
Sure, you can handle it. But should you?
Let our experts manage the tech maintenance while you focus on your business.
Let our experts manage the tech maintenance while you focus on your business.
Konfiguration
Personalisierte Relevanz
Einleitung
Mithilfe dieses Plugins kann das Mindbreeze Relevanzmodell beeinflusst werden (auch Boosting von Dokumenten genannt). Dabei wird das Suchverhalten aller Benutzer miteinbezogen. Die Grundfunktionalität dieses Plugins ist, dass Dokumente, die öfter geklickt wurden (Öffnen- / Vorschauaktion), bei zukünftigen (gleichen) Suchanfragen weiter oben angezeigt werden.
Folgende Faktoren werden zusätzlich miteinbezogen:
- Wie viele verschiedene Benutzer haben eine Aktion am Dokument durchgeführt
- In wie vielen verschiedene Sessions wurde eine Aktion am Dokument durchgeführt
- Wie oft wurde die gleiche Suchanfrage ausgeführt (relativ zu allen ausgeführten Suchanfragen)
Bitte beachten Sie, dass zur Relevanzberechnung das Suchverhalten aller Benutzer einbezogen wird und nicht pro Benutzer eigene Relevanzberechnungen stattfinden.
Installation
Das Plugin ist bereits in Mindbreeze InSpire enthalten und muss deswegen nicht zusätzlich installiert werden.
Vorbedingungen
Damit das Plugin funktionsfähig ist, muss die Personalisierung im Client Service aktiviert sein. Damit werden alle Suchen und Aktionen der Benutzer in der app.telemetry mitprotokolliert. Standardmäßig ist diese Option aktiv. Prüfen Sie dies, indem Sie im Mindbreeze Management Center im Menü „Configuration“ den Tab „Client Services“ öffnen, die „Advanced Settings“ aktivieren und unter „Personalization Settings“ sehen, dass die Option „Enable Personalization“ aktiv ist.

Die Aufzeichnungen in der app.telemetry werden standardmäßig maximal 6 Monate aufbewahrt. Beachten Sie außerdem, dass wenn „Enable Personalization“ nicht aktiv war, keine Daten aufgezeichnet wurden und somit der PersonalizedRelevanceTransformer keine Auswirkungen auf das Relevanzmodell haben kann.
Außerdem muss für die Verwendung des PersonalizedRelevanceTransformers bei jeder Suchanfrage der „referer“ in der Suchanfrage mitgesendet werden. Andernfalls hat der Transformer keine Auswirkung auf das Relevanzmodell.
Konfiguration
Um das Plugin zu konfigurieren, öffnen Sie im Mindbreeze Management Center im Menü „Configuration“ den Tab „Indices“. Fügen Sie einen neuen Service im Bereich „Services“ hinzu, indem Sie auf den Button „+ Add Service“ klicken. Wählen Sie in der Liste „Service“ das Plugin „PersonalizedRelevanceTransformer“ aus.
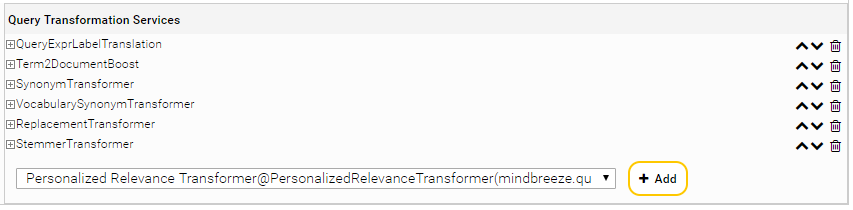
Je nachdem, ob der QueryExprTransformationService für alle oder nur für ausgewählte Indices verfügbar sein soll, müssen Sie folgendermaßen vorgehen:
- Für alle Indices: Im Bereich „Query Transformation Services“ können Sie den konfigurierten Service auswählen (<Display Name>@PersonalizedRelevanceTransformer)
- Für ausgewählte Indices: Am ausgewählten Index im Bereich „Query Transformation Services“ können Sie den konfigurierten Service auswählen
Klicken Sie in beiden Fällen anschließend auf den Button „+ Add“, um den Service hinzuzufügen.

Stellen Sie anschließend sicher, dass das PersonalizedRelevanceTransformer Service an oberster Stelle steht. Um die Reihenfolge des Services zu ändern, benutzen Sie die Pfeil-Buttons rechts (![]() ).
).
Im Bereich Services können Sie den Service nun konfigurieren (aktivieren Sie die „Advanced Settings“, um alle Konfigurationsoptionen sehen zu können).
Base Configuration
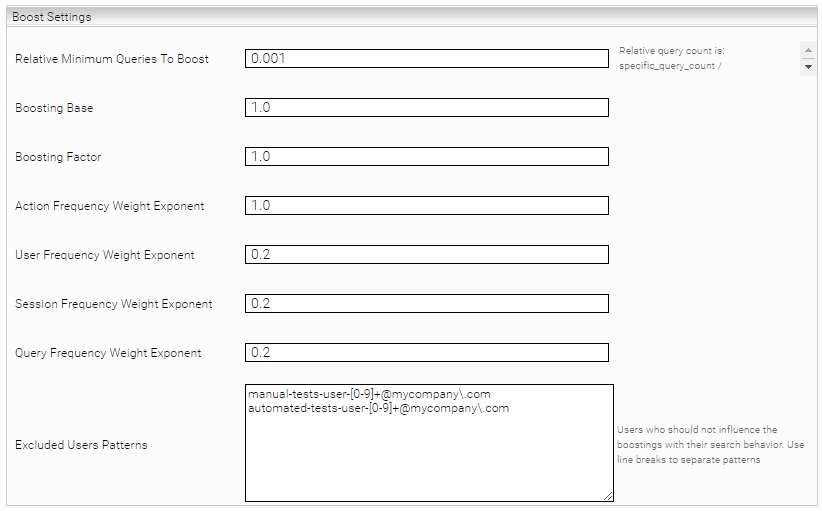
Einstellung | Beschreibung |
Bind Port | Der Port, auf dem der Service laufen soll. |
Boosting Data Cache Refresh Interval Seconds | Der Service verwendet intern einen Cache, um die Suchanfragen effizient bearbeiten zu können. Je nachdem, wie aktuell die Daten für die Relevanzberechnung sein müssen, können sie das Intervall zum Erneuern des Caches in Sekunden angeben. Wird „0“ angegeben, wird der Cache nicht aufgebaut. Stattdessen kann das Refresh Servlet unter /api/boostings/refresh verwendet werden, um die Aktualisierung des Caches manuell zu starten. |
Boosting Type (Advanced Setting) | Damit das Plugin auch bei älteren Mindbreeze InSpire Versionen funktioniert, kann die Option „QueryExpr“ ausgewählt werden. Aus Performancegründen sollte jedoch, wenn möglich immer „FQCategory and Key“ ausgewählt werden |
Report Heap Dump on out of Memory (Advanced Setting) | Wenn aktiv und es tritt ein OutOfMemoryError auf, wird im aktuellen Log-Verzeichnis ein Heap-Dump als .hprof-Datei abgelegt. |
Default Servlet Page Size (Advanced Setting) | Die Standardseitengröße der Servelts |
Maximum Number of Boosting Exports (Advanced Setting) | Boostings werden automatisch bei jedem Refresh exportiert. Dabei werden standardmäßig die letzten 10 Exports aufgehoben. Wie viele Exports aufgehoben werden, kann mit dieser Option konfiguriert werden. |
Application Definitions | Um die Boostings von verschiedenen Search Clients zu trennen, können „Application Definitions“ angegeben werden:
Bei einer Suchanfrage werden die Boostings der ersten Applikation verwendet, die der URL der Suchanfrage entspricht. Standardmäßig gibt es außerdem eine „Application Definition“ mit dem Namen „default“, welche auf alle URLs matcht (.*) – diese ist jedoch in der Konfiguration nicht sichtbar. |
Boost Settings
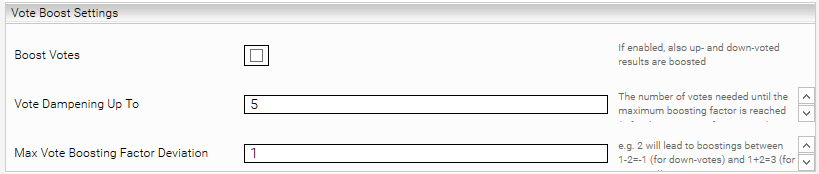
Einstellung | Beschreibung |
Relative Minimum Queries To Boost | Die relative Anzahl an gleichen Suchanfragen, die mindestens zuvor abgesetzt wurden, um Dokumente mit einer bestimmten Query zu boosten. Wurde z.B. nach „mindbreeze“ 1000 mal gesucht und es gab 500000 Queries in der Vergangenheit, ist der Relative Queries To Boost für die Query „mindbreeze“ 1000/500000 = 0,002 |
Add Empty Boostings (Advanced Settings) | Fügt auch Boostings hinzu, die auch unter dem konfigurierten „Relative Minimum Queries To Boost“ liegen (mit Boosting Faktor 1). Diese Option hat keine Auswirkung auf das Relevanz-Modell, jedoch werden diese Boostings dann im Servlet /api/boostings angezeigt. |
Boosting Base | Die Basis des Boosting-Werts (entspricht dem Minimalwert). |
Boosting Factor | Der Faktor, wie stark sich das Boosting auswirkt. |
Action Frequency Weight Exponent | Kommawerte (mit . als Dezimaltrennzeichen) zwischen 0 und 1 sind gültig (0 = wird nicht in die Berechnung einbezogen, 1 = wird vollständig in die Berechnung miteinbezogen). |
User Frequency Weight Exponent | Auswirkung auf das Boosting davon, wie viele verschiedene Benutzer eine Aktion am Dokument durchgeführt haben. Kommawerte zwischen 0 und 1 sind gültig. |
Session Frequency Weight Exponent | Auswirkung auf das Boosting davon, in wie vielen verschiedene Sessions eine Aktion am Dokument durchgeführt wurde. Kommawerte zwischen 0 und 1 sind gültig. |
Query Frequency Weight Exponent | Auswirkung auf das Boosting davon, wie oft die gleiche Suchanfrage (mit gleichem Query String) ausgeführt wurde (relativ zu allen ausgeführten Suchanfragen). Kommawerte zwischen 0 und 1 sind gültig. |
Excluded Users Patterns | Patterns (Java RegEx) für Benutzer, welche durch ihr Suchverhalten die Boostings nicht beeinflussen sollen. Es können mehrere Patterns angegeben werden, getrennt durch Zeilenumbrüche. Kann beispielsweise dafür verwendet werden, dass die Suchen von automatisierten oder manuellen Tests keine Auswirkung auf das Boosting haben. Die Patterns werden mit Zeilenumbrüchen getrennt. Diese Option hat auch Auswirkung auf Vote Boostings. |
Vote Boost Settings

Einstellung | Beschreibung |
Boost Votes | Wenn aktiviert, werden auch die up- und down-voted Ergebnisse im Relevanzmodell miteinbezogen. Das Relevanzmodell wird dabei unabhängig vom Suchbegriff beeinflusst. |
Vote Dampening Up To | Die Anzahl der Votes, die benötigt werden, bis der maximale Boosting-Faktor erreicht ist (Maximum ist 0 für Down-Votes, 2 für Up-Votes). |
Max Vote Boosting Factor Deviation | z.B. 2 führt zu Boostings zwischen 1-2=-1 (für Down-Votes) und 1+2=3 (für Up-Votes)). |
DB Connection Settings

Einstellung | Beschreibung |
JDBC URL | Der JDBC URL zur app.telemetry Datenbank. |
Custom Credential | Die Anmeldeinformationen zur app.telemetry Datenbank. Dieses Feld kann leer gelassen werden („None“). Wenn Sie jedoch den Default „JDBC URL“ geändert haben (jdbc:postgresql://localhost:5432/telemetrydb), müssen Sie die Anmeldeinformationen explizit konfigurieren. Fügen Sie dazu im Tab „Network“ unter „Credentials“ neue Anmeldeinformationen mit dem Type „Username/Password“ hinzu. Die Standardanmeldeinformationen können in Initiale Inbetriebnahme für G7 Appliances – Reporting gefunden werden. Falls Sie eine G6 Appliance in Verwendung haben, finden Sie die Standardanmeldeinformationen in Initiale Inbetriebnahme für G6 Appliances (vor Jänner 2018 ausgeliefert) – Reporting. Bitte beachten Sie auch, dass Sie in diesem Fall im Bereich „DB Schema“ (Advanced Setting) die Option „Table Name“ anpassen müssen. |
Maximum Pooled Connections | Maximale an Datenbank Connections, die im Connection Pool gehalten werden. |
DB Schema (Advanced Setting)
Diese Optionen müssen normalerweise nicht angepasst werden.

Einstellung | Beschreibung |
Table Name | Wenn sie eine G6 Appliance in Verwendung haben, müssen sie diesen Wert anpassen. Gehen Sie zuerst im Mindbreeze Management Center auf Telemetry Details Configuration Log Pools Client Service Query Log und kopieren Sie den „Database Table Prefix“. Setzen Sie die Option „Table Name“ im PersonalizedRelevanceTransformer auf „<Database Table Prefx>mesclientservicequerylog“ (ohne Anführungszeichen), z.B. „client_service_query_logmesclientservicequerylog“ Standardwert: clientservicequerylogmesclientservicequerylog |
Query Id Column | Standardwert: log:query_id |
User Query Column | Standardwert: query:user_query |
Search User Column | Standardwert: log:username |
Action Column | Standardwert: queryAction:action |
Key Column | Standardwert: queryResultAction:key |
Weight Column | Standardwert: queryResultAction:weight |
FQCategory Column | Standardwert: queryResultAction:fqcategory |
Session ID Column | Standardwert: log:session_id |
Referer Column | Standardwert: log:referer |
Position Column | Standardwert: queryResultAction:position |
Total Count Column | Nur relevant für Reporting Query Logs. Standardwert: query:total_count |
Start Time Column | Nur relevant für Reporting Query Logs. Standardwert: starttime |
Duration Column | Nur relevant für Reporting Query Logs. Standardwert: duration |
Operation Column | Nur relevant für Reporting Query Logs. Standardwert: log:operation |
Scrollposition in Percentage Column | Nur relevant für Reporting Query Logs. Standardwert: queryResultAction:scroll_position_in_percentage |
Duration in ms Column | Nur relevant für Reporting Query Logs. Standardwert: queryResultAction:duration_in_ms |
Appendix
Analyse-Servlets
Folgende Servlets stehen zur Verfügung. Diese können über https://<appliance-hostname>:8443/index/<transformer-bind-port>/<path> abgeholt werden (z.B. https://myappliance:8443/index/8989/api/boostings?application=default).
GET (HTML Servlets via Browser)
Pfad | Beschreibung |
/api oder | HTML-Seite, die Links auf die anderen Servlets zur Verfügung stellt |
/api/boostings | Gibt eine HTML-Tabelle zurück, die alle effektiven cached Boostings enthält (sortiert nach Query, Application, Boosting). Folgende HTTP Query-Parameter können angegeben werden:
|
/api/boostings/refresh | Erneuert den Boosting Cache. Der Cache wird regelmäßig automatisch erneuert, je nachdem, was in Option „Boosting Data Cache Refresh Interval Seconds“ konfiguriert ist. Folgende HTTP Query-Parameter können angegeben werden, um Config-Options für den Cache Refresh zu überschreiben:
|
/api/queries | Gibt eine HTML-Tabelle zurück, welche Queries wie oft abgesetzt wurden (sortiert nach Anzahl, absteigend). Folgende HTTP Query-Parameter können angegeben werden:
|
/api/actions | Gibt eine HTML-Tabelle zurück, die für jedes Dokument angibt, wie viele Benutzeraktionen durchgeführt wurden (pro Query ID wird maximal eine Aktion pro Dokument gezählt). Außerdem werden Statistiken zur Position der Dokumente in den Suchresultaten und zu den Boostings geliefert. Um die detaillierten Boostings und Queries zu erhalten, wird ein Link auf /api/boosting geliefert. Folgende HTTP Query-Parameter können angegeben werden:
|
/api/referers | Gibt eine HTML-Tabelle zurück, welche alle Referer (URL, von denen eine Suche abgesetzt wurde), zu welche Application Definition diese gehören und wie oft eine Suche ausgeführt wurde. Folgende HTTP Query-Parameter können angegeben werden:
|
/api/voteboostings | Gibt eine HTML-Tabelle zurück, die alle effektiven cached Vote Boostings enthält (sortiert nach Boosting, FQCategory, Application). Folgende HTTP Query-Parameter können angegeben werden:
|
POST
Pfad | Beschreibung |
Boostings können als Binärdatei exportiert werden, um anschließend mithilfe des Import-Servlets wieder importiert zu werden. Dieses Servlet kann für Backups oder Producer-Consumer Setups verwendet werden. Genau einer der folgenden HTTP Query-Parameter muss angegeben werden:
| |
/api/boostings/import | Der mit dem Export-Servlet abgelegte Boosting-Cache kann mithilfe dieses Servlets wieder importiert werden. Bei jedem Import und Refresh wird zusätzlich automatisch ein Export in /data/currentservices/launchedservice-<service-name>/data/export/<uuid> abgelegt, der mithilfe des „uuid“-URL-Parameters wieder importiert werden kann. Genau einer der folgenden HTTP Query-Parameter muss angegeben werden:
|
api/boostings/clear | Boosting- und Servelt-Caches können gelöscht werden. Mithilfe von GET /api/boostings/refresh können diese Caches wieder aufgebaut werden. |
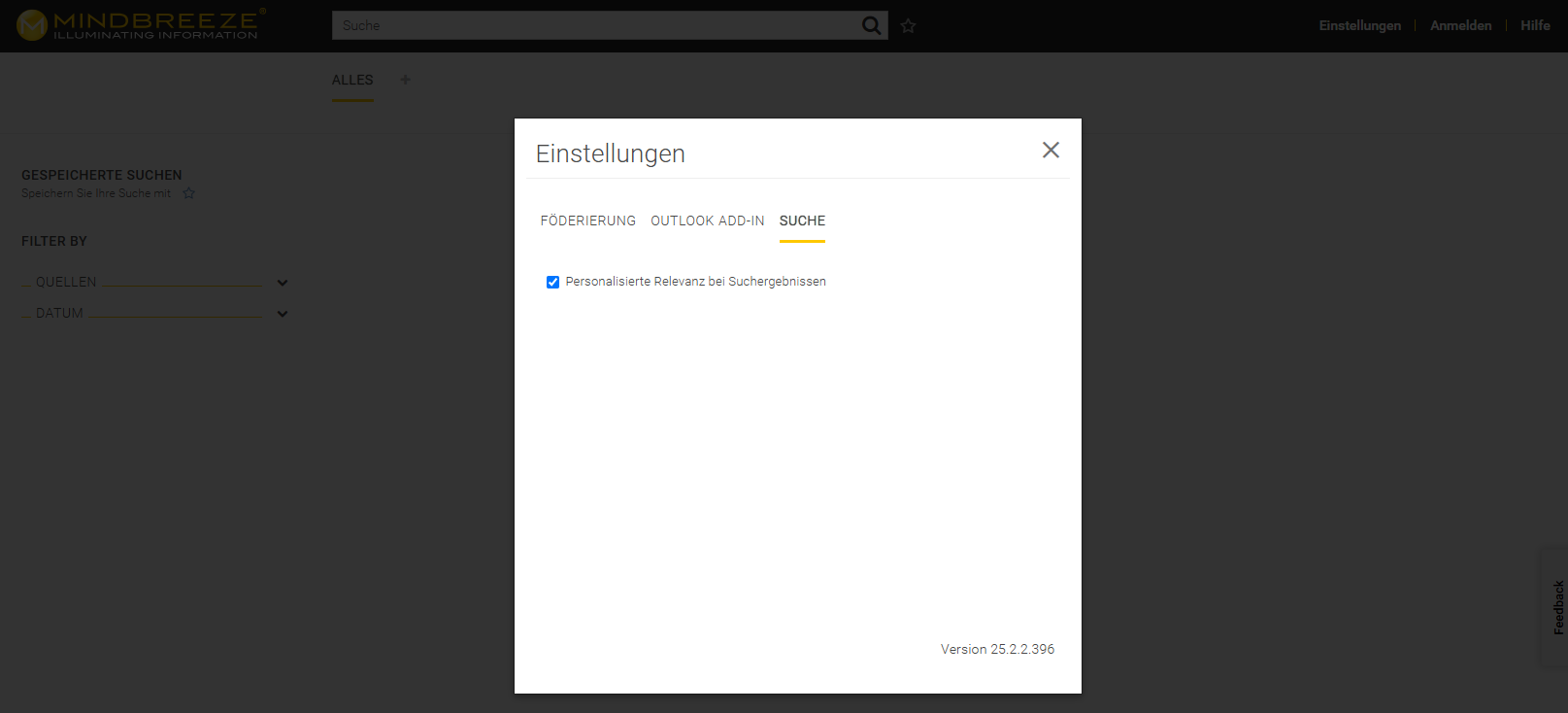
Ein- und Ausschalten der Personalisierung im Search Client
Auf Ihrem Search Client können Sie unter „Einstellungen“ -> „Suche“ mit der Option „Disable personalized search relevance“ den PersonalizedRelevanceTransformer für Ihre Suchen deaktivieren. Beachten Sie, dass diese Einstellung nicht gespeichert wird und bei einem Neuladen der Seite verloren geht.

Relevanzberechnung im Search Client
Um zu überprüfen, wie stark sich das Boosting der personalisierten Relevanz auswirkt, kann im Search Client der URL-Query-Parameter „relevance-info=true“ verwendet werden. Das Boosting des Plugins fließt in die Spalte „Document Boost (%)“ ein.