis: Deaktivieren sie den Support Mode im “normalen” Gebrauch, um die Performanz nicht unnötig zu verschlechtern.
Um die Änderungen zu speichern drücken sie “Save”.

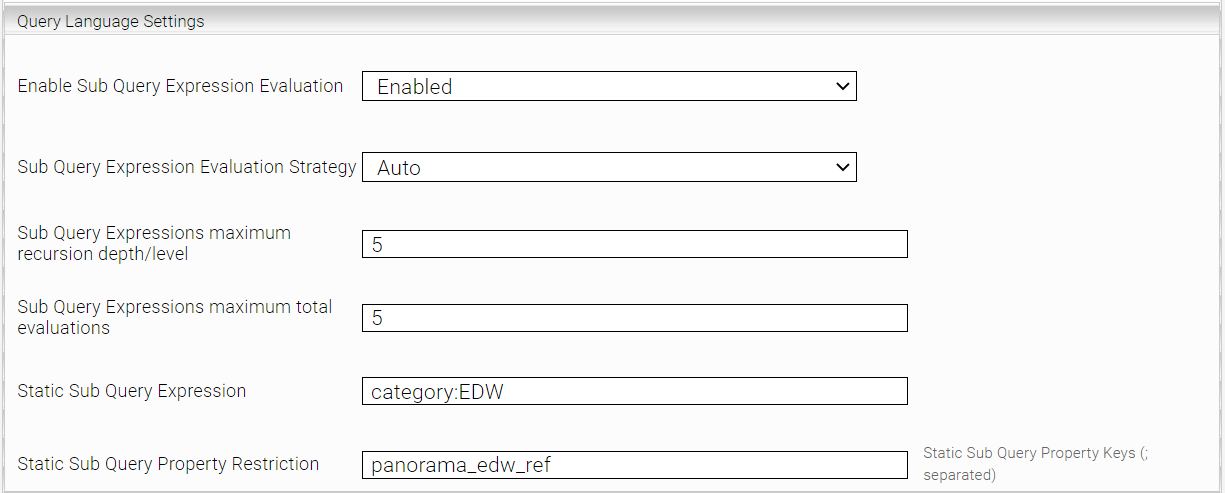
Sub Query Expression
Sub Query Expression ermöglicht es Referenzen von Daten für die Suche auszuwerten. So kann z.B. aus einem Ordner alle Dateien gesucht werden, oder auch umgekehrt, der Ordner in dem sich eine Datei befindet. Dies kann auf alle Metadata Keys angewandt werden, die auf ein anderes Dokument zeigen. Die Invertierte Richtung kann auch genutzt werden, wenn die Metadata Keys in Inverted Reference Metadata Keys eingetragen sind. Zusätzlich zu Forward- und Reverse-Referenzen können String- und Reverse-String-Referenzen (via Property Expression lookup und rev_lookup) verwendet werden.

Einstellung | Beschreibung | ||||||||
Aktiviert das Feature. | |||||||||
Sub Query Expression Evaluation Strategy | Diese Einstellung ermöglicht eine optimierte Strategie der Sub Query Suche. Man kann zwischen drei Optionen auswählen:
| ||||||||
Sub Query Expressions maximum recursion depth/level | Bestimmt die Rekursion Tiefe einer Sub Query suche. Da Sub Queries in einander verschachtelt werden können, aber die Laufzeit sehr viel kostet, ermöglicht dies die Komplexität einzuschränken. | ||||||||
Sub Query Expressions maximum total evaluations | Bestimmt die maximale Anzahl von Sub Queries, die in einer Suche enthalten sein dürfen. Dies unterscheidet sich zu Tiefe, da eine Suche von parallelen Sub Queries durch die Tiefe nicht eingegrenzt werden kann. | ||||||||
Hier kann eine Sub Query Expression angegeben werden. Falls die Suche bereits eine Sub Query enthält, wird die bestehende Sub Query mit der hier angegebenen Sub Query nochmal eingeschränkt. Dokumente, die über den Wert von „Static Sub Query Property Restriction“ referenziert werden, werden zurückgeliefert. | |||||||||
Static Sub Query Property Restriction | Liste von Referenzen, die der "RestrictToProperty"-Komponente der Sub Query hinzugefügt werden. Liste der Referenzen werden durch ";" getrennt. |
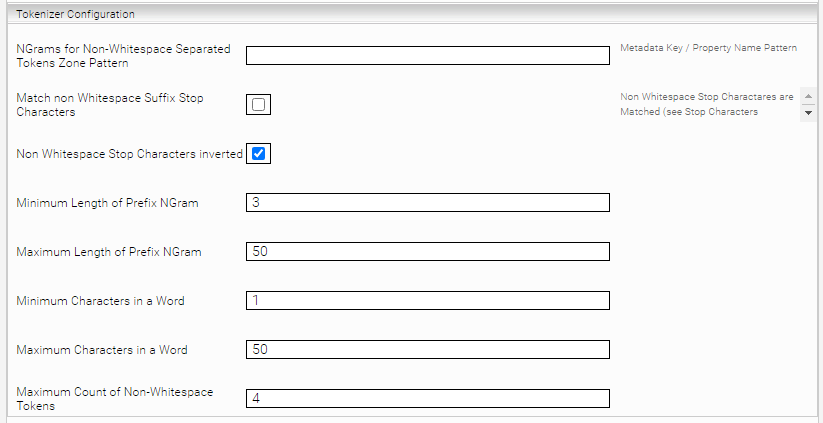
Tokenizer Configuration
Die Optionen in „Tokenizer Configuration“ dienen der Anpassung der Suchtreffer für Wortteile.

Einstellung | Beschreibung |
NGrams for Non-Whitespace Separated Tokens Zone Pattern | Diese Option definiert den Regulären Ausdruck (RegEx) für die Metadaten, für die Non-Whitespace Separated N-Gramme erzeugt werden. Wenn dieses Feld leer gelassen wird, ist das Feature deaktiviert.
Beispiele: (Liste der Suchbegriff ist unvollständig) |
Match non Whitespace Suffix Stop Characters | Wenn aktiv, liefern Suchanfragen genauere Ergebnisse mit Trenn- und Sonderzeichen. Dadurch können Dokumente mit beispielseweise Aktenzahlen, Rechnungsnummern oder Geschäftszeichen besser gefunden werden. Dokumente, in denen der Suchbegriff – jedoch ohne die gesuchten Trenn- und Sonderzeichen – vorkommt, werden dann nicht mehr angezeigt. Beispiel: Suche nach ISBN 978-0201100884 Wenn Match non Whitespace Suffix Stop Characters:
Anmerkung: Damit die Einstellung wirksam ist, muss auch Non Whitespace Stop Characters inverted aktiviert sein. Bitte beachten Sie, dass bereits bestehende Indizes re-invertiert werden müssen, wenn Non Whitespace Stop Characters inverted aktiviert wird; Details dazu finden Sie unten. |
Non Whitespace Stop Characters inverted | Muss aktiviert sein, wenn Match non Whitespace Suffix Stop Characters aktiviert ist. Ist Match non Whitespace Suffix Stop Characters nicht aktiviert, dann hat diese Einstellung keine Auswirkungen auf die Suche. Anmerkung: Bitte beachten Sie, dass eine Re-Invertierung notwendig ist, damit Änderungen an dieser Einstellung wirksam sind. Wenn Sie einen bestehenden Index mit Mindbreeze InSpire Version 22.3 oder älter haben und auf Version >= 23.1 updaten, muss dieser Index ebenfalls re-invertiert werden, damit das Feature wirksam ist. |
Minimum Length of Prefix NGram | Minimale Länge von Präfix-NGrammen, die für die Sucher berücksichtigt werden. |
Maximum Length of Prefix NGram | Maximale Länge von Präfix-NGrammen, die für die Sucher berücksichtigt werden. |
Minimum Characters in a Word | Minimale Länge von Wörtern. Längere Wörter werden nicht unterschieden. |
Maximum Characters in a Word | Maximale Länge von Wörtern. Längere Wörter werden nicht unterschieden. |
Maximum Count of Non-Whitespace Tokens | Diese Option wird verwendet, um die Zahl von nicht Leerzeichen getrennten Token zu begrenzen. |
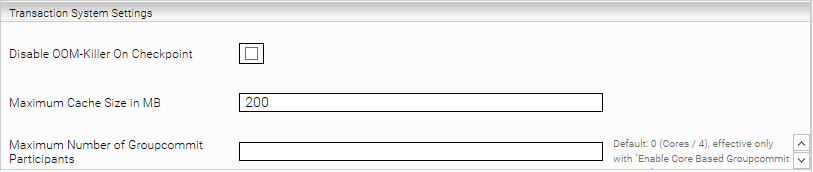
Transaction System Settings
Die Optionen in dieser Gruppe können für die Feinabstimmung im Transaktionssubsystem verwendet werden.

Diese Option erlaubt es, die eingebaute OOM-Killer-Funktionalität in Linux bei den Checkpoint Schritten vorübergehend zu deaktivieren, um zu verhindern, dass der Indexprozess bei Speichermangel gekillt wird. | |
Maximum Cache Size in MB | Diese Option wird verwendet, um den Standardwert für die Cache-Größe zu ändern. |
Maximum Number of Groupcommit Participants | Kann verwendet werden, um die Anzahl der Groupcommit-Teilnehmer zu begrenzen, d. h. standardmäßig die Anzahl der Kerne / 4. Diese Option ist nur effektiv, wenn die Option "Enable Core Based Groupcommit Strategy" aktiviert ist. |
Memory Analysis Settings
Memory Test Allocation size in Bytes | Diese Option kann verwendet werden, um zu testen, wie lange eine Allokierung einer bestimmten Speichergröße auf Ihrer JVM dauert. Das Ergebnis befindet sich im Log-Verzeichnis des Index innerhalb der Logdatei memory-usage.csv. |
Statistcs Calculation Frequency | Hier kann bestimmt werden, in welchem Zeitintervall die Ergebnisse der Optionen „Memory Test Allocation size in Bytes“ und „Enable JVM Statistics“ berechnet werden sollen. (in Sekunden) |
Enable JVM Statistics | Wenn diese Option aktiviert ist, werden die JVM-Statistiken in die Logdatei memory-usage.csv im Log-Verzeichnis des Index geschrieben. |
Enable Core Dumps | Wenn diese Option aktiviert ist, werden Core Dumps in eine Datei geschrieben, falls der Index abstürzt. Die Datei befinden sich im Log-Verzeichnis des Index. |
Optional Terms
Mithilfe der „Optional Terms“ kann das Finden von Dokumenten vereinfacht werden, indem Resultate geliefert werden, in denen nicht unbedingt alle Suchbegriffe vorkommen müssen. Damit das transparent für den Benutzer geschieht, wird ein Hinweis beim Treffer angezeigt. Dieses Feature ist standardmäßig aktiv, kann jedoch parametrisiert oder ganz deaktiviert werden.
Wichtig ist hier zu erwähnen, dass manche Optionen in den Konfigurations-Bereichen Index Global, Index Lokal und Client Service/UI des Relevance Bereiches im MMC denselben Namen bzw. dieselbe Funktionalität haben, jedoch überschreiben/dominieren manche Optionen die anderen.
Prinzipiell gilt folgende Mächtigkeit (erstes am wenigsten dominant, letztes am dominantesten):
Index Global < Index Lokal < Client Service/UI des Relevance Bereiches im MMC
Beispiel:
Index Global: Optional Terms = aktiviert
Index Lokal: Optional Terms = aktiviert
Client Service: Optional Terms = deaktiviert
Insgesamt: Optional Terms = deaktiviert
Weiteres Beispiel:
Index Global: Optional Terms = deaktiviert
Index Lokal: Optional Terms = deaktiviert
Client Service: Optional Terms = aktiviert
Insgesamt: Optional Terms = aktiviert
Bereich: Global Query Settings | |
Optional Terms Ratio | Ist diese Option aktiviert, kann zusätzlich das Verhältnis der Terms angegeben werden bzw. wie viele Terms weggelassen werden können. Beispiel: |
Term Boost Position Reduction Max | Maximaler Wert, um den das Boosting eines Terms verringert werden kann. Werte: 0.0 – 1.0 (Default 0.2) Beispiel: |
Term Boost Position Reduction Step | Schrittgröße, um den jeder folgende (rechtsstehende) Wert verringert wird. Beispiel bei 0.1 und „Term Boost Position Reduction Max“=0.2 und Sucheingabe von „Ich heiße Max Mustermann“ ergibt folgende Term Boosting: |
Disable Term Boost Position Reduction | Wenn angehakt, werden „Term Boost Position Reduction Max“ und „Term Boost Position Reduction Step“ deaktiviert. |
Default Restricted Categories for Did You Mean | “Did You Mean”-Vorschläge werden nur aus den hier angegebenen Categories berechnet. Wenn leer, werden alle Dokumente aus allen Categories miteinbezogen. Trennen Sie die Categories mit Zeilenumbrüchen oder Strichpunkten. Z.B.: Web;Microsoft File |
Bereich: Term Boost Relative to Position in Query | |
Wenn aktiviert, ermöglicht diese Option Legacy-Terme in Terms zu transformieren. Damit kann man in der Suchzeile wie bisher nur eine Serie von Termen eingeben und die Suche verwendet trotzdem das Optional Terms. Dies ist eine Voraussetzung für das „Optional Terms“ Feature und ist standardmäßig aktiviert. Falls Sie ältere Query-Transformation-Plugins installiert haben und Probleme mit der Suche auftreten, empfehlen wir die Plugins zu aktualisieren. Falls dies nicht möglich ist, können Sie diese Einstellung deaktivieren. Damit sollten auch ältere Query-Transformation-Plugins funktionieren. | |
Optional Terms Ratio | Siehe „Optional Terms Ratio” in Global Query Settings. |
Term Boost Position Reduction Max | Siehe „Term Boost Position Reduction Max” in Global Query Settings. |
Term Boost Position Reduction Step | Siehe „Term Boost Position Reduction Step” in Global Query Settings. |
Disable Term Boost Position Reduction | Siehe „Disable Term Boost Position Reduction” in Global Query Settings. |
Bereich: Query Settings | |
Show Missing Terms in Results | Bei Aktivierung dieser Option, werden die fehlenden oder der zu ergänzenden Begriffe zusätzlich mittels eines Hinweises beim Suchresultat angezeigt. |
Optional Terms Ratio | Siehe „Optional Terms Ratio” in Term Boost Relative to Position in Query. |
Kompositazerlegung
Mithilfe der Kompositazerlegung können einzelne, aus mehreren zusammengesetzten Wörtern erkannt und entsprechend getrennt werden, so dass zum Auffinden komplexerer Wörter auch Teilwörter für die Suchanfrage ausreichen.
Beispiel: Um auch Dokumente, die z.B. auch „Arbeitsplatz“, etc. enthalten, in den Ergebnissen zu finden, kann in der Sucheingabe folgendes eingegeben werden:
Nahtlose Integration in Ihren Platz
Hinweise:
- Voraussetzung für die Kompositazerlegung ist die Aktivierung der Option „Enable Language Detection“, die die automatische Spracherkennung der Dokumente aktiviert. Derzeit werden für die Funktionalität der Kompositazerlegung die Sprachen DE und EN unterstützt. Weitere unterstützbare Sprachen werden bald folgen.
- Die Funktionalität der Kompositazerlegung gilt nur für neu hinzugefügte Dokumente. Um die Funktionalität auf bereits existierende Dokumente anzuwenden, ist eine vollständige Re-invertierung des Indexes notwendig. Eine Beschreibung dazu finden Sie hier.
- Die Compound Splitting-Funktion ist standardmäßig aktiviert und die folgenden Optionen sind sowohl für die jeweiligen lokalen Indices als auch Global verfügbar. Eine ausführlichere Beschreibung dazu finden Sie in der untenstehenden Option „Compound Splitting Strategy“.
Bereich: Compound Splitting | |||||||||||||
Compound Splitting Strategy | Mit dieser Einstellung können Sie die Compound Splitting-Funktion ausschalten bzw. eine Strategie bestimmen. Man kann zwischen 6 Optionen auswählen:
| ||||||||||||
Path to Custom Compound Splitting Models Directory | Hier kann der Verzeichnispfad (innerhalb Ihrer lokalen Maschine) von benutzerdefinierten Modellen bestimmt werden. | ||||||||||||
Disable Compound Splitting for Languages matching | Hier kann bestimmt werden, welche Sprachen nicht berücksichtigt werden sollen. | ||||||||||||
Enable Compound Splitting for Languages matching | Hier kann bestimmt werden, welche Sprachen berücksichtigt werden sollen. | ||||||||||||
[Deprecated] Compound Splitting Vocabulary Path | Deprecated –> Sollte nicht mehr verwendet werden. Hier kann eine .csv-Datei (innerhalb Ihrer lokalen Maschine) von benutzerdefinierten Modellen bestimmt werden. | ||||||||||||
Disable Subword Highlighting | Wenn aktiv, wird das Highlighting (im Sample Text / Vorschau) von Termen deaktiviert, die via Compound-Splitting gefunden wurden. Das Aktivieren dieser Einstellung kann die Suchleistung verbessern. |
Hinweis: Für InSpire unter Windows müssen Sie zusätzlich Folgendes installieren: MESExtensionsSetup.exe
Named Entity Recognition (NER)
Mithilfe der Named Entity Recognition können auf Basis von KI-basierter Spracherkennung und anschließender Satzsegmentierung Entitäten sowohl im Inhalt als auch in den Metadaten eines Dokuments identifiziert und klassifiziert werden.
Derzeit werden die folgenden Entitäten unterstützt, die bereits vortrainiert sind und im weiteren Verlauf angepasst und erweitert werden können (z.B. durch Tools).
- Personen (entity:person)
- Orte (entity:location)
- Organisationen (entity:organization)
- Numerische Werte (entity:number)
Beispiel: Um alle Dokumente nach Personen zu finden, welche in der Nähe der Wörter „head“, „academy“ und „mindbreeze“ vorkommen, kann folgendes in der Sucheingabe eingegeben werden:
entity:person:ALL NEAR head NEAR academy NEAR mindbreeze
Hinweise:
- Voraussetzung der Named Entity Recognition ist die Aktivierung der Option „Enable Language Detection“, welche die automatische Spracherkennung der Dokumente aktiviert. Derzeit werden für die Funktionalität der NER die Sprachen DE und EN unterstützt. Zukünftig werden weitere Sprachen unterstützt.
- Die Funktionalität der NER gilt nur für neu hinzugefügte Dokumente. Um die Funktionalität auf bereits existierende Dokumente anzuwenden, ist eine vollständige Re-invertierung des Indexes notwendig. Eine Beschreibung dazu finden Sie hier.
- Die NER-Funktion ist standardmäßig deaktiviert und die folgenden Optionen sind sowohl für die jeweiligen lokalen Indices als auch Global verfügbar. Eine ausführlichere Beschreibung dazu finden Sie in der untenstehenden Option „Model based NER Extraction“.
Eine Beschreibung, wie Insight Apps agepasst werden können (z.B. für verschiedene Hintergrundfarben), findet man hier und hier.
Enable Language Detection | Hier kann bestimmt werden, ob die automatische Spracherkennung der Dokumente aktiviert werden soll oder nicht. (Standardmäßig aktiviert) Hinweis: Diese Option ist für die Compound Splitting- und NER-Funktion erforderlich. Wenn für ein Dokument keine Sprache erkannt wird, können die beiden genannten Features nicht auf das betreffende Dokument angewendet werden. Die automatische Spracherkennung ist im Gegensatz zum LanguageDetector ItemTransformer Plugin in den Index integriert, sodass das Plugin nicht mehr benötigt wird. | ||||||||||||
Language Detection Min Text Bytes | Mit dieser Option können Sie die Mindestmenge an Text in einem Dokument festlegen, ab der eine automatische Spracherkennung durchgeführt werden soll. Wenn die angegebene Textmenge (in Bytes) unter der Textmenge des Dokuments (in Bytes) liegt, wird die automatische Spracherkennung für dieses Dokument nicht durchgeführt. | ||||||||||||
Language Detection Max Text Bytes | Die angegebene Textmenge (in Bytes) entspricht der maximalen Textmenge, die für die automatische Spracherkennung vom Beginn des Dokuments an berücksichtigt wird. Die Textmenge des Dokuments, die über diese Grenzen hinausgeht, ist daher für die Spracherkennung nicht relevant. | ||||||||||||
Model based NER Extraction | Mit dieser Einstellung können Sie die NER-Funktion ausschalten bzw. eine Strategie bestimmen. Man kann zwischen 6 Optionen auswählen:
| ||||||||||||
Path to Custom NER Resources Directory | Hier kann der Verzeichnispfad (innerhalb Ihrer lokalen Maschine) von benutzerdefinierten NER Modellen und Katalogen bestimmt werden. Es ist dafür notwendig, die in Anhang G beschriebene Verzeichnisstruktur und Benennungskonvention einzuhalten. | ||||||||||||
Min Words Per Sentence | Legt die minimale Anzahl von Wörtern pro Satz fest, die für eine NER-Auswertung erforderlich sind. Besteht ein Satz aus weniger Wörtern als in dieser Option angegeben, dann wird der gesamte Satz nicht ausgewertet bzw. kein Tag berechnet. Der Standardwert ist 5. | ||||||||||||
Max Words Per Sentence | Definiert die maximale Wortanzahl pro Satz, bei der eine NER-Auswertung erfolgt. Besteht ein Satz aus mehr Wörtern als wie für diese Option angegeben, dann wird der gesamte Satz nicht ausgewertet bzw. kein Tag berechnet. Der Standardwert ist 30. | ||||||||||||
Minimum Probability For NER Tags | Dieser Parameter beeinflusst die Anzahl der fäschlich erkannten (false-positive) NER-Tags und verändert die Gesamtanzahl der erkannten Tags. Für jeden berechneten Tag wird eine individuelle Wahrscheinlichkeit (Fließkommazahl zwischen 0 und 1) berechnet. Ist die Wahrscheinlichkeit für den berechneten Tag kleiner als der für diesen Parameter angegebene Wert, so wird dieser Tag verworfen bzw. nicht weiter verarbeitet. Daher werden bei kleinen Wahrscheinlichkeitswerten mehr und bei großen Wahrscheinlichkeitswerten weniger Tags angezeigt. Der Standardwert ist 0.5. | ||||||||||||
Restricted Zones Pattern | Ein Regex-Pattern für Dokumentzonen (= Metadaten), die für NER verarbeitet werden sollen. Wenn dieses Muster beispielsweise auf "title|content" gesetzt ist, wird nur Text in den Zonen "content" und "title" für die NER-Auswertung verwendet. Text in anderen Zonen wird ignoriert. Wenn diese Option leer gelassen wird, werden alle ER-Zonen für die NER-Verarbeitung verwendet. Hinweis: Diese Option kannn auch verwendet werden, um die Verarbeitung von Metadaten vom Sentence Transformer einzuschränken. Wenn die Einschränkung nur für Sentence Transformers erfolgen soll, kann stattdessen die Option „Static Sentence Transformer Restricted Zones Pattern“ verwendet werden. Weitere Informationen dazu finden Sie in Handbuch – Natural Language Question Answering (NLQA) – Konfiguration: Sentence Transformation | ||||||||||||
Maximum Transformed JSON Rules Cache | Maximale Anzahl der im Cache gespeicherten transformierten JSON-Regeln, Standardwert ist 20. Transformierte JSON-Regeln, die beim Einfügen eines Dokuments mit dem Metadatum "mes:itemtransformationrulesjson" gesendet werden. | ||||||||||||
Enable NER Highlighting | Wenn diese Option aktiv ist, dann werden die gefundenen NER-Tags und die dazu relevanten Textstellen im Suchergebnis farblich markiert. Das Highlighting ist nur dann sichtbar, wenn di Client Service-Einstellungen “Mark All Entity Types”, oder “Mark Entity Types” aktiviert bzw. konfiguriert sind. Siehe . | ||||||||||||
NER Enitity Catalog Filters Strategy | Wenn diese Einstellung aktiviert ist, wird der semantischen Pipeline eine zusätzliche katalogbasierte Filterung hinzugefügt, um falsch erkannte Ergebnisse (false-positives) zu entfernen. Diese Einstellung bewirkt, dass Wörter mit NER-Tags entfernt werden, außer wenn diese Wörter im entsprechenden Entitätskatalog vorhanden sind. Wenn beispielsweise das Wort "ABCD" als NER-Tag des Typs 'Person' markiert ist, aber kein Eintrag "ABCD" in den Person-Katalogen vorhanden ist, wird der Entity-Tag aus diesem Wort entfernt.
| ||||||||||||
NER Stop Word Catalogs Strategy | Wenn diese Einstellung aktiviert ist, wird der semantischen Pipeline eine zusätzliche katalogbasierte Filterung hinzugefügt um falsch erkannte Ergebnisse (false-positives) zu entfernen, ähnlich wie bei der Option NER Enitity Catalog Filters Strategy. Diese Einstellung bewirkt, dass Wörter mit NER-Tags entfernt werden wenn diese Wörter im entsprechenden Stopp-Wort Katalog vorhanden sind. Ein weiterer Unterschied zur Option NER Enitity Catalog Filters Strategy ist, dass die Stopp-Wort-Kataloge nicht entitätsabhängig sind, sondern stattdessen von der Sprache des Dokuments abhängen. | ||||||||||||
NER Entity Catalog Filter Minimum Matched Words Ratio | Dieser Parameter beeinflusst die Wirkung der Katalogfilter, insbesondere bei Multiwort-Entitäten. Dieser Parameter gibt das Mindestverhältnis (zwischen 0 und 1) der Zeichenanzahl vorhandener Wörtern im Katalogfilter und der gesamt erkannten Wörtern an, damit eine Entität nicht verworfen wird. Dies ist relevant für Multiwort-Entitäten. Zum Beispiel könnte eine Zeichenkette wie "Dr. Albert Einstein" als eine Mehrwortentität erkannt werden. Das Wort "Dr." existiert nicht als Personenname im vordefinierten Mindbreeze-Katalog, so dass das Verhältnis der übereinstimmenden Wörter weniger als 1 beträgt. Wenn diese Einstellung auf 1 gesetzt ist, wird "Dr. Albert Einstein" nicht als Personenentität gekennzeichnet. Ein niedrigerer Wert für diesen Parameter macht den Filter zwar toleranter, birgt aber auch das Risiko, dass der Filter mehr falsch erkannte Ergebnisse (false-positives) liefert. | ||||||||||||
NER Stop Word Catalog Filter Maximum Matched Words Ratio | Ähnlich wie bei der Option NER Entity Catalog Filter Minimum Matched Words Ratio beeinflusst dieser Prameter die Wirkung der Katalogfilter bei Multiwort-Entitäten. Ist das Verhältenis der Zeichenanzahl der erkannten Stopp-Wörter einer Multiwort-Entität größer als der hier definierte Wert, wird die Entitätsmarkierung entfernt. | ||||||||||||
Enable Inversion of Text Region Entity Annotations | Wenn diese Einstellung aktiviert ist, können benutzerdefinierte entity-annotations ebenfalls invertiert und durchsucht werden. Die benutzerdefinierten entity-annotations können genauso wie die mit NER extrahierten Entitäten hervorgehoben werden (siehe "Enable NER Highlighting "). Weiters können diese entity-annotations wie andere NER-Tags durchsucht werden, z.B. mit der Suchabfrage: Hinweis: Siehe Hierarchical CSV Enricher für Informationen zum Hinzufügen von benutzerdefinierten Entity-Anmerkungen. | ||||||||||||
Included Text Region Entity Annotation Label Patterns for Inversion | Regex-Muster von benutzerdefinierten „entity annotation“-Namen, die bei der Reinversion berücksichtigt werden sollen, getrennt durch eine neue Zeile. Wenn diese Einstellung leer gelassen wird, werden alle benutzerdefinierten entity-annotations berücksichtigt. | ||||||||||||
Hinweis: Für InSpire unter Windows müssen Sie zusätzlich Folgendes installieren: MESExtensionsSetup.exe .


Named Entity Recognition (Client Service)
Area: Query Settings | |
Enable NER in Sample Text | Wenn diese Option aktiviert ist, wird die Hervorhebung der Entity-Recognition für den Beispieltext aktiviert |
Enable NER in HTML Preview | Wenn diese Option aktiviert ist, wird die Hervorhebung der Entity-Recognition für die HTML-Vorschau aktiviert. Dies betrifft alle Dokumenttypen außer PDF. |
Enable NER in PDF Preview | Wenn diese Option aktiviert ist, wird die Hervorhebung der Entity-Recognition für die PDF-Vorschau aktiviert. |
Mark All Entity Types | Wenn diese Option aktiviert ist, werden alle Wörter mit einer markierten Entität in der Suche hervorgehoben, unabhängig vom Entitätstyp. Wenn diese Option deaktiviert ist, werden nur die in Mark Entity Types angegebenen Entitätstypen markiert. |
Mark Entity Types | In dieser Einstellung können Sie festlegen, welche Entitätstypen im Beispieltext und in der Vorschau hervorgehoben werden sollen (durch Zeilenumbruch getrennt). Das prebuilt NER-Modell unterstützt derzeit folgende Entitätstypen: Wenn Mark All Entity Types nicht aktiviert ist, werden nur die Entitätstypen aus diesem Textfeld hervorgehoben. Wenn Mark All Entity Types nicht aktiviert ist und Mark Entity Types leer gelassen wird, wird keine Texthervorhebung in der Suche vorgenommen. |

Sentence Transformation
In diesem Abschnitt werden alle Konfigurationsoptionen zum Thema „Sentence Transformation“ beschrieben. Diese Einstellungen beziehen sich auf „Natural Language Question Answering“ (kurz: NLQA). Bitte lesen Sie vorher das Handbuch – Natural Language Question Answering (NLQA).
Bereich: Semantic Text Extraction | |||||||||||
Maximum Transformed JSON Rules Cache | Die Maximalgröße von im Cache gespeicherten transformierten JSON-Regeln, Transformierte JSON-Regeln werden beim Einfügen eines Dokuments an das Metadatum „mes:itemtransformationrulesjson“ gesendet. Standardwert: 20 | ||||||||||
Aktivieren Sie diese Option, um Sentence Transformation zu aktivieren (ist notwendig, um NLQA zu aktivieren). Damit NLQA vollständig aktiviert wird, müssen zusätzliche Einstellungen vorgenommen werden, siehe Handbuch – Natural Language Question Answering (NLQA) – Konfiguration. | |||||||||||
Sentence Transformers Use GPU | Wenn aktiv, verweden die Sentence Transformers die GPU. Falls keine GPU verfügbar ist, wird auf die CPU zurückgegriffen. | ||||||||||
Sentence Transformation GPU Device ID | Die Device ID der GPU, die verwendet werden soll. Sollte nur dann konfiguriert werden, wenn Sentence Transformers Use GPU aktiviert ist und mehr als eine GPU installiert ist. Standardwert: 0 | ||||||||||
Sentence Transformers Model ID Setting | Sentence Transformer Modell, welches für NLQA verwendet wird.
| ||||||||||
Path to Custom Sentence Transformers Model | Definiert den Pfad zu einem benutzerdefinierten Sentence Transformer Modell. Ist nur effektiv, wenn in „Sentence Transformers Model ID Setting“ entweder „Custom“ oder „Default“ ausgewählt ist. Falls Sie für Ihr Data-Science-Projekt ein benutzerdefiniertes Modell verwend möchten, wenden Sie sich bitte an support@mindbreeze.com. | ||||||||||
Path to Custom Sentence Transformers Pooling Model | Standardmäßig wird kein Sentence Transformers Pooling Modell verwendet. Falls Sie für Ihr Data-Science-Projekt dies verwenden möchten, wenden Sie sich bitte an support@mindbreeze.com. | ||||||||||
Sentence Transformer Max Batches | Kann konfiguriert werden, um die Indizierungsdauer für Dokumente, die vom Sentence Transformer verarbeitet werden, zu verringern. Standardwert: leer (keine Einschränkung auf die Anzahl der Sätze, die verarbeitet werden sollen) | ||||||||||
Sentence Transformer Batch Size | Um Text zu verarbeiten, erstellt der Sentence Transformer „Batches“ (= eine Anzahl von Satzsegmenten). Diese Einstellung definiert die maximale Größe der Batches. Wenn Performance-Probleme auftreten, kann eine Anpassung dieser Einstellung zur Verbesserung der Performance beitragen. Standardwert: 10 | ||||||||||
Skip Embeddings for Property Values if Language was Unreliably Detected | Diese Einstellung wirkt sich auf die Berechnung von Sentence Embeddings und die gefundenen Suchergebnisse der Ähnlichkeitssuche aus, wenn der Language Detector die Erkennung der Sprache als unzuverlässig einstuft. Standardeinstellung: Disabled
| ||||||||||
Skip Embeddings for Property Value if Language is Undetectable | Diese Einstellung wirkt sich auf die Berechnung von Sentence Embeddings und die gefundenen Suchergebnisse der Ähnlichkeitssuche aus, wenn der Language Detector keine Sprache erkannt hat. Dies kann bei sehr kurzen Texten oder Metadaten der Fall sein. Standardeinstellung: Disabled
| ||||||||||
Sentence Transformer Restrict to Language Pattern | Regex-Pattern, um Dokumente auf Basis der erkannten Dokumentensprache für die Verarbeitung vom Sentence Transformer einzuschränken. Wenn diese Option leer gelassen wird, werden alle Dokumente, unabhängig von der erkannten Dokumentensprache, verarbeitet. Standardwert: be|bg|br|bs|ca|cs|cy|da|de|el|en|es|et|eo|eu|fi|fo|fr|fy|ga|gd|gl|gv|he|hr|hu|is|it|ka|kl|kw|la|lb|lt|lv|mk|mt|nl|no|pl|pt|ro|ru|sk|sl|sq|sr|sv|tr|uk|wen (alle europäischen Sprachen) Achtung: Das Einschränken des Sentence Transformer ist nur mit Sprachcodes gemäß ISO 639-1 möglich. | ||||||||||
Static Sentence Transformer Restricted Zones Pattern | Ein Regex-Pattern für Dokumentzonen, die vom Sentence Transformer verarbeitet werden sollen. Wenn dieses Pattern beispielsweise auf "title|content" gesetzt ist, wird nur Text in den Zonen "content" und "title" verarbeitet. Text in anderen Zonen wird ignoriert. Wenn diese Option leer gelassen wird, wird auf "title|content" eingeschränk (Standardwert). Hinweis: Wenn Restricted Zones Pattern konfiguriert ist, wird diese Einschränkung zuerst ausgewertet. Anschließend wird die Enschränkung von Static Sentence Transformer Restricted Zones Pattern ausgewertet. Beispiel: Restricted Zones Pattern: content|description | ||||||||||
Dynamic Sentence Transformer Excluded Zones Pattern | Metadaten, die explizit mit „EMBEDDINGS_COMPUTED“ markiert sind, werden vom Sentence Transformer verarbeitet. Hier kann zusätzlich ein Regex-Pattern für Dokumentzonen, die vom Sentence Transformer ausgeschlossen werden sollen, konfiguriert werden, wenn für die Zone „EMBEDDINGS_COMPUTED“ gesetzt ist. Standardwert: leer (keine Zoneneinschränkung) Weitere Informationen, wie man „embeddings-computed“ in einer Sitemap setzen kann, siehe Konfiguration – Web Connector - Mindbreeze-Erweiterung des Sitemaps.org Protokolls. | ||||||||||
Vector Index Merge Service Maximum Runs | Diese Einstellung kann die Anzahl der Zusammenführungsdurchläufe für Vektorindexdateien begrenzen. Vektorindexdateien enthalten Embeddings und das Zusammenführen dieser Dateien kann sich auf die Leistung auswirken. Die Änderung dieser Einstellung ist nur in besonderen Anwendungsfällen erforderlich. Achtung: Die Konfiguration dieser Einstellung kann sich auf die Leistung auswirken. Bitte ändern Sie diese Einstellung daher nicht ohne Rücksprache mit dem Mindbreeze DSupport. | ||||||||||

Bereich: Sentence Segmentation Layout Processing | |
Enable Process Layout Information for Sentence Segmentation | Wenn aktiviert, werden bei der Satzsegmentierung Layout-Informationen (Annotationen) des Dokuments berücksichtigt. Die segmentierten Sätze bilden die Grundlage für die Berechnung der Vektoren des Sentence Transformer, der "Natural Language Question Answering" (NLQA) ermöglicht. Standardeinstellung: Deaktiviert. |
Minimum Regions Length for Sentence Segmentation | Die Mindestlänge einer Region, die bei der Satzsegmentierung berücksichtigt wird. Dies hilft, relevante Informationen besser hervorzuheben. Standardwert: 20. |
HTML Tags for Sentence Segmentation | HTML-Annotationen (= HTML-Tags), die bei der Satzsegmentierung berücksichtigt werden. Standardwert: p |
Text Regions for Sentence Segmentation | Regions-Annotationen, die bei der Satzsegmentierung berücksichtigt werden. Standardwert: |
Process Layout if any Expr Matches | Hier können mehrere Mindbreeze Property Expressions konfiguriert werden, getrennt durch einen Zeilenumbruch. Achtung: Nur Property Expressions, die auch zum Invertierungszeitpunkt verfügbar sind, können verwendet werden. Layoutinformationen werden nur bei Dokumenten berücksichtigt, bei denen mindestens ein Eigenschaftsausdruck etwas aussagt. Bei anderen Dokumenten wird die Satzsegmentierung ohne Berücksichtigung von Layoutinformationen durchgeführt. Ist der Wert leer, werden Layoutinformationen für alle Dokumente berücksichtigt. Standardwert: leer. |

Bereich: Sentences Transformation Text Segmentation | |||||||||||||
Text Segmenter Profile | Die Textsegmentierung kann über Profile beinflusst werden. Die segmentierten Textabschnitte bilden die Grundlage für die Berechnung der Vektoren des Sentence Transformers, welcher „Natural Language Question Answering“ (NLQA) ermöglicht.
| ||||||||||||
Min Sentence Element Size | Minimale Anzahl an Elementen, damit ein Textabschnitt als Satz gewertet wird. Hinweis: ein „Element“ ist meistens ein Wort | ||||||||||||
Max Sentence Element Size | Maximale Anzahl an Elementen, bevor ein Textabschnitt als mehr als ein Satz gewertet wird. | ||||||||||||
Element Split Threshold | Ist das aktuelle Text Segment inklusive des aktuellen Satzes länger als Max Element Size, wird mit dieser Option konfiguriert, an welcher Stelle der aktuelle Satz geteilt wird und es wird auch sichergestellt, dass der zweite Teil des Satzes nicht zu klein ist. Im letzteren Fall wird dennoch der ganzen Satz inkludiert, um sicherzustellen, dass der Kontext erhalten bleibt. | ||||||||||||
Max Sentence Size | Maximale Anzahl an Sätzen, die ein Textsegment enthalten darf. | ||||||||||||
Max Element Size | Maximale Anzahl an Elementen, die ein Textsegment enthalten darf. | ||||||||||||
Overlap Max Sentence Size | Maximale Anzahl der Sätze, die beim Berechnen der Textsegmente überlappt werden | ||||||||||||
Overlap Max Element Size | Maximale Anzahl an Elementen, die beim Berechnen der Textsegmente überlappt werden | ||||||||||||
Large Text Segment Max Size | Maximale Anzahl von Segmenten, die für große Textsegmente verwendet werden. | ||||||||||||
Large Text Segment Overlap Size | Anzahl der überlappenden Segmente, die für große Segmente verwendet werden sollen. | ||||||||||||
Large Text Segment Min Size | Mindestanzahl von Segmenten, die für große Segmente verwendet werden. | ||||||||||||
Bereich: Similarity Search Settings | |||||||||
Minimum Score | Es werden bei der Suche nur Antworten geliefert, die mindestens den hier konfigurierten Score aufweisen. Gültige Werte für diese Option: 0.0 bis 1.0 Standardeinstellung: 0.5 | ||||||||
Definiert die Größe der Antworten. Diese Einstellung kann überschrieben werden, wenn sie in der Query Expression explizit angegeben wird, z.B. ~[region:large]"Wie viele Konnektoren bietet Mindbreeze InSpire an?". Folgende Optionen stehen zur Auswahl:
Standardeinstellung: Use Global Settings. | |||||||||
Diese Einstellung wirkt sich auf die Anzahl der Ergebnisse aus, die von der Similarity Search gefunden werden. Man konfiguriert die Einstellung, indem man die maximale Anzahl der besten Vektoren definiert, die bei einer Similarity Search zuerst abgefragt und dann weiterverarbeitet werden. Die Definition der maximalen Anzahl abgerufener Vektoren kann sich wie folgt auswirken:
Standardeinstellung: leer (der Wert „1000“ aus den globalen Einstellungen wird verwendet). Hinweis: Diese Einstellung überschreibt den Wert der globalen Konfiguration. Achtung: Die Standardeinstellung ist für die meisten Anwendungsfälle ausreichend, da sie es der Similarity Search ermöglicht, in kurzer Zeit viele Ergebnisse zu finden. Bitte ändern Sie diese Einstellung nur in Absprache mit dem Mindbreeze Support. | |||||||||
Transform Terms to Similarity | Wenn aktiv, werden terms_expr automatisch in similarity_expr umgewandelt. Somit wird bei einer normalen unparsed_expr Suche (z. B. bei einer Suche mit der Standard Insight App) automatisch eine Similarity-Suche durchgeführt. Bitte beachten Sie, dass dazu auch „Enable Unparsed Term Series to Terms Transformer“ aktiviert sein muss (Standard: enabled). Standardeinstellung: Optional.
| ||||||||
Remove Trailing Question Mark | Wenn aktiv, wird das Fragezeichen am Ende der Query entfernt, falls vorhanden. Nur wirksam, wenn Transform Terms to Similarity aktiviert (Enabled oder Optional). Hinweis: Beim Standard Sentence Transformer Modell führt diese Option (wenn aktiv) durchschnittlich zu besseren Ergebnissen. Standardeinstellung: Aktiviert | ||||||||
Similarity Include Ignored Terms | Wenn aktiv, werden ignorierte Terme von QueryExprTransformation Services (z.B. Stoppwörter) trotzdem in der Similarity Search miteinenbezogen. In der Volltextsuche werden diese Terme weiterhin ignoriert. Nur wirksam, wenn Transform Terms to Similarity aktiviert (Enabled oder Optional). Standardeinstellung: Aktiviert | ||||||||
Die Suchstrategie für die Similarity Search. Eine Änderung der Standardeinstellung kann zu einer Verschlechterung der Performance führen und sollte daher normalerweise nicht geändert werden.
| |||||||||

Area: Global Similarity Search Settings | |
Text Region | Nur aktiv, wenn in den lokalen Index Settings Use Global Settings ausgewählt ist. Siehe Beschreibung von Text Region in der Tabelle „Similarity Search Settings (Indices)”. |
Maximum Retrieved Vectors | Die maximale Anzahl der besten Vektoren, die bei einer Similarity Search zuerst abgefragt werden, bevor sie weiterverarbeitet werden. Standardwert: 100 |

Bereich: Similarity Search Settings | |
Answer Count | Die maximale Anzahl der Antworten, die mit einer einzigen Suchanfrage zurückgegeben werden, sofern dies nicht ausdrücklich in der Insight App angegeben ist. Für mehr Informationen zur Angabe des Answer Count in einer Insight App, siehe Entwicklung von Insight Apps - Antworten. |
Maximum Request Answer Count | Definiert das Maximum an Antworten, die angefragt werden können in einer Suchanfrage. Ist die Anzahl der Antworten in der Insight App festgelegt, kann diese das Maximum nicht überschreiten. Standardeinstellung: 100 Für mehr Informationen zur Angabe des Answer Count in einer Insight App, siehe Entwicklung von Insight Apps - Antworten. |
Minimum Score | Es werden bei der Suche nur Antworten geliefert, die mindestens den hier konfigurierten Score aufweisen. Gültige Werte für diese Option: 0.0 bis 1.0 Standardeinstellung: 0.5 Hinweis: Diese Option überschreibt die Indexeinstellung “Minimum Score“. Wenn Minimum Score in den Client Services Einstellungen nicht konfiguriert ist, wird Minimum Score aus den Indices Einstellungen verwendet. |
Maximum Retrieved Vectors | Die maximale Anzahl der besten Vektoren, die bei einer Ähnlichkeitssuche zuerst abgefragt und dann weiterverarbeitet werden. Wenn diese Einstellung leer ist, wird der Wert der Global Similarity Search Settings verwendet. Standardwert: leer |

Storage Einstellungen
Bereich: Storage Settings | |
Block Storage Requests on Sync | Wärend einer laufenden Indexsynchronisierung kann es kurzfristig dazu kommen, dass keine Dokumente verarbeitet werden können. In diesem Fall werden Filter/Index-Anfragen mit HTTP-Status-Code 503 beantwortet. Ist diese Option aktiv, wird stattdessen die Anfrage blockiert bist sie beantwortet werden kann. |
Stop Word Catalogs Settings
Stop-Word-Kataloge können in einigen Anwendungsfällen, z. B. bei der Hervorhebung, zum Überspringen von Stopp-Wörtern verwendet werden.
Section: Stop Word Catalogs Settings | |||||||||||||
Stop Word Catalogs Strategy | Mit dieser Option können Sie die zu ladenden Stop-Word-Kataloge bestimmen oder Stop-Words ganz deaktivieren. Sie können zwischen den folgenden Optionen wählen:
| ||||||||||||
Path to Custom Stop Words Catalogs Directory | Hier können Sie den Verzeichnispfad (innerhalb Ihres lokalen Rechners) für benutzerdefinierte Modelle und Kataloge angeben. Es ist notwendig, die Verzeichnisstruktur und die Benennungskonvention zu befolgen, die in Anhang G beschrieben sind. | ||||||||||||
Exclude Stop Words from Highlighting | Wenn diese Option aktiviert ist, werden Stopp-Wörter vom Highlighting ausgeschlossen. | ||||||||||||
Exclude Stop Words from Term Lexicons | Wenn diese Option aktiviert ist, werden Stopp-Wörter nicht in den Term Lexica aufgenommen. Bitte beachten Sie, dass nach einer Änderung dieser Option eine vollständige Re-Invertierung benötigt wird. Ist diese Option aktiv und es wird der dahinterliegende Stopp-Wort-Katalog geändert, ist ebenfalls eine vollständige Re-Invertierung notwendig. | ||||||||||||

Textbereinigung
Mit der Option „Text Cleaning“ können spezielle Unicode-Zeichen aus dem Beispieltext und der HTML-Vorschau entfernt werden. Die Option ist standardmäßig aktiviert.

Datenquellen
Zur Erstellung von Datenquellen für einen Index klicken Sie im Abschnitt „Data Sources“ ganz unten auf eines der Symbole rechts in der Kopfzeile.

Zu jedem Index können Sie beliebig viele Datenquellen zuordnen.
Drittanbieter-Datenquellen
Eine Drittanbieter-Datenquelle ermöglicht Ihnen von einem Dritthersteller integrierte Daten auch vom Mindbreeze InSpire Client durchsuchbar zu machen.
Solche Konnektoren können im Mindbreeze Management Center installiert werden (siehe auch Konfiguration – Plugin Installation).
Zur Erstellung einer Drittanbieter-Datenquelle gehen Sie wie folgt vor:
- Klicken Sie auf das Symbol
 , es erscheint die Konfigurationsmaske für eine Drittanbieter-Datenquelle
, es erscheint die Konfigurationsmaske für eine Drittanbieter-Datenquelle - Geben Sie im Feld „Source name“ einen beliebigen Namen für diese Datenquelle ein
- Wählen Sie im Feld „Category“ die registrierte Datenkategorie, die der einzustellenden Datenquelle entspricht.
Um die durchgeführten Änderungen dauerhaft zu speichern, drücken Sie den „Save“ Knopf rechts oben.
Wie Sie eine neue Datenkategorie in Mindbreeze InSpire registrieren können und wie Ihre Indizierung zu konfigurieren ist, erfahren Sie aus der Dokumentation der jeweiligen Dritthersteller-Mindbreeze-Connector.
Crawler-Zeitplanung
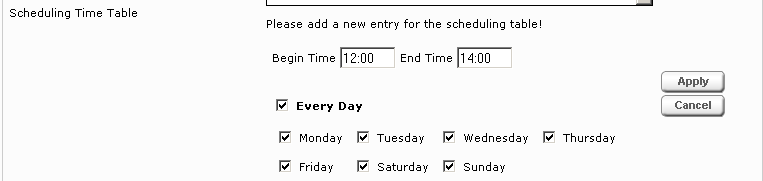
Für jede Datenquelle ist es möglich, einen Zeitraum zu definieren, in dem diese aktiv ihre Daten für die Suche aufbereitet. Dafür müssen Sie „Advanced Settings“ aktiviert haben. Danach sehen Sie unterhalb der Standard Konfigurationsfelder unter anderem ein neues Feld „Crawler Schedule“.
Dieses Feld zeigt, welche Zeiträume bereits definiert sind. Um einen neuen Zeitraum hinzuzufügen, benutzen sie die Schaltfläche „Add“. Um einen bestehenden Zeitraum zu modifizieren, selektieren Sie ihn bitte in der Liste und benutzen dann bitte die Schaltfläche "Edit". Einen bestehenden Zeitraum löschen können Sie mit der Schaltfläche "Remove" entfernen.

Nun öffnet sich darunter eine neue Eingabefläche.

Hier können sie nun die Startzeit und die Endzeit des Vorgangs festlegen. Diese müssen im Format hh:mm eingegeben werden. Weiters können Sie bestimmen, an welchen Tagen diese Aufgabe gestartet werden soll. Wenn Sie Every Day auswählen, wird der Vorgang an jedem Tag ausgeführt, ansonsten nur an den von Ihnen bestimmten Wochentagen. Mit der Schaltfläche „Cancel“ verwerfen Sie ihre Einstellungen. Drücken Sie „Apply“, um den Zeitraum zu übernehmen. Danach sollte dieser Zeitraum im Feld „Crawler Schedule“ angezeigt werden.
Um alle Änderungen endgültig abzuspeichern, müssen Sie noch die Schaltfläche „Save“ am Kopf der Seite betätigen.
Filter- und Index Performanzeinstellungen
Unter „Advanced Settings“ hat man die Möglichkeit im Bereich „Performance Settings“ mit der Option „Concurrent Filter and Index Dispatch Threads“ die Anzahl der Threads festzulegen, welche Dokumente parallel herunterladen und an den Filter- und Index Service schicken. Mit einem höheren Wert (z.B. 20) kann man die Performance optimieren, allerdings erhöht sich somit auch die Auslastung des Filter- und Index-Service.
Standardwert: 10
Extension Point Properties und Environment Variables
Für jede Datenquelle können “Extension Point Properties“ und „Extension Point Environment Variables“ definiert werden. Diese Einstellungen sind für Sie nicht relevant und dienen nur zur internen Verwendung.
Anpassen des Category Descriptors
Die Category Descriptor beschreibt die Anzeigeoptionen und die Filterinformation einer Datenquelle und ist ein XML Dokument, das im Plugin abgelegt ist (typischerweise categoryDescriptor.xml, der Name ist via plugins.xml referenziert). Die Wurzel bildet das „category“ Element.
<?xml version="1.0" encoding="UTF-8"?>
<category id="Category" supportsPublic="false" keep-docinfo-metadata="false">
<name>Category</name>
</category>
Attribute auf dem „category“ Element sind:
- supportsPublic: definiert, ob die Datenquelle in einem öffentlichen Index konfiguriert werden darf. Der Standardwert ist false.
- keep-docinfo-metadata: definiert, ob Metadaten die aggregatable oder regexmatchable Attribute aufweisen durch einen aktualisierten Descriptor bestehen bleiben oder überschrieben werden. Der Standardwert ist false.
Hinzufügen von eigenen Metadaten Spalten
Eine Metadaten-Definition könnte folgendermaßen aussehen:
<metadata>
<metadatum aggregatable="true" id="current_state" visible="true">
<name xml:lang="en">Ticket State</name>
<name xml:lang="de">Ticket Status</name>
</metadatum>
</metadata>
Folgende Attribute können auf dem metadatum Element definiert werden und dienen der Steuerung des Metadatums im Index:
- aggregatable: wenn diese Option auf true gesetzt ist, wird die Spalte als Filter verfügbar sein (soll nur für Properties definiert werden, bei denen die Werte eine Gruppierung der Ergebnisse zulassen – bei einzigartigen Werten, die also im Suchergebnis jeweils nur einmal vorkommen können, macht aggregatable keinen Sinn).
- regexmatchable: definiert, ob die Suche nach diesen Metadaten mit einer Regular Expression durchgeführt werden kann.
- visible: definiert, ob die Spalte in der standardmäßigen Ergebnispräsentation angezeigt wird.
Ersetzen der Treffersymbole
Das kleine Icon in der Datenquelle-Liste beim Suchclient wird von der Datei „categoryIcon.png” im ZIP-Archiv vom Datenquelle Plugin bestimmt. Sie können das Icon mit einem 16x16 Icon Ihrer Wahl ersetzen.
Sie können ein Icon auch direkt im categoryDescriptor.xml mit dem Icon-Tag definieren. Es benötigt eine eindeutige id, Größenattribute (height und width) und das Bild selbst (value), codiert als Base64-Wert.
<context>
<Icon alt="Ticket" height="16" width="16"
id="tag:mindbreeze.com,2007/contextitems/contexticon;ticket"
mimetype="image/png"
type="tag:mindbreeze.com,2007/contextitems/contexticon"
value="
iVBORw0KGgoAAAANSUhEUgAAABAAAAAQCAYAAAAf8/9hAAAABmJLR0QA/wD/AP+gvaeTAAAACXBIWXMAAAsTA AALEwEAmpwYAAAAB3RJTUUH3wIXECgw/xAFagAAAS1JREFUOMvFkz1uwkAUhL/nNV4Zesw9wgUILYq4gymCgCiRIG3gCkAOEnMFTgMNFT8W65cCpOAIAqmY8knzaTQ7C/eWvA8Gpd1uN3HOPQFyo0+NMYm1tkcrjmuzJNH/apYk2orjmu+c88tRxHq91tVqJSJ/hBBhu9kQRZGWo0icc74PoFmGqspkPMZae9G/3W55brdJ01Q0ywA4AIAgCPgYDi+agyAAYL/fIyLo8e4fKlEKhQKf0+nZBM45ur1eDoTqCeCo17e36/WrctpTDtDtdAjD8KzROUej0eCxXs/dc4DhaJSjh2FIsVi8nkA8D0Dn87kU/B9mpVLhoVr99ZICoOJ5AuAbY/bLxQJAms3mzQteLhYYY5wM+v1SmqbT45S5ecqe9xVY+3L3z8g3o1Sele9r3SQAAAAASUVORK5CYII= " />
</context>
Hinzufügen von benutzerdefinierten Trefferaktionen
Es ist möglich, benutzerdefinierte Aktionen, die auf spezifischen Metadaten basieren, hinzuzufügen. Z. B. um ein Ticket-Suchresultat in einer benutzerdefinierten Ticket Webanwendung zu öffnen.
<context>
<Menu>
<Action name="Open" pattern="http://intranet.myorganization.com/ticketing/show.html?ticketid={{mes:key}}">
<name xml:lang="en">Open Ticket</name>
<name xml:lang="de">Ticket Öffnen</name>
</Action>
</Menu>
</context>
Damit die Änderungen wirksam werden, können Sie das Plugin ZIP-Archiv mit dem modifizierte categoryDescriptor.xml über die Mindbreeze Konfigurationsoberfläche hochladen.
Anmerkung: es wird empfohlen, modifizierte Plugins mit einem eigenen Namen umzubenennen, um Änderungen in Produktupdates besser erkennen zu können.
Einschränkungen
Die gleichzeitige Verwendung derselben Kategoriebezeichnung in zwei benutzerdefinierten Plugins wird nicht unterstützt. In diesem Fall ist die Reihenfolge, in der diese Plugins während eines Snapshots verwendet werden, nicht definiert.
App.telemetry Konfiguration für Crawl Runs
Die Crawl Run Informationen können in einen separaten LogPool abgelegt werden.
Dazu müssen die Fabasoft app.telemetry Log Definitionen für die Mindbreeze Services von der Mindbreeze Konfigurationsoberfläche heruntergeladen werden. Wählen Sie dazu den „Overview“ Karteireiter aus und klicken Sie auf dem Link „Fabasoft app.telemetry log definitions and Dashboards“.
Legen sie danach einen neuen Logpool mit folgenden Einstellungen an:

Application: Mindbreeze
Application ID: *
Application Tier: Crawler Service Run
Tier ID: *
Im Tab “Log Definition Columns” muss noch die xml Datei: apptelemetrylogdefinitions_crawlerservicerun.xml aus den Logdefinitionsarchiv hochgeladen werden.

Registerkarte „Filters“
Auf der Registerkarte „Filters“ können alle Filter Services verwaltet werden. Im Feld „Filter Services“ werden die vorhandenen Filter Services angezeigt. Das Plus-Symbol rechts außen im Kopfbereich der Liste dient zum Hinzufügen weiterer Filter Services.

Um im Feld Filters ein neues Filter Service zu erzeugen, gehen Sie folgendermaßen vor:
- Klicken Sie auf das Plus-Symbol rechts außen im Kopfbereich der Liste ().
- Bearbeiten Sie die Eigenschaften des Filter Service.
- Im Feld „Setup“ steht standardmäßig das Feld „Display Name“ zur Verfügung. In diesem Feld kann ein Name für das Filter Service definiert werden.
- Im Feld „Node“ können jene Server ausgewählt werden, auf denen das Filter Service ausgeführt werden soll.
Um ein Filter Service anzupassen, gehen Sie folgendermaßen vor:
- Markieren Sie das Kontrollkästchen „Advanced settings“, um alle Dateierweiterungen anzuzeigen, die vom Filter Service nach Informationen durchsucht werden soll. Verfügbare Filter werden ebenso angezeigt, wie die von Mindbreeze InSpire bereitgestellten Filter.
- Falls der Java Filter mehr Speicher bei der Ausführung benötigt, erhöhen Sie den Wert der Option „Embedded Java VM Maximum Heap Size“.
- Zur Analyse von Fehlern und Problemen mit den Filtern aktivieren Sie „Dump Requests/Responses“ und wählen ein Verzeichnis zur Ablage der „Dumps“ aus.
- Standardmäßig können nur Dokumente die kleiner als 50 MB sind gefiltert werden. Um größere Dokumente zu filtern, erhöhen Sie den Wert „Maximal Input Size (MB)“.
- Um das Filtern von Zips oder PST-Files zu beschleunigen erhöhen Sie den Wert „Maximum Threads per Filter Request“ um mehr Parallelität zu erlangen.
- Bestimmen Sie die „Maximum Filter Recursion Depth“ um die Anzahl extrahierter Objekte aus ineinander verschachtelten Containerobjekten wie ZIPs zu steuern.
- Definieren Sie eine Regular Expression für die Option „Filter Pass Through Regular Expression“ um ausgewählte Extensions ohne Filter direkt an den Index zu schicken.
- „Index Empty Content Regardless of Extension“:Dokumente mit leerem Inhalt werden immer indiziert, auch falls kein Content Filter für den Dokumenttyp definiert ist.
- Geben Sie im Feld „Probe Filters Matching Extension Regex“ die Datei-Endungen – in der Form von Regular Expression - ein, für die alle Filter-Plugins ausprobiert werden sollen, wenn ein Fehler passiert.
- Um die Metadaten von der Datenquelle beim Filtern nicht zu überschreiben, Wählen sie „Keep Datasource Metadata“ von „Metadata Merge Strategy“ Dropdown Box.
- Bearbeiten Sie die „Filter Plugins“ analog der gewünschten Konfiguration. Abhängig von der Dateiendung werden Dokumente unterschiedlich vom Filter Service behandelt, hier kann angepasst werden, ob und von welchem Filter Plugin ein bestimmter Dateityp behandelt werden soll.
- Im Feld „Generate CRC64 of Metadata“ kann eingestellt werden, ob eine CRC64 der gefilterten Metadaten generiert werden soll. Ist CRC unterschiedlich, wird ein Dokument im Index gegebenenfalls ersetzt. Weiters gibt es zusätzlich noch die Möglichkeit über Regular Expression Rules einzelne Metadaten der Crawler zur Berechnung des CRC hinzuzufügen oder auszunehmen. Die Standardkonfiguration sieht vor das alle Metadaten der Crawler zur Berechnung des Metadata CRC herangezogen werden.
- Aktivieren Sie “Ignore Heartbeat Error” falls das Filter Service nicht neugestartet werden soll wenn es keine Heartbeats an Node schickt. Das kann bei stark ausgelastetem System der Fall sein.
Metadata CRC:
- Wenn die Option „Generate CRC64 of Metadata“ aktiviert ist, wird der metadatacrc zusätzlich verwendet um zu prüfen, ob ein Item im Index ersetzt werden soll.
- In den weiteren Optionen kann eine „Regular Expression“ angegeben werden um Metadaten im CRC zu inkludieren oder zu exkludieren.
Indizieren zusätzlicher PDF Metadaten
Aus PDF Dokumenten werden falls verfügbar die folgenden Metadaten extrahiert:
- document:title
- document:Author
- document:Subject
- document:Keywords
- document:Creator
- document:Producer
- document:CreationDate
- document:LastModified
- document:Trapped
- document:PageCount
Um zusätzliche PDF Metadaten zu extrahieren gehen, fügen Sie beim Filter unter „Global Filter Plugin Properties“ das Plugin „FilterPlugin.PDFPreviewFPDFFilter“ hinzu und konfigurieren Sie die Eigenschaft „PDF Meta Keys“, getrennt mit Strichpunkt, siehe unten:

HTML Meta Tags als Metadaten speichern
Die HTML Filter Plugins Jericho und JerichoWithThumbnails extrahieren die HTML Meta Tags als Metadatumswerte. Wenn diese HTML Meta Tags mehrfach vorkommen (mit demselben Namen und Wert), ist es möglich diese nur einmal als Metadatumwert speichern.
Fügen Sie dafür beim Filter unter „Global Filter Plugin Properties“ das Plugin „FilterPlugin.JerichoWithThumbnails“ oder „FilterPlugin.Jericho“ (wenn keine HTML Thumbnail Generierung verwendet ist) hinzu und aktivieren Sie die Eigenschaft „Store only distinct HTML meta tag values as metadata“.

Wenn hier ein Regulärer Ausdruck als „Parsable HTML meta tag pattern“ definiert ist, werden nur Meta Tags mit passenden „name“ oder „http-equiv“ Attributen als Metadaten gespeichert.
Falls Post Filter Transformation Plugins installiert sind (z.B.: SignatureToKeyRewriter) wird folgender zusätzlicher Abschnitt angezeigt:

Verwenden Sie die Drop-Down Box, um ein verfügbares Post Filter Transformation Plugin auszuwählen. Aktivieren Sie ein ausgewähltes Plugin indem Sie auf die „Add“ Schaltfläche daneben klicken.
Aktivierte Plugins werden im Bereich über der „Add“ Schaltfläche aufgelistet. Durch Bestätigen der „Expandieren“ Schaltfläche eines aktiven Plugins wird ein Abschnitt mit den Plugin Properties angezeigt. Hier haben Sie die Möglichkeit Properties in Form von Schlüssel – Wert Paaren für das aktuelle Plugin zu definieren. Mit der entsprechenden „delete“ Schaltfläche können Sie diese benutzerspezifischen Plugin Properties wieder löschen.
Ein Klick auf eine weitere „delete“ Schaltfläche rechts neben dem Pluginnamen entfernt das ganze Plugin mitsamt aller benutzerspezifischen Properties, sodass dieses nicht mehr vom aktuellen Filtern Service verwendet wird.
- Um Ihre Angaben zu übernehmen, klicken Sie auf die Schaltfläche „Save“. Änderungen der Konfiguration werden den betroffenen Nodes mitgeteilt und übernommen.
- Wechseln Sie auf die Registerkarte „Overview“, um eine Übersicht über die Zuordnung von Services zu Servernodes angezeigt zu bekommen.
Gleich wie bei der Registerkarte „Indices“ gibt es auch auf der Registerkarte „Filters“ die Möglichkeit den Support-Modus einzuschalten.
Destination rewrite

Einstellung | Beschreibung |
Ist eine regulärer Ausdruck (regex) der auf Destinations in Index-Requests angewendet wird z.B.: | |
Destination Replacement | Die Destination wird mit “Destination Replacement” ersetzt. Es können Optional Backreferences auf Capture-Groups in “Destination Pattern” verwendet werden z.B.: |
Registerkarte „Client Services“
Auf der Registerkarte „Client Services“ werden alle Client Services verwaltet. Ein Client Service stellt die serverseitige Unterstützung für den Mindbreeze InSpire Web Client zur Verfügung. Im Feld „Web Client Services“ werden die vorhandenen Web-Client-Services angezeigt.
Über einen Klick auf das Plus-Symbol (![]() ) rechts außen im Kopfbereich der Liste können weitere hinzugefügt werden.
) rechts außen im Kopfbereich der Liste können weitere hinzugefügt werden.

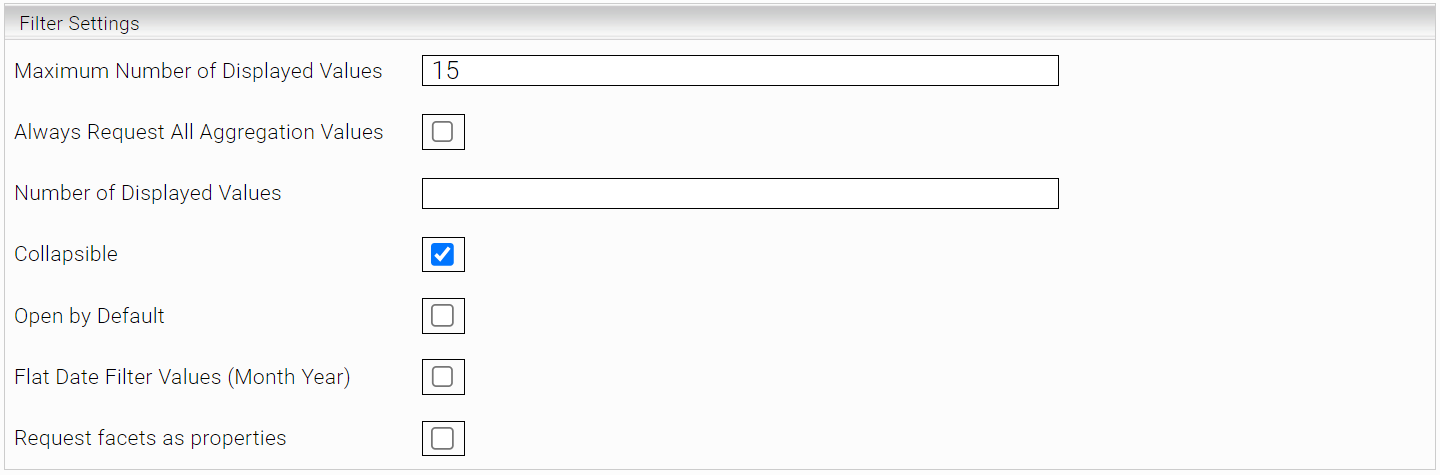
Um ein neues Web Client Service zu erstellen, gehen Sie folgendermaßen vor:
Klicken Sie auf das Plus-Symbol rechts außen im Kopfbereich der Liste (![]() ).
).
Bei Anklicken des „Enable“ bzw „Disable“ -Button kann man einen bereits erstellten Client Service temporär ein- oder ausschalten.
Folgende Optionen stehen zur Verfügung:
Bereich: Setup | |
Display Name | In diesem Feld wird der Name für das Client Service definiert. |
Node | In diesem Feld wird der Rechner angegeben, auf dem das Client Service ausgeführt wird. |
Port (HTTPS) | In diesem Feld wird konfiguriert, unter welchem TCP-Port das Service erreichbar gemacht wird. Dieser Port steht dann in der Adresse vom Web Client, z.B. http://myserver.myorganization.com:23350/ |
Bind Address (HTTPS) | Hier wird konfiguriert, auf welcher IP-Adresse das Service erreichbar ist. Standardmäßig (Wert nicht gesetzt) wird die IP-Adresse 0.0.0.0 (alle IP-Adressen) verwendet. Wenn beispielsweise der Service nur auf localhost erreichbar sein soll, muss die Option „Bind Address (HTTPS)“ auf den Wert 127.0.0.1 gesetzt werden. |
Data Port (TCP/IP) | TCP-Port, der zur Kommunikation mit Subsystemen verwendet wird. |
Query Metrics Port(TCP/IP) | Mit diesem Port kann das Aufzeichnen von Query Statistiken eingeschaltet werden. Wird dieser Port nicht konfiguriert gibt es keine Aufzeichnungen. |
Requires Authentication | Dieses Feld definiert, ob das Client Service seine Ressourcen öffentlich anbietet, oder nur für die lokalen Benutzer. Sollen die Daten öffentlich verfügbar gemacht werden, so müssen die Indizes auch entsprechend markiert sein („Advanced Settings“, „Unrestricted Public Access“). |
Suppress Termination Cause | Bei Aktivierung der Option wird dem Benutzer keine Information angezeigt, falls bei einer Suche ein Timeout auftritt. |
Display Tabs for Data Sources | Ist diese Option aktiviert, werden für alle aktivierten Datenquellen Karteireiter angezeigt. |
Enable Tab Editing | Ist diese Option aktiviert, können die Karteireiter editiert werden. |
Load More Results Using | Ist „Infinite Scrolling“ aktiv, werden in der Standardsuchanwendung weitere Resultate automatisch geladen, wenn man ans Ende der Seite kommt. Mit Pages aktiviert man das seitenweise Blättern. Die Anzahl der maximal sichtbaren Seiten wird mit Maximum Number of Displayed Pages eingestellt. |
Pages
|


URL of Help-Website | Hier kann eine URL zu einer Hilfeseite hinterlegt werden, die im Client Service als Link zur Verfügung steht. |
Fabasoft app.telemetry Web API URL | Tragen Sie hier die URL zur app.telemetry Web API ein, um End-To-End Software-Instrumentierung einzuschalten. |
Dump Requests | Zur Analyse von Fehlern und Problemen aktivieren Sie diese Option. |
Dump Directory | Ist das Verzeichnis zur Ablage der „Dumps“. |
One Phase Search and Enrich | Ist diese Option aktiviert, werden Suche und Kontextualisierung der Resultate in einer Anfrage, statt der üblichen zwei, durchgeführt. Aktivieren Sie diese Option, falls vom Client Service nur wenige Query Engines verwendet werden. |
Disable External Contextualization | Die Kontextualisierung ist eine Standard-Schnittstelle zur Transformation der Treffer durch Plugins. Die Treffer werden dadurch im Client „kontextualisiert“ bzw. korrekt angezeigt. Ist diese Option aktiviert, wird bei der Suche keine externe Kontextualisierung durchgeführt. Diese Option kann vom Search Request übersteuert werden. Standardeinstellung: Deaktviert. |
Logout Redirect URL | Meldet sich ein Benutzer vom Client Service ab, erfolgt eine Weiterleitung zur konfigurierten URL. Wird kein Wert angegeben, erfolgt eine Weiterleitung zur Startseite des Client Service. |
User ID is E-Mail Address | Falls der angezeigte Benutzername eine gültige E-Mail Adresse ist, kann damit festgelegt werden, dass die E-Mail Adresse im Feedback Dialog automatisch befüllt wird. |
Disable Autocompletion of Query | Deaktiviert die Autovervollständigung des Suchbegriffs. |
Mandatory Data Source Search In Constraints Resolution | Führt dazu, dass für alle Datenquellen die Search In Constraints berechnet werden. Kann im Category Descriptor je Datenquelle gesetzt werden. |
Query Expansion for Diacritic Term Variants | Ist diese Option aktiviert, wird die Suche auf diakritischen Varianten des Suchwortes ausgeweitet. |
Use SSL (HTTPS) | Diese Option legt fest, ob das Client Service SSL verwendet. Ist „Use SSL“ aktiviert, ist das Client Service im Browser unter https:// verfügbar, sonst unter http://. Die Einstellung „Port“ wird weiterhin berücksichtigt. |
Supported TLS Protocols | Diese Option erlaubt die vom Client Service unterstützten TLS Protokolle zu konfigurieren. Hier kann eine, mit Beistrich getrennte Liste von JSSE Protokollnamen angegeben werden. Die Dokumentation von JSSE finden Sie hier. |
SSL Certificate | Dieses Feld erlaubt die Auswahl des vom Client Service verwendeten SSL-Zertifikats. Als Standardeinstellung wird das in der Lizenz enthaltene Zertifikat verwendet („Use SSL Certificate supplied with your license“). Wurden in der Registerkarte „Certificates“ SSL-Zertifikate installiert, werden diese zur Auswahl angeboten. |
Use SAML Authentication | Legt fest, ob SAML-Authentifizierung für das Client Service verwendet wird. |
External URL | Definiert die URL unter dem der Client Service ereichbar ist. Falls ein Load Balancer oder Reverse Proxy verwendet wird, ist die Angabe einer externen URL (inklusive Pfad) zwingend notwendig. Siehe dazu die Beschreibung der Einstellung „URL Base Path“. Achtung: Ist keine externe URL gesetzt, können potentielle Probleme mit diversen Features und Authorisierungen autreten. Daher wird die Angabe einer externen URL, unabhängig vom Anwendungsfall, empfohlen. |
URL Base Path | Hier kann eine andere URL als der Default Root („/“) Basispfad eingetragen werden. Das wird vor allem benötigt, wenn ein Client Service hinter einem zentralen Reverse Proxy, der URL-Pfade nicht umschreiben kann, verwendet wird. |
Override Browser Language | Wenn "Use Browser Language" ausgewählt ist, wird die Spracheinstellung des Browsers eines Benutzers für die Lokalisierung des Client Service verwendet. Ansonsten hat die in diesem Feld ausgewählte Sprache Vorrang gegenüber der Browsersprache. |
Enable Explicit Time Zone | Standardmäßig wird für Datumswerte in Suchergebnisse die Zeitzone des Browsers verwendet. Wenn Sie stattdessen eine andere Zeitzone verwenden wollen, aktivieren Sie diese Option und setzen die gewünschte Zeitzone in der Option „Explicit Time Zone“. |
Fallback to English for Languages without Built-In Translations | Wenn diese Option aktiviert ist, werden Sprachen, die nicht über integrierte Übersetzungen verfügen, stattdessen als en-US geparst. Wenn diese Option deaktiviert ist, werden alle Sprachen des ISO 639-Standards akzeptiert und an den Client-Service weitergeleitet. Hinweise: Diese Einstellung ist nur relevant, wenn Sie benutzerdefinierte i18n-Übersetzungen für diesen Client-Dienst verwenden. Eine Liste der Sprachen mit integrierten Übersetzungen finden Sie in der Mindbreeze Inspire Produktinformation. |
Explicit Time Zone | Zeitzone, in der die Datumswerte in Suchergebnissen angezeigt werden. Die unterstütztem Zeitzonen sind hier gelistet. |
Servlet Affinity | Geben Sie hier eine eindeutige Bezeichnung für jedes Client Service ein, wenn Sie SAML Authentifizierung mit einem Load Balancer verwenden. Der Wert dieses Feldes wird als „AFFINITY“-Cookie hinterlegt. |
Maximum Number of User Query Terms | Limitiert die Anzahl der bei der Suche berücksichtigten Wörter. |
Maximum Custom Metadata Count | Wenn die Datenquelle gruppierte Metadaten unterstützt, wird mithilfe dieses Werts die Maximalanzahl der in der Detailansicht anzuzeigenden gruppierten Metadaten bestimmt. Zusätzlich bestimmt dieser Wert die maximale angezeigte Länge von Listen-Metadaten. |
Content Fetch Timeout | Legt fest, nach welcher Zeit das Herunterladen von Dokumenten abgebrochen wird. |
Query Timeout | Hier wird konfiguriert, nach welcher Zeit Suchen gegen einzelne Indizes abgebrochen werden. Die Suchen gegen einzelne Indizes werden parallel ausgeführt. Liefert ein Index innerhalb des Timeouts keine Resultate, dann werden nur Resultate der anderen Indizes angezeigt. Innerhalb dieses Timeouts werden alle notwendigen Vorgänge durchgeführt, wie z.B. Query Transformation, Suche im Index, Autorisation von Treffern usw… |
Refinement Resolution Timeout | Dieses Feld legt die Zeit fest, nach der das Laden von Einschränkungen abgebrochen wird |
Search In Resolution Timeout | Gibt an, nach welcher Zeit das Laden von der „Quellen“ Liste abgebrochen wird. |
HTTP Connect Timeout | Legt fest, nach welcher Zeit Anfragen an Query Services abgebrochen werden, wenn keine Verbindung aufgebaut werden kann. |
AJAX Request Timeout | Legt fest, nach welcher Zeit AJAX-Anfragen abgebrochen werden. |
Preview Length | Legt die Länge der Vorschau fest. |
Maximum Request Size | Maximale Anfragegröße in kB. |
Maximum Search Request Size | Maximale Anfragegröße für Suchanfragen in kB. |
User Profile Storage Path | Legt ein konkretes Verzeichnis fest, in dem die Benutzerprofile abgelegt werden. Benutzerprofile werden während der Verwendung des Clients automatisch gespeichert. Wenn mehrere Client Services die gleichen Benutzerprofile verwenden sollen, geben Sie hier jeweils den gleichen Pfad an. Ist kein Pfad eingetragen, werden die Benutzerprofile für jedes Client Service getrennt abgelegt. |
Embedded Java VM Args (-Xmx..) | Dieses Feld bestimmt Optionen die beim Start des Client Service übergeben werden. Bitte verwenden Sie diese Option nur in Rücksprache mit Mindbreeze Support. Mit der Option “-XX:+ExitOnOutOfMemoryError” wird das Client Service automatich neu gestartet wenn es aufgrund von Speicherauslastung nicht mehr reagiert. |
Flush in Memory Metrics after (queries) | Query Aufzeichnung werden nach dem angegebenen Wert Queries persistiert. |
Flush in Memory Metrics after (seconds) | Query Aufzeichnungen werden nach dem angegebenen Wert Sekunden persistiert. |
Maximum Metrics Filesize | Begrenzung der Dateigröße der Query Aufzeichnungen. |
Metrics Base Directory | Verzeichnis zum Ablegen der Query Aufzeichnungen. |
[Deprecated] Enable Healthcheck | Diese Option ist veraltet und soll nicht mehr verwendet werden. Bitte verwenden Sie stattdessen folgende Healthcheck Settings Option. Aktiviert das Healthcheck-Service, das für Tests der Funktionalität des Client Services verwendet werden kann. |

Bereich: Filter Settings | |
Maximum Number of Displayed Values | Hier kann die maximale Anzahl der pro Filter angezeigten Werte angegebene werden. |
Always Request All Aggregation Values | (Nur für Diagnosezwecke) Wenn diese Option ausgewählt ist, werden anstatt nur den „Maximum Number of Displayed Values“ alle Values vom Index angefordert. Dies kann die Performanz der Suche reduzieren. Dies hat keine Auswirkung auf Anzahl die im Client angezeigten Filterwerte. (Standardwert: nicht aktiv). |
Number of Displayed Values | Hier kann die Anzahl der pro Filter angezeigten Werte angegebene werden. |
Collapsible | Wenn diese Option ausgewählt ist, können die Filter Werte zusammengeklappt werden. |
Open by Default | Wenn diese Option ausgewählt ist, werden Filter Werte standardmäßig aufgeklappt angezeigt. |
Flat Date Filter Values (Month Year) | Wenn diese Option ausgewählt ist, werden bei Datumswerte die Filter Werte als eine flache Liste angezeigt (anstatt hierarchisch nach Jahr gruppiert). (Standardwert: nicht aktiv) |
Request facets as properties | Wenn diese Option aktiviert ist, werden alle filterbaren Eigenschaften auch für jedes Dokument abgefragt. Dies kann verwendet werden, um die Anzahl der Dokumente in den Filtern zu korrigieren, wenn mehrere Indizes Duplikate enthalten. Diese Option kann die Suchleistung drastisch verringern. |

Section: Chat UI Settings (Advanced Settings) | |
Chat Service | Der Insight Service, der für die Generierung von Antworten (für den AI Chat) verwendet werden soll, kann hier ausgewählt werden. |
Enable Feedback Button | Wenn diese Option aktiviert ist, wird ein Feedback-Button angezeigt, wenn Sie den Mauszeiger über eine Nachricht im AI Chat bewegen. Das Feedback wird an den app.telemetry Form Log Pool gesendet. |
app.telemetry Form ID | Die ID des app.telemetry Form Log Pools für Feedback-Nachrichten. Standardmäßig ist für diesen Zweck der Form Log Pool „ChatUI“ mit der Form ID „ChatUIForm“ vorhanden. Weitere Log Pools können in der app.telemetry Konfiguration angelegt werden. Diese Einstellung ist nur relevant, wenn „Enable Feedback Button“ aktiviert ist. |

Section: PDF Diff (Advanced Settings) | |
PDF Diff Service | Der Service, der für das Vergleichen von PDFs genutzt werden soll, kann hier ausgewählt werden. |
- „Additional Client Service Nodes“: Mindbreeze Knoten, auf welchen das Client Service zusätzlich gestartet wird
- Im Abschnitt „Data Sources“ wird die Sortierung der Datenquellen festgelegt. Durch „Group by Category“ werden die Datenquellen nach Datenquellentyp (Category) gruppiert und danach alphabetisch sortiert. Möchten sie die Reihenfolge der Datenquellentypen ändern, geben Sie die gewünschte Reihenfolge Beistrich getrennt in das Feld „Order of Categories“ ein. Um eine angepasste Sortierung nach Name der Datenquelle zu machen, verwenden Sie das Feld „Manual Order of Data Sources“. Ist „Group by Category“ aktiviert, werden die Datenquellen in der Gruppe nach vorne sortiert. Wenn Sie nicht alle verwendeten Datenquellentypen oder Namen angeben, werden die restlichen Datenquellen laut der Standardsortierung angezeigt. Enthält ein Wert einen Beistrich, können Sie statt der Beistrich getrennten Liste ein JSON-Array verwenden.
- Im Abschnitt „Filters“ können die Filter ausgewählt werden, die im Client Service angezeigt werden. Die auswählbaren Filter hängen von den ausgewählten Query Services und den konfigurierten Datenquellen ab.
- Im Feld „Query Engines“ können jene Query Services ausgewählt werden, die über das Client Service zur Verfügung gestellt werden.
- „Federated Query Engines“: Hier können die URLs von Query-Services eingetragen werden, die nicht von diesem Manager verwaltet werden. Zur Authorisierung ist hier eine spezielle Multi-Master Konfiguration erforderlich, genauere Details hierzu finden sich im Whitepaper "Konfiguration SAML (deu)".
- „Federated Client Services“: URLs von Client Services, die für alle Benutzer eingebunden werden.
- „Display federated results immediately, ignoring global relevancy ranking “: Ist die Option aktiviert, werden immer alle Resultate, die von den einzelnen Services angefordert wurden angezeigt. Dadurch kann es sein, dass weniger relevante Resultate bereits auf der ersten Seite angezeigt werden.
- „Federated Client Services Use Legacy Messageframe Channel”: Ist die Option aktiviert, läuft die Kommunikation zu den eingebunden Client Services über den Legacy Messageframe Channel. Diese Option kann verwendet werden, wenn Client Services eingebunden werden sollen, die auf einer InSpire Appliance der Version 20.2 oder älter laufen.
- „Use Legacy Messageframe Channel“: Um auch den Legacy Messageframe Channel für Client Services zu verwenden, die über die Einstellungen direkt am Search Client eingebunden wurden, setzen Sie die Option „Use Legacy Messageframe Channel“ auf „Enable“. Folgende Werte können ausgewählt werden:
- „Auto“: Mindbreeze InSpire entscheidet selbst, ob der Legacy Messageframe Channel verwendet wird (empfohlen)
- „Enable“: aktiviert explizit den Legacy Messageframe Channel
- „Disable“: deaktiviert explizit den Legacy Messageframe Channel
- „Metrics Query Engines“: Sollen für die Autovervollständigung Benutzeranfragen verwendet werden, müssen hier die URLs von Query Engines mit aufgezeichneten Metrics eingetragen werden.
- „Federated Sources“: Haken Sie die Option „Enable Fabasoft Mindbreeze Cloud Services” an, um mehrere Fabasoft Mindbreeze Cloud Services einzubinden. Referenzieren Sie eigene Servicelisten, um zusätzliche Services zu verwenden.
- „API V2 Concurrent Request Limits”: Hier können die maximal gleichzeitig verarbeiteten Anfragen pro API-Service konfiguriert werden. Ist das Limit erreicht, liefern die API-Aufrufe die Statusmeldung „Maximum number of concurrent requests exceeded, please try again later!“, bis das Limit wieder unterschritten wird. 0 bedeutet keine Limitierung. Standardwert: 0
- „API V2 Named Concurrent Request Limits“: Hier können die maximal gleichzeitig verarbeiteten Anfragen pro Anfrage Name konfiguriert werden. Der Anfrage Name kann mit dem Request Header „x-mes-api-request-name“ gesetzt werden. Wenn die „Request Name Pattern“ Regex auf die Anfrage Name passt wird der Anzahl gleichzeitig verarbeiteten Anfragen auf das Wert in „Maximum Concurrent Request Count“ Feld gesetzt. 0 bedeutet auch hier keine Limitierung.
- Im Abschnitt “Query Persistence Settings“ kann das Speichern von Suchen für den Benutzer freigeschaltet werden. Schalten sie mittels „Enable“ die Funktionalität frei und konfigurieren Sie eine Datenbankverbindung zum Speichern der Suchen mittels der Felder „JDBC URL“, „User“, „Password“ und „Database Table Prefix“. Der „Database Table Prefix“ kann dazu verwendet werden, um verschiedene Clientservices in die gleiche Datenbank abspeichern zu können. Die „User“ und „Password“ Parameter können auch als Username/Password Credential konfigurieren werden. Dazu muss ein Endpoint Eintrag für die JDBC URL angelegt werden.
- Wird im Abschnitt „Query Settings“ die Option „Count Filtered Values“ aktiviert so werden die Filterzahlen auch für nicht ausgewählte Filterwerte angezeigt.
- Wird im Abschnitt „Query Settings“ die Option „Enable Character NGRAMs“ aktiviert so können Character NGRAMs ein- und ausgeschaltet werden. Default: true.
- Die Einstellung „Maximum Request Result Count” im Abschnitt „Query Settings“ definiert das Maximum an Ergebnissen, die angefragt werden können in einer Suchanfrage. Ist die Anzahl der Ergebnisse in der Insight App festgelegt, kann diese das Maximum nicht überschreiten. Standardeinstellung: 100
- Mit der Auswahl der Option „Ignore Global Uniform Properties“ kann man die Übersetzung eines Metadatums, das im Uniform Property Descriptor existiert mit der Übersetzung im Category Descriptor der Datenquelle überschreiben.
Memory Analysis Settings (Advanced Settings)

Memory Test Allocation size in Bytes | Diese Option kann verwendet werden, um zu testen, wie lange eine Allokierung einer bestimmten Speichergröße auf Ihrer JVM dauert. Das Ergebnis befindet sich im Log-Verzeichnis des Client Services innerhalb der Logdatei memory-usage.csv. |
Statistcs Calculation Frequency | Hier kann bestimmt werden, in welchem Zeitintervall die Ergebnisse der Optionen „Memory Test Allocation size in Bytes“ und „Enable JVM Statistics“ berechnet werden sollen. (in Sekunden) |
Enable JVM Statistics | Wenn diese Option aktiviert ist, werden die JVM-Statistiken in die Logdatei memory-usage.csv im Log-Verzeichnis des Client Services geschrieben. |
Zulässige Weiterleitungs-URL für Benutzeranmeldung konfigurieren

Wenn sich ein Benutzer am Client-Service anmeldet, oder der Insight App Editor verwendet wird, werden je nach konfigurierter Anmeldeart vom Browser HTTP Weiterleitungen (über die Adresse /mashup-login) durchgeführt. Aus Sicherheitsgründen sind keine Weiterleitungen auf beliebige URLs erlaubt. Mit diesen Einstellungen kann konfiguriert werden, welche URLs zugelassen sind.
Standardmäßig ist die Einstellung „Allow login redirect URLs to“ auf „Client Service External URL“ gesetzt. Das bedeutet es werden nur URLs erlaubt, die der „External URL“ des Client Services entsprechen. Wenn z.B. die Client Service External URL https://search.myorganization.com ist, dann ist die URL https://search.myorganization.com/login erlaubt, die URL https://crm.myorganization.com/login allerdings nicht.
Hinweis: Ist im Client Service die External URL nicht gesetzt, dann wir nur das URL-Schema überprüft, HTTP oder HTTPS, je nach „Use SSL“ Einstellung im Client Service.
Relative URLs sind immer zulässig. Der Browser bekommt bei einer nicht zulässigen URL einen „HTTP 403 Forbidden“ Fehler.
Die Standardeinstellungen sind für einfache Anwendungsfälle meist ausreichend. In speziellen Fällen, wie bei z.B. Load-Balancer mit abweichenden Client Service „External URLs“ oder Reverse-Proxies, die SSL terminieren, sind die Standardeinstellungen nicht geeignet und verursachen HTTP 403 Fehler. Für diese speziellen Anwendungsfälle muss die Einstellung „Allow login redirect URLs to“ auf „Custom Pattern“ gestellt werden, sowie ein regulärer Ausdruck (Java) bei „Custom Pattern“ angegeben werden. Der reguläre Ausdruck wird direkt gegen die Weiterleitungs-URL gematcht. Bei einem Match ist die URL zulässing, ansonsten wird ein HTTP 403 Fehler ausgegeben. Ein Beispiel für einen regulären Ausdruck ist z.B. https://search.myorganization.com.* welcher die URL https://search.myorganization.com/login erlaubt, jedoch nicht https://crm.myorganization.com/login.
Hinweis: fehlt oder ist der reguläre Ausdruck fehlerhaft, so ist jede Weiterleitungs-URL nicht zulässig.
Einstellungen zur Impersonierung von Suchanfragen
Die Impersonierung von Suchanfragen wird beispielsweise im „InSpire AI Chat und Insight Services für Retrieval Augmented Generation“ im „Retrieval“ verwendet.

Einstellung | Beschreibung |
Token Lifetime (seconds) | Zeitdauer (in Sekunden) für die das Impersonierungs-Token gültig ist (Standard: 60 Sekunden). |
Zone ID | Benutzerdefinierte ID mit denen die Client-Services definiert werden, die sich gegenseitig Impersonierungs-Tokens ausstellen und akzeptieren. Standardwert: nicht gesetzt. |
Impersonation Zone ID
Aus Sicherheitsgründen wird ein Impersonierungs-Token, welches von einem Client Service ausgestellt wird, standardmäßig nur vom selben Client Service, oder von synchronisierten Client Services (Node-Verbund-Szenario) akzeptiert. Ein möglicher Anwendungsfall ist beispielsweise ein InSpire AI Chat, der hinter einem Load-Balancer betrieben wird, und ein Failover auf einen anderen Client-Service durchführt.
Dieses Verhalten kann bei Bedarf im Abschnitt „Impersonation Settings“ mit der Einstellung „Zone ID“ beeinflusst werden. Die „Zone ID“ kann auf einen beliebigen Wert konfiguriert werden, welcher dann zur Prüfung der Impersonierungs-Token verwendet wird. Ein möglicher Anwendungsfall ist beispielweise auf einem anderen Client-Service (am selben oder auf einem anderen Node) die gleiche Zone ID zu konfigurieren, damit der Retrieval-Suchvorgang im „InSpire AI Chat“ auf einem anderen Client-Service möglich ist, als der, über den der Benutzer einsteigt.
Sicherheitshinweise:
Stellen Sie unbedingt sicher, dass alle Client Services, bei denen Sie eine Zone ID setzen, eine korrekt konfigurierte Authentifizierung besitzen. Ein gültiges Impersonation-Token ermöglicht das Absetzen einer Suchanfrage ohne weitere Endbenutzer-Authentifizierung. Das Gesamtsystem ist nur so sicher, wie der am wenigsten sichere Client-Service unter den beteiligten Client-Services.
Einstellungen zur nicht-interaktiven Impersonierung
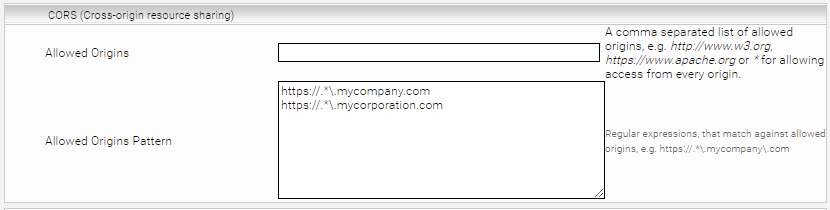
Einstellung | Beschreibung |
Enable Non-Interactive Impersonation | Wenn diese Option aktiviert ist, ist nicht-interaktive Impersonierung möglich. |
Token Lifetime (hours) | Die Zeitdauer (in Stunden) für die das nicht-interaktive Impersonierungs-Token gültig ist. Standardeinstellung: 24 Stunden |
Max Challenge Timestamp Age (seconds) | Das maximale Alter (in Sekunden) von Challenge Timestamps. Standardeinstellung: 60 Sekunden |
Allow remote requests | Wenn diese Option aktiviert ist, können nicht-interaktive Impersonierungstoken auch außerhalb von derselben Node verwendet werden. |
Einstellungen zur Validierung von Anfragen konfigurieren

Der Client Service unterstützt die Validierung des HTTP-Host Headers von Anfragen. Dadurch kann die Sicherheit erhöht werden. Mit der Einstellung „Validate HTTP Request Host Header Pattern“ kann ein regulärer Ausdruck angegeben werden, welcher auf den Host matched. Nur bei einer Übereinstimmung wird die Anfrage verarbeitet. Ansonsten wird ein Fehler im Log vermerkt und die Anfrage mit dem Status HTTP 403 zurückgewiesen.
Einstellungen zur Auslieferung von Bildern konfigurieren

Standardmäßig werden nicht-statische Bilder, wie z.B. Vorschaubilder oder Icons, als Data-URLs ausgeliefert. Falls z.B. ein Custom-Client mit Data-URLs Probleme macht, kann mit dem Aktivieren der Einstellung „Enable Get Image Resources In Separate Requests“ die Auslieferung auf HTTP(S)-URLs umgestellt werden. Diese Einstellung wird möglicherweise in der nächsten Version von Mindbreeze entfernt. Daher muss der Custom-Client angepasst werden und Data-URLs verwenden, um auch nach dem nächsten Update zu funktionieren. Sicherheitshinweis: Ist diese Einstellung aktiv, wird der Hostname in der URL nicht validiert.
Einstellungen für Query Service konfigurieren
In einem Producer-Consumer Szenario werden Suchanfragen auf dem Consumer Node standardmäßig an den Index im Consumer Node geleitet. Wenn z.B. wegen einer Wartung der Consumer Index nicht erreichbar ist, kann der Consumer nicht für eine Suche herangezogen werden. Die Client Service Einstellung „Enable Fallback to Query Services on other Nodes“ kann aktiviert werden, um in solchen Situationen die Suchanfrage direkt zu dem Producer Index zu senden. Dadurch wird die Verfügbarkeit der Suche in Producer-Consumer Szenarien verbessert.
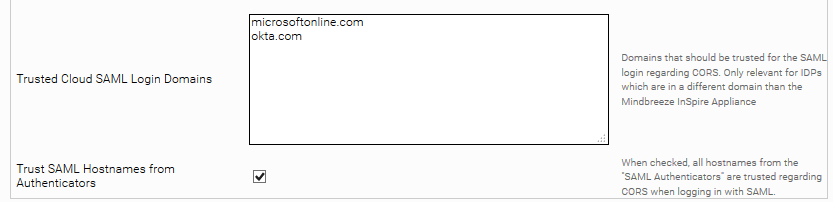
Die Einstellung "Use Credentials from Endpoint Mapping Fallback" ist für den internen Gebrauch bestimmt und muss nicht verändert werden.
Gespeicherte Suchen aktivieren

Diese Einstellung erlaubt es, die gespeicherten Suchen am Server abzuspeichern. Dazu kann im Abschnitt “Query Persistence Settings“ das Speichern von Suchen für den Benutzer freigeschaltet werden. Schalten sie mittels „Enable“ die Funktionalität frei und konfigurieren Sie eine Datenbankverbindung zum Speichern der Suchen mittels der Felder „JDBC URL“, „User“, „Password“ und „Database Table Prefix“. Das „Database Table Prefix“ kann dazu verwendet werden, um verschiedene Clientservices in die gleiche Datenbank abspeichern zu können.
Einstellungen:
Einstellung | Beschreibung |
Enable | Aktivieren der serverseitigen Speicherung. |
JDBC URL | URL zur Datenbank. |
Max Number Of Database Connections | Maximale Anzahl der Datenbankverbindungen. Standardwert: 10, Minimalwert: 2. |
User | Der Benutzer der Datenbank. |
Passwort | Das Passwort für den Benutzer der Datenbank. |
Database Table Prefix | Angabe eines Table-Prefixes. |
- Die „User“ und „Password“ Parameter können auch als Username/Password Credential konfigurieren werden. Dazu muss ein Endpoint Eintrag für die JDBC URL angelegt werden.
Optionale Authentisierung
Die „Optionale Authentisierung“ Einstellung erlaubt eine anonyme Suche in den öffentlich verfügbaren Dokumenten. Die Benutzer können sich jederzeit im Mindbreeze Client Service anmelden, um die Inhalte mit eingeschränktem Zugriff durchsuchen zu können oder sich abmelden um wieder auf die anonyme Suche zurückzuschalten.
Um die Einstellung zu aktivieren müssen Sie in der Registrierkarte „Client Services“ die Option „Requires Authentication“ auf „Optional“ einstellen.

Für eine optionale Authentisierung ist es erforderlich, dass die Option „Authentication Generates Trusted Peer Credentials“ aktiv ist und ein “Trusted Peer Credential Certificate” selektiert ist.
Wenn kein “Trusted Peer Credential Certificate” verfügbar ist, ist kein anonymer Zugriff auf das Mindbreeze Client Service erlaubt.
Wenn die optionale Authentisierung konfiguriert ist kann der User zwischen authentisiertem - und anonymen Modus umschalten. Um sich zu authentisieren betätigt der User den „Anmeldung“ Button, um eine anonyme Suche abzusetzen loggt sich der User mittels „Abmelden“ einfach wieder aus.


Benutzername ein-/ausblenden
Ist ein Benutzer angemeldet und ein Benutzername ist verfügbar, kann dieser mit dem Setting „Display Username“ ein- und ausgeblendet werden.
Wenn dieses Setting aktiviert ist, wird der volle Benutzername ausgegeben. Ist das Setting nicht aktiviert, erscheint je nach Anmeldestatus „Login“ oder „Logout“.

CORS Header
Wenn Sie die föderierte Suche verwenden, oder eine Insight App verwenden, welche auf einem anderen Server betrieben wird, dann sind diese Einstellungen möglicherweise für Sie relevant. In solchen Szenarien verbieten Webbrowser meistens die Kommunikation mit anderen Servern, ausgenommen sind nicht authentisierte, öffentliche Server, da hier keine kritischen Daten übertragen werden.
Die Option “Allowed Origins” steuert, welche „Origins“ erlaubt sind. Origins sind absolute URLs, von denen aus Requests erlaubt sind.
Falls Sie einen ClientService mit Authentisierung von anderen Origins mit anderen privaten Domänen aus verwenden wollen, müssen Sie die URLs dieser Origins explizit in der Option „Allowed Origins” auflisten. Z.B. http://www.example.com,https://www.myorganization.com
Alternativ können Sie auch mit der Option „Allowed Origins Pattern“ mit regulären Ausdrücken steuern, welche Origins erlaubt sind. Sie können hier mehrere Zeilen angeben. Z.B. der Wert
https://.*\.myorganization\.com
https://.*\.mycorporation\.com
erlaubt den Zugriff von z.B.
https://search.myorganization.com
https://myapp.myorganization.com
https://find.mycorporation.com
aber jedoch nicht von
https://search.example.com
Hinweis: sobald Sie die Option „Allowed Origins Pattern“ verwenden, ist die Option „Allowed Origins“ wirkungslos.
Standardwerte
Bei nicht authentisierten ClientServices („Requires Authentication“: „No“) wird für „Allowed Origins Pattern” standardmäßig der Wert “.*” angenommen, wenn „Allowed Origins (Pattern)“ nicht explizit konfiguriert ist.
Bei (optional) authentisierten ClientServices („Requires Authentication“: „Optional“ oder „Yes“) sind standardmäßig alle Hosts mit beliebigem Port erlaubt, die innerhalb Ihrer obersten privaten Domäne liegen, wenn „Allowed Origins (Pattern)“ nicht explizit konfiguriert ist. Mit „oberster privaten Domäne“ ist die Domäne gemeint, die eine Ebene unterhalb des öffentlichen Suffixes (gemäß der Definition in der Public Suffix List (PSL) der Mozilla Foundation) liegt. Beispielsweise wäre solch eine Domäne „mindbreeze.com“, aus der das Pattern „(.*\.)?\Qmindbreeze.com\E(:[0-9]+)?“ generiert wird. Der Domänenname wird dabei aus der „External URL“ extrahiert. Wenn diese nicht konfiguriert ist, wird er aus dem konfigurierten „Hostname“ aus der Nodes-Konfiguration extrahiert. Ist dies auch nicht möglich, wird der Domänenname aus dem System-FQDN extrahiert.
CORS bei SAML
Wenn Ihr SAML IDP nicht innerhalb der Domäne Ihrer Mindbreeze InSpire Appliance liegt, müssen unter bestimmten Bedingungen Konfigurationen vorgenommen werden. Meistens ist das für SAML IDPs in der Cloud interessant. Es muss sichergestellt werden, dass Mindbreeze InSpire Ihrem IDP vertraut. Aktivieren Sie dazu zunächst die Advanced Settings.
Einstellung | Beschreibung |
Trusted Cloud SAML Login Domains | Standardmäßig wird Microsoft Entra ID (vormals „Azure Active Directory“ genannt) und Okta vertraut. Wenn Sie einen anderen SAML IDP verwenden, kontaktieren Sie uns bitte. Wir sind sehr daran interessiert, welche IDPs unsere Kunden verwenden, um die Unterstützung dieser IDPs zu verbessern. |
Trust SAML Hostnames from Authenticators | Standardmäßig werden den IDPs aus den „Available SAML Authenticators“ Einstellungen vom „Authentication“ Tab vertraut. Dies ist jedoch nicht immer ausreichend, da die Login-URL unterschiedlich sein kann (z.B. wegen Redirects). Wenn dies der Fall ist, kann die Domäne der Login-URL in „Trusted Cloud SAML Login Domains“ eingetragen werden. |
Achtung: Bei der Umleitung durch den SAML IDP zurück zum Log-In-Bildschirm im Client Service kann ein Fehler 403 erscheinen. Der Grund dafür ist, dass der „Origin“ HTTP-Header den Wert „null“ besitzt. Um dies zu verhindern, setzen Sie bei der Einstellung „Allowed Origins Pattern“ den Wert „null“.
Preview Settings
Bei der Vorschau von PDF-Dateien wird automatisch zum relevantesten Trefferergebnis gescrawlt. Default: false.
Healthcheck
Im Abschnitt „Healthcheck Settings“ wird der Healthcheck des Client Services konfiguriert.
Die Adresse <Adresse des Client Services>/ping liefert, ob das Client Service betriebstüchtig ist. Damit kann das Service überwacht werden, um z.B. den Betrieb zu informieren oder es an einem Load Balancer zu aktivieren/deaktivieren.
Standardmäßig wird mit dem „Workload Check“ die Auslastung des Web-Servers und die Anzahl der parallelen Anfragen geprüft (siehe auch API V2 Concurrent Request Limits). Die Einstellung „Disabled“ deaktiviert diese Prüfung.
Zusätzlich können in „JSON Healthcheck Files Directory“ eigene Prüfungen hinzugefügt werden. Damit können Suchanfragen ausgeführt und deren Resultate geprüft und mit Javascript verarbeitet werden.
Antworten
Workload Check | JSON Healthcheck Files Directory | HTTP Status Code | HTTP Body |
OK | Nicht konfiguriert | 200 | OK |
OK | Konfiguriert | Laut Konfiguration | Laut Konfiguration |
NOK | - | 500 | NOK |
Voting
Um die Möglichkeit anzubieten, Feedback zu einem Treffer zu geben (positive oder negative Bewertung), kann im Client-Service die Option „Enable Voting“ gesetzt werden.

Ist die Option aktiv, werden die Treffer im Client mit zwei weiteren Buttons ausgestattet.

Das jeweilige Feedback wird in app.telemetry angezeigt.
Cookie Einstellungen
Der Client Service setzt standardmäßig automatisch ein Session Cookie (JSESSIONID). Falls gewünscht, kann dies mittels aktivieren der Einstellung „Disable Session Cookie“ unterbunden werden. (Wenn z.B. der Client Service öffentlich betrieben wird, und aus rechtlichen Gründen Cookies nicht zulässig sind) Hinweise: Diese Einstellung kann die Performance verschlechtern. Diese Einstellung darf nicht in Zusammenhang mit der Autorisierungsform SAML verwendet werden.
Die Einstellung „Same Site Cookie Behavior“ bestimmt, ob Cookies domänenübergreifend verwendet werden. Falls Sie die Suche föderiert verwenden und die Server auf unterschiedlichen Domänen liegen, (z.B. search.myorganization.de föderiert auf search.mycorporation.com) und Sie zur Anmeldung im Browser Cookies verwenden (für z.B. die Autorisierungsform SAML), dann muss „Same Site Cookie Behavior“ auf den Wert „Auto“ gestellt sein (Standardwert). Damit ist sichergestellt, dass die zur Autorisierung notwendigen Cookies übertragen werden können. Hinweis: der Wert „Auto“ führt dazu, dass wenn „Use SSL“ aktiv ist, effektiv Cookies mit Same Site Cookie Behavior „None“ gesetzt werden. Falls „Use SSL“ nicht aktiv ist (z.B. bei Verwendung eines Load Balancers), wird kein Same Site Cookie Behavior gesetzt.
Falls Sie keine föderierte Suche mit Cookie-basierter Autorisierung verwenden, können Sie zur Erhöhung der Sicherheit die Einstellung „Same Site Cookie Behavior“ auf den Wert „Strict“ setzen. Damit können dann keine Cookies weitergegeben werden. Die anderen möglichen Werte dieser Einstellung sind für internen Gebrauch vorgesehen und sollten nicht verwendet werden.

Content Security Policy Einstellungen
Im Client Service besteht die Möglichkeit, dass ein Content-Security-Policy Header (CSP Header) konfiguriert werden kann.
Dieser wird für jeden Request einer Insight App mitgeschickt, es sei denn es handelt sich um eine URL die das Muster: „https://<<your-domain.com>>/api/...“ beinhaltet.
Basis Konfiguration
Die minimale Konfiguration besteht darin, die Einstellung: „Enable CSP“ auszuwählen sowie eine gültige „External URL“ einzutragen.
Mittels dieser zwei Optionen wird folgender CSP Header generiert:
Content-Security-Policy: frame-ancestor 'self' <<externalurl>>; object-src 'none';
Durch diesen Header können potentielle „Clickjacking“-Angriffe verhindert werden und verwendete Sicherheits-Scanner werden diese potentielle Schwachstelle nicht mehr auflisten.
Erweiterte Konfiguration
Bei der erweiterten Konfiguration können benutzerdefinierte Richtlinienanweisungen definiert werden die die Basis Konfiguration überschreiben.
Dafür muss ebenfalls die Checkbox „Enable CSP“ ausgewählt sein sowie ein oder mehrere „Custom Policy Directive“ angelegt werden.
Dies ermöglicht eine Erweiterung der Basiskonfiguration wobei bei der erweiterten Konfiguration keine automatischen „Directives“ angelegt werden (frame-ancestor & object-src).
Es ist möglich einen Teil einer neuen Richtlinie ohne Wert anzulegen wie es zum Beispiel bei folgendem Header der Fall ist:
Content-Security-Policy: 'unsafe-inline'; frame-ancestors 'self'; ...
Einstellung | Beschreibung |
Enable CSP | Aktiviert die Erstellung eines einfachen CSP Header. (Die externe URL muss gesetzt sein) |
Custom Directive Name | Der Name der benutzerdefinierten Richtlinie die erstellt werden soll (überschreibt Basiskonfiguation) |
Custom Directive Value | Die Werte der benutzerdefinierten Richtlinie die erstellt werden soll. (überschreibt Basiskonfiguation) |
HTTP Header Security Einstellungen
Unter „HTTP Header Security Settings” kann das Verhalten gewisser HTTP Security Header konfiguriert werden.
Einstellung | Beschreibung |
HSTS | Steuert den Header Strict-Transport-Security. Aktiviert den Header automatisch, wenn „SSL (HTTPS) verwenden“ aktiviert ist. Standardeinstellung: Auto |
HSTS Include Sub-Domains | Setzt zusätzlich zu Strict-Transport-Security auch includeSubDomains. Standardeinstellung: Deaktiviert |
Anti-Clickjacking | Steuert den Header X-Frame-Options.
Standardeinstellung: Deaktiviert |
Block Content Type Sniffing | Steuert den Header X-Content-Type-Options. Standardeinstellung: Aktiviert |
Betreiben von Insight Apps über das Client Service und Ändern der Standard Insight App
Um eigene Insight Apps direkt über das Client Service zu betreiben und dort auch als Standard zu hinterlegen, kann der Menüpunkt „Web Application Contexts Settings“ verwendet werden. Details zur Konfiguration finden sich in der Dokumentation „Entwicklung von Insight Apps“.
Verwendung von Port 80 als Client Service Port auf G7 Appliances
Um ein Client Service auf Port 80 zu betreiben, sind auf G7 Appliances folgende Schritte notwendig.
Deaktivieren sie die Option: „Use SSL (HTTPS)“ und setzen sie den „Port (HTTP)“ auf 23350. Port 80 wird automatisch auf diesen Port weitergeleitet.
![]()
![]()
Aus Sicherheitsgründen ist der Zugriff auf Port 80 eingeschränkt. Um den Zugriff für bestimmte IP-Adressen oder Subnetze zu erlauben, bearbeiten Sie die Datei: „/var/data/iptables.sh“.
Tragen sie in der Zeile „iptables -t nat -A PREROUTING -m addrtype --dst-type LOCAL -s 127.0.0.1 -p tcp -m tcp --dport 80 -j DOCKER“ anstatt 127.0.0.1 die erlaubten Adressen ein oder entfernen sie „-s 127.0.0.1“ um den Zugriff von überall aus freizugeben. Starten Sie anschließend die Appliance neu um die Firewall Regeln anzuwenden.
Bei einem Update wird die Datei „/var/data/iptables.sh“ überschrieben und automatisch ein Backup im Format „/var/data/iptables.sh.bak.YYYY-MM-DD“ erstellt. Stellen Sie bei Bedarf ihre angepassten Regeln nach dem Update wieder her.
Registerkarte „License“
Die Registerkarte „License“ dient zur Verwaltung der Mindbreeze InSpire-Lizenz.

Um eine Lizenz neu zu installieren oder zu aktualisieren, führen Sie folgende Schritte durch:
- Im Feld neben „License“: Wählen Sie die gewünschte Lizenzdatei aus. Sie können dazu die Schaltfläche „Choose File“ verwenden .
- Klicken Sie anschließend auf „Upload“ und speichern Sie mit einem Klick auf „Save“.
Im Bereich „Current License Information“ wird nach dem Laden einer Lizenz angezeigt, wer berechtigt ist, die aktuelle Installation von Mindbreeze InSpire zu benutzen und bis wann die Lizenz gültig ist.
Im Bereich „Licensed Products“ werden Ihre lizenzierten Produkte und deren Einschränkungen angezeigt.
Zu den Einschränkungen zählen:
- Maximum User Count: Zeigt die maximale Anzahl der Benutzer an, für die die aktuelle Lizenz ausgestellt ist.
- Maximum Document Count: Zeigt die maximale Anzahl der indizierbaren Dokumente an, für die die aktuelle Lizenz ausgestellt ist.
Registerkarte „Certificates“
Generelle Informationen über Trusted Peer Authentifikation
Mindbreeze InSpire bietet die Möglichkeit, dass Applikationen von Drittherstellern beim Query Service Abfragen durchführen, ohne Benutzername und Passwort zu übergeben. Es handelt sich um so genannte „trusted peers“, die sich mit einem SSL-Zertifikat ausweisen. Um die Vertraulichkeit von den im Index erfassten Daten zu gewährleisten, wird vorausgesetzt, dass ein derartiges Zertifikat von einer in Mindbreeze InSpire registrierten Certificate Authority (CA) signiert ist.

Um die vertraute CA zu definieren, laden Sie in der Registerkarte „Certificates“ im Feld Trusted Certificate Authority die .CER-Datei, die das Zertifikat des CAs im PEM Format enthält. Wenn sie kein CA-Zertifikat laden, ist die Funktionalität von „Trusted Peers“ nicht verfügbar. Für jedes übermittelte Zertifikat legt die Option „Trusted Peer“ fest, ob das Zertifikat für diesen Zweck verwendet wird. Im Feld „Current Trusted CA Information“ werden die aktuell registrierten Zertifikate angezeigt.
Authentifikation mit Client-Zertifikaten
Alle verfügbaren CA-Zertifikate („Available CAs“) können für die Authentifizierung mit Client-Zertifikaten verwendet werden. Diese Authentifizierungsart kann beim Windows Client eingesetzt werden, um Benutzer anhand von Zertifikaten zu authentifizieren. Auch hierzu muss ein CA-Zertifikat vorliegen, mit dem alle Benutzerzertifikate signiert sind, damit eine vertrauenswürdige Verbindung eingegangen werden kann. Dazu muss beim Index unter „Advanced Settings“ ein Zertifikat für die Einstellung „Authentication Certificate“ ausgewählt werden.

Damit ein Web Client Service mit einem anderen SSL-Zertifikat betrieben werden kann, beispielsweise um Loadbalancing zu ermöglichen, muss in der „Certificates“ Registerkarte ein Zertifikat im PKCS #12-Format übertragen werden.
Voraussetzungen für Zertifikate im PKCS #12 Format
SSL/TLS-Zertifikate sind in verschiedenen Formaten erhältlich. Für Mindbreeze InSpire ist ein bestimmtes Format erforderlich:
- Unverschlüsseltes PKCS #12 Archivformat (enthält in den meisten Fällen die Dateierweiterung .p12 oder .pfx) mit folgendem Inhalt:
- Unencrypted private key
- Subject public key
- Root public key
- Certificate chain
- Kein Importpasswort für PKCS #12 festgelegt
Achtung: Das Hochladen eines Zertifikats in einem anderen Format führt zum Scheitern der Installation.
Hochladen und Aktivierung eines SSL-Zertifikates
In den folgenden Kapiteln wird der Upload eines SSL-Zertifikats sowie die Aktivierung des SSL-Zertifikats für den Client Service und das Mindbreeze Management Center erklärt. Bitte beachten Sie, dass die Aktivierung des SSL-Zertifikats für den Client Service und das Mindbreeze Management Center separat erfolgen muss. Der Grund dafür ist, dass die Verwendung des SSL-Zertifikats unterschiedlich ist. Für das Mindbreeze InSpire Management Center wird das SSL-Zertifikat für die Administrationsoberfläche verwendet. Für die Mindbreeze Client Services wird ein pro Dienst konfiguriertes SSL-Serverzertifikat verwendet, das mit der externen Server-URL korrespondiert, die für den Endbenutzer zugänglich ist.
Tutorial Video „Installieren eines SSL-Zertifikats“
Informationen zum Hochladen und Aktivieren eines SSL-Zertifikates für den Client Service und für das Mindbreeze Management Center sind im folgenden Video verfügbar: https://www.youtube.com/watch?v=oThC_VNcc5s
Die nachfolgenden Kapitel bieten die Informationen, die im Video erwähnt werden und zusätzliche Informationen an.
Hochladen
Um ein SSL-Zertifikat hochzuladen, gehen Sie auf „Configuration“ und dann auf die Registerkarte „Certificates“. Hier können Sie den Typ des Zertifikats zwischen „Auto“, „CA“ und „SSL“ wählen. Schalten Sie den Typ auf „SSL“ um und wählen Sie dann das SSL-Zertifikat mit „Choose File“ aus. Klicken Sie abschließend auf „Upload“, um das ausgewählte SSL-Zertifikat hochzuladen.

Alle hochgeladenen Zertifikate sind unten im Abschnitt „Available SSL Certificates“ aufgeführt. Diese Zertifikate können für jeden Web Client Service ausgewählt werden.
SSL-Zertifikate für den Client Service aktivieren
Gehen Sie zu „Configuration“ und dann zu „Client Services“. Aktivieren Sie „Advanced Settings“ und öffnen Sie Ihren Web Client Service. Gehen Sie im ersten Abschnitt „Setup“ auf die Einstellung „Use SSL (HTTPS)“. Falls diese Einstellung nicht aktiv ist, aktivieren Sie sie bitte. Gehen Sie dann zu der Einstellung „SSL Certificate“. Die Standardeinstellung „Use SSL Certificate supplied with your license“ verwendet das mit Ihrer Lizenz gelieferte Zertifikat. Öffnen Sie das Dropdown-Menü und wählen Sie das gewünschte SSL-Zertifikat aus. Vergewissern Sie sich abschließend, dass „Apply changes and restart on save“ in der oberen rechten Ecke aktiviert ist, und klicken Sie auf „Save“.

Achtung: Der Client Service akzeptiert nur SSL-Zertifikate im PKCS #12-Format mit leerem Import-Passwort. Die SSL-Zertifikatsdatei muss einen privaten Schlüssel und das entsprechende Serverzertifikat enthalten.
SSL-Zertifikate für das Mindbreeze Management Center aktivieren
Gehen Sie zu „Setup“ und dann zu „SSL Certificate“. Klicken Sie auf „Choose File“, um das gewünschte SSL-Zertifikat auszuwählen. Laden Sie dann das Zertifikat mit „Upload File“ hoch. Nachdem der Upload abgeschlossen ist, aktualisieren Sie das Mindbreeze Management Center, um das SSL-Zertifikat zu aktivieren.
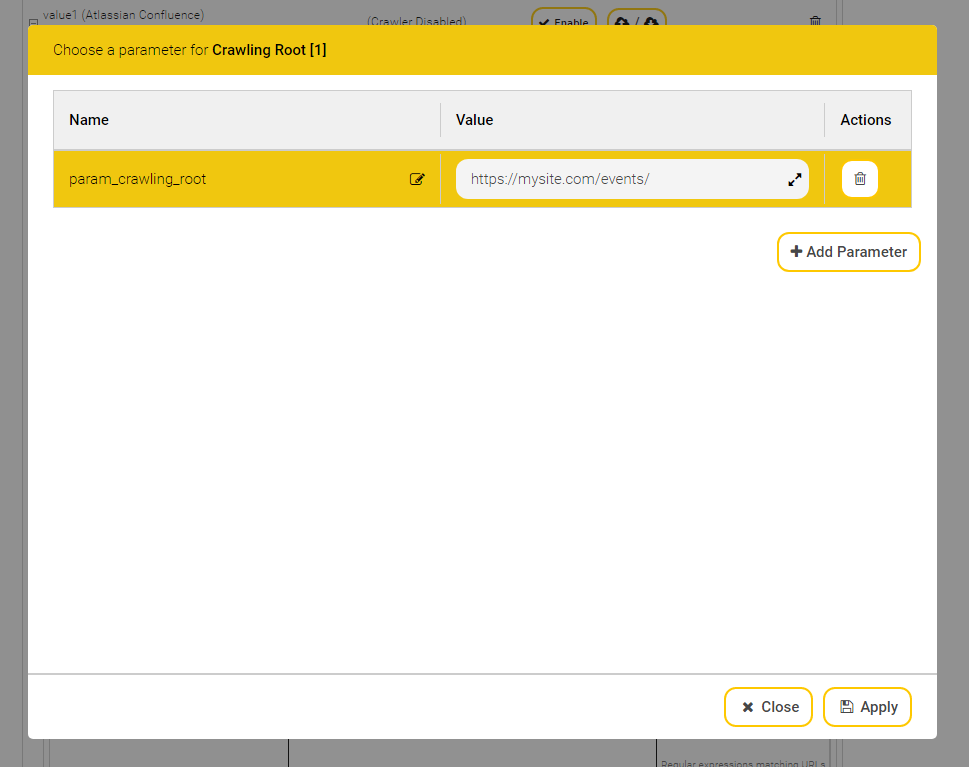
Achtung: Das Management Center akzeptiert nur SSL-Zertifikate im Format PKCS #12. Wenn das Zertifikat ein Import-Passwort hat, kann dieses im Feld „Password“ angegeben werden. Die SSL-Zertifikatsdatei muss einen privaten Schlüssel und das entsprechende Serverzertifikat enthalten.
Hochladen und Aktivieren von SSL-Zertifikaten für mehrere Mindbreeze InSpire Applikationen
Bei mehreren Mindbreeze InSpire Applikationen, die miteinander verbunden sind, muss das SSL-Zertifikat anders gehandhabt werden. Ein solcher Fall kann beispielsweise in einer Producer-Consumer-Infrastruktur vorliegen.
Damit das SSL-Zertifikat ordnungsgemäß funktioniert, muss einer der beiden Punkte erfüllt sein:
- Das SSL-Zertifikat ist für alle beteiligten Domains gültig.
- Das SSL-Zertifikat ist ein Wildcard-Zertifikat.
Wenn einer der beiden Punkte erfüllt ist, muss das SSL-Zertifikat auf der Master-Appliaktion installiert werden. Danach synchronisiert der Task-Manager das Zertifikat mit den verbundenen Applikationen, wenn die Aufgabe „Synchronize config and data“ ausgeführt wird. Die konfigurierten Aufgaben des Task-Masters finden Sie im Management Center im Hauptmenüpunkt „Setup“ unter „Aufgaben“.
Überprüfung der erfolgreichen Aktivierung des SSL-Zertifikats
Nach der Aktivierung eines SSL-Zertifikats für den Client Service und/oder das Management Center kann es vorkommen, dass im Browser noch das alte Zertifikat angezeigt wird. Dies liegt daran, dass Browser das Zertifikat oft in den Cache aufnehmen und das neue Zertifikat nicht sofort angezeigt wird, obwohl die Hintergrunddienste neu gestartet wurden.
Um dieses Problem zu beheben, versuchen Sie es bitte mit den URLs des Client Services und des Management Centers in einem anderen Browser oder starten Sie den aktuellen Browser neu. Nach einigen Minuten sollte das neue Zertifikat sichtbar sein.
Registerkarte „Network“
Auf der Registerkarte „Network“ werden allgemeine Netzwerkeinstellungen für alle Mindbreeze Enterprise Search Services ermöglicht.

Proxy Settings
Um Zugang zu den Web Ressourcen durch einen Proxy Server zu erhalten sind die Host Adresse und Port Information vom Proxy Server und bei Bedarf einen gültigen Usernamen und Passwort einzugeben.
LDAP Settings
Zur Konfiguration der LDAP Abfragen, die für Autorisierung notwendig sind, sind folgende Information wichtig:
Einstellung | Beschreibung |
Vollqualifizierter Domänen Name | |
LDAP Server | Diese Server werden für LDAP Abfragen bevorzugt. Falls die konfigurierte LDAP Server nicht erreichbar sind oder keine Ergebnisse liefern werden zusätzlich die LDAP Server in DNS Server Records (_ldap._tcp.gc._msdcs and _ldap._tcp) von Active Directory aufgelöst und abgefragt. |
Disable LDAP Server Discovery | Nur die konfigurierten Server werden für LDAP Abfragen benutzt. |
Excluded Domain | Domänen die nicht abgefragt werden. |
Connection Encryption | Für die Verbindung zum LDAP-Server kann das SSL-Protokoll (LDAPS) an Port 636 oder das TLS-Protokoll (StartTLS) an Port 389 ausgewählt werden. Bei Auswahl von Unencrypted wird keine Verschlüsselung durchgeführt. |
Enable Connection Pool Manager | Durch die Wiederverwendung von Verbindungen wird die Performanz erhöht. |
Maximum Connections | Maximale Anzahl von Verbindungen zum LDAP Server die für die LDAP Abfragen beim Starten eines Services aufgebaut werden. Diese Verbindungen können gleichzeitig verwendet werden. Eine Abfrage wird nur dann blockiert wenn alle Verbindungen zur dieser Zeit besetzt sind. |
Maximum Shared Connections | Dadurch wird eine physische Verbindung gemeinsam von mehreren Threads verwendet. |
Die LDAP Abfragen werden im „Network Requests“ Log Pool von AppTelemetry geloggt. Scheme „ldap“ und Port „389“ können als filter verwendet werden. Alle Abfragen die im Cache vorhanden sind haben den Status „Persisted Cache“.
Registerkarte „About“
Auf der Registerkarte „About“ werden allgemeine Informationen, wie die Versionsnummer und das Copyright der aktuell installierten Version von Mindbreeze InSpire angezeigt.
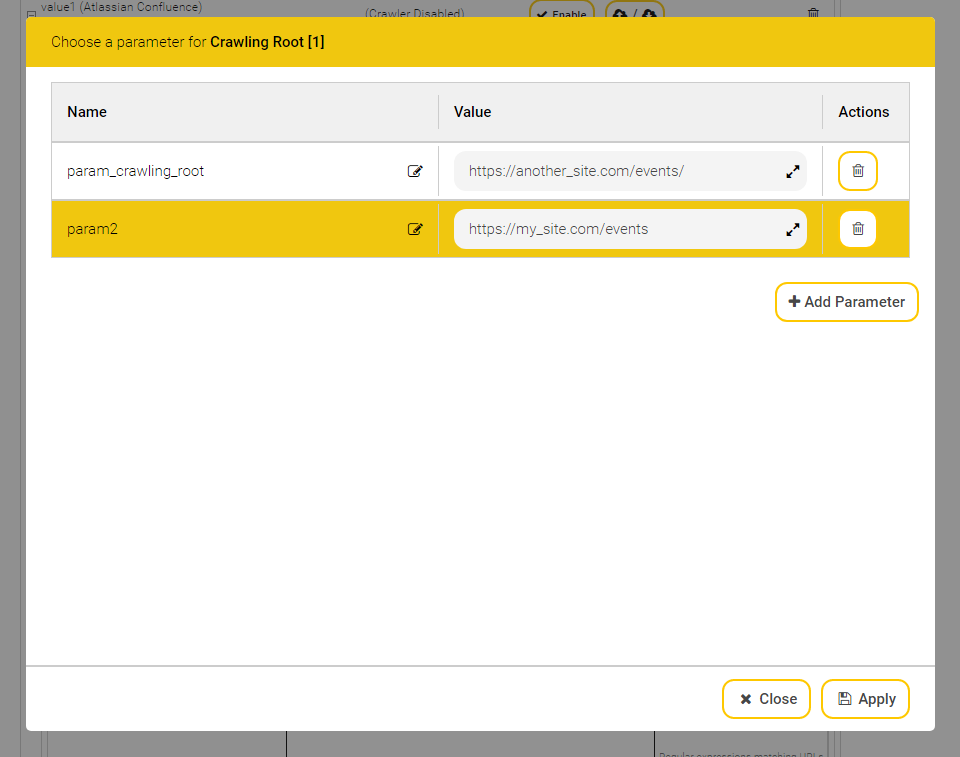
Konfiguration aus Sicherungskopie wiederherstellen
Wenn eine Konfigurationsänderung mit „Save“ gespeichert wird, werden Sicherungskopien von den Konfigurationsdateien (mesmaster.xml und pluginsite.xml) gemacht. Die Kopien liegen im selben Verzeichnis wie die Konfigurationsdateien:
%userprofile% ist der Profilverzeichnis des Servicebenutzers des Mindbreeze Manager Services. Wenn das Mindbreeze Manager Service mit System Konto gestartet wird, befindet sich das Profilverzeichnis unter:
C:\Windows\System32\config\systemprofile\ AppData\Roaming\Mindbreeze\Enterprise Search\Server\
Die Sicherungskopien folgen dem Namensschema: mesconfig.xml.backup_<Zeitstempel> und pluginsite.xml.backup_<Zeitstempel>.
Um den letzten Mindbreeze Konfigurationsstand wiederherzustellen sind folgende Schritte nötig:
- Mindbreeze Manager Service und Mindbreeze Node Service stoppen
- mesconfig.xml und pluginsite.xml mit den gewünschten mesconfig.xml.backup_<Zeitstempel> und pluginsite.xml.backup_<Zeitstempel> Dateien ersetzen
- Mindbreeze Manager Service und Mindbreeze Node Service starten
Import/Export von Einstellungen
Einstellungen für verschiedenen Services können mithilfe dieser Komponente importiert und exportiert werden.

Format
Folgendes Format wird für den Export und Import von Einstellungen verwendet:
<settings>
<attributes>
<attribute name="name" value="value"></attribute>
</attributes>
<properties>
<property name="name" value="value"></property>
</properties>
</settings>
Export
Das Export Fenster (links) liest automatisch alle verfügbaren Optionen aus dem jeweiligen Service aus, welche im Anschluss 1:1 für den Import verwendet werden können.
Import
Im Import Fenster (Mitte) wird die angepasste Konfiguration eingespielt. Achtung: Diese Konfigurationen müssen vom selben Typ sein (Index, Filter, Client Service, Crawler, Launched Service).
Changes
Das Fenster Changes zeigt die Änderungen im Überblick als Diff.
Remove existing settings
Ist diese Option aktiviert (Default), wird die Konfiguration für das jeweilige Service überschrieben. Folgende Optionen werden in keinem Fall überschrieben:
- Service Name
- Index Path
- Index Port (HTTP)
- Data Port (TCP/IP)
- Query Port (HTTPS)
- Filter Service
- Caching Principal Resolution Service
- Authorization Service
Wenn Sie die bestehende Konfiguration nur erweitern und updaten möchten, deaktivieren Sie diese Option.
XML als Datei herunterladen
Durch „XML als Datei herunterladen“ werden Einstellungen (inklusive Eigenschaften und Attribute) im XML-Format heruntergeladen.
Eigenschaften herunterladen als YAML
Durch „Eigenschaften herunterladen als YAML“ werden Einstellungen (nur Eigenschaften) im YAML Format heruntergeladen.
Eigenschaften herunterladen als JSON
Durch „Eigenschaften herunterladen als JSON“ werden Einstellungen (nur Eigenschaften) im JSON-Format heruntergeladen.
Parametrisierung
Einleitung
Durch die Einführung von Konfigurationsparametern und sogenannten Development-Snapshots können Anpassungen an
- der Mindbreeze Service Konfiguration (Hinzufügen/Entfernen und Anpassen von Connectoren, Indizes, Filter, Client Services, …)
- der Semantik Pipeline
- der Query Transformation Pipeline
- InSpire Insight Apps
- Beliebiger Resource-Files wie Boostings, Relevanzparameter
Als Snapshot exportiert werden und dann automatisch in die Produktion übernommen werden. Dabei können beliebige Einstellungen (wie zB die zu indizierenden Quellsysteme) als Parameter auf der jeweiligen Umgebung lokal überschrieben werden. Damit z.B.: kann sichergestellt werden, dass produktiv die Produktionsquellen indiziert werden und im Entwicklungssystem die Entwicklerquellen. Credentials, Zertifikate werden nicht abgelegt und bleiben erhalten.
Parametrisierung Aktivieren/Deaktivieren
Diese Funktion ist nur für G7 Appliances verfügbar.
In den erweiterten Einstellungen (advanced settings) unter ‘Indices’ kann die Parametrisierung aktiviert oder deaktiviert werden.

Hinweis: Um die Parametrisierung zu deaktivieren, klicken Sie auf den Button 'Disable Parameterized Configuration'. Wenn es aktive parametrisierte Konfigurationsoptionen gibt, ist der Button deaktiviert. Um die Parametrisierung in diesem Fall zu deaktivieren, müssen Sie zuerst alle Parameter entfernen.

Parameter hinzufügen
Sobald die Parametrisierung aktiviert ist, kann man über den Button ‘Add/Update Parameter’ (…) gewünschte Parameter hinzufügen.

Sie können einen der vorhandenen Parameter auswählen oder einen neuen Parameter aus der folgenden Tabelle hinzufügen.

Hinweis: Der Name des Parameters darf keine Leer- oder Sonderzeichen enthalten.
Um Änderungen anzuwenden, müssen Sie einen Parameter aus der Tabellenliste auswählen.

Hinweis: Die Auswahl eines Parameters erfolgt durch Klicken auf die Tabellenzeile. Falls ausgewählt, wird sie gelb markiert.
Nach dem Klicken auf ‘Apply’ ist der Wert der Konfigurationsoption 'z.B. Crawling Root [1]' der Wert des aus der vorherigen Tabelle ausgewählten Parameters. Zusätzlich ist der Wert der Konfigurationsoption jetzt schreibgeschützt.

Parameter updaten
Um die Parameter zu bearbeiten (z.B. den Parameterwert zu ändern oder einen anderen Parameter zu wählen), klicken Sie auf den Button ‘Add/Update Parameter'.
Das Dialogfeld wird geöffnet, und der referenzierte Parameter für diese Konfigurationsoption wird automatisch aus der verfügbaren Liste ausgewählt (hervorgehoben).

Ändern Sie den Wert des Parameters (z.B. 'https://another_site.com/events') und klicken Sie auf ’Apply’:
Der Wert der Konfigurationsoption ändert sich ebenfalls entsprechend.
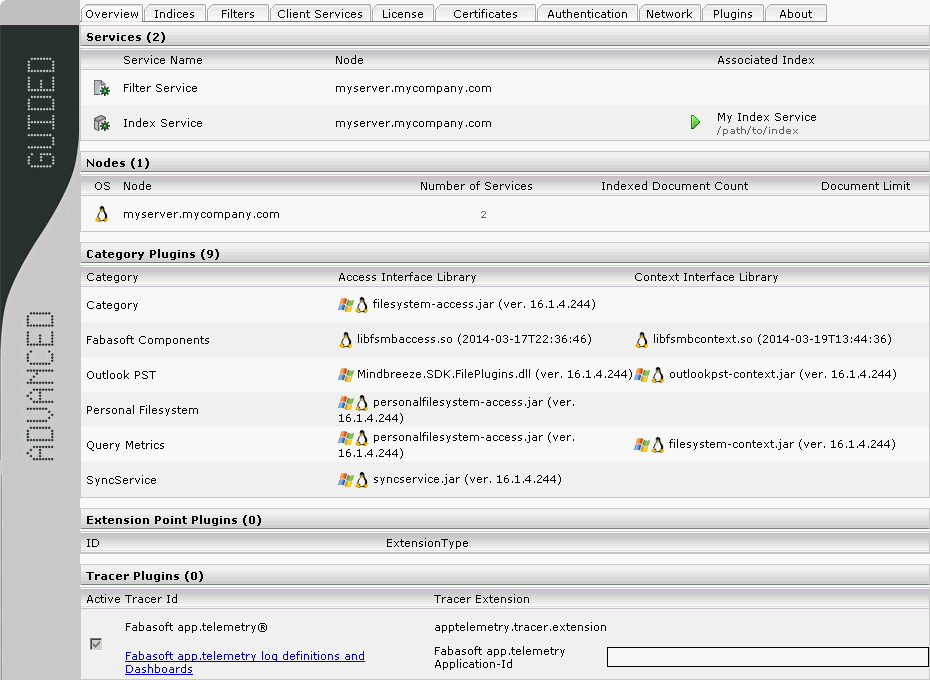
Hinweis: Eine weitere mögliche Änderung ist die Wahl eines anderen Parameters (z.B. 'param2'). In diesem Fall bezieht sich die Konfiguration 'Crawling Root [1]' nun auf den neu gewählten Parameter.

Und der Wert von 'Crawling Root [1]' wird sich dementsprechend auf den Wert von 'param2' beziehen.
Remove a Parameter
Um einen Parameter aus der Konfigurationsoption z.B. 'Crawling Root [1]' zu entfernen,klicken Sie auf den Button ‘Remove Parameter’.
Hinweis: Der Wert der Konfigurationsoption 'Crawling Root [1]' ist jetzt read/write und nimmt den Wert des zuletzt referenzierten Parameters an.
Wenn Sie nun auf den Button ‘Add/Update Parameter’ klicken, wird der Dialog zur Parametrisierung dieser Konfigurationsoption von Anfang an wieder geöffnet.
Abfragesprache von Mindbreeze InSpire
Die Mindbreeze InSpire Abfragesprache wird zur Formulierung von Abfragen in den Clients verwendet.
Abfragen von einzelnen Wortanfängen (Single Terms)
Allgemein werden bei der Suche nach Wortanfängen und Wörtern keine Platzhalterzeichen (wie %, * usw.) verwendet.
Bau |
Eine Eingabe von „bau“ startet eine Suche nach Objekten, die Wörter mit den Zeichen „bau“ am Wortanfang und das Wort (den Term) bau enthalten. Bei einer Suche wird Groß- und Kleinschreibung grundsätzlich nicht berücksichtigt, d.h. eine Suche nach bau ergibt dieselben Treffer wie eine Suche nach Bau oder BAU.
Analog zum Abfragen von einzelnen Wörtern bzw. Wortanfängen können mehrere Wörter bzw. Wortanfänge in einem Dokument gesucht werden. Die einzelnen Wortanfänge einer Suchabfrage werden mit einem logischen UND verknüpft. Es werden nur jene Dokumente ausgegeben, die alle eingegebenen Wörter bzw. Wortanfänge enthalten.
Suche nach mehreren Wortanfängen im selben Dokument
Zusätzlich zur Abfrage einzelner Begriffe können Sie auch mehrere Begriffe in einem Dokument abfragen. Eine Suche nach mehreren Begriffen umfasst Dokumente, die die Begriffe selbst enthalten, sowie Dokumente, die Wörter enthalten, die mit diesen Begriffen beginnen. Um Teil des Suchergebnisses zu sein, müssen alle eingegebenen Begriffe in einem Dokument enthalten sein.
Variante 1 | auto test |
Variante 2 | Auto Test |
Variante 3 | AUTO TEST |
Alle drei Varianten in diesem Beispiel liefern dasselbe Resultat. Es werden jene Ergebnisse geliefert, in denen die Wörter "auto" und "test" als Wortanfang oder als eigenständige Wörter (Terme) vorkommen. Die Groß- und Kleinschreibung wird nicht berücksichtigt.
Phrasensuche / exakte Suche
Eine Phrasensuche sucht nach exakten Wörtern oder exakten Phrasen. Diese wird durch Angabe von beginnenden und schließenden Anführungszeichen (") unmittelbar vor und am Ende der gesuchten Phrase initiiert.
"Knowledge is a matter of seconds" |
Es wird nur nach exakt dieser Phrase gesucht. Die Phrasensuche ist daher nicht sinnvoll, wenn die genaue Schreibweise der Wörter bzw. der Phrase nicht bekannt ist.
Einschränkung nach Datenerweiterung
Mindbreeze InSpire bietet die Möglichkeit, die Suche auf bekannte Dateierweiterungen einzuschränken.
mind (extension:doc OR extension:xls OR extension:msg) |
Diese Abfrage sucht in allen Dateien mit den Dateierweiterungen ".doc" (Microsoft Word), ".xls" (Microsoft Excel) und ".msg" (Microsoft Outlook) nach Wörtern mit dem Wortanfang "mind" und nach dem Wort "mind", wobei die Groß- und Kleinschreibung nicht berücksichtigt wird.
Logische Verknüpfungen
AND
Wortanfänge, Wörter und Phrasen einer Suchabfrage werden implizit und-verknüpft. Das heißt, es werden nur jene Treffer zurückgeliefert, in denen alle gelisteten Wortanfänge, Wörter und Phrasen vorkommen. Das Schlüsselwort AND kann ebenfalls explizit in einer (zum Beispiel geschachtelten) Abfrage vorkommen.
"Mindbreeze" AND "Search" |
OR
Die Oder-Verknüpfung liefert jene Ergebnisse, in denen zumindest eine der Suchbedingungen erfüllt ist, also in denen einer der Wortanfänge, eines der Wörter oder eine der Phrasen vorkommet. Das heißt, es werden auch jene Treffer zurückgeliefert, in denen nur ein einziger gelisteter Wortanfang, ein Wort oder eine gelistete Phrase vorkommen. Das Schlüsselwort OR muss explizit in einer Abfrage formuliert werden und kann auch geschachtelt vorkommen.
Variante 1 | ("Mindbreeze" OR "Search") AND "Software" |
Variante 2 | ("Mindbreeze" OR "Search") "Software" |
Diese beiden Abfragen liefern jene Ergebnisse, in denen das Wort "Mindbreeze" und/oder das Wort "Search" gemeinsam mit dem Wort "Software" vorkommt. Sie liefern also Ergebnisse mit den Kombinationen "Mindbreeze" und "Software", "Search" und "Software", sowie "Mindbreeze", "Search" und "Software".
Andere Schlüsselwörter
NEAR
Eine Suche mit NEAR liefert ausschließlich Ergebnisse zurück, in denen ein Wort nahe einem anderen steht.
Mindbreeze NEAR Search |
NOT
Eine Suche mit NOT liefert Ergebnisse aus einer Grundmenge zurück, in denen ein Wort nicht vorkommt. NOT kann nicht alleine verwendet werden.
Mindbreeze NOT slow |
Metadatensuche
Die Metadatensuche wird vor allem verwendet, um eine Ergebnismenge weiter einzuschränken, man spricht in diesem Zusammenhang auch von "Refinement" (Verfeinerung). Es gibt von Mindbreeze InSpire fix vorgegebene Metadaten sowie herstellerabhängige Metadaten (die von Mindbreeze-Partnern selbst definiert werden).
Syntax einer Metadatensuche: <metadatum>:<wert>
title:Integration |
Die Suche nach einer Dateierweiterung kann durch das Metadatum "extension" definiert werden.
extension:doc mind |
In diesem Beispiel liefern beide Varianten dasselbe Ergebnis: Microsoft Word Dateien, die das Wort „mind“ oder Wörter enthalten, die mit „mind“ beginnen.
Folgende Metadaten sind für die standardmäßig unterstützten Datenquellen definiert:
Kurzname | Metadatum | Erklärung | Verfügbar für |
Name | title | Suche innerhalb des Namens | Alle |
Erweiterung | extension | Suche innerhalb der Erweiterung | Alle |
Ordner | directory | Suche innerhalb des Ordners | Dateisystem, Outlook, Exchange |
Betreff | subject | Suche innerhalb des Betreffs | Outlook, Exchange |
Von | from | Suche innerhalb der Sender | Outlook, Exchange |
An | to | Suche nach Empfängern | Outlook, Exchange |
(nicht angezeigt) | content | Suche innerhalb des Dokumentinhalts | Alle |
Der Exchange Connector definiert unter anderem die Metadaten from und to.
from:bauernf |
Diese Suche liefert jene Objekte, die in der Absendeadresse den Begriff "bauernf" enthält.
Intervallsuche
Eine Suche mit TO liefert grundsätzlich Begriffe zwischen der linken und der rechten Seite des TO Operators. Besonders interessant ist das bei der Verwendung der Intervallsuche in Verbindung mit numerischen Strings. Mindbreeze erkennt numerische Werte verschiedener Art, zB
Text | Kanonische Repräsentation (Deutsch) |
100 | 100,00 |
100.0 | 100,00 |
100,0 | 100,00 |
1.000,00 | 1000,00 |
1.000 | 1,00 |
1,000.00 | 1000,00 |
-100 | -100,00 |
Syntax einer Intervallsuche: <von> TO <bis>
Beispiel: | 105 TO 110 |
Erweiterte Metadaten-Intervallsuche
Syntax einer erweiterten Intervallsuche:
label:[<von> TO <bis>]
label:[<von>]
label:[TO <bis>]
Beispiel: | size:[1MB TO 1,4MB] mes:date:[2012-03-20 TO 2012-03-25] |
Kombination der Sprachelemente der Abfragesprache
Eine Kombination der oben genannten Sprachelemente der Mindbreeze InSpire -Abfragesprache ist möglich.
title:Integration from:bauernf extension:doc |
Dieses Beispiel liefert Microsoft Word-Dokumente, die von einer Adresse mit dem Begriff "bauernf" geschickt wurden. Der Titel der resultierenden Objekte enthält das Wort "Integration" (bzw. ein Wort das mit "Integration" beginnt) enthält.
Hilfreiche Suchresultate, auch wenn nicht alle Suchbegriffe übereinstimmen
Mithilfe der „Optional Terms“ kann das Finden von Dokumenten vereinfacht werden, indem Resultate geliefert werden, in denen nicht unbedingt alle Suchbegriffe vorkommen müssen. Damit das transparent für den Benutzer geschieht, wird ein Hinweis beim Treffer angezeigt. Dieses Feature ist standardmäßig aktiv, kann jedoch parametrisiert oder ganz deaktiviert werden (siehe Abschnitt Optional Terms).
Artificial Intelligence Human Interaction Article |
Standardmäßig werden Dokumente gefunden, bei denen mindestens zwei Drittel (67%) der Suchbegriffe vorkommen. Da die Suchanfrage in diesem Beispiel 5 Suchbegriffe enthält, kann damit 1 Begriff im Resultat fehlen. Der Screenshot unten zeigt ein Beispiel, bei dem für diese Suchanfrage ein Dokument gefunden wird, welches den Begriff „Article“ nicht enthält.

Betrieb und Wartung
Ändern des Index Service-Modus
Ein Mindbreeze InSpire Index Service unterstützt die folgenden Modi:
- Mode: running (
 )
)
Dies ist der Standardmodus von Mindbreeze InSpire Index Services. In diesem Modus wird das Index Service betrieben. - Mode: readonly (
 )
)
Dieser Modus wird benützt um die Indexdateien von Mindbreeze InSpire zu sichern (Backup) und die Konsistenz der Daten während dieses Zeitraumes zu gewährleisten.
Hinweis: Um den Indizierungsvorgang fortzusetzen bzw. hinzukommende Dokumente indizieren zu können (Deltaindizierung) muss vom „Mode: readonly“ wieder auf den „Mode:running“ gewechselt werden. - Mode: offline (
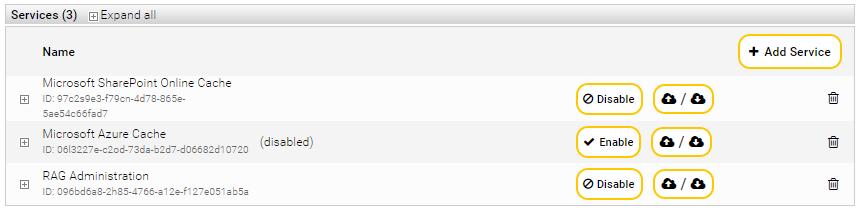 )
)
Dieser Modus kann vom Benutzer nicht explizit gesetzt werden. In diesem Modus befindet sich ein gestoppter Index Service.
Manuelles Ändern des Index Service-Modus
Neben dem automatisierten Setzen des Index Service-Modus, kann der Modus auch über die Mindbreeze InSpire -Konfiguration geändert werden. Klicken Sie dazu im Abschnitt „Services“ in der Zeile des entsprechenden Index Service auf „Enable“ oder „Disable“. Erneutes Klicken ändert den Modus wieder in den Ausgangszustand
Hinweis: Ein nicht laufendes Index Service wird ebenfalls angezeigt. Der Modus des Index Service kann in diesem Fall nicht geändert werden. Um den Modus zu ändern, muss das Index Service gestartet werden.
Ändern des Index Service-Modus mit Hilfe eines Skripts
- Um den Modus des Index Service auf „Mode: readonly“ () zu ändern, führen Sie folgenden Befehl aus:
mescontrol http://indexserver.yourcompany.com:23100 readonly - Um den Modus des Index Service auf „Mode: running“ () zu ändern, führen Sie folgenden Befehl aus
mescontrol http://indexserver.yourcompany.com:23100 readwrite
Sichern der Indexdaten
Mindbreeze InSpire erzeugt einen dateibasierten Index. Diese Indexdateien können in einem konsistenten Zustand vollständig gesichert werden.
Um die Indexdaten zu sichern, gehen Sie folgendermaßen vor:
- Ändern Sie den Modus des Index Service auf „Mode: readonly” ().
- Prüfen Sie Konsistenz des Index mit folgendem Kommando:
mescontrol http://indexserver.yourcompany.com:23100 checkconsistency' - Navigieren Sie zum Indexverzeichnis und sichern Sie die enthaltenen Dateien
- Ändern Sie den Modus des Index Service aufs “Mode: running” ().
Wiederherstellen der Indexdaten
Um den gesicherten Index wieder einzusetzen, führen Sie die folgenden Schritte aus:
- Stoppen Sie das Index Service.
- Löschen Sie die vorhandenen Dateien aus dem Indexverzeichnis (falls nicht mehr benötigt) oder wählen Sie in der Mindbreeze InSpire-Konfiguration für diesen Index ein anderes Verzeichnis.
Hinweis: Wenn Sie ein anderes Verzeichnis definieren, vergewissern Sie sich, dass der Servicebenutzer für den definierten Pfad Schreibrechte besitzt - Kopieren Sie die gesicherten Indexdateien in das Indexverzeichnis.
- Starten Sie das Index Service wieder.
Index Status Information
Index Statistiken
Jedes Indexservice bietet unter der URL “/statistics” detailierte Statusinformationen über den Status des Indexprozesses und die Anzahl der Dokumente:
Ein Indexservice auf dem Host “indexserver.myorganization.com” unter 23100 ist unter folgender Statistik URL erreichbar: http://indexserver.myorganization.com:23100/statistics
Indizierte Dokumente
Zusätzlich zu den Indexstatistiken können unter dem Pfad “/documents” die indizierten Dokumente mittels des Dokumentenschlüssels (anhängig vom benutzten Connector) oder der ID des Dokuments (docid) abgerufen werden. Bitte beachten Sie, dass die docid eine interne Sequenznummer ist und zwischen den Indizierungsläufen variiert.
Ein Indexservice auf dem Host “indexserver.myorganization.com” unter 23100 ist unter folgender URL erreichbar: http://indexserver.myorganization.com:23100/documents
Index Status Information abfragen
Um die Verfügbarkeit des Index Services zu überprüfen gibt es eine Statushandler, der einerseits via mescontrol abgefragt und auch direkt via HTTP aufgerufen werden kann. Für die direkte Abfrage steht ein Handler via /index_mode am jeweiligen Index Service Port zur Verfügung.
Läuft der Index Service auf dem Host indexserver.myorganization.com und horcht dieser auf 23100, kann die Status Information unter folgender Adresse abgerufen werden: http://indexserver.myorganization.com:23100/index_mode
Erhält der Index Service eine HTTP GET Anfrage, antwortet dieser mit einem XML Dokument, das folgenden Aufbau hat::
<status mode=”<status-information>” />
<status-information> beschreibt dabei den Modus des Index Services und kann folgende Werte annehmen:
- normal (read write)
- readonly
- offline (closed)
Erhält man einen HTTP Statuscode der nicht 200 (HTTP SUCCESS) lautet, deutet dies ebenso auf einen nicht betriebsbereiten Index Service hin.
Backup von Log-Dateien
Die Log Dateien werden regelmäßig archiviert. Dies geschieht mithilfe eines Cron-Jobs, der standardmäßig jeden Sonntag um 2:30 Uhr ausgeführt wird.
Dabei werden Logdateien aus den Pfaden /data/logs und /var/opt/mindbreeze/log archiviert und in /data/backups/log-backups abgelegt.
Binäre Dateien werden nicht gesichert sondern beim Backup entfernt.
Von sehr großen Dateien werden nur die ersten 50GB gesichert.
Query Service Rekonfiguration
Die folgenden Query Service Optionen können vorübergehend geändert werden, ohne dass der Index neugestartet werden muss. Diese Änderungen bleiben in der Indexkonfiguration nicht bestehen:
- „Query Threads per Index“
- „Number of ACL Precomputation Threads”
Diese Neukonfiguration ist nur bei aktivierter Option "Unrestricted Privileged Servlets" möglich.
- Um die Anzahl der Query Threads zu ändern, führen Sie folgenden Befehl aus:
- mescontrol http://localhost:23100 reconfigure --query-threads=<n>
- Um die Anzahl der ACL Precomputation Threads zu ändern, führen Sie folgenden Befehl aus:
- mescontrol http://localhost:23100 reconfigure --precompute-acl-threads=<n>
Anhang A
Service Neustartverhalten bei Konfigurationsänderungen
Änderung | Index/ | Index/ | Connector | Filter | Filter Plugins | Caching Principal Resolution Service | Client Service | Client Service |
Connector | ||||||||
Neuer Index mit Connector | R | R | ||||||
Hinzufügen Connectors zu bestehendem Index | R | R | R | R | ||||
Ändern einer Connector Konfiguration | R | |||||||
Index/Query | ||||||||
Ändern des Indexpfades | ||||||||
Ändern einer Index Konfiguration | R | R | ||||||
Hinzufügen eines Query Plugins | R | R | ||||||
Ändern einer Query Plugin Konfiguration | R | |||||||
Filter | ||||||||
Hinzufügen eines Filter Plugins | R | R | ||||||
Ändern einer Filter Konfiguration | R | R | ||||||
Ändern einer Filter Plugin Konfiguration | R | |||||||
Client Service | ||||||||
Ändern eines Client Service | R | R | ||||||
Hinzufügen eines Client Service Plugins | R | R | ||||||
Ändern eines Client Service Plugins | R | |||||||
Allgemein | ||||||||
Ändern des Log-Levels | ||||||||
Ändern des Log-Verzeichnisses | R | R | R | R | R | R | R | R |
Ändern der Proxy Einstellung | R | R | R | R | R | R | R | R |
Ändern der LDAP Einstellung | R | R | R | R | R | R | R | R |
Ändern der Credentials und Endpoints | R | R | R | R | R | |||
Ändern der Authentisierungs-konfiguration ** | R | R | R | R | R | R | ||
Ändern der Zertifikate ** | R | R | R | R | R | R | ||
** Nur jene Services, die von den Änderungen betroffen sind (z.B. welche Authentisierung benutzen) werden neugestartet. | ||||||||
Anhang B
Manuelle Konfiguration der Authentifizierung mittels Kerberos
Für die manuelle Konfiguration ist folgendes nötig:
- Setzen des Service Principal Names HTTP/<host_fqdn> für den Servicebenutzer mittels setspn.exe oder händisch mitttels adsiedit.msc. Der <host_fqdn> ist der voll qualifizierte Hostname des Mindbreeze InSpire Node:
setspn -a HTTP/myserver.mydomain.com DOMAIN\serviceuser
Wichtig ist hierbei, dass der SPN für kein anderes Active Directory Objekt gesetzt ist. Dies kann unter Windows Server 2008 Systemen mittels "setspn -X" oder mit Hilfe von externen Tools wie zum Beispiel "dumpspn" überprüft werden.
- Setzen von "Trusted for delegation" für den Servicebenutzer mittels des "Benutzer und Computer" Management Console Plugins (dsa.msc).
Anhang C
In diesem Anhang finden Sie Beschreibungen zur Administration einzelner Komponenten von Mindbreeze InSpire.
Web Client Browsereinstellungen
Es gibt Sicherheitseinstellungen des Browsers, die den Komfort für Nutzer einschränken. So werden im Standardfall Links von Webseiten zu Dateiressourcen (z.B. file://myserver.myorganization.com/freigabe/brief.doc) nicht geöffnet. Zusätzlich werden Kerberos-Tickets nicht an das Mindbreeze InSpire Web Client Service weitergegeben: Mindbreeze InSpire setzt Netzwerk Single-Sign-On via Kerberos voraus, um einen sicheren und effizienten Zugriff auf Suchtreffer im Netzwerk zu erlauben. Im folgenden wird beschrieben, wie die Einstellungen des Browsers so gesetzt werden können, dass sowohl Verknüpfungen zu lokalen Dateien geöffnet, als auch die Konfiguration der Kerberos Single-Sign-On Umgebung ordnungsgemäß funktioniert.
Mozilla Firefox - Manuelles setzen der Einstellungen
Die Einstellungen, die bei der Installation der Erweiterung gemacht werden, können selbstverständlich auch manuell gesetzt werden. Um unter Mozilla Firefox eine Liste der Konfigurationsmöglichkeiten sichtbar zu machen, muss in der Adressleiste about:config eingegeben werden.
Um Kerberos Authentifizierung gegen das Mindbreeze InSpire Client Service zu erlauben, sollten folgende Einstellungen ähnlich zu den Beispielen gesetzt sein:
Konfigurationswert | Beschreibung | Beispiel |
network.negotiate-auth.delegation-uris | Dieser Wert sollte den voll qualifizierten Hostnamen des Mindbreeze Web Client Service Nodes einmal für das http und einmal für das https Protokoll enthalten. Hinweis: Mehrere Werte können vorkommen. Trennzeichen ist das Komma (,). | … http://myserver.myorganization.com, https://myserver.myorganization.com |
network.negotiate-auth.trusted-uris | Dieser Wert sollte den voll qualifizierten Hostnamen des Mindbreeze Web Client Service Nodes einmal für das http und einmal für das https Protokoll enthalten. Hinweis: Mehrere Werte können vorkommen. Trennzeichen ist das Komma (,). | … http:/://myserver.myorganization.com, https://myserver.myorganization.com |
Nach einem Neustart von Mozilla Firefox sollte die Anmeldung an das Mindbreeze InSpire Client Service über Kerberos funktionieren.
Zusätzlich soll es möglich sein, dass die Mindbreeze InSpire Web Client Dateien öffnen kann, die auf einem Netzlaufwerk liegen. Für Firefox 1.0.x, der Mozilla Browser Suite 1.7.x und früheren Versionen gibt es lediglich eine globale Einstellungsmöglichkeit. Durch Setzen der Einstellung „security.checkloaduri“ auf „false“ können alle Internet Seiten auf lokale Dateien verlinken und diese auch öffnen. Anschliessend muss der Browser neu gestartet werden.
Warnung: Diese Einstellung könnte von potentiell böswilligen Seiten genutzt werden, um lokale Dateien auszuführen.
In neueren Versionen (Mozilla Firefox 1.5, Mozilla Seamonkey 1.0 und neuer) kann diese globale Einstellung durch Sicherheitsrichtlinien, die auf bestimmte Seiten eingegrenzt werden können, ersetzt werden.
Neue Richtlinien können über die Datei user.js hinzugefügt werden. Diese liegt – sofern vorhanden - im Profilordner des jeweiligen Benutzers
(z.B.: C:\Dokumente und Einstellungen\Mindbreeze User\Anwendungsdaten\Mozilla\Firefox\Profiles\jisttzus.default\user.js).
Existiert die Datei noch nicht, muss die Datei angelegt werden.
Folgende Einstellungen müssen in die Datei eingefügt werden:
user_pref("capability.policy.policynames", "messecuritysettings");
user_pref("capability.policy.messecuritysettings.sites", "https://myserver.myorganization.com:23350");
user_pref("capability.policy. messecuritysettings.checkloaduri.enabled", "allAccess");
Hinweis: Sind in der Infrastruktur mehrere Web Clients vorhanden, die von einem Rechner aus abgerufen werden sollen, so können auch zusätzliche Adressen – durch Leerzeichen getrennt – hinzugefügt werden.
Hinweis: Die Datei „%USERPROFILE%\Anwendungsdaten\Mozilla\Firefox\profiles.ini“ gibt Aufschluss darüber in welchem Unterverzeichnis das gewünschte Profil zu finden ist, falls mehrere Profile verwendet werden.
Microsoft Internet Explorer
Manuelles setzen der Einstellungen
Im Microsoft Internet Explorer setzen Sicherheitszonen das Sicherheitskonzept um. Ohne die Einstellungen zu ändern, befindet sich jede Seite in der Zone „Internet“. Um dem Web Client die nötigen Rechte einzuräumen, fügen Sie die URL des Mindbreeze InSpire Web Client Service zur Sicherheitszone „Lokales Intranet“ hinzu.
Klicken Sie in der Statuszeile im rechten Bereich auf das Globus Symbol doppelt und markieren Sie im Reiter „Sicherheit“ die Sicherheitszone „Lokales Intranet“. Über die Schaltfläche „Sites“, gelangen Sie zu einem Dialogfenster, über welches die Adresse des Mindbreeze InSpire Web Client Service hinzugefügt werden kann.
Sie müssen sowohl die http- als auch die https-URL hinzufügen.
Beispiel: Ihr Mindbreeze InSpire Web Client Service wird vom Rechner myserver.myorganization.com verfügbar gemacht. Daher fügen Sie die Adressen
http://myserver.myorganization.com und
https://myserver.myorganization.com
zur Liste hinzu.
Stellen Sie außerdem sicher, dass die Option „Gemischte Inhalte anzeigen“ für das lokale Intranet aktiviert ist. Sie können diese Einstellung mit „Stufe anpassen“ überprüfen.
Zusätzlich sollten Sie die Option “Verschlüsselte Seiten nicht auf der Festplatte speichern“ im „Erweitert“ Tab deaktiveren.
Um die Änderungen zu übernehmen, laden Sie die Web Client Seite neu, nachdem die Adresse des Web Clients zur Intranetzone hinzugefügt wurde.
Automatisches setzen der Einstellungen
Um den Microsoft Internet Explorer automatisch für alle Mitglieder Ihrer Domäne zu konfigurieren, kann die Adresse der Client Service Webseite auch über die Gruppenrichtlinien zu den vertrauenswürdigen Webseiten hinzugefügt werden.
Als ersten Schritt müssen Sie sich dafür als ein Mitglied der Domänenadministratoren an Ihrem Domänen-Controller anmelden.
Danach starten Sie das Verwaltungswerkzeug „Active Directory, Benutzer und Computer“. Öffnen sie mit einem Rechtsklick das Kontextmenü der Organisationseinheit, auf die die Änderung der Einstellung durchgeführt werden soll, und wählen Sie dort den Menüpunkt Eigenschaften aus.
Wählen Sie als nächsten Schritt den Reiter Gruppenrichtlinie aus. Dort fügen Sie über die Schaltfläche „Neu“ eine neue Gruppenrichtlinie hinzu und benennen sie diese entsprechend (z.B.: MES IE Config). Klicken Sie dann auf die Schaltfläche „Bearbeiten“.

Im folgenden Abschnitt wird erklärt wie man die Konfiguration des Internet Explorers über Gruppenrichtlinien vornimmt.
Nach dem Öffnen der Gruppenrichtlinie, clicken Sie mit der rechten Maustaste auf „Administrative Vorlagen“ und klicken sie auf „Filterung…“.
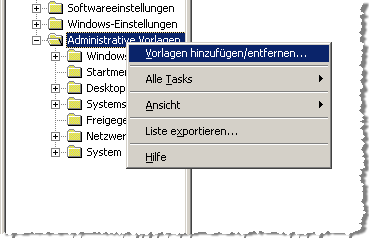
Deaktivieren Sie im folgenden Dialog “Nur vollständig verwaltbare Richtlinieneinstellungen anzeigen”.
Als nächstes werden wir die administrative Vorlage für die Internet Explorer Einstellungen hinzufügen.
Clicken Sie zuerst mit der rechten Maustaste auf „Administrative Vorlagen“ und clicken auf „Vorlagen hinzufügen/entfernen“.
Fügen Sie im folgenden Dialog die Datei “MindbreezeEnterprise SearchWebclient.adm” zu ihren Vorlagen hinzu. Diese Datei finden sie im Mindbreeze InSpire Installations ZIP / ISO.
Nachdem Sie die administrative Vorlage hinzugefügt haben, aktivieren Sie bitte alle Optionen.
Um den Mindbreeze Webclient zu ihren „Vertrauenswürdigen Sites“ hinzuzufügen, navigieren Sie danach durch „Benutzereinstellungen“ > „Windows-Einstellungen“ > „Internet Explorer-Wartung“ > „Sicherheit“ bis Sie in der rechten Hälfte den Punkt „Sicherheitszonen und Inhaltsfilter“ sehen. Öffnen Sie dort mit einem Rechtsklick das Kontextmenü und wählen Sie den Menüpunkt „Eigenschaften“ aus.
Im nächsten Schritt wählen Sie den Punkt „Aktuelle Einstellungen für Sicherheitszonen und Datenschutz importieren“ aus. Bestätigen Sie das Popupfenster mit „Weiter“. Sie können nun die Schaltfläche „Einstellungen ändern“ klicken.

Standardmäßig ist nun die Zone „Internet“ markiert. Wechseln Sie zur Zone „Lokales Intranet“. Danach klicken Sie auf „Sites“. In manchen Fällen öffnet sich nun ein Dialog in dem Sie definieren können, welche Seiten der Lokalen Intranet Zone angehören. Klicken Sie hier bitte auf „Erweitert“. Nun können Sie die Adresse des Web Clients hinzufügen. Führen Sie hier bitte eine Adresse für das HTTP- und eine für das HTTPS-Protokoll an (z.B.: http://myserver.myorganization.com und https://myserver.myorganization.com).
Zusätzlich können Sie auch das Zertifikat von Mindbreeze InSpire in die Liste der vertrauenswürdigen Zertifikate einfügen. Dies wird benötigt damit bei einer Verbindung über https der Web Client eindeutig identifiziert werden kann. Dazu navigieren Sie bitte durch Computerkonfiguration > Windows-Einstellungen > Sicherheitseinstellungen > Richtlinien öffentlicher Schlüssel zum Knoten „Vertrauenswürdige Stammzertifizierungsstellen“. Öffnen Sie mit einem Rechtsklick auf diesen das Kontextmenü und wählen Sie dort den Punkt „Importieren“.
Den ersten, nun erscheinenden, Dialog bestätigen Sie bitte mit „Weiter“. Im nun erscheinenden Dialog wählen Sie das Zertifikat von Mindbreeze InSpire aus. Dieses befindet sich im Installationsordner (z.B. C:\Programme\Mindbreeze\Enterprise Search\Server) und trägt den Namen ca-mindbreeze.pem. Bestätigen Sie den nächsten Dialog mit „Weiter“ und den darauf folgenden mit „Beenden“

Nun sollte sich unter „Vertrauenswürdige Stammzertifizierungsstellen“ ein Eintrag mit dem Namen Mindbreeze MES Server Authority befinden. Schließen Sie jetzt alle offenen Fenster und Dialoge die im Zusammenhang mit dem Verwaltungswerkzeug „Active Directory, Benutzer und Computer“ geöffnet wurden. Die Änderungen sollten nun nach einem Neustart aktiviert werden. Sie können nun den Mindbreeze Enterprise Web Client auf Microsoft Internet Explorer in Ihrer Domäne uneingeschränkt benutzen.
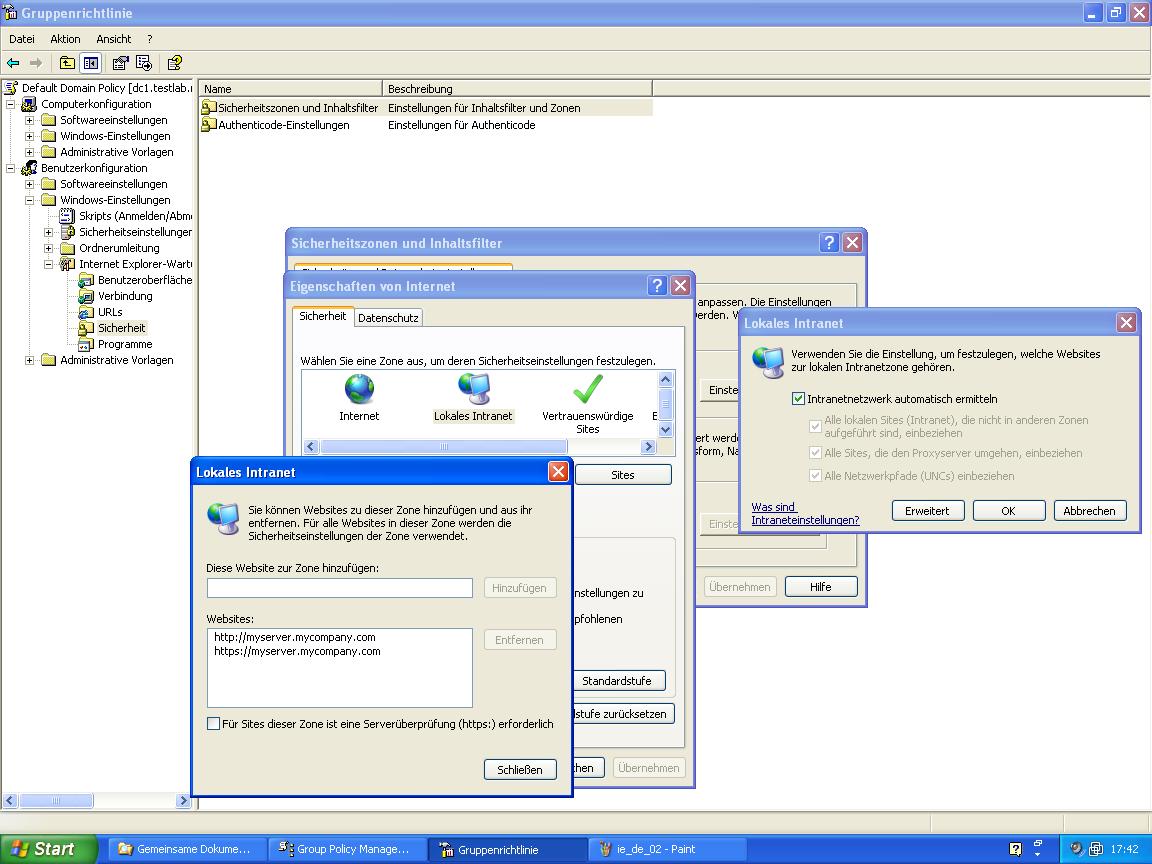
Anhang D
Verfügbare Fabasoft app.telemetry Log Pools zur Überwachung von Mindbreeze InSpire Services
InSpire stellt zur Überwachung von Fehlern und Warnungen von Services folgende Log Pools im Bereich „Mindbreeze InSpire Warnings and Errors“ zur Verfügung:
Um über Fehler oder Warnungen informiert zu werden, können Administrator:innen mittels Fabasoft app.telemetry benachrichtigt werden. InSpire stellt dafür folgende Counter Checks zur Verfügung:
In app.telemetry können für die einzelnen Service Checks Notifikationen eingerichtet werden.
Konfiguration von Notifikationen
Klicken Sie auf „Configuration“ und öffnen Sie dann „Notifications“ mit einem Klick auf das Plus-Symbol. Sie sehen nun einen Unterpunkt namens „Local Mail“. Mit einem Recktsklick oder durch den Knopf „New Notification Account“ erstellen Sie ein neues Notification-Konto.
Im nun erschienenen Fenster, geben Sie ihren Namen und unter „Send Notification to“ die Mail-Adresse an, die Benachrichtigungen erhalten soll. Bei „Notify when status changes from“ und „Notify when status changes to“ können Sie festlegen, bei welchen Status-Änderungen Sie eine Mail-Benachrichtigung erhalten möchten.
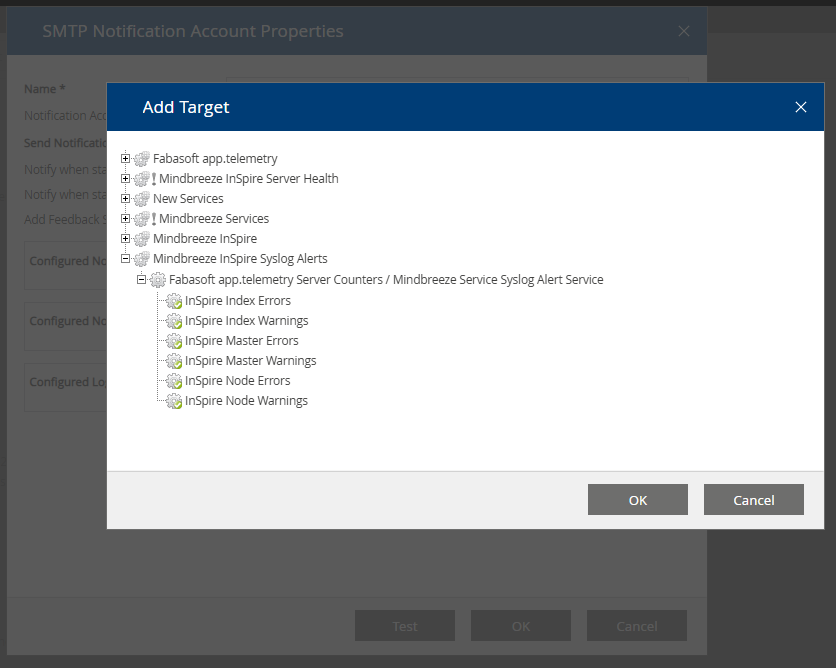
Weiters, können Sie nun festlegen, welche Logs sie überwachen möchten. Während bei „Configured Notification Targets“ einzelne Logs separat ausgewählt werden können, ist mit „Configured Notification Target Groups (notify each service status change)“ die Auswahl von Logpool-Gruppen möglich.
Sollten Sie separate Logs überwachen wollen, klicken Sie bei „Configured Notification Targets“ auf „Add Target“. Im nun erschienenen Fenster können Sie nun zum Beispiel „Mindbreeze InSpire Syslog Alerts“ öffnen, dann „Fabasoft.app.telemetry Server Counters / Mindbreeze Service Syslog Alert Service“ öffnen und die jeweiligen Logs wählen.
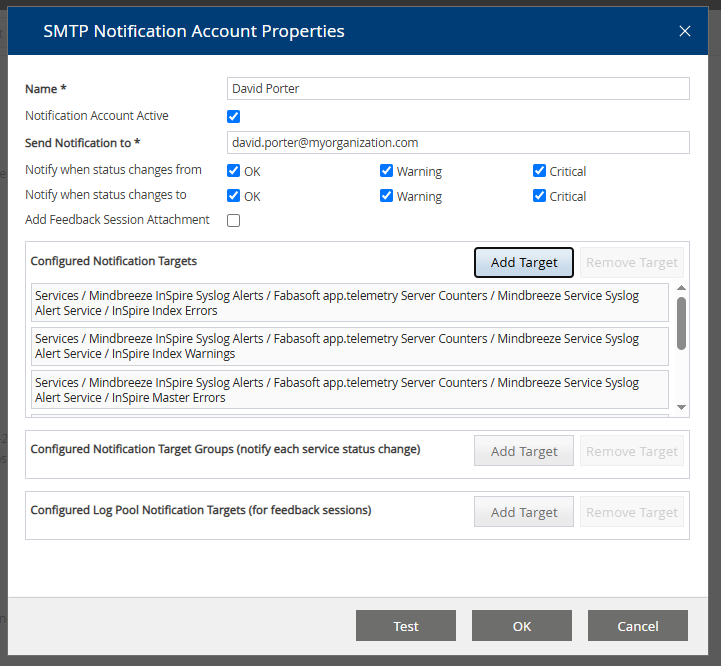
Die ausgewählten, separaten Logs werden folgendermaßen angezeigt:
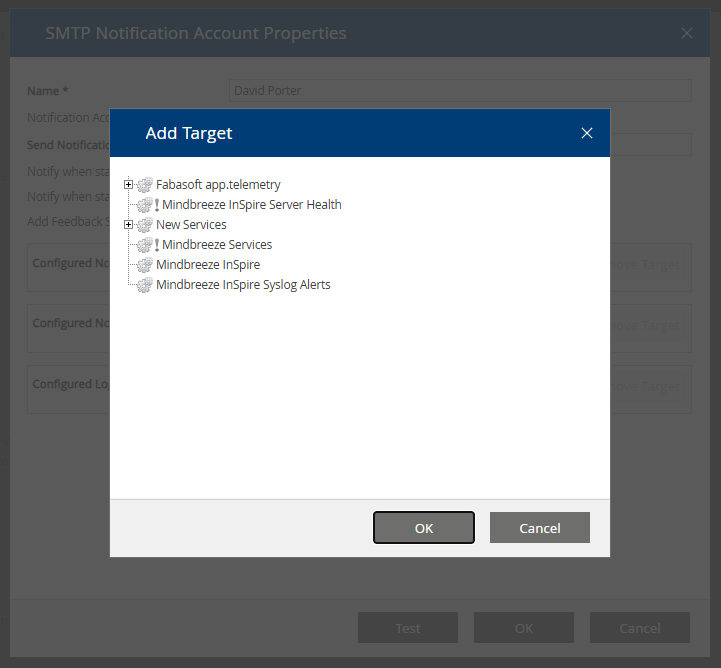
Sollten Sie eine gesamte Logpool-Gruppe überwachen wollen, klicken Sie bei „Configured Notification Target Groups (notify each service status change)“ auf „Add Target“. Im nun erschienenen Fenster können Sie nun zum Beispiel „Mindbreeze InSpire Syslog Alerts“ auswählen.
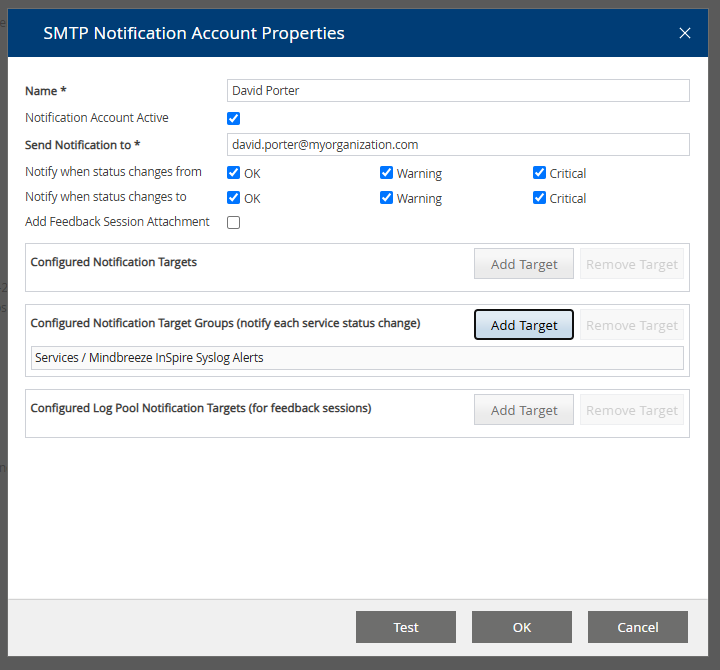
Die ausgewählte Logpool-Gruppe wird folgendermaßen angezeigt:
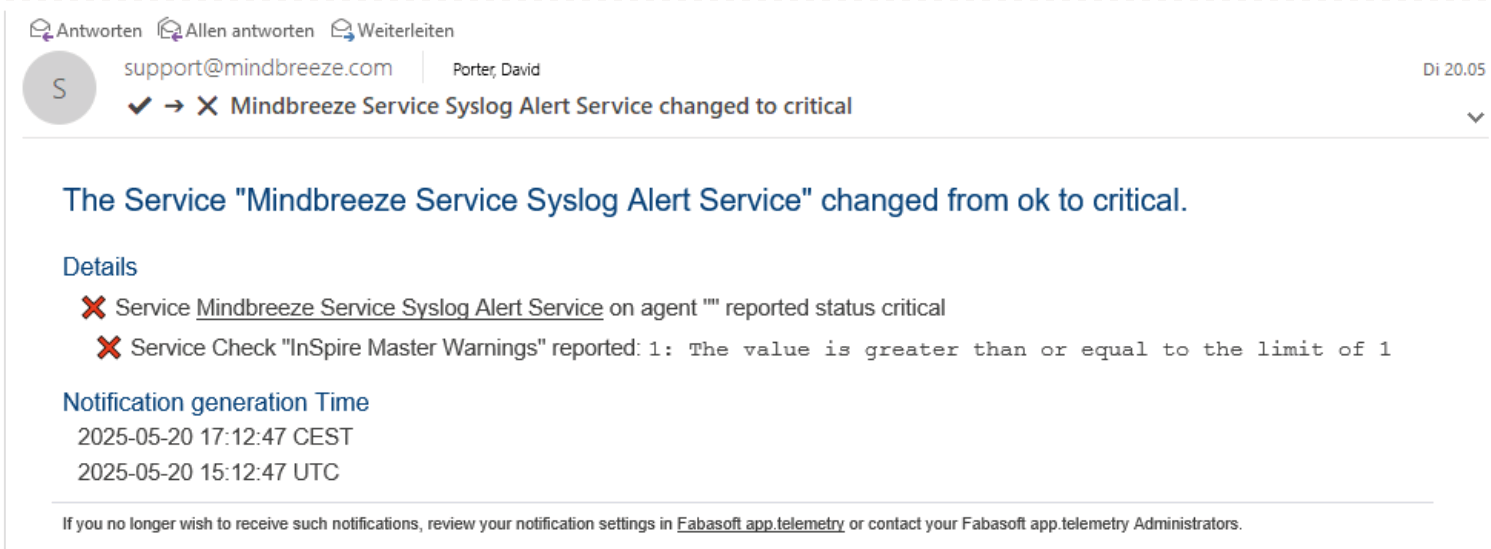
Bestätigen Sie abschließend ihre Einstellungen und Auswahl mit „OK“, um das Notification-Konto zu aktivieren.
Durch die Aktivierung des Notifikation-Konto erhalten Sie nun Email-Benachrichtigungen über Fehler oder Warnungen, die zum Beispiel so aussehen könnten:
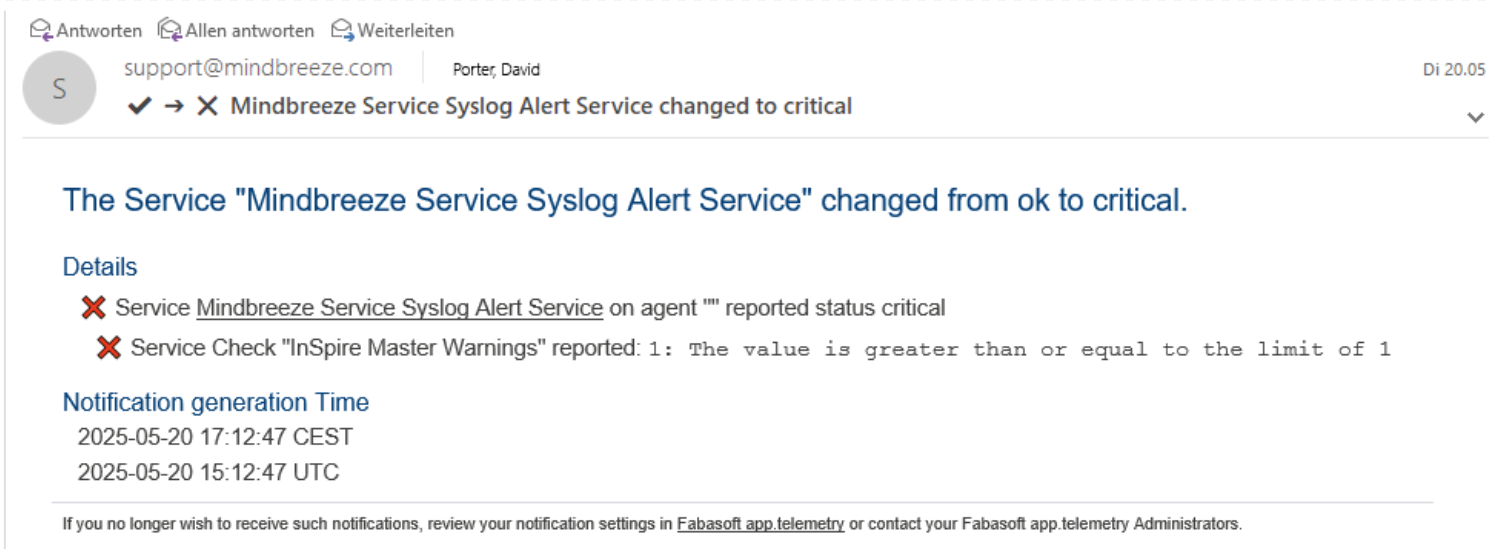
Sollten Fehler oder Warnungen behoben sein, erhalten Sie eine Email-Benachrichtigung, die zum Beispiel so aussehen könnte:
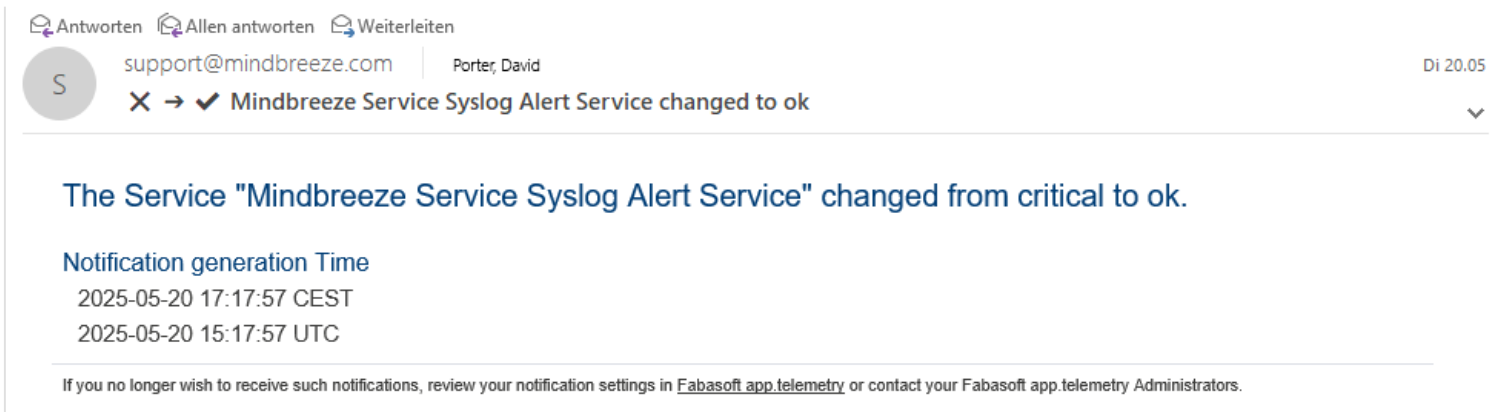
Fabasoft app.telemetry Log Pools manuell installieren für die Mindbreeze Services
Log Pools müssen in Mindbreeze InSpire nicht manuell installiert werden, da das Mindbreeze InSpire Setup alle Log Pools selbst verwaltet. Das manuelle Installieren von Log Pools ist nur in Fabasoft Mindbreeze Enterprise erforderlich.
Log Definitionen herunterladen
Sie können die Fabasof app.telemetry Log Definitionen für die Mindbreeze Services von der Mindbreeze Konfigurationsoberfläche herunterladen. Wählen Sie dazu den „Overview“ Karteireiter aus und klicken Sie auf dem Link „Fabasoft app.telemetry log definitions and Dashboards“.
Nachdem Sie den apptelemetryconfig.zip Archiv erfolgreich heruntergeladen und extrahiert haben, finden Sie die Log Definition Files im Verzeichnis „Logdefinitions“. Die folgenden Files sind hier enthalten:
- apptelemetrylogdefinitions_clientservice.xml: Log Definition File für die Mindbreeze Client Services;
- apptelemetrylogdefinitions_client.xml: log definition file for the Mindbreeze JavaScript Clients;
- apptelemetrylogdefinitions_contentfilterservice.xml: Log Definition File für Mindbreeze Content Filter Services;
- apptelemetrylogdefinitions_crawlerservice.xml: Log Definition File für die Mindbreeze Crawler Services;
- apptelemetrylogdefinitions_filterservice.xml: Log Definition File für die Mindbreeze Filter Services;
- apptelemetrylogdefinitions_indexservice.xml: Log Definition File für die Mindbreeze Index Services;
- apptelemetrylogdefinitions_jobsyncservice.xml: Log Definition File für die JobSync Services (wird bei die Mindbreeze InSite Installationen verwendet);
- apptelemetrylogdefinitions_networkrequests.xml: Log Definition für ein Netzwerkabfragen Log Pool für Mindbreeze Web Crawlers;
- apptelemetrylogdefinitions_queryservice.xml Log Definition File für Mindbreeze Query Services;
- apptelemetrylogdefinitions_sdkcsandbox.xml: Log Definition File für Mindbreeze SDKCsandbox services;
- apptelemetrylogdefinitions_tenantqueryservice.xml: zusätzliches Log Definition File für multitenant Query Services.
- apptelemetrylogdefinitions_crawlerservicerun.xml: zusätzliches Log Definition File für die Crawl Runs aller Datenquellen.
Log Pools anlegen für die Mindbreeze Services in Fabasoft app.telemetry
Die nötigen Schritte für Log Pools zu definieren finden Sie unter folgenden Link:
Auf dem „Log Pool Properties“ Karteireiter in der Log Pool Konfiguration die folgende „Application Filter“ Parameter sollen für die Mindbreeze Log Pools gesetzt werden:
- Application: Mindbreeze
- Application Tier:
- “Client” für Mindbreze Client Log Pools
- “Client Service” für Mindbreeze Client Service Log Pools
- “Client Service Query Log” für Mindbreeze Client Service Query Log - Log Pools
- “Content Filter Service” für Content Fitler Service Log Pools
- “Index Service” für Index Service Log Pools
- “Query Service” für Query Service Log Pools
- “Sandbox” für SDKCsandbox für Service Log Pools.
- “Sandbox” für SDKCsandbox für Service Log Pools.
- “Crawler Service Run” für Crawler Run Log Pools.
Anhang E
Extended Cron Ausdrücke
Mit einem Extended Cron Ausdruck kann man festlegen wann bzw. in welche Intervalle ein Task ausgeführt werden soll. Dies hat insbesondere den Vorteil, dass der Task automatisch von selbst ausgeführt wird anstatt, dass man ihn manuell jedes Mal ausführen muss.
Format und Syntax
Grundsätzlich besteht ein Extended Cron Ausdruck aus 6 Feldern:
1. Feld | 2. Feld | 3. Feld | 4. Feld | 5. Feld | 6. Feld | |
Feld Name | Sekunden | Minuten | Stunden | Monatstag | Monat | Wochentag |
Zulässige Werte | 0-59 | 0-59 | 0-23 | 1-31 | 1-12 oder | 0-6 oder |
Die Felder werden jeweils durch ein Leerzeichen getrennt und sehen wie folgt aus (X ist ein Platzhalter für ein Feld):
X X X X X X
Beispiele
Extended Cron Ausdruck | Bedeutung |
0 0 12 * * * | |
0 15 10 * * * | Jeden Tag um 10:15 |
20 15 10 * * * | Jeden Tag um 10:15:20 |
0 15 10 * * 0 | Jeden Sonntag um 10:15 |
0 15 10 * * SUN | Jeden Sonntag um 10:15 |
0 15 10 2 4 * | Jeden 2.April um 10:15 |
0 15 10 * 4 * | Jeden Tag im April um 10:15 |
0 15 10 7 * * | An jedem 7.Tag des Monats um 10:15 |
Anhang F
Liste unterstützter Zeitzonen
Africa/Abidjan, Africa/Accra, Africa/Addis_Ababa, Africa/Algiers, Africa/Asmara, Africa/Asmera, Africa/Bamako, Africa/Bangui, Africa/Banjul, Africa/Bissau, Africa/Blantyre, Africa/Brazzaville, Africa/Bujumbura, Africa/Cairo, Africa/Casablanca, Africa/Ceuta, Africa/Conakry, Africa/Dakar, Africa/Dar_es_Salaam, Africa/Djibouti, Africa/Douala, Africa/El_Aaiun, Africa/Freetown, Africa/Gaborone, Africa/Harare, Africa/Johannesburg, Africa/Juba, Africa/Kampala, Africa/Khartoum, Africa/Kigali, Africa/Kinshasa, Africa/Lagos, Africa/Libreville, Africa/Lome, Africa/Luanda, Africa/Lubumbashi, Africa/Lusaka, Africa/Malabo, Africa/Maputo, Africa/Maseru, Africa/Mbabane, Africa/Mogadishu, Africa/Monrovia, Africa/Nairobi, Africa/Ndjamena, Africa/Niamey, Africa/Nouakchott, Africa/Ouagadougou, Africa/Porto-Novo, Africa/Sao_Tome, Africa/Timbuktu, Africa/Tripoli, Africa/Tunis, Africa/Windhoek, America/Adak, America/Anchorage, America/Anguilla, America/Antigua, America/Araguaina, America/Argentina/Buenos_Aires, America/Argentina/Catamarca, America/Argentina/ComodRivadavia, America/Argentina/Cordoba, America/Argentina/Jujuy, America/Argentina/La_Rioja, America/Argentina/Mendoza, America/Argentina/Rio_Gallegos, America/Argentina/Salta, America/Argentina/San_Juan, America/Argentina/San_Luis, America/Argentina/Tucuman, America/Argentina/Ushuaia, America/Aruba, America/Asuncion, America/Atikokan, America/Atka, America/Bahia, America/Bahia_Banderas, America/Barbados, America/Belem, America/Belize, America/Blanc-Sablon, America/Boa_Vista, America/Bogota, America/Boise, America/Buenos_Aires, America/Cambridge_Bay, America/Campo_Grande, America/Cancun, America/Caracas, America/Catamarca, America/Cayenne, America/Cayman, America/Chicago, America/Chihuahua, America/Coral_Harbour, America/Cordoba, America/Costa_Rica, America/Creston, America/Cuiaba, America/Curacao, America/Danmarkshavn, America/Dawson, America/Dawson_Creek, America/Denver, America/Detroit, America/Dominica, America/Edmonton, America/Eirunepe, America/El_Salvador, America/Ensenada, America/Fort_Nelson, America/Fort_Wayne, America/Fortaleza, America/Glace_Bay, America/Godthab, America/Goose_Bay, America/Grand_Turk, America/Grenada, America/Guadeloupe, America/Guatemala, America/Guayaquil, America/Guyana, America/Halifax, America/Havana, America/Hermosillo, America/Indiana/Indianapolis, America/Indiana/Knox, America/Indiana/Marengo, America/Indiana/Petersburg, America/Indiana/Tell_City, America/Indiana/Vevay, America/Indiana/Vincennes, America/Indiana/Winamac, America/Indianapolis, America/Inuvik, America/Iqaluit, America/Jamaica, America/Jujuy, America/Juneau, America/Kentucky/Louisville, America/Kentucky/Monticello, America/Knox_IN, America/Kralendijk, America/La_Paz, America/Lima, America/Los_Angeles, America/Louisville, America/Lower_Princes, America/Maceio, America/Managua, America/Manaus, America/Marigot, America/Martinique, America/Matamoros, America/Mazatlan, America/Mendoza, America/Menominee, America/Merida, America/Metlakatla, America/Mexico_City, America/Miquelon, America/Moncton, America/Monterrey, America/Montevideo, America/Montreal, America/Montserrat, America/Nassau, America/New_York, America/Nipigon, America/Nome, America/Noronha, America/North_Dakota/Beulah, America/North_Dakota/Center, America/North_Dakota/New_Salem, America/Ojinaga, America/Panama, America/Pangnirtung, America/Paramaribo, America/Phoenix, America/Port-au-Prince, America/Port_of_Spain, America/Porto_Acre, America/Porto_Velho, America/Puerto_Rico, America/Rainy_River, America/Rankin_Inlet, America/Recife, America/Regina, America/Resolute, America/Rio_Branco, America/Rosario, America/Santa_Isabel, America/Santarem, America/Santiago, America/Santo_Domingo, America/Sao_Paulo, America/Scoresbysund, America/Shiprock, America/Sitka, America/St_Barthelemy, America/St_Johns, America/St_Kitts, America/St_Lucia, America/St_Thomas, America/St_Vincent, America/Swift_Current, America/Tegucigalpa, America/Thule, America/Thunder_Bay, America/Tijuana, America/Toronto, America/Tortola, America/Vancouver, America/Virgin, America/Whitehorse, America/Winnipeg, America/Yakutat, America/Yellowknife, Antarctica/Casey, Antarctica/Davis, Antarctica/DumontDUrville, Antarctica/Macquarie, Antarctica/Mawson, Antarctica/McMurdo, Antarctica/Palmer, Antarctica/Rothera, Antarctica/South_Pole, Antarctica/Syowa, Antarctica/Troll, Antarctica/Vostok, Arctic/Longyearbyen, Asia/Aden, Asia/Almaty, Asia/Amman, Asia/Anadyr, Asia/Aqtau, Asia/Aqtobe, Asia/Ashgabat, Asia/Ashkhabad, Asia/Baghdad, Asia/Bahrain, Asia/Baku, Asia/Bangkok, Asia/Barnaul, Asia/Beirut, Asia/Bishkek, Asia/Brunei, Asia/Calcutta, Asia/Chita, Asia/Choibalsan, Asia/Chongqing, Asia/Chungking, Asia/Colombo, Asia/Dacca, Asia/Damascus, Asia/Dhaka, Asia/Dili, Asia/Dubai, Asia/Dushanbe, Asia/Gaza, Asia/Harbin, Asia/Hebron, Asia/Ho_Chi_Minh, Asia/Hong_Kong, Asia/Hovd, Asia/Irkutsk, Asia/Istanbul, Asia/Jakarta, Asia/Jayapura, Asia/Jerusalem, Asia/Kabul, Asia/Kamchatka, Asia/Karachi, Asia/Kashgar, Asia/Kathmandu, Asia/Katmandu, Asia/Khandyga, Asia/Kolkata, Asia/Krasnoyarsk, Asia/Kuala_Lumpur, Asia/Kuching, Asia/Kuwait, Asia/Macao, Asia/Macau, Asia/Magadan, Asia/Makassar, Asia/Manila, Asia/Muscat, Asia/Nicosia, Asia/Novokuznetsk, Asia/Novosibirsk, Asia/Omsk, Asia/Oral, Asia/Phnom_Penh, Asia/Pontianak, Asia/Pyongyang, Asia/Qatar, Asia/Qyzylorda, Asia/Rangoon, Asia/Riyadh, Asia/Saigon, Asia/Sakhalin, Asia/Samarkand, Asia/Seoul, Asia/Shanghai, Asia/Singapore, Asia/Srednekolymsk, Asia/Taipei, Asia/Tashkent, Asia/Tbilisi, Asia/Tehran, Asia/Tel_Aviv, Asia/Thimbu, Asia/Thimphu, Asia/Tokyo, Asia/Tomsk, Asia/Ujung_Pandang, Asia/Ulaanbaatar, Asia/Ulan_Bator, Asia/Urumqi, Asia/Ust-Nera, Asia/Vientiane, Asia/Vladivostok, Asia/Yakutsk, Asia/Yekaterinburg, Asia/Yerevan, Atlantic/Azores, Atlantic/Bermuda, Atlantic/Canary, Atlantic/Cape_Verde, Atlantic/Faeroe, Atlantic/Faroe, Atlantic/Jan_Mayen, Atlantic/Madeira, Atlantic/Reykjavik, Atlantic/South_Georgia, Atlantic/St_Helena, Atlantic/Stanley, Australia/ACT, Australia/Adelaide, Australia/Brisbane, Australia/Broken_Hill, Australia/Canberra, Australia/Currie, Australia/Darwin, Australia/Eucla, Australia/Hobart, Australia/LHI, Australia/Lindeman, Australia/Lord_Howe, Australia/Melbourne, Australia/NSW, Australia/North, Australia/Perth, Australia/Queensland, Australia/South, Australia/Sydney, Australia/Tasmania, Australia/Victoria, Australia/West, Australia/Yancowinna, Brazil/Acre, Brazil/DeNoronha, Brazil/East, Brazil/West, CET, CST6CDT, Canada/Atlantic, Canada/Central, Canada/East-Saskatchewan, Canada/Eastern, Canada/Mountain, Canada/Newfoundland, Canada/Pacific, Canada/Saskatchewan, Canada/Yukon, Chile/Continental, Chile/EasterIsland, Cuba, EET, EST5EDT, Egypt, Eire, Etc/GMT, Etc/GMT+0, Etc/GMT+1, Etc/GMT+10, Etc/GMT+11, Etc/GMT+12, Etc/GMT+2, Etc/GMT+3, Etc/GMT+4, Etc/GMT+5, Etc/GMT+6, Etc/GMT+7, Etc/GMT+8, Etc/GMT+9, Etc/GMT-0, Etc/GMT-1, Etc/GMT-10, Etc/GMT-11, Etc/GMT-12, Etc/GMT-13, Etc/GMT-14, Etc/GMT-2, Etc/GMT-3, Etc/GMT-4, Etc/GMT-5, Etc/GMT-6, Etc/GMT-7, Etc/GMT-8, Etc/GMT-9, Etc/GMT0, Etc/Greenwich, Etc/UCT, Etc/UTC, Etc/Universal, Etc/Zulu, Europe/Amsterdam, Europe/Andorra, Europe/Astrakhan, Europe/Athens, Europe/Belfast, Europe/Belgrade, Europe/Berlin, Europe/Bratislava, Europe/Brussels, Europe/Bucharest, Europe/Budapest, Europe/Busingen, Europe/Chisinau, Europe/Copenhagen, Europe/Dublin, Europe/Gibraltar, Europe/Guernsey, Europe/Helsinki, Europe/Isle_of_Man, Europe/Istanbul, Europe/Jersey, Europe/Kaliningrad, Europe/Kiev, Europe/Kirov, Europe/Lisbon, Europe/Ljubljana, Europe/London, Europe/Luxembourg, Europe/Madrid, Europe/Malta, Europe/Mariehamn, Europe/Minsk, Europe/Monaco, Europe/Moscow, Europe/Nicosia, Europe/Oslo, Europe/Paris, Europe/Podgorica, Europe/Prague, Europe/Riga, Europe/Rome, Europe/Samara, Europe/San_Marino, Europe/Sarajevo, Europe/Simferopol, Europe/Skopje, Europe/Sofia, Europe/Stockholm, Europe/Tallinn, Europe/Tirane, Europe/Tiraspol, Europe/Ulyanovsk, Europe/Uzhgorod, Europe/Vaduz, Europe/Vatican, Europe/Vienna, Europe/Vilnius, Europe/Volgograd, Europe/Warsaw, Europe/Zagreb, Europe/Zaporozhye, Europe/Zurich, GB, GB-Eire, GMT, GMT0, Greenwich, Hongkong, Iceland, Indian/Antananarivo, Indian/Chagos, Indian/Christmas, Indian/Cocos, Indian/Comoro, Indian/Kerguelen, Indian/Mahe, Indian/Maldives, Indian/Mauritius, Indian/Mayotte, Indian/Reunion, Iran, Israel, Jamaica, Japan, Kwajalein, Libya, MET, MST7MDT, Mexico/BajaNorte, Mexico/BajaSur, Mexico/General, NZ, NZ-CHAT, Navajo, PRC, PST8PDT, Pacific/Apia, Pacific/Auckland, Pacific/Bougainville, Pacific/Chatham, Pacific/Chuuk, Pacific/Easter, Pacific/Efate, Pacific/Enderbury, Pacific/Fakaofo, Pacific/Fiji, Pacific/Funafuti, Pacific/Galapagos, Pacific/Gambier, Pacific/Guadalcanal, Pacific/Guam, Pacific/Honolulu, Pacific/Johnston, Pacific/Kiritimati, Pacific/Kosrae, Pacific/Kwajalein, Pacific/Majuro, Pacific/Marquesas, Pacific/Midway, Pacific/Nauru, Pacific/Niue, Pacific/Norfolk, Pacific/Noumea, Pacific/Pago_Pago, Pacific/Palau, Pacific/Pitcairn, Pacific/Pohnpei, Pacific/Ponape, Pacific/Port_Moresby, Pacific/Rarotonga, Pacific/Saipan, Pacific/Samoa, Pacific/Tahiti, Pacific/Tarawa, Pacific/Tongatapu, Pacific/Truk, Pacific/Wake, Pacific/Wallis, Pacific/Yap, Poland, Portugal, ROK, Singapore, SystemV/AST4, SystemV/AST4ADT, SystemV/CST6, SystemV/CST6CDT, SystemV/EST5, SystemV/EST5EDT, SystemV/HST10, SystemV/MST7, SystemV/MST7MDT, SystemV/PST8, SystemV/PST8PDT, SystemV/YST9, SystemV/YST9YDT, Turkey, UCT, US/Alaska, US/Aleutian, US/Arizona, US/Central, US/East-Indiana, US/Eastern, US/Hawaii, US/Indiana-Starke, US/Michigan, US/Mountain, US/Pacific, US/Pacific-New, US/Samoa, UTC, Universal, W-SU, WET, Zulu, EST, HST, MST, ACT, AET, AGT, ART, AST, BET, BST, CAT, CNT, CST, CTT, EAT, ECT, IET, IST, JST, MIT, NET, NST, PLT, PNT, PRT, PST, SST, VST
Anhang G
Mindbreeze bietet die Möglichkeit, benutzerdefinierte trainierte Modelle und benutzerdefinierte Kataloge zu verwenden, zum Beispiel für Stopp-Wörter und Entity-Erkennung.
Um benutzerdefinierte Ressourcen zu verwenden, muss eine bestimmte Benennungskonvention und Ordnerstruktur verwendet werden:
|-----parent_folder [Folder]
|------------model_names [Folder]
|------------current_version.json [File]
|------------current_version [Folder]
|-------------------model [File]
Benennungskonventionen für benutzerdefinierte Modelle und Kataloge
parent_folder [Folder]:
Kann jeder vom Betriebssystem erlaubte Name sein und eine beliebige Anzahl von unterstützten Modellen enthalten. Dies ist der Ordnerpfad, der in der Indexkonfiguration angegeben werden muss.
model_names [Folder]:
Dies ist ein Ordner, der nach den enthaltenen Modellen benannt ist.
Die Modellnamen müssen der folgenden Namenskonvention entsprechen:
Resource type | Naming guideline | Description |
Compound Splitting Models | mindbreeze.models.nlp.char_ngram_hash_profile.wikipedia.<language> | language ist der Sprachcode für das Modell (z. B. "en" oder "de"). Diese Modelle werden für das „compound splitting“-Feature verwendet. Die Modelldateien müssen die Dateiendung proto.bin haben. |
NER Entity Catalogs | mindbreeze.catalogues.nlp.lowercased_word_type.entity.<entityType> | entityType ist einer der anerkannten Entitätstypen: location, organization, person, misc. Nur Wörter, die in diesem Katalog enthalten sind, werden als Entitäten erkannt. Dies kann als Maßnahme zur Verringerung falsch positiver Ergebnisse verwendet werden. Dies ist relevant für NER-Hervorhebung und Aggregation. Diese Ressourcendateien müssen eine .csv- Dateiendung haben |
NER Stop Words Catalogs | mindbreeze.catalogs.nlp.stop_words.<langage> | language ist der Sprachcode für den Katalog (z. B. "en" oder "de"). Die Wörter in diesen Katalogen werden bei der NER-Verarbeitung ignoriert. Dies kann als Maßnahme zur Verringerung falsch positiver Ergebnisse verwendet werden. Ressourcendateien dieses Typs müssen eine .txt-Dateiendung haben |
Stop Words Catalogs | mindbreeze.catalogs.nlp.lowercased_stop_words.<language> | language ist die Sprache des Katalogs. Wörter in diesen Katalogen werden beim normalen Highlighting und für das " Did you mean"-Feature ignoriert. Ressourcendateien dieses Typs müssen eine .txt- Dateiendung haben |
current_version.json [File]:
Diese json-Datei gibt an, welche Modellversion zu laden ist, da es unterschiedliche Versionen von Modellen geben kann. Diese Datei muss in der Ordnerstruktur vorhanden sein.
Diese Datei sollte die aktuelle Version des zu ladenden Modells enthalten, wie folgt:
{
"current_version": "<version>"
}
version kann zum Beispiel 1.0.0 sein.
version_folder [Folder]:
Dieser Ordner ist nach der Version des Modells benannt, z. B. 1.0.0.
model_file [File]:
Dies ist die zu ladende Modelldatei. Der Dateiname und die Erweiterung müssen der oben beschriebenen Namenskonvention entsprechen.