
Sure, you can handle it. But should you?
Let our experts manage the tech maintenance while you focus on your business.
Let our experts manage the tech maintenance while you focus on your business.
Handbuch
Natural Language Question Answering (NLQA)
Motivation und Überblick
Die große Popularität und vielen Anwendungsmöglichkeiten von OpenAIs ChatGPT Lösung zeigen, wie relevant das Thema Generative AI auf Basis von Large Language Models (LLMs) ist. Gerade im Unternehmenskontext kann diese Technologie einen großen Mehrwert bieten. Der Einsatz wird jedoch durch Themen wie Halluzinationen, fehlende Aktualität, Datensicherheit, kritische Fragen bezgl. geistiges Eigentum und technische Umsetzung bei sensiblen Daten erschwert. Mindbreeze bietet eine Lösung in Form einer Kombination aus Insight Engine und LLMs, die in der Lage ist genau diese Schwächen auszugleichen. Das Ergebnis ist die ideale Basis für Generative AI im Unternehmenskontext.
Diese Basis trägt den Namen „Natural Language Question Answering“, kurz NLQA und vereint die semantische Suche mit dem „Question Answering“. Die semantische Suche ermöglicht das Arbeiten mit vollständigen Sätzen, womit man durch die Eingabe von Sätzen nach Informationen suchen kann. Das „Question Answering“ ist für das Identifizieren von Antwort zuständig, wodurch Antworten in natürlicher Sprache inklusive umliegendem Kontext und Quellenverweis wiedergegeben werden.
In den folgenden Kapiteln wird erklärt, wie die Basiskonfiguration für das NLQA durchgeführt wird. Für weitere Fragen über die Konfiguration und Nutzung des Features, ist das FAQ zu empfehlen. Auch Informationen über die Unterstützung eigener Sprachmodelle und die Handhabung von Feedback ist dort zu finden.
Achtung: Bei der semantischen Suche über trainierte Modelle kann keine 100% vollständige und korrekte Suche gewährleistet werden. Eine Anpassung der Modelle wird nur bei dedizierten Projekten unterstützt, wobei die gelabelten Trainings- und Testdaten von der Kundenumgebung bereitgestellt werden. Zusätzlich ist zu beachten, dass wesentlich mehr Rechenleistung für die Aufbereitung der Daten verwendet wird. Bitte beachten Sie, dass dadurch die Indizierungszeit länger dauen kann. Daher ist nicht gewährleistet, dass die volle Dokumentanzahl mit diesem Feature betrieben werden kann.
Konfiguration
In diesem Abschnitt wird beschrieben, Konfigurationsschritte notwendig sind, damit Natural Language Question Answering (NLQA) aktiviert wird.
Konfiguration des Index
Navigieren Sie im Mindbreeze Management Center (MMC) zum „Configuration“ Menü und wechseln Sie zum „Indices“ Tab. Fügen Sie anschließend einen neuen Index hinzu („+ Add Index“) und aktivieren Sie „Advanced Settings“.
Konfiguration der Sentence Transformation
Aktivieren Sie im nächsten Schritt folgende Optionen im Bereich „Semantic Text Extraction“:
Enable Language Detection | Aktiviert |
Enable Sentence Transformation | Aktiviert |
Weitere Einstellungen, die angepasst werden können:
Static Sentence Transformer Restricted Zones Pattern | Wenn andere Zonen als „content“ oder „title“ für NLQA verfügbar sein sollen. Empfohlener Wert: “content|title” (Standardwert) |
Falls nur Dokumente gewisser Dokumentsprachen für NLQA verfügbar sein sollen, können Sie dies hier einschränken. Zum Beispiel wenn deutsche und englische Dokumente verarbeitet werden sollen: „en|de“ Standardwert: be|bg|br|bs|ca|cs|cy|da|de|el|en|es|et|eo|eu|fi|fo|fr|fy|ga|gd|gl|gv| |
Konfiguration der Datenquelle
Konfigurieren Sie ihre Datenquelle. Dokumentation der von Mindbreeze InSpire unterstützen Datenquellen finden sie auf help.mindbreeze.com im Bereich „Datenquellen“.
Test
Warten Sie, bis die Indizierung abgeschlossen ist. Testen Sie ihre Konfiguration mithilfe der Standard Mindbreeze InSpire Insight App.

FAQ
Kann ich NLQA auf einem bestehenden Index aktivieren?
Ja, Sie können NLQA auch auf bestehenden Indizes aktivieren. Konfigurieren Sie „Named Entity Recognition (NER)“ und „Sentence Transformation“, so wie oben beschrieben. Anschließend muss der Index neu aufgebaut werden. Führen Sie einen der folgenden Schritte durch:
- Re-Indizierung („Reindex“ Schaltfläche) oder
- vollständige Re-Invertierung des Index
Wie kann ich NLQA in meine Insight App integrieren?
Standardmäßig werden die Antworten direkt über den Suchresultaten angezeigt. Darüber hinaus kann die Visualisierung der Antworten frei an Ihre Bedürfnisse angepasst und auch vollständig deaktiviert werden. Siehe dazu Entwicklung von Insight Apps – answers.
Kann NLQA mit meiner bereits bestehenden Mindbreeze InSpire Lizenz verwendet werden?
Das NLQA-Feature kann mit der bestehenden Mindbreeze InSpire Lizenz genutzt werden. Für weitere Informationen wenden Sie sich bitte an support@mindbreeze.com.
Gibt es Support für Custom Sentence Transformer Models?
Die Basis für die semantische Suche wird von Transformer-Based-Language-Models im ONNX-Format gebildet. Durch die Verwendung dieses offenen Standards können vortrainierte (pre-trained Models) oder selbst trainierte LLMs in Mindbreeze InSpire integriert werden. Die Konfiguration von Custom Sentence Transformer Models ist in Konfiguration – Mindbreeze InSpire – Sentence Transformation beschrieben.
Ich bin mit der Qualität der Antworten nicht zufrieden. Was kann ich tun?
Es ist möglich, ein Reranker-Modell zu konfigurieren, um die Antworten umzusortieren.
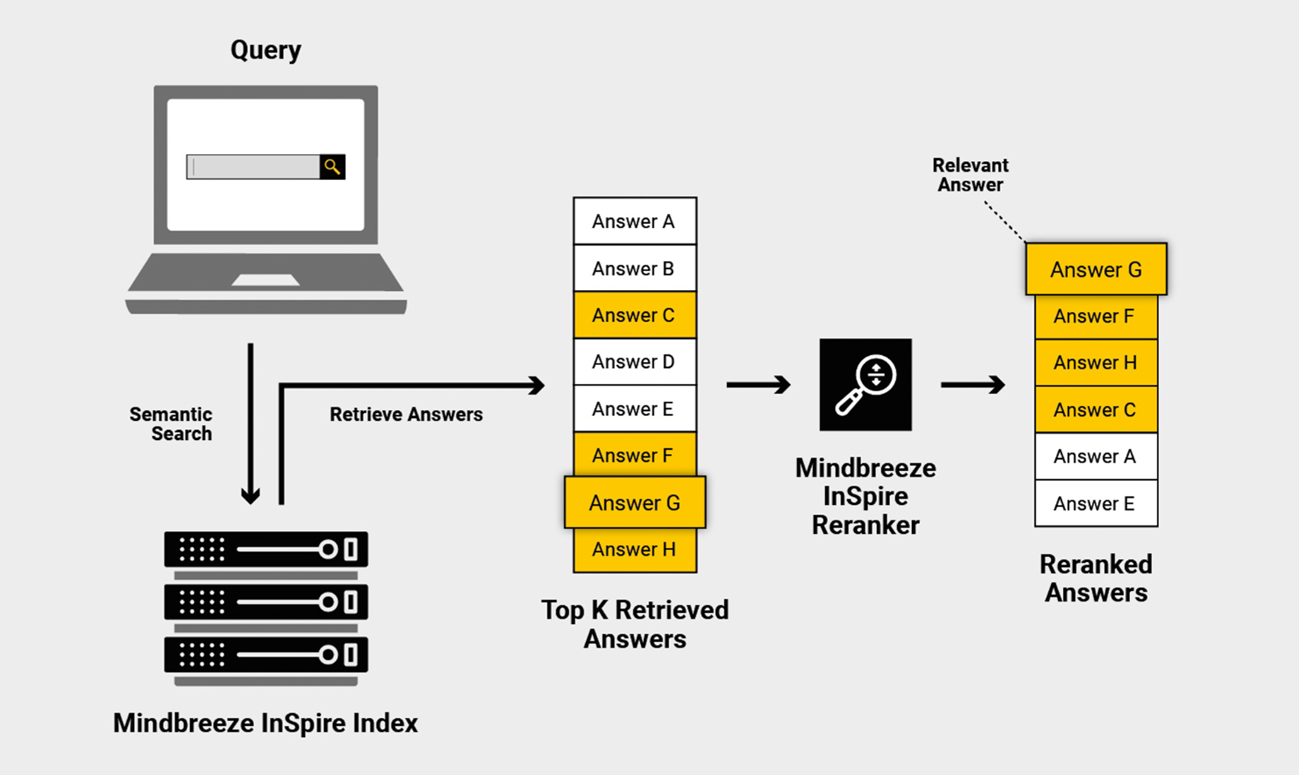
Um dies zu aktivieren, werden folgende Einstellungen benötigt:
Index Einstellungen:
“ms-marco-MiniLM-L12-v2” wenn die Appliance über eine GPU verfügt, ansonsten “ms-marco-MiniLM-L12-v2 (quantized, optimized)” | |
Enable Reranking | “Enabled (SearchRequest)” (Standardwert) |
Client Service Einstellungen:
Enable Reranking | aktiviert |
Die folgenden Einstellungen sind in der Mindbreeze InSpire Konfiguration verfügbar (siehe Konfiguration – Mindbreeze InSpire – Sentence Transformation):
Bereich: Semantic Text Extraction | |
Cross Encoder Model ID Setting | Cross-Encoder-Modell, das für das Reranking von Antworten für NLQA verwendet wird. Mögliche Werte: „Disabled“ (Standardwert), “ms-marco-MiniLM-L12-v2”, “ms-marco-MiniLM-L12-v2 (quantized, optimized)”, “Custom”.. |
Path to Custom Cross Encoder Model | Legt den Pfad zu einem benutzerdefinierten Cross Encoder-Modell fest. Ist nur wirksam, wenn "Custom" in "Cross Encoder Model ID Setting" ausgewählt ist und wenn das Antwort-Reranking aktiv ist. Wenn Sie ein benutzerdefiniertes Modell für Ihr Data-Science-Projekt verwenden möchten, wenden Sie sich bitte an support@mindbreeze.com. |
Bereich: Similarity Search Settings | |
Enable Reranking | Legt fest, ob Antworten unter Verwendung eines Cross-Encoder-Modells umsortiert werden sollen. Dazu muss eine „Cross Encoder Model ID Setting“ konfiguriert werden. Mögliche Werte: “Enabled (Search Request)” (Standardwert), “Disabled”, “Force” |
Max Answers to be used for Reranking | Legt fest, wie viele Antworten vor der Reranking-Phase gesammelt werden. Ein höherer Wert kann die Qualität der Antworten verbessern, verschlechtert aber die Performance. Standardwert: 100 |
Answer Batch Size to be used for Reranking | Während der Reranking-Phase werden die Antworten in Batches gruppiert und einzeln an den Cross Encoder gesendet. Mit dieser Einstellung wird die Größe der Batches festgelegt. Wenn Performanceprobleme auftreten, kann eine Anpassung dieser Einstellung zur Verbesserung der Leistung beitragen. Standardwert: 10 |
Bereich: Similarity Search Settings | |
Enable Reranking | Wenn diese Option aktiviert ist, werden die Antworten auf Suchanfragen standardmäßig vom Reranker umsortiert. Standardwert: deaktiviert |
Darüber hinaus sind die folgenden Felder in der api.v2.search-Anfrage verfügbar (siehe api.v2.search Schnittstellenbeschreibung – Sentence Transformation Settings):
- enable_answer_reranking
- rerank_source_max_answer_count: kann verwendet werden, um die Einstellung „Max Answers to be used for Reranking“ zu überschreiben
Die Priorität der verschiedenen „Enable Reranking“-Einstellungen wird wie folgt aufgelöst:
- Wenn die Indexeinstellung „Force“ oder „Disabled“ lautet, wird das Reranking entsprechend dieser Einstellung aktiviert;
- Andernfalls, d.h. wenn die Indexeinstellung „Enabled (SearchRequest)“ ist und wenn in der Suchanfrage ein Wert für enable_answer_reranking gesetzt ist, wird das Reranking gemäß diesem Wert aktiviert;
- Andernfalls, d.h. wenn die Indexeinstellung „Enabled (SearchRequest)“ ist und die Suchanfrage keinen Wert für enable_answer_reranking enthält, wird das Reranking entsprechend der Einstellung im Client-Service aktiviert.
Kann ich beeinflussen, welche Antworten angezeigt werden?
Es gibt verschiedene Möglichkeiten, die angezeigten Antworten zu beeinflussen:
Filtern von Antworten aufgrund der Qualität oder Anzahl:
Antworten werden nach Ähnlichkeitsfaktor sortiert, wobei die beste Antwort an erster Stelle steht. Der minimale Ähnlichkeitsfaktor für die Anzeige einer Antwort beträgt standardmäßig 50%. Dieser Wert („Minimum Score“) sowie die maximale Anzahl von Antworten („Answer Count“) können in der jeweiligen Index- und Client-Service-Konfiguration (Konfiguration – Mindbreeze InSpire – Sentence Transformation) eingestellt werden.
Reihenfolge der Antworten kann beeinflusst werden (Boostings):
Mindbreeze-Komponenten zur Beeinflussung der Relevanz von Suchtreffern wie der Term2DocumentBoost Transformer und Personalisierte Relevanz können auch für das Boosten von Antworten verwendet werden. Darüber hinaus werden Boostings, die in der api.v2.search-Schnittstelle definiert werden, auch für die Relevanz von Answers angewendet.
Wie kann ich Antworten von anderen Metadaten als vom Content bekommen?
Standardmäßig werden die Sentence Embeddings nur für „content“ und „title“ berechnet, weswegen die semantische Suche nur Antworten von diesen Metadaten liefert. Um auch Antworten von anderen Metadaten zu bekommen, konfigurieren Sie die Option „Static Sentence Transformer Restricted Zones Pattern“. Z.B.: Es sollen zusätzlich auch Antworten vom Metadatum „description“ kommen, dann muss Static Sentence Transformer Restricted Zones Pattern“ mit folgendem Wert konfiguriert werden: "content|title|description".
Außerdem ist es wichtig, dass das Metadatum bei der Suche explizit angefordert wird (in unserem Beispiel „description“). Dazu gibt es zwei Möglichkeiten, falls das Metadatum noch nicht angefordert wird:
- Metadaten via Mustach-Template anfordern:
<div class="media"><span class="hidden">{{description}}</span></div> - Über Application-Objekt:
modelDefaults: {
search: {
properties: { "description": { "formats": ["VALUE"]} }
}
}
(siehe Entwicklung von Insight Apps – Das Application-Objekt)
Gibt es erweiterte Konfigurationsoptionen für NLQA?
Ja, es gibt erweiterte Konfigurationsoptionen für NLQA in Konfiguration – Mindbreeze InSpire – Sentence Transformation. Diese Optionen sind normalerweise nur dann für Sie relevant, wenn Sie spezielle Anwendungsfälle haben, die eine spezielle Konfiguration erfordern. Bitte kontaktieren Sie support@mindbreeze.com, wenn Sie für Ihr Data-Science-Projekt Unterstützung benötigen, z.B. wenn Sie ein anderes Modell als das standardmäßig mitgelieferte Sentence Transformer Modell verwenden wollen.
Ich bin mit der Invertierungsdauer und/oder Suchperformance nicht zufrieden. Was kann ich tun?
Grundsätzlich: Je mehr Daten von den Sentence Transformern verarbeitet werden, desto länger dauert die Invertierung und desto größer wird auch der (invertierte) Index. Je größer der Index, desto mehr Rechenaufwand ist auch zum Suchzeitpunkt nötigt. Das heißt: Wird der Index verkleinert, wirkt sich dies im Normalfall auch positiv auf die Invertierungsdauer und Suchperformance aus. Dazu gibt es folgende Möglichkeiten in den Index-Einstellungen (Abschnitt Semantic Text Extraction):
Einstellung | Beschreibung |
Um eine bessere Invertierungs- und Such-Performance mit minimalen Qualitätseinbußen zu erhalten, wird die Nutzung des Models all-MiniLM-L6-v2 (quantized, optimized) empfohlen. | |
Sentence Transformer Max Batches | Wenn sehr große Dokumente (mit sehr viel Text) indiziert werden, kann sich das auch negativ auf die Performance auswirken. Mit dieser Option kann definiert werden, wie viele Satz-„Batches“ maximal vom Sentence Transformer verarbeitet werden. Zum Beispiel: Sentence Transformer Batch Size: 10 |
Sentence Transformer Restrict to Language Pattern | Wenn z.B. nur englische Dokumente für die Similarity Search relevant sind, kann dies hier mit „en“ eingeschränkt werden. |
Restricted Zones Pattern Static Sentence Transformer Restricted Zones Pattern, Dynamic Sentence Transformer Excluded Zones Pattern | Standardmäßig werden Sentence Embeddings nur für „content“ und „title“ berechnet (Standardwert Static Sentence Transformer Restricted Zones Pattern: „content|title“). Es wird nicht empfohlen, mittels “.*” alle Metadaten mit Sentence Transformers zu prozessieren. Besser ist, die Option „Static Sentence Transformer Restricted Zones Pattern“ zu erweitern, z.B. „content|title|description“, wenn „description“ ein Metadatum mit relevanten Informationen ist. |
Weitere Informationen zu diesen Einstellungen siehe Konfiguration – Mindbreeze InSpire – Sentence Transformation.
Des Weiteren führt in den meisten Fällen folgende Einstellung zu einer verbesserten Invertierungsperformance (Abschnitt „Setup“):
Beschreibung | |
Documents per Index Bucket | Standardmäßig ist ein „Bucket“ auf 60000 Dokumente begrenzt. Da Buckets parallel invertiert werden (maximal 1 Thread pro Bucket), kann man mehr Parallelität beim Invertieren erreichen, indem dieser Wert verringert wird (z.B. auf 10000). Falls Fragmentierung ein Problem darstellt, kann die Einstellung „Periodic Delete Bucket if Deleted %“ z.B. auf 70% verringert werden. Siehe dazu auch Konfiguration – Mindbreeze InSpire – Kompaktifizierung des Index. |
Ähnlichkeitssuchen, die zusätzliche Ausdrücke beinhalten, können optimiert werden, um die Anzahl der für die Ähnlichkeitssuche verwendeten Dokumente zu reduzieren.
Zum Beispiel, würde der Index, nach der Optimierung, bei der Abfrage ~„Was ist Mindbreeze?“ extension:pdf zunächst alle PDF-Dokumente auswählen und dann die Ähnlichkeitssuche nur für diese Dokumente durchführen. Bei großen Indizes und Abfragen mit mehreren Ausdrücken kann dies die Leistung erheblich steigern.
Dies kann sich jedoch negativ auf die Relevanz der Suchergebnisse auswirken, da der erste Auswahlvorgang nicht in die Relevanzberechnung einfließt. Der Antworten-Score wird davon nicht beeinflusst.
Dies wird durch die folgenden Optionen in den Indexeinstellungen gesteuert:
Bereich: Semantic Text Extraction | |
Vector Index File Format Revision | Für eine optimale Leistung muss diese Einstellung auf die Option „Latest“ oder „1 (with Document IDs)“ gesetzt werden. Diese Einstellung wurde mit der Mindbreeze InSpire 25.6 Release eingeführt und erfordert eine vollständige Re-Inversion, um wirksam zu werden. |
Bereich: Similarity Search Settings | |
Optimize Query For Similarity Search | Diese Einstellung steuert, ob Ähnlichkeitssuchen optimiert werden. Die möglichen Werte sind:
|
Optimize Transformed Query | Wenn diese Einstellung aktiviert ist, werden automatisch transformierte Abfragen ebenfalls gemäß der vorherigen Einstellung „Optimize Query For Similarity Search“ optimiert. |
Bereich: Similarity Search Settings | |
Optimize Query For Similarity Search | Diese Einstellung wird verwendet, wenn die Option „Use Global Settings“ in der Indexeinstellung „Optimize Query For Similarity Search“ im Bereich „Similarity Search Settings“ ausgewählt ist. Standardwert: Default |
Darüber hinaus ist das folgende Feld in der api.v2.search-Anfrage verfügbar (siehe api.v2.search Schnittstellenbeschreibung - Sentence Transformer Settings):
- optimize_for_similarity_search
Die Optimierung kann in der Suchanfrage mit folgenden Befehlen angefordert oder abgelehnt werden:
- ~[optimize:true]„Was ist Mindbreeze?“
- ~[optimize:false]„Was ist Mindbreeze?“
Die Priorität dieser Einstellungen wird wie folgt festgelegt:
- Als erstes wird der strengste Wert (in der Reihenfolge vom geringsten zum strengsten Wert: Default, Always, Not Disabled, Enabled, Never) zwischen der Indexeinstellung und der Einstellung der api.v2.search-Anfrage ausgewählt.
- Anschließend wird anhand dieses Werts zusammen mit der Abfrage entschieden, ob die Abfrage optimiert wird:
Strengster Wert des Index und der api.v2.search-Anfrage | Wert aus der Abfrage | ||
[optimize:true] | Nicht spezifiziert | [optimized:false] | |
Default (Enabled) | Ja | Nein | Nein |
Always | Ja | Ja | Ja |
Not Disabled | Ja | Ja | Nein |
Enabled | Ja | Nein | Nein |
Never | Nein | Nein | Nein |
Kann ich von meinen Benutzern Feedback über die Qualität von Antworten bekommen?
Das Voting-Feature bietet die Möglichkeit, Feedback eines Users zu einem Answer-Suchresultat zu erhalten. Dieses Feedback wird ebenfalls in der app.telemetry aufgezeichnet. Die InSpire Beta-Version von NLQA unterstützt derzeit keine automatische Anpassung der Relevanz von Antworten für Benutzer auf der Grundlage ihres Feedbacks.
Darüber hinaus werden andere User-Interaktionen mit Answers in app.telemetry aufgezeichnet, z.B. wenn ein Benutzer auf das Quell-Dokument der Answer klickt. Diese Interaktionen sowie das Feedback der Nutzer können im app.telemetry Insight App Reporting Dashboard grafisch dargestellt und ausgewertet werden.
Kann ich mithilfe der Mindbreeze Query Language die Suche mit NLQA beeinflussen?
Ja, es gibt Erweiterungen der Mindbreeze Query Language für NLQA.
Wenn NLQA aktiviert ist, wird bei jeder Suche automatisch eine sogenannte Ähnlichkeitssuche (englisch: „Similarity Search“) ausgeführt. Dieses Standardverhalten kann in der Index-Konfiguration angepasst werden. Siehe dafür die Einstellung „Transform Terms to Similarity“ in Konfiguration – Mindbreeze InSpire – Sentence Transformation.
Um eine Ähnlichkeitssuche explizit mithilfe der Mindbreeze Query Language abzusetzen (unabhängig von der Einstellung „Transform Terms to Similarity“), kann folgende Syntax verwendet werden:
~"<Frage>"
Beispiel: ~"Wie viele Konnektoren bietet Mindbreeze InSpire an?"
Die Ähnlichkeitssuche kann auch in Kombination mit der Metadaten-Suche verwendet werden:
<Metadatum>:~"<Frage>"
Beispiel: content:~"Wie viele Konnektoren bietet Mindbreeze InSpire an?"
Die Ähnlichkeitssuche unterstützt auch Optionen, wobei mehrere Optionen in einer Query angegeben werden können:
~[<Option>:<Wert> …]"<Frage>"
Beispiele:
- ~[minscore:0.5]"Wie viele Konnektoren bietet Mindbreeze InSpire an?"
- ~[minscore:0.5 region:large]"Wie viele Konnektoren bietet Mindbreeze InSpire an?"
Folgende Optionen stehen dabei zur Verfügung:
- minscore – Überschreibt den konfigurierten „Minimum Score“. Für mehr Informationen über den „Minimum Score“ siehe Konfiguration – Mindbreeze InSpire – Sentence Transformation.
- Gültige Werte: Kommazahl zwischen 0 und 1 (in englischer Schreibweise, z. B. 0.5).
- region – Überschreibt die konfigurierte „Text Region“ Einstellung. Diese Option definiert die Größe der Antwort. Hierbei stehen die Werte „default“ und „large“ zur Auswahl.
- default: Ist die Standardgröße und ist abhängig von den konfigurierten „Sentences Transformation Text Segmentation“ Einstellungen. Für mehr Informationen siehe Konfiguration – Mindbreeze InSpire – Sentence Transformation.
- large: Ist ein großer Textblock, abhängig von folgenden Einstellungen im Konfigurationsbereich „Sentences Transformation Text Segmentation“:
- Hinweis: Der Score der Antworten ist mit dieser Option tendenziell niedriger, weswegen empfohlen wird, auch die Option minscore (z. B. mit Wert 0.3) anzugeben.
- optimize – Kann auf „true“ oder „false“ gesetzt werden, um Optimierungen zu aktivieren oder zu deaktivieren. Weitere Informationen finden Sie im Kapitel Ich bin mit der Invertierungsdauer und/oder Suchperformance nicht zufrieden. Was kann ich tun?