Sure, you can handle it. But should you?
Let our experts manage the tech maintenance while you focus on your business.
Let our experts manage the tech maintenance while you focus on your business.
Handbuch
Administration von Insight Services für Retrieval Augmented Generation
Motivation und Überblick
Retrieval Augmented Generation (RAG) ist eine Technik zur Verarbeitung natürlicher Sprache, die Stärken von abfragebasierten und generativen Modellen der künstlichen Intelligenz (KI) kombiniert. In einem RAG-basierten KI-System wird ein Abfragemodell verwendet, um relevante Informationen aus vorhandenen Informationsquellen zu finden. Währenddessen nimmt das generative Modell die abgefragten Informationen auf, synthetisiert alle Daten und formt sie in eine zusammenhängende, kontextbezogene Antwort um.
Konfiguration eines Large Language Model (LLM)
Initialeinrichtung
Die Anleitung für die Initialeinrichtung eines LLMs finden Sie in Konfiguration – InSpire AI Chat und Insight Services für Retrieval Augmented Generation.
Integration eines LLMs
Um ein Large Language Model (LLM) für Ihre Pipelines zu konfigurieren, wechseln Sie im Menüpunkt „RAG“ zum Bereich "LLMs".
Klicken Sie auf "Hinzufügen" und wählen Sie das entsprechende LLM aus, um es zu konfigurieren. Derzeit sind vier LLMs für die Integration verfügbar:
Die folgenden Einstellungen können für das jeweilige LLM konfiguriert werden.
InSpire LLM
Verbindung

Einstellung | Beschreibung |
URL (erforderlich) | Definiert die URL des LLM Endpoint. Die URL erhalten Sie von sales@mindbreeze.com. Für mehr Informationen, siehe Konfiguration - InSpire AI Chat und Insight Services für Retrieval Augmented Generation - Vorbereitung. |
Model (erforderlich) | Wählt das Modell aus, das Sie verwenden möchten. Die Option „default“ bezieht sich auf das stabilste und zuverlässigste verfügbare Modell. |
Für die Bereiche „Allgemein“, „Prompt“ und „Test“ siehe das Kapitel Allgemeine Teile der LLM-Einstellungen.
OpenAI
Beim Anlegen eines OpenAI LLMs werden Sie durch einen Dialog auf die Datenschutzbestimmungen hingewiesen. Sie müssen diesen Datenschutzbestimmungen zustimmen, um mit dem Anlegen fortzufahren.
Achtung: Bei Verwendung der OpenAI API werden Chat Eingaben des Benutzers und von Ihrer Organisation indizierte Informationen über Prompts an die jeweiligen Endpunkte übermittelt. Der Umgang mit den übermittelten Informationen richtet sich nach den Datenschutz-Bestimmungen des entsprechenden KI-Anbieters. Mindbreeze ist für die weiterführende Datenverarbeitung nicht verantwortlich. Der KI-Anbieter ist weder Erfüllungsgehilfe noch Unterauftragsverarbeiter von Mindbreeze. Wir weisen darauf hin, dass eine rechtmäßige Nutzung von KI-Dienstleistungen nach gegenwärtiger Einschätzung nicht sichergestellt ist (vorsorglicher Hinweis nach Art 28 Abs. 3 S. 3 DSGVO). Für weitere Informationen und Risiken wird auf die jeweiligen Datenschutzhinweise des jeweiligen KI-Anbieters verwiesen.
Mehr Informationen erhalten Sie unter https://openai.com/enterprise-privacy .
Durch Bestätigung der Checkbox weisen Sie als Datenverantwortlicher Mindbreeze an, diese Übermittlung dennoch durchzuführen und nehmen den oben beschriebenen Hinweis zur Kenntnis.
Verbindung

Einstellung | Beschreibung |
API-Key (erforderlich) | Definiert den API-Key. Den API-Key erhalten Sie von Open AI bei der Verwendung eines Modelles. |
Modell (erforderlich) | Der Name des zu verwendenden Open AI LLM. |
Eigene LLM URL verwenden | Ist diese Einstellung aktiviert, kann man eine individuelle URL zu einem LLM in der nachfolgenden Einstellung „URL“ angeben. Damit wird die Verwendung eines LLM ermöglicht, das nicht direkt von OpenAI gehostet wird, aber die OpenAI Schnittstelle verwendet. Standardeinstellung: Deaktiviert |
URL | Hier kann man eine individuelle URL zu einem LLM angeben, das die OpenAI Schnittstelle verwenden soll. |
Mit "Verbindung testen" wird geprüft, ob die angegebenen Werte gültig sind und ob die Verbindung hergestellt werden kann.
Für die Bereiche „Allgemein“, „Prompt“ und „Test“ siehe das Kapitel Allgemeine Teile der LLM-Einstellungen.
Erweiterte Einstellungen
Beschreibung | |
API-Key Header Name | Definiert den Namen für den Header, wenn der API-Key mit einem speziellen Header gesendet werden soll. Beispiel: abcdef12345 |
OAuth2 Scope | Standardeinstellung: https://graph.microsoft.com/.default |
API-Key und Azure AD Token senden | Ist diese Einstellung aktiviert, wird der API-Schlüssel neben dem Request zusätzlich noch im Header mitgesendet. |
Azure OpenAI
Beim Anlegen eines Azure OpenAI LLMs werden Sie durch einen Dialog auf die Datenschutzbestimmungen hingewiesen. Sie müssen diesen Datenschutzbestimmungen zustimmen, um mit dem Anlegen fortzufahren.
Achtung: Bei Verwendung der Azure OpenAI API werden Chat Eingaben des Benutzers und von Ihrer Organisation indizierte Informationen über Prompts an die jeweiligen Endpunkte übermittelt. Der Umgang mit den übermittelten Informationen richtet sich nach den Datenschutz-Bestimmungen des entsprechenden KI-Anbieters. Mindbreeze ist für die weiterführende Datenverarbeitung nicht verantwortlich. Der KI-Anbieter ist weder Erfüllungsgehilfe noch Unterauftragsverarbeiter von Mindbreeze. Wir weisen darauf hin, dass eine rechtmäßige Nutzung von KI-Dienstleistungen nach gegenwärtiger Einschätzung nicht sichergestellt ist (vorsorglicher Hinweis nach Art 28 Abs. 3 S. 3 DSGVO). Für weitere Informationen und Risiken wird auf die jeweiligen Datenschutzhinweise des jeweiligen KI-Anbieters verwiesen.
Mehr Informationen erhalten Sie unter https://learn.microsoft.com/de-de/legal/cognitive-services/openai/data-privacy
Durch Bestätigung der Checkbox weisen Sie als Datenverantwortlicher Mindbreeze an, diese Übermittlung dennoch durchzuführen und nehmen den oben beschriebenen Hinweis zur Kenntnis.
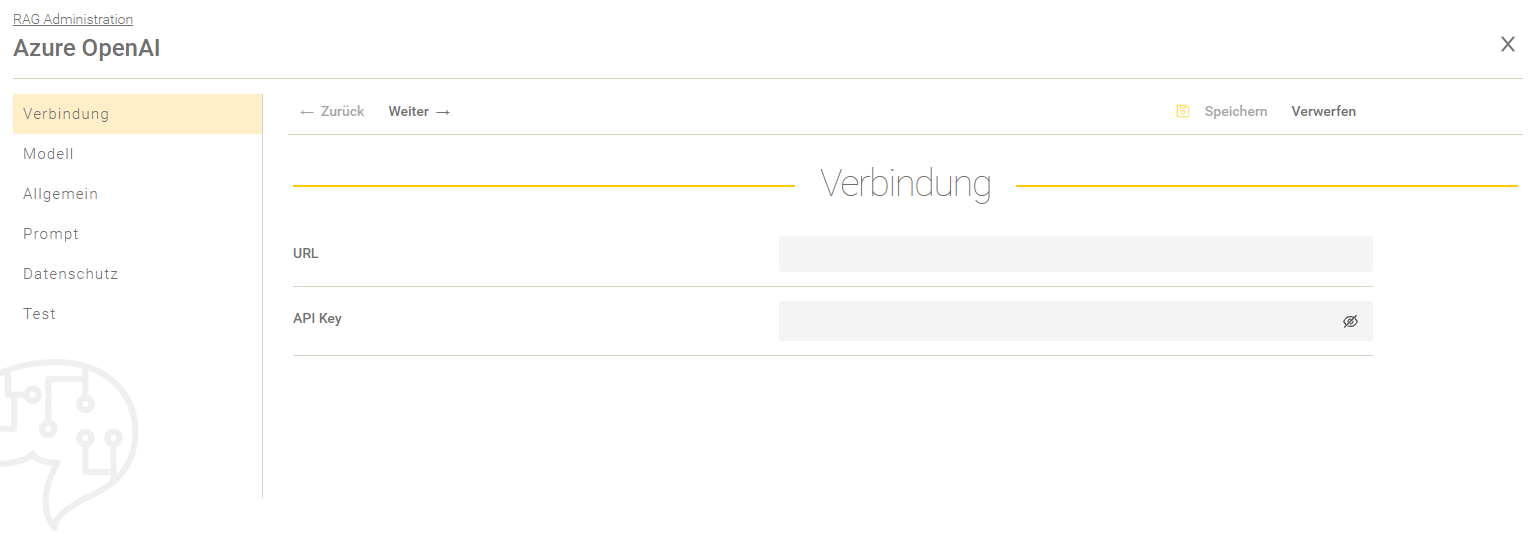
Verbindung
Einstellung | Beschreibung |
URL (erforderlich) | Definiert den URL des LLM Endpoint. Die URL erhalten Sie von Microsoft Azure bei der Verwendung eines Modelles. |
API Key (erforderlich) | Definiert den API Key. Den API-Key erhalten Sie von Microsoft Azure bei der Verwendung eines Modelles. |
Informationen zur Erstellung eines Credentials für ein Azure OpenAI LLM, finden Sie in Konfiguration - InSpire AI Chat und Insight Services für Retrieval Augmented Generation - Beispiel: Credential erstellen für ein Azure OpenAI LLM.
Erweiterte Einstellungen

Einstellung | Beschreibung |
OAuth2 Scope | Standardeinstellung: https://graph.microsoft.com/.default |
API-Key und Azure AD Token senden | Ist diese Einstellung aktiviert, wird der API-Key neben dem Request zusätzlich noch im Header mitgesendet. |
Modell

Einstellung | Beschreibung |
Azure Bereitstellung (erforderlich) | Definiert den Namen der Microsoft Azure Bereitstellung. Für mehr Informationen, siehe Deployment Types. |
Für die Bereiche „Allgemein“, „Prompt“ und „Test“ siehe das Kapitel Allgemeine Teile der LLM-Einstellungen.
InSpire LLM (TGI)
Das InSpire LLM (TGI) nutzt die Text Generation Inference (kurz: TGI) Schnittstelle von Huggingface.
Verbindung
Einstellung | Beschreibung |
URL (erforderlich) | Definiert die URL des LLM Endpoint. Die URL erhalten Sie von sales@mindbreeze.com. Für mehr Informationen, siehe Konfiguration - InSpire AI Chat und Insight Services für Retrieval Augmented Generation - Vorbereitung. |
Modell

Einstellung | Beschreibung |
User Message Token User Message End Token Assistant Message Token Assistant Message End Token Message End Token | Je nach Modell auszufüllen, wobei die Einstellungen je nach Modell variieren können. Standardeinstellung: Nur die Einstellung “Message End Token” wird mit dem Wert “</s>” verwendet. |
Für die Bereiche „Allgemein“, „Prompt“ und „Test“ siehe das Kapitel Allgemeine Teile der LLM-Einstellungen.
Allgemeine Teile der LLM-Einstellungen
Allgemein
Einstellung | Beschreibung |
Name | Der Name für das Large Language Model. |
LLM Key | Definiert den Key mit dem das LLM eindeutig identifiziert werden kann. Der LLM Key kann im OpenAI Proxy als model verwendet werden. Für mehr Informationen, siehe Konfiguration - InSpire AI Chat und Insight Services für Retrieval Augmented Generation - Konfiguration des OpenAI Proxy. |
Maximale Länge der Antwort (Tokens) | Begrenzt die Menge der erzeugten Token (1 Token ~ 1 Wort). Indem man die Länge der Antwort begrenzt, können lange Antworten vermieden und die Belastung des LLM Endpoints verringert werden. Mit dem Wert "0" werden die Token bzw. die Antwort nicht begrenzt. Achtung: Stellen Sie sicher, dass die Länge des Prompts und die maximale Antwortlänge nicht größer sind, als die Länge des Kontextes des Modells. |
Zufälligkeit (Temperatur) überschreiben | Wenn aktiviert, wird die Standardtemperatur des LLM mit der konfigurierten "Zufälligkeit der Antwort" überschrieben. Für mehr Informationen über die Zufälligkeit bzw. Temperatur einer Antwort, siehe die Beschreibung der Einstellung „Zufälligkeit der Antwort (Temperatur)“. |
Zufälligkeit der Antwort (Temperatur) | Steuert die Zufälligkeit bzw. die Kreativität der generierten Antwort (0 - 100%). Durch die Konfiguration der Temperatur wird die Wahrscheinlichkeitsverteilung beeinflusst, die während der Generierung des nächsten Tokens erzeugt wird. Durch die Veränderung der Wahrscheinlichkeitsverteilung wird das Model folgendermaßen beeinflusst:
|
Wiederholungsstrafe überschreiben | Ist diese Einstellung aktiviert, wird der Wert von der Einstellung „Wiederholungsstrafe“ als LLM Parameter übernommen. Für mehr Informationen über Wiederholungsstrafen, siehe die Beschreibung der Einstellung „Wiederholungsstrafe“. |
Wiederholungsstrafe | Mit diesem Parameter können Token, basierend darauf wie häufig sie im Text vorkommen (inklusive des eingegebenen Prompts), bestraft werden. Ein Token welcher bereits mehrmals vorgekommen ist, wird härter „bestraft“ als ein Token, welcher erst ein- oder noch keinmal vorgekommen ist. Die Bestrafung besteht darin, dass die Wahrscheinlichkeit reduziert wird, dass ein Token der vorher schon im Text vorgekommen ist, erneut generiert wird. Der gültige Wertebereich der Wiederholungsstrafe ist abhängig vom verwendeten LLM. |
Top P überschreiben | Ist diese Einstellung aktiviert, wird der Wert von der Einstellung „Top P“ als LLM Parameter übernommen. Für mehr Informationen über Top P, siehe die Beschreibung der Einstellung „Top P“. |
Top P | Mit Top-P-Sampling kann die Vielfalt und Zufälligkeit von generiertem Text gesteuert werden. Dabei wird der nächste Token aus einem "Kern" von Top-P-Token ausgewählt. Dieser Kern wird auf eine von zwei Arten zusammengestellt:
Der angegeben Top-P-Wert bestimmt die Diversität der Ausgabe folgendermaßen:
Der Top-P-Wert muss größer als 0 aber kleiner als 1 sein. |
Prompt-Token abschneiden (experimentell) | Hiermit wird angegeben, ob der Prompt auf eine gewisse Anzahl an maximalen Tokens abgeschnitten wird. Achtung: Diese Einstellung funktioniert nur, wenn das verwendete LLM mit vLLM bereitgestellt ist. |
Stopsequenzen | Falls Stopsequenzen definiert sind, beendet das Modell die Generierung eines Textes sofort, sobald eine solche Sequenz vom Modell generiert worden ist. Selbst wenn die Ausgabelänge das angegebene Token-Limit noch nicht erreicht hat, wird die Textgenerierung beendet. |
Prompt

Einstellung | Beschreibung |
Preprompt | Ein Pre-Prompt wird verwendet, um spezifische Rollen, Absichten und Einschränkungen auf jeden nachfolgenden Prompt eines Modells anzuwenden. Beispiel: Ich möchte, dass du dich wie ein Mitglied des Mindbreeze Sales Teams verhältst. Ich werde dir Fragen stellen und du wirst mir diese Fragen ausführlich beantworten. Formuliere deine Antworten enthusiastisch und aufregend, aber bleibe bei den Fakten. Hebe besonders die Vorteile von verschiedenen Mindbreeze Features hervor. |
Prompt Examples | Siehe das Kapitel Prompt Beispiele. |
Prompt Beispiele

Diese Beispiele werden im Mindbreeze InSpire AI Chat als Beispielfragen angezeigt (siehe Screenshot am Ende des Kapitels). Dementsprechend eignen sich häufig gestellte Fragen als Prompt Beispiele. Durch das Anklicken eines Prompt Beispiels wird diese Frage im Mindbreeze InSpire AI Chat automatisch eingegeben. Ein Prompt Beispiel kann erstellt werden, indem Sie auf „Hinzufügen“ drücken und die folgenden Felder befüllen:
Einstellung | Beschreibung | Beispiel |
Titel | Der Titel des Prompt Beispiels. Dieser Text wird im Mindbreeze InSpire AI Chat angezeigt | Fragen Sie, wie viele Konnektoren Mindbreeze unterstützt. |
Prompt | Die Frage oder Anweisung, die im Mindbreeze InSpire AI Chat eingegeben wird. | Wie viele Konnektoren unterstützt Mindbreeze? |
Klicken Sie auf „Speichern“ um das Prompt Beispiel zu sichern. Es können beliebig viele Prompt Beispiele erstellt werden. Sind alle Prompt Beispiele erstellt, speichern sie das gesamte LLM um die Änderungen zu sichern. Nun sollten Sie die Prompt Beispiele im AI Chat sehen:
Hinweis: Prompt Beispiele aus den LLMs und den RAG-Pipelines werden im neuen Widget „chat“ (verfügbar mit Mindbreeze InSpire 25.7 Release) noch nicht unterstützt.
Datenschutz
Falls Sie ein InSpire LLM verwenden, ist dieser Bereich nicht verfügbar. Sollten Sie ein LLM von OpenAI oder Azure OpenAI verwenden, können Sie sich hier über den Haftungsausschluss zum Datenschutz informieren.
Test

Auf dieser Seite kann die Konfiguration getestet werden. Falls LLM Parameter definiert worden sind, werden dieser hier nochmals zusammengefasst. Beachten Sie, dass der generierte Text nicht auf abgerufenen Dokumenten basiert.
Nach dem Testen der LLM-Einstellungen klicken Sie auf "Speichern", um das LLM zu speichern.
Erstellung einer Pipeline
Um eine Pipeline zu erstellen, gehen Sie zum Bereich „Generative Pipelines“. Klicken Sie auf „Hinzufügen“, um mit der Erstellung einer neuen Pipeline zu beginnen.
Die Erstellung einer Pipeline teilt sich in fünf Bereiche auf:
- Allgemein
- Retrieval
- Generierung
- Test
In den folgenden Kapiteln wird genauer auf die einzelnen Bereiche eingegangen.
Allgemein
Im Bereich „Allgemein“ können folgende allgemeine Einstellungen vorgenommen werden:
Einstellung | Beschreibung |
Name | Der Name, der im Mindbreeze InSpire AI Chat angezeigt wird. |
Beschreibung | Beschreibung der Pipeline. |
Version | Eine generierte Versions-ID. |
Vorgängerversion | Die vorhergehende Version, worauf diese Version basiert. |
Versionsname | Wenn eine Pipeline freigegeben wird, muss ein Versionsname angegeben werden. Der Versionsname wird nicht im Mindbreeze InSpire AI Chat angezeigt und dient zur Nachvollziehbarkeit von Änderungen an der Pipeline. Der Versionsname soll eine kurze Zusammenfassung der Änderungen beinhalten. |
Versionsbeschreibung | Eine detailliertere Beschreibung der Änderungen in der Pipeline. |
Pipeline-Key | Key einer Pipeline (vgl. Erstellung von Datensets). |
Im Bereich „Prompt Beispiele“ können Beispielfragen für eine Pipeline hinzugefügt werden, die im AI Chat angezeigt werden. Sind keine Beispielfragen in der Pipeline definiert, werden Beispielfragen vom LLM übernommen. Sind auch im LLM keine Beispielfragen definiert, werden im AI Chat keine Beispielfragen angezeigt. Für mehr Informationen zu Prompt Beispielen, siehe das Kapitel Erstellung von Prompt Beispielen.
Sind die notwendigen Einstellungen erledigt, können Sie mit „Weiter“ oder mit einem Klick auf den gewünschten Bereich in der linken Navigationsleiste zum nächsten Bereich fortfahren.
Retrieval
Im Bereich „Retrieval“ kann der Retrieval-Teil des RAG konfiguriert werden. Nur Indizes, die das Feature „Semantic Sentence Similarity Search” aktiviert haben, können im AI Chat Antworten für die Generierung liefern. Es stehen die folgenden Einstellungen zur Verfügung:
Suchservice
Einstellung | Beschreibung |
Suchservice | Der Client Service, der für die Suche verwendet werden soll. |
Erweiterte Einstellungen

Einstellung | Beschreibung | ||||||||
SSL Zertifikat Überprüfung überspringen | Ist dies aktiviert, wird bei der Suche keine Überprüfung des SSL-Zertifikats durchgeführt. Die Aktivierung dieser Einstellung wird empfohlen, wenn ein SSL-Zertifikat besteht. | ||||||||
Nur Content verarbeiten | Wenn diese Eigenschaft gesetzt wird, werden nur Antworten, aus dem content Metadatum verwendet. Ansonsten werden Antworten aus allen Metadaten verarbeitet. | ||||||||
Maximale Anzahl Antworten | Die ersten n Antworten der Suche werden prozessiert und für den Prompt verwendet. Hinweis: Wenn n = 0 und das Prompt Logging in app.telemetry deaktiviert ist, dann haben die Spalten für die Antworten im CSV Logging keine Spaltenüberschriften für die Antwort-Details. | ||||||||
Minimaler Antwort Similarity-Score [0-1] | Es werden nur Antworten prozessiert, die eine größere Antwort-Wertung haben. Hinweis: Wenn der Score in der Pipeline 0 ist, dann wird (wenn gesetzt) der Minimum Score aus den Similarity Search Settings des Client Services verwendet. | ||||||||
Minimaler Antwort Gesamt-Score [0-1] | |||||||||
Antwortgröße | Definiert wie lange die Antwort sein soll, die im Prompt Template dargestellt wird. Es stehen die Optionen „Standard“ und „Groß“ zur Verfügung. Die Option „Standard“ ist abhängig von der Konfiguration von „Sentence Transformation Text Segmentation“. Die Option „Groß“ ist ein großer Textblock. Für mehr Informationen, siehe Konfiguration - Mindbreeze InSpire- Sentence Transformation. Standardeinstellung: Standard. | ||||||||
Satzzeichen entfernen | Ist diese Einstellung aktiviert, werden Satzzeichen aus der Nutzereingabe entfernt bevor sie von der Similarity Search verarbeitet werden. Folgende Satzzeichen werden entfernt:
Standardeinstellung: Aktiviert. Hinweis: Durch das Deaktivieren dieser Einstellung können potentiell bessere oder mehr Antworten gefunden werden. Standardmäßig ist diese Einstellung aktiviert, um rückwärtskompatibel zu bleiben, falls durch das Weglassen der Satzzeichen eine Verschlechterung der Qualität der Antworten erkennbar ist. | ||||||||
Formatierte Antworten verwenden | Diese Einstellung ist standardmäßig deaktiviert. Die Antworten werden somit als einfacher Text weiterverarbeitet. Ist diese Einstellung aktiviert, wird HTML-Formatierung zu den erhaltenen Antworten hinzugefügt, um die Struktur des Originaldokuments zu reproduzieren. Für mehr Informationen, siehe api.v2.search Schnittstellenbeschreibung - formatted_answers. | ||||||||
Antwort-Reranking | Diese Einstellung hat drei Optionen:
Hinweis: Damit das Answer Reranking auch wie erwartet funktioniert und um die Einstellung vollumfänglich zu verstehen, lesen Sie bitte vorab die folgende Dokumentation: | ||||||||
Maximale Anzahl Basis-Antworten für das Reranking | Dieser Wert gibt an, wie viele Antworten für den Reranking-Prozess verwendet werden. Hinweis: Je mehr Antworten vorab gesammelt werden, desto höher kann die Qualität der Antwort sein. Hierbei ist zu beachten, dass sich eine große Menge an Antworten auch negativ auf die Performance auswirken kann |
Regeln
Im Abschnitt „Regeln“ kann die Pipeline verfeinert und auf die jeweiligen Anforderungen angepasst werden.

Einstellung | Beschreibung |
Überschreiben der Suchanfragenvorlage erlauben | Ist nur relevant, wenn die API direkt verwendet wird. Erlaubt das Überschreiben von Werten der Suchanfragenvorlage via API-Requests. Für mehr Informationen, siehe api.chat.v1beta.generate Schnittstellenbeschreibung. |
Sucheinschränkung | Bei der Suche mittels Search Service wird der Wert in diesem Feld (sofern vorhanden) auch als Bedingung in die Suche miteingenommen. |
Datenquelle inkludieren | Wenn (eine oder mehrere) Datenquellen inkludiert werden, dann werden automatisch alle anderen Datenquellen ausgeschlossen. |
Datenquelle ausschließen | Wenn (eine oder mehrere) Datenquellen ausgeschlossen werden, dann werden automatisch alle anderen Datenquellen eingeschlossen. |
Im Abschnitt „Verwendete Datenquellen“ wird eine Übersicht über die effektiven Datenquellen des gewählten Suchservices geboten.
Antwortsortierung
Mithilfe der Antwortsortierung kann die Reihenfolge der Antworten, die den Prompt eingefügt werden, definiert werden.
Die Reihenfolge und die Anzahl der Sortierkriterien kann dabei beliebig gewählt werden.
Ist die Antwortsortierung konfiguriert, wird entsprechend dem ersten Kriterium sortiert und nachfolgende Kriterien werden nur berücksichtigt, wenn die vorherigen Werte ident sind. Sollten keine Sortierungskriterien definiert sein, werden die Antworten nach dem Antworten-Score sortiert.
Folgende Kriterien sind zur Sortierung verfügbar:
Kriterium | Beschreibung |
Dokument mit höchstem Score | Reiht die Antworten aus dem Dokument entsprechend dem Antworten-Score, wobei die beste Antwort nach vorne gereiht wird. |
Dokument mit höchstem akkumuliertem Score | Zählt die Scores einzelner Antworten aus dem gleichen Dokument zusammen. |
Position im Dokument | Sortiert die Antworten entsprechend der Startposition im Text. |
Benutzereingaben Transformierung mittels Prompt
Wenn die Funktion „Benutzereingabe Transformation“ aktiviert ist, wird die Benutzereingabe für die Suchanfrage über LLM transformiert, bevor die Suchanfrage gestellt wird.
Einstellung | Beschreibung | ||||||
Transformierung durchführen | Aktiviert oder Deaktiviert die Query Transformation. | ||||||
Ausgabeformat | Für das Ausgabeformat gibt es zwei Optionen:
| ||||||
Anzahl der Nachrichten des Konversationsverlaufs | Die Anzahl der bisher geführten Konversation wird zur Generierung der nächsten Antwort herangezogen. Dies kann zum Bespiel bei Folgefragen zu potenziell besseren Antworten führen. | ||||||
Prompt | |||||||
System Message Template | Die System-Message definiert im Prompt das Verhalten (Persönlichkeit, Rolle), gibt Einschränkungen und Regeln mit und stellt Hintergrundinformationen für das LLM bereit. Die System Message fungiert quasi als "Job-Beschreibung" für das LLM. | ||||||
User Message Template | Die User-Message definiert die konkreten Anweisungen, Aufgaben oder Fragen an das LLM. | ||||||
Hinweis: Für „System Message Template“ und „User Message Template“ ist folgender Platzhalter gültig:
Platzhalter | Beschreibung |
question | Für die eingegebene Frage des Benutzers. |
Weitere Prompt Platzhalter werden in diesen Prompt Templates nicht berücksichtigt.
Erweiterte Einstellungen für das Ausgabeformat „Query Text“
Einstellung | Beschreibung | ||||
Ähnlichkeitssuche verwenden | Gibt an, ob in der Suchanfrage die Ähnlichkeitssuche verwendet werden soll. | ||||
Text Normalisierung | Mithilfe dieser Einstellung wird die generierte Antwort normalisiert oder bearbeitet, bevor sie als Query in die Suchanfrage eingefügt wird. Standardmäßig werden die Antworten mit der folgenden Einstellung normalisiert:
Es ist möglich, mehrere Einträge für die Normalisierung zu setzen. Sind mehrere Einträge eingefügt worden, werden diese in der gegebenen Reihenfolge abgearbeitet. |
Erweiterte Einstellungen für das Ausgabeformat „Liste von Queries“

Beschreibung | |
Ähnlichkeitssuche verwenden | Gibt an, ob in der Suchanfrage die Ähnlichkeitssuche verwendet werden soll. |
Trennzeichen | Mit dem Trennzeichen wird der generierte Text in eine Liste von Queries getrennt. Die einzelnen Queries werden in der Suchanfrage dann verodert. Standard-Trennzeichen: \n |
Aufteilen größerer Inhaltsbereiche

Einstellung | Beschreibung | ||||||||
Aufteilung anwenden | Definiert, ob große Antworten aufgeteilt werden sollen. Verfügbare Optionen:
| ||||||||
Maximale Chunk Größe | Definiert wie groß die aufgeteilten Chunks maximal sein sollen (in Zeichen). Standardeinstellung: 500 |
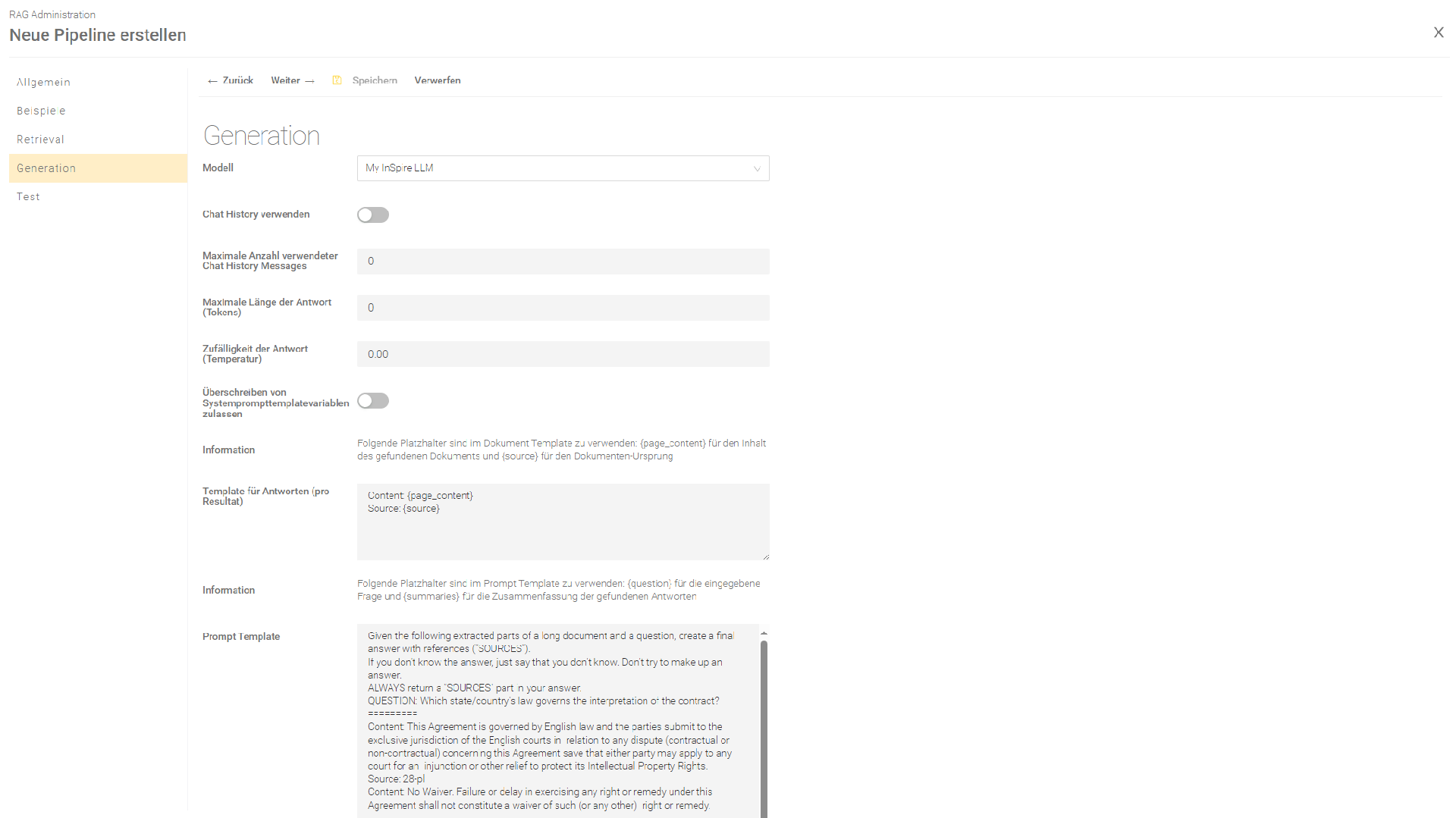
Generierung
Im Bereich „Generierung“ wird die Prompt-Generierung konfiguriert und das LLM und die Prompt Templates ausgewählt, die mit den Suchergebnissen befüllt und anschließend zum konfigurierten LLM geschickt werden.




Modell
Wählen Sie in der Einstellung „Modell“ das von Ihnen erstellte LLM aus.
Einstellung | Beschreibung |
Modell | Zeigt welches LLM ausgewählt ist. |
Erweiterte Einstellungen
Einstellung | Beschreibung |
Maximale Länge der Antwort (Tokens) | Diese Einstellung überschreibt die Einstellung "Maximale Länge der Antwort (Tokens)" des LLMs, wenn der Wert größer als 0 ist. Durch das Begrenzen der Länge der Antwort, werden lange Antworten vermieden und die Belastung des LLM Endpoints verringert. |
Zufälligkeit der Antwort (Temperatur) | Diese Einstellung überschreibt die Einstellung "Zufälligkeit der Antwort (Temperatur)" im LLM, wenn der Wert größer als 0 ist. Für mehr Informationen über die Zufälligkeit bzw. Temperatur einer Antwort, siehe die Beschreibung der Einstellung „Zufälligkeit der Antwort (Temperatur)“ im Kapitel Allgemeine Teile der LLM-Einstellungen. |
Überschreiben von Systemprompttemplatevariablen zulassen | Nur relevant, wenn die API direkt verwendet wird. Erlaubt das Überschreiben der Systemprompttemplatevariablen ({question}, {summaries}). Für mehr Informationen, siehe api.chat.v1beta.generate Schnittstellenbeschreibung. |
Prompts
Die Definition von Prompts kann auf zwei Arten durchgeführt werden:
- in einer strukturierten Form
- als reine Text-Vorlage
Mit der Mindbreeze InSpire 25.2 Release wird bei neu angelegten Pipelines automatisch das strukturierte Format angewandt. Bei bereits bestehenden Pipelines wird das Textformat beibehalten, wobei in den erweiterten Einstellungen das Format geändert werden kann.
Hinweis: Die Nutzung der strukturierten Form für Prompts wird empfohlen.
Prompt-Formate
Strukturiertes Prompt Format
Folgende Einstellungen können in „Chat Template“ und „Chat Template (ohne Retrieval Ergebnisse)“ vorgenommen werden:
Einstellung | Beschreibung |
System Message Template | Die System-Message definiert im Prompt das Verhalten (Persönlichkeit, Rolle), gibt Einschränkungen und Regeln mit und stellt Hintergrundinformationen für das LLM bereit. Die System Message fungiert quasi als "Job-Beschreibung" für das LLM. |
User Message Template | Die User-Message definiert die konkreten Anweisungen, Aufgaben oder Fragen an das LLM. |
Prompt im Text Format
Für mehr Informationen, siehe die Einstellung Strukturiertes Prompt-Format verwenden.
Prompt-Varianten
Chat Template
Dieses Prompt-Template wird beim Abrufen von Dokumenten verwendet.
Chat Template (ohne Retrieval Ergebnisse)
Dieses Prompt-Template wird verwendet, wenn keine Dokumente abgerufen werden.
Erweiterte Einstellungen für Chat Template und Chat Template (ohne Retrieval Ergebnisse)
Einstellung | Beschreibung |
Strukturiertes Prompt-Format verwenden | Mit dieser Einstellung kann man einen bestehenden Prompt im Textformat in einen Prompt im strukturierten Format umwandeln. Achtung: Bei Änderungen des Formats werden Prompts nicht konvertiert. Es wird daher empfohlen, die Prompts vor der Formatänderung zu sichern. Standardeinstellung:
|
Undefinierte Platzhalter zulassen | Erlaubt nicht definierte Werte von Platzhalter im Prompt. Fehlende Werte werden durch leere Strings ersetzt. Standardeinstellung: Aktiviert |
Prompt Template zum Erzeugen des Konversations-Titels | |
Prompt Template zum Erzeugen des Konversations-Titels | Dieser Prompt wird an das LLM gesendet, um im AI Chat den Titel einer Konversation zu generieren. Der folgende Platzhalter kann eingefügt werden:
|
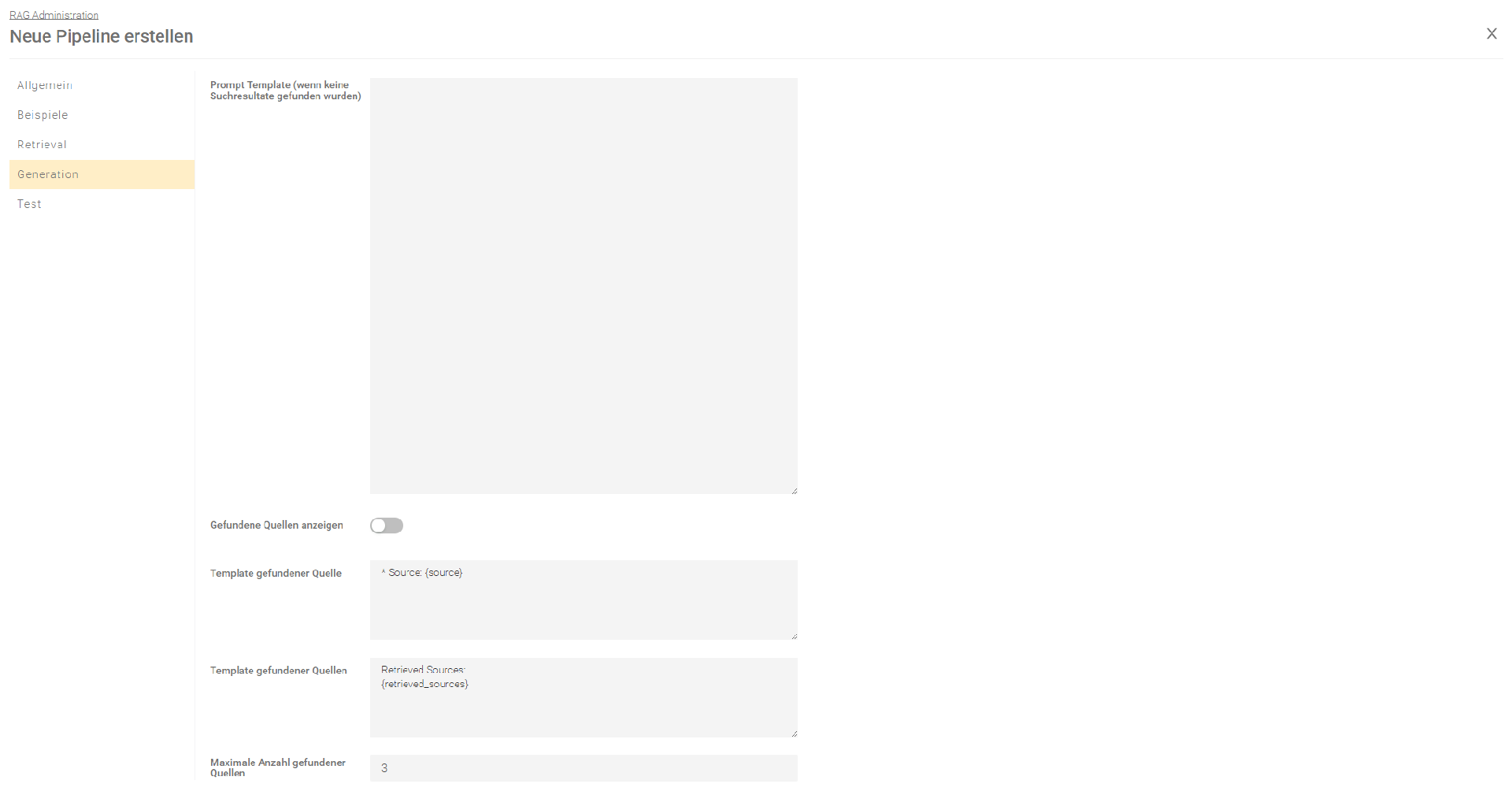
Gefundene Quellen anzeigen | |
Gefundene Quellen anzeigen | Wenn diese Einstellung aktiviert ist, werden die zuletzt abgerufenen Quellen laut der Einstellung "Maximale Anzahl gefundener Quellen" am Ende des generierten Antworttextes angehängt. Standardmäßig weist die Einstellung "Prompt Template" das Modell an, die relevanten Quellen bereitzustellen, unabhängig von dieser Einstellung. Wenn diese Einstellung aktiviert ist, empfiehlt es sich, die Einstellung "Prompt Template" anzupassen, um doppelte Quellen in der generierten Antwort zu vermeiden. |
Template gefundener Quelle | Das Template legt fest, wie die einzelnen Quellen angezeigt werden sollen. Der folgende Platzhalter muss eingefügt werden:
|
Template gefundener Quellen | Das Template zeigt die abgerufenen Zusammenfassungen der Templates der gefundenen Quellen an. Der folgende Platzhalter muss eingefügt werden:
|
Maximale Anzahl gefundener Quellen | Diese Einstellung legt fest, wie viele gefundene Quellen angezeigt werden sollen. |
Chat Template für Chatverlauf
Dieses Chat Template wird verwendet, wenn der Chatverlauf aktiviert ist und die Konversation fortgeführt wird. Hiermit kann die Frage mit Kontext aus dem Verlauf angereichert, oder unter Umständen direkt beantwortet werden.
Einstellung | Beschreibung |
Chatverlauf verwenden | Ist diese Einstellung aktiviert, wird der Inhalt der bisher geführten Konversation zur Generierung der nächsten Antwort herangezogen. Dies kann zum Bespiel bei Folgefragen zu potentiell besseren Antworten führen. |
System Message Template | Die System-Message definiert im Prompt das Verhalten (Persönlichkeit, Rolle), gibt Einschränkungen und Regeln mit und stellt Hintergrundinformationen für das LLM bereit. Die System Message fungiert quasi als "Job-Beschreibung" für das LLM. |
User Message Template | Die User-Message definiert die konkreten Anweisungen, Aufgaben oder Fragen an das LLM. |
Erweiterte Einstellungen für Chat Template für Chat-Verlauf
Einstellung | Beschreibung | ||||||||||
Maximale Anzahl verwendeter Chatverlauf Messages | Diese Einstellung ist nur wirksam, wenn „Chat-History verwenden“ aktiv ist. Limitiert die Anzahl an Chat-History Nachrichten die für die Generierung verwendet werden. Ist der Wert „0“, werden alle Chat-History Nachrichten verwendet. Mit dieser Einstellung wird sichergestellt, dass die Anfragen an das LLM bei längeren Chats nicht zu groß werden. Empfohlene Werte: 2 - 4 | ||||||||||
Chatverlauf Template | Dieses Template verarbeitet jede Nachricht des Chatverlaufs zu einem Text für den Prompt. Je nach den gewünschten Informationen aus der Antwort können die folgenden Platzhalter eingefügt werden:
| ||||||||||
Antwortpräfix | Die Vorlage, die die empfangenen Antworten zu einem Text für die Eingabeaufforderung verarbeitet. Je nach den gewünschten Informationen aus der Antwort können die folgenden Platzhalter eingefügt werden:
Zusätzliche Metadaten für die einzelnen Dokumente können ebenfalls angefordert werden, z. B. {language}. Wenn für das Dokument keine Metadaten vorhanden sind, wird der Platzhalter durch einen leeren Wert ersetzt. | ||||||||||
Fragepräfix | Wenn der generierte Text in der fortgeführten Konversation mit diesem Präfix beginnt, wird dieser Text als Query für das Retrieval verwendet. Das Präfix wird vorher entfernt. |
Platzhalter in Prompts
Es können unterschiedliche Platzhalter in Prompts eingefügt werden.
Vordefinierte Platzhalter
Die Platzhalter können sowohl im System Prompt Template als auch im User Prompt Template (und in der unstrukturierten Text Prompt Variante) verwendet werden.
Beschreibung | |
{question} | An dieser Stelle wird die Benutzereingabe eingefügt. |
{summaries} | An dieser Stelle werden die eingeholten Dokumente eingefügt. Für mehr Informationen, siehe das Kapitel Zusammenfassung der Antworten. |
{citation_instruction} | An dieser Stelle wird, wenn Zitate verwendet werden, die Anweisung zum Zitieren eingefügt. |
{conversation_history} | Nur verfügbar für Chat Template für Chat-Verlauf. Hier wird der Chat-Verlauf eingefügt. Dabei werden die einzelnen Chat-Nachrichten eingefügt, wie es im Chat Verlauf Template definiert wurde. Für mehr Informationen, siehe Chat-Verlauf Template. |
Individuelle Platzhalter
Zusätzlich zu den vordefinierten Platzhaltern können auch noch individuelle Platzhalter eingefügt werden.
Die Werte dafür müssen im Chat-Request im Feld prompt_dictionary mitgeschickt werden. Für mehr Informationen zum Feld, siehe api.chat.v1beta.generate Schnittstellenbeschreibung - prompt_dictionary.
Wenn ein Platzhalter keinen Wert über den Chat-Request erhält, muss definiert werden, ob eine Fehlermeldung ausgegeben werden soll oder ob der Platzhalter einfach mit einem leeren String ersetzt werden soll. Für mehr Informationen, siehe Undefinierte Platzhalter zulassen.
Zusammenfassung der Antworten

Einstellung | Beschreibung | ||||||||||
Information | Ist ein Hinweis für die Einstellung „Template für Antworten (pro Resultat)“. | ||||||||||
Template für Antworten (pro Resultat) | Das Template, das die erhaltenen Antworten in einen Text für den Prompt verarbeitet. Je nach gewünschten Informationen aus der Antwort können folgende Platzhalter eingebaut werden:
Es können auch zusätzliche Metadaten der einzelnen Dokumente angefordert werden, z.B. {language}. Wenn ein Metadatum am Dokument nicht existiert, wird der Platzhalter mit einem leeren Wert ersetzt. | ||||||||||
Template für Antworten mit Zitaten (pro Resultat) | Definiert ein Template, das für den ersten Chunk pro Dokument verwendet wird. Durch dieses Template wird definiert, wie die Chunks im Prompt dargestellt werden, um den Prompt zu verbessern. Achtung: Um diese Einstellung zu nutzen, muss im „Retrieval“-Bereich der Pipeline, die Einstellung „Aufteilung anwenden“ im Abschnitt „Aufteilen größerer Inhaltsbereiche“ aktiviert sein. | ||||||||||
Template für Antworten Rest aufgeteilt (pro Resultat) | Definiert ein Template, das für die restlichen Chunks pro Dokument verwendet wird. Durch dieses Template wird definiert, wie die Chunks im Prompt dargestellt werden, um den Prompt zu verbessern. |
Erweiterte Einstellungen

Einstellung | Beschreibung | ||||
Verbindungstext für Template für Antworten | Mit diesem Text werden die einzelnen Resultat-Templates für Antworten verbunden. Diese Einstellung kann dabei helfen, den Prompt im Bereich der erhaltenen Antworten zu optimieren. Standardwert: \n\n | ||||
Normalisierung der Zusammenfassung der gefundenen Antworten | Mithilfe dieser Einstellung können die erhaltenen Antwort-Texte ({summaries}) normalisiert oder bearbeitet werden, bevor sie in den Prompt eingefügt werden. Standardmäßig werden die Antworten mit der folgenden Einstellung normalisiert:
Es ist möglich, mehrere Einträge für die Normalisierung zu setzen. Sind mehrere Einträge eingefügt worden, werden diese in der gegebenen Reihenfolge abgearbeitet. Ist ein Muster nicht in den Antwort-Texten enthalten oder ungültig, dann wird dieser Eintrag ignoriert, während die vorangegangenen und nachfolgenden Einträge ausgeführt werden. |
Details zu Zitaten
Einstellung | Beschreibung | ||||||||
Zitate verwenden | Definiert, ob der Zitats-Prompt eingefügt werden soll. Folgende Werte sind verfügbar:
| ||||||||
Einleitung | Dieser Prompt wird standardmäßig an den System-Prompt angehängt, wenn Zitate verwendet werden sollen. Wenn der Platzhalter {citation_introduction} im Prompt Template vorkommt, wird dieser Text stattdessen dort eingefügt. Bei Pipelines, die noch das Text Prompt Format verwenden, wird der Platzhalter nicht automatisch eingefügt. Wenn Zitate verwendet werden sollen, muss der Platzhalter dort zwingend händisch eingefügt werden. |
Erweiterte Einstellungen
Einstellung | Beschreibung |
Starttext | Text, der ein Zitat einleitet. |
Endtext | Text, der ein Zitat beendet. |
Pattern | Regex-Pattern, das das Format eines Zitats beschreibt. |
Start-Pattern | Regex-Pattern, das verwendet wird, um den Start und die ID eines Zitats zu extrahieren. |
Block-Pattern | Regex-Pattern, das verwendet wird, um ein komplettes Zitat und die dazügehörige ID zu extrahieren. |
End-Pattern | Regex-Pattern, das verwendet wird, um das Ende eines Zitats zu extrahieren. |
Test
Im Bereich „Test“ können Sie die Einstellungen der Pipeline testen und überprüfen, ob die getätigten Einstellungen die Anforderungen erfüllen.

Veröffentlichung der erstellten Pipeline
Status der Pipeline
Eine Pipeline kann mehrere Versionen haben und jede Version davon hat einen Status:
- In Bearbeitung: Diese Pipeline hat momentan eine Bearbeitungsversion. Es kann pro Pipeline nur eine Bearbeitungsversion geben, die jederzeit bearbeitet werden kann.
- Freigegeben: Eine freigegebene Version ist im Nachhinein nicht mehr veränderbar. Wenn man doch noch Änderungen vornehmen möchte, muss man eine neue Bearbeitungsversion erstellen, sofern noch keine vorhanden ist.
- Veröffentlicht: Pro Pipeline kann nur eine freigegebene Version veröffentlicht werden. Es ist auch möglich eine frühere freigegebene Version zu veröffentlichen. Daher muss nicht zwangsläufig die letzte freigegebene Version veröffentlicht werden. Veröffentlichte Versionen können auch wieder zurückgenommen werden, wenn man die Veröffentlichung entfernt.
Freigabe der Pipeline-Version
Nachdem eine Pipeline erstellt oder bearbeitet wurde, gibt es dafür eine Bearbeitungsversion. Um die Bearbeitungsversion abzuschließen, muss diese freigegeben werden. Wählen Sie dafür die erstellte Pipeline aus, indem Sie ein Häkchen neben dem Namen der Pipeline setzen. Geben Sie einen Versionsnamen und optional eine Versionsbeschreibung an. Klicken Sie dann auf „Version freigeben“.
Der Status der Pipeline ist nun „Freigegeben“.

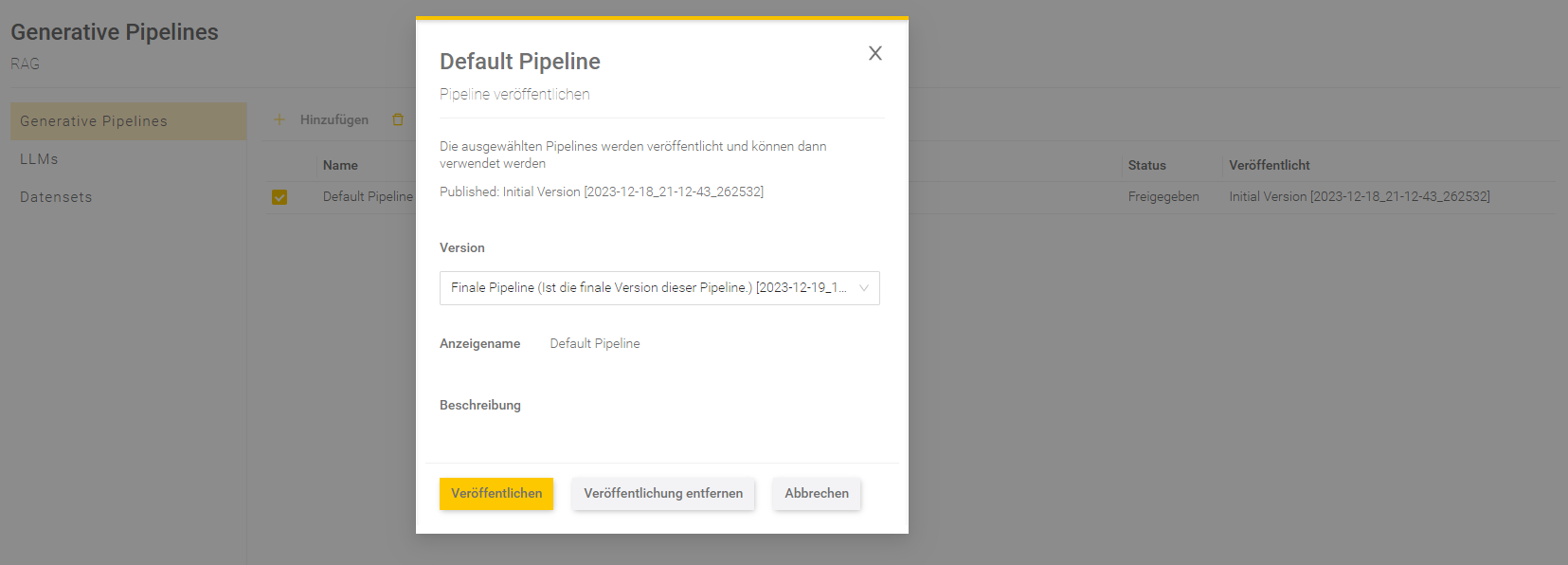
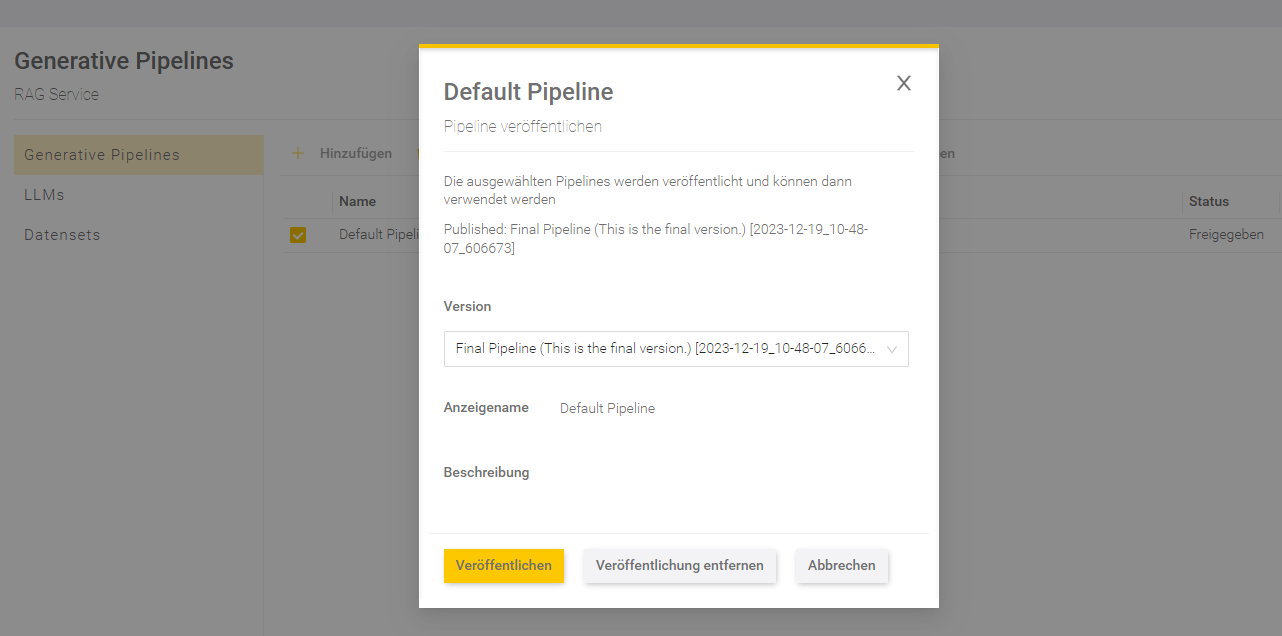
Veröffentlichung der Pipeline-Version
Um eine Pipeline im Mindbreeze InSpire AI Chat zu verwenden ist die Veröffentlichung einer Pipeline-Version notwendig. Wählen Sie dazu eine Pipeline mit dem Status „Freigegeben“ aus, indem Sie ein Häkchen neben dem Namen der Pipeline setzen. Klicken Sie dann auf „Veröffentlichen“. Es können nur Pipeline-Versionen mit dem Status „Freigegeben“ veröffentlicht werden.
Wählen Sie in dem Dialogfeld eine Pipeline-Version aus, die Sie veröffentlichen möchten, und überprüfen Sie den Anzeigenamen und die Beschreibung. Wenn bereits eine Version der Pipeline veröffentlicht ist, dann findet man Informationen zu der veröffentlichten Version der Pipeline über dem Auswahlfeld.
Klicken Sie anschließend „Veröffentlichen“, damit die ausgewählte Version veröffentlicht wird.
Nach der Veröffentlichung sollte in der Spalte „Veröffentlicht“ die Versionsnummer der veröffentlichten Version stehen.

Sie können nun ihre erstellte Pipeline im Mindbreeze InSpire AI Chat auswählen und benutzen.

Entfernung der Veröffentlichung
Wählen Sie eine Pipeline mit einer Versionsnummer in der Spalte „Veröffentlicht“, indem Sie ein Häkchen neben dem Namen der Pipeline setzen. Klicken Sie dann auf „Veröffentlichen“. In dem aufkommenden Dialogfeld finden Sie Informationen zur veröffentlichten Version. Klicken Sie anschließend auf „Veröffentlichung entfernen“.

In der Übersicht sollte bei der Pipeline keine Versionsnummer mehr bei der Spalte „Veröffentlicht“ stehen. Die Pipeline ist nun nicht mehr im Mindbreeze InSpire AI Chat verfügbar.
Producer-Consumer-Einrichtung
Wenn Sie ein Producer-Consumer-Szenario besitzen, kann die RAG-Konfiguration mit der Schaltfläche "Mit dem Consumer synchronisieren" auf alle Nodes synchronisiert werden.
Erstellung von Datensets
In diesem Bereich können Datensets erstellt werden, welche zur Evaluierung von Pipelines notwendig sind.
Erstellung eines neuen Datensets
Hinzufügen von Daten
Klicken Sie auf „Neues Datenset hinzufügen“ und geben Sie dem Datenset bei „Name des Datensets“ einen Namen. Fügen Sie anschließend Daten zu einem Datenset hinzu, indem Sie im Bereich „Daten“ auf „Hinzufügen“ klicken.
Folgende Felder können befüllt werden:
Spaltenname | Beschreibung |
Frage | Die Frage, die verschickt wird. |
Antwort | Die erwartete Antwort zur Frage. |
Queries | Jedes Query muss in einer eigenen Zeile geschrieben werden. |
Query Einschränkungen | Einschränkungen, die auf die Query beim Retrieval angewendet werden. Jede Einschränkung muss in einer neuen Zeile geschrieben werden. |
Pipeline-Key | Der Pipeline Key kann vom Benutzer selbständig definiert werden. Ist ein Pipeline Key definiert, kann man diesen auswählen und die Frage wird ausschließlich mit der veröffentlichten Version der Pipeline beantwortet, die dem Key zugeordnet ist. |
Anmerkung | Anmerkung zu den Fragen. |
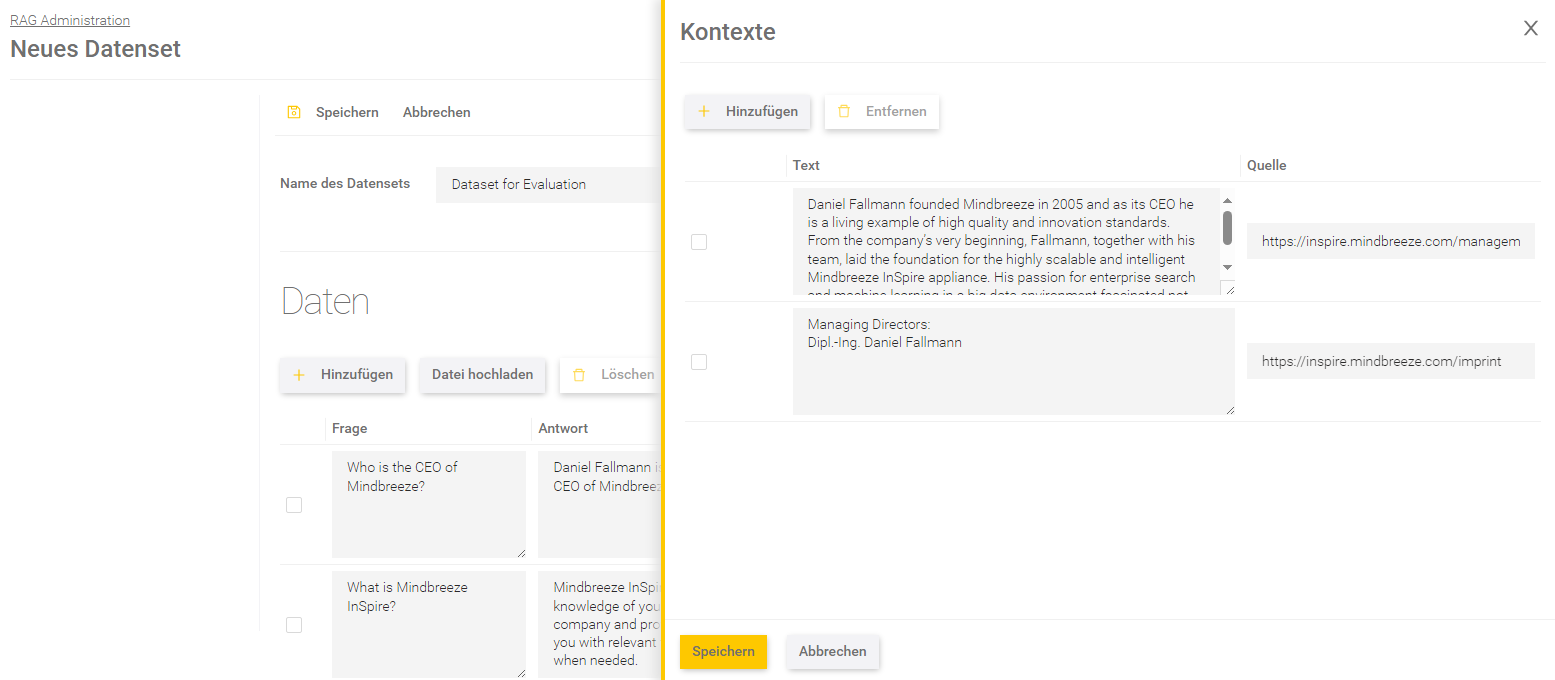
Kontexte
In den Kontexten können pro Frage die erwarteten Antworten eingegeben werden.
Beschreibung | |
Text | Definiert den erwarteten Text, bestehend aus einer Antwort und umliegendem Kontext. |
Quelle | Definiert die erwartete Quelle. |
Speichern Sie die Änderungen in den Kontexten indem Sie in dem Fenster unten auf „Speichern“ klicken.
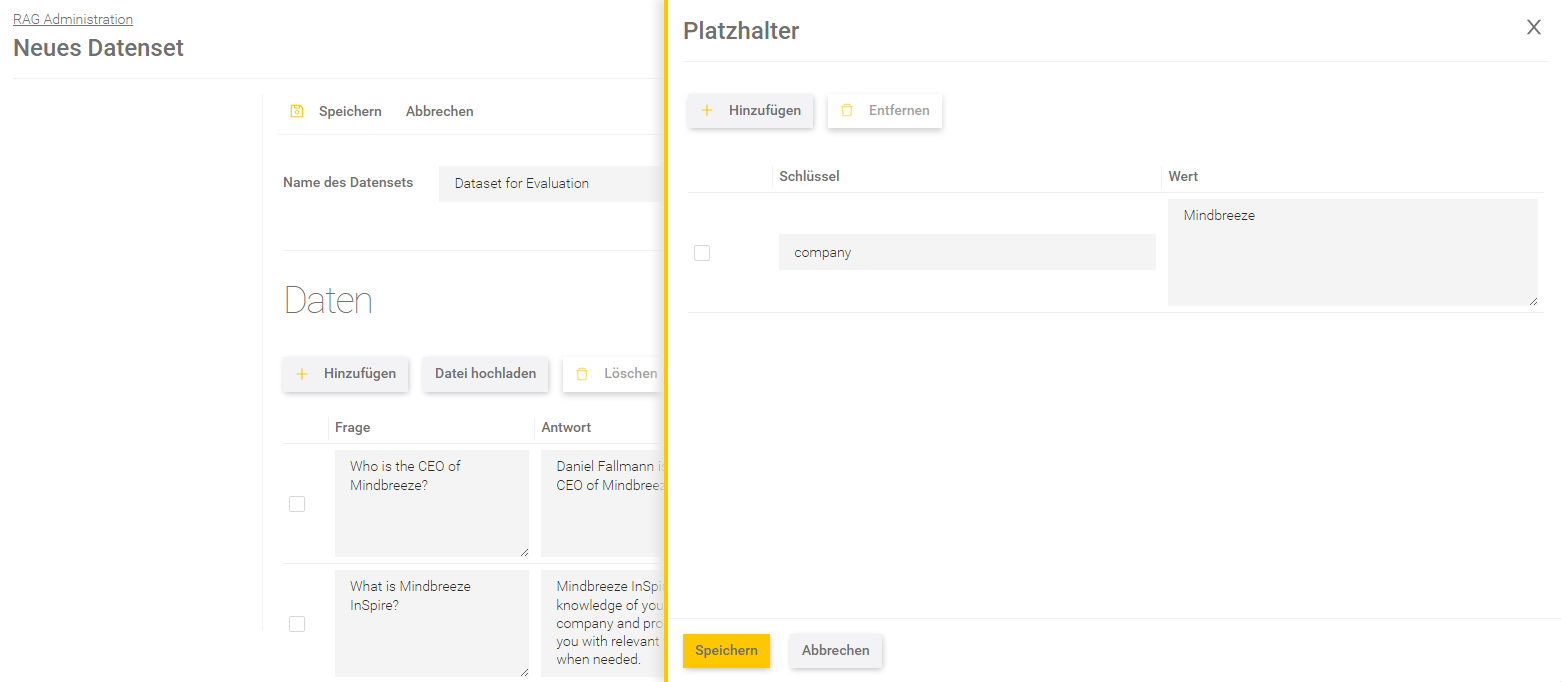
Platzhalter
Pro Frage können Platzhalter definiert werden, wo der Wert des Platzhalters in den Prompt eingefügt werden soll. Der Abgleich erfolgt anhand des Schlüssels.

Beschreibung | |
Key | Der Key ist die ID, die im Prompt mit geschwungenen Klammern definiert ist. Wenn zum Beispiel im Prompt steht „{xyz}“, dann ist der Key „xyz“. |
Wert | Der Wert kann beliebig definiert werden. Zum Beispiel kann man zum Schlüssel „company“ den Wert „Mindbreeze“ definieren. Hinweis: Wird als Wert regressiv wieder ein Schlüssel verwendet (wie zum Beispiel „{department}“), wird der Wert nicht mehr verändert. |
Speichern Sie die Änderungen in den Platzhaltern indem Sie im Fenster unten auf „Speichern“ klicken.
Klicken Sie schlussendlich auf „Speichern“, um das Datenset zu speichern.

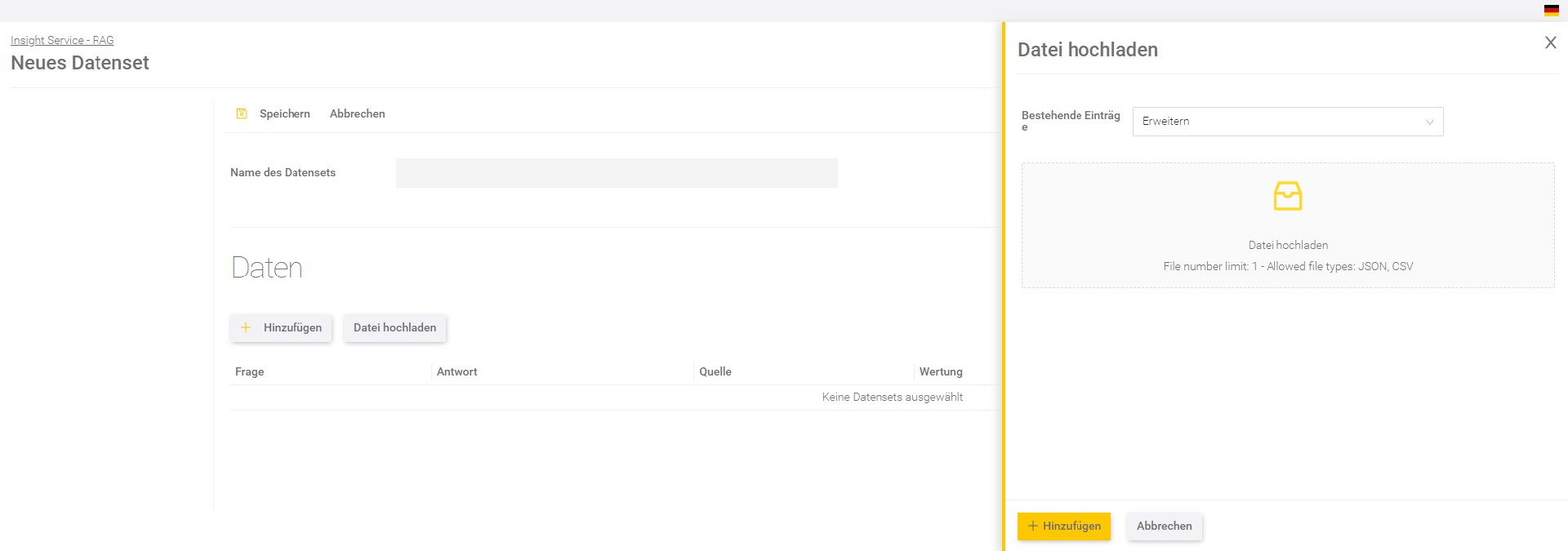
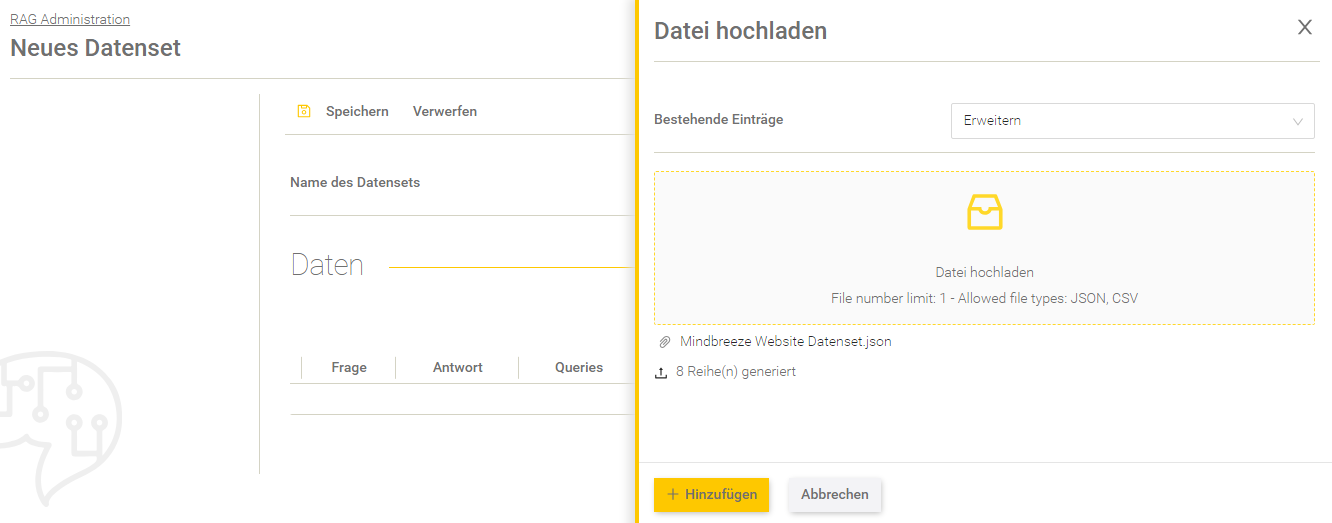
Hochladen einer Datei
Neben der manuellen Erstellung von Daten, kann auch eine Datei hochgeladen werden. Klicken Sie dafür auf „Datei hochladen“. Legen Sie mit der Einstellung „Bestehende Einträge“ fest, ob die Daten aus der Datei die bestehenden Einträge erweitern oder überschreiben soll.
Beachten Sie, dass nur eine Datei hochgeladen werden kann. Die Dateitypen JSON und CSV sind kompatibel.
Wurde die Datei erfolgreich geladen, klicken Sie auf „Hinzufügen“. Speichern Sie anschließend das Datenset.
JSON Upload
Pro Frage können folgende Werte angegeben werden:
Werte | Beschreibung | ||||||
Definiert die Frage. | |||||||
answer | Definiert die erwartete Antwort. | ||||||
queries | Liste an Queries für das Retrieval. Damit können Fragen eines Datensets mit zusätzlichen Informationen ausgestattet werden, um den Retrieval-Prozess zu unterstützen. Beispiel: Ein Datenset besitzt Aufforderungen anstatt Fragen. Um den Retrieval-Prozess zu unterstützen, können passende Fragen als queries zu den jeweiligen Aufforderungen hinzugefügt werden:
| ||||||
query_constraints | Liste an Query-Bedingungen. Damit können Einschränkungen für den Retrieval Prozess definiert werden, wie zum Beispiel die Verwendung bestimmter Dateiformate oder Metadaten. Beispiel: Der Retrieval-Prozess soll nur PDF-Dokumente zum Beantworten der Fragen verarbeiten:
| ||||||
pipeline_key | Definiert den Schlüssel einer Pipeline. Ein Pipeline Key kann vom Benutzer selbst definiert und dann ausgewählt werden. Damit lassen sich zum Beispiel Kennzahlen aus mehreren Pipelines errechnen, indem man durch Pipeline Keys Fragen für bestimmte Pipelines zuweist. | ||||||
remark | Eine Notiz mit Anmerkungen. | ||||||
contexts | Erwartete Kontexte (siehe Kontexte). Besitzt immer ein text und ein source Element:
| ||||||
prompt_placeholders | Verzeichnis von Schlüsseln zu Begriffen. Durch die Definition von prompt_placeholders kann der Prompt, der beim Generieren der Antwort an das LLM geschickt wird, angepasst und verfeinert werden. Ein prompt_placeholder besteht aus einem Schlüssel (Key) und einem Wert (Value), wobei diese beliebig definiert werden können. Der {key} Platzhalter im Prompt wird dann durch den benutzerdefinierten Key-Wert ersetzt, bevor der Prompt dann an das LLM geschickt wird. Damit ist es möglich den Prompt pro Frage zum Beispiel für die Evaluierung abzuwandeln. Achtung: Definierte prompt_placeholders dürfen nicht in der Frage oder in den queries verwendet werden, da diese im Retrieval-Prozess angewandt werden, wo die prompt_placeholder nicht ausgetauscht werden. |
Beispiel einer JSON-Datei:
"data": [
{
"question": "Wie kann ich eine SAML basierende Authentication in Mindbreeze InSpire konfigurieren?",
"answer": "Die Konfiguration von SAML in Mindbreeze erfolgt in vier Schritten: 1. Hinzufügen eines SSL Zertifikats 2. Konfiguration des SAML Authenticators 3. Konfiguration der Parameter 4.Aktivieren von SAML für einzelne Services",
"remark": "Das ist eine Notiz zur Frage",
"contexts": [
{
"text": "Die Konfiguration von SAML in Mindbreeze erfolgt in vier Schritten: 1. Hinzufügen eines SSL Zertifikats, das zur Erzeugung der Service Provider Metadaten verwendet wird 2. Konfiguration des SAML Authenticators 3. Konfiguration der Parameter (Session timeout und Metadata timeout) 4. Aktivieren von SAML für einzelne Services",
"source": "https://help.mindbreeze.com/de/index.php?topic=doc/SAML-Authentifizierung/index.html"
{
"text": "Noch ein Context",
"source": "noch_eine_quelle.pdf"
}
],
"pipeline_key": "spezielle-pipeline",
"query_constraints": [
"extension:pdf",
"fqcategory:Web"
],
"queries": [
"Welche Authorisierungsmöglichkeiten gibt es in {product}?",
"Was ist {authentication}?"
],
"prompt_placeholders": {
"product": "Mindbreeze InSpire",
"authentication": "SAML"
}
},
{
"question": "Die nächste Frage ..."
}
]
}
CSV Upload
Bei der CSV-Datei muss darauf geachtet werden, dass das Trennzeichen ein Semikolon ist und die Datei im UTF-8 Format gespeichert wurde, da die Bereiche gegebenenfalls nicht korrekt eingelesen werden können oder es Fehler beim Einlesen geben kann.
Die Datei muss einen Header haben.
Werte | Beschreibung |
Frage | |
answer | Erwartete Antwort |
remark | Notiz |
queries | Liste an Queries für das Retrieval. Die einzelnen Queries müssen jeweils mit einem Zeilenumbruch getrennt sein. |
queryconstraints | Liste an Bedingungen für die Query für das Retrieval. Die einzelnen Bedinungen müssen jeweils mit einem Zeilenumbruch getrennt sein. |
context / source | Text und Source eines Kontextes müssen mit „context“ und „source direkt aufeinanderfolgend angegeben werden. Sind mehrere Kontexte gewünscht, dann muss pro Kontext ein „context“ und ein „source“ Feld angelegt sein. |
pipelinename | Key einer Pipeline. |
pp_<key> | Diese Einstellung ist nur relevant, wenn man eigene Platzhalter im Prompt Template spezifiziert hat. Jeder Platzhalter braucht ein eigenes Feld beginnend mit „pp_“ und dem Platzhalter-Schlüssel. |
Beispiel einer CSV-Datei:
question;answer;remark;queries;queryconstraints;context;source;context;source;pipelinename;pp_product;pp_authentication
Wie kann ich eine SAML basierende Authentication in Mindbreeze InSpire konfigurieren?;Die Konfiguration von SAML in Mindbreeze erfolgt in vier Schritten: 1. Hinzufügen eines SSL Zertifikats 2. Konfiguration des SAML Authenticators 3. Konfiguration der Parameter 4.Aktivieren von SAML für einzelne Services;Eine Frage über Authentifizierung;"Welche Authorisierungsmöglichkeiten gibt es in {product}?
Was ist {authentication}?";"extension:pdf
fqcategory:Web";Die Konfiguration von SAML in Mindbreeze erfolgt in vier Schritten: 1. Hinzufügen eines SSL Zertifikats, das zur Erzeugung der Service Provider Metadaten verwendet wird 2. Konfiguration des SAML Authenticators 3. Konfiguration der Parameter (Session timeout und Metadata timeout) 4. Aktivieren von SAML für einzelne Services;https://help.mindbreeze.com/de/index.php?topic=doc/SAML-Authentifizierung/index.html;Ein zweiter Kontext;noch_eine_quelle.pdf;spezielle_pipeline;Mindbreeze InSpire;SAML
Datensets exportieren
Datensets können als JSON- oder als CSV-Datei exportiert werden.
Um ein oder mehrere Datensets zu exportieren, müssen die jeweiligen Datensets ausgewählt werden. Setzen Sie dafür ein Häkchen neben den jeweiligen Datensets, um diese auszuwählen. Ist mindestens ein Datenset ausgewählt, können Sie bei „Export“ im Drop-Down-Menü das Dateiformat auswählen.

Klicken Sie auf das gewünschte Dateiformat und Sie erhalten anschließend ein Pop-Up-Fenster, wo sich der Download-Link für das exportierte Datenset befindet.
Sind mehrere Datensets gleichzeitig ausgewählt, werden diese in der gewählten Art verpackt und in einem ZIP-File exportiert.
Hinweis: Falls kein Datenset ausgewählt ist, sind beide Dateiformat-Optionen ausgegraut und nicht auswählbar.
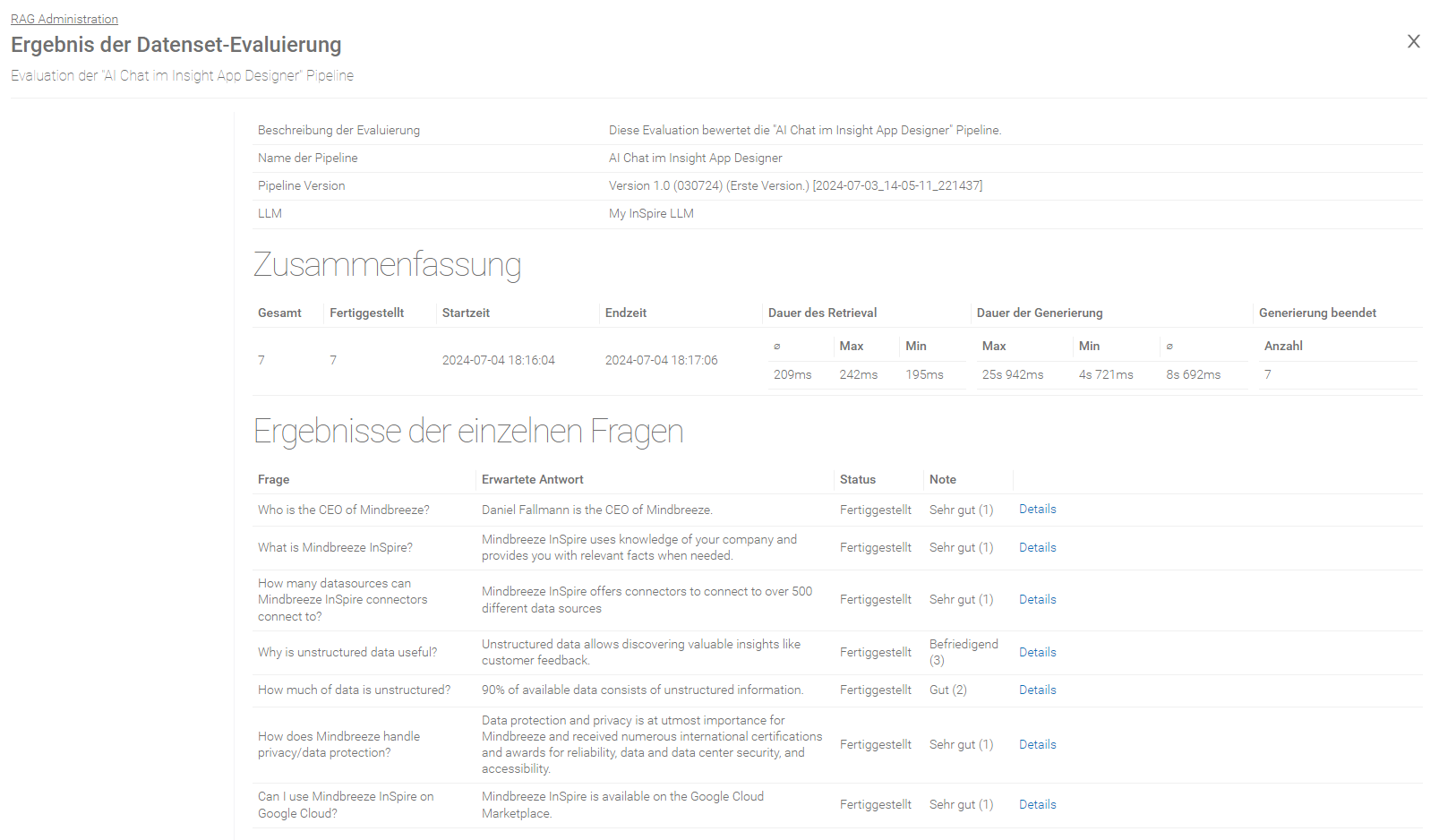
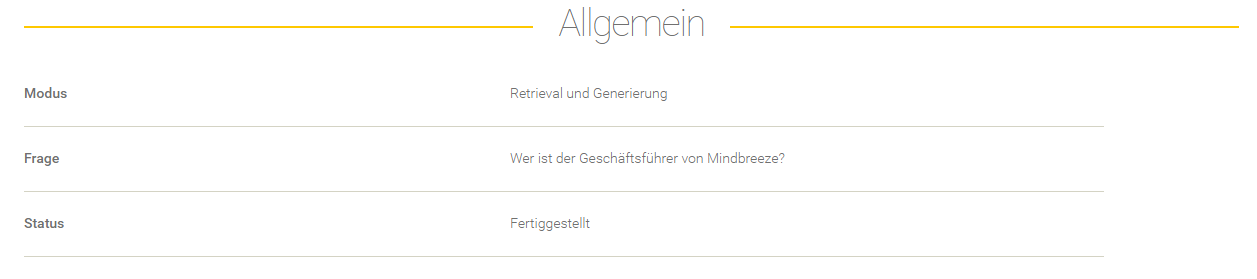
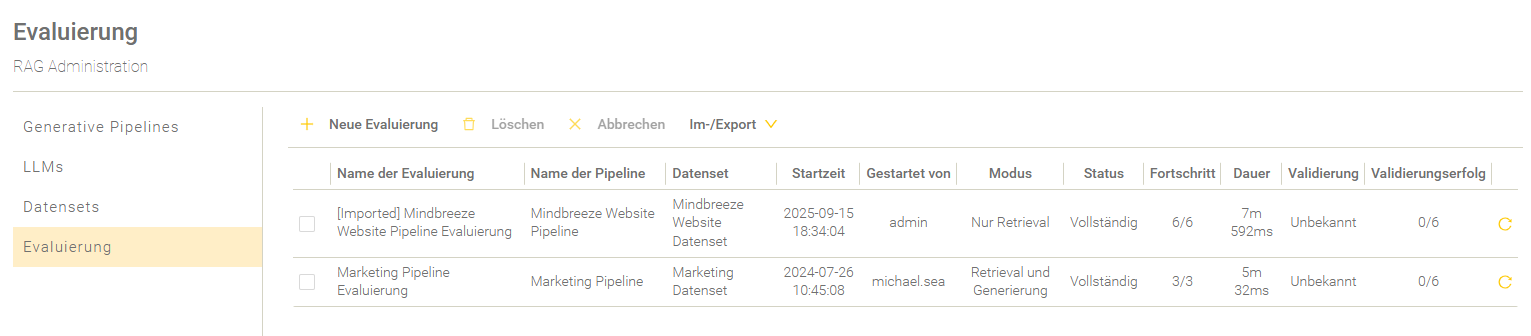
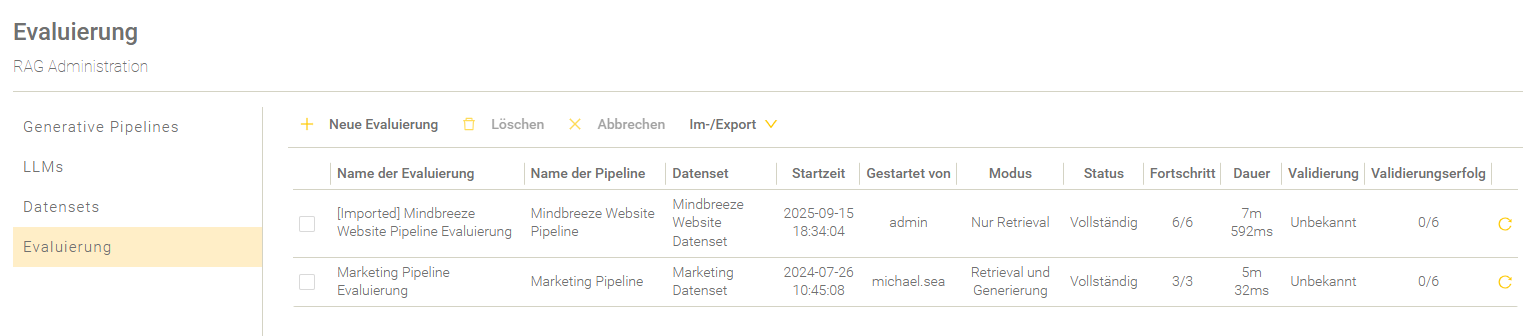
Evaluierung einer Pipeline
Um die Effektivität einer Pipeline zu testen, gibt es die Möglichkeit, Pipelines dahingehend zu evaluieren.
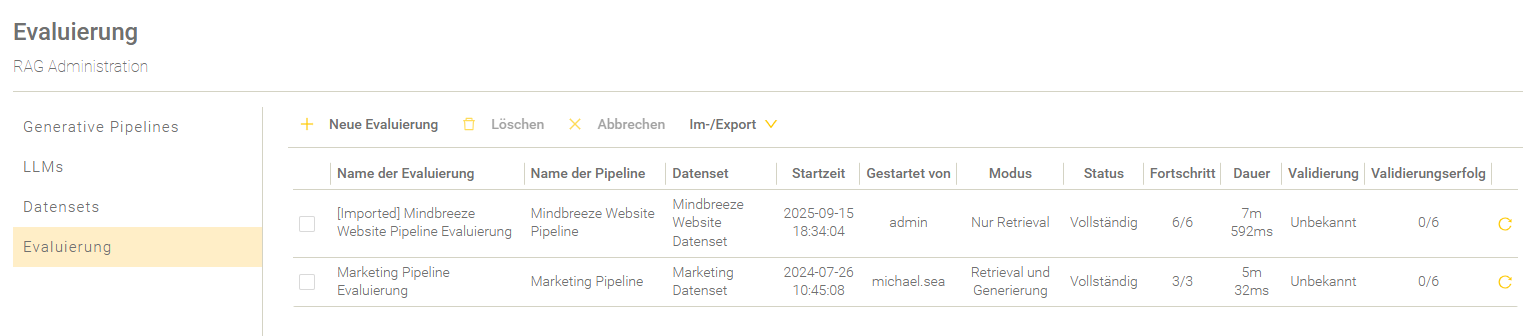
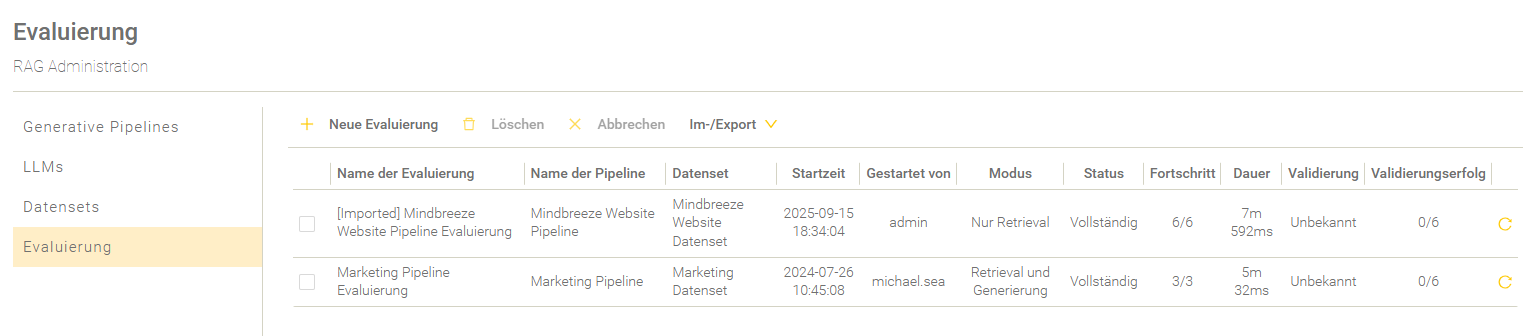
Übersicht
In der Übersicht werden die Evaluierungen aufgelistet und entsprechend der Startzeit gereiht.
Einstellung | Beschreibung |
Der Name der Evaluierung. | |
Name der Pipeline | Der Name der Pipeline. |
Datenset | Der Name des Datensets. |
Startzeit | Der Zeitpunkt, wann die Evaluierung gestartet wurde. |
Gestartet von | Der Name des Nutzers, der die Evaluierung gestartet hat. |
Modus | Der gewählte Evaluierungsmodus. Für mehr Informationen zu den Evaluierungsmodi, siehe Neue Evaluierung anlegen. |
Status | Der aktuelle Status der Evaluierung. Die folgenden Stati des Evaluierungsprozesses sind möglich: „…“ – Die Evaluierung befindet sich in der Warteschlange. „Läuft“ – Die Evaluierung ist im Gange. „Unvollständig“ - Mindestens eine Frage besitzt nicht den Status „Fertiggestellt“. „Vollständig“ - Alle Fragen besitzen den Status „Fertiggestellt“. |
Fortschritt | Die Anzahl der bereits prozessierten Fragen im Vergleich mit der Anzahl aller insgesamt zu prozessierenden Fragen. |
Dauer | Die Dauer des Evaluierungsdurchlaufs. |
Validierung | Zeigt an, ob die Validierung auf Basis der ausgewählten Metriken erfolgreich durchgeführt wurde. Schlägt eine Metrik fehl, wird die gesamte Validierung als fehlgeschlagen gewertet. Eine Metrik schlägt dann fehl, wenn sie die Bewertungsnote 5 erhält. |
Validierungserfolg | Zeigt die Anzahl der Fragen an, die bei der Validierung den Wert „true“ bzw. als erfolgreich gewertet wurden. |
Evaluierung wiederholen | Solange eine Evaluierung läuft wird in der letzten Spalte ein Lade-Symbol angezeigt. Ist eine Evaluierung beendet, dann wird in der letzten Spalte ein „Wiederholen“ Symbol angezeigt. Wenn man auf das Symbol klickt, kann man eine neue Evaluierung starten, welche initial bereits mit der Konfiguration der gewählten Evaluierung ausgefüllt wird. |
Neue Evaluierung anlegen
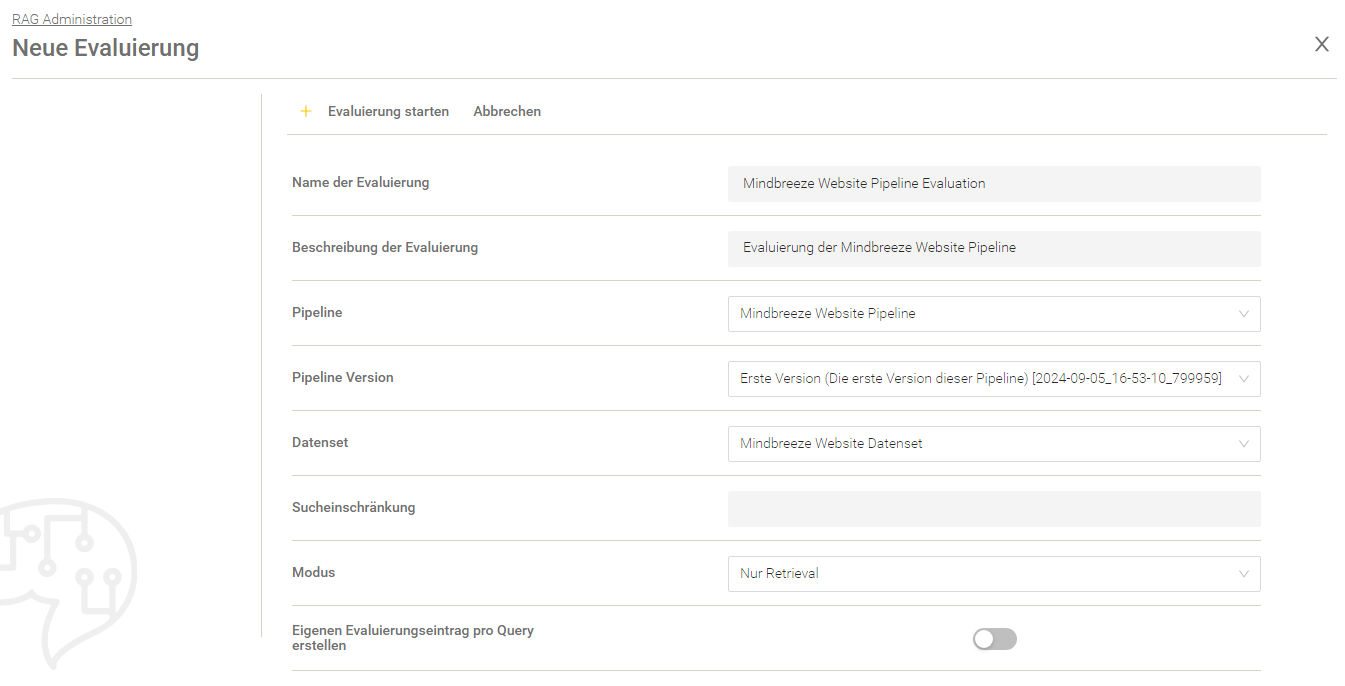
Mit „Neue Evaluierung“ kann eine neue Evaluierung angelegt werden.

Einstellung | Beschreibung |
Der Name der Evaluierung. | |
Beschreibung der Evaluierung | Die Beschreibung der Evaluierung. Hier kann man erklären was man evaluieren möchte oder welche Einstellung geändert oder angepasst wurde. |
Pipeline | Die Auswahl der Pipeline. |
Pipeline Version | Die Version der gewählten Pipeline. |
Datenset | Das Datenset auf dessen Basis die Evaluierung erstellt werden soll. |
Sucheinschränkung | Hier kann eine Sucheinschränkung für die gesamte Evaluierung definiert werden. Der hier definierte Wert wird (sofern vorhanden) als Bedingung in die Suche mit eingenommen. |
Modus | Die folgenden Modi stehen zur Auswahl:
|
Eigenen Evaluierungseintrag pro Query erstellen (wenn „Modus“ auf „Nur Retrieval“ gesetzt ist) | Wenn aktiviert, wird für jede Query des Datensets ein eigener Evaluierungseintrag erstellt. Standardeinstellung: Deaktiviert. |
LLM der Pipeline überschreiben (wenn „Modus“ auf „Nur Generierung“ oder „Retrieval und Generierung“ gesetzt ist) | Wenn aktiviert, kann ein anderes LLM für die Generierung verwendet werden, als in der Pipeline definiert. |
Metriken | Listet die Metriken auf, die für die Evaluierung verwendet werden. Durch den Knopf „Hinzufügen“ können Metriken für die Evaluierung ausgewählt werden. Hinweis: Je mehr Metriken für die Berechnung ausgewählt werden, desto länger dauert die Auswertung. Weitere Informationen zu den verfügbaren Metriken finden Sie im folgenden Kapitel Verfügbare Metriken. |
Verfügbare Metriken
Die folgenden Metriken stehen zur Verfügung:

Beschreibung | |
Bilingual Evaluation Understudy (BLEU) | Ist ein standardisierter Algorithmus, der die Qualität von maschinell übersetzten Texten evaluiert. Die Qualität wird hierbei als Übereinstimmung zwischen der maschinellen und der menschlichen Übersetzung definiert. Eine höhe Qualität ist gegeben, wenn die maschinelle Übersetzung der menschlichen Übersetzung sehr ähnlich oder gleich ist. |
Context Recall | „Context Recall“ bewertet den Anteil relevanter Dokumente (oder Informationen), die erfolgreich abgerufen wurden. Es legt Wert darauf, alle wichtigen Ergebnisse zu erfassen, um sicherzustellen, dass nichts Wesentliches übersehen wird. |
Factual Correctness | „Factual Correctness““ ist eine Metrik, die bewertet, wie sachlich genau die generierte Antwort im Vergleich zur erhaltenen Antwort ist. |
Faithfulness | „Faithfulness“ bewertet, wie genau eine Antwort mit dem abgerufenen Kontext übereinstimmt. Eine Antwort ist dann valide, wenn alle ihre Behauptungen durch die bereitgestellten Informationen gestützt werden. |
Recall-Oriented Understudy for Gisting Evaluation (ROUGE) | Ist ein standardisiertes Set an Metriken. Diese Metrik evaluiert die automatische Zusammenfassung und maschinelle Übersetzungssoftware bei der Verarbeitung natürlicher Sprache. Bei der Evaluierung werden automatisch generierte Zusammenfassungen oder Übersetzungen mit von Menschen erstellten Zusammenfassungen oder Übersetzungen verglichen. Hierbei ist zu beachten, dass diese Metrik nicht auf die Groß und Kleinschreibung achtet. |
Um die Evaluierung zu speichern und zu starten, klicke auf „Evaluierung starten“. Nachdem die Evaluierung durchgeführt wurde, können die Ergebnisse analysiert werden.

Evaluierungsübersicht
Zusammenfassung des Evaluierungsergebnisses

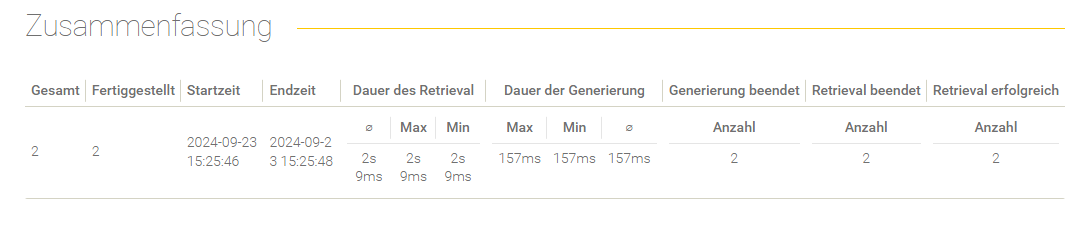
Allgemeine Zusammenfassung
Einstellung | Beschreibung |
Die Anzahl der zu verarbeiteten Anfragen. | |
Fertiggestellt | Die Anzahl der verarbeiteten Anfragen. |
Startzeit | Das Datum und die Uhrzeit wann die Evaluierung gestartet wurde. |
Endzeit | Das Datum und die Uhrzeit wann die Evaluierung beendet wurde. |
Dauer des Retrieval | Die Dauer des Retrieval wird mit den folgenden Werten bestimmt:
|
Dauer der Generierung | Die Dauer der Generierung wird mit den folgenden Werten bestimmt:
|
Validierungserfolg | Zeigt die Anzahl der Fragen an, die bei der Validierung den Wert „true“ bzw. als erfolgreich gewertet wurden. |
Retrieval erfolgreich | Die Anzahl der Anfragen bei denen das Retrieval erfolgreich war. |
Generierung beendet | Die Anzahl der Anfragen bei denen die Generierung erfolgreich beendet wurde. |
Retrieval beendet | Die Anzahl der Anfragen bei denen das Retrieval beendet wurde. |
Zusammenfassung der Metriken
Die Werte für jede Metrik liegen im Bereich von 1 (bestes Ergebnis) bis 5 (schlechtestes Ergebnis). Für jede Metrik, die für eine Evaluierung ausgewählt wurde, werden in der Zusammenfassungstabelle folgende Informationen angezeigt.
Beschreibung | |
Min | Das schlechteste Ergebnis für diese Metrik. |
Ø | Das durchschnittliche Ergebnis für diese Metrik. |
Max | Das beste Ergebnis für diese Metrik. |
Erfolgreiche Validierungen | Anzahl der Fragen, die für die jeweilige Metrik als valide ausgewiesen wurde. Diese Information wird angezeigt unabhängig davon, ob die Metrik für die generelle Validierung herangezogen wird oder nicht. |
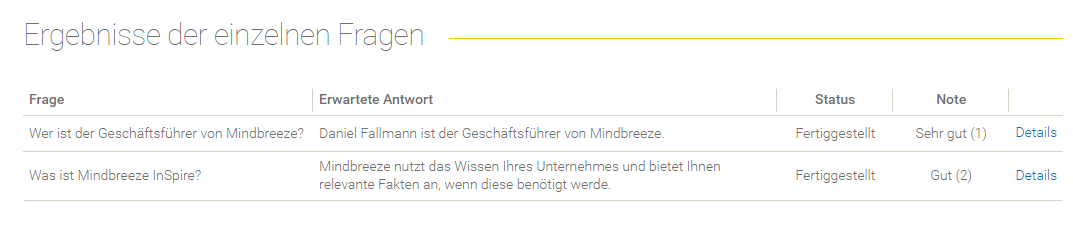
Übersicht der Ergebnisse der einzelnen Fragen

Feld | Beschreibung |
Frage | Die Frage, die im Datenset definiert wurde. |
Erwartete Antwort | Die erwartete Antwort, die im Datenset definiert wurde. |
Status | Der Status der Evaluierung (z. B. „Fertiggestellt“, „Fehlgeschlagen“ und andere). |
Valide | Wenn Metriken zur Evaluierung eingesetzt wurden, wird hier angezeigt, ob dieser Eintrag als valide eingestuft wurde. Zur Einstufung werden nur die Ergebnisse der Metriken herangezogen, die auch für die Validierung ausgewählt wurden. |
Details | Hier findet man die Details der Evaluierung einer Frage. |
Angereichertes Datenset aus einer Evaluierung
Pro Evaluierung kann ein angereichertes Datenset heruntergeladen oder als neues Datenset gespeichert und weitergenutzt werden. Je nach Modus wird das Datenset mit unterschiedlichen Daten angereichert:
Modus | Anreicherung mit… |
Retrieval and Generation |
|
Retrieval only | retrievte Kontexte. |
Generation only | generierte Antworten. |
Speicherung des angereicherten Datensets als neues Datenset
Mit „Als Datenset speichern“ kann das angereicherte Datenset als neues Datenset gespeichert werden.
Export des erhaltenen Datensets aus der Evaluierung
Angereicherte Datensets können mit „Exportieren“ als JSON oder CSV Datei heruntergeladen werden.

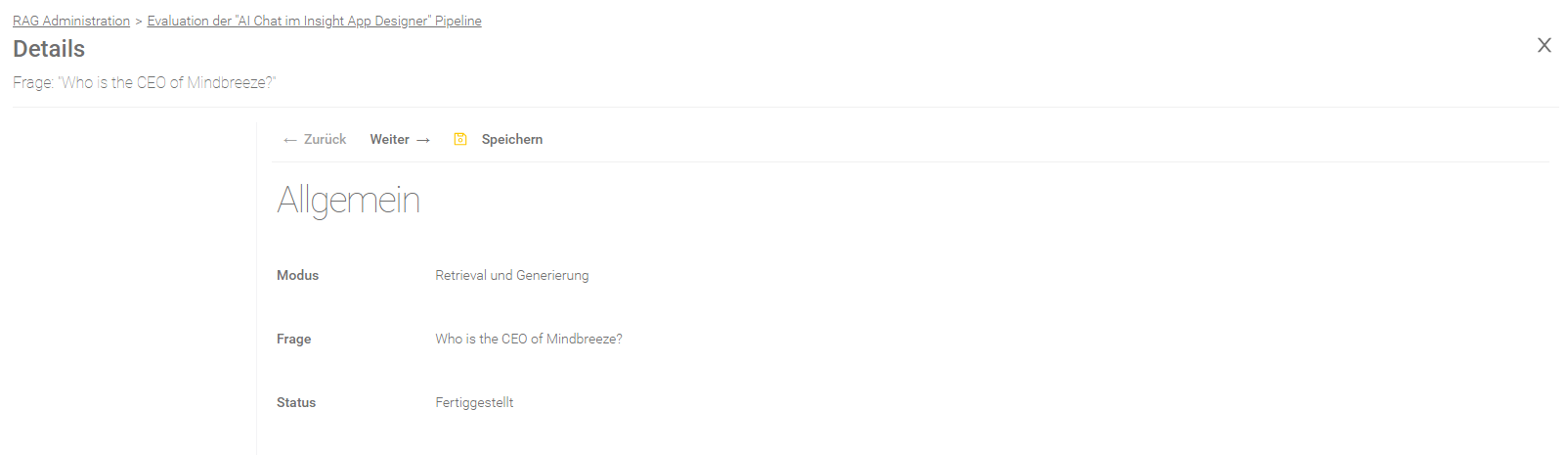
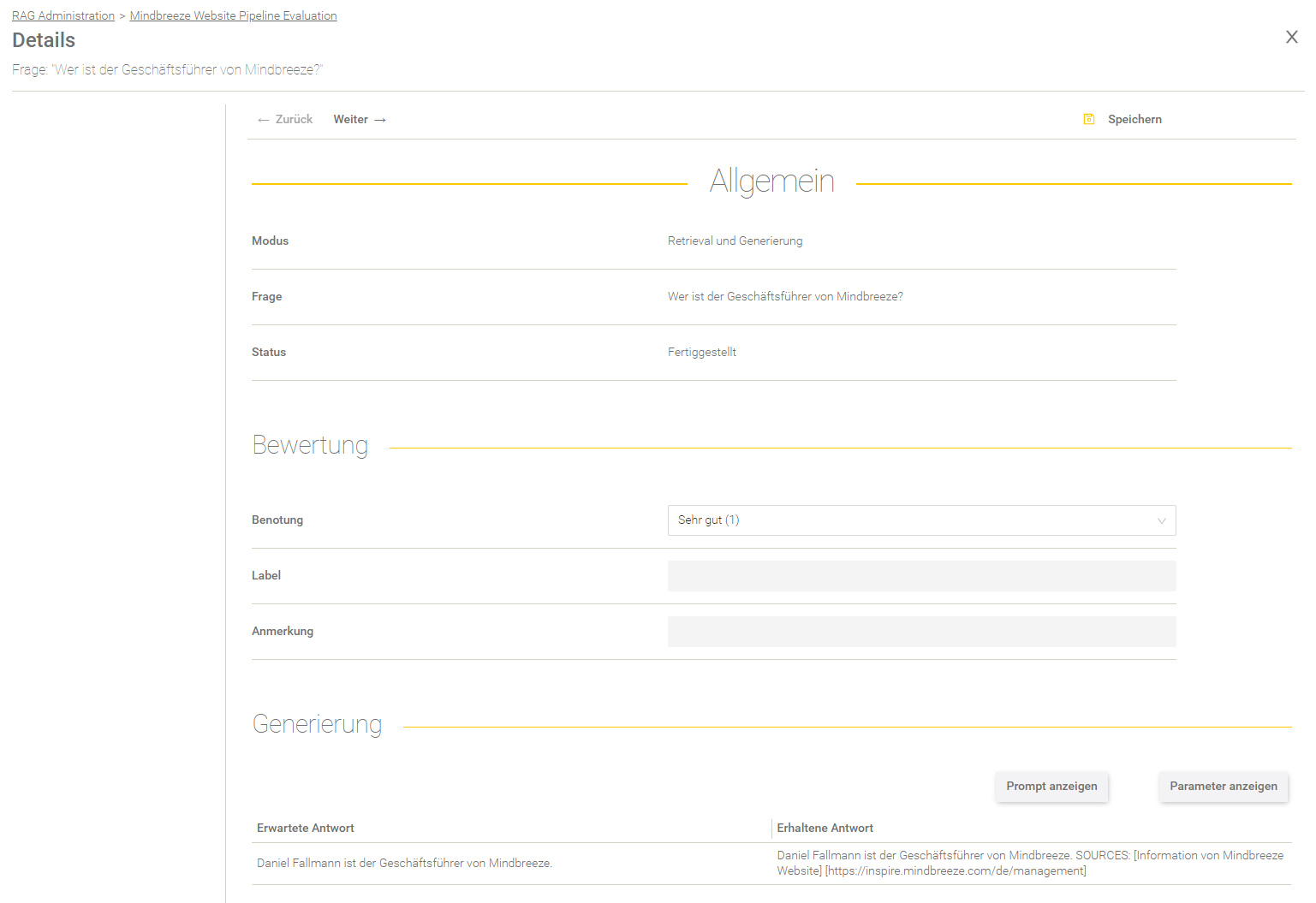
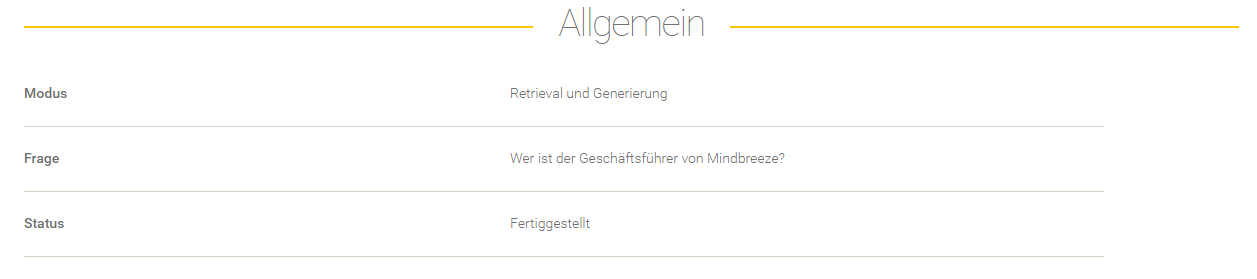
Ergebnis einer Frage

Allgemein

Feld | Beschreibung | ||||||||||||||||
Der ausgewählte Modus der Evaluierung. Für mehr Informationen, siehe Neue Evaluierung anlegen. | |||||||||||||||||
Frage | Die verarbeitete Frage. | ||||||||||||||||
Status | Folgende Stati sind möglich:
| ||||||||||||||||
Fehlernachricht | Falls der Status „Fehlgeschlagen“ lautet, findet man hier einen Hinweis zum Fehler. |
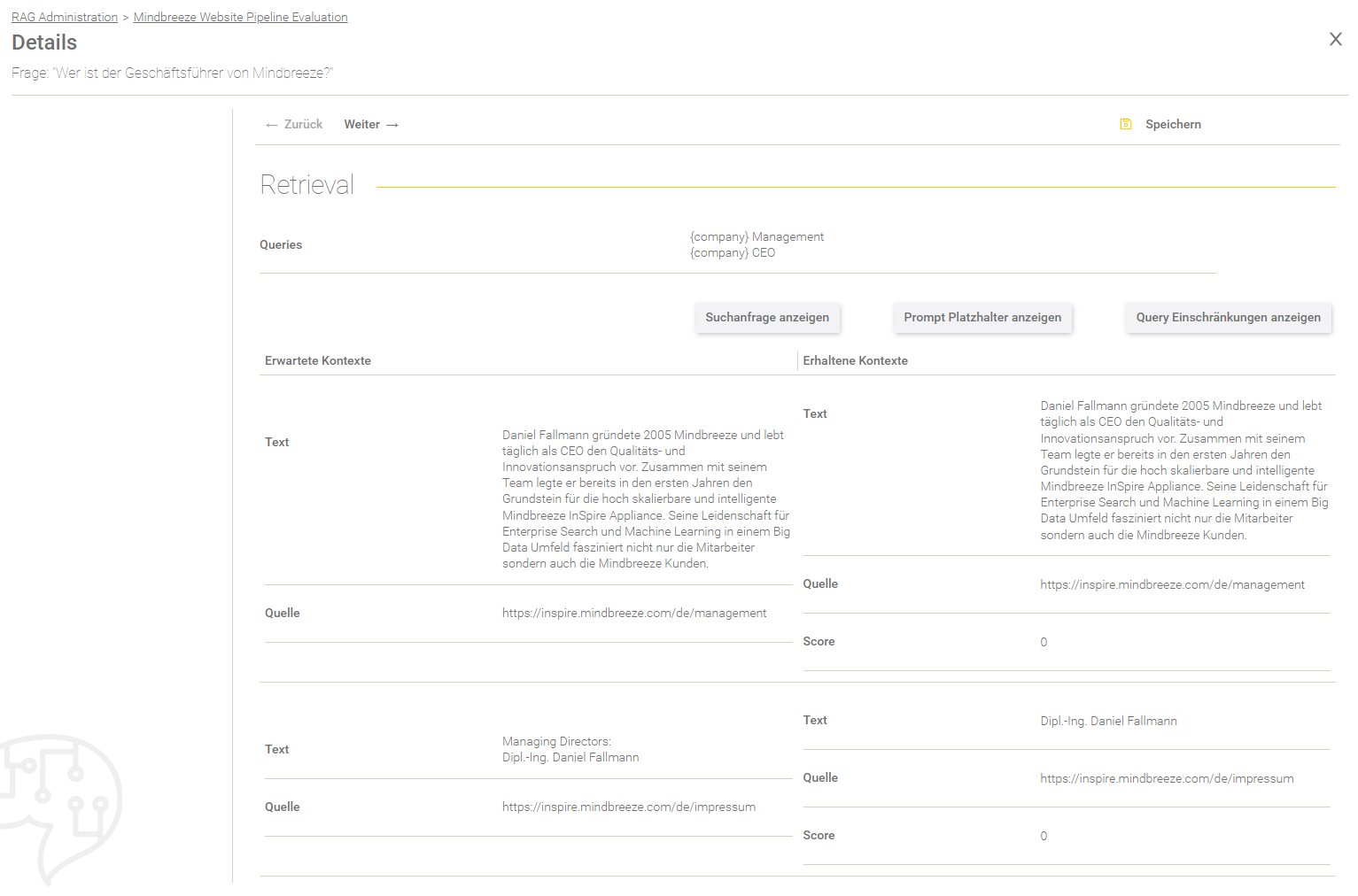
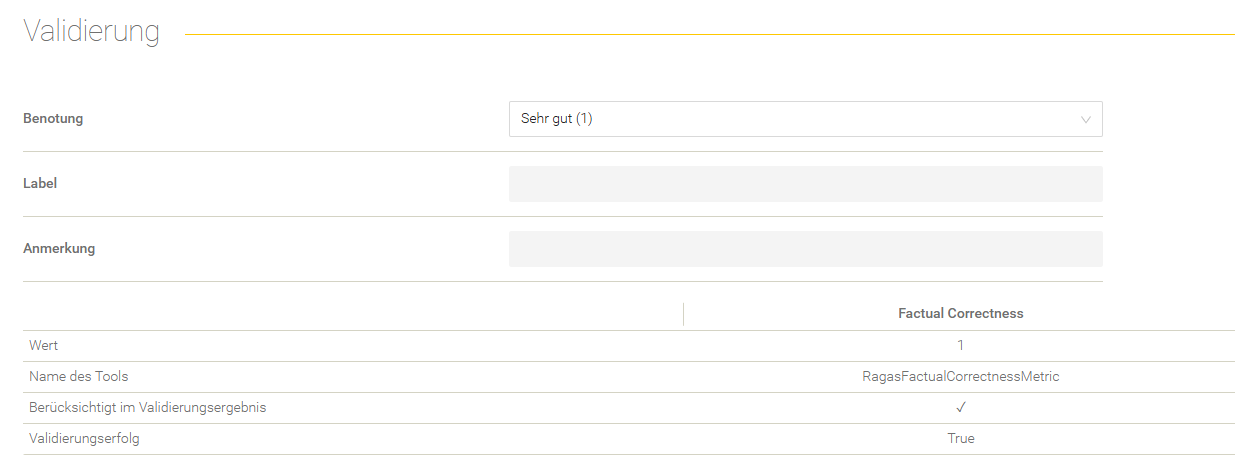
Validierung
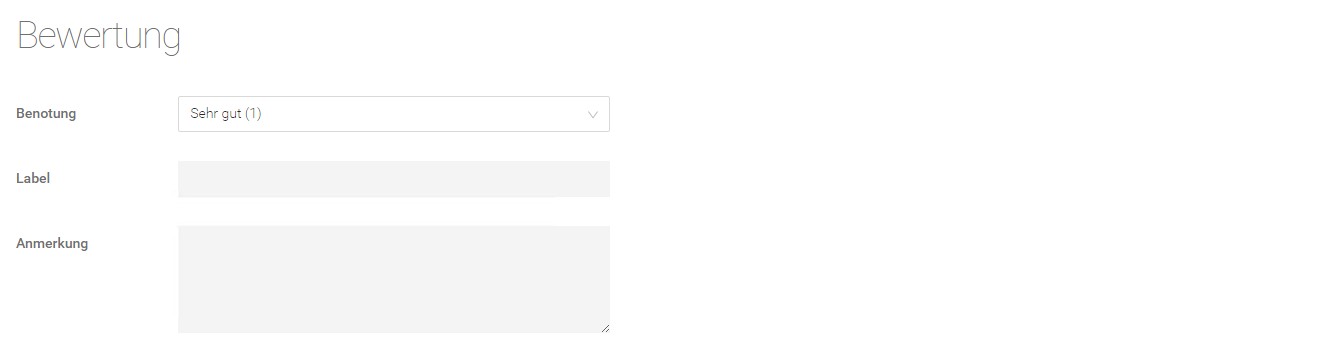
Hier gibt es die Möglichkeit, das Validierungsergebnis für eine Frage zu bewerten.
Einstellung | Beschreibung |
Hier kann eine Note von 1 (Sehr gut) bis 5 (Nicht genügend) vergeben werden, um die Verarbeitung der Frage zu bewerten. | |
Label | Hier kann ein selbstdefiniertes, individuelles Label vergeben werden. |
Anmerkung | Hier kann man eine Anmerkung zum Evaluierungsergebnis hinterlassen. |
Nach dem Einfügen/Ändern einer Bewertung muss das Ergebnis mit „Speichern“ gespeichert werden.
Übersicht der Metriken
In der Übersicht der Metriken werden die Werte aller Metriken für die jeweilige Frage angezeigt.
Beschreibung | |
Wert | Errechneter Wert der jeweiligen Metrik. |
Name des Tools | Name des Tools, welches für die Errechnung des Wertes verwendet wurde. |
Berücksichtigt im Validierungsergebnis | Gibt an, ob diese Metrik für das finale Validierungsergebnis berücksichtigt wurde. |
Validierungserfolg | Gibt an, ob der errechnete Wert der jeweiligen Metrik als valide oder nicht valide eingestuft wird. Jeder Wert kleiner gleich 4 wird hierbei als valide eingestuft. Der Wert 5 gilt als nicht valide. |
Generierung
Dieser Bereich gibt Aufschluss über die Antwortgenerierung.

Option | Beschreibung |
Der effektive Prompt wird angezeigt. | |
Parameter anzeigen | Die verwendeten Parameter für die Generierung werden angezeigt, wie z.B. Temperatur und andere Parameter. |
In der Tabelle darunter findet man die erwartete Antwort der Frage (im Datenset definiert) gegenübergestellt mit der erhaltenen Antwort des LLM.
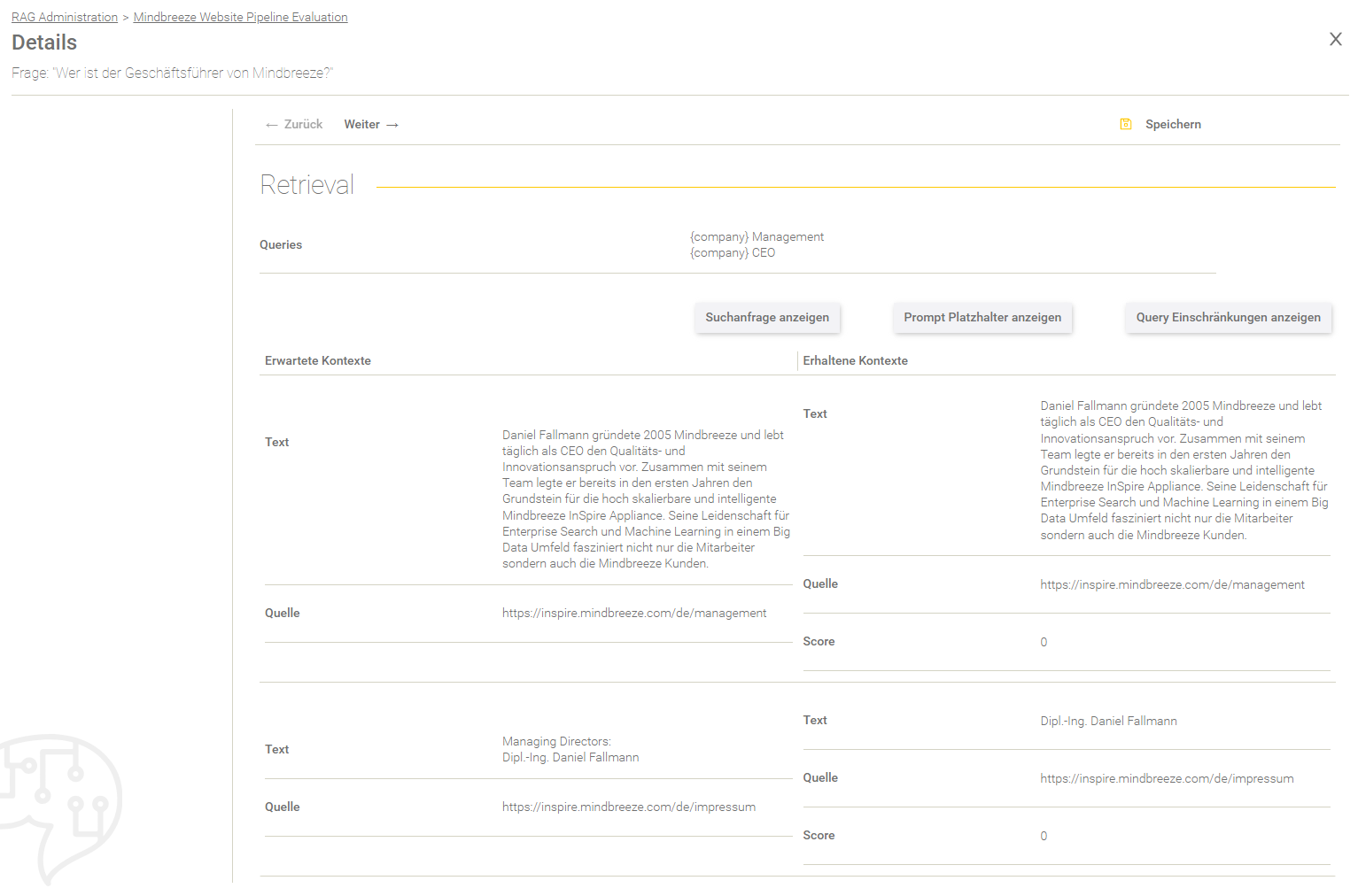
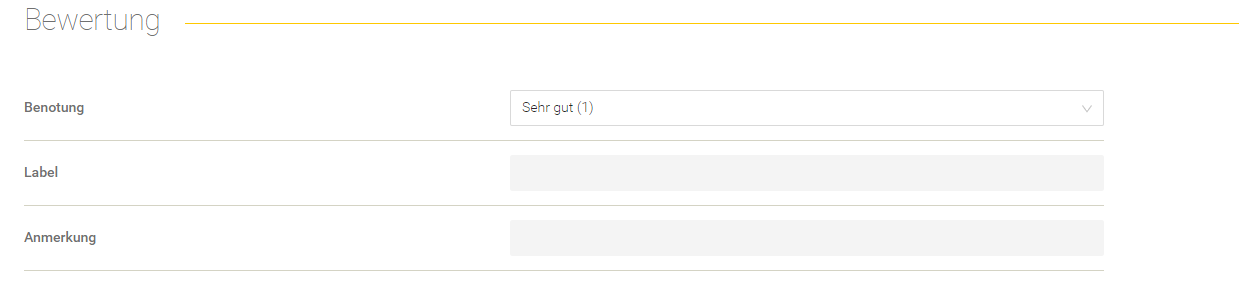
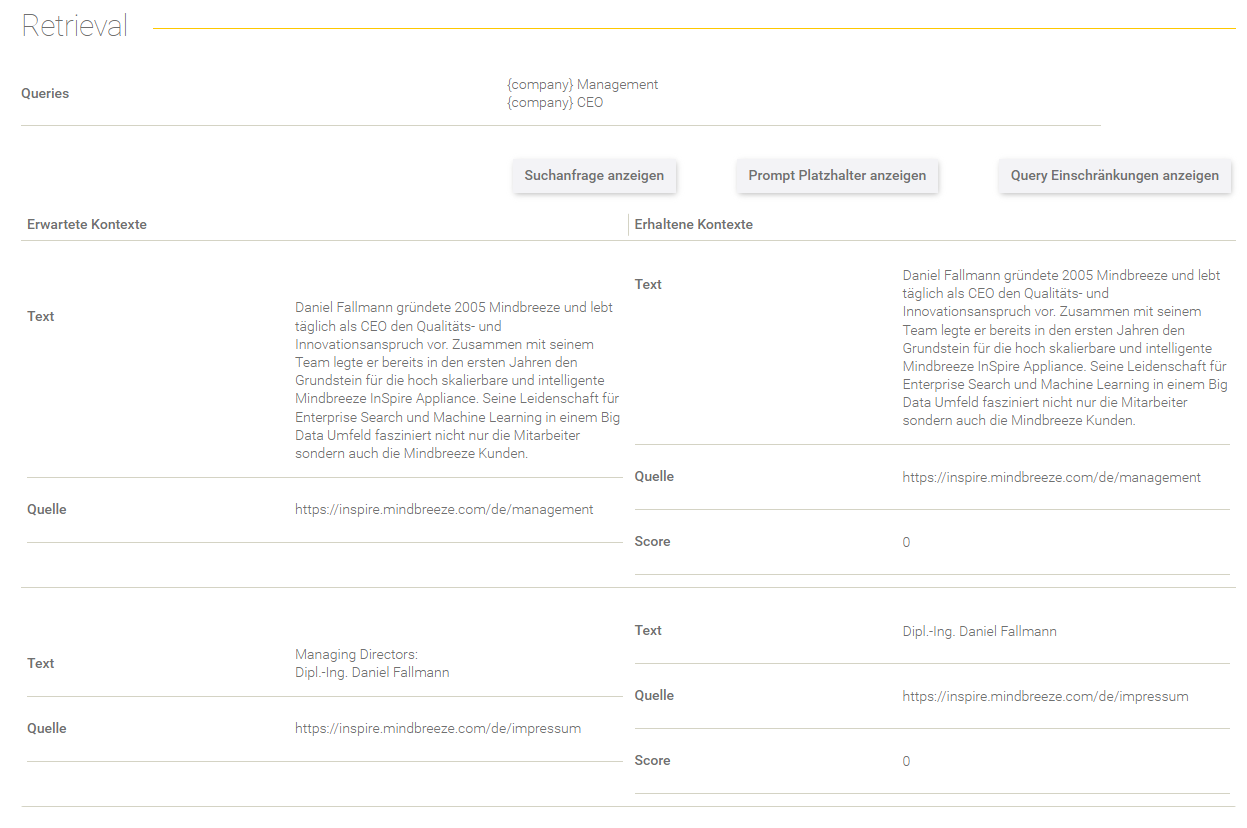
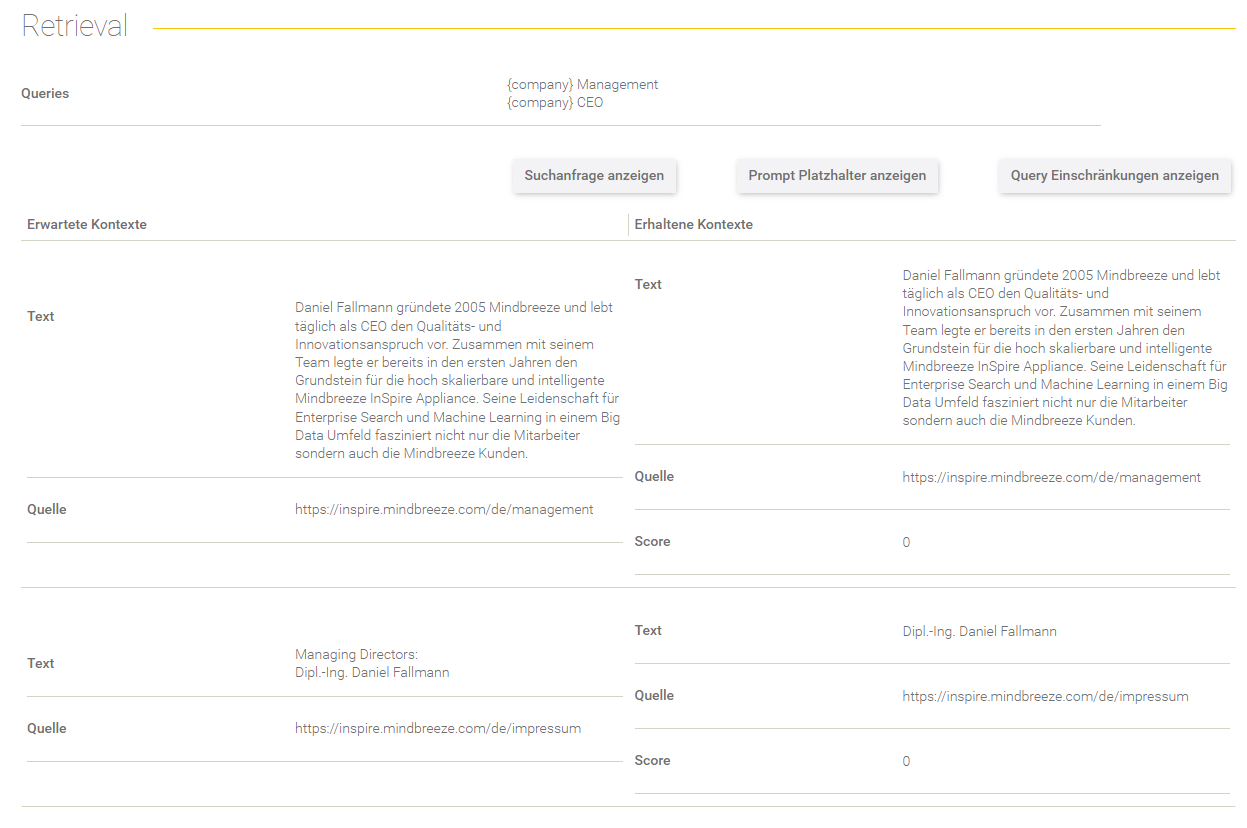
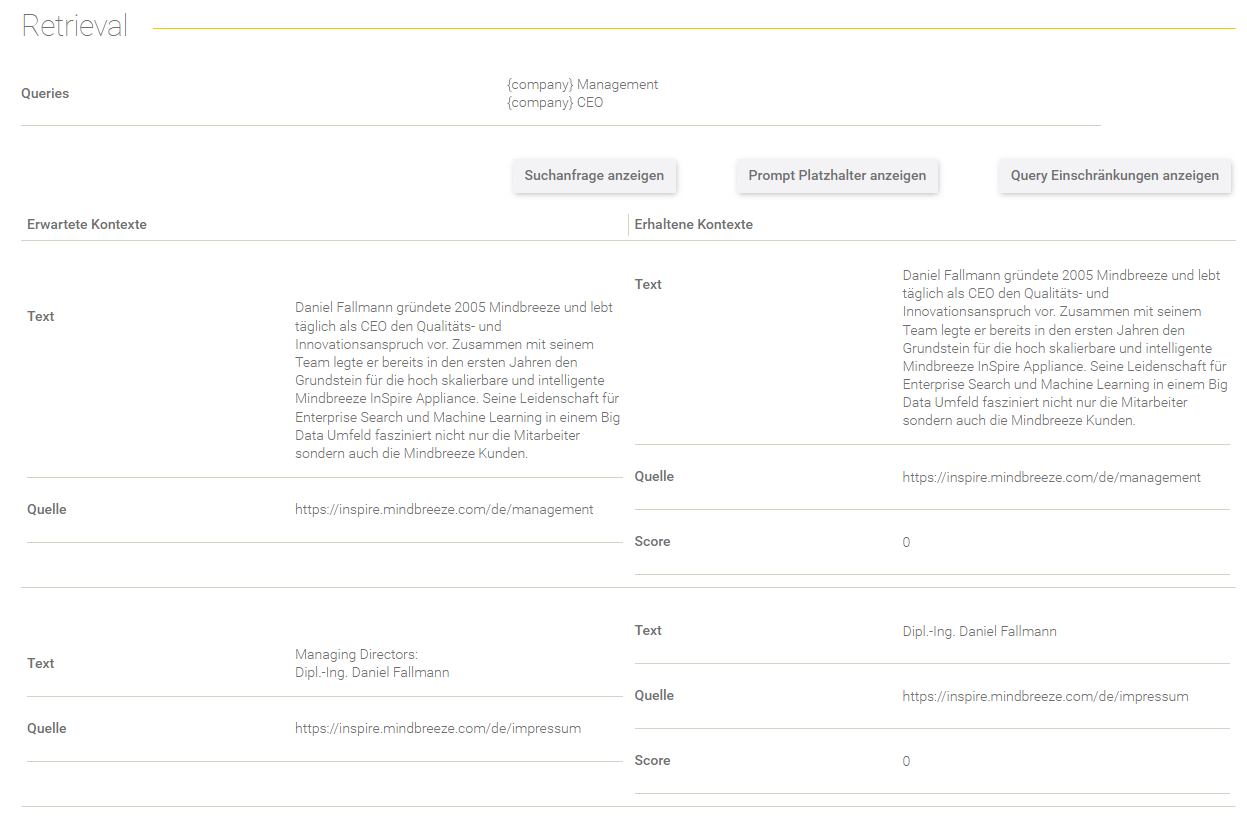
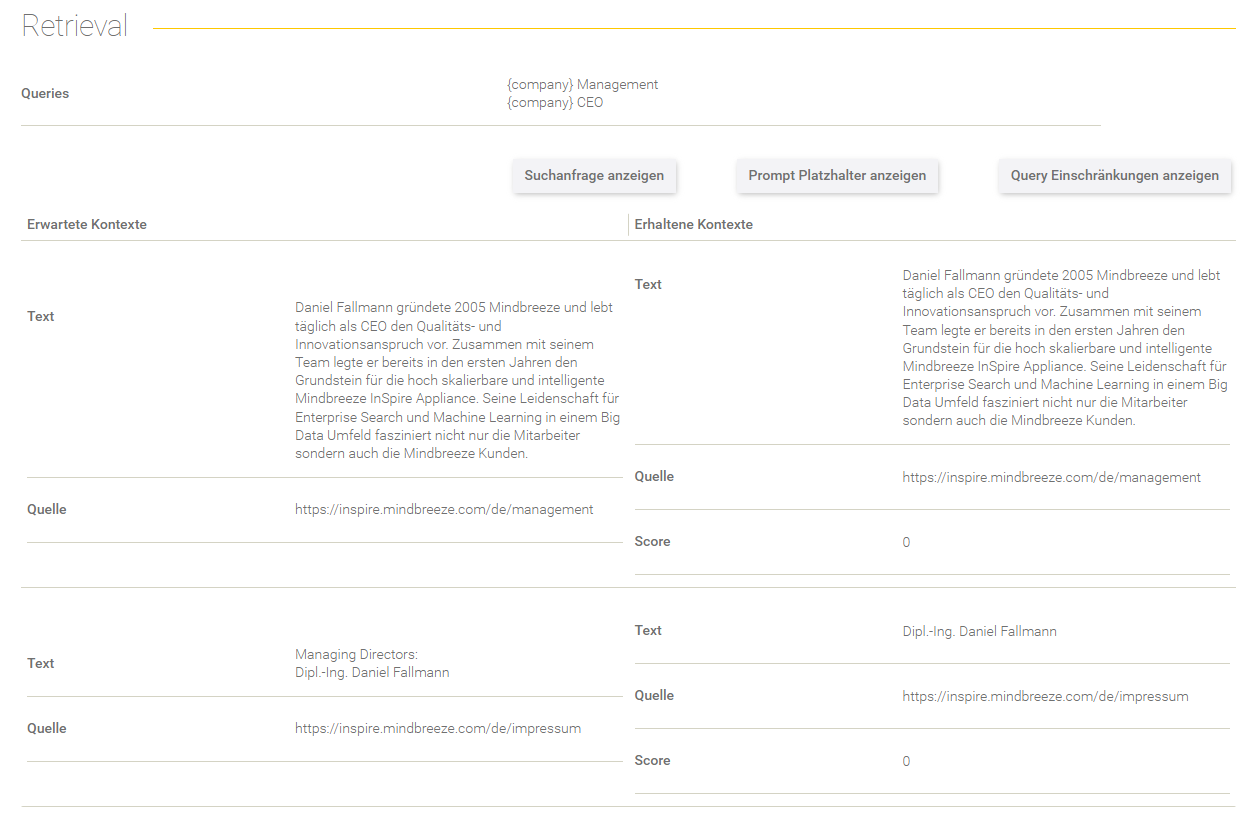
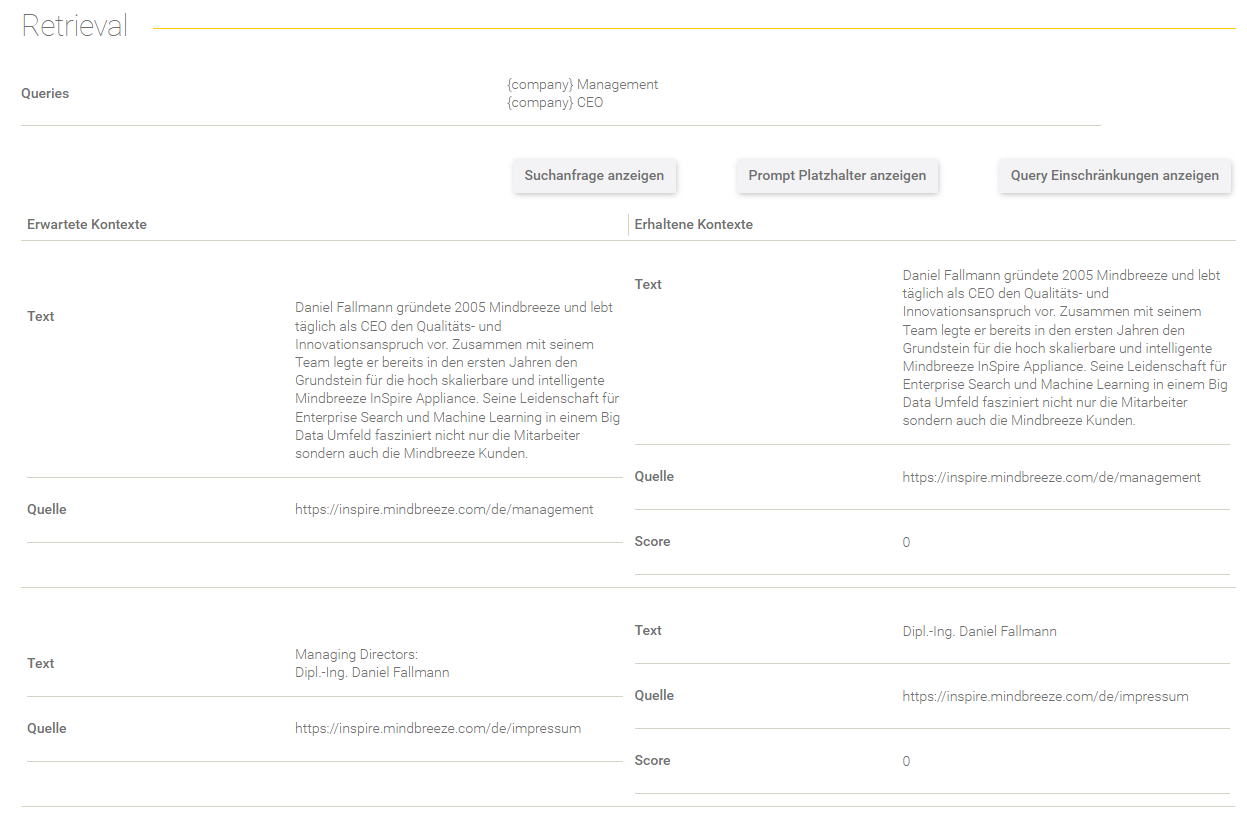
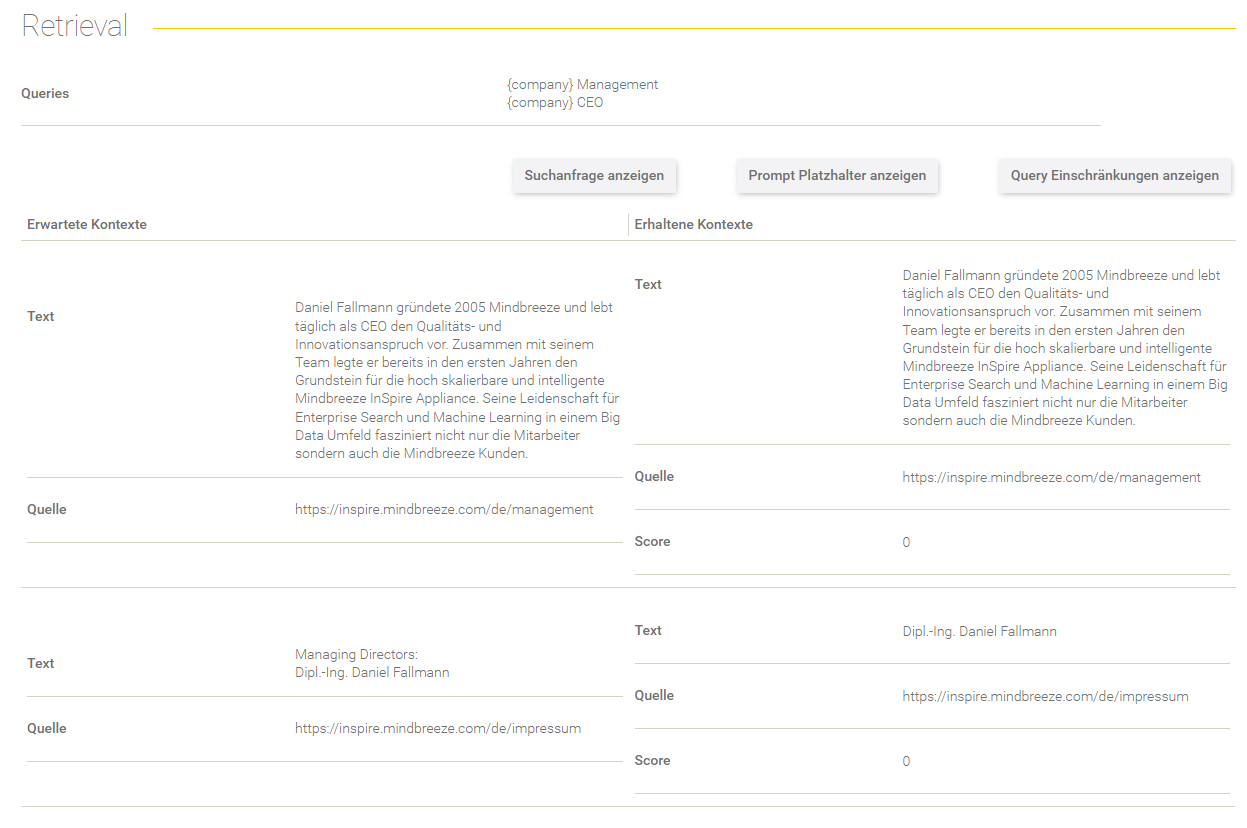
Retrieval
Dieser Bereich gibt Aufschluss über den Retrieval Prozess.

Feld/Optionen | Beschreibung |
Queries | Hier werden die Queries angezeigt, mit denen die Suchanfrage ergänzt wurde. |
Suchanfrage anzeigen | Hier sieht man die effektive Suchanfrage, die an den Client Service gesendet wurde. |
Prompt Platzhalter anzeigen | Hier werden die gegebenen Prompt Platzhalter aus dem Datenset-Eintrag aufgelistet. |
Query Einschränkungen anzeigen | Hier werden die gegebenen Query Einschränkungen aus dem Datenset-Eintrag aufgelistet. |
In der Tabelle werden die erwarteten Kontexte (im Datenset definiert) gegenübergestellt mit den erhaltenen Kontexten aus dem Retrieval Prozess.
Evaluierungen exportieren und importieren
Evaluierungen können nur als JSON-Datei exportiert werden.
Das Importieren und Exportieren von Evaluierungen kann mit „Im-/Export“ durchgeführt werden.
Export
Um eine (oder mehrere) Evaluierung(en) zu exportieren, müssen die jeweiligen Evaluierungen ausgewählt werden. Setzen Sie dafür ein Häkchen neben den jeweiligen Evaluierungen, um diese auszuwählen. Ist mindestens eine Evaluierung ausgewählt, können Sie bei „Im-/Export“ die Option „Exportieren“ auswählen. Es erscheint anschließend ein Pop-Up-Fenster, wo sich der Download-Link für die exportierte Evaluierung befindet.

Sind mehrere Evaluierungen gleichzeitig ausgewählt, werden diese als ZIP-Dateien exportiert.
Hinweis: Ist keine Evaluierung ausgewählt, ist die Option „Exportieren“ ausgegraut und nicht auswählbar.
Import
Exportierte Evaluierungen kann man in einem anderen RAG-Service auch wieder als ZIP-Dateien importieren. Importierte Evaluierungen von anderen RAG Services werden in der Übersichtstabelle mit „[Imported]“ vor dem Namen gekennzeichnet. Sie werden mit den weiteren (nicht importierten) Evaluierungen anhand des Evaluierungsstarts sortiert.