
Sure, you can handle it. But should you?
Let our experts manage the tech maintenance while you focus on your business.
Let our experts manage the tech maintenance while you focus on your business.
Alternative Suchvorschläge und automatische Sucherweiterung
Einleitung
Alternative Suchvorschläge
Werden für die vom Benutzer eingegebenen Suchbegriffe zu wenige Treffer gefunden, so wird oberhalb der Resultatsliste ein Feld „Meinten Sie:“ eingeblendet, in dem ein alternativer Suchvorschlag angeboten wird.
Automatische Sucherweiterung
Ist diese Funktion konfiguriert, so wird neben den vom Benutzer eingegebenen Begriffen auch gleich zusätzlich nach dem alternativen Suchvorschlag gesucht.
Konfiguration
Mehrwortfähigkeit des Term Lexikons
Auf der Registerkarte „Indices“ befindet sich ganz unten ein Abschnitt „Global Index Settings“, der einen Unterabschnitt „Term Lexicon Settings“ enthält.
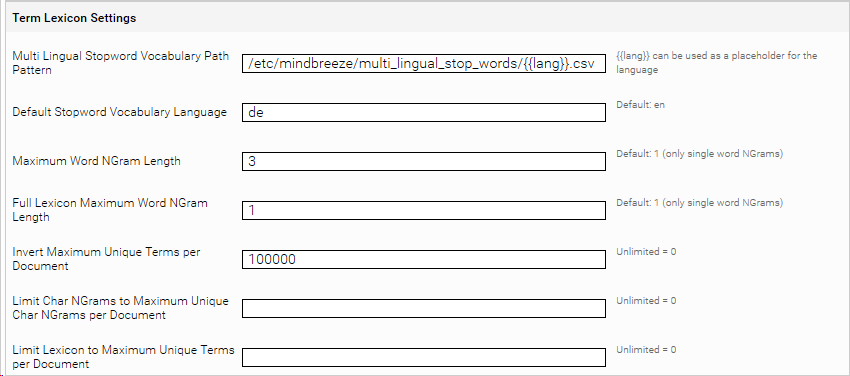
Folgende Eigenschaften können über diese Felder konfiguriert werden:
„Multi Lingual Stopword Vocabulary Path Pattern“: hier wird ein Pfadmuster angegeben, mit dem CSV Dateien erreicht werden könne, die Stoppwörter enthalten.
Der Platzhalter {{lang}} wird dabei durch die jeweilige Sprache ersetzt.
Diese Stoppwörter werden bei der Erstellung des Term-Lexicons nicht berücksichtigt.
„Default Stopword Vocabulary Language“: Hier wird die standardmäßig verwendete Sprache in Form eines i18n-Identifiers angegeben. Dieser Wert wird dann Ersatz für den {{lang}} Platzhalter verwendet
Das Metadatum mes:lang wird verwendet um den Platzhalter {{lang}} auszuprägen.„Maximum Word NGram Length“: wird ein Wert größer 1 einstellt, z. B. 3, so werden während der Invertierung des Index benachbarte Wörter gesammelt und abgelegt
Einzelne Wörter bei Wert >= 1
Zusätzlich benachbarte Wortpaare bei Wert >= 2
Zusätzlich benachbarte Worttripel bei Wert >= 3
usw
Diese Wortkombinationen werden dann sowohl bei den alternativen Suchvorschlägen als auch bei der automatischen Sucherweiterung bevorzugt zur Berechnung der Alternativen herangezogen.
„Full Lexicon Maximum Word NGram Length”: für das Full Lexicon werden nur N Wort NGRAMs herangezogen für N <= Limit Full Lexicon to Word NGram Length.
„Invert Maximum Unique Terms per Document“: stoppt die Dokumentinvertierung bei Erreichen der angegebenen maximalen Anzahl eindeutiger Terme im Dokument.
„Limit Char NGrams to Maximum Unique Char NGrams per Document“: maximale Anzahl der eindeutigen Zeichen-Ngrammen, die pro Dokument gespeichert werden sollen.
„Limit Lexicon to Maximum Unique Terms per Document“: maximale Anzahl der eindeutigen Terme im vollen Lexikon, die pro Dokument gespeichert werden sollen.
Die Term Lexikon Eigenschaften können zusätzlich per Index überschrieben werden:

Aktivierung der automatischen Sucherweiterung
Auf der Registerkarte „Client Services“ (nach Klick auf das Feld „Advanced Settings“) gibt es unter dem Abschnitt „Query Settings“ ein Feld „Enable Query Expansion for Similar Terms“, mittels dessen die automatische Sucherweiterung eingeschalten werden kann. Standardmäßig ist das Feld ausgeschaltet.
