
Sure, you can handle it. But should you?
Let our experts manage the tech maintenance while you focus on your business.
Let our experts manage the tech maintenance while you focus on your business.
Installation und Konfiguration
Web Connector
Video Tutorial „Set up a basic Web Connector“
Dieses Video beschreibt, wie Sie einen einfachen Web Connector konfigurieren, um eine Website mit oder ohne Sitemap zu indizieren: https://www.youtube.com/watch?v=-Le3J0NOoMI
Konfiguration von Mindbreeze
Konfiguration von Index und Crawler
Klicken Sie auf das „Indices“-Tab und danach auf das „Add new index“-Symbol, um einen neuen Index zu erstellen.
Geben Sie den Indexpfad ein, z.B. „C:\Index“. Passen Sie gegebenenfalls den Display Name des Index Service und des zugehörigen Filter Service an.

Fügen Sie eine neue Datenquelle mit dem Symbol „Add Data Source“ rechts unten ein.
Wenn nicht bereits ausgewählt, selektieren Sie „Web“ bei der Schaltfläche „Category“ aus.
Über die Einstellung „Crawler Interval“ konfigurieren Sie die Zeitspanne, die zwischen zwei Indizierungsdurchläufen gewartet wird.
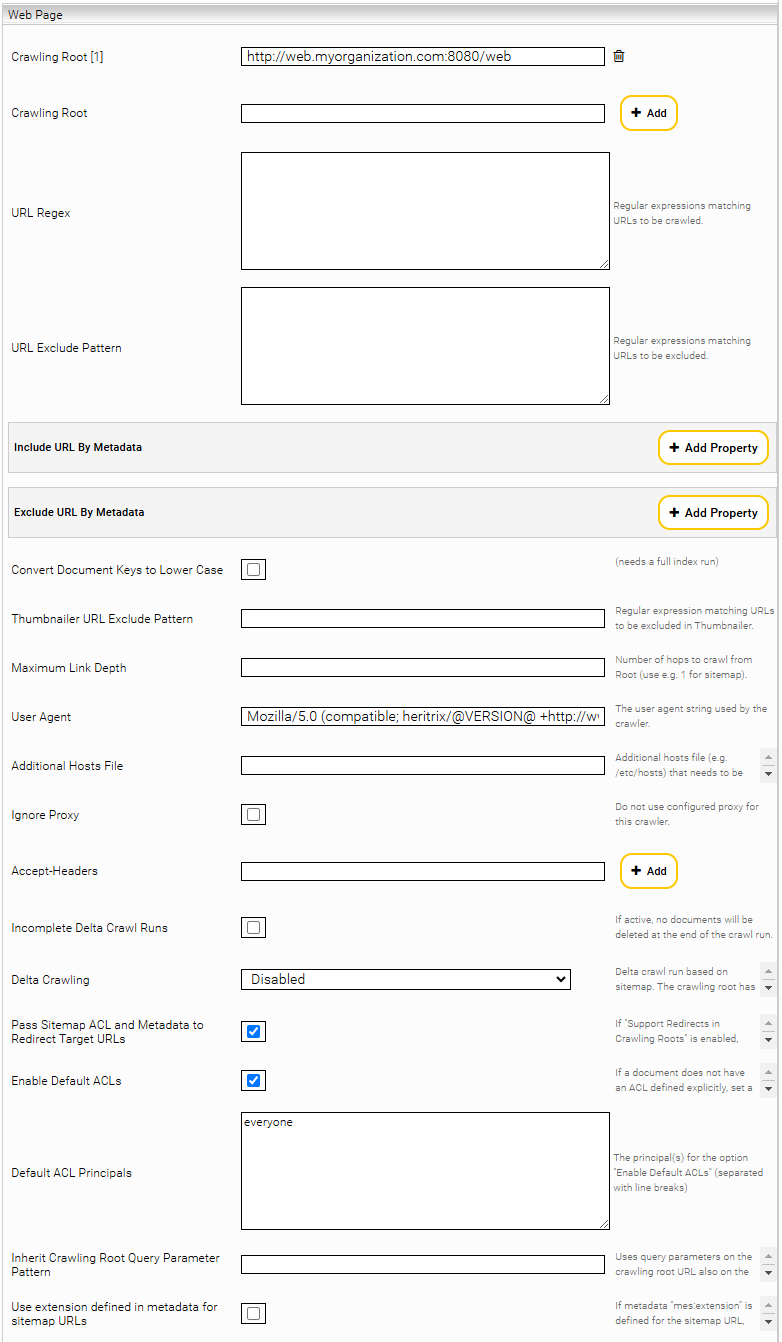
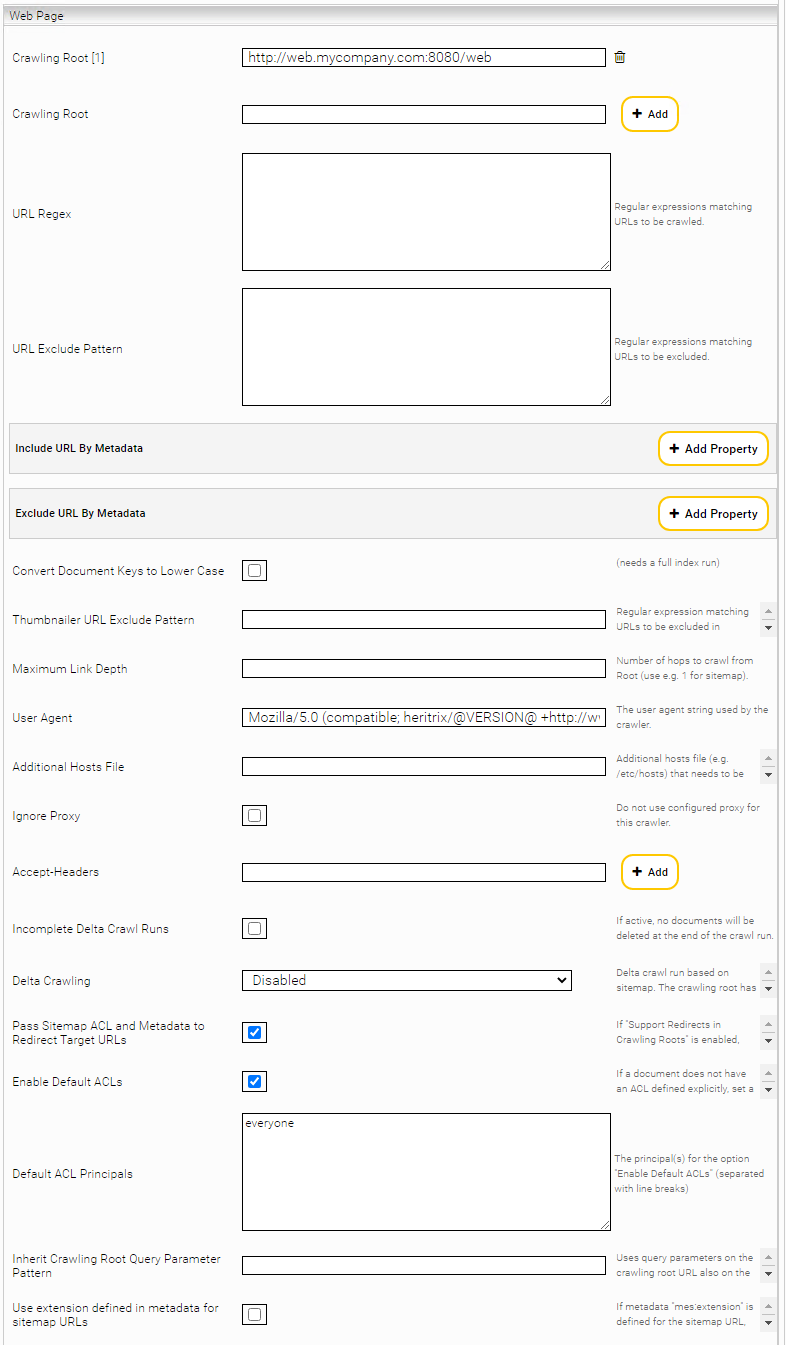
Web Page
Im Feld „URL Regex” können Sie einen regulären Ausdruck bestimmen, der ein Muster für die Links, die indiziert werden sollen, vorgibt. Wenn Sie das Feld leer lassen, werden alle Seiten mit dem gleichen Host- und Domain-Teilen wie die „Crawling Root“ indiziert (z.B. de.wikipedia.org bei „Crawling Root“ http://de.wikipedia.org). Es können mehrere Crawling Roots demselben Crawler hinzugefügt werden.
Sollen bestimmte URLs vom Crawlen ausgenommen werden, so können diese mit einem regulären Ausdruck unter „URL Exclude Pattern“ konfiguriert werden. Dieser muss auf die gesamte URL (inc. URL Parameter) zutreffen.
Mit der Option „Include URL By Metadata“ bzw. „Exclude URL by Metadata“ können beim Crawlen mit Sitemaps, gewisse Seiten anhand der Metadaten in der Sitemap ausgenommen werden. Das Feld „Metadata Name“ spezifiziert den Namen des Metadatums und das Feld „Pattern“ den regulären Ausdruck, gegen den der Wert des Metadatums gematcht wird.
Werden „URL Regex“, „URL Exclude Pattern“ und „Include/Exclude URL by Metadata“ gleichzeitig verwendet, wird zuerst „URL Regex“ angewendet, dann die Seiten mit „URL Exclude Pattern“ ausgeschlossen und letztendlich die restlichen Seiten mit „Include/Exclude URL by Metadata“ gefiltert.
Mit „Convert Document Keys to Lower Case“ Option werden die Dokumentschlüssel (header/mes:key) für alle Dokumente auf Kleinschrift konvertiert.
Mit „Maximum Link Depth“ kann die Verschachtelungstiefe beim Extrahieren von Folgeseiten eingestellt werden. Der Wert „1“ wäre beispielsweise für eine Sitemap geeignet.
Sollte aus netzwerktechnischen Gründen die DNS-Auflösung bestimmter Webserver nicht klappen, kann man mit dem „Additional Hosts File“ die IPs vorgeben.
Möchte man bestimmte HTTP Header hinzufügen (beispielsweise Accept-Language), so kann man das über die „Accept Headers“ einstellen.
Wenn die Option „Incomplete Delta Crawl Runs“ aktiviert ist, bleiben nach dem Crawl Run auch die Seiten im Index, die von der „Crawling Root“ aus nicht mehr erreichbar sind. Um die Anzahl der Anfragen an den Web Server bei Deltaindizierungsläufen gering zu halten, besteht die Möglichkeit eine Seite, die nur Links zu geänderten Seiten enthält, als „Crawling Root“ zu konfigurieren.
ACHTUNG: Die Option „Incomplete Delta Crawl Runs“ darf nicht für Sitemap Delta Crawling verwendet werden. Siehe dafür „Sitemap basiertes Crawlen“.
Wenn ein regulärer Ausdruck als „Enforce Extension from URL if Matches“ Parameter gesetzt ist, wird für Dokumente mit passenden URL-s die Erweiterung aus der URL abgeleitet anstatt vom „Content-Type“ http Header.
Für den Fall, dass Web Dokumente keine ACLs besitzen, können ACLs folgendermaßen hinzugefügt werden:
- Definition der ACLs mit dem Tag „<mes:acl>“
- Aktivierung der Einstellung „Enable Default ACLs“ und Definition der ACLs in „Default ACL Principals“
- Die Einstellung „Enable Default ACLs“ ist standardmäßig aktiviert und fügt die ACLs hinzu, die in der Einstellung „Default ACL Principals“ definiert sind. Mithilfe von Zeilenumbrüchen ist die Definition von mehreren ACLs in „Default ACL Principals“ möglich. Ist kein „Default ACL Principals“ definiert, wird standardmäßig das ACL „everyone“ dem Web Dokument hinzugefügt.
Hinweis: Beachten Sie, dass die gleichzeitige Verwendung des „<mes:acl>“-Tags und der Einstellungen „Enable Default ACLs“ und „Default ACL Principals“ nicht möglich ist, da sich beide Optionen gegenseitig aufheben:
- ACLs, die mit dem „<mes:acl>“-Tag zur Sitemap des Dokumentes hinzugefügt werden, können nicht mit den „Default ACL Principals“ kombiniert werden.
- „Default ACL Principals“ werden ausschließlich bei Web Dokumenten hinzugefügt, die keine ACLs in der Sitemap besitzen (zum Beispiel durch den „<mes:acl>“-Tag).
Mit der Option „Inherit Crawling Root Query Parameter Pattern” können URL Query Parameter vom Crawling Root an die Kinder URLs vererbt werden. Der Anwendungsfall sind beispielsweise Webseiten, die je nach Query Parameter unterschiedlichen Inhalt liefern. Z.B. folgende Crawling Roots https://mysite.com/events?location=us und https://mysite.com/events?location=de liefern unterschiedliche Inhalte. Ebenso liefern Kinderseiten unterschiedliche Inhalte: https://mysite.com/events/sponsored?location=us und https://mysite.com/events/sponsored?location=de Damit der Query Parameter location, der von der Crawling Root kommt, auch auf die Kinderseiten angewendet wird, muss die Option „Inherit Crawling Root Query Parameter Pattern” auf den Wert location gesetzt werden. Der Wert kann ein beliebiger regulärer Ausdruck sein, der gegen die Query Parameter Namen gematcht wird. Falls eine Kindseite bereits gleichnamige Query Parameter gesetzt hat, werden diese von dem Crawling Root Query Parameter überschrieben.
Die Option „Max Document Size (MB)“ setzt die maximal erlaubte Dateigröße eines Dokuments. Der Standardwert ist 50. Wenn ein Dokument größer ist als dieser Wert, dann wird das Dokument abgeschnitten. Ein Wert von 0 bedeutet, dass keine maximale Dateigröße gesetzt ist.
Mit der Option „Process Canonical Link“ können Sie einen regulären Ausruck definieren, der bestimmt, für welche URLs versucht werden soll die URL aus dem „canonical“ Tag zu lesen und als Indizierungschlüssel und URL Metadatum zu setzen.
Mit der Option „Encode Canonical Links“ können Sie bestimmen, ob die URLs, die aus dem „canonical“-Tag extrahiert werden, encoded werden sollen bevor sie im Index gespeichert werden. Um sicherzustellen, dass dieses Setting korrekt übernommen wird, empfehlen wir den Index zu cleanen und neu zu indizieren. Dies ist nützlich, da die URLs dann im gleichen Format im Index gespeichert werden, wie wenn man sie aus dem Browser kopiert, da dieser die URLs meistens automatisch encoded.
HTTP Protocol Version
Mit der Einstellung „HTTP Protocol Version“ können Sie das HTTP-Protokoll auswählen, das für den Abruf der Webseiten verwendet werden soll.
Standardmäßig wird HTTP/1.0 verwendet. Eine Änderung dieser Einstellung wirkt sich lediglich auf die Protokollversion im HTTP-Request aus und nicht auf die verfügbaren Funktionen oder die Performance.
Diese Einstellung sollte geändert werden, wenn der Zielserver HTTP/1.0 blockiert oder wenn der Response für HTTP/1.1 anders ist.
![]()
Skip Up-to-date Documents
Wenn diese Option aktiviert ist, wird ein Dokument nur dann vollständig verarbeitet (Inhalt extrahiert, auf inhaltliche Änderungen überprüft, etc.), wenn sich seit dem letzten Crawl-Run entweder mes:date (siehe hier) oder die Zugriffsinformationen geändert haben.
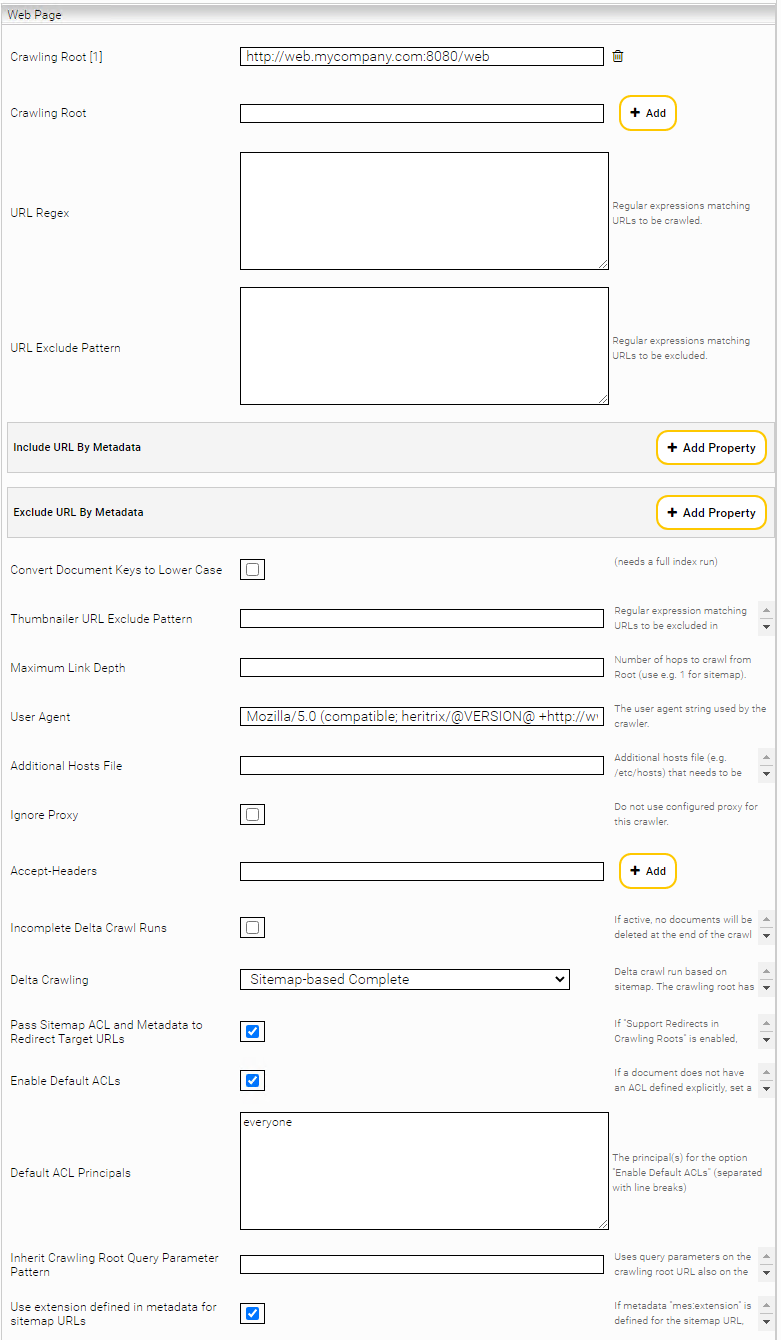
Sitemap basiertes Crawlen
Um Sitemaps gemäß dem Sitemaps.org Protokoll zu verwenden, aktivieren Sie “Delta Crawling” und geben Sie die zentrale Sitemap Ihrer Webseite als Crawling Root an.
In diesem Modus liest der Connector die Webseiten exklusiv aus den Sitemaps aus. Hier werden sowohl die lastmod als auch die changefreq Eigenschaften der Seiten der Sitemap mit den indizierten Seiten verglichen. Mittels einer präzisen Sitemap können sehr hochfrequente Indizierungsstrategien angewendet werden.
Für den „Sitemap-based Delta Crawling“ Modus sind zwei Optionen verfügbar:
- „Sitemap Based Incomplete“: die URLs von den konfigurierten Sitemaps sind indiziert, die schon indizierten Dokumente die nicht in den Sitemaps enthalten sind bleiben im Index.
- „Sitemap Based Complete“: die URLs von den konfigurierten Sitemaps sind indiziert, die schon indizierten Dokumente die nicht in den Sitemaps enthalten sind werden gelöscht.
Wenn die Option „Pass Sitemap ACL and Metadata to Redirect Target URLs“ Option aktiv ist und http Redirects in Root URLs erlaubt sind, werden die Sitemap Metadaten und ACLs auch für die Redirect Ziel URL-s übernommen.
Mit der „Use Stream Parser“ Option wird ein Stream Parser verwendet für die Bearbeitung der Sitemaps. Diese Option ist für Sitemaps mit sehr viele URLs geeignet.
![]()
Mit der „Use extension defined in metadata for sitemap URLs“ Option, wenn der Metadatum „mes:extension“ gesetzt ist für ein Sitemap URL, wird der als File Extension übernommen.
![]()
Die Option „Sitemap Metadata Prefix“ stellt allen aus der Sitemap extrahierten Metadaten den konfigurierten Prefix voran.
![]()
Falls ein Delta Crawling Modus ausgewählt ist, können auch Sitemaps im lokalen Dateisystem indiziert werden. Dazu muss im Crawling Root eine File-URL angegeben werden. Es sind nur File-URLs im Verzeichnis „data“ zulässig. Z.B.: file:///data/sitemap.xml.
Mindbreeze-Erweiterung des Sitemaps.org Protokolls
Mit dem Sitemaps.org Protokoll können Web-Sites in einer Sitemap definiert werden, die gecrawlter werden sollen, z.B.:
<?xml version="1.0" encoding="UTF-8"?>
<urlset xmlns="http://www.sitemaps.org/schemas/sitemap/0.9">
<url>
<loc>http://www.example.com/</loc>
<lastmod>2005-01-01</lastmod>
<changefreq>monthly</changefreq>
<priority>0.8</priority>
</url>
</urlset>
Um zusätzliche Metadaten und ACLs zu definieren, gibt es eine Mindbreeze-Erweiterung. Folgende XML-Tags sind zusätzlich verfügbar:
XML-Tag | Optional/Erforderlich | Beschreibung |
<mes:meta> | optional | Kann mehrfach innerhalb eines <url> Tags definiert werden, um Metadaten zu definieren. Folgende Attribute sind verfügbar:
|
<mes:value> | erforderlich | Kann mehrfach innerhalb eines <mes:meta> Tags definiert werden, um einen oder mehrere Werte für ein Metadatum zu definieren
Hinweise:
|
<mes:annotated> | optional | Kann mehrfach innerhalb eines <mes:meta>-Tags definiert werden, um einen oder mehrere annotierte Werte für ein Metadatum festzulegen. |
<mes:value> | erforderlich | Muss einmal innerhalb eines <mes:annotated>-Tags definiert werden, um den Wert zu definieren, der annotiert wird. Für annotierte Werte werden nur String-Werte unterstützt. |
<mes:ctx-annotation> | optional | Kann mehrfach innerhalb eines <mes:annotated>-Tags definiert werden, um dem Wert Annotationen hinzuzufügen. Die folgenden Attribute sind verfügbar:
|
<mes:ref-annotation> | optional | Kann mehrfach innerhalb eines <mes:annotated>-Tags definiert werden, um den Metadaten Referenzannotationen hinzuzufügen. Das folgende Attribut ist verfügbar:
|
optional | Kann innerhalb eines „<mes:meta>“-Tags verwendet werden, um ACLs zu definieren. Bitte beachten Sie außerdem, dass ACLs aus Sitemaps nicht gemeinsam mit „Access Check Rules“ verwendet werden können. | |
<mes:grant> | optional | Kann mehrfach innerhalb eines <mes:acl> Tags definiert werden, um den Zugriff für ein Principal zu gewähren |
<mes:deny> | optional | Kann mehrfach innerhalb eines <mes:acl> Tags definiert werden, um den Zugriff für ein Principal zu verbieten |
<mes:require> | optional | Kann mehrfach innerhalb eines <mes:acl> Tags definiert werden, um zu definieren, in welchen Gruppen ein User sein muss. <mes:require> gewährt grundsätzlich keinen Zugriff, aber verbietet den Zugriff, wenn der User nicht in der Gruppe ist. Somit ist zusätzlich nach dem letzten <mes:require> Tag ein <mes:grant> Tag notwendig, um Zugriff zu gewähren. |
Beispiel:
<?xml version="1.0" encoding="UTF-8" ?>
<urlset xmlns="http://www.sitemaps.org/schemas/sitemap/0.9"
xmlns:xsi="http://www.w3.org/2001/XMLSchema-instance"
xsi:schemaLocation="http://www.sitemaps.org/schemas/sitemap/0.9
http://www.sitemaps.org/schemas/sitemap/0.9/sitemap.xsd"
xmlns:mes="tag:mindbreeze.com,2008:/indexing/interface">
<url>
<loc>https://www.mindbreeze.com</loc>;
<lastmod>2020-08-22T09:03:56+00:00</lastmod>
<!-- additional metadata -->
<mes:meta key="breadcrumb">
<mes:value>Mindbreeze</mes:value>
<mes:value>Home</mes:value>
</mes:meta>
<mes:meta key="keywords" aggregatable="true">
<mes:value>Search Appliance</mes:value>
<mes:value>InSpire</mes:value>
<mes:value>Semantic Search</mes:value>
<!-- more -->
</mes:meta>
<mes:meta key="parent">
<mes:annotated>
<mes:value>Main parent</mes:value>
<mes:ctx-annotation metakey="related" aggregatable="false">Fabasoft</mes:ctx-annotation>
<mes:ref-annotation metakey="parentkey">abcd.1.2.3.4</mes:ref-annotation>
</mes:annotated>
</mes:meta>
<!-- ACL -->
<mes:acl>
<mes:require>cn=domain users,cn=users,dc=myorganization,dc=com</mes:require>
<mes:deny>unauthorized</mes:deny>
<mes:grant>cn=marketing,cn=users,dc=myorganization,dc=com</mes:grant>
</mes:acl>
</url>
</urlset>
Default Content Type
![]()
Mit dem „Default Content Type“ Option kann der MIME-Typ für alle Dokumente gesetzt werden, bei denen kein MIME-Typ von der HTTP-Antwort gelesen werden kann.
Resource Parameters
Dieser Abschnitt ist nur sichtbar, wenn der Modus "Advanced Settings" auf der Registerkarte "Indices" aktiviert ist.

Einstellung | Beschreibung |
Memory Profile | Das InSpire-Profil ist Standard, bei Bedarf kann auch das ressourcenschonende InSite-Profil verwendet werden. |
Number of Crawler Threads | Die Anzahl der Threads, welche die Webseite(n) parallel crawlen. |
Minimum Request Interval | Mindestverzögerung in Millisekunden zwischen aufeinanderfolgenden Anfragen des Crawlers. |
Maximum Request Interval | Maximale Verzögerung in Millisekunden zwischen aufeinanderfolgenden Anfragen des Crawlers. |
Crawler Queue Size | Maximale Anzahl der Dokumente in der Warteschlange, die an den Index gesendet werden. |
Mindbreeze Dispatcher Thread Count | Die Anzahl der Threads, die parallel Daten an den Index senden. |
Allowed Delete Ratio | Maximal zulässiger Anteil der zu löschenden Dokumente im Verhältnis zur Anzahl der Dokumente im Index. Standardwert: 0.8. Dies ist eine Funktion um Datenverlust bei Netzwerkstörungen oder unbeabsichtigten Konfigurationsänderungen zu verhindern. (z.B., wenn in einem Crawl-Run mehr als 0.8 (80%) der Dokumentenmenge gelöscht werden würde, wird der Crawl-Run automatisch abgebrochen um Datenverlust zu verhindern). Achtung: Diese Einstellung ist nur wirksam, wenn die Einstellung „Delta Crawling“ deaktiviert ist. |
General JavaScript Einstellungen
Standardmäßig lädt der Web Connector HTML Dokumente herunter und extrahiert den Inhalt direkt. Falls Webseiten den Inhalt dynamisch mit JavaScript laden, ist der Inhalt nicht im Original-HTML Dokument enthalten. Standardmäßig wird JavaScript ignoriert und daher kann der Inhalt nicht extrahiert werden.
Allgemein
Mit der Einstellung „Enable JavaScript“ können Inhalte von Webseiten, die JavaScript zur Darstellung der Inhalte verwenden, indiziert werden.
Hinweis: Wenn „Enable JavaScript“ aktiviert ist, benötigt der Connector deutlich mehr Ressourcen. Das führt zu langsamerem Crawlen und höherer Speicherverbrauch. Daher wird empfohlen, die Option „Enable JavaScript“ nur bei einem einzigen Crawler zu aktivieren und die JavaScript Verarbeitung mit der Optionen „Include/Exclude JavaScript URL Regex Pattern“ auf nur die URLs einzuschränken, die tatsächlich JavaScript benötigen.
Zum Beispiel sollen die Webseiten https://mysite.com/products und https://mysite.com/internal indiziert werden. https://mysite.com/products benötigt JavaScript, https://mysite.com/internal benötigt kein JavaScript zur Indizierung. In diesem Fall muss „Include JavaScript URL Regex Pattern“ wie folgte konfiguriert werden: https:\/\/mysite\.com\/products\.*
Sicherheitsmechanismen und Sicherheitsausnahmen
Da Webseiten beliebigen JavaScript Code beinhalten können und der Code im Connector ausgeführt wird, werden die aus Webbrowser üblichen Sicherheitsmechanismen, wie Sandboxing und CORS eingesetzt. Weiters sind aus Sicherheitsgründen die Netzwerkschnittstellen des JavaScript Codes stark begrenzt.
Besonders werden nur Netzwerk-Requests auf URLs mit demselben Hostnamen erlaubt. Dies sollte für die meisten Anwendungsfälle kein Problem darstellen. Falls beispielsweise die Seite https://mysite.com/products (Hostname mysite.com) indiziert wird, welche die Seite JavaScript von externen URLs laden soll, z.B. https://ajax.googleapis.com/ajax/libs/angularjs, dann werden die Netzwerk-Requests auf den Hostnamen ajax.googleapis.com blockiert, da dies ein andere Hostname ist. Alle blockierten (und erfolgreichen) Netzwerk-Request werden in der app.telemetry dargestellt. Um dies anzuzeigen, Navigieren Sie dazu im Management Center > Reporting > Telemetry Details > Applications in den “Network Requests” Log Pool. Stellen Sie sicher, dass die Spalten “URL”, “Status” sowie “Status Description“ eingeblendet sind.
Falls externe Netzwerk-Requests unbedingt notwendig sind, um den Inhalt der Webseite anzeigen zu können, ist es möglich Sicherheitsausnahmen mit der Einstellung „Additional Network Resources Hosts“ zu definieren (Advanced Setting). Diese Einstellung kann eine Liste von Hostnamen bestimmen, die auf jeden Fall erlaubt sind. Im Beispiel von oben können Sie bei „Additional Network Resources Hosts“ den Wert ajax.googleapis.com setzen. Damit werden nun auch Netzwerk-Request wie zum Beispiel https://ajax.googleapis.com/ajax/libs/angularjs erlaubt.
Einschränkungen der „Enable JavaScript“ Option
Das Indizieren von Webseiten mit aktivierten „Enable JavaScript“ ist mit diversen funktionalen Einschränkungen verbunden. Aktuell können folgende Features nicht zusammen mit der Option „Enable JavaScript“ verwendet werde:
- Netzwerkproxy mit Authentisierung (User, Password)
- Indizieren von Webseiten mit NTLM oder Kerberos Authentisierung
- Indizieren von Single-Page-Applications (SPA), welche URL-Anchors verwenden
- Indizieren von Webseiten, die eine hohe Anzahl von Ressourcen laden
- Indizieren von Webseiten die 2-Faktor-Authentifizierung verwenden.
Zusätzliche erweiterte Einstellungen
Aktivieren Sie „Advanced Settings“, um alle Einstellungen anzuzeigen:
Einstellung | Beschreibung |
Enable JavaScript | Aktiviert die Verarbeitung von JavaScript (siehe Beschreibung Oben), Warnung: benötigt erhöhte Systemresourcen (Standardwert: deaktiviert) |
Enable Verbose Logging | Aktiviert erweitertes Logging für Diagnosezwecke (Standardwert: deaktiviert) |
Skip Head Requests | Überspringt den HEAD Request, der verwendet wird, um zu ermitteln, ob das JavaScript einer Webseite verarbeitet werden soll. (standardmäßig wird JavaScript nur für Text/HTML ermittelt) |
Include JavaScript URL (regex) | Liste von regulären Ausdrücken, welche die URLs definieren, bei denen JavaScript verarbeitet wird (Standardwert: .*) |
Exclude JavaScript URL (regex) | Liste von regulären Ausdrücken, welche die URLs definieren, bei denen JavaScript nicht verarbeitet wird. Diese Einstellung hat Priorität gegenüber der Einstellung Include JavaScript URL. |
Thumbnail Width | Breite der generierten Thumbnails in Pixel (Standardwert: 100) |
Thumbnail Height | Höhe der generierten Thumbnails in Pixel (Standardwert: 75) |
Browser Width | Breite des Browserfensters, das zum Crawlen verwendet wird. Standardwert: 1024 |
Browser Height | Höhe des Browserfensters, das zum Crawlen verwendet wird. Standardwert: 768 |
Page Load Strategy | Bestimmt mit welcher Strategie Webseiten geladen werden. Dieser Wert ist für interne Verwendung bestimmt und sollte nicht geändert werden. (Standardwert: „Eager“) |
Page Ready State | Bestimmt wie festgestellt wird, ob eine Seite fertig geladen wurde. Dieser Wert ist für interne Verwendung bestimmt und sollte nicht geändert werden (Standardwert: „Complete Or Interactive“) |
Javascript Script Settings
Einstellung | Beschreibung |
Content Selector Type (deprecated) | Gleiches Verhalten wie beim Feld "Content Selector Type". |
Content Presence Selector (deprecated) | Gleiches Verhalten wie beim Feld "Content Presence Selector". |
Assume Content if no Script triggered | Ist diese Einstellung aktiviert, wird davon ausgegangen, dass der Inhalt geladen ist, obwohl kein Script Trigger Selector aktiv ist. Darf nicht zusammen mit Content Presence Selector verwendet werden. |
On New Document Script | Dieses Script wird direkt vor dem Laden einer Seite einmalig ausgeführt. Dies kann hilfreich für Anwendungsfälle sein, bei denen normalen Scripts zu spät ausgeführt werden würden. |
HTTP Authentication Dialog (Hier können Zugangsdaten für Browser-HTTP-Authentifizierungsdialoge konfiguriert werden) | |
Allowed Hostnames | Eine durch Zeilenumbrüche getrennte Liste von Hosts, auf denen die Zugangsdaten verwendet werden dürfen. |
Credential | Das Credential, das gesendet wird, wenn das entsprechende Ereignis ausgelöst wird. |
Content Presence Selector
Beschreibung | |
URL Patterns (regex) | Definiert die Regex-Muster, die mit den URLs von Websites abgeglichen werden. Nur bei einer Übereinstimmung ist der Content Presence Selector wirksam. |
Content Selector Type | Definiert den Typ des Content Presence Selector. Der Standardwert ist CSS. Neben CSS ist auch XPath als Wert möglich. |
Content Presence Selector | Ein CSS- oder XPath-Ausdruck, der verwendet wird, um festzustellen, ob der gesuchte Inhalt vorhanden ist. Darf nicht mit Assume Content if no Script triggered verwendet werden. Muss unbedingt in einfachen Hochkommas (') und nicht in doppelten Hochkommas (") angegeben werden. |
Scripts

Einstellung | Beschreibung |
Script Name | Ein benutzerdefinierter Name für das Skript. (Wird zur Identifizierung in den Logs verwendet) |
URL Patterns (regex) | Das Skript wird nur auf Websites ausgeführt, deren URLs mit den angegebenen Regex-Mustern matchen. Wenn das Feld leer ist, wird es als Ausdruck '.*' interpretiert. |
Script Selector Type | Legt den Typ des 'Content Presence Selector' fest. (Standard: CSS) |
Script Trigger Selector | Ausdruck (CSS oder XPath) zum Auslösen des Scripts. Muss unbedingt in einfachen Hochkommas (') angegeben werden und nicht in doppelten Hochkommas ("). |
Script | Definiert das Skript, das ausgeführt werden soll, wenn der ‘Script Trigger Selector’ aktiv ist. |
Credential Scripts

Einstellung | Beschreibung |
| Ein benutzerdefinierter Name für das Skript (wird zur Identifizierung in den Logs verwendet). |
Allowed Hostnames | Das Skript wird nur auf Seiten ausgeführt, deren Hostname mit einem der angegebenen Hostnamen matcht. Patterns können hier nicht verwendet werden. |
Script Selector Type | Legt den Typ des “Content Presence Selector” fest. Der Standardwert ist CSS. |
Script Trigger Selector | Ausdruck zum Auslösen des Skripts, definiert in CSS oder XPath. Muss unbedingt in einfachen Hochkommas (') und nicht in doppelten Hochkommas (") angegeben werden. |
Script | Definiert das auszuführende Skript, wenn der Script Trigger Selector gefunden wird. Im Gegensatz zu normalen Scripts, kann hier ein bereitgestelltes Objekt 'mesCredential' verwendet werden. Dieses besitzt die Variablen 'domain', 'username' und 'password', die je nach ausgewähltem Credential definiert werden. let password = mesCredential.password; let username = mesCredential.username; let domain = mesCredential.domain; |
Credential | Hier kann ein beliebiges Credential vom 'Netzwerk'-Tab ausgewählt werden, das dann im Skript verwendet wird. Derzeit werden nur Credentials vom Typ "Passwort" und "Benutzername/Passwort" unterstützt. |
HTTP Authentication Dialog Handling
Einstellung | Beschreibung |
Allowed Hostnames | Eine durch Zeilenumbrüche getrennte Liste von Hosts, auf denen die Zugangsdaten verwendet werden dürfen. |
Credential | Das Credential, das gesendet wird, wenn das entsprechende Ereignis ausgelöst wird. |
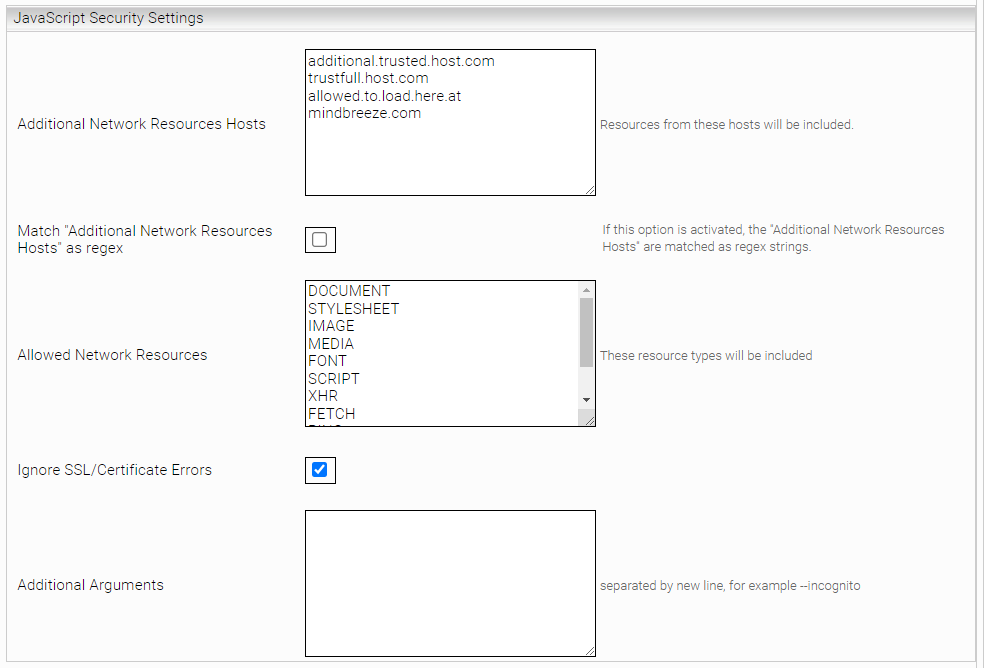
Javascript Security Settings
Einstellung | Beschreibung |
Additional Network Resources Hosts | Liste von Hostnamen, zu denen Netzwerk-Requests erlaubt sind. Patterns können hier nicht verwendet werden, außer wenn Match "Additional Network Resources Hosts" as regex aktiviert ist. |
Match "Additional Network Resources Hosts" as regex | Ist diese Option aktiviert, werden die „Additional Network Resources Hosts“ als Regex-Patterns verwendet. Hierbei muss für jedes Skript mindestens ein URL-Pattern definiert werden. |
Allowed Network Resources | Liste von Netzwerk Ressourcen zu denen Requests erlaubt sind. |
Ignore SSL/Certificate Errors | Wenn aktiv, werden HTTPS SSL oder Zertifikatsfehler ignoriert. Diese Einstellung darf aus Sicherheitsgründen nur in Testsystemen aktiviert werden. |
Additional Arguments | Dieser Wert ist für interne Verwendung bestimmt und sollte nicht geändert werden. (Standardwert: leer) |
JavaScript Performance Settings

Einstellung | Beschreibung |
Page Load Timeout | Zeit in Sekunden, die für das Laden und Ausführen von JavaScript auf einer Webseite erlaubt ist. Falls diese Zeit überschritten wird, wird die Verarbeitung abgebrochen. (Standardwert: 10) Dieser Wert sollte immer kleiner sein als „Network Timeout“ |
Network Timeout | Zeit in Sekunden, die der Konnektor auf eine Antwort von der Website wartet. Dieser Wert sollte immer größer sein als „Page Load Timeout“ (Standardwert: 10) |
Browser Recycle Threshold | Anzahl der Websites, welche mit einer internen Browser-Instanz verarbeitet werden, bevor die Instanz automatisch beendet und neu gestartet wird, um Systemresourcen zu schonen. (Standardwert: 1000) |
Browser Control Process XmX |
Proxy
Im Abschnitt „Proxy“ können Sie einen Proxy Server eintragen, falls ihre Infrastruktur dies erfordert. Tragen Sie dazu den Computernamen und den Port des Proxy-Servers in „Proxy Host“ und „Proxy Port“ ein.
Der Web Connector kann sich am Proxy auch mittels HTTP-BASIC anmelden. Tragen Sie in das Feld „Proxy User“ den Benutzer und in „Proxy Password“ das zugehörige Passwort ein, wenn die Verbindungen über einen Proxy mit Authentifizierung erfolgen sollen.

Authentisierung
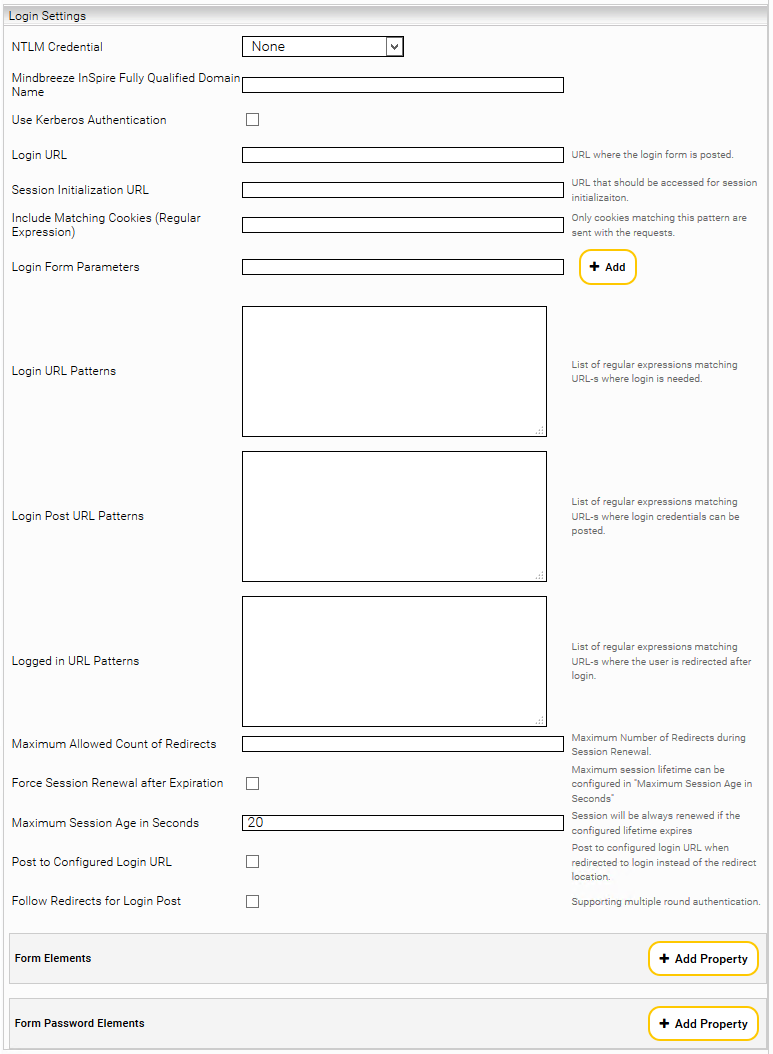
In diesem Kapitel werden die verschiedenen Authentisierungsmethoden für den Web Connector beschrieben. Das Kapitel beleuchtet dabei jene Methoden die verwendet werden können, um Inhalte, die sich hinter einem Login befinden, indizieren zu können.
Formularbasiertes Login
Dieser Abschnitt beschäftigt sich mit dem Mechanismus des formularbasierten Logins. Es handelt sich dabei um einen Mechanismus der einen Login über ein Login Formular und eine Sitzungsverwaltung durch HTTP Cookies durchführen kann.
Formularbasiertes Login simuliert das Benutzerverhalten und Browserverhalten, das notwendig ist, um derartige Logins zu automatisieren.
In diesem Kapitel werden zwei Szenarien beschrieben. Beide Szenarien basieren auf den Einstellungen der nachstehenden Abbildung.

Statisches formularbasiertes Login mit Sitzungsverwaltung
In diesem Szenario wird ein Post-Request an eine bestimmte URL gesendet, um die Authentifizierung auszulösen. Die URL, die dafür verwendet werden soll, wird unter Login URL eingetragen. Diese URL kann zum Beispiel mittels der Debugging-Funktionen des Webbrowsers ermittelt werden. Nachstehend werden die benötigten Optionen erklärt:
Beschreibung | |
Session Initialization URL | In manchen Fällen ist es notwendig ein dynamisch generiertes Cookie von einer bestimmten URL abzuholen und dieses bereits beim formularbasierten Login mitzusenden. Auf die hier eingetragene URL wird ein http-get-request durchgeführt und die so erhaltenen Cookies beim eigentlichen Login mitgesendet. |
Include Matching Cookies (Regular Expression) | Damit kann eingeschränkt werden, welche Cookies für die Sitzungsverwaltung gespeichert werden sollen. In dieses Feld muss ein regulärer Ausdruck eingegeben werden, welcher für die Namen jener Cookies zutrifft, die übernommen und für die Session verwendet werden sollen. |
Follow Redirects for Login Post | Ist diese Option aktiviert, werden nach dem http-post-request auf die Login URL alle Redirects weiterverfolgt und alle Cookies gesammelt bis kein weiterer Redirect mehr angefordert wird oder die Authentifizierung erfolgreich ist. |
Form Elements Form Password Elements | Mit dieser Einstellung müssen die Namen und Werte jener Elemente angegeben werden, die beim http-post-request auf die Login URL verwendet werden. Dabei wird der Name des Feldes des HTML-Formulars angegeben. Alle Passwortfelder müssen unter Password Elements angegeben werden. |
Die weiteren Einstellungen werden für dieses Szenario nicht benötigt.
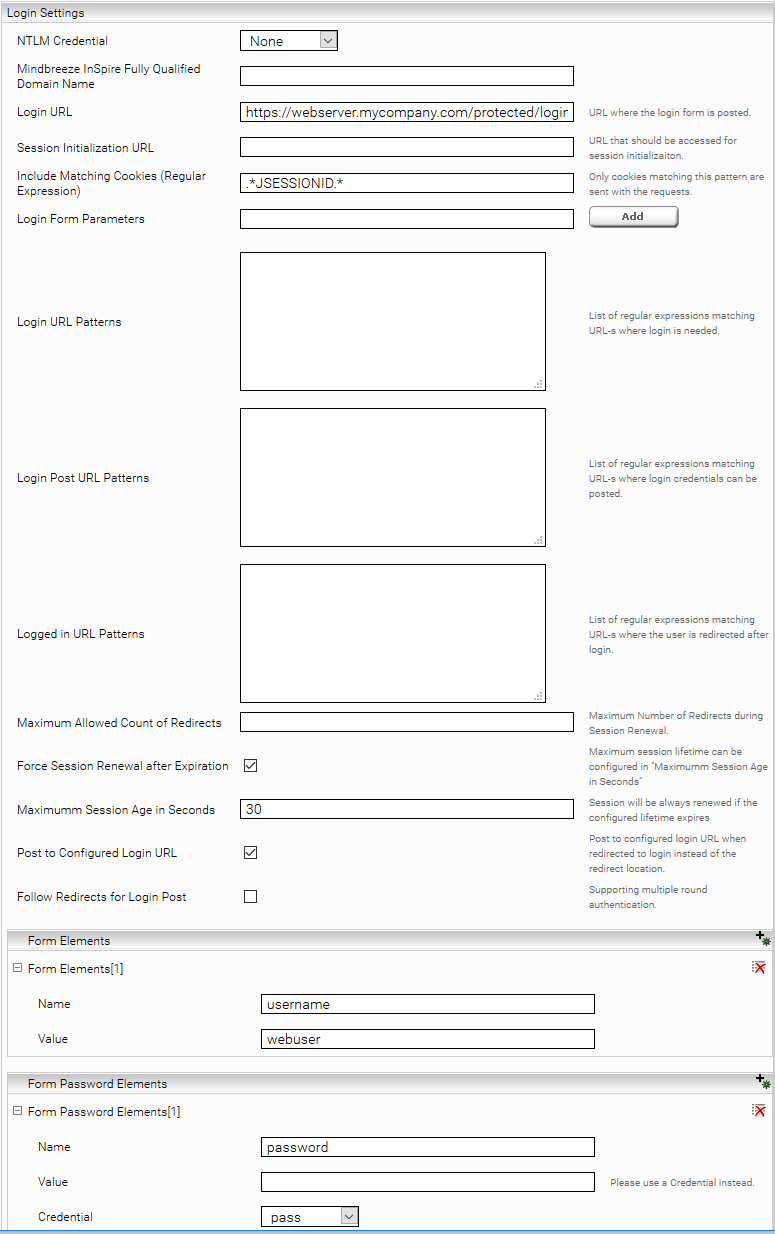
Komplexes formularbasiertes Login
Wenn das vorherige Szenario nicht ausreicht, können folgende Einstellungen verwendet werden:


Beschreibung | |
Session Initialization URL | Diese URL wird zu Beginn aufgerufen um danach dynamisch weitergeleitet zu werden. Die dabei erhaltenen Cookies werden für die Session beibehalten. |
Login Form Parameters | Wenn beim Login-Formular versteckte Felder gesetzt werden, können diese hier aufgelistet werden. Diese werden extrahiert und beim Login-Request mitgesendet. Ein typisches Beispiel dafür ist die dynamisch generierte FormID, die als hidden Parameter vom Webserver zurückgesendet wird. |
Login URL Patterns | Alle Redirects, die den hier angegebenen regulären Ausdrücken entsprechen, werden beim Loginvorgang verfolgt |
Login Post URL Patterns | Beim Folgen von Redirects, die den hier angegebenen regulären Ausdrücken entsprechen, werden alle gesammelten Formularparameter mittels http-post-request mitgesendet. |
Logged in URL Patterns | Wird auf eine URL weitergeleitet, die den hier angegebenen regulären Ausdrücken entspricht, dann gilt der Loginvorgang als erfolgreich. |
Maximum Allowed Count of Redirects | Hiermit kann die maximale Tiefe der verfolgten Redirects festgelegt werden. |
Post to Configured Login URL | Ist diese Option gesetzt, so werden Weiterleitungen an eine „Login Post URL“ mit einem http-post-request an die unter „Session Initialization URL“ konfigurierte URL ersetzt. |
Reset Session Before Login | Ist diese Option gesetzt, werden beim Ablaufen einer Session nicht die alten Sessioncookies zum Erstellen einer neuen Session verwendet. |
Force Session Reneval After Expiration | Ist diese Option gesetzt wird die Login Prozess immer neu ausgeführt wenn die Sitzung älter ist als die konfigurierte Maximum Session Alter (Maximum Session Age in Seconds). Die Option funktioniert nur wenn „Post to Configured Login URL“ aktiv ist. |
Maximum Session Age in Seconds | Maximum Session Alter in Sekunden. |
NTLM
Um NTLM Authentisierung zu verwenden, müssen zuerst User, Passwort und Domain im Network Tab als Credential konfiguriert werden:

Danach muss dieses Credential im Web Connector bei der Einstellung „NTLM Credential“ ausgewählt werden:

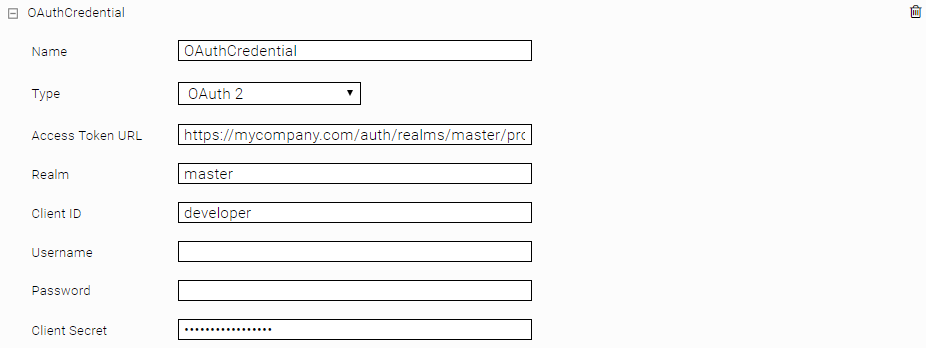
OAuth2
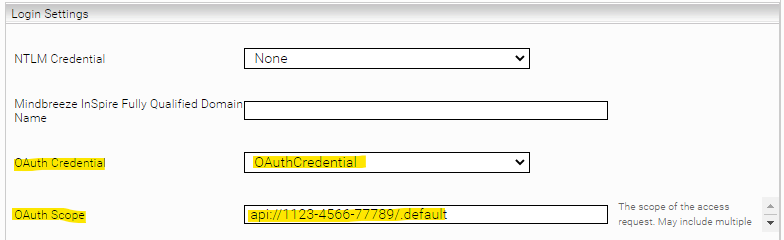
Um OAuth Authentisierung zu verwenden, muss ein Credential vom Typ OAuth2 im Network Tab erstellt werden:

Für den Grant-Type Client Credentials reicht es aus, Realm, Client ID und Client Secret zu konfigurieren. Für den Grant-Type Password müssen zusätzlich auch noch Username und Password konfiguriert werden.
Danach muss dieses Credential im Web Connector bei der Einstellung „OAuth Credential“ ausgewählt werden:
Mit der Einstellung „OAuth Scope“ können bestimmte Berechtigungen für die OAuth Authentifizierung angefordert werden.
Authorization Basic Header
Die Basic Authentication (Basisauthentifizierung) nach RFC 2617 ist die häufigste Art der HTTP-Authentifizierung. Der Webserver fordert mit
WWW-Authenticate: Basic realm="RealmName"
eine Authentifizierung an, wobei RealmName eine Beschreibung des geschützten Bereiches darstellt. Der Browser sucht daraufhin nach Benutzername/Passwort für diese URL und fragt gegebenenfalls den Benutzer ab. Anschließend sendet er die Authentifizierung mit dem Authorization-Header in der Form Benutzername:Passwort Base64-codiert an den Server.
Beispiel:
Authorization: Basic d2lraTpwZWRpYQ==
Um den im obigen Beispiel angegebenen Header einzustellen, muss dieser in der Option HTTP Request Header wie im nachstehenden Screenshot ersichtlich konfiguriert werden:
Kerberos Authentication
Die Kerberos Authentication verwendet das Negotiate-Protokoll zur Authentifizierung der HTTP-Anfragen. Der Web Connector ist somit in der Lage, Webseiten zu indizieren, die nur mit Kerberos Authentifizierung erreichbar sind. Folgende Schritte sind notwendig, um die Kerberos Authentication zu aktivieren:
- Ein funktionierendes Kerberos Setup auf der Appliance sicherstellen. Dazu siehe Kerberos Authentfizierung
- Einen „Connector“ Keytab generieren und dem Web Connector zuweisen. Siehe Connector Authentifizierung Kerberos
- In den Web Connector Einstellungen die Option „Use Kerberos Authentication“ aktivieren.
Hinweis: Aktuell werden mit Kerberos keine Web-Thumbnails unterstützt, diese werden automatisch deaktiviert.
Content Extraction
Seiten von der Indizierung ausnehmen
Mit der Option „URLs Excluded from Filtering“ können mittels eines regulären Ausdrucks bereits gefundene Seiten von der Indizierung ausgenommen werden. Ein möglicher Anwendungsfall ist beispielsweise, wenn man gewisse Seiten indizieren möchte, die nur über Umwege erreichbar sind und man die Umwege selbst nicht Indizieren will. In diesem Fall kann mit „URLs Excluded from Filtering“ ein regulärer Ausdruck angegeben werden, welcher die Umwege ausschließt.
Hier ein Überblick die Optionen, welche die Crawling Richtung beeinflussen:
- „Crawling Root“ bestimmt mit welche URL das crawling gestartet wird
- „URL Regex“ bestimmt, welche URLs weiterverfolgt werden
- „URL Exclude Regex“ bestimmt, welche URLs ausgeschlossen und nicht weiterverfolgt werden
- „URLs Excluded from Filtering“ bestimmt, welche gecrawlten Dokumente schlussendlich indiziert werden
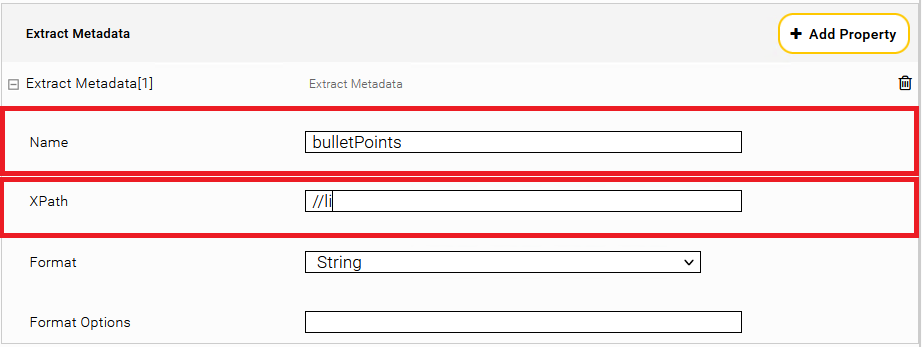
Extract Metadata
Tragen Sie im Abschnitt „Extract Metadata“ als Name: bulletPoints und als XPath: „//li“ ein.
Anschließend neu indizieren.
Filterkonfiguration
Folgende Umgebungsvariablen sind verfügbar:
Cache-Einstellungen für die Erzeugung von Vorschaubildern
Die Variable MES_THUMBNAIL_CACHE_LOCATION legt das Verzeichnis für die Erstellung von Vorschaubildern fest. Die maximale Cache-Größe wird mit der Variable MES_THUMBNAIL_CACHE_SIZE_MB festgelegt. Der Cache wird nur dann verwendet, wenn beide Variablen gesetzt sind.
Beispiel (Linux):
export MES_THUMBNAIL_CACHE_LOCATION=/tmp/thumbcache
export MES_THUMBNAIL_CACHE_SIZE_MB=20
Auf Microsoft Windows Plattformen können diese Variablen in der Systemsteuerung festgelegt werden.
Timeout-Einstellungen für die Erzeugung von Vorschaubildern
Mit der Variable MES_THUMBNAIL_TIMEOUT kann der Standard-Timeout-Wert von 50 Sekunden verändert werden.
Beispiel (Linux):
export MES_THUMBNAIL_TIMEOUT=10
Auf Microsoft Windows Plattformen können diese Variablen in der Systemsteuerung festgelegt werden.
Hauptinhalt extrahieren mit alternativem Filter-Modus
Beim Crawler von z.B. News-Seiten werden auch „unnütze“ Inhalte indiziert, wie Menüs oder Fußzeilen. Der HTML-Filter kann in einen alternativen Modus geschaltet werden, der mit einer Heuristik nur „sinnvolle“ Inhalte indiziert.
Es gibt mehrere Möglichkeiten zur Konfiguration:
Filter Plugin Properties
Klicken Sie auf das „Filters“ Tab und aktivieren Sie „Advanced Settings“.
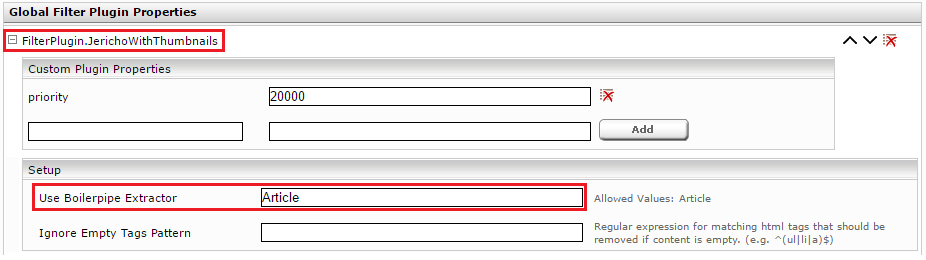
Im Abschnitt „Global Filter Plugin Properties“ wählen Sie „FilterPlugin.JerichoWithThumbnails(…)“ aus und klicken Sie auf „Add“.

Klappen Sie den neuen Eintrag „FilterPlugin.JerichoWithThumbnails“ auf und setzen Sie die Einstellung „Use Boilerpipe Extractor“ auf den Wert „Article“.

Anschließend neu Indizieren.
Datasource XPath Metadata
Klappen Sie den betreffenden Index auf. Im Abschnitt „Data Source“, Unterabschnitt „Extract Metadata“ klicken Sie auf das Plus-Symbol „Add Property“.
Tragen sie im neuen Abschnitt „Extract Metadata“ als Name: htmlfilter:extractor und XPath: "Article" (Wichtig: unter Hochkomma) ein.

Anschließend neu Indizieren.
Leere HTML-Elemente ignorieren
Wenn in Dokumenten leere HTML-Elemente vorkommen, können Sie einen regulären Ausdruck definieren, welcher diese Elemente beim Filtern entfernt.
Es gibt mehrere Möglichkeiten zur Konfiguration:
Filter Plugin Properties
Klicken Sie auf das „Filters“ Tab und aktivieren Sie „Advanced Settings“.
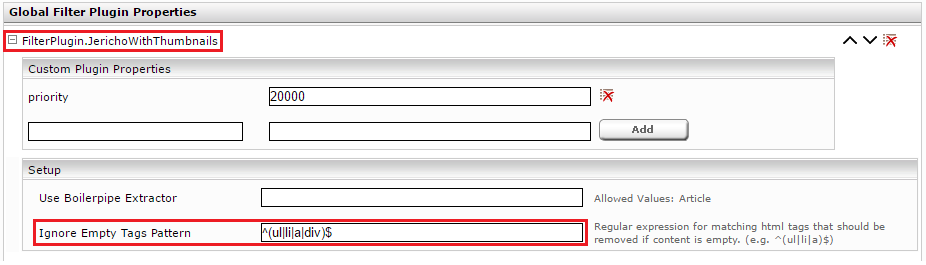
Im Abschnitt „Global Filter Plugin Properties“ wählen Sie „FilterPlugin.JerichoWithThumbnails(…)“ aus und klicken Sie auf „Add“.
Klappen Sie den neuen Eintrag „FilterPlugin.JerichoWithThumbnails“ auf und setzen Sie die Einstellung „Ignore Empty Tags Pattern“ auf z.B. den Wert „^(ul|li|a|div)$“. Dies bedeutet, dass die HTML-Elemente ul, li, a und div entfernt werden, falls diese leer sind.
Anschließend neu Indizieren.
Datasource XPath Metadata
Im Tab „Indices“ aktivieren Sie „Advanced Settings“.
Klappen Sie den betreffenden Index auf. Im Abschnitt „Data Source“, Unterabschnitt „Extract Metadata“ klicken Sie auf das Plus-Symbol „Add Composite Property“.
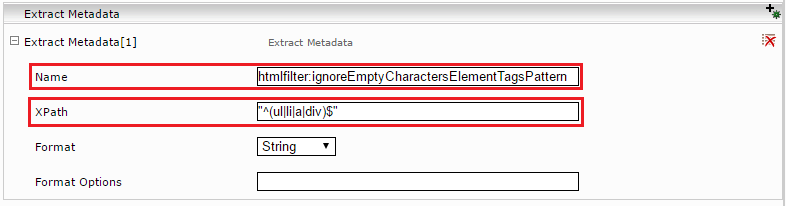
Tragen sie im neuen Abschnitt „Extract Metadata“ als Name: htmlfilter:ignoreEmptyCharactersElementTagsPattern und XPath: "^(ul|li|a|div)$" (Wichtig: unter Hochkomma) ein. Dies bedeutet, dass die HTML-Elemente ul, li, a und div entfernt werden, falls diese leer sind.
Anschließend neu Indizieren.
Googleon/Googleoff Tags anwenden
Die Google GSA definiert einen Mechanismus, um innerhalb einer einzelnen HTML-Website gewisse Teile als „nicht durchsuchbar“ markieren zu können. Diese markierten Teile werden dann nicht indiziert, der Rest der Seite allerdings schon. Die Markierungen sind HTML-Kommentare, die paarweise gesetzt werden.
Unterstützt werden folgende Tags:
Es gibt mehrere Möglichkeiten zur Konfiguration.
Systemweite Verwendung mit Global Filter Plugin Properties
Zum Aktivieren dieser Funktion klicken Sie auf das „Filters“ Tab und klicken Sie auf „Advanced Settings“.
Im Abschnitt „Global Filter Plugin Properties“ wählen Sie „FilterPlugin.JerichoWithThumbnails(…)“ aus und klicken Sie auf „Add“.
Klappen Sie den neuen Eintrag „FilterPlugin.JerichoWithThumbnails“ auf und haken Sie die Einstellung „Apply googleon/googleoff Tags“ an. Anschließend re-indizieren.
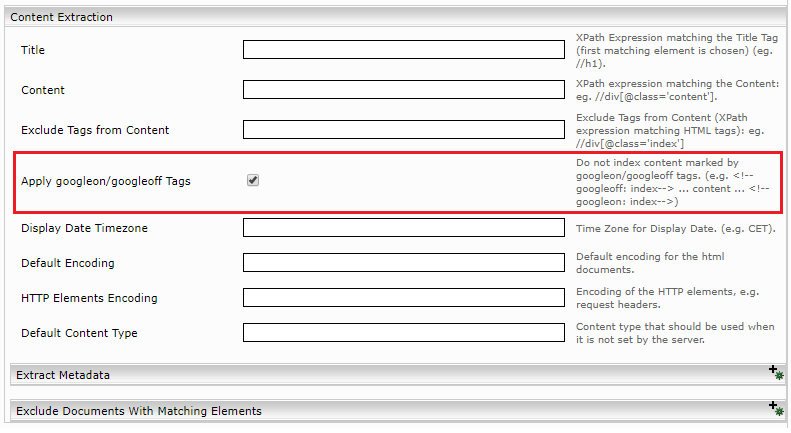
Verwendung im Web-Connector
In den Web-Connector Einstellungen unter der Sektion „Content Extraction“ haken Sie die Einstellung „Apply googleon/googleoff Tags“ an. Anschließend reindizieren.

Crawlerspezifische Verwendung mit Datasource XPath Metadata
Im Tab „Indices“ aktivieren Sie „Advanced Settings“.
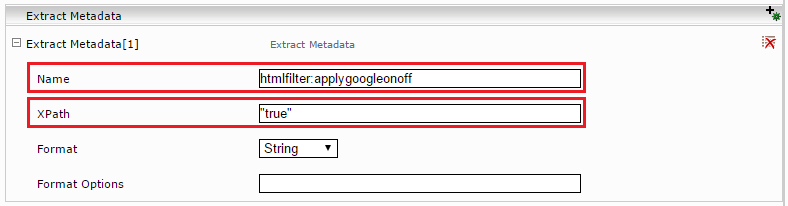
Klappen Sie den betreffenden Index auf. Im Abschnitt „Data Source“, Unterabschnitt „Extract Metadata“ klicken Sie auf das Plus-Symbol „Add Composite Property“.
Tragen sie im neuen Abschnitt „Extract Metadata“ als Name: htmlfilter:applygoogleonoff und XPath: "true" (Wichtig: unter Hochkomma) ein.
Anschließend neu Indizieren.
CDATA Inhalte als Text Extrahieren
Optional kann der Jericho Filter Plugin auch Text Inhalte von HTML CDATA Abschnitte extrahieren. Dieses Feature kann entweder Global für den Filter Service, oder pro Dokument mit ein spezifisches Metadatum aktiviert werden.
Systemweite Verwendung mit Global Filter Plugin Properties
Zum Aktivieren dieser Funktion klicken Sie auf das „Filters“ Tab und klicken Sie auf „Advanced Settings“.
Im Abschnitt „Global Filter Plugin Properties“ wählen Sie „FilterPlugin.JerichoWithThumbnails(…)“ aus und klicken Sie auf „Add“.
Klappen Sie den neuen Eintrag „FilterPlugin.JerichoWithThumbnails“ auf und haken Sie die Einstellung „Extract CDATA content“ an. Anschließend re-indizieren.
Crawlerspezifische Verwendung mit Datasource XPath Metadata
Im Tab „Indices“ aktivieren Sie „Advanced Settings“.
Klappen Sie den betreffenden Index auf. Im Abschnitt „Data Source“, Unterabschnitt „Extract Metadata“ klicken Sie auf das Plus-Symbol „Add Composite Property“.
Tragen sie im neuen Abschnitt „Extract Metadata“ als Name: htmlfilter:extractcdatacontent und XPath: "true" (Wichtig: unter Hochkomma) ein.
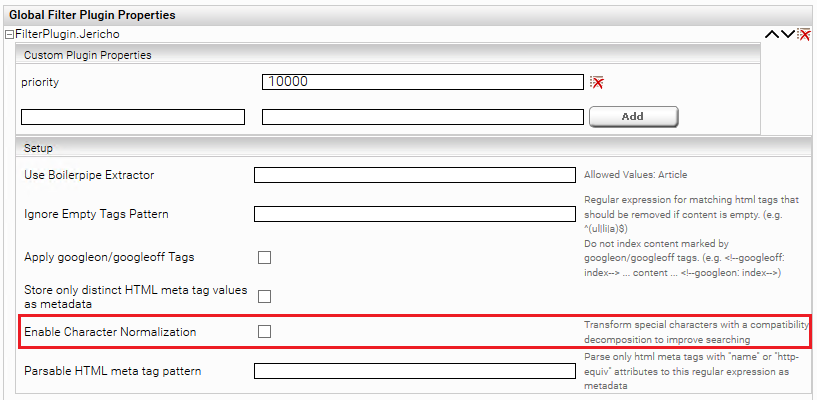
Normalisieren von Sonderzeichen
Mit der Option „Enable Character Normalization“ werden Sonderzeichen, wie z.B. ü,â in eine Normalform transformiert (Compatibility decomposition), welche das Suchen erleichtert. Diese Option kann zu besseren Ergebnissen führen, wenn die Client-Service Option „Query Expansion for Diacritic Term Variants“ nicht die gewünschte Qualität liefert.

Autorisierung
Um die Autorisierungsparameter zu konfigurieren soll die „AuthorizedWeb“ Kategorie ausgewählt werden.

Konfiguration von „Access Check Rules“
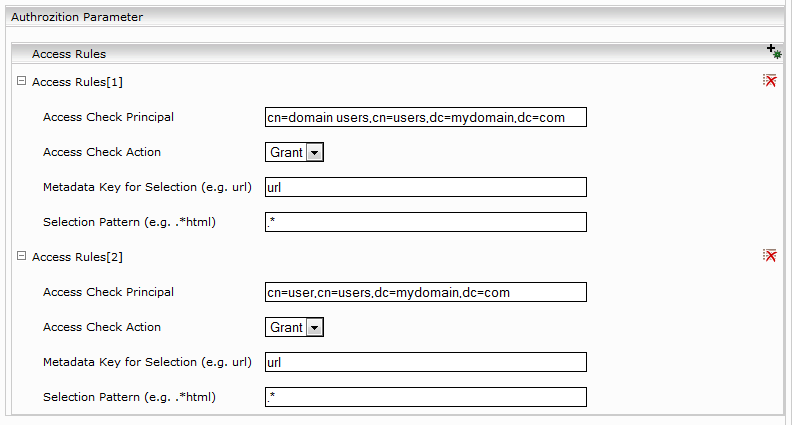
Ein Access Check Rule besteht aus:

Beschreibung | |
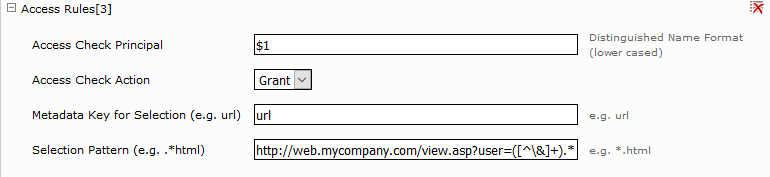
Access Check Principal | Die Benutzernamen können im username@domain Fromat oder im domain\username Fromat oder distinguished name Format sein. Die Gruppennamen können nur im distinguished name Format sein. Weiters kann hier ein Verweis auf eine Capture-Group in der Selection Pattern verwendet werden (siehe Access Rules[3]). |
Access Check Action | Grant order Deny. |
Metadata Key for Selection (e.g. url) | Ein Metadatenname, kann leer sein (alle Dokumente werden selektiert). |
Selection Pattern (e.g. .*html) | Eine Regularexpression, kann leer sein (alle Dokumente werden selektiert). |
Wenn Access Check Rules mit Sitemaps als Crawling Root verwendet wird, werden die Regeln nur dann angewendet, wenn in der Sitemap keine ACLs definiert sind.
Wenn Sitemaps als Crawling Root verwendet werden und Access Check Regeln konfiguriert sind, die sich nicht auf das „url“ Metadatum beziehen, werden bei einer Deltaindizierung alle Dokumente neuindiziert die potentiell ACL Änderungen enthalten können (auch wenn das Änderungsdatum nicht neuer ist).
Parallele Bearbeitung der URLs
Mit der Option „Use hashing queue assignment policy“ werden die input URLs Hash-basiert auf parallele Bearbeitungsschlangen verteilt. Die Anzahl der Bearbeitungsschlangen lassen sich mit der Option „Parallel Queue Count“ einstellen.
Ohne die „Use hashing queue assignment policy“ Option werden die URLs Hostname-basiert verteilt.

Entfernen von Dokumenten mit hoher Priorität
Dokumente, welche nicht mehr verfügbar sind, werden am Ende des Crawldurchganges aus dem Index entfernt. Dabei werden alle Dokumente gelöscht, die nicht erfolgreich heruntergeladen und indiziert wurden.
Wenn die Option „Incomplete Delta Crawl Runs“ aktiv ist, werden keine Dokumente am Ende des Crawlruns gelöscht.
![]()
Zusätzlich kann mit der Option: “Invalid document deletion Schedule” ein Zeitplan konfiguriert werden, in dem nicht mehr verfügbare Dokumente parallel zum Crawldurchlauf aus dem Index entfernt werden. Dazu muss eine Extended Cron Expression in das Feld eingetragen werden.
Eine Dokumentation und Beispiele zu Cron Expressions finden Sie hier.
![]()
Das Bespiel: „0 */45 * * * ?“ bedeutet einen Löschdurchgang alle 45 Minuten.
Dieser Zeitplan ist zusätzlich durch den Crawler Schedule beschränkt.
Folgende Dokumente werden während des Crawlruns gelöscht:
- Nicht gefundene Dokumente (HTTP Status 404, 410)
- Umleitungen auf diese Dokumente (z.B. HTTP Status 301, 307)
Wenn „Cleanup non matching URL-s from Index” aktiviert ist, werden zusätzlich folgende Dokumente gelöscht:
- Laut „URL Exclude Pattern“ ignorierte Dokumente
- Umleitungen auf diese Dokumente (z.B. HTTP Status 301, 307)
![]()
Wenn die Option „Cleanup non matching URL-s from Index“ aktiv ist und kein “Invalid document deletion Schedule” definiert wurde, dann wird der Löschvorgang mit jedem Crawlrun gestartet. Handelt es sich um einen Delta Crawl Run, werden nur laut „URL Exclude Pattern“ ignorierte Dokumente gelöscht, ansonsten werden zusätzlich auch nicht erreichbare Dokumente gelöscht (HTTP Status 404, 410, 301, 307). Es handelt sich um einen Delta Crawl Run, wenn die Option „Incomplete Delta Crawl Runs“ aktiv ist oder bei der Option „Delta Crawling“ „Sitemap-based Incomplete“ ausgewählt ist.
Appendix A
Heritrix Statuscodes
Der Heritrix Web Crawler, der in die Mindbreeze Web Connector verwendet wird, protokolliert die Status Codes von alle URLs die besucht waren. Diese Status Codes können die HTTP-Statuscode von den Server Antworten sein oder folgende Heritrix-spezifische Fehlercode:
Beschreibung | |
1 | Erfolgreiche DNS Lookup. |
0 | Download war nicht probiert (vielleicht das Protokoll war nicht unterstützt oder illegales URI). |
-1 | DNS Lookup fehlgeschlagen. |
-2 | HTTP Verbindung fehlgeschlagen. |
-3 | HTTP Verbindung abgebrochen. |
-4 | HTTP Timeout. |
-5 | Unerwarteter Laufzeitfehler. Siehe runtime-errors.log. |
-6 | Domain-auflösung fehlgeschlagen. |
-7 | URI erkennt als nicht unterstützt oder illegal. |
-8 | Maximale Anzahl an Versuchen erreicht. |
-50 | Temporäre Status für URI-s die auf Voraussetzungsprüfung warten. |
-60 | URIs mit Fehlerstatus, die nicht im Frontier eingereiht waren. |
-61 | Voraussetzung von robots.txt nicht erfüllt. |
-62 | Eine andere Voraussetzung (nicht robots.txt) nicht erfüllt. |
-63 | Eine Voraussetzungsprüfung könnte nicht durchgeführt werden. |
-404 | Leeres HTTP Antwort. |
-3000 | Java Fehler wie OutOfMemoryError or StackOverflowError während URI Bearbeitung. |
-4000 | "Chaff" Erkennung von Fällen/Inhalt mit vernachlässigbarem Wert. |
-4001 | Zu viele Link Hops von der Ausgangsseite entfernt. |
-4002 | Zu viele Embed/Transitive Hops vom letzten URI im Scope entfernt. |
-5000 | Die URI ist bei der erneuten Untersuchung nicht verfügbar. Dies geschieht nur, wenn sich der Bereich während des Crawlvorgangs ändert. |
-5001 | Download durch eine Benutzereinstellung blockiert. |
-5002 | Download von einem Custom Crawler blockiert. |
-5003 | Gesperrt wegen Überschreitung einer festgelegten Quote. |
-5004 | Blockiert wegen Zeitüberschreitung. |
-6000 | Gelöscht von Frontier durch Benutzer. |
-7000 | Verarbeitungsfaden wurde vom Betreiber gekillt. Dies kann passieren, wenn ein Thread eine nicht reagierende Bedingung ist. |
-9998 | Robots.txt Regel erlauben den Download nicht. |
Unterstütze Komprimierungstypen
Der Mindbreeze WebConnector unterstützt Dokumente, die mit den folgenden Komprimierungstypen (Content-Encoding) komprimiert sind:
- gzip
- x-gzip
- deflate
- identity
- none
Wie wird mes:date bestimmt?
Die Entscheidung, welches Datum für mes:date verwendet wird, wird in folgender Reihenfolge getroffen:
- Es wird geprüft, ob während dem Crawlrun das XML-Attribut "Last-Mod" extrahiert wurde. (Nur bei Sitemaps verfügbar)
- Es wird geprüft, ob während dem Crawlrun das XML-Attribut "Publication Date" extrahiert wurde. (Nur bei Sitemaps verfügbar)
- Wenn die oberen zwei Attribute nicht verfügbar sind (z.B., wenn eine normale Website und keine Sitemap gecrawlt wird), wird das aktuellere Datum aus den folgenden Zwei Werten verwendet:
- Das Last-Modified Datum aus den Response-Headern
- Wenn sich im HTML-Dokument ein <meta>-Tag mit dem Attribut „http-equiv“ (<meta http-equiv="Last-Modified" content="...">) befindet, wird das Datum aus diesem Tag extrahiert. Die Funktion dieses Tags ist äquivalent zu dem „Last Modified“ Header.
Wenn kein mes:date gesetzt werden konnte (z.B., wenn das Parsen des Response-Headers fehlgeschlagen ist), wird als Fallback-Wert der aktuelle Zeitstempel während dem Abrufen des Dokuments verwendet.